SpatialClaw - Rethinking Action Interface for Agentic Spatial Reasoning
S. Cho, R. Hachiuma, A. Badki, H. Su, B.-K. Lee, C. H. Song, S. Liu, S. Radhakrishnan, S. Kim, Y.-C. F. Wang, and M.-H. Chen, "SpatialClaw: Rethinking Action Interface for Agentic Spatial Reasoning," arXiv:2606.13673, 2026.
저자
NVIDIA 지각·학습 연구팀과 KAIST 컴퓨터비전 그룹의 교차점에서 이 논문이 나왔습니다.
천민훙 (NVIDIA Research Taiwan)은 직전 연구인 SpaceTools-Toolshed에서 구조화 도구 호출(structured tool-call) 방식을 직접 구현하고 평가한 인물입니다. 그 경험을 통해 JSON/XML 인터페이스가 열어주는 자유도의 한계를 누구보다 잘 알고 있었고, "인터페이스 자체를 바꿔야 한다"는 방향을 설정했습니다.
조석주 (1저자, KAIST)는 김승룡 교수 지도 아래 밀집 대응(dense correspondence) 및 다중 시점 기하 연구를 해온 연구자입니다. 카메라 기하와 시점 간 추론에 대한 깊은 이해가, 코드로 중간 결과를 보존하며 체이닝하는 persistent kernel 설계로 자연스럽게 이어졌습니다.
아비셰크 바드키와 류스페이 (NVIDIA Learning and Perception Research)는 스테레오 깊이, 광학 흐름, 4D 장면 이해 등 저수준 인식 도구를 직접 개발해온 팀입니다. SpatialClaw의 SAM3, DA3, Reconstruct 등 핵심 perception tool이 이들의 손에서 나왔습니다.
세 계열의 역할이 맞아 떨어진 셈입니다. 도구를 만든 사람, 인터페이스 한계를 경험한 사람, 그리고 기하를 체이닝하는 법을 아는 사람.
배경
"이 물체와 저 물체 사이 거리가 얼마나 되나요?" "카메라가 50번 프레임과 100번 프레임 사이에 얼마나 이동했나요?" VLM에 이런 질문을 던지면 상당히 잘 틀립니다.
이유는 단순합니다. 3D 공간 추론은 단일 패스로 해결되지 않는 경우가 많습니다. 객체를 분할하고, 깊이를 추정하고, 카메라 기하를 복원한 뒤, 거기서 나온 포인트 클라우드 안에서 최근접 거리를 계산해야 합니다. 각 단계의 출력이 다음 단계의 입력이 됩니다.
도구 증강 에이전트(tool-augmented agent)는 이 문제를 해결하려는 자연스러운 접근입니다. 분할, 깊이, 재구성 전문 모듈을 VLM에게 쥐여주는 것입니다. 그런데 여기서 질문이 하나 생깁니다. 어떤 방식으로 도구를 쥐여줄 것인가.
기존 방식은 두 갈래였습니다. 단일 패스 코드(single-pass code): 에이전트가 실행 결과를 보기 전에 분석 전략 전체를 코드로 미리 써야 합니다. 구조화 도구 호출(structured tool-call): JSON이나 XML 커맨드로 도구를 선택하고, 타입이 정해진 인자를 채워 넣는 방식입니다. 두 방식 모두 공통된 한계가 있습니다. 복잡한 3D/4D 공간 추론에서 필요한 조합과 수정이 중간에 자유롭게 일어나지 못합니다.
SpatialClaw의 출발점은 이 관찰입니다. "에이전트의 성능 한계는 도구의 품질이 아니라 도구를 호출하는 인터페이스 설계에 달려 있습니다."
