The Deterministic Horizon - When Extended Reasoning Fails and Tool Delegation Becomes Necessary
D. Guo, J. Wu, and S. M. Yiu, "The Deterministic Horizon: When Extended Reasoning Fails and Tool Delegation Becomes Necessary," arXiv:2606.00376, 2026.
지금 추론 모델의 지배적 믿음은 단순합니다. 오래 생각할수록 더 잘 푼다. o1, DeepSeek-R1 같은 모델은 추론 시점 연산(test-time compute)에 막대하게 투자하고, 사용자도 "더 길게 생각해"라고 시킵니다. The Deterministic Horizon은 이 통념을 정면으로 반박합니다. 단, 모든 과제가 아니라 결정적 상태 추적(deterministic state-tracking) 과제에 한해서입니다.
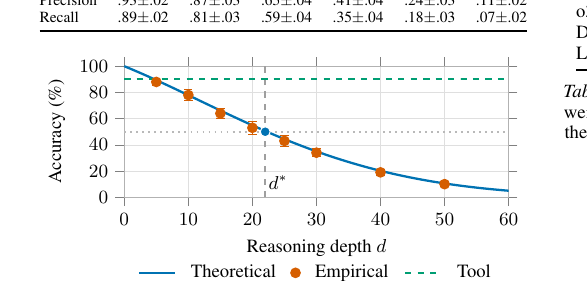
핵심 발견은 충격적입니다. BFS로 0.1초 안에 풀리는 순열 퍼즐을, 최신 추론 모델은 몇 분을 생각하고도 틀립니다. 깊이 10에서는 78% 정확도를 유지하다가, 깊이 30에서 34%로 떨어지고, 깊이 50을 넘으면 사실상 찍기 수준이 됩니다. 그리고 이 붕괴는 긴 추론이 막아 주는 게 아니라, 긴 추론이 일으킵니다.
저자
세 명이 썼습니다. 1저자 겸 교신은 홍콩대(HKU) 박사과정 궈둥신, 지도교수는 야오시우밍, 그리고 산업계 공저자 우지쿤입니다. ICML 2026에 채택됐습니다.
궈둥신의 연구 정체성이 이 논문에 그대로 담겨 있습니다. "LLM이 증명 가능하게 할 수 있는 것과, 배포된 뒤 신뢰할 수 있는 것 사이의 경계"가 그의 주제이고, 이 논문은 그 경계를 정보이론으로 못 박은 결과물입니다. 지도교수 야오시우밍는 보안·암호학에서 출발한 엄밀함을 가져옵니다. 디코더 어텐션의 용량을 정보 채널로 보고 한계를 증명하는 접근은 그 배경과 잘 맞습니다. 우지쿤는 Brain Investing과 Stellaris AI 소속으로, 논문은 두 회사가 자금을 대지 않았고 평가 모델도 만들지 않았다는 이해상충 공시를 따로 답니다.
배경
저자들이 공격하는 과제는 결정적 상태공간 탐색입니다. 초기 상태 \(\sigma_0\)를 연산자 집합 \(O\)로 변환해 목표 \(\tau\)에 도달하는, 정확한 연산 시퀀스를 요구하는 문제입니다. 소프트웨어 엔지니어링, 형식 검증, 순차 계획이 여기 속합니다. 이런 과제에서는 정답이 이진법입니다. "거의 맞음"은 그냥 틀림입니다.
이 현상에는 경쟁하는 설명이 둘 있습니다. 하나는 동시기 연구 Wu et al.(2026)의 Simplicity Bias로, 모델이 짧은 추론을 선호하는 "취향" 문제라는 해석입니다. 이 관점은 학습 개입(파인튜닝, 프롬프트)으로 성능을 회복할 수 있다고 봅니다. 다른 하나가 이 논문의 Decoherence입니다. 모델이 길게 추론하려고 시도해도 정확도를 유지할 수 없는데, 자기회귀 어텐션에 정확한 상태 추적을 위한 토대 자체가 없기 때문이라는 주장입니다. 토큰 예측을 알고리즘 실행으로 착각하는 Simulator Fallacy입니다.
