Recursive Multi-Agent Systems
ChatGPT한테 "이 코드베이스 전체 리팩터링해줘"라고 하면 어떻게 됩니까. 100만 줄짜리 프로젝트라면? 맥락창이 터지거나, 절반만 보고 이상한 답을 내놓거나, 아예 포기합니다. 이건 모델이 멍청해서가 아닙니다. 구조 문제입니다.
2023년 이후 LLM 연구의 핵심 질문 중 하나가 이겁니다. 단일 모델의 한계를 어떻게 넘어서냐. 그 답으로 나온 것이 멀티에이전트 시스템, 그중에서도 에이전트가 에이전트를 낳는 재귀적 구조입니다.
단일 에이전트의 세 가지 구조적 한계
멀티에이전트 구조가 필요한 이유를 이해하려면 단일 에이전트가 왜 안 되는지를 먼저 봐야 합니다. 단순히 "컨텍스트가 짧다"는 이야기가 아닙니다.
첫 번째는 컨텍스트 한계입니다. GPT-4의 128K 토큰, Claude 3.7의 200K 토큰, Gemini 1.5 Pro의 1M 토큰 — 이 숫자들이 커 보이지만 실제 작업 단위에서는 금방 찹니다. 소형 Python 프로젝트 하나가 이미 수십만 토큰입니다. 더 심각한 건 lost in the middle 현상입니다. Liu et al. (2023) "Lost in the Middle: How Language Models Use Long Contexts"에서 실증한 것처럼, LLM은 긴 컨텍스트의 중간 부분을 체계적으로 무시합니다. 관련 정보가 앞이나 뒤에 있을 때보다 중간에 있을 때 성능이 크게 떨어집니다. 컨텍스트창을 늘려도 근본 해결이 안 된다는 뜻입니다.
두 번째는 순차 처리입니다. 단일 에이전트는 본질적으로 직렬입니다. "문서 100개 요약해줘"라고 하면 1번 문서부터 100번 문서까지 순서대로 처리합니다. 병렬 실행이 불가능하니 작업 규모에 선형적으로 시간이 늘어납니다.
세 번째가 가장 교묘합니다. 단일 실패 지점(Single Point of Failure)입니다. 에이전트가 하나면 그 에이전트가 잘못된 가정을 하는 순간 전체가 틀어집니다. 검증자가 없습니다. 스스로 틀렸다는 걸 모르는 채로 틀린 방향으로 달려갑니다. Wang et al. (2022) "Self-Consistency Improves Chain of Thought Reasoning in Language Models"에서 같은 문제를 여러 번 풀어 다수결로 답을 내는 self-consistency 기법이 단일 경로 대비 큰 성능 향상을 보인 것도 이 때문입니다 — 다수 경로 탐색이 단일 경로의 구조적 취약성을 보완합니다.
재귀적 멀티에이전트 구조: 트리와 DAG
재귀적(Recursive) 멀티에이전트란 에이전트가 서브에이전트를 생성하고, 그 서브에이전트가 또 서브에이전트를 생성할 수 있는 구조입니다. 단순히 에이전트 여럿을 병렬로 돌리는 것과 다릅니다. 핵심은 **계층성(hierarchy)**과 **문맥 격리(context isolation)**입니다.
구조를 그림으로 보면 이렇습니다.
오케스트레이터 (Orchestrator)
├── 서브에이전트 A (코드 작성)
│ ├── 서브에이전트 A-1 (함수 설계)
│ └── 서브에이전트 A-2 (테스트 작성)
├── 서브에이전트 B (문서화)
└── 서브에이전트 C (보안 검토)
└── 서브에이전트 C-1 (취약점 분석)
루트 오케스트레이터가 작업을 분해하고, 각 노드가 독립적인 컨텍스트창을 가집니다. A가 처리하는 내용이 B에게 전달되지 않습니다 — 오케스트레이터가 명시적으로 넘기지 않는 한. 이게 컨텍스트 격리입니다.
실제 구현에서는 단순 트리보다 DAG(Directed Acyclic Graph)가 더 흔합니다. 노드 A와 B의 결과를 모두 받아서 처리하는 노드 C가 있을 수 있으니까요. 다만 사이클(cycle)은 무한 루프로 이어지기 때문에 대부분의 프레임워크가 DAG를 강제합니다.
