SpatialWorld - Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks
H. Gao, H. Qu, J. Tang, Z. Huang, ..., N. Duan, and Y. Dong, "SpatialWorld: Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks," arXiv:2606.09669, 2026.
멀티모달 모델에게 사진 한 장을 주고 "냉장고가 식탁 왼쪽에 있나요?"라고 물으면 곧잘 맞힙니다. 그런데 "부엌에 가서 식탁 위 컵을 싱크대에 옮겨주세요"라고 시키면 이야기가 완전히 달라집니다. 모델은 한 장면을 한 번에 다 볼 수 없습니다. 직접 돌아다니며 시야를 갱신하고, 어디까지 왔는지 기억하고, 다음에 무엇을 할지 계획해야 합니다. 이 능력을 그동안의 벤치마크는 거의 측정하지 못했습니다.
SpatialWorld는 바로 이 빈자리를 노립니다. 정적인 질의응답이 아니라 "상호작용하며 공간을 이해하는" 능력을, 서로 다른 8개의 3D 시뮬레이터를 하나의 인터페이스로 묶어 760개 과제로 측정합니다. 그리고 그 결과는 꽤 충격적입니다.
저자
이 논문은 칭화대를 축으로 충칭대, 베이징대 등 중국 여러 대학과 산업 랩이 함께 만든 작업입니다. 저자가 20명을 넘습니다.
공동 1저자는 가오훙청와 Hailong Qu입니다. 가오훙청는 칭화대 College of AI에서 대규모 추론 모델과 멀티모달 에이전트를 연구하는데, 이미 NeurIPS 2024의 Spider2-V 공저자로 "현 세대 에이전트가 실제 작업을 얼마나 못 해내는지"를 정량화한 이력이 있습니다. 그때의 문제의식이 공간 과제로 옮겨온 셈입니다.
교신저자는 둥인펑입니다. 그는 칭화대에서 머신러닝의 적대적 견고성과 신뢰가능 AI를 파 온 연구자입니다. "모델이 어디서 무너지는가"를 집요하게 들여다보는 견고성 연구자의 시선은, 화려한 데모 뒤에 가려진 공간지능의 결손을 드러내려는 이 벤치마크의 설계 철학과 잘 맞습니다.
데이터셋의 무게를 떠받치는 시니어로 장원타오(베이징대 머신러닝연구센터, 데이터 중심 AI 그룹)과 두안난(언어를 넘어 비전·체화 AI까지 파운데이션 모델을 넓혀 온 시니어 연구자)이 합류했습니다. 760개 과제를 사람 손으로 깔고 교차검증으로 다듬는 작업이라, 데이터 품질을 전공한 연구자가 들어온 구성이 자연스럽습니다.
배경
공간추론은 멀티모달 모델이 물리 세계를 인식하고 그 안에서 행동하기 위한 기초 능력입니다. 그런데 기존 벤치마크는 크게 두 갈래였고, 둘 다 한계가 분명했습니다.
첫째는 정적 평가입니다. 이미지 한 장이나 미리 녹화된 영상을 주고 객체 위치, 공간 관계를 묻는 VQA 방식입니다. 장면을 한 번에 다 보여주기 때문에 "능동적으로 탐색해서 정보를 모은다"는 핵심이 빠집니다. 실제 물리 공간은 부분적으로만 관측됩니다(partially observable). 한 시점에서 모든 정보를 얻을 수 없으니, 에이전트는 직접 이동해 점진적으로 시각 증거를 모으고 공간에 대한 믿음을 갱신해야 합니다.
둘째는 체화(embodied) 벤치마크입니다. 상호작용은 되지만 특정 시뮬레이터에 깊게 묶여 있습니다. 센서 가정, 액션 인터페이스, 실행 파이프라인이 백엔드마다 제각각이라, 성공이 "진짜 공간추론" 덕분인지 "그 시뮬레이터에 적응한" 덕분인지 구분하기 어렵습니다. 게다가 관절 각도나 객체 목록 같은 특권적 상태 정보(privileged state)를 시각 입력과 함께 넣어주는 경우가 많습니다.
