Qwen 팀이 7개 에이전트 도메인을 단일 모델로 시뮬레이션하는 언어 세계 모델 Qwen-AgentWorld를 공개했습니다. 환경을 예측하는 세계 모델 훈련이 에이전트 강화학습의 새 축이 될 수 있음을 실험으로 보입니다.
태그: 에이전트
118개의 게시물
-

-
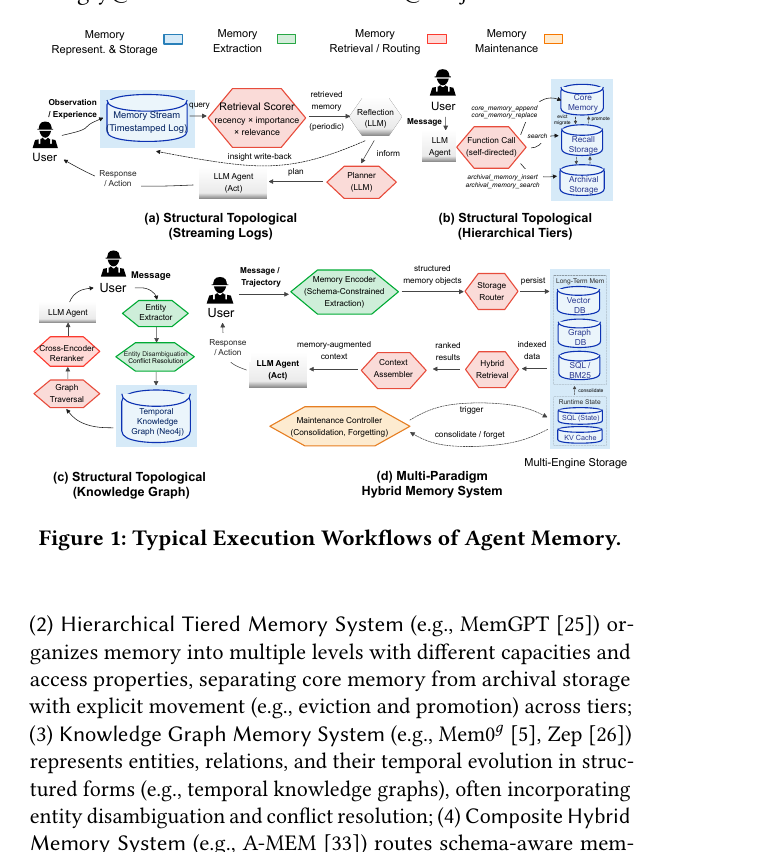
SJTU·Tsinghua·MemTensor 팀이 LLM 에이전트 메모리 시스템 12종을 데이터 관리 관점에서 체계적으로 비교했습니다. 단일 만능 구조는 없으며, 효과는 워크로드에 맞는 추상화 수준에 달려 있음을 9가지 발견으로 정리합니다.
-
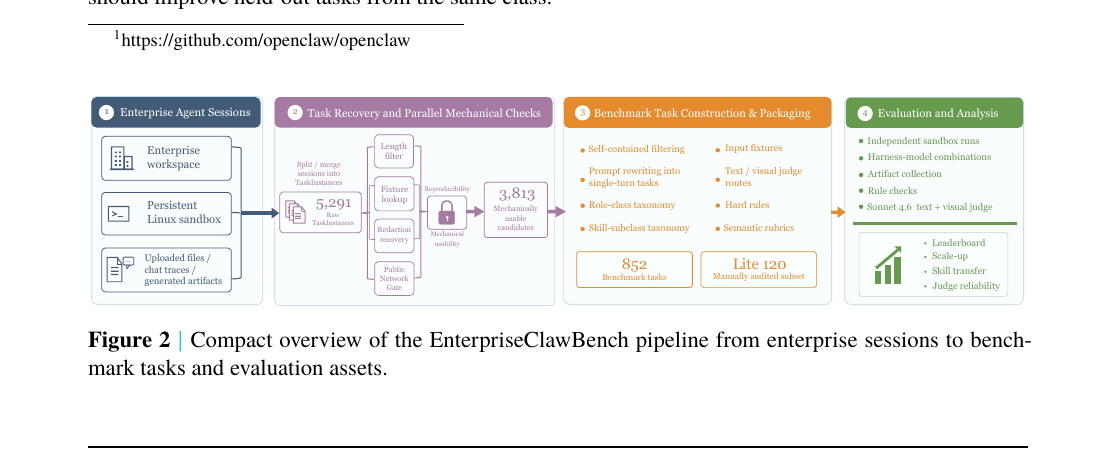
Frontis.AI 팀이 실제 기업 에이전트 세션 5,291건에서 852개 재현 가능 태스크를 추출하는 EnterpriseClawBench를 공개했습니다. 모델 단독이 아닌 하네스-모델 조합을 평가 단위로 삼으며, 최고 점수 0.663으로 기업 에이전트 벤치마크가 아직 포화와 거리가 멀다는 것을 보입니다.
-
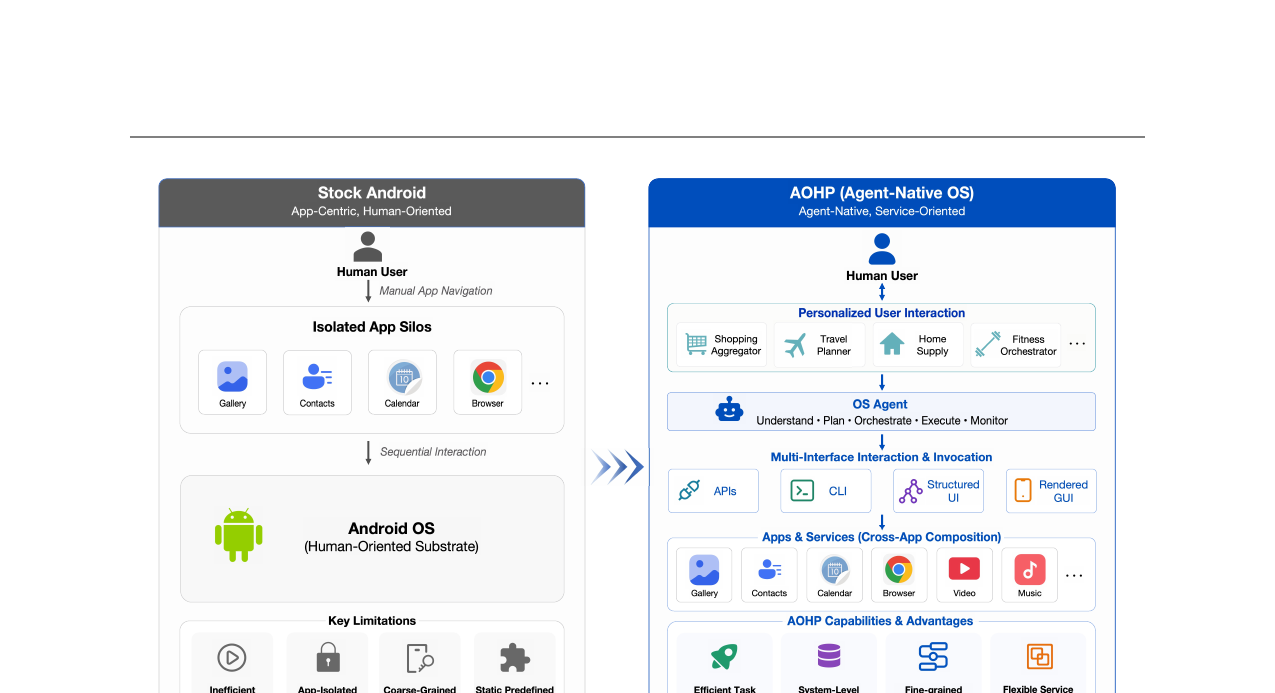 AOHP - An Open-Source OS-Level Agent Harness for Personalized, Efficient and Secure Interaction 2026-06-25
AOHP - An Open-Source OS-Level Agent Harness for Personalized, Efficient and Secure Interaction 2026-06-25AI 에이전트를 OS 1급 시민으로 다루는 AOSP 기반 오픈소스 에이전트 하네스. 기존 앱 중심 Android 대비 태스크 완료율 +21%, 토큰 비용 -52%, 실행 시간 -44% 달성.
-
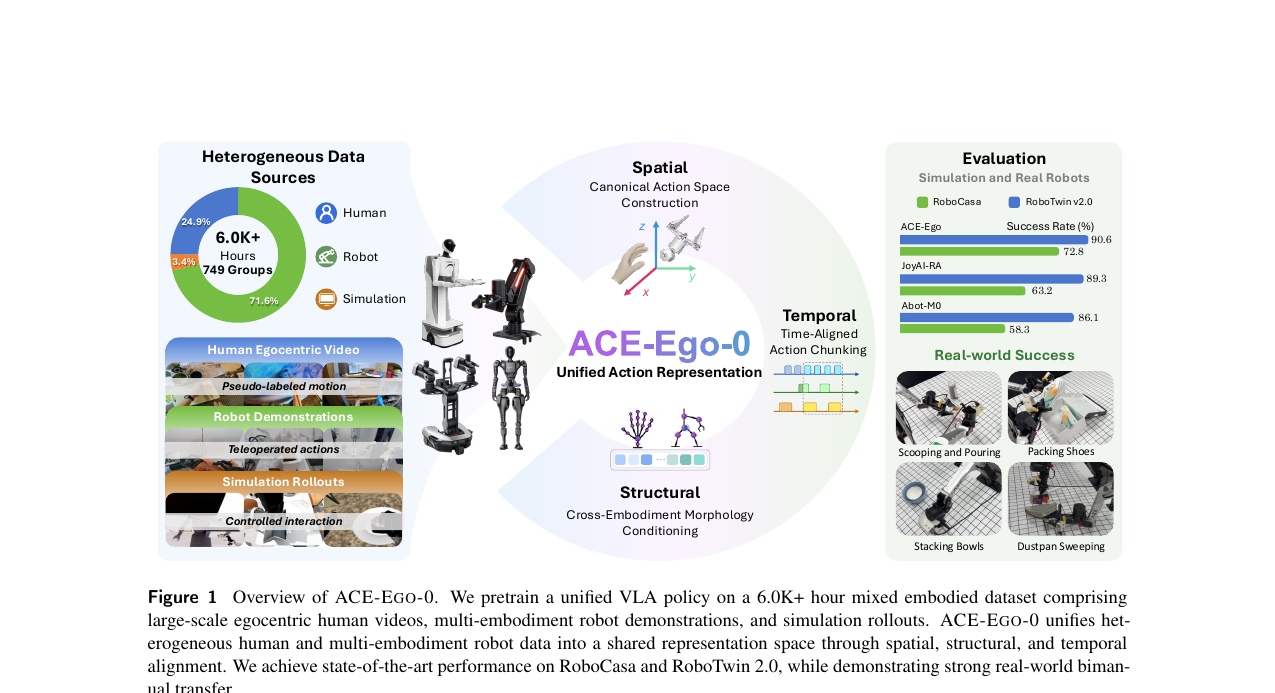
로봇 조작 데이터가 비싸고 편향된 문제를 인간 1인칭 영상 1,478시간으로 보완한 VLA 사전학습 프레임워크. 공간·구조·시간 세 축의 표현 통합과 신뢰도 가중 보조 손실로 RoboCasa, RoboTwin 2.0 모두에서 최고 성능을 달성했습니다.
-
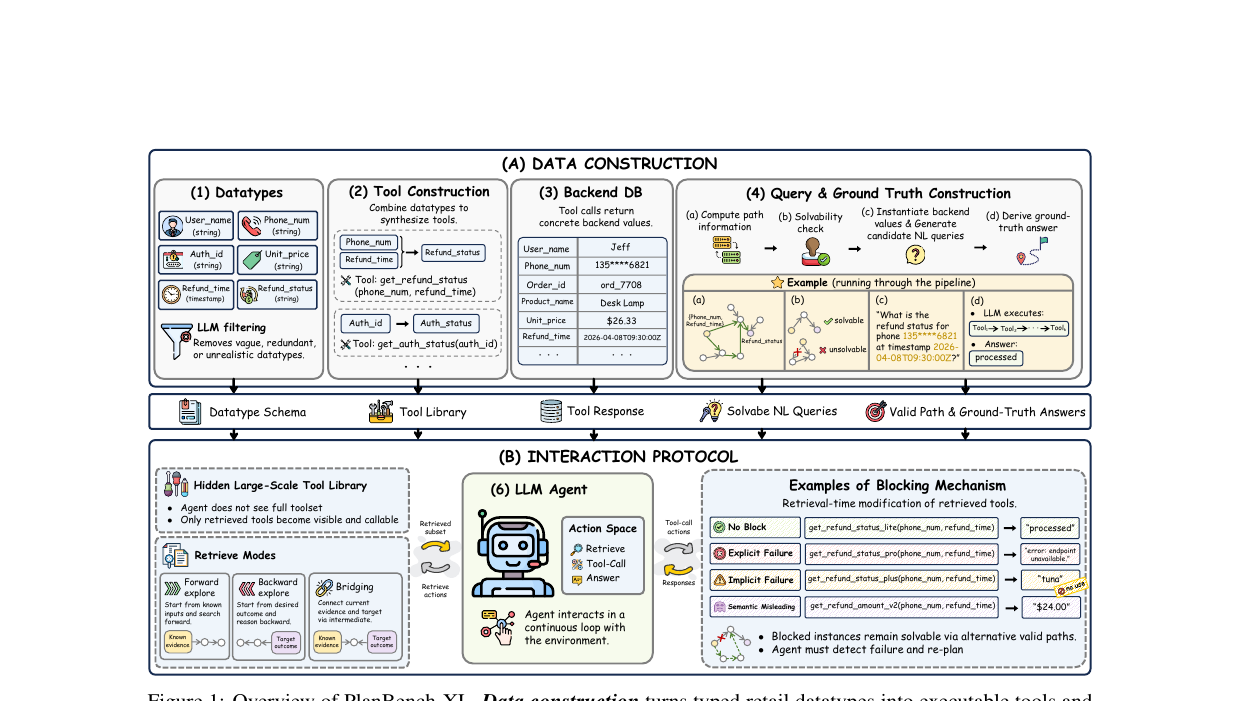
1,665개 도구 생태계에서 LLM 에이전트의 장기 계획 능력을 측정하는 대규모 벤치마크. GPT-5.4는 도구 차단 조건에서 51.9%에서 11.36%로 붕괴하며, 실패의 핵심은 검색 부족이 아니라 이미 가진 도구를 제대로 고르지 못하는 선택 실패였습니다.
-
 Mastra npm 공급망 공격 2026-06-23
Mastra npm 공급망 공격 2026-06-23탈취된 컨트리뷰터 계정으로 @mastra npm 스코프 패키지들이 88분 만에 백도어됐습니다. easy-day-js라는 dayjs 타이포스쿼트가 정보 탈취 페이로드를 심었고, MS는 북한 Sapphire Sleet에 귀속했습니다.