이 구조를 처음 체계적으로 정리한 논문 중 하나가 Yao et al. (2022)의 **"ReAct: Synergizing Reasoning and Acting in Language Models"**입니다. 여기서 핵심 아이디어는 Reason + Act의 반복 — 에이전트가 생각하고, 행동하고, 관찰하고, 다시 생각하는 루프입니다. 멀티에이전트 구조는 이 루프를 여러 에이전트가 계층적으로 나눠 수행하는 것으로 볼 수 있습니다.
에이전트 간 커뮤니케이션: 무엇을 어떻게 넘기나
멀티에이전트 시스템에서 가장 설계가 까다로운 부분이 에이전트 간 정보 전달입니다. 세 가지 방식이 있습니다.
메시지 패싱(Message Passing): 가장 단순합니다. 한 에이전트의 출력이 그대로 다음 에이전트의 입력이 됩니다. Claude Code의 Agent 툴이 이 방식입니다.
<!-- -->
# Claude Code Agent 툴 사용 예시 (개념적 표현)
result = agent.run(
prompt=f"다음 코드를 분석하고 버그를 찾아라:\n{code}",
tools=["read_file", "bash"]
)
<!-- -->
# result가 다음 에이전트의 입력으로
review = agent.run(
prompt=f"이 분석 결과를 검토하라:\n{result}",
tools=[]
)
공유 메모리(Shared Memory): 에이전트들이 공통 상태 저장소를 읽고 씁니다. LangGraph의 State가 대표적입니다. 어떤 에이전트든 상태를 조회할 수 있고, 자기 결과를 기록합니다.
블랙보드(Blackboard): 공유 메모리의 변형으로, 특정 패턴의 데이터가 게시되면 해당 에이전트가 깨어나는 pub-sub 구조입니다. 대규모 시스템에서 에이전트 수가 많을 때 쓰입니다.
무엇을 선택하냐는 격리 수준과 조율 복잡도의 트레이드오프입니다. 메시지 패싱은 가장 격리가 강하지만 중간 상태 공유가 어렵고, 공유 메모리는 유연하지만 동시 쓰기 충돌(write conflict)을 관리해야 합니다.
오케스트레이션 패턴 4가지
2023~2024년에 걸쳐 실전에서 수렴된 오케스트레이션 패턴이 있습니다. 각각 쓰임새가 다릅니다.
Map-Reduce
입력을 잘게 쪼개어 병렬 처리 후 결과를 합치는 패턴입니다. 대용량 문서 처리, 코드 분석, 데이터 파이프라인에 적합합니다.
오케스트레이터
→ [문서1 처리] [문서2 처리] [문서3 처리] (병렬)
→ 결과 합산 에이전트
→ 최종 요약
단순해 보이지만 실제 구현 시 청킹(chunking) 전략이 결과 품질을 크게 좌우합니다. 문서를 고정 크기로 자르면 문장 중간에서 끊기고, 의미 단위로 자르려면 먼저 구조 분석이 필요합니다.
Pipeline
작업이 순서 의존성을 가질 때 씁니다. 각 단계의 출력이 다음 단계의 입력으로 엄격하게 이어집니다. CI/CD, 데이터 변환 워크플로우와 비슷한 구조입니다.
코드 생성 → 테스트 작성 → 테스트 실행 → 버그 수정 → 코드 리뷰
Pipeline의 핵심 이슈는 오류 전파입니다. 2단계에서 잘못되면 3, 4, 5단계가 모두 잘못됩니다. 각 단계에 검증(validation) 노드를 끼워 넣거나, 실패 시 이전 단계로 되돌리는 롤백 로직이 필요합니다.
Hierarchical (계층형)
복잡한 도메인 전문성이 필요한 작업에서 "관리자 - 팀장 - 팀원" 구조를 만드는 패턴입니다. Wu et al. (2023)의 AutoGen 논문에서 제안한 Group Chat 구조가 이 범주에 들어갑니다. 오케스트레이터가 Manager Agent 역할을 하고, 도메인별 전문 에이전트들에게 작업을 위임합니다.