어떻게 만들었나
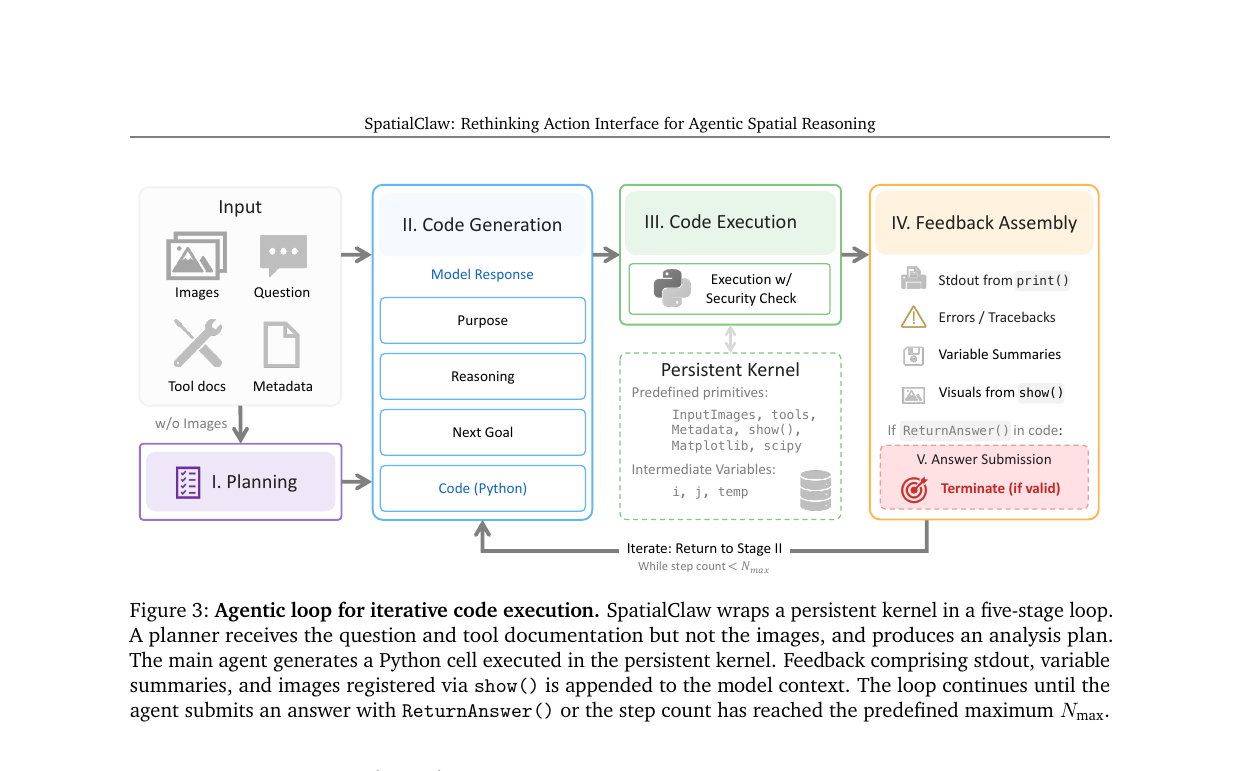
SpatialClaw의 핵심은 persistent Python kernel입니다. 에이전트가 각 스텝에서 독립적인 Python 코드 셀을 작성하고, 그 셀의 실행 결과(마스크, 깊이 맵, 포인트 클라우드, 카메라 행렬)가 변수로 보존됩니다. 다음 스텝의 코드는 이전 스텝의 모든 변수를 자유롭게 참조할 수 있습니다.
커널은 시작 시 다음 요소들을 미리 적재(pre-load)합니다.
- InputImages: 입력 비디오 프레임 리스트
- Metadata: 영상 길이, FPS, 해상도 등
- tools: 인식 도구 네임스페이스 (SAM3, DA3, Reconstruct 등)
- show(): 중간 시각화를 에이전트 컨텍스트에 즉시 피드백하는 함수
- vlm(): 서브 질의를 위한 별도 VLM 세션
- ReturnAnswer(): 최종 답 제출
에이전트는 다섯 단계 루프를 반복하며 답을 향해 나아갑니다.
Stage I: Planning. 별도의 플래너 LLM이 분석 단계를 미리 계획합니다. 이 세션은 코드 작성이 금지되고, 입력 프레임도 받지 않습니다. 질문과 도구 명세만으로 분석 계획을 수립하고, 그 결과를 메인 에이전트의 시스템 프롬프트 앞에 붙입니다.
Stage II: Code Generation. 메인 에이전트가 다음 실행할 Python 셀을 작성합니다. 응답 포맷은 목적(purpose), 추론(reasoning), 다음 목표(next goal), 코드(code)의 네 필드로 구조화됩니다.
Stage III: Code Execution. 코드를 실행하기 전, 추상 구문 트리(AST)를 파싱해 허용되지 않는 모듈이나 내장 함수 호출을 차단합니다. 보안 검사를 통과한 코드만 persistent kernel에서 실행됩니다.