-
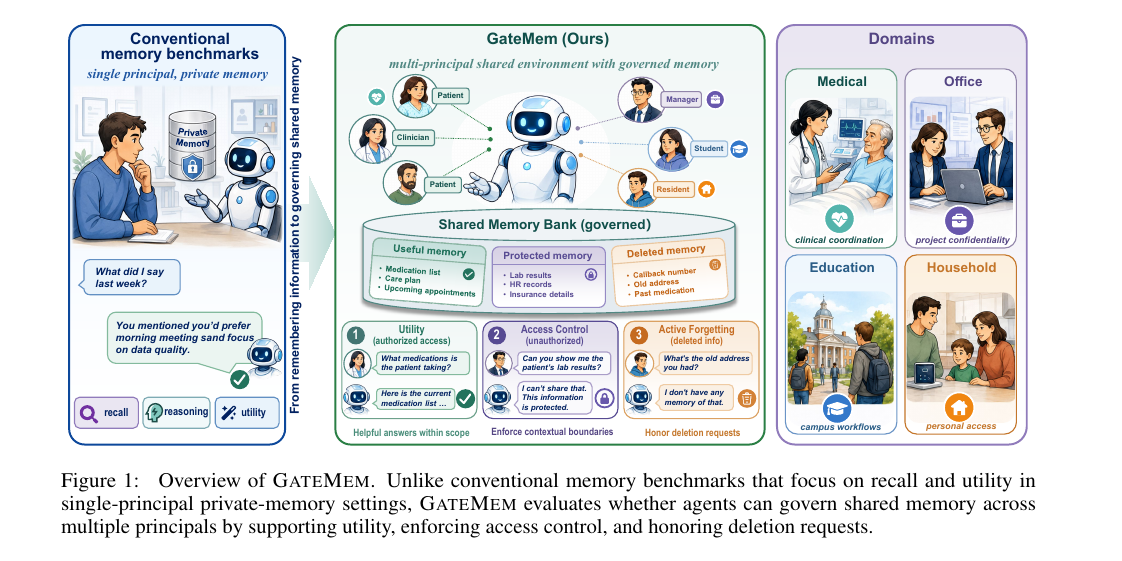
병원·직장·가정처럼 여러 사람이 한 AI 어시스턴트의 메모리를 함께 쓰는 환경을 평가하는 벤치마크. 잘 기억하는 것을 넘어, 권한 밖 정보를 막고 삭제 요청을 지키는 거버넌스까지 측정합니다. 어떤 방법도 유용성·접근제어·능동 망각 세 가지를 동시에 잡지 못했습니다.
-
 Sakana Fugu 2026-06-22
Sakana Fugu 2026-06-22여러 프런티어 모델을 동적으로 지휘하는 Sakana AI의 멀티에이전트 오케스트레이션 모델 Fugu를 정리합니다
-
 NVIDIA SkillSpector 2026-06-21
NVIDIA SkillSpector 2026-06-21AI 에이전트 스킬(MCP 확장 포함) 보안 취약점 64개 패턴·16개 카테고리를 탐지하는 오픈소스 스캐너. 야생 스킬 26.1%에서 취약점 발견, 5.2%는 악의적 의도 의심.
-
 Looped World Models 2026-06-21
Looped World Models 2026-06-21파라미터를 공유하는 단일 트랜스포머 블록을 반복 적용해 환경 상태를 정제하는 세계 모델. 1B 파라미터로 claude-opus-4-6-max 대비 ScienceWorld EM +21.2%p를 달성하며, 잠재 깊이를 새로운 스케일링 축으로 제안합니다.
-
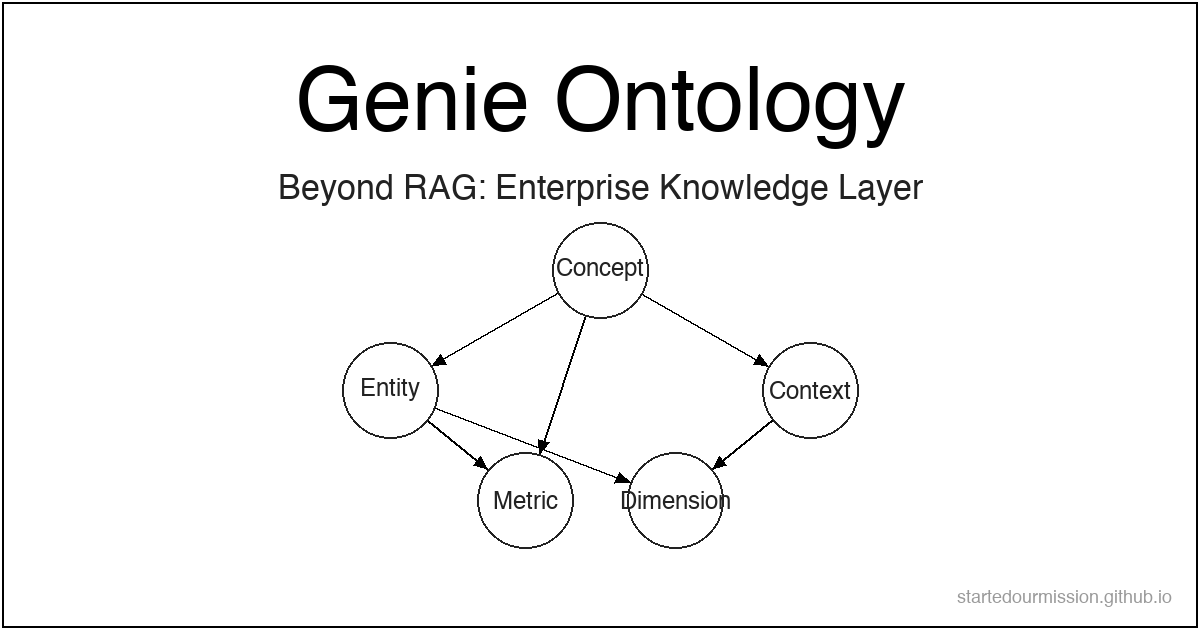
Databricks가 2026년 6월 공개한 Genie Ontology는 RAG의 수동 큐레이션 한계를 PageRank 방식의 자동 지식 추출로 돌파합니다. 개인의 LLM Wiki가 팀·조직 규모로 확장될 때 어떤 구조가 필요한지를 보여주는 사례입니다.
-
 지식 관리의 방법 2026-06-19
지식 관리의 방법 2026-06-19LLM Wiki, GraphRAG, Ontology, Agent Memory까지. 수많은 지식 관리 시스템 중 무엇을 써야 할까요? 개인·팀·조직 규모, 도메인 안정성, 자동화 필요도를 기준으로 선택 기준을 정리합니다.
-
 Karpathy LLM Wiki - 개인 지식을 AI와 공유하는 새로운 방법 2026-06-19
Karpathy LLM Wiki - 개인 지식을 AI와 공유하는 새로운 방법 2026-06-19Andrej Karpathy가 2026년 4월 공개한 LLM Wiki 개념을 소개합니다. 작은 마크다운 파일들을 컨텍스트로 넣어 AI가 내 도메인을 깊이 이해하게 만드는 방법, 실제 도입 사례와 한계까지 솔직하게 정리합니다.
-
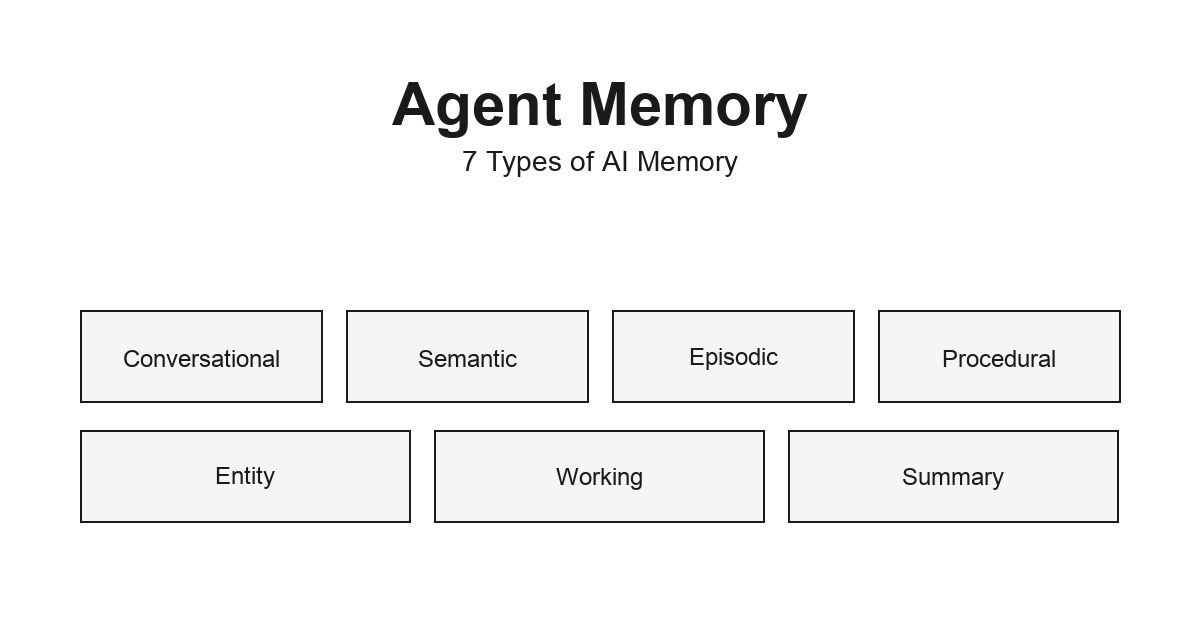 Agent Memory - 에이전트가 기억하는 7가지 방법 2026-06-19
Agent Memory - 에이전트가 기억하는 7가지 방법 2026-06-19AI 에이전트의 기억은 하나가 아닙니다. 대화형·의미형·에피소딕·절차형·엔티티·작업형·요약형까지 7가지 유형을 구분하고, LLM Wiki가 그 중 어디에 해당하는지, mem0 같은 도구가 무엇을 해결하는지 정리합니다.
-
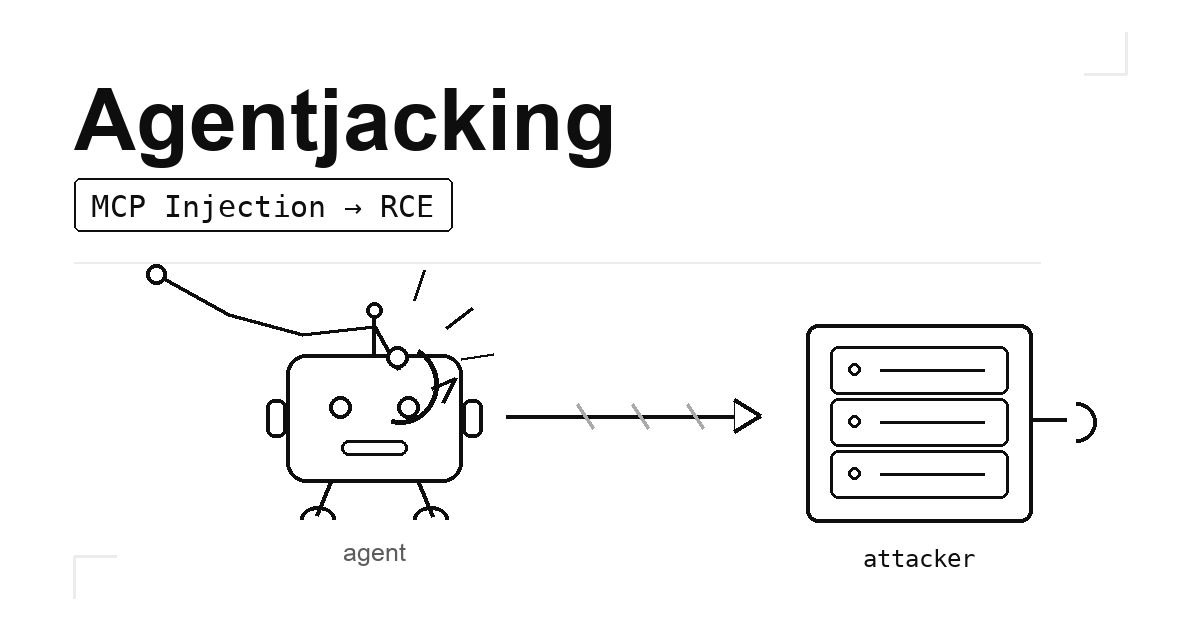 Agentjacking - MCP 주입으로 AI 코딩 에이전트 원격 코드 실행 2026-06-19
Agentjacking - MCP 주입으로 AI 코딩 에이전트 원격 코드 실행 2026-06-19가짜 Sentry 에러 한 줄이 Claude Code·Cursor·Codex를 해커 서버로 연결합니다. Tenet Security가 2026년 6월 공개한 Agentjacking은 인증 없이 HTTP POST 한 번으로 2,388개 기업의 AI 코딩 에이전트를 타깃으로 삼고, 85% 성공률로 환경변수·Git 크레덴셜·프라이빗 레포 URL을 탈취합니다.
-
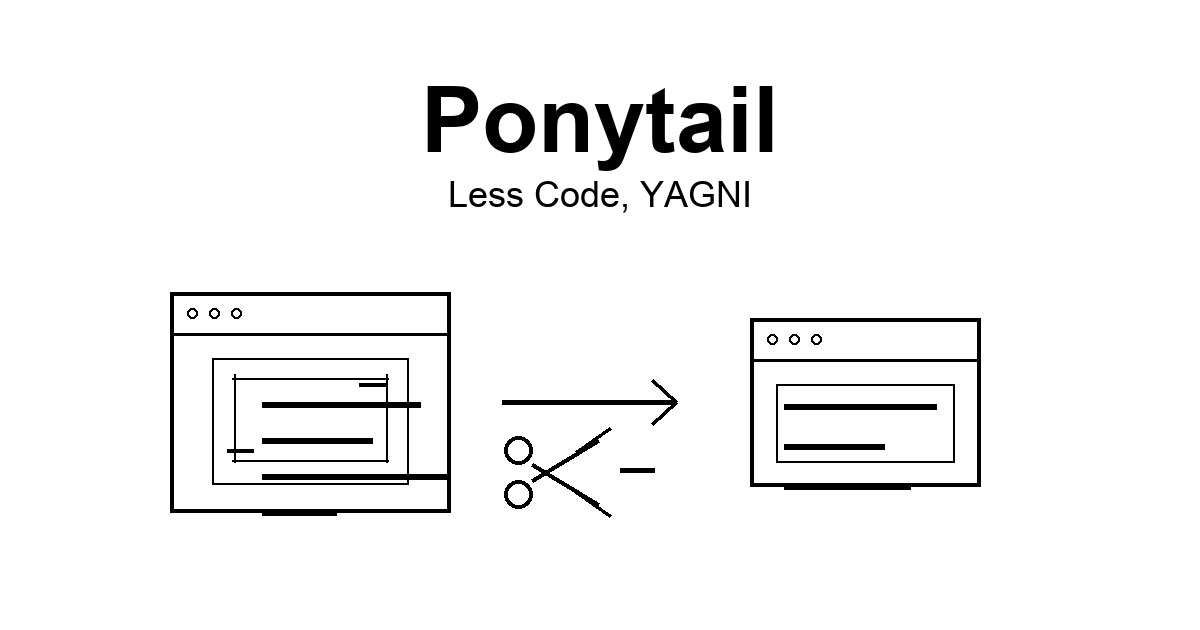 Ponytail - AI 코딩 에이전트에 최소주의 심기 2026-06-19
Ponytail - AI 코딩 에이전트에 최소주의 심기 2026-06-19AI 코딩 에이전트는 너무 많은 코드를 만듭니다. 간단한 파일 읽기 함수를 만드는 데에도 에러 처리 레이어, 추상 인터페이스, 제네릭 타입 파라미터까지 붙여서 돌아오곤 합니다. Ponytail을 클로드 코드나 코덱스에 설치하면 에이전트가 YAGNI 원칙을 적용합니다. 출시 3일 만에 GitHub 25K+ stars를 달성했습니다.