Manager Agent
├── Research Agent (논문 검색, 요약)
├── Code Agent (구현)
├── Critic Agent (검토, 비판)
└── Writer Agent (최종 문서화)
AutoGen에서는 이를 GroupChat과 GroupChatManager로 구현합니다.
from autogen import AssistantAgent, GroupChat, GroupChatManager
research_agent = AssistantAgent("researcher", ...)
code_agent = AssistantAgent("coder", ...)
critic_agent = AssistantAgent("critic", ...)
groupchat = GroupChat(
agents=[research_agent, code_agent, critic_agent],
messages=[],
max_round=20
)
manager = GroupChatManager(groupchat=groupchat, llm_config=llm_config)
Debate/Reflection
같은 문제를 여러 에이전트가 독립적으로 풀게 한 뒤 결과를 상호 검토하게 하는 패턴입니다. Du et al. (2023)의 **"Improving Factuality and Reasoning in Language Models through Multiagent Debate"**에서 실증한 방법입니다. 수학 문제, 코드 작성, 사실 확인 같은 정확도가 중요한 영역에서 단일 에이전트 대비 큰 성능 향상을 보였습니다.
에이전트 A의 풀이 ─┐
에이전트 B의 풀이 ─┼─→ 검토 라운드 → 최종 합의
에이전트 C의 풀이 ─┘
실용적 단점은 비용입니다. 에이전트 3개가 같은 문제를 풀면 비용이 3배입니다. 검토 라운드까지 더하면 5~6배가 됩니다. 고정밀도가 필요한 작업에만 선별적으로 쓰는 게 맞습니다.
주요 구현체 비교
현재 프로덕션에서 쓸 수 있는 구현체들입니다.
Claude Code Agent 툴
Anthropic의 Claude Code CLI에 내장된 Agent 툴입니다. 별도 프레임워크 없이 Claude 모델끼리 서브에이전트를 생성합니다. 마크다운 파일(SKILL.md)로 에이전트 행동을 정의하고, Bash·Read·Write·WebSearch 같은 툴셋을 명시합니다.
// .claude/settings.json
{
"permissions": {
"allow": ["Bash(git:*)", "Read", "Write", "WebSearch"],
"deny": ["Bash(rm -rf:*)"]
}
}
장점: 추가 설치 없음, Claude 모델 최적화, 파일시스템·웹 툴 내장. 단점: Claude 모델만 사용 가능, 복잡한 상태 관리는 수동으로 구현.
AutoGen (Microsoft Research)
Wu et al. (2023) "AutoGen: Enabling Next-Generation LLM Applications via Multi-Agent Conversation Framework"에서 공개한 프레임워크입니다. Agent 간 대화(Conversation)를 기본 추상화 단위로 씁니다. Human-in-the-loop, 코드 실행, 도구 호출을 통합합니다.
GitHub: microsoft/autogen (40K+ stars)
from autogen import AssistantAgent, UserProxyAgent
assistant = AssistantAgent(
name="assistant",
llm_config={"model": "gpt-4", "api_key": "..."}
)
user_proxy = UserProxyAgent(
name="user_proxy",
human_input_mode="NEVER",
code_execution_config={"work_dir": "coding"}
)
user_proxy.initiate_chat(assistant, message="피보나치 수열 코드 짜줘")
LangGraph (LangChain)
상태 머신(State Machine) 기반 에이전트 오케스트레이션입니다. DAG를 코드로 명시하고, 각 노드가 상태를 변환합니다. LangSmith 관측 도구와 통합됩니다.
from langgraph.graph import StateGraph, END
from typing import TypedDict, Annotated
import operator
class AgentState(TypedDict):
messages: Annotated[list, operator.add]
next: str
workflow = StateGraph(AgentState)
workflow.add_node("research", research_node)
workflow.add_node("write", write_node)
workflow.add_node("review", review_node)
workflow.add_edge("research", "write")
workflow.add_conditional_edges(
"review",
lambda state: state["next"],
{"approved": END, "revise": "write"}
)
장점: 상태 관리 명시적, 조건 분기 자유로움, 관측 도구 통합. 단점: 구조 정의가 장황해질 수 있음, LangChain 생태계 의존.
CrewAI
"팀(Crew)" 개념으로 에이전트에 역할(Role), 목표(Goal), 배경(Backstory)을 부여합니다. 인간이 팀을 운영하는 방식을 모사합니다.
from crewai import Agent, Task, Crew
researcher = Agent(
role="선임 연구원",
goal="최신 AI 동향 파악",
backstory="10년 경력의 AI 연구자",
tools=[search_tool]
)
writer = Agent(
role="기술 작가",
goal="연구 결과를 읽기 쉬운 글로 변환",
backstory="기술 블로그 전문 작가"
)
task1 = Task(description="GPT-5 출시 동향 조사", agent=researcher)
task2 = Task(description="조사 결과로 블로그 포스트 작성", agent=writer)
crew = Crew(agents=[researcher, writer], tasks=[task1, task2])
result = crew.kickoff()
장점: 역할 기반 추상화 직관적, 비개발자도 이해 가능한 구조. 단점: 복잡한 DAG 표현 제한적, 내부 상태 제어 어려움.