SpatialWorld는 다른 질문을 던집니다. 특정 시뮬레이터용으로 학습하지 않은 범용 멀티모달 모델이, 1인칭 시각 관측과 언어 기반 고수준 결정만으로, 서로 다른 3D 환경들에서 폐루프(closed-loop) 상호작용으로 과제를 풀 수 있는가. 아래 비교표가 이 논문의 위치를 한눈에 보여줍니다. 통합 인터페이스, 상호작용성, 1인칭 관측, 비전 전용 입력, 언어형 출력의 다섯 속성을 모두 만족하는 것은 SpatialWorld뿐입니다.
유형 |
벤치마크 |
통합 인터페이스 |
상호작용 |
1인칭 |
비전 전용 |
언어형 출력 |
|---|---|---|---|---|---|---|
ImageQA |
SpatialScore, 3DSRBench 등 |
✘ |
✘ |
일부 |
✓ |
✓ |
VideoQA |
VSI-Bench, SITE |
✘ |
✘ |
일부 |
✓ |
✓ |
Embodied |
ALFRED, VLABench |
✘ |
✓ |
✓ |
일부 |
✘ |
본 논문 |
SpatialWorld |
✓ |
✓ |
✓ |
✓ |
✓ |
어떻게 만들었나
핵심은 "서로 다른 시뮬레이터를 어떻게 하나의 잣대로 묶었는가"입니다. SpatialWorld는 환경 실행과 에이전트 의사결정을 분리하는 모듈형 구조를 씁니다. 환경/검증 인터페이스가 과제 초기화와 성공 판정을 담당하고, 그 사이를 관측·액션 인터페이스라는 표준 입출력 병목이 잇습니다.
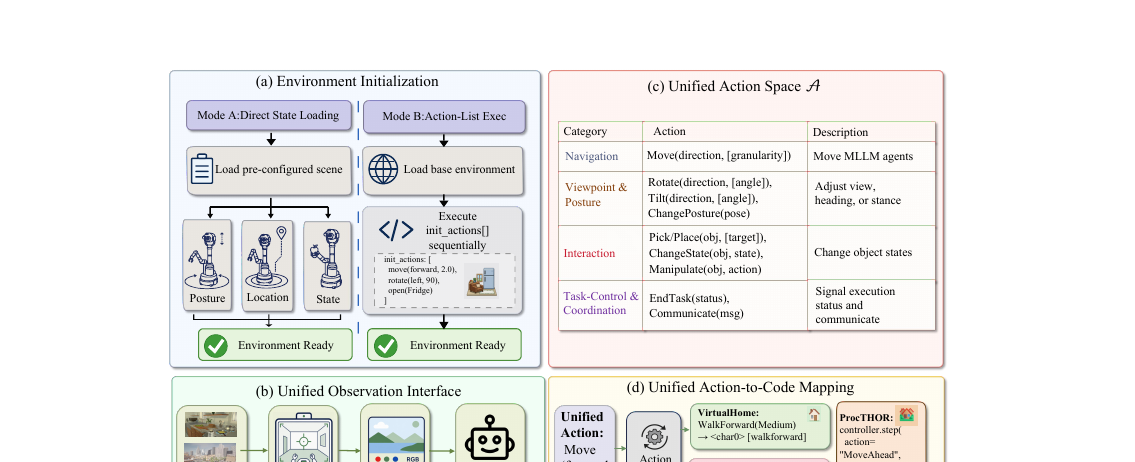
먼저 과제를 부분관측 마르코프 결정과정(POMDP) \(\langle S, O, A, T, \Omega, R \rangle\)으로 정식화합니다. 매 스텝 \(t\)에서 에이전트는 자연어 목표 \(g\)와 1인칭 RGB 관측 \(o_t\)만 받습니다. 깊이 맵이나 전역 지도 같은 특권 신호는 없습니다. 궤적 이력 \(H_t = (o_1, a_1, \dots, o_t)\)를 보고 정책 \(\pi_\theta\)가 다음 고수준 액션 \(a_t \sim \pi_\theta(a_t \mid H_t, g)\)를 내면, 시뮬레이터가 그 액션을 실행해 숨은 상태를 전이시키고 다음 관측 \(o_{t+1}\)을 렌더링합니다. 이 과정이 EndTask를 부르거나 스텝 예산이 떨어질 때까지 반복됩니다.