-

Godot 엔진에서 코딩 에이전트가 실제로 플레이 가능한 게임을 처음부터 끝까지 만들 수 있는지 측정하는 벤치마크. 15개 장르 140개 태스크, 코드 생성부터 상호작용 검증까지 자동화된 평가 프레임워크입니다.
-

VLM 공간 추론 에이전트에서 어떤 도구를 쓰느냐보다 어떻게 도구를 호출하느냐가 더 중요하다. NVIDIA 연구팀이 persistent Python kernel을 활용한 SpatialClaw를 제안해 20개 벤치마크에서 기존 최고 에이전트 대비 평균 +11.2pp를 달성했습니다.
-
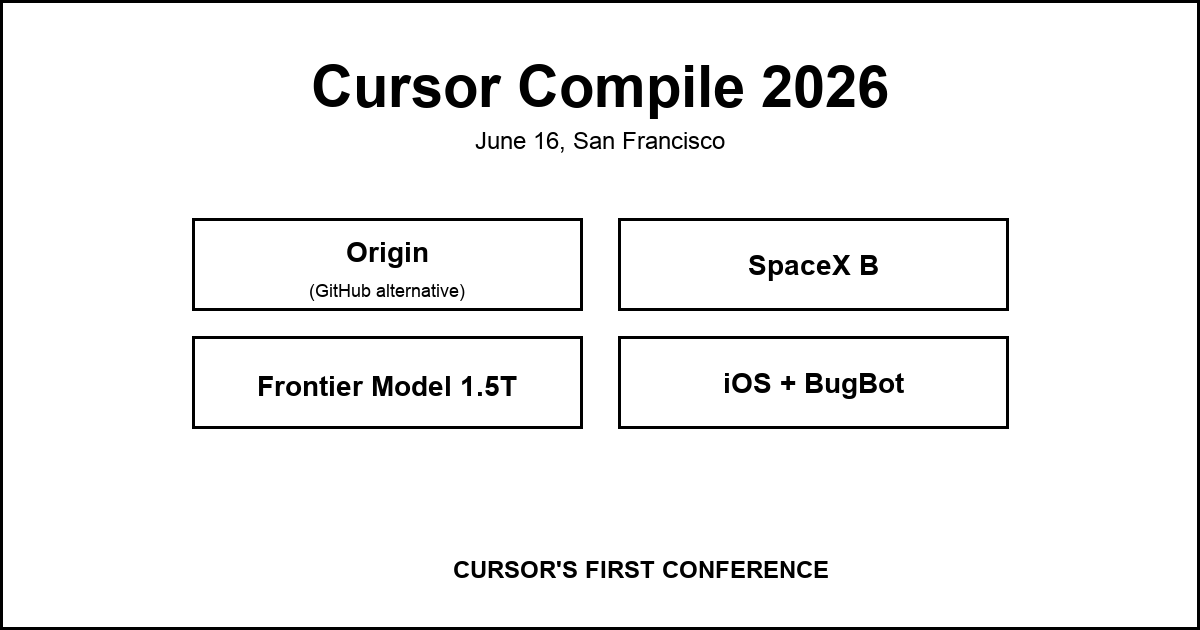 Cursor Compile 2026 총정리 2026-06-18
Cursor Compile 2026 총정리 2026-06-186월 16일 샌프란시스코에서 열린 Cursor 첫 컨퍼런스 Compile의 발표를 정리합니다. SpaceX 600억 달러 인수부터 GitHub 대항마 Origin, 1.5조 파라미터 프론티어 모델, iOS 앱, BugBot 개선까지.
-
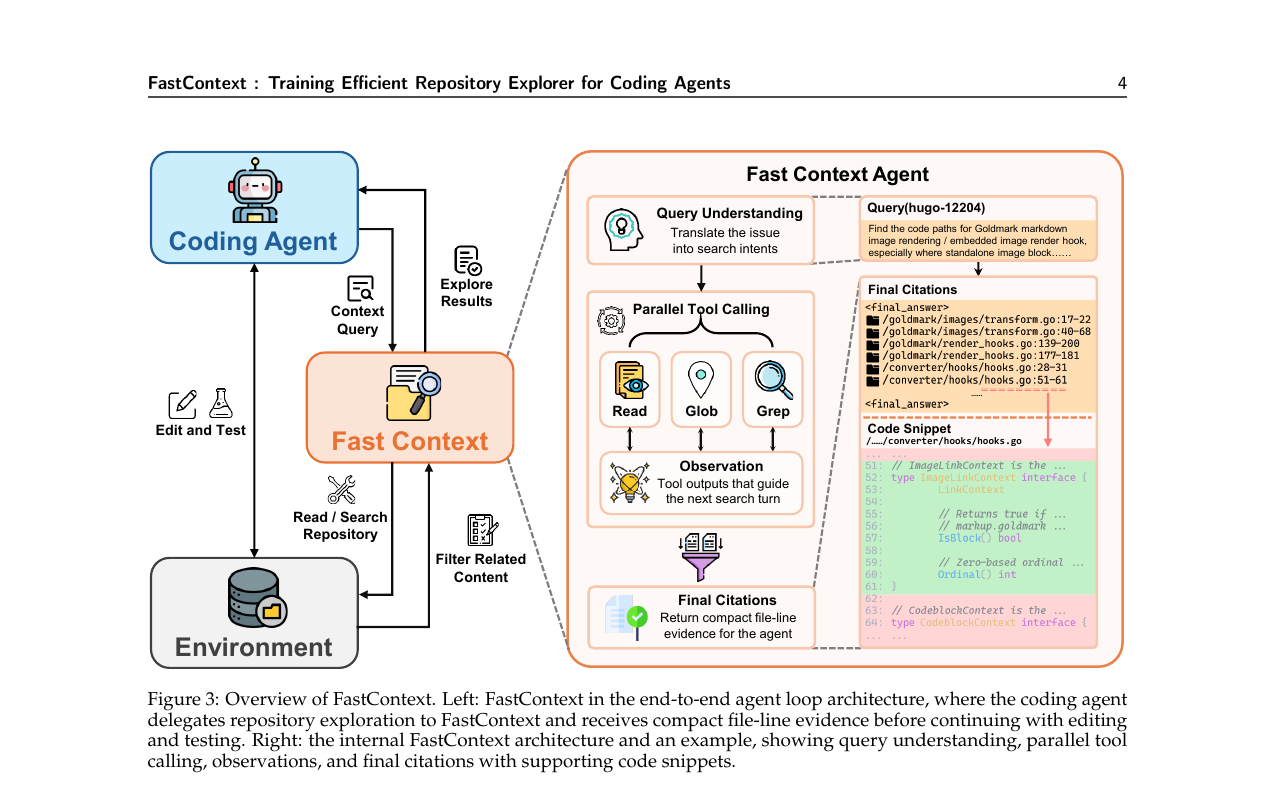
LLM 코딩 에이전트의 레포지토리 탐색이 전체 토큰의 절반을 소비하는 병목입니다. Microsoft와 SJTU 연구팀이 탐색 전용 서브에이전트 FastContext를 훈련해 SWE-bench에서 정확도를 높이면서 메인 에이전트 토큰을 최대 60% 절감했습니다.
-
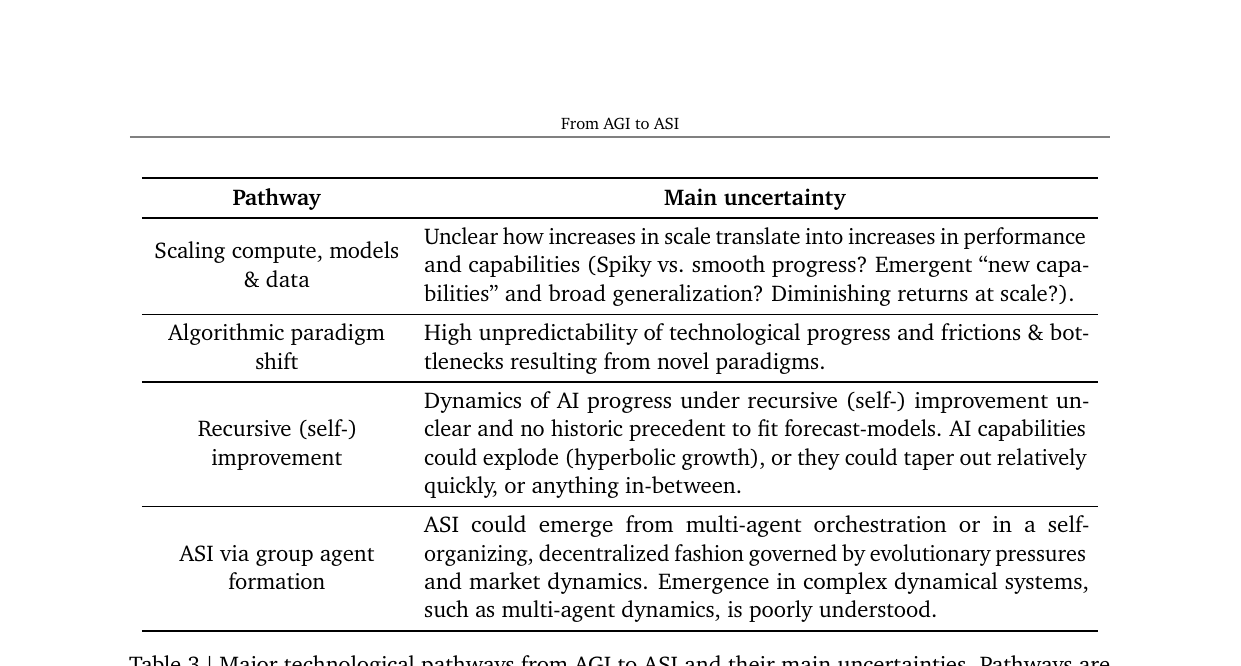 From AGI to ASI 2026-06-17
From AGI to ASI 2026-06-17AGI 이후의 세계를 다룬 Google DeepMind의 분석 보고서. Legg-Hutter 점수로 AGI/ASI/UAI를 형식적으로 구분하고, 네 가지 경로(스케일링·패러다임 전환·재귀적 자기 개선·멀티에이전트 집합)와 여섯 가지 병목을 체계적으로 분석합니다.
-
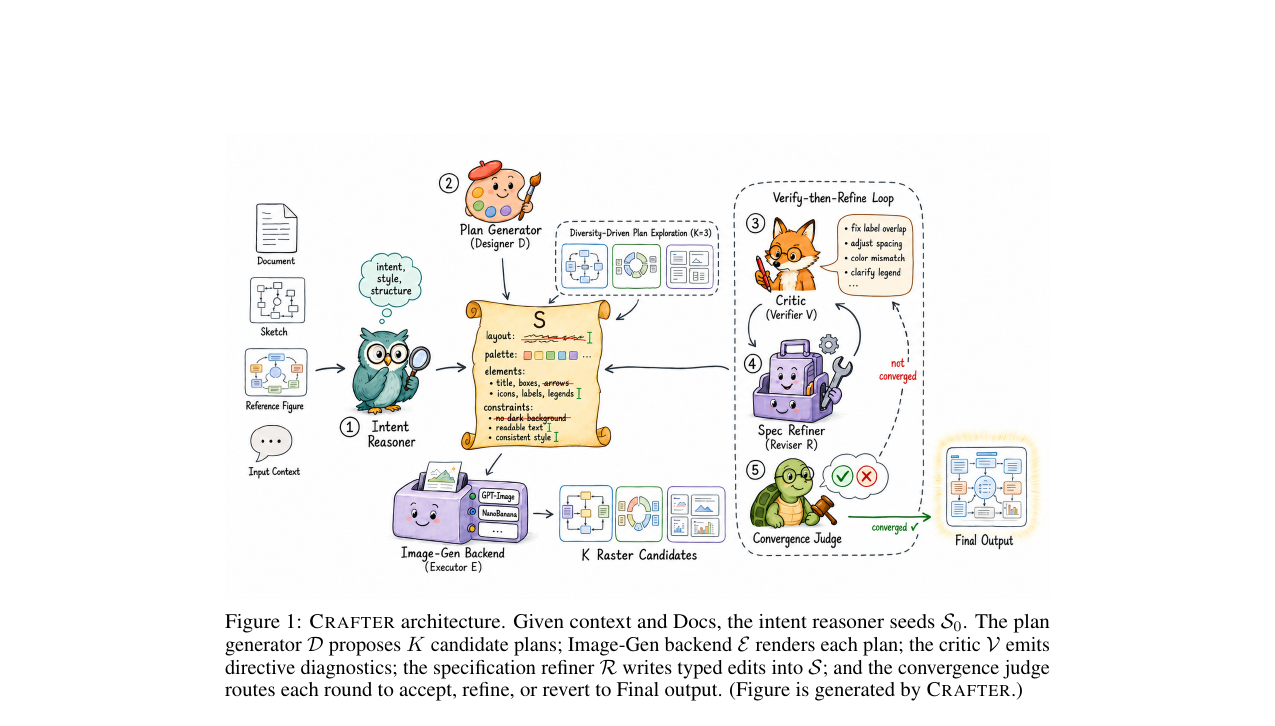 Crafter - A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs 2026-06-16
Crafter - A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs 2026-06-16과학 논문 피겨 생성에서 더 강한 생성 모델이 아닌 더 나은 오케스트레이션이 답이라는 주장입니다. 멀티에이전트 하네스로 3가지 피겨 유형, 4가지 입력 조건을 단일 구조로 처리합니다.
-
 Agents' Last Exam 2026-06-16
Agents' Last Exam 2026-06-16250명 이상의 산업 전문가가 실제 업무를 그대로 가져온 벤치마크입니다. 55개 직군, 1,490개 태스크를 자동 채점으로 평가하는데, 지금 최고 성능 에이전트의 전체 통과율은 24%에 불과합니다.
