Orchestra-o1 - Omnimodal Agent Orchestration
F. Zhang, V. Zhang, S. Qian, H. Li, H. Wu, J. Wu, D. Zhou, Z. Zhu, Z. Lian, X. Wang, and P.-A. Heng, "Orchestra-o1: Omnimodal Agent Orchestration," arXiv:2606.13707, 2026.
저자
장판이 공동 1저자를 맡았습니다. CUHK CSE 박사과정 1년차로, 지도교수가 이 논문의 교신저자인 헹 평안입니다. 텐센트 YouTu Lab과 알리바바 통이랩 인턴 경력이 있고 멀티모달 AI 평가와 에이전트 시스템을 주로 연구합니다.
반대편 교신저자는 Shengju Qian으로, 텐센트의 게임·AI 부문인 LIGHTSPEED 소속입니다. 실험 파이프라인 구현의 핵심 기여자로 보입니다. 그 외에도 PKU, THU, 통지대에서 각각 연구자가 합류한 5개 기관 협업 프로젝트입니다.
배경
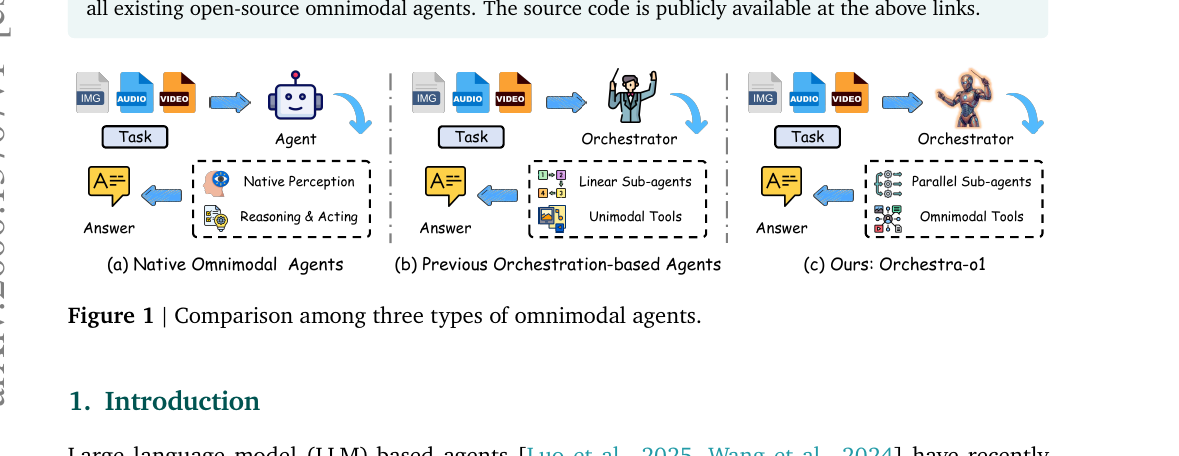
에이전트 연구는 지금 두 갈래로 갈라져 있습니다. 하나는 단일 대형 모델이 지각·추론·행동을 한 번에 처리하는 네이티브 옴니모달 에이전트 방식입니다. GPT-5나 Gemini-3 계열이 대표적입니다. 다른 하나는 메인 에이전트가 서브에이전트에게 일을 위임하는 오케스트레이션 기반 방식입니다.
두 방식 모두 옴니모달 태스크에서는 아직 한계가 있습니다. 네이티브 방식은 지각과 행동을 같은 모델이 처리하다 보니 긴 추론, 외부 정보 탐색, 크로스모달 이해가 겹칠 때 병목이 생깁니다. Gemini-3-Pro도 OmniGAIA에서 62.5%에 그쳤습니다. 기존 오케스트레이션 방식은 텍스트 또는 비전-언어 환경에 묶여 있었고, 서브에이전트 실행이 선형적이었습니다.
프레임워크
Orchestra-o1은 메인 에이전트(오케스트레이터)와 서브에이전트를 명확히 분리하는 계층 구조입니다. 메인 에이전트는 고수준 결정만 담당합니다. 지각과 행동 실행은 전문화된 서브에이전트에 위임합니다.
모달리티-인식 태스크 분해. 메인 에이전트는 입력 태스크를 받으면 의존성 그래프 \(G_t = (V_t, E_t)\)를 구성합니다. 각 노드 \(v\)는 해결해야 할 서브골이고, 방향 간선 \((v_i, v_j) \in E_t\)는 \(v_j\)가 \(v_i\)의 결과를 필요로 한다는 의존 관계를 나타냅니다. 선행 조건이 완료된 서브골들이 현재 실행 가능한 준비 집합 \(\mathcal{R}_t\)를 이룹니다.
온라인 서브에이전트 특화. 각 서브태스크마다 가장 적합한 백엔드 모델과 툴 서브셋을 매칭합니다. 백엔드 선택은 비용·지연·모달리티 역량의 트레이드오프를 반영해 쉬운 검색 태스크는 저렴한 모델로, 복잡한 추론 태스크는 강력한 백엔드로 라우팅합니다.
병렬 서브태스크 실행. 준비 집합의 독립적인 서브태스크들을 AsyncExecute로 동시에 처리합니다. 선형 오케스트레이터와 비교하면 라운드당 레이턴시 차이는 다음과 같습니다.
\[\text{Latency}^{\text{linear}}(t) = \sum_{j=1}^{K_t} \delta_{t,j}, \quad \text{Latency}^{\text{parallel}}(t) = \max_{j} \delta_{t,j} + \delta_t^{\text{sync}}\]
\(K_t\)개의 서브태스크 중 가장 느린 것의 실행 시간만 기다리면 되므로, 이론적으로 최대 \(K_t\)배까지 빨라집니다.
