Are We Ready For An Agent-Native Memory System
W. Zhou, X. Zhou, S. Han, H. Xu, G. Li, Z. Li, F. Xiong, and F. Wu, "Are We Ready For An Agent-Native Memory System?," arXiv:2606.24775, 2026.
저자
이 논문은 상하이 교통대학교(SJTU) 컴퓨터과학부의 Xuanhe Zhou가 교신저자로, Guoliang Li Tsinghua 교수 팀 및 에이전트 메모리 전문 스타트업 MemTensor(상하이)의 Zhiyu Li·Feiyu Xiong이 함께 썼습니다. Wei Zhou가 1저자로 전체 실험을 주도했습니다.
Xuanhe Zhou는 SIGMOD 2025 Jim Gray Honorable Mention을 중국 본토 연구자 최초로 받은 AI4Data 연구자입니다. Guoliang Li는 ACM·IEEE Fellow로 데이터베이스와 LLM 결합 분야를 선도해 왔습니다. 두 팀이 데이터 관리 시스템의 관점에서 에이전트 메모리 문제를 다룬다는 것이 이 논문의 정체성입니다.
배경
LLM 에이전트 메모리 시스템은 단순한 RAG에서 지식 그래프·하이브리드 멀티엔진 구조까지 빠르게 다양화됐습니다. MemoryBank, Mem0, Zep, A-MEM 같은 시스템이 각자 다른 설계 원리로 출시됐고, 2026년 초 기준으로 연구 논문만 수십 편에 달합니다.
문제는 평가입니다. 기존 벤치마크에는 네 가지 구조적 한계가 있습니다. 첫째, MemoChat·MemTree·LightMem 같이 활발히 쓰이는 시스템들이 선행 비교 연구에서 아예 빠졌습니다. 둘째, F1·BLEU 같은 단일 태스크 성공 지표만 봐서 시스템 내부 동작을 추론할 수 없습니다. 셋째, 인덱스 생성 시간·쿼리 지연 같은 운영 비용이 측정된 적이 없습니다. 넷째, 시스템 전체를 블랙박스로 다루어 어느 모듈이 성능에 기여하는지 알 수 없습니다.
저자들은 이 네 가지를 모두 다루는 데이터 관리 관점의 체계적 실험으로 논문을 채웁니다. 핵심 질문은 제목 그대로입니다. "우리는 에이전트 네이티브 메모리 시스템을 만들 준비가 됐는가?"
어떻게 만들었나
평가 체계의 기반은 에이전트 메모리 시스템을 4모듈 튜플로 형식화한 것입니다.
\[\mathcal{M}_{sys} = \langle \mathcal{R},\, \mathcal{S},\, \mathcal{Q},\, \mathcal{U} \rangle\]
\(\mathcal{R}\)은 표현 및 저장(Representation & Storage), \(\mathcal{S}\)는 추출(Extraction), \(\mathcal{Q}\)는 검색 및 라우팅(Retrieval & Routing), \(\mathcal{U}\)는 유지관리(Maintenance)입니다. 이 4축으로 12개 시스템 각각의 설계 결정을 테이블 하나에 비교합니다(Table 1).
평가는 5개 RQ로 구성됩니다.
RQ |
질문 |
|---|---|
RQ1 |
에이전트 태스크 전반에서 효과적으로 도움이 되는가? |
RQ2 |
저장된 근거를 얼마나 정확히 검색하는가? |
RQ3 |
동적 업데이트 후에도 강건하게 유지되는가? |
RQ4 |
장기 호라이즌에서 성능이 안정적인가? |
RQ5 |
운영 비용은 효과에 비례하는가? |
벤치마크 3개, 데이터셋 11개를 동일한 time-overhead trace 러너로 실행합니다. 사용한 벤치마크는 LoCoMo(장기 대화 QA), LongMemEval(멀티세션 장기 메모리), DB-Bench/LifeLongAgentBench(절차 실행)입니다.