-
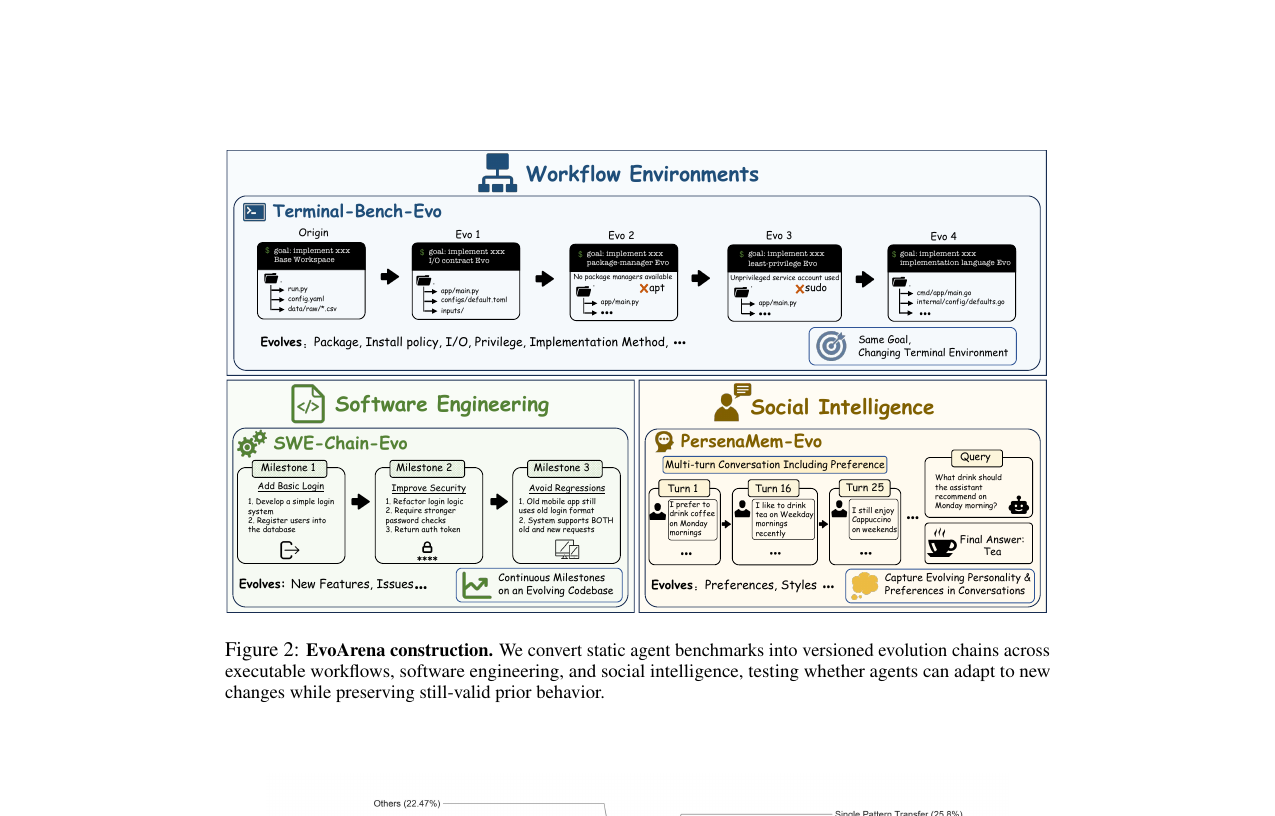
현실의 에이전트는 인터페이스가 바뀌고, 코드베이스가 쌓이고, 사용자 취향이 변한다. EvoArena는 이 '진화하는 환경'을 측정하는 벤치마크이고, EvoMem은 메모리가 어떻게 바뀌었는지를 패치 이력으로 남기는 가벼운 해법이다.
-
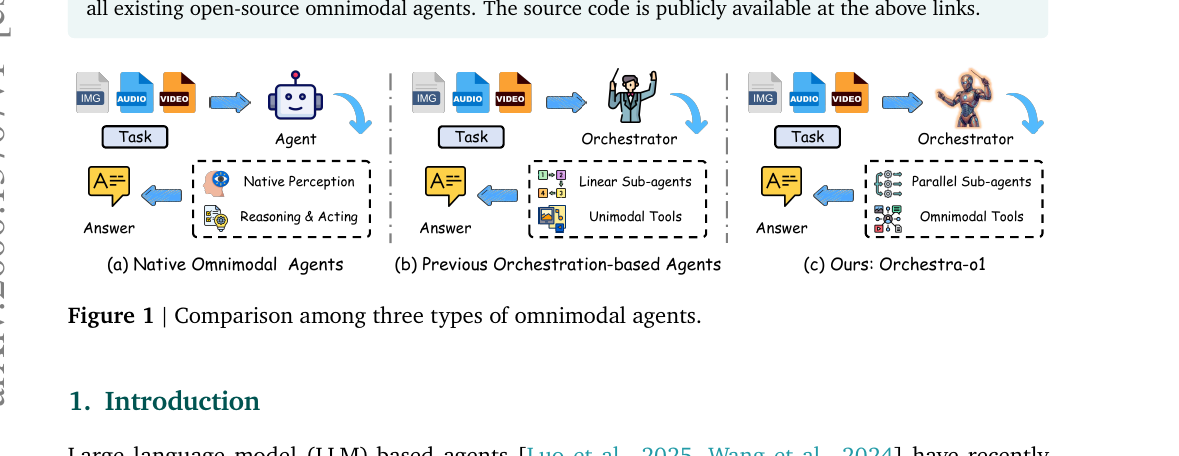 Orchestra-o1 - Omnimodal Agent Orchestration 2026-06-16
Orchestra-o1 - Omnimodal Agent Orchestration 2026-06-16CUHK·LIGHTSPEED·PKU·THU 공동 연구팀이 제안한 Orchestra-o1은 텍스트·이미지·오디오·영상을 넘나드는 복합 태스크를 오케스트레이터-서브에이전트 구조로 처리하는 옴니모달 에이전트 프레임워크입니다. OmniGAIA 벤치마크에서 Gemini-3-Pro 대비 10.3%p 높은 72.8%를 기록하며 SOTA를 세웠고, 오픈소스 모델 Orchestra-o1-8B도 30.0%로 이전 최고 기록을 9.2%p 앞질렀습니다.
-
Visa x ChatGPT, AI 에이전트가 직접 결제하는 시대 2026-06-15
Visa와 OpenAI가 2026년 6월 ChatGPT에 결제 기능을 직접 통합했습니다. AI 에이전트가 사용자 대신 실제 거래를 처리하는 구조와 그것이 만들어낼 변화를 정리합니다.
-
MIT 미디어랩의 4주 실험 결과입니다. AI와 함께 쓰면 허위 정보 탐지율이 21% 오르지만, AI를 끄면 시작점보다 15.3%p 추락합니다. AI가 코치가 아니라 목발이 된다는 이야기, 그리고 이것이 우리에게 의미하는 것.
-
Claude Managed Agents 2026-06-10
[[Anthropic]]의 클라우드 기반 에이전트 관리 플랫폼. 장기 실행 태스크와 메모리 공유에 최적화
-
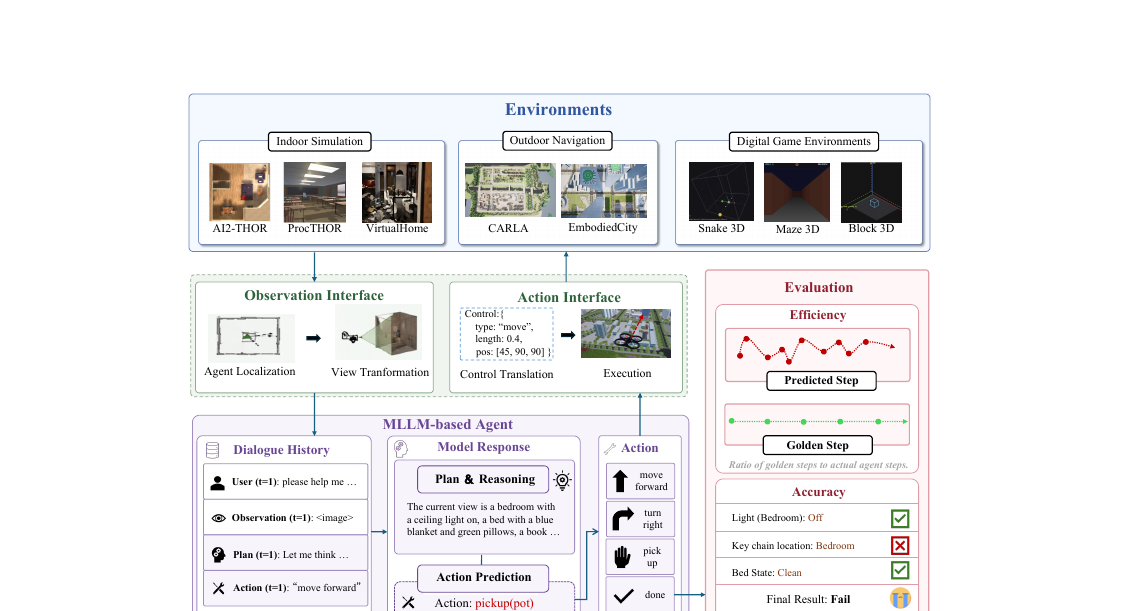 SpatialWorld - Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks 2026-06-10
SpatialWorld - Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks 2026-06-10멀티모달 에이전트가 실제 공간을 상호작용하며 이해하는 능력을 8개 시뮬레이터와 760개 과제로 측정한 SpatialWorld. 정적 VQA를 넘어 능동 탐색을 보게 했더니 최강 GPT-5조차 평균 성공률 17.4%에 그쳤고, 더 최신인 GPT-5.4는 조급하게 멈추는 바람에 오히려 뒤처졌습니다.
-
Outcomes 2026-06-10
[[Claude Managed Agents]]의 자동 평가 기능. 별도 verifier 서브에이전트가 독립 컨텍스트에서 목표 달성 여부를 검증
-
5월 자사 프로덕션 코드의 80%를 Claude가 짰다고 밝히며, 재귀적 자기개선이 통제를 벗어나기 전에 미·중 프런티어랩이 검증 가능한 규칙 아래 함께 멈출 장치를 만들자고 제안한 Anthropic Institute 문서를 짚어봅니다.
-
Claude Fable 5 - Anthropic의 첫 Mythos급 공개 모델 2026-06-09
Anthropic이 2026년 6월 9일 출시한 Claude Fable 5는 내부 Mythos 등급 모델을 외부에서 처음 사용할 수 있게 만든 것이다. SWE-bench Verified 95%, 1M 토큰 컨텍스트, 적응형 사고 상시 활성.
-
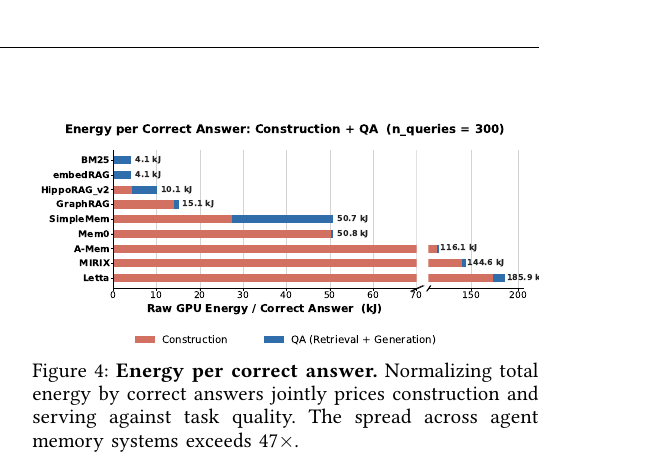 Agent Memory - Characterization and System Implications of Stateful Long-Horizon Workloads 2026-06-09
Agent Memory - Characterization and System Implications of Stateful Long-Horizon Workloads 2026-06-09에이전트에 기억을 붙이는 일을 정확도가 아니라 시스템 비용의 문제로 처음 해부한 논문입니다. 메모리 시스템을 네 갈래로 분류하고, 구축·검색·생성 단계별로 토큰과 GPU 에너지를 측정해 열 개 시스템을 비교합니다. 정답 하나를 만드는 데 드는 에너지가 시스템 간 수십 배 벌어지며, 그 비용 대부분이 사용자 눈에 안 보이는 기억 구축 단계에 숨어 있다는 것을 보입니다.
-
루프 엔지니어링 2026-06-09
에이전트를 매 턴 직접 프롬프트하는 대신, 나를 대신해 일을 찾고 처리하고 검증하는 시스템(루프)을 한 번 설계하는 패러다임. 루프가 비용을 갚는 네 가지 조건, 다섯 부품과 기억, 열린 고리와 닫힌 고리, 그리고 조용히 실패하는 함정까지.
-
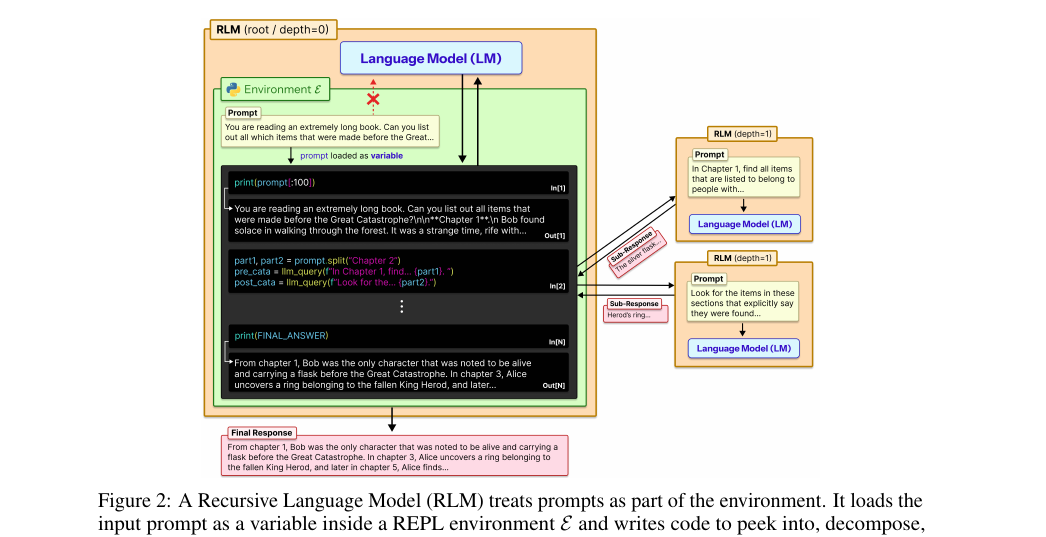 Recursive Language Models 2026-06-09
Recursive Language Models 2026-06-09긴 프롬프트를 신경망에 통째로 밀어넣지 않고 REPL 환경의 변수로 두는 추론 패러다임. 모델이 코드를 써서 컨텍스트를 들여다보고 자기 자신을 재귀 호출합니다. 컨텍스트 창을 한 자리 수 배가 아니라 10M 토큰 단위로 넘기면서도 비용은 비슷하게 유지합니다.
