EnterpriseClawBench - Benchmarking Agents from Real Workplace Sessions
J. Zhong, W. Wang, C. Jiang, K. Tian, Z. Yuan, J. Yang, D. Lei, and K. Zhang, "EnterpriseClawBench: Benchmarking Agents from Real Workplace Sessions," arXiv:2606.23654, 2026.
저자
Kaiyan Zhang이 교신저자로 주도한 Frontis.AI(Horizon Research) 팀의 작업입니다. Jincheng Zhong, Weizhi Wang, Che Jiang이 코어 컨트리뷰터로 벤치마크 구축과 실험을 담당했습니다. 이 팀은 Frontis.AI라는 AI 스타트업 내부에서 실제 에이전트를 운영하면서 발생한 세션 로그를 연구 자원으로 전환한 특이한 위치에 있습니다. 사용자가 직접 에이전트를 운영하기 때문에 "기업 에이전트 평가가 어려운 이유"를 가장 가까이서 봐온 팀이라고 할 수 있습니다.
배경
에이전트 평가 연구는 Workspace-Bench, WildClawBench, ClawBench, Claw-SWE-Bench 등으로 빠르게 축적됐습니다. 하지만 저자들은 세 가지 구조적 간격이 여전히 메워지지 않았다고 주장합니다.
Gap 1 — 기업 현실성과 확장 가능한 태스크 구축의 갈등. 기존 Workspace-Bench, WorkArena, TheAgentCompany, EntWorld의 태스크 다수는 여전히 인간이 직접 제작했거나 공개 환경에서 시뮬레이션했습니다. 자연 발생한 기업 수요와의 간격이 있습니다.
Gap 2 — 다차원 평가 부재. 에이전트 성능은 모델만으로 설명되지 않습니다. WildClawBench는 하네스 효과를, Claw-SWE-Bench는 환경·상태 기반 실행을, AgenticVBench는 멀티모달 산출을 각자 다룹니다. 하네스-모델 조합, 아티팩트 품질, 비용, 런타임을 함께 보고하는 프레임워크가 없었습니다.
Gap 3 — 태스크 클래스 수준의 스킬 평가 부재. 재사용 가능한 스킬은 기업 에이전트 시스템에서 운영 자산이 되고 있지만, 기존 벤치마크는 스킬을 개별 태스크 단위로 평가하거나 아예 설계하지 않았습니다. 같은 클래스에서 학습한 스킬이 보류된 태스크로 전이되는지 측정하는 프레임워크가 필요합니다.
어떻게 만들었나
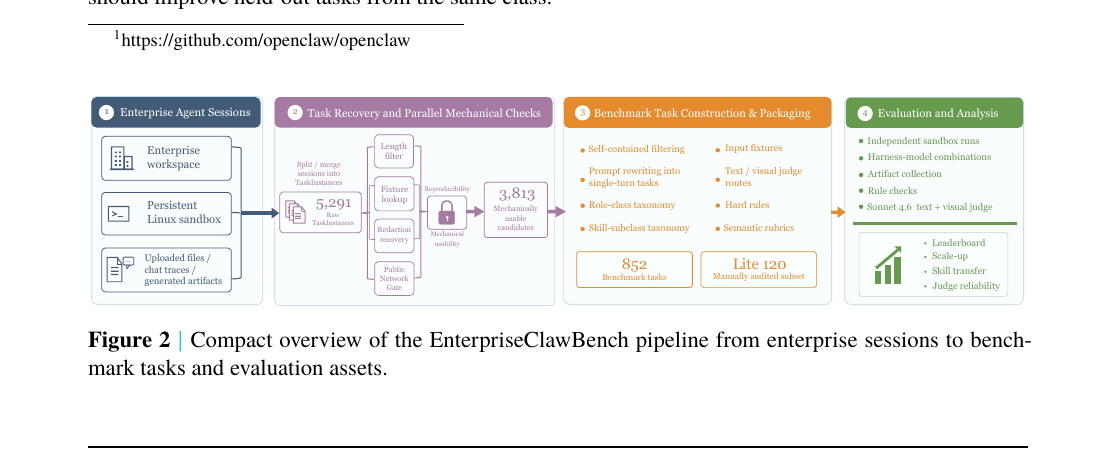
EnterpriseClawBench는 2026년 3월부터 5월까지 100명 이상 직원을 보유한 한 AI 스타트업의 기업 에이전트 시스템에서 수집한 세션 로그를 원자재로 씁니다. 직원들은 협업 플랫폼의 개인/그룹 채팅을 통해 에이전트와 상호작용하고, 파일을 업로드하며, 영구 Linux 워크스페이스에서 결과물을 기대합니다.
