Self-Manager - Parallel Agent Loop for Long-form Deep Research
Y. Xu, Z. Zheng, X. Long, Y. Cai, and Y. Wang, "Self-Manager: Parallel Agent Loop for Long-form Deep Research," arXiv:2601.17879, 2026.
저자
1저자 쉬이룽는 중국과학원 컴퓨팅기술연구소(CAS ICT) 박사과정이고 ModelBest Inc.에서 인턴으로 모델 연구를 병행합니다. 그동안 retrieval-augmented LLM 라인을 따라 인용 평가(Aliice), utility-based retriever 학습, agentic search 평가(Ravine)를 차곡차곡 쌓아왔습니다. Self-Manager는 그 라인의 자연스러운 다음 칸으로, 검색을 잘하는 에이전트에서 복수의 검색 줄기를 동시에 굴리는 에이전트로 한 단계 더 올린 것입니다.
시니어 저자는 UC Merced NLP Lab을 이끄는 왕이웨이입니다. 분할 정복으로 LLM을 제어하는 라인을 EMNLP 2024부터 진행했고, 컨텍스트 충실성 정렬(Context-DPO)을 ACL 2025에 발표했습니다. Self-Manager의 thread 격리 컨텍스트 관리도 "control" 키워드의 연장으로 읽힙니다.
공저자 차이위쥔는 University of Queensland 강사로, Meta Research Scientist 이력을 가진 멀티모달 연구자입니다. 같은 Queensland 그룹의 Xiang Long과 함께 평가·실험 설계 쪽으로 합류한 것으로 보입니다. Zhi Zheng은 ModelBest의 MiniCPM 라인 공저자로, 1저자의 ModelBest 라인 쪽 멘토 역할로 추정됩니다.
다섯 명을 한 줄로 묶으면 retrieval-기반 LLM 그룹 + control-기반 LLM 그룹 + 멀티모달 평가 그룹의 교집합입니다. agentic search라는 키워드가 이 셋을 한 자리에 모은 것에 가깝습니다.
배경
LLM 에이전트가 처음으로 정착한 패턴은 ReAct의 "Think-Act-Observe"입니다. 한 스레드가 한 컨텍스트 안에서 생각하고 도구를 부르고 관측하기를 반복하죠. 깔끔하지만 두 가지 한계가 있습니다.
첫째, 컨텍스트가 선형으로 누적됩니다. 매 턴 관측이 들어오면 컨텍스트가 길어지고, 결국 모델의 컨텍스트 윈도우 한계에 부딪칩니다. Deep research처럼 수십 번의 검색·읽기·종합을 거치는 작업에서는 이게 일찍 터집니다.
둘째, 하나의 컨텍스트 안에 모든 정보가 섞입니다. "Lost in the Middle" 류 연구가 보여주듯, 길어진 컨텍스트에서 중요한 정보가 희석됩니다. 더 큰 문제는 서브태스크 간 간섭으로, A 서브태스크의 관측이 B 서브태스크의 추론에 노이즈로 작용한다는 점입니다.
선행 연구는 두 가지 우회로를 시도했습니다. (1) 컨텍스트가 한계에 다다르면 요약·압축으로 줄이는 ReSum 계열. 정보 손실이 잘 일어납니다. (2) 서브태스크 경계에서 컨텍스트를 접는 FoldAgent 계열. 동일 컨텍스트 윈도우를 공유하기 때문에 서브태스크가 동시에 못 굴러갑니다(synchronous, blocking).
Self-Manager는 서브태스크가 자기 컨텍스트를 가지고 비동기·병렬로 실행 되는 방향을 잡습니다. 본 스레드는 ReAct의 "Think-Act-Observe" 루프를 유지하되, "Act" 의 한 선택지로 서브스레드 생성·종료·삭제가 추가됩니다.