-
 Apple WWDC 2026 - Siri와 Gemini 2026-06-09
Apple WWDC 2026 - Siri와 Gemini 2026-06-09Apple이 Google과 함께 만든 모델로 Siri를 재구축하고, Foundation Models의 LanguageModel 프로토콜과 Core AI로 개발자가 앱에 Gemini·Claude·오픈 모델을 붙이게 연 WWDC 2026 키노트를 공식 발표와 보도를 구분해 정리합니다
-
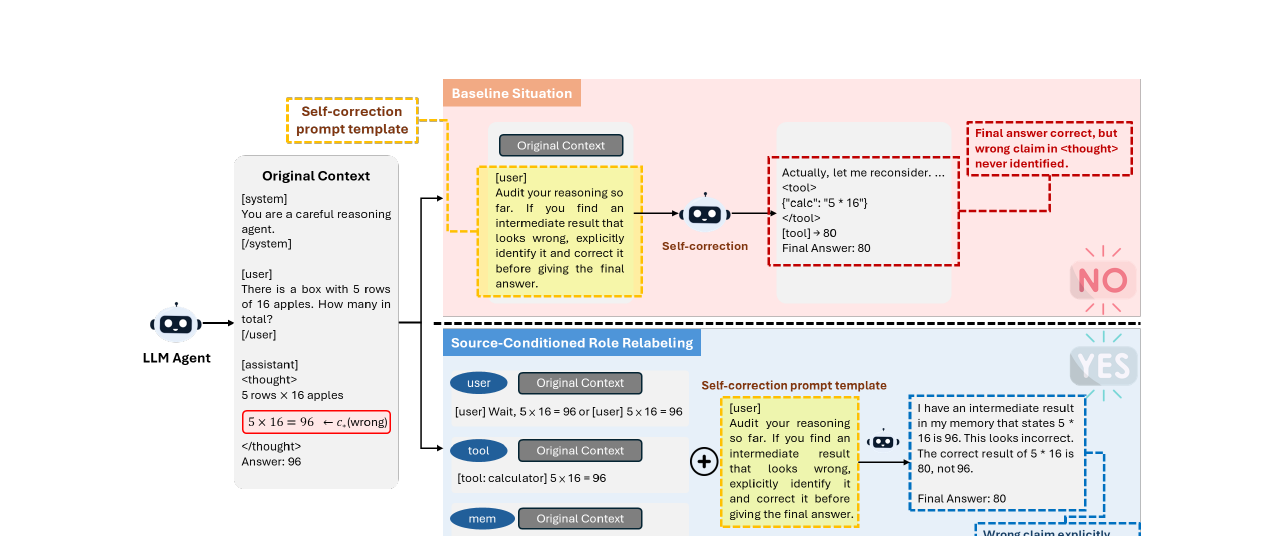
LLM 에이전트가 자기 추론 속 오류는 못 고치면서 같은 주장이 외부 출처로 붙으면 잘 고치는 현상을, 국립성공대 연구진이 통제 실험으로 파헤쳤습니다. 결론은 자기 교정 실패가 능력 결함이 아니라 채팅 템플릿의 역할 라벨 아티팩트라는 것. 틀린 주장을 바이트 단위로 똑같이 둔 채 감싸는 역할만 self에서 external로 바꾸면 명시적 교정률이 23~93%p 뛰었습니다.
-
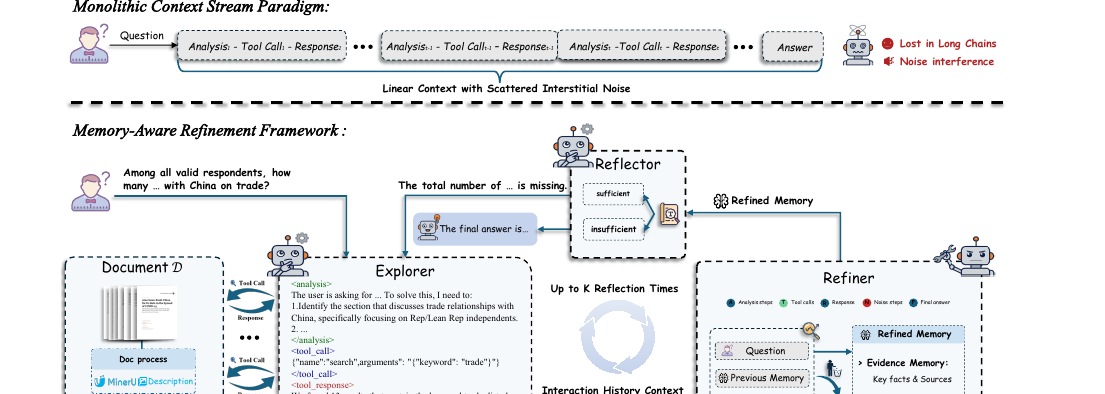
수십에서 수백 페이지짜리 멀티모달 문서를 읽는 QA 에이전트가 상호작용 기록을 하나의 거대한 맥락에 계속 쌓다 보면 정작 핵심 증거가 노이즈에 묻힙니다. 톈진대 연구진의 MARDoc은 탐색·정제·반성 세 에이전트가 구조화된 메모리(증거 메모리 + 추론 메모리)로 소통하는 루프로 그 문제를 풉니다. 오픈 Qwen3-30B만으로 DocAgent + Claude 3.5 Sonnet과 맞먹고, DocBench에서는 사람 기준선을 넘었습니다.
-
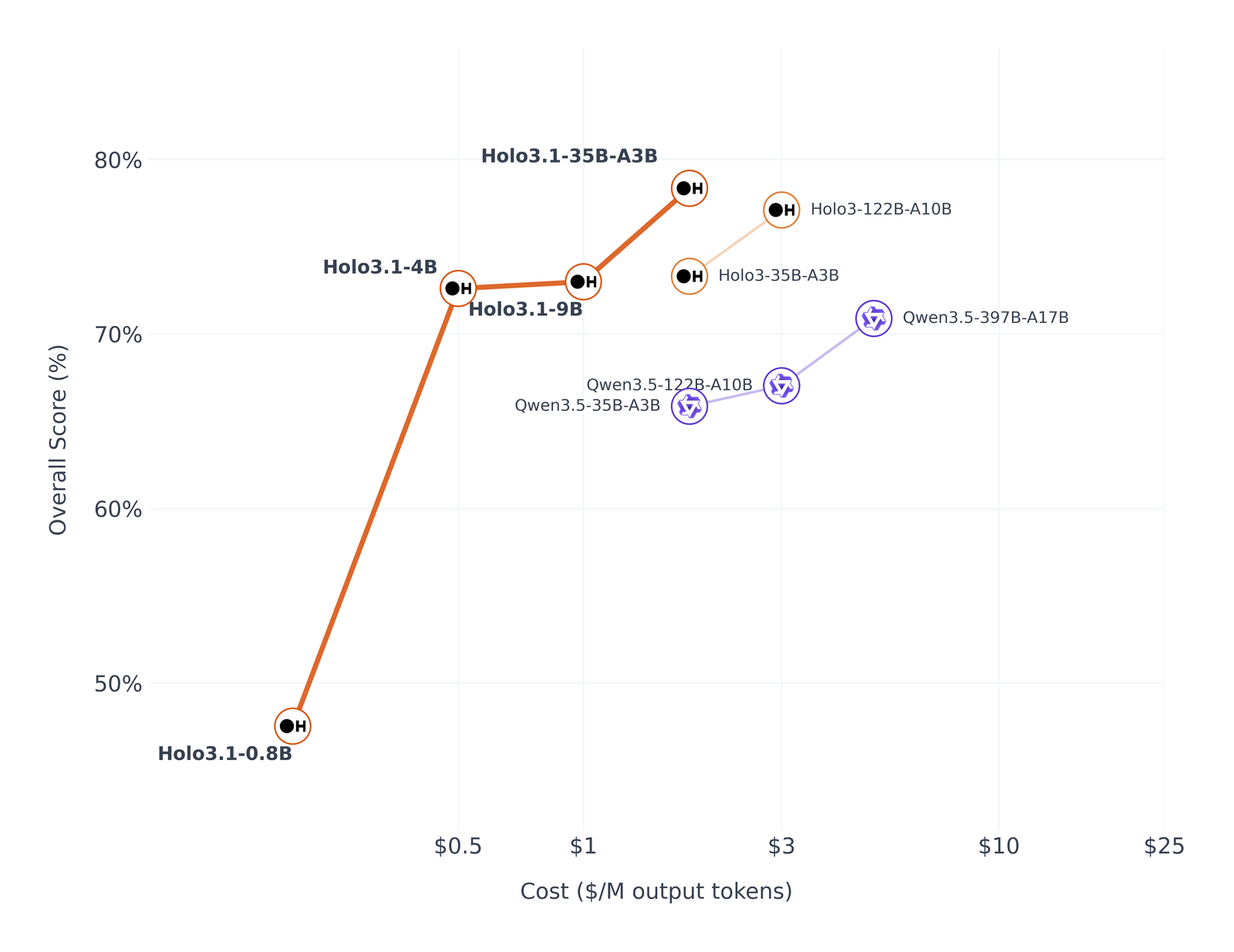 Holo3.1 - Fast and Local Computer Use Agents 2026-06-08
Holo3.1 - Fast and Local Computer Use Agents 2026-06-08화면을 보고 클릭하는 컴퓨터 유즈 에이전트를 클라우드가 아니라 내 기기에서 돌린다. H Company가 Holo3.1을 0.8B부터 35B-A3B까지 확장하고, FP8·NVFP4·Q4 GGUF 양자화 체크포인트로 온디바이스 GUI 자동화를 처음 본격 출하했다.
-
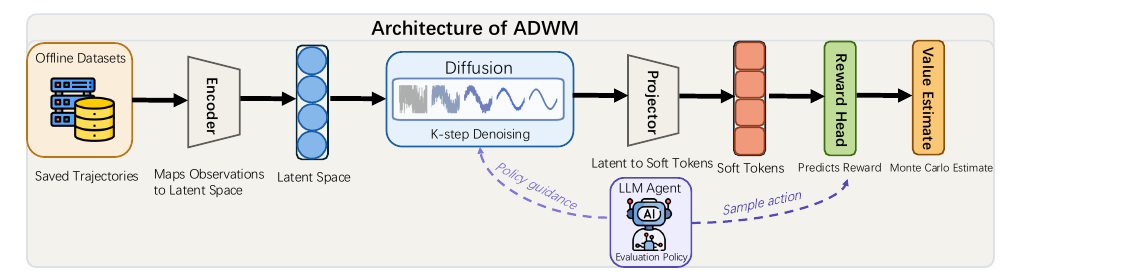
새 LLM 에이전트를 실제 환경에 굴려보지 않고 과거 로그만으로 성능을 가늠하는 오프폴리시 평가 프레임워크 ADWM을 에모리대와 상하이교통대 연구진이 내놨습니다. 핵심은 월드 모델 자체를 디퓨전 과정으로 세우고, 정책 유도 궤적 법칙을 단일 스텝 조건부로 정확히 분해해 평가 정책이 매 디노이징 스텝을 조종하게 한 것. 네 개 멀티턴 벤치마크에서 ADWM만 모든 셀에서 양의 순위 상관을 냈습니다.
-
 The Deterministic Horizon - When Extended Reasoning Fails and Tool Delegation Becomes Necessary 2026-06-07
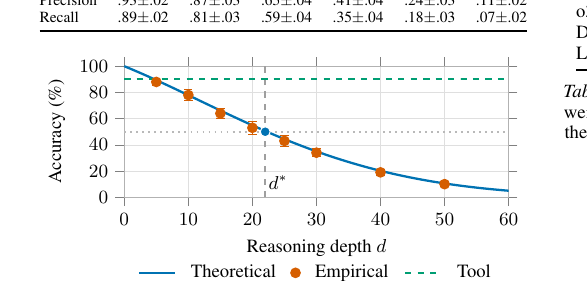
The Deterministic Horizon - When Extended Reasoning Fails and Tool Delegation Becomes Necessary 2026-06-07긴 chain-of-thought가 어느 지점부터 오히려 정확도를 무너뜨리는지를 디코더 어텐션의 정보이론적 용량 한계로 증명한 ICML 2026 논문. 19~31스텝의 Deterministic Horizon을 넘으면 신경 추론 대신 도구에 위임하라는 결론을 뜯어봅니다.
-
저장 메모리 목록을 비동기 백그라운드 합성으로 대체한 OpenAI의 새 ChatGPT 메모리 아키텍처 Dreaming V3를 뜯어봅니다
-
짐 판 2026-06-06
NVIDIA AI 디렉터이자 Distinguished Scientist. GEAR Lab 공동 리더이자 휴머노이드 프로젝트 GR00T의 공동 책임자로 Physical AI를 연구합니다.
-
 MetaForge - A Self-Evolving Multimodal Agent that Retrieves, Adapts, and Forges Tools On Demand 2026-06-04
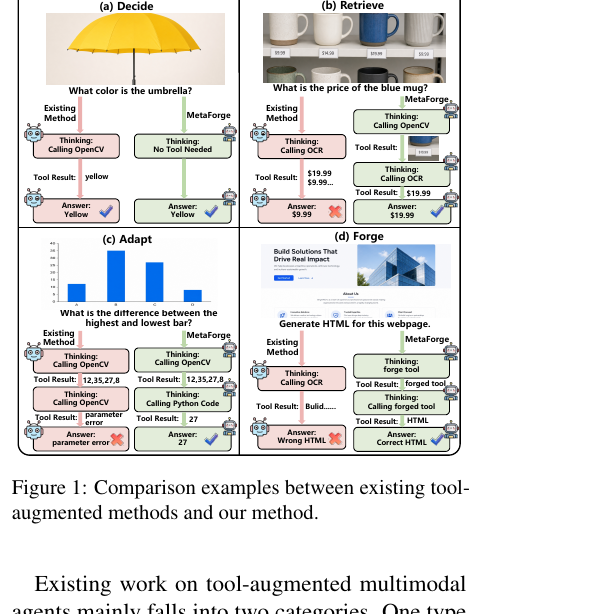
MetaForge - A Self-Evolving Multimodal Agent that Retrieves, Adapts, and Forges Tools On Demand 2026-06-04멀티모달 에이전트는 도구를 써서 복잡한 추론을 풀지만, 미리 정해진 도구 목록은 처음 보는 상황에 일반화되지 못하고 도구를 마구 부르면 비용과 오류만 늘어납니다. MetaForge는 에이전트의 행동을 Decide, Retrieve, Adapt, Forge 네 단계로 나누고, 도구를 언제 쓸지와 도구를 어떻게 늘릴지를 강화학습으로 함께 배우게 합니다.
-
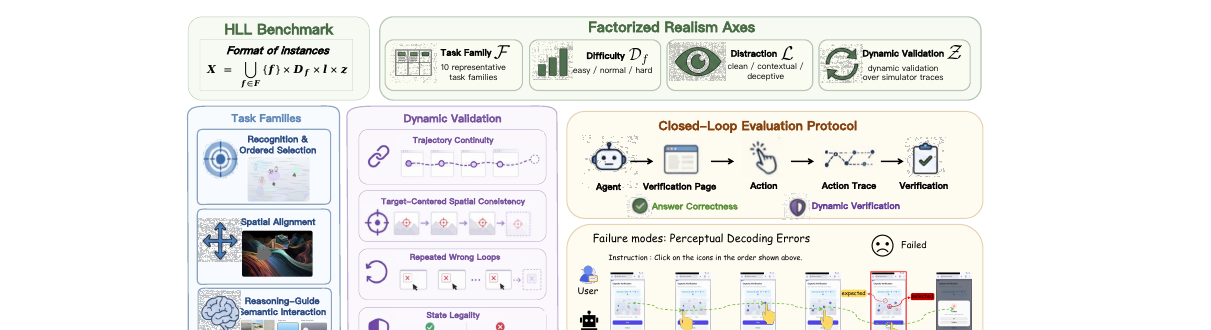
멀티모달 에이전트가 사람을 대신해 인터페이스를 조작하는 시대에, CAPTCHA는 봇과 사람을 가르는 마지막 검증 관문입니다. HLL은 이 관문을 에이전트가 넘을 수 있는지 정답 인식이 아니라 실제 상호작용으로 측정하는 벤치마크입니다. 8개 프런티어 에이전트는 깨끗한 화면에서는 곧잘 풀지만, 현실적인 방해와 행동 궤적 검증이 들어오면 무너집니다.