비용 현실
멀티에이전트가 좋아 보여도 비용이 무시무시합니다. 구체적으로 계산해봅시다.
Claude Sonnet 4 기준 (2026년 4월): 입력 \(3/1M 토큰, 출력\)15/1M 토큰.
코드 리뷰 파이프라인 예시: - 오케스트레이터: 입력 5K + 출력 2K = \(0.045 - 서브에이전트 5개 (각 10K 입력, 5K 출력): 5 ×\)0.105 = \(0.525 - 검토 에이전트: 입력 30K + 출력 5K =\)0.165 - 합계: 약 $0.74/실행
하루 100번 실행하면 \(74/일, 월\)2,220입니다. 복잡도가 올라가면 쉽게 10배가 됩니다. 프로덕션 도입 전에 반드시 비용 시뮬레이션을 해야 합니다.
비용 최적화 전략: 1. 모델 분리: 오케스트레이터만 Opus, 서브에이전트는 Haiku 또는 Sonnet 2. 캐싱 적극 활용: 시스템 프롬프트와 공통 컨텍스트는 프롬프트 캐시로 3. 트리밍(Trimming): 에이전트 간 전달 시 관련 없는 내용 제거 4. 조기 종료: 목표 달성 시 나머지 에이전트 실행 취소
오류 전파와 디버깅
단일 에이전트 디버깅도 어렵지만 멀티에이전트는 차원이 다릅니다.
오류 전파 문제: 파이프라인에서 2번 에이전트가 잘못된 분석을 했다면, 3번 에이전트는 그 위에 더 정교한 오류를 쌓습니다. 최종 결과만 보면 뭐가 틀린지 알 수 없습니다. 각 노드에 verifier 에이전트를 끼워 넣는 방어 패턴이 필요합니다.
무한 루프 위험: 재귀 구조에서 에이전트가 스스로 서브에이전트를 낳고, 그 서브에이전트가 또 서브에이전트를 낳는 루프가 발생할 수 있습니다. 방어 코드가 필수입니다.
MAX_DEPTH = 5
MAX_AGENTS = 50
def spawn_agent(task, depth=0, agent_count=[0]):
if depth >= MAX_DEPTH:
raise RecursionError(f"최대 깊이 {MAX_DEPTH} 초과")
if agent_count[0] >= MAX_AGENTS:
raise RuntimeError(f"최대 에이전트 수 {MAX_AGENTS} 초과")
agent_count[0] += 1
# 에이전트 실행 로직
관측성(Observability): 멀티에이전트 시스템을 프로덕션에 쓰려면 각 에이전트의 입출력, 실행 시간, 비용을 추적할 수 있어야 합니다. LangSmith와 Langfuse가 이 용도로 많이 쓰입니다. 에이전트 실행 트리를 시각화하고, 어느 노드에서 시간이 많이 걸리는지, 어디서 오류가 발생하는지를 볼 수 있습니다.
안전과 최소 권한
멀티에이전트 시스템에서 안전은 중요한 연구 주제입니다. Anthropic의 다중 에이전트 보안 가이드라인에서 강조하는 원칙이 **최소 권한(Least Privilege)**입니다.
- 서브에이전트는 작업에 필요한 최소한의 도구만 가져야 합니다
- 파일 쓰기 권한이 필요 없는 에이전트에게 쓰기 권한을 주지 않습니다
- 외부 API 호출 에이전트와 파일시스템 접근 에이전트를 분리합니다
또한 간접 프롬프트 인젝션(Indirect Prompt Injection) 공격에 주의해야 합니다. 웹 서치나 외부 문서를 읽는 에이전트가 악의적인 지시문이 삽입된 페이지를 처리할 경우, 오케스트레이터 전체가 악용될 수 있습니다. 외부 입력을 처리하는 에이전트는 신뢰 경계(trust boundary)를 명확히 분리해야 합니다.
현재 상황과 한계
솔직하게 말하면, 재귀적 멀티에이전트 시스템은 아직 불안정합니다.