어떻게 동작하나
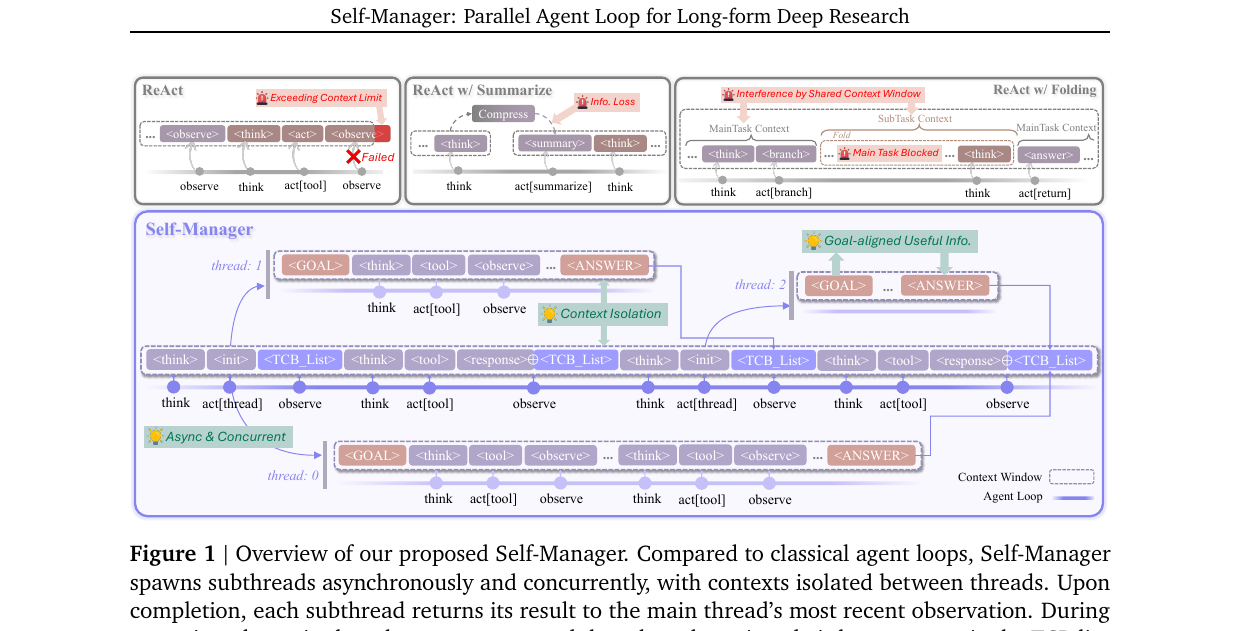
본 논문의 Figure 1이 전체 구조를 보여줍니다. 위쪽 ReAct, ReAct w/ Summarize, ReAct w/ Folding 세 종류의 단일 스레드 루프가 각각의 한계(컨텍스트 초과, 정보 손실, 메인 블로킹)에 부딪히는 모습이 왼쪽 위에 모여 있고, 아래쪽 Self-Manager는 메인 스레드가 별도의 서브스레드 두 개를 spawn 해서 자기 컨텍스트만 보고 작업한 다음 결과를 메인 컨텍스트로 돌려보내는 흐름입니다.
표기상 메인 스레드의 trajectory는 다음과 같습니다.
\[\tau_{\text{main}} = \left(\, (a_t, o_t)_{t=1}^{T}, \mathcal{A} \,\right), \; h_{\text{main}}\]
여기서 \(a_t\)는 t턴의 행동(도구 호출 또는 서브스레드 조작), \(o_t\)는 관측, \(\mathcal{A}\)는 최종 답, \(h_{\text{main}}\)은 메인 컨텍스트입니다. 서브스레드 \(i\)의 trajectory도 같은 모양이지만 격리된 컨텍스트 \(h_{\text{sub}}^{(i)}\)를 가집니다.
\[\left\{\, \tau_{\text{sub}}^{(i)} = \left(\, (a_t^{(i)}, o_t^{(i)})_{t=1}^{T^{(i)}}, \mathcal{A}^{(i)}, h_{\text{sub}}^{(i)} \,\right) \,\right\}_{i=1}^{N}\]
메인 스레드가 새로 도입하는 행동은 세 가지입니다. branch(서브스레드 생성), kill(러닝 중인 서브스레드 강제 종료), delete(완료된 서브스레드 정보를 TCB 리스트에서 제거). 이 외에 검색·방문 같은 일반 도구 호출과 sleep(서브스레드 결과를 기다림)이 있습니다.