관측 공간은 시뮬레이터 원본 해상도의 1인칭 RGB 스크린샷 한 장뿐입니다. 깊이·광류·세그멘테이션·점유 격자 같은 보조 모달리티는 일절 주지 않습니다. 이 비전 전용 제약이 VLA 계열 벤치마크와의 가장 큰 차별점입니다.
액션 공간은 저수준 연속 명령(관절 토크, 속도 벡터) 대신, 이종 백엔드를 공통 기호 인터페이스 뒤로 추상화한 고수준 액션입니다. 네 범주로 나뉩니다.
- Navigation: Move(방향, 입자도)
- Viewpoint & Posture: Rotate, Tilt, ChangePosture
- Interaction: Pick/Place, ChangeState, Manipulate
- Task-Control & Coordination: EndTask(status), Communicate(msg)
이 통합 액션을 액션-투-코드 매핑이 시뮬레이터별 실제 호출로 번역합니다. 같은 Move(forward, medium)이 VirtualHome에서는 WalkForward(Medium), ProcTHOR에서는 MoveAhead(moveMagnitude=0.5), CARLA에서는 차량 제어 호출이 됩니다. 하나의 에이전트 정책이 코드 수정 없이 8개 환경을 모두 돌 수 있는 이유입니다. 이렇게 하면 두 가지 이득이 있습니다. 추가 파인튜닝 없이 기성 모델을 바로 평가할 수 있고, 의사결정의 부산물로 언어 기반 추론 흔적(chain-of-thought)이 자연스럽게 남습니다.
평가는 OSWorld·Spider2-V를 따라 궤적 일치가 아니라 종료 상태 검증(terminal-state verification)으로 합니다. 정해진 행동 순서를 똑같이 밟았는지가 아니라, 마지막에 목표 상태에 도달했는지만 봅니다. 자율 에이전트의 개방형 탐색을 인정하는 방식입니다. 주 지표는 과제 성공률(TSR)입니다.
\[\text{TSR} = \frac{1}{N}\sum_{i=1}^{N} \mathbb{1}\!\left[V_i\!\left(s_T^{(i)}\right) = 1\right]\]
성공만으로는 부족합니다. 같은 목표를 도달하더라도 헤매며 도달했는지, 깔끔하게 도달했는지가 다릅니다. 그래서 스텝 효율(SE)을 함께 봅니다. 성공한 과제 집합 \(S\)에 대해, 사람이 주석한 기준 길이 \(n_i^*\)를 에이전트의 실제 스텝 수 \(n_i\)로 나눈 값입니다. 높을수록 효율적입니다.
\[\text{SE} = \frac{1}{|S|}\sum_{i \in S} \frac{n_i^*}{n_i}\]
데이터는 환경 수집 → 어노테이터 튜토리얼 학습 → 지시문 작성 → 성공 조건 정의 → 자동 실행 검증 + 사람 교차검증의 파이프라인으로 쌓았습니다. 과제마다 세 단계를 거칩니다. (i) 어노테이터가 자연어 지시와 초기 상태를 설계하고, (ii) 훈련된 어노테이터가 직접 시뮬레이터에서 과제를 풀어 정답 종료 상태와 기준 행동 순서를 기록하고, (iii) 별도 검토자가 과제 타당성·지시 명확성·평가 스크립트 정확성을 교차 점검합니다.
무엇으로 구성돼 있나
SpatialWorld는 760개 과제를 두 축으로 분류합니다.
시나리오 범주는 물리(physical)와 디지털(digital)로 갈립니다. 물리 쪽은 일상 가사, 공부·업무, 엔터테인먼트, 여행 내비게이션, 사회적 협업의 다섯이고, 디지털 쪽은 3D 게임(Block3D, Snake3D, 루빅스 큐브 등)입니다. 게임을 따로 둔 이유가 흥미롭습니다. 사실적 시뮬레이터는 난이도가 사진 같은 시각 의미·자연 장면 사전지식과 뒤엉켜 있습니다. 게임은 그 시각적 지름길을 걷어내고 순수한 기하 추론·위상 추론만 남기는 통제된 탐침 역할을 합니다.