구축 파이프라인은 4단계로 원자재를 재현 가능한 벤치마크 태스크로 변환합니다.
- Enterprise Agent Sessions: 기업 워크스페이스, 영구 Linux 샌드박스, 업로드 파일/생성 아티팩트에서 원시 세션 수집 → 5,291 raw TaskInstances
- Task Recovery & Parallel Mechanical Checks: 길이 필터(5,181 통과), 픽스처 검색(4,896), 편집 복원(4,286), 공개 네트워크 게이트(5,003) 4개 체크를 병렬 실행 → 3,813 기계적 합격
- Benchmark Task Construction & Packaging: 자기 포함성 검토, 단일 턴 프롬프트 재작성, 역할 클래스 분류, 스킬 서브클래스 분류, 하드 룰 및 시맨틱 루브릭 생성, 샌드박스 프리플라이트 → 852 벤치마크 태스크
- Evaluation & Analysis: 독립 샌드박스 실행, 하네스-모델 조합 테스트, 아티팩트 수집, 룰 체크, Sonnet 4.6 텍스트+비주얼 judge → 리더보드·스케일업·스킬 전이·judge 신뢰도 분석
최종 852개 태스크 중 120개는 수동 감사를 거친 Lite 서브셋으로 메인 리더보드에 사용됩니다. 벤치마크 데이터는 내부 세션과 기업 기밀을 포함하므로 공개하지 않습니다. 재사용 가능한 기여는 구축·평가 프로토콜입니다.
무엇으로 구성돼 있나
852개 태스크는 7개 역할 클래스로 구분됩니다.
역할 |
태스크 수 |
|---|---|
Product/project |
220 (26%) |
Engineering/IT |
174 (20%) |
HR/admin |
102 (12%) |
Executive |
89 (10%) |
Sales/customer |
88 (10%) |
Marketing |
77 (9%) |
Finance/ops |
64 (8%) |
7개 역할 클래스는 45개 역할별 스킬 서브클래스로 확장되어 태스크 클래스 수준 스킬 평가를 가능하게 합니다. 입력 픽스처는 719개이며 MD(29%), DOC(18%), Image(16%)가 주류입니다. 기대 산출물은 887개 요건으로 MD(39%), TXT(32%), HTML(9%)입니다.
평가는 두 층으로 구성됩니다. 하드 룰이 파일 타입, 파일 개수, 비어 있지 않음, 열람 가능성, 미교체 플레이스홀더를 체크합니다. 시맨틱 judge는 5개 차원을 채점합니다.
차원 |
무엇을 보나 |
|---|---|
Accuracy |
사실 정확성, 근거 기반 출력 |
Relevance |
태스크 관련성 |
Depth |
실질적 깊이 |
Utility |
실용적 사용 가능성 |
Quality |
커뮤니케이션 품질 |
텍스트 추출 가능 산출물은 텍스트 judge, HTML·슬라이드·PDF·스프레드시트·이미지는 스크린샷 렌더링 후 비주얼 judge로 라우팅됩니다.