Thread Control Block
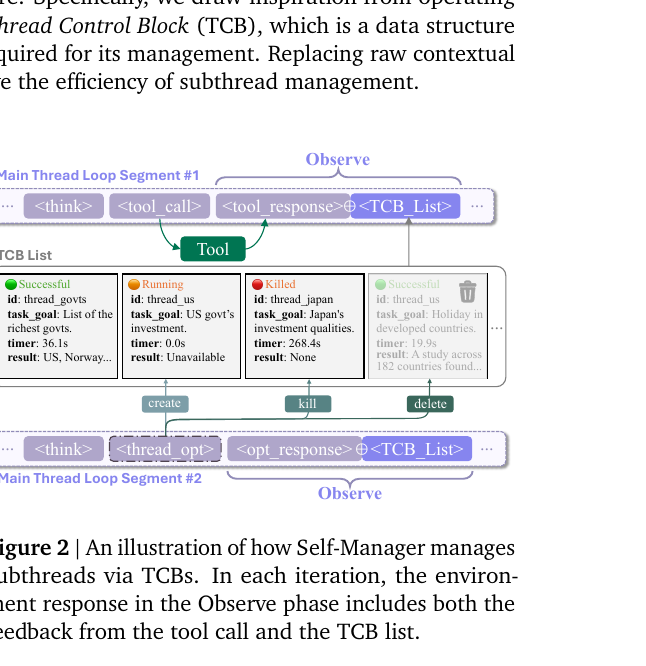
핵심 자료 구조는 운영체제에서 빌려온 Thread Control Block(TCB)입니다. 메인 스레드가 "Observe" 단계에서 받는 정보 안에 TCB 리스트가 들어 있고, 메인 스레드는 이걸 보고 다음 행동을 결정합니다.
각 TCB가 보유하는 필드는 다음과 같습니다.
id: 서브스레드 식별자 (Thread_US,Thread_japan같은 이름)goal: 메인이 부여한 서브태스크 목표state:running/successful/failed/killedallowed_tools: 메인이 이 서브스레드에 허용한 도구 목록prefix_context: 메인이 넘겨주는 prefix 컨텍스트 (선택)extra_info: 메인이 남기는 추가 메모start_time: 시작 시각 (경과 시간 추적용)result: 완료 후 결과
OS의 TCB와 다른 점은, 낮은 레벨의 자원 포인터·레지스터 같은 항목을 다 뺐다는 것입니다. LLM 에이전트가 직접 들여다볼 의미가 없는 필드는 들어가 있지 않습니다.
또 한 가지 영리한 디테일은 TCB 리스트가 매 턴 새로 만들어진다는 것입니다. 다음 턴이 시작되면 이전 TCB 리스트를 컨텍스트에서 비워, 메인 컨텍스트가 TCB 누적으로 늘어나는 것을 막습니다. 그 결과 메인 스레드의 컨텍스트는 선형이 아니라 간헐적으로 비워지는 짧은 컨텍스트 가됩니다.
비동기성과 동시성
서브스레드가 생성되면 메인은 블로킹되지 않습니다. 메인은 다른 도구를 부르거나, 다른 서브스레드를 또 spawn 하거나, 자기 추론을 이어갈 수 있습니다. 메인이 모델 생성을 요청하는 동안에만 블로킹이 일어나고, 그 시간 사이에 다른 스레드들이 자기 모델 호출을 끝낼 수 있어 자연스럽게 컨텍스트 스위칭이됩니다.
동시성은 메인이 한 턴에 여러 서브스레드를 동시에 spawn 할 수 있다는 점에서 옵니다. "한 문제의 여러 측면을 병렬로 탐색" 하는 패턴이죠.
결과
DeepResearch Bench(100개의 장문 deep research 과제) 위에서 RACE와 FACT 두 메트릭으로 평가합니다. RACE는 종합·통찰·지시 충실·가독성 네 축, FACT는 정확도와 효율을 봅니다. 모두 Gemini-2.5-Flash를 LLM-as-Judge로 사용합니다.