환경은 8개 백엔드를 세 갈래로 묶었습니다. 실내(AI2-THOR, ProcTHOR, VirtualHome), 실외(CARLA, EmbodiedCity), 그리고 멀티에이전트 변형(Multi-AI2THOR, Multi-ProcTHOR)과 디지털 게임입니다. 과제 분포는 일상 가사가 350개로 가장 많고, 엔터테인먼트 173개, 여행 132개, 업무 59개, 사회적 협업 46개 순입니다.
복잡도 수준은 세 가지입니다. Navigation(목표 위치·객체에 도달, 상태 변경 없음), Interaction(집기·놓기·열기·토글 같은 객체 상태 변경, 긴 탐색 없음), 그리고 Navigation-Interaction(둘 다, 즉 긴 탐색과 정밀 조작의 결합)입니다. 마지막 결합 모드가 진짜 난관입니다.
결과
15개 최신 멀티모달 모델을 풀 벤치마크에 돌린 결과가 아래 표입니다. 모든 모델은 파인튜닝 없이 공식 API나 오픈웨이트 체크포인트로 평가했고, 온도 \(\tau = 1.0\), 이력 창 \(w = 30\)턴, 스텝 예산 \(2g + 10\)(g는 사람이 매긴 정답 행동 수)을 썼습니다.
모델 |
일상 |
업무 |
엔터(물리) |
여행 |
사회 |
물리 종합 |
디지털 |
|---|---|---|---|---|---|---|---|
Qwen2.5-VL-72B |
3.7 |
8.5 |
2.9 |
0.8 |
2.2 |
3.4 |
7.6 |
Qwen3-VL-235B-Instruct |
6.9 |
8.5 |
7.4 |
4.5 |
10.9 |
6.9 |
5.0 |
Qwen3-VL-235B-Thinking |
5.7 |
8.5 |
7.4 |
3.8 |
10.9 |
6.1 |
28.3 |
Qwen-3.5-397B-A17B |
13.1 |
16.9 |
13.2 |
4.5 |
19.6 |
12.2 |
26.0 |
GLM-4.5V |
3.7 |
3.4 |
4.4 |
1.5 |
13.0 |
4.0 |
14.5 |
Kimi-K2.5 |
11.1 |
8.5 |
4.4 |
3.8 |
17.4 |
9.2 |
31.0 |
Gemini-2.5-Pro |
7.4 |
11.9 |
1.5 |
3.8 |
10.9 |
6.7 |
32.6 |
Gemini-3-Flash |
8.0 |
10.2 |
4.4 |
6.1 |
4.3 |
7.2 |
38.1 |
Gemini-3.1-Pro |
11.4 |
10.2 |
5.9 |
4.5 |
8.7 |
9.2 |
39.0 |
GPT-5 |
14.9 |
16.9 |
10.3 |
6.8 |
34.8 |
14.4 |
36.4 |
GPT-5.4 |
8.0 |
5.1 |
5.9 |
3.8 |
6.5 |
6.6 |
11.9 |
Doubao-2.0-Lite |
5.7 |
6.8 |
5.9 |
3.0 |
13.0 |
5.8 |
24.8 |
(지면상 일부 모델은 생략. 수치는 TSR(%), 굵게는 열별 최고.)
표에서 가장 먼저 눈에 들어오는 건 절대 수치의 처참함입니다. 최강 GPT-5의 물리 종합 TSR이 14.4%, 디지털까지 합한 평균이 17.4%입니다. 최강 오픈소스 Qwen-3.5-397B-A17B는 물리 종합 12.2%, 평균 14.1%입니다. 정적 장면 인식은 잘하는 모델들이, 동적인 물리 환경에 들어가는 순간 대부분 실패한다는 뜻입니다. 그나마 성공하는 과제도 "기기 하나 켜기" 같은 짧은 단발성 조작에 몰려 있습니다.