두 가설은 검증 가능한 예측에서 갈립니다. Simplicity Bias는 최적 길이 트레이스로 파인튜닝하면 30% 넘게 회복된다고 보고, 이 논문은 아키텍처 천장 때문에 5% 미만이라고 봅니다. 누구 말이 맞는지는 실험으로 가립니다.
이론
이 논문의 무게중심은 이론입니다. 네 개의 결과가 맞물립니다.
첫째, 맥락 의존 오차 모델입니다. 기존처럼 스텝당 오차를 상수로 보지 않고, 깊이에 따라 커지는 것으로 둡니다.
\[\epsilon(d) = \epsilon_0 + \gamma \cdot \frac{d}{L_{\text{eff}}}\]
\(\epsilon_0\)는 기본 스텝 오차, \(\gamma\)는 어텐션 감쇠율, \(L_{\text{eff}}\)는 유효 결깨짐 길이입니다. 중요한 점은 \(L_{\text{eff}}\)가 원본 컨텍스트 윈도 \(L\)보다 훨씬 작다는 것입니다. 실측으로 \(L_{\text{eff}} = O(10^2)\) 스텝인데 \(L = O(10^5)\) 토큰입니다. 모델의 실효 작업기억은 컨텍스트 창보다 수백 배 좁습니다.
둘째, 이 오차 모델에서 정확도가 초지수적으로 감쇠한다는 결깨짐 한계(Decoherence Bound)가 나옵니다.
\[P(\text{correct at depth } m) \le \exp\left(-m\epsilon_0 - \frac{\gamma\, m(m+1)}{2 L_{\text{eff}}}\right)\]
\(m(m+1)\)의 이차항이 핵심입니다. 깊이가 늘수록 정확도가 선형이나 단순 지수가 아니라 그보다 빠르게 무너집니다. 실제로 이 초지수 곡선이 데이터를 \(R^2 = 0.96\)으로 맞추고, 선형(\(0.71\))이나 단순 지수(\(0.83\))보다 잘 맞습니다.
셋째, 어텐션 병목 정리입니다. 자기회귀 어텐션은 매 스텝 모든 과거 상태 정보를 고정 용량 채널로 압축해야 하는데, 추적 가능한 서로 다른 상태 수가 다음으로 묶입니다.
\[|S_{\text{track}}| \le c(\delta, \rho_{\max}) \cdot 2^{H \cdot \log_2(L/H) \cdot \sqrt{d_h}}\]
\(H\)는 헤드 수, \(L\)은 컨텍스트 길이, \(d_h\)는 헤드 차원입니다. 즉 용량은 대략 \(O(H \cdot \log(L/H) \cdot \sqrt{d_h})\) 꼴입니다.
넷째, 이 모든 게 가리키는 임계점이 Deterministic Horizon \(d^*\)입니다. 목표 성공 확률 \(\alpha\)에서 정확도가 \(\alpha\) 밑으로 떨어지는 최대 깊이로, 닫힌 형식이 있습니다.
\[d^* = \frac{-\epsilon_0 L_{\text{eff}} + \sqrt{\epsilon_0^2 L_{\text{eff}}^2 + 2\gamma L_{\text{eff}} \ln(1/\alpha)}}{\gamma}\]
주력 모델군에서 \(d^* \in [19, 31]\)로 나옵니다. 그리고 \(d^* \propto \sqrt{d_h \cdot H}\)로 스케일링되어, 큰 모델일수록 호라이즌이 멀어집니다. 다만 원본 컨텍스트 윈도 \(L\)은 이 관계에 들어가지 않습니다. 컨텍스트를 아무리 늘려도 결깨짐 한계는 거의 그대로입니다.