메인 비교
모델 |
Overall |
Comp. |
Insight |
Inst. |
Read. |
C.acc. |
Eff.c. |
|---|---|---|---|---|---|---|---|
Single Agent |
|||||||
ReAct (Qwen3-30B-A3B) |
40.51 |
39.15 |
37.71 |
43.98 |
43.40 |
21.69 |
1.36 |
ReSum (Qwen3-30B-A3B) |
42.77 |
41.34 |
40.09 |
46.82 |
45.15 |
32.72 |
2.33 |
FoldAgent (Qwen3-30B-A3B) |
41.79 |
40.04 |
38.95 |
46.22 |
43.97 |
19.61 |
1.56 |
Self-Manager (Qwen3-30B-A3B) |
44.33 |
43.14 |
42.28 |
47.61 |
45.97 |
25.49 |
2.19 |
Multi-Agent Workflow |
|||||||
LangChain-open-DeepResearch |
43.89 |
43.61 |
42.19 |
47.30 |
45.07 |
53.52 |
31.17 |
AI-Q NVIDIA Research Assistant |
43.69 |
42.07 |
42.76 |
46.15 |
45.14 |
— |
— |
Proprietary |
|||||||
Gemini-2.5-Pro Deep Research |
48.24 |
48.24 |
47.62 |
48.74 |
48.97 |
85.71 |
27.0 |
OpenAI DeepResearch |
47.20 |
47.07 |
45.84 |
48.98 |
47.64 |
65.30 |
34.15 |
같은 베이스 모델(Qwen3-30B-A3B) 안에서 Self-Manager가 모든 단일 에이전트 베이스라인을 RACE 네 축 전부에서 이깁니다. ReSum과 FoldAgent가 약 41~43 사이에서 정체하는 데 비해, Self-Manager는 44.33으로 한 칸 위로 올라갑니다.
흥미로운 점은 Self-Manager가 멀티 에이전트 워크플로우(LangChain, NVIDIA)와도 같은 줄에 선다 는 점입니다. 단일 에이전트 패러다임이 사전 정의된 워크플로 없이도 유사한 성능을 낸다는 것이 본 논문의 핵심 주장입니다. 다만 Proprietary 시스템(Gemini Deep Research, OpenAI DeepResearch)과는 여전히 3~5점 차가 납니다.
베이스 모델을 키우면 점수가 함께 오릅니다. Qwen3-Next-80B-A3B로 갈아끼우면 Overall 45.63까지 올라가며, 작은 Qwen3-8B로 내려도 43.88로 ReSum·FoldAgent 30B 베이스라인을 이깁니다. Self-Manager 구조 자체가 모델 크기와 함께 잘 스케일됩니다.
정보 보존과 컨텍스트 효율
정보 손실 메트릭은 다음과 같이 정의됩니다.
\[\mathcal{L}_{\text{info}} = 1 - \frac{|\mathcal{I}_j \cap \tilde{\mathcal{I}}_j|}{|\mathcal{I}_j|}\]
여기서 \(\mathcal{I}_j\)와 \(\tilde{\mathcal{I}}_j\)는 \(j\)번째 컨텍스트 전환 전후의 정보 유닛 집합으로, LLM-as-Judge가 추출합니다.
모델 |
\(\mathcal{L}_{\text{info}}\) ↓ |
C.C. |
Avg. PL |
Avg. L |
|---|---|---|---|---|
ReAct |
— |
— |
13.1k |
13.1k |
ReSum |
25.23% |
2.7 |
14.2k |
15.7k |
FoldAgent |
19.24% |
5.6 |
9.5k |
9.5k |
Self-Manager |
11.53% |
7.0 |
10.2k |
10.2k |
C.C.는 컨텍스트 전환 횟수(요약·접기·서브스레드 생성), Avg. PL은 평균 피크 컨텍스트 길이, Avg. L은 실행 종료 시 컨텍스트 길이입니다.