신뢰성 문제: 에이전트 수가 늘어날수록 전체 시스템의 신뢰성은 개별 에이전트 신뢰성의 곱에 비례해서 떨어집니다. 에이전트 하나가 95% 신뢰성을 가진다면, 10개가 직렬로 연결된 파이프라인의 신뢰성은 \(0.95^{10} ≈ 60\%\)입니다. 각 단계에 검증을 넣으면 비용이 더 올라갑니다.
벤치마크 한계: 현재 에이전트 평가 벤치마크들 — SWE-Bench, WebArena, AgentBench 등 — 은 단일 태스크 완료율을 측정합니다. 실제 프로덕션 워크로드에서의 비용-성능 트레이드오프, 장시간 실행 시 신뢰성, 에러 복구 능력은 제대로 측정되지 않습니다.
개발 경험: 멀티에이전트 시스템을 디버깅하는 것은 분산 시스템을 디버깅하는 것과 비슷합니다 — 어렵고, 비결정적이고, 재현하기 어렵습니다. 아직 성숙한 툴링이 없습니다.
그럼에도 방향은 분명합니다. Park et al. (2023)의 **"Generative Agents: Interactive Simulacra of Human Behavior"**에서 25개의 AI 에이전트가 가상 마을에서 서로 대화하고 기억하고 계획을 세우는 실험을 했습니다. 에이전트 간 창발적 행동(emergent behavior)이 관찰됐습니다 — 소문이 퍼지고, 파티가 조직되고, 관계가 형성됐습니다. 연구 수준에서는 이미 흥미로운 것들이 나오고 있습니다.
결론
재귀적 멀티에이전트 시스템은 단일 LLM의 구조적 한계를 넘어서는 현실적인 접근입니다. 컨텍스트 격리, 병렬 실행, 상호 검증이라는 세 가지 이점이 명확합니다.
다만 비용, 신뢰성, 디버깅 복잡도라는 현실적 비용이 있습니다. 지금 시점에서 무조건 멀티에이전트를 쓰는 게 답은 아닙니다. 작업 규모가 단일 에이전트 컨텍스트를 넘어설 때, 병렬 처리가 실질적인 시간 단축을 줄 때, 독립적인 검증이 필요할 때 — 이 세 조건 중 하나 이상에 해당할 때 도입을 검토하는 것이 맞습니다.
실험하고 싶다면 Claude Code의 Agent 툴이 가장 진입 장벽이 낮습니다. 추가 설치 없이 바로 써볼 수 있습니다. 복잡한 상태 관리가 필요해지면 LangGraph, 팀 역할 기반 추상화가 편하다면 CrewAI나 AutoGen으로 확장하면 됩니다.
참고 자료
- Yao et al. (2022). ReAct: Synergizing Reasoning and Acting in Language Models. arXiv:2210.03629