결과
메인 리더보드 (Lite 120)
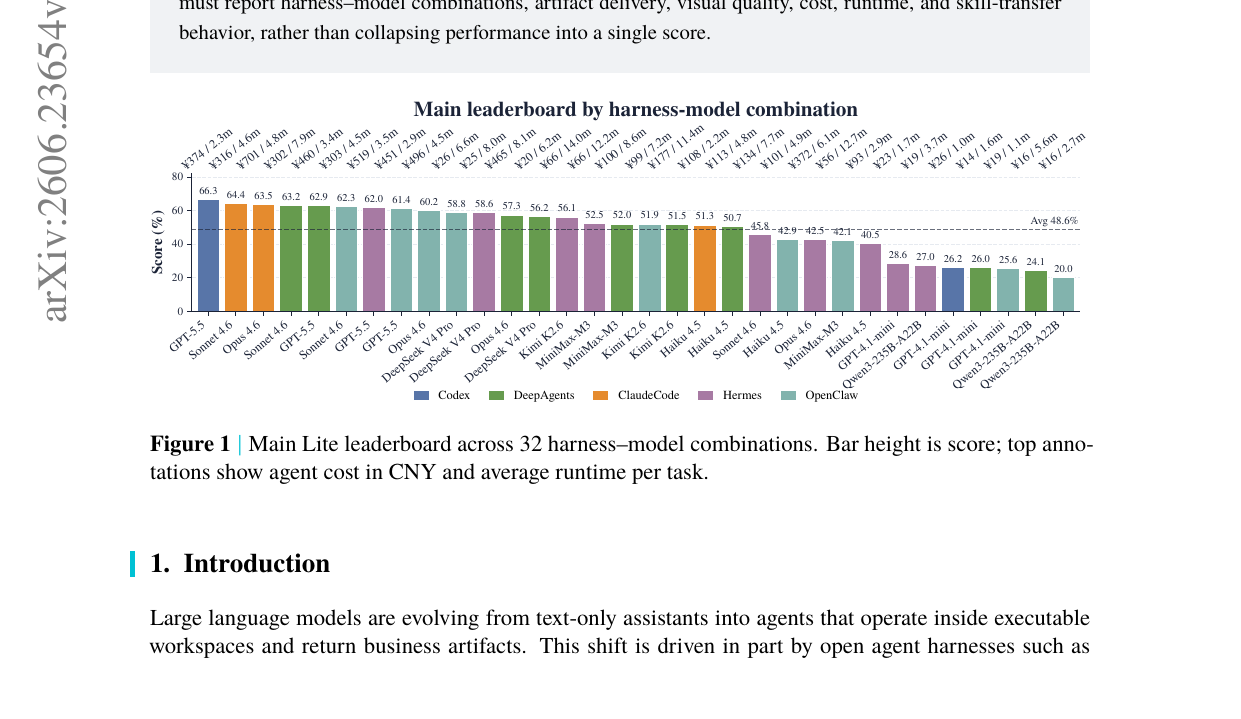
32개 하네스-모델 조합을 평가한 결과, 최고 점수는 Codex/GPT-5.5의 0.663입니다. 전체 평균 48.6%이며 어느 조합도 포화에 근접하지 않습니다. 강모델(GPT-5.5, Sonnet 4.6, Kimi K2.6)과 약모델(GPT-4.1-mini, Qwen3-235B-A22B) 사이에 20-40점 격차가 있습니다.
하네스-모델 상호작용이 핵심 발견입니다. Sonnet 4.6은 Claude Code, DeepAgents, OpenClaw 하에서 0.62~0.64 구간을 유지하지만, Hermes 하에서는 0.458로 떨어집니다. Opus 4.6과 Haiku 4.5도 같은 패턴을 보입니다. Trace 분석에 따르면 Claude 계열 모델은 활성 환경 탐색, 스크립트 실행, 다단계 수정에 의존하는데, Hermes는 이 행동을 승인 체크로 차단하거나 위임된 서브태스크로 우회시켜 아티팩트 쓰기 루프가 완료되기 전에 실행을 종료합니다. 결과적으로 /workspace/outputs에 안정적인 파일이 없는 채로 세션이 끝납니다. 동일한 Claude 모델로 Claude Code나 DeepAgents를 쓰면 정상 완료됩니다. 이것은 모델 역량 차이가 아닌 하네스-모델 호환성 문제입니다.
역할 클래스별 성능 (Figure 6)
모델 |
Product/proj |
Eng/IT |
HR/admin |
Executive |
Sales |
Marketing |
Finance/ops |
|---|---|---|---|---|---|---|---|
GPT-5.5 |
0.72 |
0.61 |
0.70 |
0.64 |
0.59 |
0.55 |
0.58 |
Sonnet 4.6 |
0.65 |
0.65 |
0.63 |
0.60 |
0.55 |
0.46 |
0.53 |
Kimi K2.6 |
0.65 |
0.66 |
0.48 |
0.43 |
0.50 |
0.46 |
0.53 |
DeepSeek V4 Pro |
0.59 |
0.66 |
0.64 |
0.58 |
0.56 |
0.45 |
0.46 |
Haiku 4.5 |
0.48 |
0.51 |
0.42 |
0.32 |
0.42 |
0.45 |
0.46 |
GPT-5.5가 전 역할 클래스에서 가장 견고한 범용 모델입니다. 마케팅과 재무/운영은 모든 모델에서 낮으며, 회사 특화 시나리오·컨벤션을 요구하는 작업들로 공개 데이터에 적게 등장하는 유형입니다.