Stage IV: Feedback Assembly. 실행 결과를 조합해 에이전트에게 돌려줍니다. stdout 출력, 에러 및 트레이스백, 새로 정의된 변수 요약, show()로 등록된 시각화 이미지가 포함됩니다.
Stage V: Answer Submission. ReturnAnswer()가 호출되고 유효성이 확인되면 루프를 종료합니다. 그렇지 않으면 Stage II로 돌아갑니다. 최대 \(N_{\text{max}} = 30\) 스텝까지 반복합니다.
이 구조에서 중요한 것은 에이전트가 중간 결과를 보고 전략을 수정한다는 점입니다. 마스크가 잘못됐으면 다른 프롬프트로 재분할합니다. get_centroid()가 부적절하다는 걸 알아채면 scipy.spatial.KDTree로 교체합니다. 분석 계획이 중간에 바뀌는 것 자체가 설계의 일부입니다.
결과
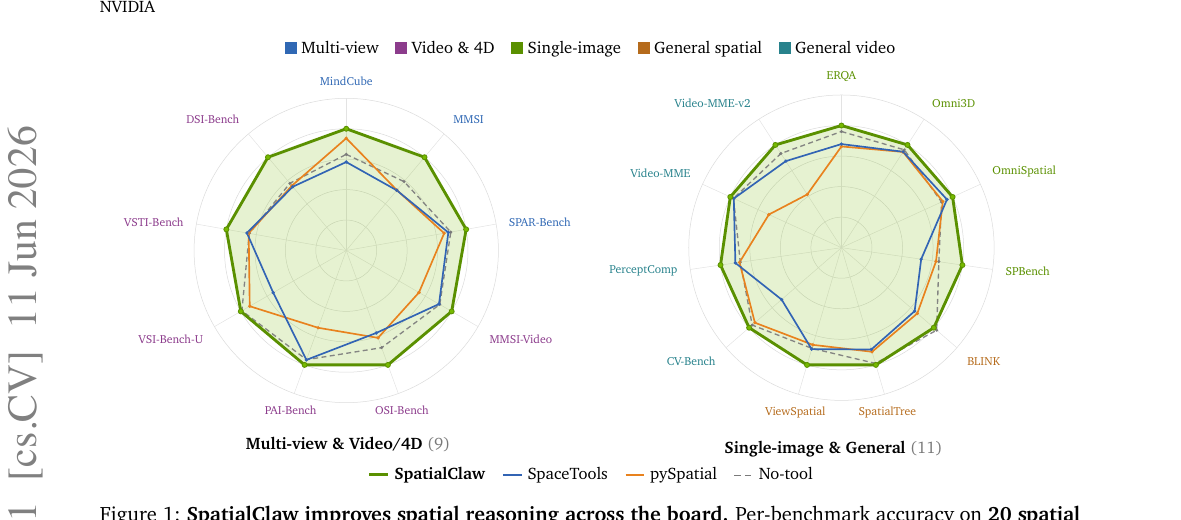
Gemma4-31B 백본을 기준으로, 동일한 도구 세트를 사용한 세 가지 행동 인터페이스를 비교한 결과입니다.
벤치마크 |
No-tool |
Single-Pass |
Structured |
SpatialClaw |
|---|---|---|---|---|
ERQA |
58.3 |
58.3 |
59.0 |
61.3 |
Omni3D |
51.7 |
48.2 |
55.7 |
54.3 |
OmniSpatial |
57.3 |
60.0 |
59.6 |
63.6 |
SPBench |
55.1 |
58.2 |
60.5 |
68.4 |
MindCube |
57.5 |
57.5 |
62.4 |
72.8 |
MMSI |
37.9 |
42.3 |
43.0 |
51.3 |
SPAR-Bench |
55.2 |
61.1 |
58.7 |
63.3 |
MMSI-Video |
36.9 |
37.1 |
35.1 |
41.6 |
OSI-Bench |
35.6 |
36.8 |
40.3 |
41.9 |
PAI-Bench |
65.0 |
64.2 |
65.6 |
68.1 |
VSI-Bench-U |
48.0 |
47.8 |
50.1 |
48.5 |
VSTI-Bench |
54.7 |
64.2 |
63.5 |
67.6 |
DSI-Bench |
45.3 |
57.9 |
58.4 |
62.9 |
BLINK |
75.7 |
73.9 |
73.9 |
73.4 |
SpatialTree |
59.9 |
58.9 |
57.7 |
60.7 |
ViewSpatial |
51.7 |
52.0 |
55.5 |
60.2 |
CV-Bench |
69.8 |
71.3 |
73.6 |
72.2 |
PerceptComp |
36.8 |
39.2 |
42.5 |
44.0 |
Video-MME |
74.8 |
74.6 |
75.8 |
77.0 |
Video-MME-v2 |
40.7 |
40.2 |
44.0 |
44.4 |
평균 |
53.4 |
55.2 |
56.7 |
59.9 |
평균 59.9%로, SpaceTools-Toolshed 대비 +11.2pp입니다. 향상 폭이 가장 큰 카테고리는 카메라 모션(+7.2pp), 다중 시점/시점 추론(+9.1pp), 상대적 방향(+9.1pp)으로, 모두 여러 프레임 또는 시점에 걸친 체인 기하 계산이 필요한 태스크입니다. 반면 BLINK와 같은 단일 이미지 시각 인식 태스크에서는 no-tool 대비 소폭 하락(-2.3pp)이 나타납니다.