- Wang et al. (2022). Self-Consistency Improves Chain of Thought Reasoning in Language Models. arXiv:2203.11171
- Wu et al. (2023). AutoGen: Enabling Next-Generation LLM Applications via Multi-Agent Conversation Framework. arXiv:2308.08155
- Du et al. (2023). Improving Factuality and Reasoning in Language Models through Multiagent Debate. arXiv:2305.14325
- Park et al. (2023). Generative Agents: Interactive Simulacra of Human Behavior. arXiv:2304.03442
- Liu et al. (2023). Lost in the Middle: How Language Models Use Long Contexts. arXiv:2307.03172
- Shen et al. (2023). HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face. arXiv:2303.17580
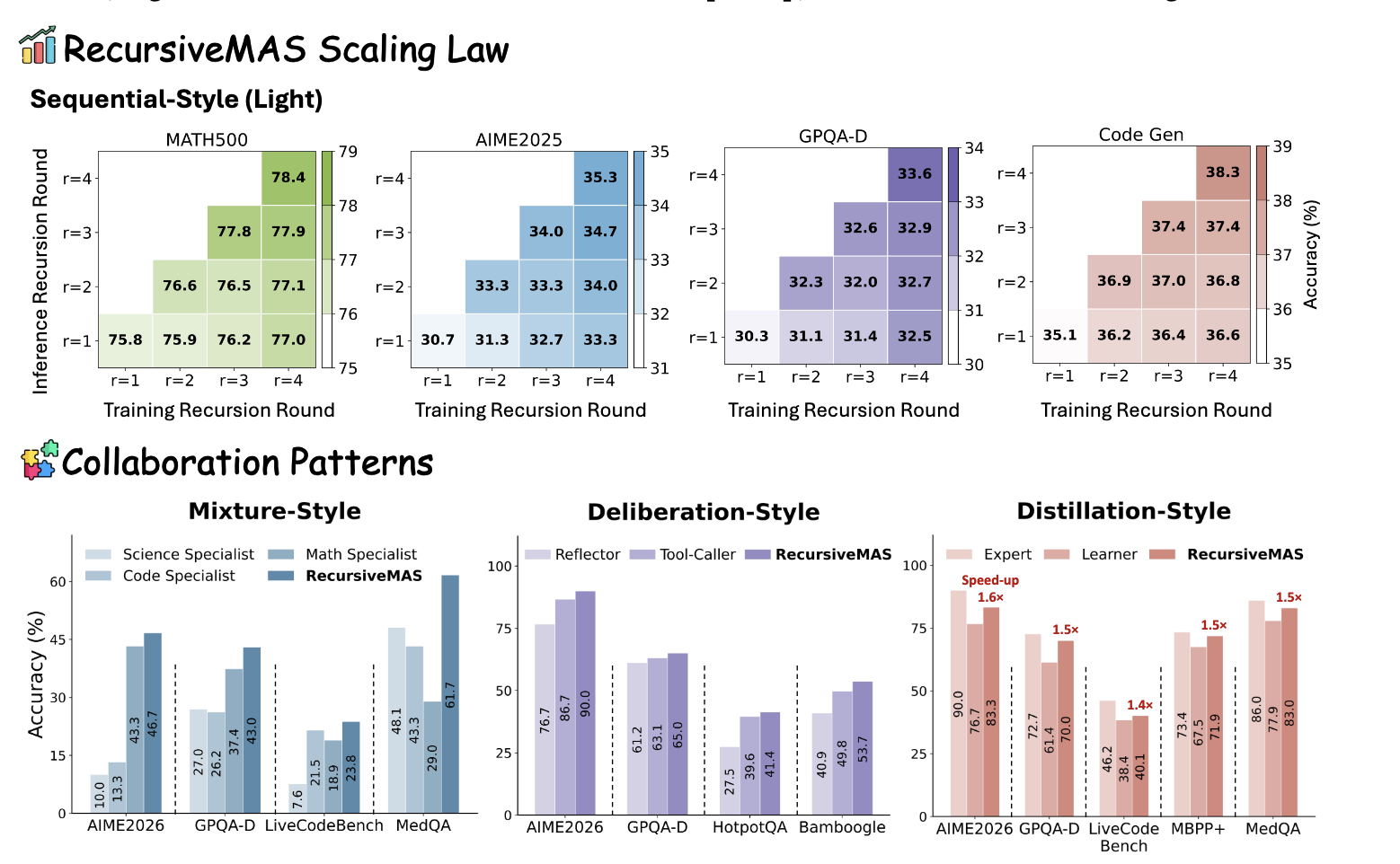
실무에서 어떻게 쓰이나
"AI 에이전트를 여러 개 쓰면 더 좋아지는가"라는 질문에 대한 가장 정직한 답이 이 논문에 있습니다.
언제 멀티에이전트가 유리한가. 단일 에이전트는 긴 컨텍스트를 유지하다 품질이 떨어집니다. 재귀적 분해는 각 서브에이전트가 좁은 범위에 집중하게 해서 이 문제를 구조적으로 회피합니다. 코드 작성→리뷰→테스트를 각각 다른 에이전트에 맡기는 파이프라인이 대표적인 사례입니다.
오케스트레이터 설계가 핵심. 재귀 시스템의 품질은 작업을 쪼개는 상위 에이전트(오케스트레이터)의 분해 전략에 달려 있습니다. 실무에서 "멀티에이전트를 썼는데 왜 더 나쁘지"라는 경우는 대부분 오케스트레이터의 지시가 모호해서 서브에이전트가 제각각 방향으로 움직이는 경우입니다.
Claude Code, AutoGen, LangGraph 등 현재 도구들. 이 논문의 구조가 현재 에이전트 프레임워크 대부분의 기반입니다. 도구를 쓸 때 "이 도구는 오케스트레이터와 실행 에이전트를 어떻게 분리하는가"를 물어보면 설계 의도가 바로 보입니다.