비용-점수 트레이드오프
비용과 점수는 로그형 관계를 보입니다. 저비용에서 중간 비용으로 올라갈 때 큰 이득을 얻고, 중간에서 고비용 구간에서는 한계 수익이 감소합니다. 예외는 Hermes/Claude 계열 조합인데, 높은 모델 비용이 하네스-모델 비호환성 때문에 점수로 이어지지 못합니다.
스킬 주입 실험
프런트엔드 페이지 생성 서브클래스를 대상으로 스킬 주입 실험을 진행했습니다. 크리에이터 에이전트가 10개 인도메인 태스크 실행 궤적·아티팩트·판정 피드백을 학습해 스킬을 증류하고, 이를 동일 클래스의 보류된 5개 태스크에 주입해 전후 점수 변화를 측정합니다.
하네스/모델 |
GPT-5.5 생성 |
Kimi K2.6 생성 |
Haiku 4.5 생성 |
평균 |
|---|---|---|---|---|
Hermes/Kimi K2.6 |
+0.030 |
+0.022 |
-0.134 |
-0.027 |
Codex/GPT-5.5 |
+0.019 |
+0.070 |
+0.050 |
+0.046 |
OpenClaw/Kimi K2.6 |
+0.045 |
+0.115 |
-0.323 |
-0.054 |
DeepAgents/Haiku 4.5 |
*+0.178* |
+0.001 |
+0.031 |
+0.070 |
Mean Delta |
+0.068 |
+0.052 |
-0.094 |
+0.009 |
GPT-5.5 크리에이터는 모든 조합에서 양수 전이(+0.068 평균)를 보이며 음수 델타가 없습니다. Kimi K2.6 크리에이터도 전반적으로 양수(+0.052)입니다. 반면 Haiku 4.5 크리에이터는 평균 -0.094으로 OpenClaw/Kimi K2.6 조합에서 -0.323의 큰 저하를 만들어냅니다. 스킬 생성 능력과 소비 능력은 정렬돼 있지 않습니다. Haiku 4.5는 약한 크리에이터지만 DeepAgents 하의 Haiku 4.5 소비자는 세 크리에이터 중 두 개에서 개선을 보입니다. 스킬 주입은 고분산 결과를 보이므로 단일 평균 스킬 점수 대신 크리에이터-소비자 매트릭스로 평가해야 합니다.
Judge 신뢰도
텍스트 judge는 인간과 높은 일치를 보입니다(Spearman 0.790, MAE 0.134). 반면 비주얼 judge는 인간과 상관관계가 음수(\(\rho = -0.259\))이며 MAE 0.303으로 현재 멀티모달 LLM judge가 세밀한 기업 아티팩트 비주얼 평가에 아직 준비되지 않았음을 드러냅니다. 이것은 EnterpriseClawBench가 노출한 중요한 공개 문제입니다.
회고
저자들이 명시한 한계점 세 가지입니다. 첫째 단일 기업 배포에서만 세션을 수집했기 때문에 결과가 모든 조직을 대표하지 않을 수 있습니다. 특히 마케팅·재무 같은 도메인이 낮은 이유가 이 기업의 산업 특성 때문인지 일반적인 어려움 때문인지 구분이 어렵습니다. 둘째 데이터 비공개로 독립 재현과 확장이 제한됩니다. 재사용 가능한 자산은 구축·평가 방법론이지 데이터셋 자체가 아닙니다. 셋째 비주얼 judge가 아직 인간 수준으로 보정되지 않았습니다. 시각적 아티팩트에서 점수 인플레이션이 관찰됩니다.
정리
- 하네스 선택이 모델만큼이나 점수를 결정합니다. Claude 계열이 Hermes 하에서 20점 이상 떨어지는 것은 역량 차이가 아니라 하네스-모델 호환성 문제이며, 기업 에이전트 배포 시 스캐폴딩 선택이 모델 선택만큼 중요함을 보여줍니다.
- 최고 점수 0.663으로 기업 에이전트 평가는 아직 포화와 거리가 멉니다. 마케팅·재무 같은 도메인 특화 클래스와 멀티모달 산출물 평가가 특히 미해결 문제로 남아 있습니다.
- 스킬 전이 실험은 "어느 모델이 스킬을 잘 만드는가"와 "어느 모델이 스킬을 잘 쓰는가"가 따로 간다는 것을 보입니다. 단일 스킬 스코어보다 크리에이터-소비자 매트릭스 평가가 현실에 가깝습니다.