-
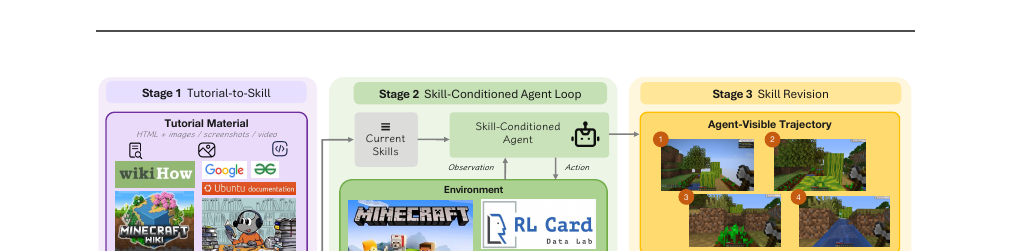
인터넷에는 사람을 위한 방법 안내가 넘쳐납니다. 위키하우, 게임 위키, 우분투 문서 같은 것들이죠. 문제는 이 가이드가 멀티모달이고 노이즈가 많고 사람이 실행한다고 가정한다는 점입니다. MMG2Skill은 이런 사람용 가이드를 에이전트가 실행할 수 있는 SKILL.md 절차로 증류하고, 실행 궤적의 진단으로 스스로 고쳐 나가는 폐루프 프레임워크입니다.
-
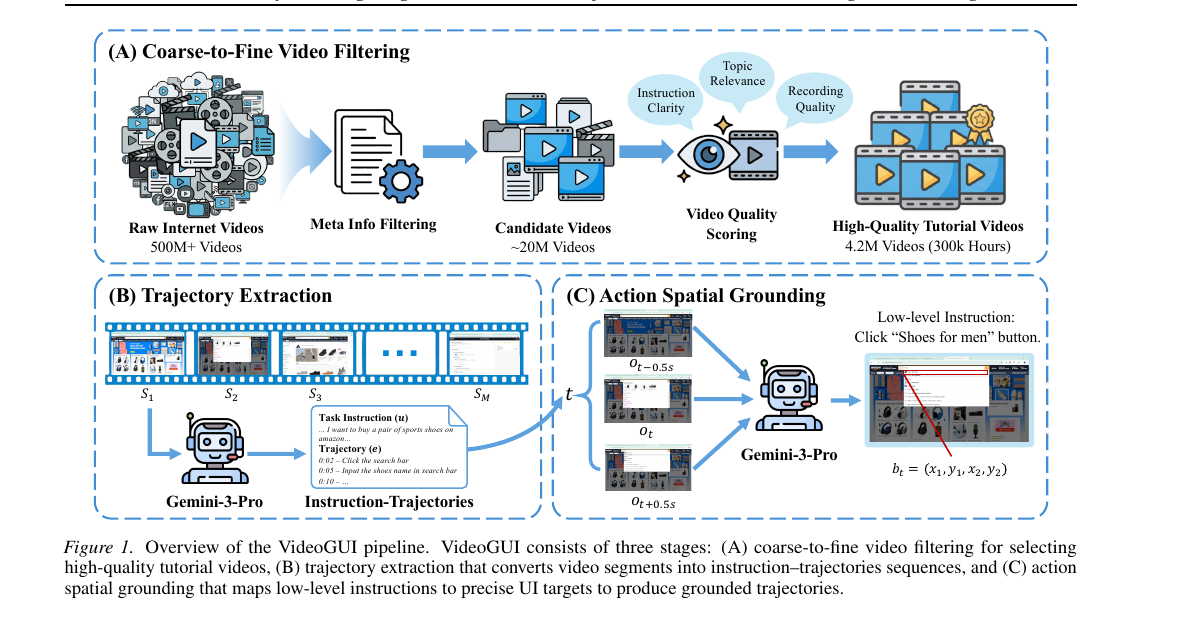 Video2GUI - Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining 2026-05-22
Video2GUI - Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining 2026-05-22라벨 없는 유튜브 비디오 5억 개에서 GUI 인터랙션 트래젝토리 1,200만 개를 자동 추출해 만든 WildGUI 데이터셋과 그 추출 파이프라인 Video2GUI. Qwen2.5-VL·MiMo-VL를 사전학습하면 ScreenSpot-Pro·OSWorld-G에서 15~20점 상승, 온라인 OSWorld·AndroidWorld까지 일관된 개선이 나타납니다.
-
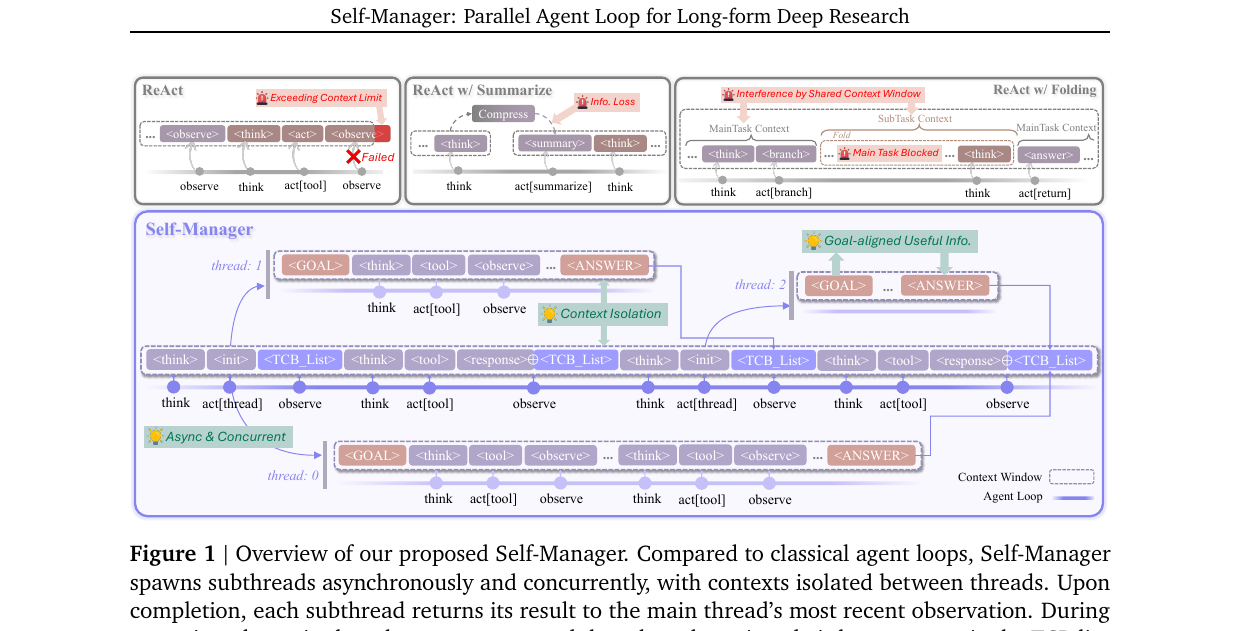
단일 에이전트 루프를 운영체제의 스레드 구조로 일반화하면, 비동기·병렬·격리 컨텍스트를 얻을 수 있다는 단순하고 강한 제안. ReAct 위에 Thread Control Block을 끼워 넣어, 본 스레드가 서브스레드들을 직접 관리합니다. DeepResearch Bench에서 단일 에이전트 베이스라인을 일관되게 앞서고, OS의 스레드 추상을 LLM 에이전트로 끌어온 첫 정식 정리에 가깝습니다.
-
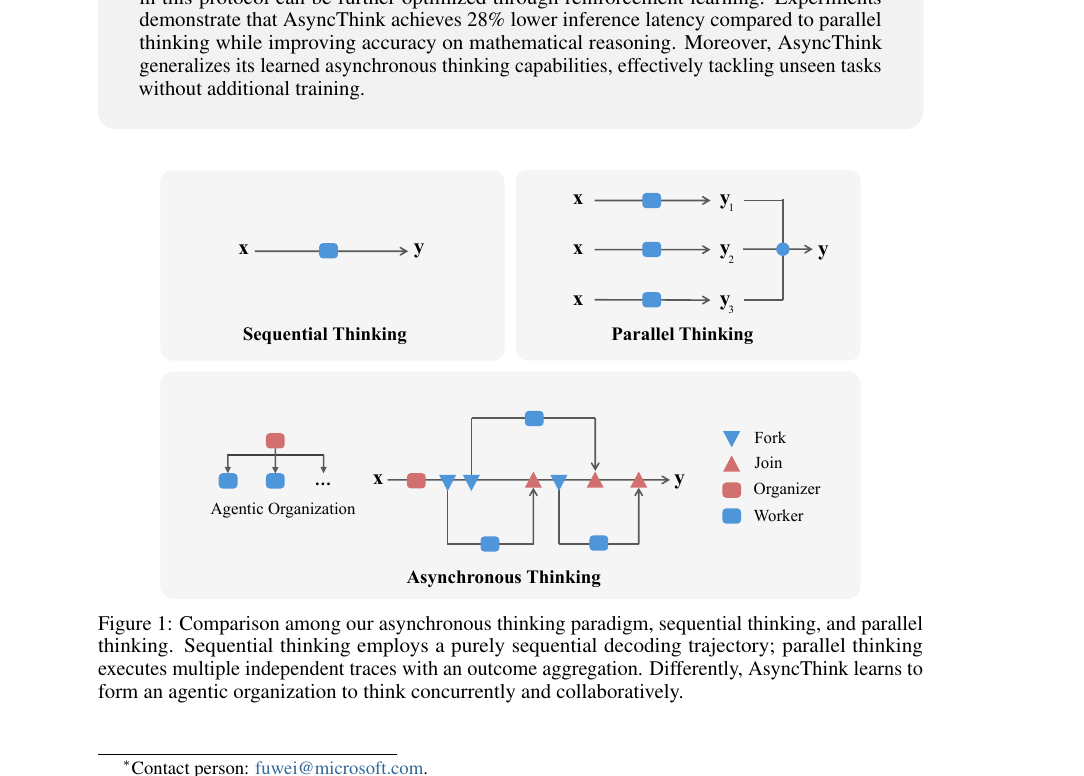
LLM의 사고 과정을 organizer와 worker 두 역할로 분리하고 Fork-Join 액션으로 비동기 사고를 학습시키는 새로운 추론 패러다임. 단일 모델이 두 역할을 모두 수행하며, RL로 사고 구조 자체를 최적화합니다. 병렬 사고 대비 추론 지연 28% 감소에 수학 추론 정확도 동시 개선, 미학습 태스크로도 비동기 사고가 zero-shot 일반화됩니다. agentic organization 시대를 선언하는 Microsoft Research의 첫 정식 정리입니다.
-
Composer 2.5 2026-05-19
Cursor가 공개한 코딩 에이전트 모델 Composer 2.5의 학습 방법과 벤치마크를 정리합니다
-
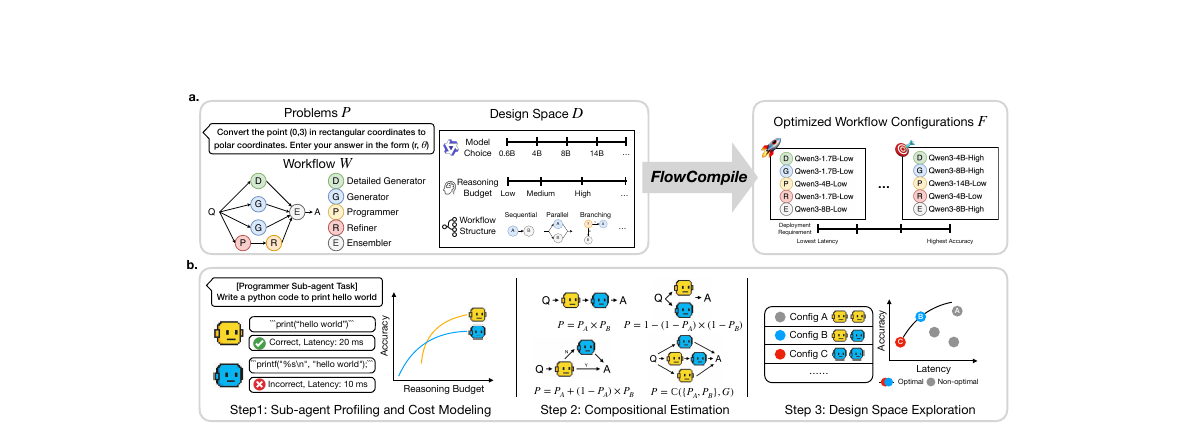
사전 정의된 워크플로 그래프 위에서 sub-agent의 모델·reasoning budget·구조 선택을 컴파일 타임에 한 번에 탐색해 정확도-지연 trade-off 집합을 만들어내는 컴파일러입니다. DSPy가 프롬프트 자동화였다면, FlowCompile은 그래프 자체의 자동화로 한 칸 더 나아간 시도입니다.
-
Cactus Needle 2026-05-15
|-
-

UCLA 팀이 ICLR 2025의 LongMemEval을 웹 에이전트 trajectory 환경으로 확장한 후속 벤치마크입니다. 451개 수작업 문항으로 static state recall·dynamic state tracking·workflow knowledge·environment gotchas·premise awareness 다섯 메모리 능력을 측정하며, 채팅 히스토리에서 ServiceNow·WebArena의 실제 에이전트 행적으로 옮겨가 25M~115M 토큰 규모의 haystack을 다룹니다.