마지막으로 가장 중요한 정리는 파인튜닝 상한입니다. 깊이 \(d > d^*\)인 트레이스로 어떻게 학습하든 정확도는 다음을 넘을 수 없습니다.
\[\text{Acc}_{\text{fine-tune}} \le \text{Acc}_{\text{baseline}} + O\!\left(\frac{d^*}{d}\right)\]
학습 데이터 분포와 무관하게 적용되는 아키텍처 천장입니다. 만약 Simplicity Bias가 원인이라면 파인튜닝이 무제한 회복해야 하는데, 이 정리는 그게 불가능하다고 말합니다.
실험
규모가 큽니다. 12개 모델 \(\times\) 5개 조건 \(\times\) 8개 과제 \(\times\) 500 인스턴스 \(\times\) 3회 = 72만 회 평가, 비용 $3,420입니다. 조건은 다섯입니다. C1은 제약 없는 신경 CoT, C2는 깊이 제한 CoT, C3은 도구 통합(BFS 솔버 접근), C4는 명시적 길이 독려("필요한 만큼 단계를 밟아라"), C5는 최적 길이 트레이스 파인튜닝입니다.
먼저 도구 위임이 압도합니다. 실세계 SWE-Bench-State에서 도구(C3)가 86~94%, 신경 CoT(C1)는 24~42%에 멈춥니다.
모델 |
C1 신경 CoT (%) |
C3 도구 위임 (%) |
\(d^*\) |
|---|---|---|---|
o3-mini |
36.8 |
92.7 |
28 |
DeepSeek-R1 |
34.2 |
90.8 |
26 |
Claude-4.5-Opus |
29.6 |
91.2 |
24 |
GPT-4o |
24.1 |
86.4 |
19 |
(SWE-Bench-State, 정확도(%). \(d^*\)는 도메인별 결정적 호라이즌.)
같은 패턴이 WebArena-Nav, SQL-Multi에서도 반복되어 실세계 호라이즌은 \(d^* \in [19, 26]\)입니다. 자연어 모호성과 큰 상태공간 때문에 합성 과제보다 호라이즌이 짧습니다.
다음이 두 가설을 가르는 결정적 실험입니다.
개입 |
회복 폭 |
Simplicity Bias 예측 |
|---|---|---|
C4 길이 독려 |
+0.7~1.0% |
|
C5 최적길이 파인튜닝 |
+3.2% |
|
길이를 독려해도(C4) 1%도 안 오르고, 최적 길이로 파인튜닝해도(C5) 3.2%만 오릅니다. Simplicity Bias가 예측한 30% 회복과 정면으로 어긋납니다. Llama-3.1-8B를 깊이 30~40 트레이스로만 학습시켜도 깊이 40 너머에서 15%를 못 넘습니다. 취향이 아니라 능력의 한계라는 증거입니다.
상태공간 Jaccard(SSJ) 분석이 이를 못 박습니다. 만약 취향 문제라면 모델이 상태를 추적할 수 있는데 안 하는 것이므로 정밀도는 높고 재현율만 떨어져야 합니다. 그런데 정밀도와 재현율이 함께 무너집니다.
깊이 |
SSJ |
정밀도 |
재현율 |
|---|---|---|---|
5 |
0.83 |
0.93 |
0.89 |
20 |
0.45 |
0.65 |
0.59 |
30 |
0.23 |
0.41 |
0.35 |
50 |
0.04 |
0.11 |
0.07 |
둘 다 비슷한 속도로 떨어진다는 건 모델이 가상의 상태공간으로 표류한다는 뜻, 곧 능력 실패(Decoherence)입니다.
마지막으로 아키텍처 스케일링이 이론을 뒷받침합니다. \(d^* \propto \sqrt{d_h \cdot H}\) 예측이 오픈웨이트 모델에서 2% 오차로 맞습니다.