여기서 숫자 하나를 짚고 가야 합니다. 초록과 서론은 GPT-5의 평균 TSR을 17.4%로 적지만, 본문 §3.2는 물리 종합 TSR을 14.4%로 적습니다. 둘은 다른 수치입니다. 17.4%는 디지털 게임까지 포함한 전체 평균이고, 14.4%는 물리 과제만 가중평균한 값입니다. 물리 세계만 따지면 더 낮습니다.
둘째 발견은 성공률과 효율의 불일치입니다. TSR이 비슷한 모델끼리는 SE가 갈립니다. Kimi-K2.5와 GPT-5.4는 물리 종합 TSR이 9.2% 대 6.6%로 엇비슷하지만, SE는 GPT-5.4가 0.569로 Kimi-K2.5의 0.486보다 높습니다. Kimi-K2.5가 같은 목표를 더 많은 시행착오, 더 많은 헛수고 행동으로 도달한다는 뜻입니다.
셋째, 한 모델이 모든 도메인을 지배하지 않습니다. GPT-5가 일상·여행·사회적 협업을 이끌고, Qwen-3.5는 업무에서 GPT-5와 동률이며 물리 엔터테인먼트를 앞섭니다. 디지털 게임에서는 Gemini-3.1-Pro가 39.0%로 최고입니다. 단일 점수 하나로 줄 세우는 리더보드로는 못 잡는 다면적 능력 차이가 드러납니다.
복잡도 모드로 쪼개면 병목이 선명합니다.
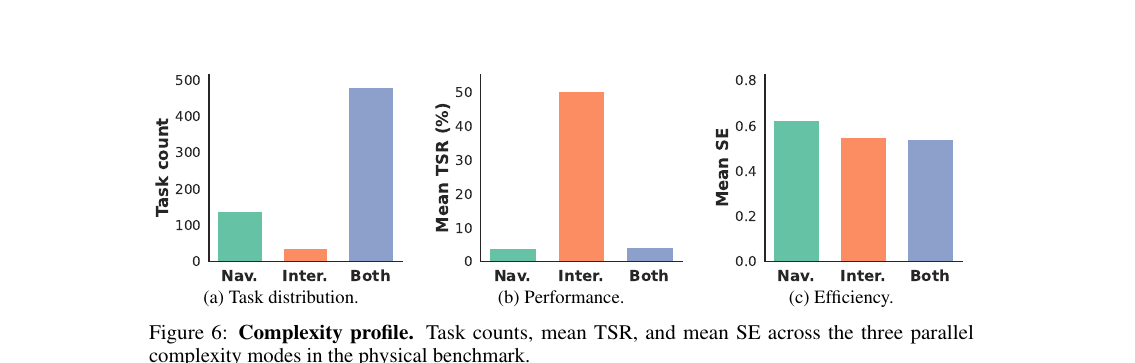
Interaction 단독 과제는 평균 TSR 50.2%로 그럭저럭 풀립니다. 그런데 긴 탐색과 정밀 조작을 결합한 Navigation-Interaction 과제는 4.2%로 곤두박질칩니다. 정작 760개 중 다수가 이 결합 모드입니다. 모드별로 강한 모델도 다릅니다. GPT-5는 Interaction에서 69.4%로 압도하고 결합 모드에서도 12.1%로 앞서는 반면, 내비게이션은 Gemini 계열이 8.6%로 이끕니다. 능력이 단일한 난이도 축이 아니라 직교하는 여러 축으로 갈린다는 증거입니다.
실내와 실외도 갈립니다. 실내는 GPT-5(14.1%)와 Qwen-3.5(13.7%)가 앞서는데, 실외 내비게이션에서는 Gemini-3-Flash(9.0%)와 GPT-5(8.3%)가 앞섭니다. GPT-5의 실내 강세는 정밀한 객체 접지와 저수준 제어를, Gemini의 실외 강세는 장기 공간추론과 거시 내비게이션을 시사합니다. 사회적 협업도 마찬가지입니다. GPT-5가 통합 34.8%로 최고지만, 대부분 손으로 짠 Multi-AI2THOR 레이아웃에서 나온 점수입니다. 절차적으로 생성된 Multi-ProcTHOR에서는 최고 모델조차 5.9%에 머뭅니다.