읽는 방법은 두 가지입니다. (1) 정보 손실은 ReSum의 25%, FoldAgent의 19%에서 Self-Manager의 11%로 절반 가까이 떨어집니다. 격리된 컨텍스트가 정보를 덜 흘리기 때문이죠. (2) 동시에 컨텍스트 길이는 ReSum보다 짧고 ReAct보다 훨씬 짧습니다(10.2k vs ReAct 13.1k). 손실은 줄이면서 컨텍스트는 짧게 쓰는 두 마리 토끼를 잡았다는 주장입니다.
비용과 효율
모델 |
Time (s) |
Cost ($) |
Tool Calls |
RN |
|---|---|---|---|---|
FoldAgent |
117.27 |
0.05 |
18.25 |
5.6 |
Self-Manager |
129.62 |
0.09 |
20.30 |
7.0 |
w/o Async |
193.08 |
0.07 |
21.63 |
7.2 |
w/o Conc |
144.55 |
0.07 |
19.37 |
6.6 |
여기서 RN은 서브태스크 결과 반환 횟수입니다.
Self-Manager는 FoldAgent 대비 시간이 10% 길고 비용이 두 배 가까이 듭니다. 도구 호출이 좀 더 잦기 때문입니다. 단일 에이전트 카테고리에서 가장 큰 성능 향상의 대가로 허용 가능한 수준의 오버헤드라고 저자들은 주장합니다.
흥미로운 부분은 ablation입니다. Async를 끄면 시간이 193초로 50% 가까이 늘어납니다. 메인이 서브스레드를 기다리느라 블로킹되는 구간이 그만큼 크다는 뜻이죠. Concurrency를 끄면 시간은 약간 늘지만(144초) 성능이 떨어집니다(자료에 점수가 별도 표기됨, 본 논문 Figure 3 참조).
일반화
DeepResearch Bench가 아닌 BrowseComp-Plus(다중 홉 deep search 벤치마크)에서도 같은 패턴이 나옵니다. Self-Manager가 Acc 36.17%로 ReAct(28.47%), ReSum(31.24%), FoldAgent(35.65%)를 다 이깁니다. 구조가 도메인에 맞춰 새로 튜닝되지 않아도 일반화된다는 보조 근거입니다.
회고
본 논문이 솔직하게 인정한 한계를 §C.3 토론에서 끌어올립니다.
서브태스크 다양성이 부족합니다. Figure 8의 워드클라우드와 Figure 9의 빈도 분포를 보면 메인이 spawn 하는 서브태스크 유형이 Research, Analyze, Investigate, Examine 같은 정보 수집·분석 동사 몇 개에 압도적으로 몰립니다. Comparison, Prediction, Summarization, Writing 같은 다른 유형은 전체 분포에서 한 자릿수 수준에 불과합니다. 저자들은 모델이 병렬 에이전트 루프 위에서 작동하도록 명시적으로 학습되지 않아서 라고 진단하면서, 더 다양한 서브태스크를 만들도록 모델을 학습시키는 것을 향후 작업으로 남깁니다.
Proprietary와의 격차는 여전합니다. Self-Manager는 단일 에이전트 카테고리에서 최고이고 워크플로우 멀티 에이전트와 동급이지만, Gemini Deep Research와 OpenAI DeepResearch는 여전히 3~5점 위에 있습니다. 저자들은 이 차이가 구조의 한계가 아니라 베이스 모델의 한계 일 가능성이 크다고 보지만, 직접 검증한 것은 아닙니다.
여전히 단일 에이전트입니다. Self-Manager는 멀티 에이전트가 아닌 단일 에이전트의 병렬 확장 으로 설계됐습니다. 모든 스레드가 같은 정책 \(\pi_\theta\)를 공유합니다. 멀티 에이전트(여러 모델, 여러 정책)에서 얻을 수 있는 다양성 은 포기한 셈입니다. 저자들은 이를 의도된 선택으로 보고, generalization 우위를 지키기 위해서 라고 설명합니다. 일리는 있지만 검증은 후속 작업으로 미뤘습니다.