5단계 컴포넌트 ablation(\(M1\)~\(M4\))도 별도로 설계됩니다. 한 번에 하나의 모듈 변수만 바꾸어 제어된 비교를 만들고, 모듈별로 어떤 설계 결정이 전체 성능에 영향을 주는지 정량화합니다.
무엇으로 구성돼 있나
12개 시스템은 메모리 표현 방식에 따라 세 계열로 나뉩니다.
Sequential Context (4종): MemoChat, Mem0, MEM1, MemAgent. 토큰 수준의 일차원 시퀀스로 메모리를 표현합니다. In-context 레지스터나 벡터 DB를 저장소로 씁니다.
Structural Topological (6종): MemTree, Zep, Mem0\(^\theta\), Cognee, LightMem, SimpleMem. 그래프·트리 위상 구조로 관계와 계층을 명시적으로 모델링합니다. Temporal Knowledge Graph, Hierarchical Tree, Labeled Graph 형태로 다양합니다.
Multi-Paradigm Hybrid (4종): MemOS, MemoryOS, A-MEM, Letta. 텍스트·임베딩·그래프를 복합 데이터 오브젝트로 묶고 멀티엔진 백엔드를 씁니다.
각 시스템은 추출 전략(Raw Sequence, Schema-Free, Schema-Constrained), 검색 전략(Semantic-Based, Topological Subgraph, Agentic Routing 등), 유지관리 전략(Timestamp-Based Versioning, LLM-Driven Consolidation 등)에서도 서로 다른 설계를 선택합니다. 단일 지표로 비교하면 이 다양성이 보이지 않습니다.
결과
전체 효과성: 단일 승자는 없다
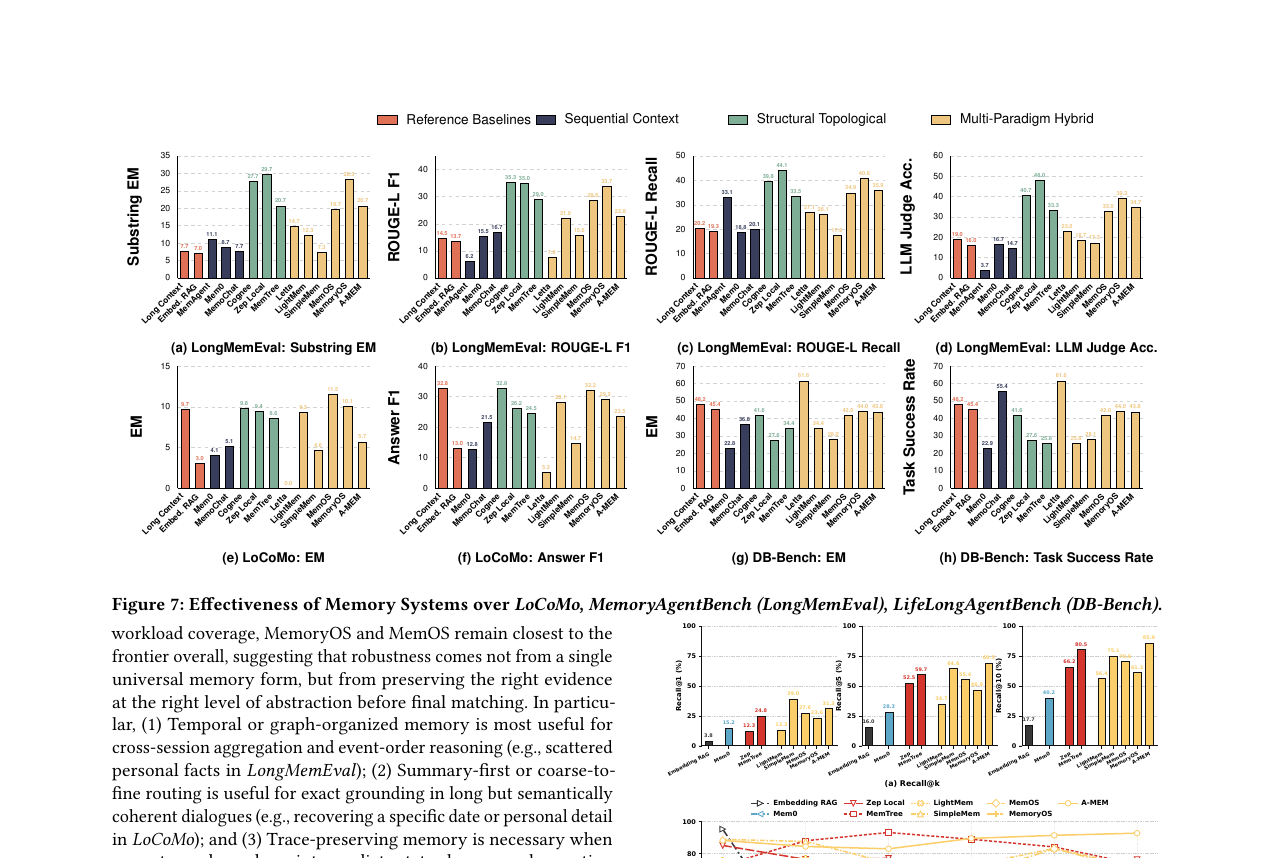
세 벤치마크에서 선두 시스템이 완전히 달라집니다.