-
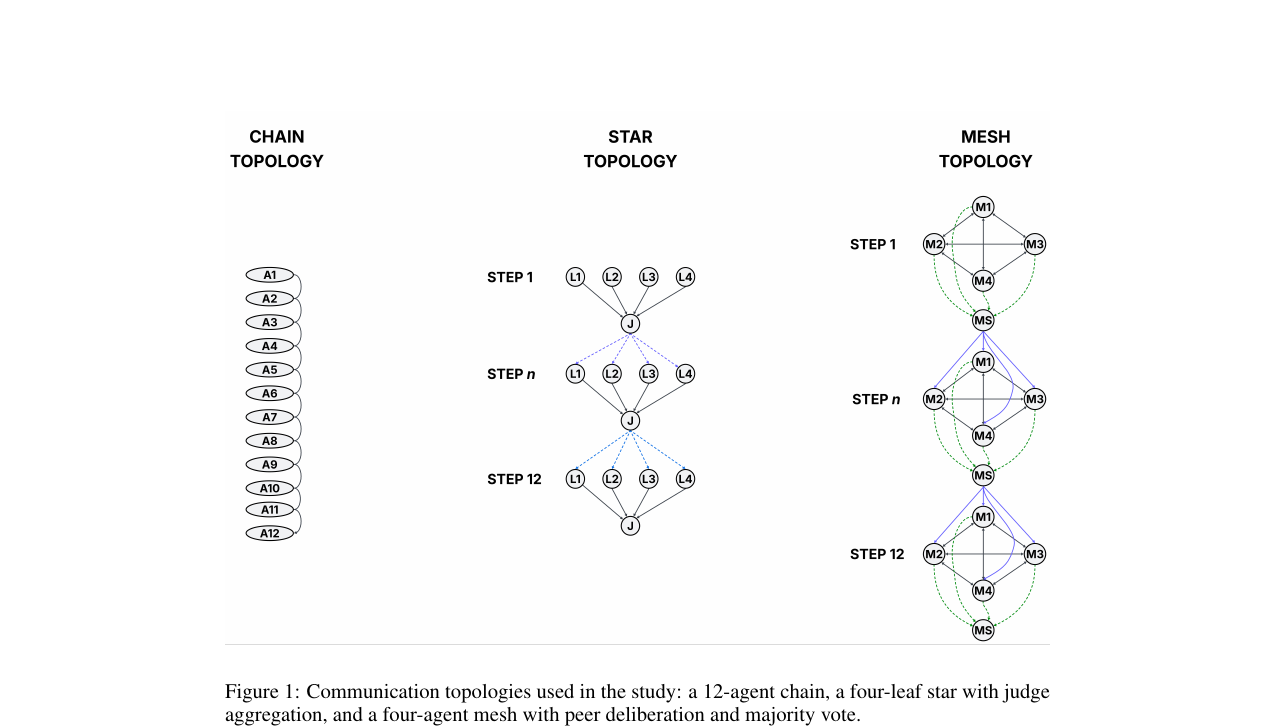
멀티에이전트 LLM 시스템의 chain·star·mesh 토폴로지를 추론을 돌리기 전에 단 세 개의 고윳값으로 진단하자는 제안. successor representation을 통신 그래프에 얹어 drift·consensus·robustness를 closed-form으로 풉니다.
-
Pappers MCP - 클로드의 법률 대리 시나리오 2026-05-14
Pappers MCP를 통해 클로드가 프랑스 상법 사건 페이지 분석 그리드를 그대로 출력하는 시연. 회사 데이터와 판례를 동시에 조회해, pin-cite·gap 분석·결정트리까지 변호사가 받아 쓸 수 있는 출력을 만듭니다. 자체 플러그인이 아닌 오픈 MCP 서버로 법률 버티컬을 묶은 사례입니다.
-
AI 팀이 30일 안에 망하는 이유 2026-05-08
AI 에이전트 팀의 90%가 한 달 안에 무너집니다. 에이전트가 멍청해서가 아닙니다. 아무도 안 보고 있어서입니다. 살아남는 AI 팀의 세 가지 원칙과 실제 역할 구성을 정리했습니다.
-
AI 에이전트의 기억 상실을 고치는 오픈소스 Beads 2026-05-07
GitHub 22.6k 스타의 Beads는 AI 에이전트 기억 문제를 Git 같은 SQL로 해결하겠다고 합니다. 아이디어는 맞는데, 실제로는 어떨까요. Dolt 마이그레이션이 망가뜨린 것들, '의미 기억 감쇠'의 진짜 정체, Mem0와의 비교까지 정리합니다.
-
직원 3명 대신 AI 에이전트 3개 — 소규모 창업자를 위한 현실적 가이드 2026-05-07
혼자 모든 걸 하는 창업자에게 AI 에이전트 3개가 실제로 도움이 될 수 있을까요. 리서치 에이전트, 콘텐츠 에이전트, 운영 에이전트 — 무엇이 가능하고 무엇이 과장인지 구체적으로 살펴봅니다.
-
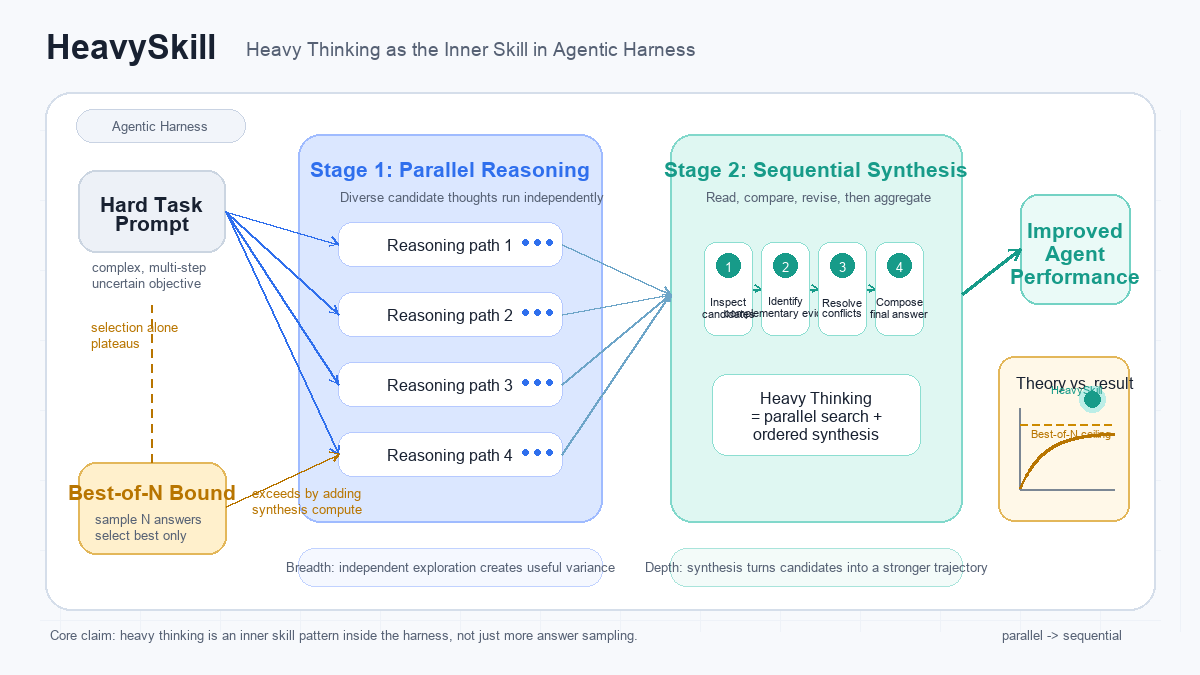
복잡한 에이전틱 하네스의 성능을 실제로 끌어올리는 건 뭘까요? 이 논문은 답이 '병렬 추론 + 순차적 종합'이라는 두 단계 패턴에 있다고 봅니다. Best-of-N의 이론적 상한을 넘는 Heavy Thinking의 구조와 실험 결과를 정리합니다.
-
MCP 2026-05-07
AI 에이전트가 외부 도구·데이터 소스와 상호작용하는 표준 인터페이스. Anthropic이 2024년 제안해 주요 에이전트 플랫폼과 에디터가 채택 중입니다.
-
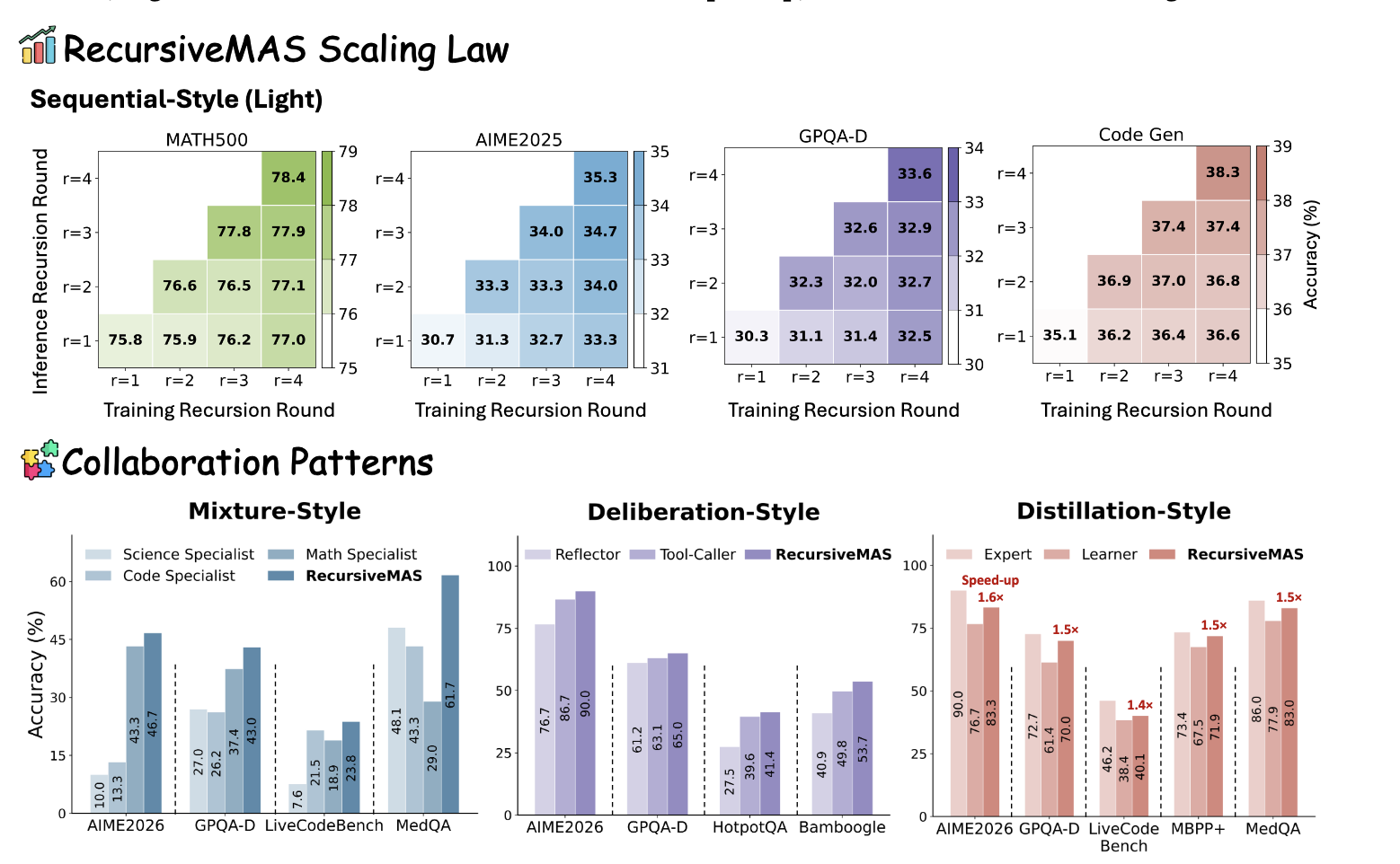 Recursive Multi-Agent Systems 2026-04-30
Recursive Multi-Agent Systems 2026-04-30AI 에이전트 하나가 작업을 받습니다. 그 에이전트가 작업을 쪼갭니다. 쪼개진 작업들을 새로운 에이전트들에게 넘깁니다. 그 에이전트들도 또 쪼갭니다. AI가 AI를 낳는다. 재귀적 멀티에이전트 시스템이 무엇이고, AI의 불편한 미래는 어디로 향하는지 정리합니다.
-
오픈클로 AI 비서 만들기 - 블로그 2026-04-30
오픈클로 사태가 주는 교훈. Claude Code + 스킬로 외부 프레임워크 없이 나만의 AI 비서를 구축하는 실전 가이드.
-
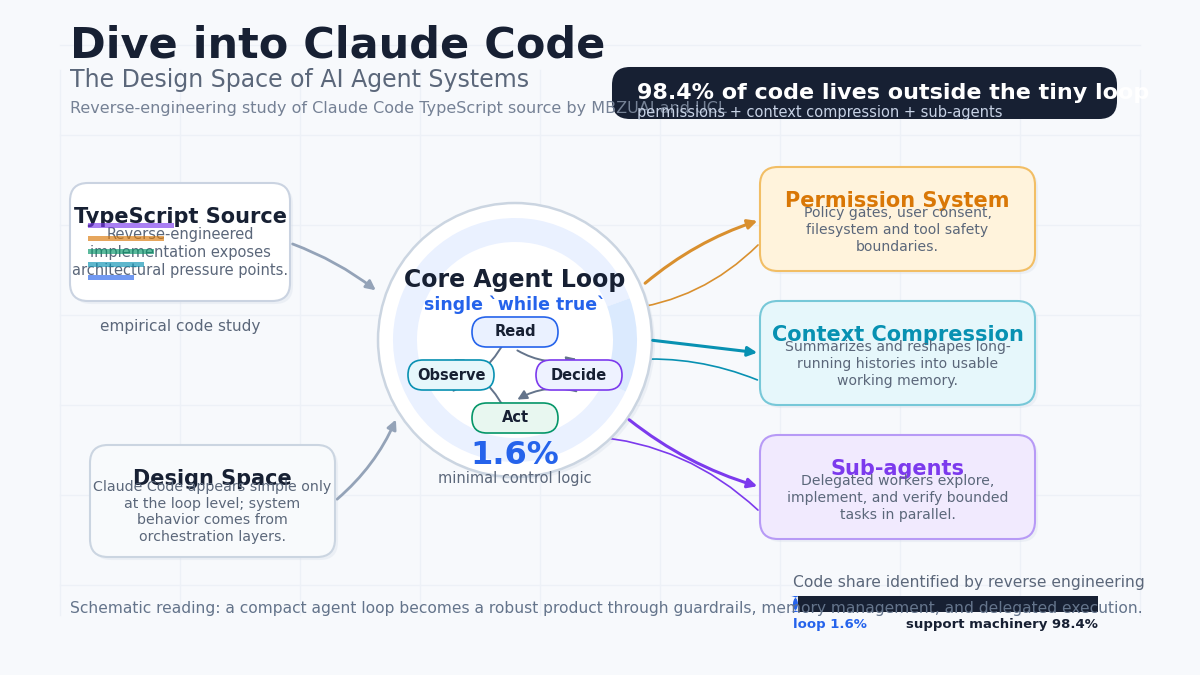
Claude Code의 TypeScript 소스를 직접 뜯어본 MBZUAI·UCL 연구. 핵심 루프는 while-true 한 덩이지만, 권한 시스템·컨텍스트 압축·서브에이전트가 코드의 98.4%를 차지합니다.
-
GPT-5.4 분석 2026-04-23
GPT-5.4가 처음으로 컴퓨터 사용 능력을 네이티브로 탑재했습니다. OSWorld에서 인간 전문가를 앞질렀고, 1M 토큰 컨텍스트도 공식 지원합니다. 에이전트 시대가 OpenAI 입장에서는 시작됐습니다.
-
Claude의 지능을 제대로 쓰는 법 2026-04-13
앤트로픽이 알려주는 클로드 에이전트 3원칙. 클로드가 이미 아는 것을 활용하고, 불필요한 구조를 제거하고, 경계를 신중하게 설정하는 방법이 중요합니다. 클로드를 너무 자유롭게 풀어두거나, 반대로 너무 많은 것을 제약하면 곤란합니다. 대체 적절한 선은 어디일까요?
-
Hermes Agent 2026-04-11
Nous Research의 Hermes Agent — 스스로 배우고 성장하는 오픈소스 AI 에이전트. 5단계 메모리, 자동 스킬 생성, 6개 실행 백엔드, 40+ 도구를 갖춘 로컬 퍼스트 에이전트 프레임워크.