지각 설정의 영향도 따로 검증했습니다. 해상도를 바꿔도 성능 곡선이 거의 평평합니다. 이미지 해상도가 상호작용형 공간이해에 별 영향을 주지 않는다는 뜻입니다. 시야각(FOV)은 넓을수록 대체로 낫지만 이득이 금세 정체되고, 저자들은 사람의 1인칭 시야에 가깝도록 기본값 60도를 유지합니다.
회고
이 논문에서 가장 흥미로운 발견은 부록에 숨어 있습니다. 더 최신 모델인 GPT-5.4가 구형 GPT-5보다 못합니다. 왜일까요.
두 모델이 모두 시도한 공통 과제에서 GPT-5는 78개(12.8%)를 풀었고 GPT-5.4는 40개(6.6%)에 그쳤습니다. GPT-5가 GPT-5.4보다 더 푼 과제가 52개인데, 반대 방향은 14개뿐이라 비대칭도 큽니다. 원인은 행동 속도가 아니라 종료 정책에 있었습니다.
GPT-5.4는 너무 일찍 멈춥니다. 실패의 32.4%가 성급한 DONE 선언이고 48.5%가 명시적 FAIL 선언입니다. 반면 GPT-5는 끝까지 버팁니다. 실패의 63.6%가 스텝 한계 도달이고 15.1%가 반복된 행동 실패 끝의 종료입니다. 행동 수에도 그대로 드러납니다. 성공한 과제에서 GPT-5는 중앙값 7스텝을, GPT-5.4는 3.5스텝을 씁니다. 실패한 과제에서는 각각 22스텝과 11스텝입니다. GPT-5는 느리고 비효율적이지만, 검증 조건이 실제로 충족될 때까지 계속 탐색하려 듭니다. GPT-5.4는 상태가 충분히 확인되기도 전에 조급하게 종료 결정을 내립니다.
신형이 구형을 못 이기는 이 역전은 시사하는 바가 큽니다. 모델을 더 효율적이고 결단력 있게 만드는 방향이, 끈질긴 탐색이 필요한 공간 과제에서는 오히려 독이 될 수 있다는 것입니다.
저자들은 실패한 궤적 100개를 손으로 뜯어보고 네 가지 실패 유형으로 정리했습니다.
- 공간적 방향 상실(Spatial Disorientation): 자기 위치를 잃고 목표로 돌아가지 못함
- 객체 환각(Object Hallucination): 현재 시야에 없는 객체에 상호작용 명령을 내림
- 성급한 종료(Premature Termination): 목표가 충족되기 전에 EndTask를 부름
- 행동 루프(Action Loop): 효과 없는 같은 행동 순서를 예산이 소진될 때까지 반복
이 네 가지가 현 세대 멀티모달 에이전트가 물리 공간에서 무너지는 전형적인 방식입니다.
정리
- SpatialWorld는 정적 VQA를 넘어, 8개 시뮬레이터를 하나의 텍스트 액션 인터페이스로 묶어 760개 과제로 멀티모달 에이전트의 능동적 공간추론을 측정합니다. 통합·상호작용·1인칭·비전 전용·언어형 출력을 모두 만족하는 첫 벤치마크입니다.
- 결과는 냉정합니다. 최강 GPT-5도 평균 17.4%, 물리만 따지면 14.4%입니다. 긴 탐색과 조작을 결합한 과제는 4.2%까지 떨어집니다. 능동 탐색과 장기 계획이 현 세대의 핵심 병목입니다.
- 더 최신인 GPT-5.4가 조급하게 멈춰 구형 GPT-5에 뒤진 사례는, 효율과 결단을 키우는 흔한 최적화 방향이 공간 과제에서는 역효과를 낼 수 있음을 보여줍니다. 끈기 있는 탐색을 어떻게 학습시킬지가 다음 숙제입니다.