모델 |
크기 |
\(d^*\) (관측) |
\(d^*\) (예측) |
|---|---|---|---|
Qwen-2.5-7B |
7B |
19 |
18.8 |
Llama-3.1-8B |
8B |
20 |
20.1 |
Llama-3.3-70B |
70B |
28 |
28.4 |
Qwen-2.5-72B |
72B |
28 |
28.4 |
조직이 다른 모델들이 같은 인스턴스에서 함께 실패하는 교차모델 상관은 \(r = 0.81\)~\(0.91\)로, 학습이 아니라 공유된 아키텍처 제약이 원인임을 가리킵니다. 어텐션 엔트로피와 정확도의 상관은 \(r \approx -0.70\)으로, 어텐션 희석이 결깨짐을 일으킨다는 메커니즘 가설을 직접 뒷받침합니다. 양방향 어텐션을 쓰는 인코더-디코더(T5-Large)는 깊이 30에서 \(2.8\times\) 높은 정확도(67.3% vs GPT-4o 23.4%)를 내, 인과 마스킹 자체가 병목임을 시사합니다.
회고
저자들이 적은 한계가 솔직합니다.
첫째, 닫힌 모델입니다. \(d^*\)는 헤드 수 \(H\)와 헤드 차원 \(d_h\)에 의존하는데 이 값은 오픈웨이트만 공개됩니다. 따라서 GPT-4o·Claude의 \(d^*\)는 경험적 적합값이고, \(\sqrt{d_h H}\) 스케일링 검증은 오픈웨이트로만 했습니다. 닫힌 모델 결과는 같은 정성적 패턴을 보이는 일관성 확인용일 뿐 아키텍처 증거로는 쓰지 않는다고 명시합니다.
둘째, 파인튜닝 실험은 단일 모델(Llama-3.1-8B, 5,000 트레이스) 한 건이라, 용량 한계와 데이터 한계를 완전히 분리하려면 더 큰 모델·데이터가 필요합니다. 셋째, 도구 조건이 정확한 BFS 솔버라 C1 대 C3 격차는 위임의 이득을 상한으로 잡은 것입니다. 불완전한 도구는 향후 과제로 남깁니다. 넷째, \(d^*\)는 \(\epsilon_0\)에 민감하고 \(\epsilon_0\)은 프롬프트 형식·few-shot에 흔들리므로, 보고된 [19, 31] 구간은 정밀한 모델별 상수가 아니라 영역 지표로 읽어야 합니다.
가장 중요한 범위 한정은 이것입니다. 이 호라이즌은 결정적·정확검증 가능 과제에만 적용됩니다. 요약·대화·창작처럼 정답 상태가 하나가 아닌 과제, GSM8K류처럼 보통 15스텝 미만으로 끝나는 근사 추론에는 해당하지 않습니다. 거기서는 긴 CoT가 여전히 이롭습니다. "긴 추론이 항상 해롭다"는 주장이 결코 아닙니다.
정리
- 결정적 상태 추적에서 긴 CoT가 무너지는 건 모델의 취향이 아니라 디코더 어텐션의 정보이론적 용량 한계라는 것을, 어텐션 병목 정리와 초지수 결깨짐 한계로 증명했습니다. 임계점 \(d^* \in [19, 31]\)을 넘으면 파인튜닝으로도 못 넘습니다(C5 +3.2% vs 예측 +30%).
- 실용적 함의는 명확합니다. 약 20스텝 이상 정확한 상태 전이가 필요한 과제(프로그램 상태 추적, 다중 테이블 SQL 조인, 긴 순열·계획)는 신경 추론에 맡기지 말고 도구(코드 실행·심볼릭 솔버)에 위임하라는 것입니다. 도구 위임은 정확도뿐 아니라 비용에서도 \(4.2\)~\(4.7\times\) 효율적입니다(GPT-4o 정답당 \(0.021 vs 신경 CoT\)0.089).