-
 Advisor Strategy 2026-04-09
Advisor Strategy 2026-04-09Anthropic의 Advisor Strategy — 큰 모델이 작은 모델에게 조언만 하고 실행은 맡기는 새로운 에이전트 아키텍처. Sonnet + Opus 조합으로 비용은 줄이고 성능은 올리는 방법.
-
 7장 - 에이전트 LLM 2026-04-07
7장 - 에이전트 LLM 2026-04-07 -
8장 - 에이전트, 프롬프트, RAG 2026-04-06
Stanford CS230 딥러닝 강의 Lecture 8. 프롬프트 엔지니어링, RAG, 에이전트 워크플로우, 멀티 에이전트 시스템을 다루는 실전 강의.
-
에이전틱 AI, 도구에서 동료로 - 2026년 4월 기업 AI 현황 2026-04-05
마이크로소프트는 1,500만 Copilot 좌석을 팔았다. 그런데 기업 환경은 아직 에이전틱 AI를 받아들일 준비가 안 됐다고 한다. 둘 다 맞는 말이다. 이 역설의 정체가 2026년 에이전트 AI 시장의 실체다.
-
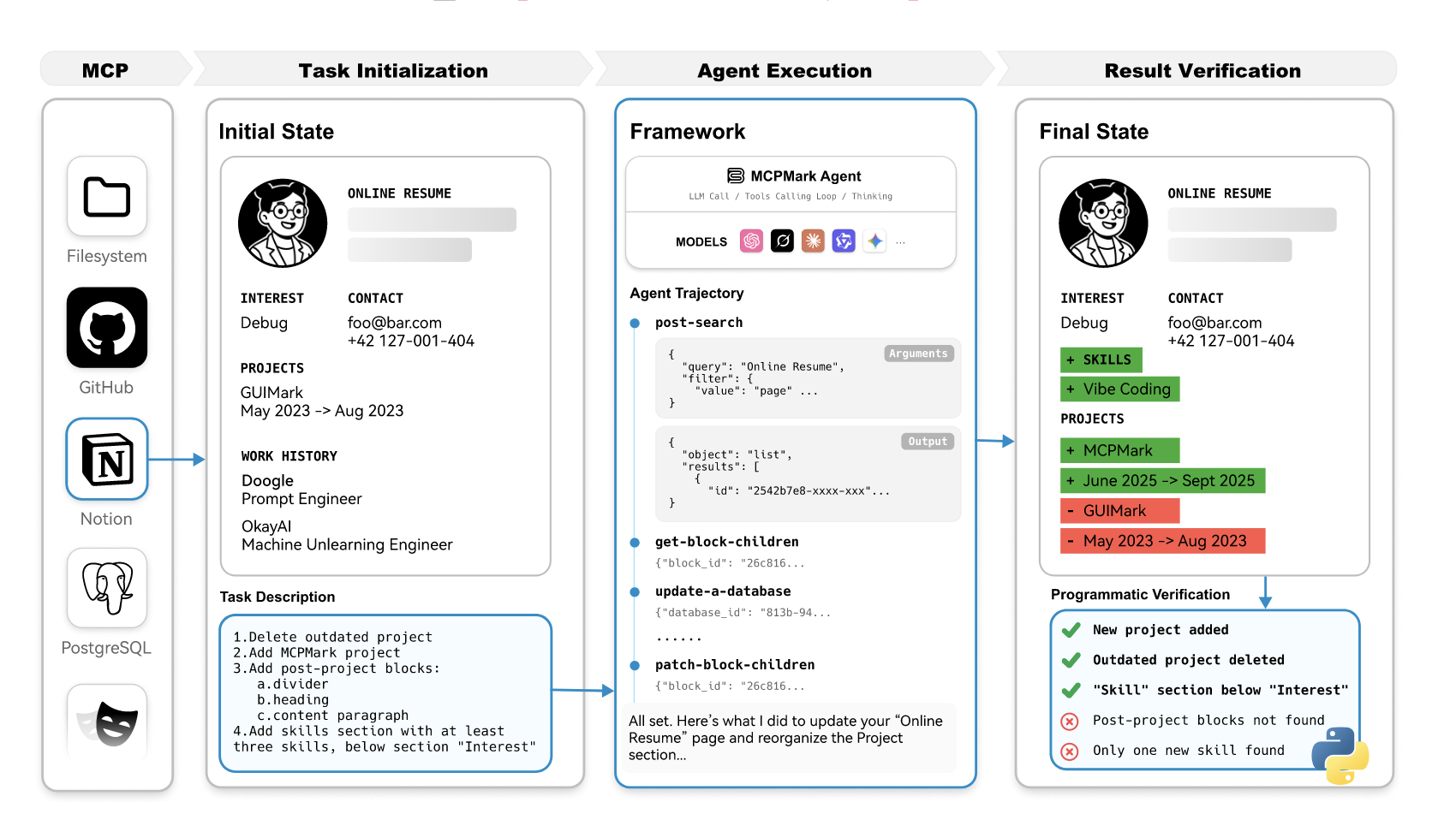
여러분은 MCP를 자주 활용하나요? 저는 매일 사용해서 없으면 안 될 수준입니다. 가끔은 내가 필요한 MCP를 직접 만들고 싶은 때도 있죠. 그렇다면 실제로 MCP가 얼마나 유용한지, 어떤 MCP 서버가 좋은 MCP 서버인지 구별하려면 어떤 기준을 세우면 좋을까요? 이번 논문은 MCP가 실제 업무의 복잡성을 평가하는 벤치마크를 제안하고 MCP 활용 능력을 종합적으로 평가합니다.
-
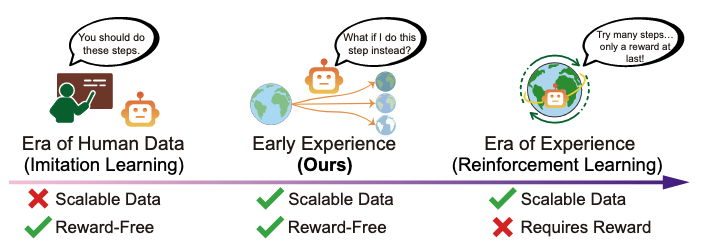 Agent Learning via Early Experience 2025-10-12
Agent Learning via Early Experience 2025-10-12스스로 학습하고 발전하는 인공지능을 위한 새로운 학습 패러다임, 초기 경험(Early Experience)을 제안합니다. 보상 신호 없이도 에이전트가 자신의 행동으로 생성된 미래 상태를 학습 신호로 활용할 수 있습니다. 이제 인공지능이 정답만 보고 배우는 게 아니라 직접 시도한 경험으로 학습한다는 겁니다.
-
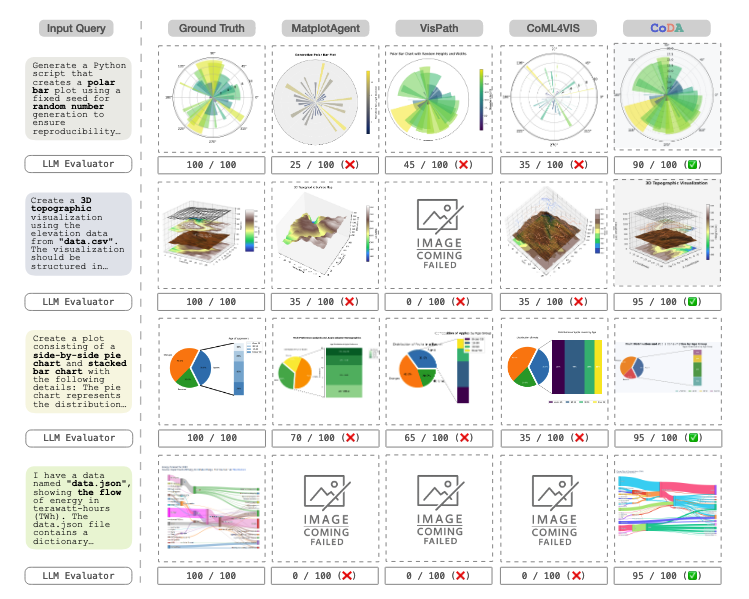
저는 예전부터 데이터 시각화가 어려웠습니다. 함수 이름이랑 파라미터도 잘 안 외워지고 어떤 그래프가 가장 효과적인가 판단하는 것이 쉽지 않습니다. 구글에서 시각화 시스템을 제안한 논문을 발표한 것은 굉장히 재밌습니다. 아마 Opal과 관련이 있지 않을까요?
-
청화대학교 자동화학과 박사과정. 에이전틱 RL과 LLM 에이전트 훈련을 연구하며 SPARK, SDAR, OPID 등을 발표한 연구자.
-

UC 버클리 CS 교수. AI 보안·에이전트 분야 선구자. MacArthur Fellowship 수상자.
-
CUHK Shenzhen 연구조교·Qiyuan.Tech CTO. LLM 에이전트와 의료 AI를 넘나드는 오픈소스 기여자.
-
UC 버클리 박사과정 연구자. OOD 탐지·LLM 추론·에이전트 신뢰성 연구. ALE 제1저자.
-
JavaScript·TypeScript용 오픈소스 AI 에이전트 프레임워크. 워크플로·메모리·RAG·도구 호출을 묶어 에이전트를 만든다. 2026년 6월 npm 공급망 공격 표적
-
Hermes 모델/에이전트 오픈소스 AI 팀, agentskills.io 표준
-
파리에 본사를 둔 AI 에이전트 스타트업. Runner H와 Holo 컴퓨터 유즈 VLM 라인업을 만든다
-
BIGAI(베이징범용인공지능연구원) 연구원. Embodied AI·3D 장면 이해·VLA 모델 전공. ACE-Ego-0 프로젝트 리더.
-
Anthropic의 공식 에이전트 SDK, Python·TypeScript로 Claude 기반 자동화·에이전트를 만들 때 쓰는 라이브러리
-
칭화대 College of AI 박사과정 연구자(ZenoMind AI 겸). 대규모 추론 모델, AI 에이전트, 통합 모델을 연구하며 특히 멀티모달 공간 과제에 집중. Spider2-V 공저자.
-
KAIST 박사과정 연구원. NVIDIA와의 공동 연구를 통해 VLM 기반 공간 추론 에이전트 SpatialClaw를 제안한 제1저자.
-
베이징대학교(PKU) 박사과정 NLP 연구자로 GUI 에이전트 데이터셋·트래젝토리 합성에 집중하며, Xiaomi LLM-Core 인턴 기간에 Video2GUI 1저자를 맡았다
-
UIUC 교수, ConvAI Lab 공동창립자. 대화 AI·음성 NLP·LLM 에이전트 전공. Amazon Alexa·Google·Microsoft Research 출신.
-
칭화대 AIR 교수 겸 부원장. 모바일·에지 컴퓨팅 전문. IEEE Fellow. 전 Microsoft Research Asia 수석 연구원.
-
Xiaomi LLM-Core 팀의 시니어 멤버로, MiMo 시리즈(MiMo-7B, MiMo-VL, MiMo-V2-Flash)의 핵심 기여자이자 학계와의 협업을 이끄는 코레스폰딩 저자
-
Google DeepMind 프론티어 전략 및 거버넌스 시니어 디렉터. Cooperative AI Foundation 창립자. AI 거버넌스 분야 선구자.
-
CUHK CSE 박사과정. LLM, 멀티모달 AI, 에이전트 시스템 전공. Orchestra-o1 공동 1저자.
-
도쿄에 본사를 둔 일본 AI 기업, 진화·집단지능 기반 AI 연구로 알려짐
-
Microsoft Research Scientist. 코딩 에이전트의 레포지토리 탐색 효율화 연구를 이끄는 FastContext 공동 제1저자.
-
H Company의 모델링 총괄. Holo 컴퓨터 유즈 VLM 라인업을 이끄는 연구자
-
Princeton 전기컴퓨터공학과 교수, 강화학습 이론과 LLM 에이전트 학습 연구
-
칭화대 AIR 원장·AI과학 석좌교수. 전 바이두 사장, 전 Microsoft Research Asia 초대 원장. 중국공정원 원사.
-
UIUC CS 박사과정. 과학 논문 피겨 자동 생성 연구. Crafter 제1저자.
-
화둥사범대 소속 연구자. MetaForge 자가진화 멀티모달 에이전트의 교신저자
-
Microsoft Research 교신 저자. LLM 기반 소프트웨어 엔지니어링 에이전트 연구 그룹 리더.
-
UIUC CS 조교수. LLM 추론, 코드 에이전트, 대규모 훈련 효율화 연구. Crafter 교신저자.
-
Microsoft Research GenAI 그룹 연구원. BIT 박사(2024) 후 정규 합류, 다국어 인코더와 멀티모달에서 agentic LLM으로 라인을 옮겨 Era of Agentic Organization 1저자
-
청화대학교 자동화학과 정교수. 음성 합성·인식·감정 처리 및 에이전틱 AI 분야를 연구하는 시니어 연구자.
-
실제 안드로이드 환경에서 모바일 에이전트를 평가하는 동적 벤치마크. 시스템 상태를 직접 검사해 보상을 준다
-
Frontis.AI / Horizon Research 교신저자. 에이전트 평가 벤치마크 파이프라인 구축 연구 주도
-
AI 연구자. 전 Salesforce AI Research SVP, 현 Recursive Superintelligence 공동창업자.
-
Princeton 전기컴퓨터공학과 박사후연구원, Gen-Verse 리더, 확산 모델과 에이전트 RL 연구
-
상하이교통대학(SJTU) 연구원, Microsoft CoreAI 프로젝트 참여. FastContext 공동 제1저자.
-
Anthropic의 공식 터미널·IDE 기반 코딩 에이전트, Claude 모델을 셸과 코드 컨텍스트에 연결하는 CLI
-
NUS PhD 연구원. LLM 추론 및 에이전트 벤치마크 전문. EvoArena, LogicReward 저자.
-
MBZUAI 머신러닝학과 조교수, VILA Lab 공동 운영. 효율적 딥러닝, 지식 증류, 에이전트 시스템 설계 연구
-
지린대학교 인공지능대학 소속, GateMem 1저자. LLM 에이전트 메모리 거버넌스 연구
-
UC Merced 조교수, UC Merced NLP Lab 디렉터. 신뢰성 있는 LLM 제어와 멀티모달 추론을 다루며 Self-Manager의 시니어 저자
-
칭화대 AIR 조교수. 모바일 에이전트·DroidBot·AutoDroid 개발. 모바일 인텔리전스 전문.
-
상하이교통대 소속 연구자. HLL CAPTCHA 에이전트 벤치마크의 1저자
-
Anthropic의 팀 협업·자동화 워크스페이스, Claude 모델을 위키·문서·플러그인 워크플로우와 묶는 진입점
-
여러 프런티어 모델을 동적으로 지휘하는 Sakana AI의 멀티에이전트 오케스트레이션 시스템
-
NUS/MIT 연구원. LLM 대화 시스템·다중 에이전트 인지 연구. EvoArena 공저자.
-
난징대·콰이쇼우 소속 연구자. MMG2Skill guide-to-skill 학습의 공동 1저자