- LongMemEval: Zep이 LLM Judge Accuracy 48.0으로 가장 높고, Cognee가 ROUGE-L F1 35.3으로 뒤를 잇습니다. 그래프 기반 시스템이 크로스세션 집계와 시간 정렬 추론에서 강합니다.
- LoCoMo: MemOS가 11.5 EM으로 최고입니다. 하이브리드 필터링이 긴 대화 속 특정 사실을 정밀하게 꺼내는 데 유리합니다.
- DB-Bench: Long Context가 48.20 EM이고, MemoChat이 55.40 Task Success Rate로 높습니다. 중간 상태와 실행 순서를 보존하는 trace 기반 메모리가 중요합니다.
full slice coverage 기준에서 MemOS와 MemoryOS가 전반적으로 프런티어에 가장 가깝지만, 이것도 "어느 한 시스템이 모든 워크로드를 지배한다"는 뜻은 아닙니다.
Exact Match(EM)는 단답형 사실에서는 의미 있지만, LongMemEval처럼 교차세션 합성이 필요한 태스크에서는 더 강한 시스템을 구분하지 못합니다. DB-Bench에서 Long Context가 EM은 높지만 MemoChat이 Task Success Rate에서 앞서는 대조가 이를 보여줍니다.
검색 정확도: 평탄 유사도 검색의 한계
SimpleMem이 단거리 쿼리에서 Recall@1 39.0으로 가장 높지만, evidence distance가 늘어날수록 성능이 급격히 떨어집니다. 반면 A-MEM과 MemTree는 Recall@5/10에서 각각 59.7/80.5로 더 안정적입니다. Embedding RAG 베이스라인은 거리가 커질수록 가장 빠르게 하락합니다.
핵심은 검색 품질이 "관련 항목을 1위로 랭킹하느냐"보다 "분산되거나 시간적으로 먼 근거를 조합해 모을 수 있느냐"에 달려 있다는 것입니다.
업데이트 강건성 (Table 2)
시스템 |
LoCoMo EM |
Knowledge Update Substr EM |
Temporal Reasoning Substr EM |
|---|---|---|---|
Long Context |
8.1 |
20.0 |
12.0 |
Embedding RAG |
1.6 |
20.0 |
10.7 |
Mem0 |
3.2 |
15.6 |
10.7 |
Cognee |
4.0 |
37.8 |
18.7 |
Zep |
4.8 |
44.4 |
13.3 |
LightMem |
4.0 |
15.6 |
12.0 |
SimpleMem |
4.4 |
6.7 |
8.0 |
MemOS |
8.9 |
28.9 |
30.5 |
MemoryOS |
3.2 |
35.6 |
16.0 |
A-MEM |
4.8 |
26.7 |
8.0 |
지식 업데이트(Knowledge Update) 슬라이스에서 Zep(44.4)이 앞서고, 시간 추론(Temporal Reasoning) 슬라이스에서 Cognee(18.7)가 앞섭니다. LoCoMo EM에서는 MemOS(8.9)와 Cognee(28.1 Ans F1)가 가장 강합니다. 여기서도 어느 한 시스템이 모든 축을 동시에 리드하지 않습니다. LLM 스케일 업(Backbone Robustness 실험)은 성능 절대값을 올리지만 시스템 간 순위를 거의 바꾸지 않습니다. 강한 백본은 이미 확보된 근거의 "표현"을 개선할 뿐, "로컬라이제이션"은 메모리 파이프라인이 결정합니다.