서브스레드는 nested되지 않습니다. 단순함을 위해 서브스레드가 또 서브스레드를 만드는 구조는 허용하지 않습니다. 이게 깊이 있는 문제 분해를 막을 수 있다는 점은 본 논문도 인정합니다. 재귀적 분해 vs 평탄한 병렬 분해 의 trade-off에 대한 명시적 ablation은 없습니다.
케이스 스터디
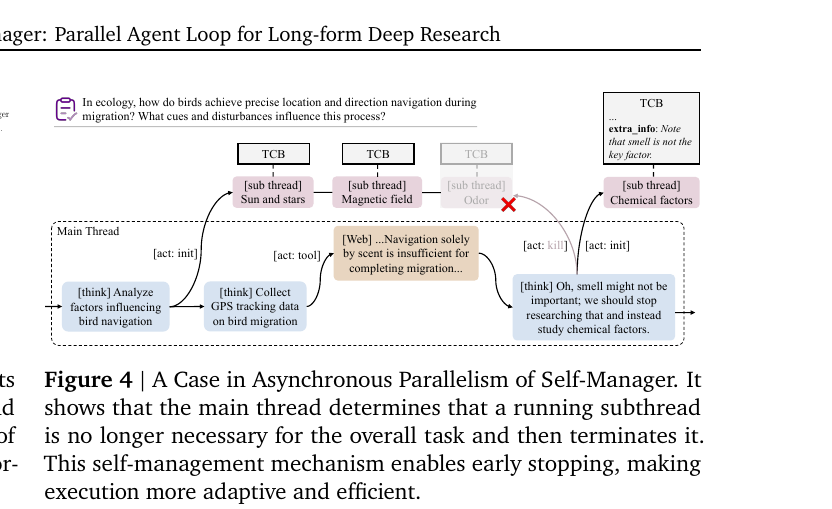
Figure 4는 메인 스레드의 자기 관리 가 실제로 발동하는 순간을 보여줍니다. 새의 이주 항행에 관한 질의에서 메인은 세 개의 서브스레드(태양과 별, 자기장, 냄새)를 동시에 돌리다가, 웹 검색 결과로 "냄새만으로는 항행에 부족하다" 는 정보를 받습니다. 그 시점에 메인이 running 중인 "냄새" 서브스레드가 더 이상 유용하지 않다 고 판단하고 kill로 종료, 그 자리에 "화학 인자" 서브스레드를 새로 spawn 합니다.
이 패턴은 두 가지를 보여줍니다. (1) 메인이 서브스레드의 진행 상황을 실시간으로 평가하고 끊을 수 있다. (2) 비동기 실행이 단순히 시간 절약이 아니라 조기 종료를 통한 자원 절약 까지 가능하게 합니다. 본 논문이 multi-agent workflow와 구분 짓는 가장 강한 차별점이 여기 있습니다.
정리
세 줄로 압축하면 다음과 같습니다.
- OS의 스레드 추상을 LLM 에이전트로 끌어왔다. 메인 스레드가 비동기 서브스레드를 spawn 하고 TCB 메타데이터로 직접 관리합니다. 구조는 단순하지만 발상이 깔끔합니다.
- 단일 에이전트가 사전 정의된 워크플로 없이도 멀티 에이전트와 같은 줄에 선다. 같은 베이스 모델로 ReAct, ReSum, FoldAgent를 다 이기고 LangChain·NVIDIA 워크플로우와 동급입니다.
- 허용 가능한 오버헤드로 정보 손실은 절반. 시간 10% 증가, 비용 약 2배 증가의 대가로 정보 손실을 19%에서 11%로 줄였습니다.
남는 질문은 어디까지가 구조의 공이고 어디까지가 베이스 모델의 한계인가입니다. Qwen3-Next-80B에서도 Proprietary와 격차가 좁혀지지 않는다면, 서브태스크 분배를 잘하는 메인 정책 이 별도로 학습돼야 한다는 후속 작업이 자연스럽게 떠오릅니다. 저자들이 본문 결론에서 명시한 방향이기도 합니다.
코드는 GitHub ylXuu/ParallelAgent에 공개돼 있습니다.