한 가지 주목할 실험 결과가 있습니다. 유틸리티 래퍼(tools.Mask, tools.Geometry 등 사전 정의된 편의 함수)를 모두 제거하고 핵심 인식 도구(SAM3, DA3)와 numpy/scipy만 남긴 변형에서도 성능이 full SpatialClaw와 거의 같습니다. 에이전트가 유틸리티 함수 없이도 numpy/scipy 연산을 즉석에서 조합해 같은 계산을 수행하기 때문입니다. 이 결과는 SpatialClaw의 이점이 특정 도구 세트가 아니라 코드 자체가 오케스트레이션 공간이 된다는 인터페이스 설계에서 온다는 것을 뒷받침합니다.
이 성능 향상은 Qwen3.5(27B에서 397B), Gemma4(26B에서 31B) 등 두 모델 계열, 여섯 개 백본에서 시스템 프롬프트나 도구 세트의 수정 없이 일관되게 재현됩니다.
회고
논문이 솔직하게 인정하는 한계들이 있습니다.
인터페이스 이득의 천장. 백본 VLM이 이미 잘 풀 수 있는 시각 인식 태스크(BLINK 등)는 반복 코드 실행이 추가 이득을 주지 못하고 오히려 오버헤드만 생깁니다. 인터페이스 수준의 개선은 다단계 기하 계산이 필요한 태스크에서만 의미 있습니다.
계산 비용. 단일 패스 코드나 구조화 도구 호출에 비해 \(N_{\text{max}} = 30\) 스텝까지 반복하는 SpatialClaw는 추론 비용이 상당히 높습니다. 실용화를 위해서는 빠른 종료 조건이나 적응적 스텝 수 조정이 필요합니다.
실패 모드 분석. 논문이 제시한 실패 유형 세 가지: (a) 인식 도구 자체의 오류(마스크 잘못됨, 깊이 부정확), (b) 에이전트의 논리 오류(올바른 도구를 잘못 사용), (c) 문제 해석 오류. 코드 기반 인터페이스가 (b)를 크게 줄이지만, (a)는 인터페이스로 해결할 수 없는 인식 품질 문제입니다.
백본 의존성. Python 코드를 문법적, 의미론적으로 올바르게 생성할 수 있는 충분히 강력한 VLM이 필요합니다. 소형 모델에서는 persistent kernel 환경 자체를 이해하지 못할 수 있습니다.
정리
- 도구 증강 에이전트의 성능은 어떤 도구를 제공하느냐보다 어떻게 도구를 호출하게 하느냐에 더 크게 달려 있습니다.
- Persistent Python kernel은 마스크, 깊이 맵, 포인트 클라우드를 변수로 보존하고 numpy/scipy 연산과 자유롭게 조합하게 함으로써, JSON/XML 인터페이스가 열어줄 수 없는 체이닝 공간을 만들어냅니다. 그 자유도가 카메라 모션, 다중 시점 추론 같은 체인 기하 태스크에서 +7~9pp의 향상으로 나타납니다.
- 6개 VLM 백본과 20개 벤치마크에 걸쳐 모델별 조정 없이 재현된 이 결과는, 앞으로 공간 추론 에이전트를 설계할 때 인터페이스 설계를 첫 번째 결정 사항으로 고려해야 한다는 설계 원칙을 제시합니다.