운영 비용
시스템 |
Normalized Utility |
Avg. Latency/Query (s) |
|---|---|---|
LightMem |
48.3 |
3.67 |
Mem0 |
21.4 |
35.9 |
MemTree |
63.5 |
15.9 |
A-MEM |
57.7 |
17.9 |
MemoryOS |
82.0 |
28.6 |
Cognee |
84+ |
116.5 |
Zep |
84+ |
155.1 |
LightMem이 가장 빠른 비용 효율 구간을 차지하고, MemTree가 보통 효율 구간에서 두드러집니다. 고성능 시스템인 MemoryOS·Cognee·Zep은 효용이 높지만 비용도 급격히 올라갑니다. 효율성은 구조의 복잡도보다 유지관리 범위(maintenance scope)가 결정합니다. 로컬 업데이트(LightMem의 세그먼트 압축, MemTree의 경로-로컬 트리 집계)가 전체 재구성보다 훨씬 저렴합니다.
회고
모듈별 ablation이 9개 발견(Finding)을 산출합니다. 그 중 가장 반직관적인 것들입니다.
표현 정보량이 구조 복잡도보다 중요합니다. LightMem User-Only Raw(원본 텍스트 그대로 저장)가 Summary 변형이나 Compressed 변형보다 LoCoMo·LongMemEval 양쪽에서 모두 앞섭니다(EM 24.2 vs. 8.5/23.6, Substr EM 26.0 vs. 11.7/10.7). 원본 표현을 압축할수록 나중에 복원 불가능한 세부 정보가 사라집니다.
추출은 늦게 걸러야 합니다. MemoChat Heuristic Topic 방식(거친 주제 그룹화)이 LLM Topic 방식(정밀 세분화)보다 LongMemEval에서 앞섭니다(10.7 vs. 7.3 Substr EM). 조기 필터링이 나중에 함께 필요한 분산 사실들을 분리해버리기 때문입니다.
보수적 통합이 지연 플러시보다 낫습니다. MemoryOS Conservative-Merge 변형이 기본 설정보다 Ans F1 23.5(기본 23.2), Substr EM 22.8(기본 22.4)로 소폭 앞서는 반면, Delayed-Flush는 20.6/19.5로 역전됩니다. 늦은 플러시는 검색 시점에 미처 통합되지 않은 조각들을 남겨둡니다.
저자들이 명시적으로 인정하는 한계도 있습니다. 평가된 12개 시스템 일부는 내부 구현이 공개되지 않아 완전한 변형 실험이 불가능했습니다. LLM judge 편향도 LLM Judge Accuracy 지표에 내재됩니다. 그리고 벤치마크 자체가 영어 중심이라 다국어 에이전트 환경을 포괄하지 못합니다.
정리
- 단일 만능 에이전트 메모리 구조는 없습니다. 어느 시스템이 앞서는지는 워크로드 유형(크로스세션 추론/사실 정밀 검색/절차 실행)에 따라 달라집니다.
- 검색 품질은 1위 랭킹보다 분산된 근거를 시간 거리에 관계없이 모으는 구조적 능력에 달려 있습니다. 그래프·계층 구조가 이 점에서 앞서고, 평탄 벡터 검색은 단거리에서만 경쟁력이 있습니다.
- 비용 효율은 전역 재구성이 아닌 로컬 유지관리에서 나옵니다. 표현 정보량을 보존하고, 추출을 늦게 걸고, 보수적으로 통합하는 세 원칙이 에이전트 네이티브 메모리 설계의 방향을 제시합니다.