각 라운드가 끝나면 메인 에이전트는 서브에이전트 결과를 구조화된 컨텍스트 메모리 \(H_t\)에 누적하고 의존성 그래프를 갱신합니다. 증거가 충분히 쌓이면 최종 답을 생성하고 멈춥니다.
툴 생태계는 6가지입니다. 이미지 분석, 오디오 분석, 영상 분석이 지각 툴이고, 웹 검색, 페이지 방문, 코드 실행이 행동 툴입니다.
학습
오픈소스 메인 에이전트 Orchestra-o1-8B는 Qwen3-8B를 베이스로 DA-GRPO로 훈련했습니다.
데이터 구축. FineVideo, LongVideoBench, COCO 2017에서 300개의 시드를 추출한 뒤 피벗 스와핑, 시간 이동, 수치 재조합, 형제 엔티티 질의, 멀티홉 재정렬의 다섯 가지 재작성 전략으로 약 1,500개 후보를 생성했습니다. 앵커 커버리지, 중복 제거, 모달-우회 테스트, 수치 검증, LLM 심판의 5단계 게이트를 통과한 약 1,200개가 최종 훈련 데이터입니다. 데이터 큐레이션에는 Claude Opus 4.6이 앵커 추출, 질문 재작성, 검증 심판을 전담했습니다.
DA-GRPO. 일반 GRPO는 최종 답이 맞는지만 봅니다. 에이전트 훈련에서는 전체 멀티에이전트 시스템을 실행해야만 리워드를 계산할 수 있어 비용이 높습니다. DA-GRPO는 이 병목을 피합니다. 메인 에이전트의 결정 하나하나를 전문가 궤적과 비교해 오프라인으로 평가합니다.
리워드는 4개 차원의 가중합입니다.
\[r_{i,j} = \alpha_1 r^{\text{format}} + \alpha_2 r^{\text{action}} + \alpha_3 r^{\text{tool}} + \alpha_4 r^{\text{decision}}\]
형식 정확도와 액션 유효성은 이진 점수, 툴 적절성과 결정 품질은 0~3점 등급입니다. 가중치는 0.1, 0.1, 0.2, 0.6으로 결정 품질에 가장 큰 비중을 뒀습니다. 리워드 모델은 Claude Haiku 4.5가 단일 호출로 4개 차원을 동시에 채점합니다.
DA-GRPO의 핵심 이점은 두 가지입니다. 서브에이전트를 실제로 실행하지 않아도 결정 단계에서 피드백이 가능하고, 위임, 툴 선택, 병렬 스케줄링, 종료 결정 같은 오케스트레이션의 핵심 행동에 밀집 피드백을 줍니다.
결과
방법 |
전체 정확도 (%) |
|---|---|
Gemini-2.5-Flash-Lite |
8.6 |
Gemini-2.5-Pro |
30.8 |
Gemini-3-Flash |
51.7 |
Gemini-3-Pro |
62.5 |
AOrchestra-GPT-5 |
40.0 |
Orchestra-o1-GPT-5 (ours) |
72.8 |
OmniAtlas-Qwen3-30B-A3B (이전 오픈소스 최고) |
20.8 |
Orchestra-o1-8B (ours) |
30.0 |
Orchestra-o1-GPT-5는 72.8%로 OmniGAIA SOTA를 달성했습니다. Gemini-3-Pro보다 10.3%p, 같은 GPT-5 메인 에이전트를 쓴 AOrchestra보다 32.8%p 앞섰습니다. 개선은 지리, 기술, 역사, 스포츠, 예술, 영화, 과학 등 대부분의 카테고리에서 일관됐습니다.
오픈소스 모델 Orchestra-o1-8B는 30.0%로, 파라미터가 4배 가까이 큰 OmniAtlas-Qwen3-30B-A3B(20.8%)를 넘어섰습니다. DA-GRPO가 단순 형식 학습이 아닌 전략적 오케스트레이션 능력을 키웠다는 근거입니다.
비용 비교. Orchestra-o1은 정확도만 높은 게 아니라 더 저렴합니다. AOrchestra가 40.0% 정확도에 비용 565.7을 쓸 때, Orchestra-o1은 72.8%에 341.6이었습니다. 병렬 실행이 서브에이전트 레이턴시를 줄이고, 백엔드·툴 명시 선택이 불필요한 고비용 호출을 막은 결과입니다.
난이도별. Orchestra-o1-GPT-5는 쉬운 태스크 80.3%, 중간 75.0%, 어려운 56.4%입니다. AOrchestra 대비 어려운 태스크에서 24.3%p 개선이 두드러집니다. 의존성-인식 분해와 반복적 증거 집계가 복잡한 크로스모달 추론에서 더 강하게 작동합니다.
에블레이션.
설정 |
정확도 (%) |
|---|---|
ReAct + Qwen3-8B |
12.5 |
Orchestra-o1 (훈련 없음) |
26.3 |
|
28.6 |
|
27.7 |
|
30.0 |
오케스트레이션 스캐폴드만 씌워도 12.5%에서 26.3%로 오릅니다. 프레임워크 자체가 강한 귀납 편향을 제공한다는 뜻입니다. 그 위에 SFT(28.6%)와 Vanilla GRPO(27.7%)가 올라가는데, Vanilla GRPO가 SFT보다 낮다는 점이 흥미롭습니다. 희소한 결과 리워드만으로는 오케스트레이션 행동을 충분히 정렬하기 어렵다는 것을 보여줍니다. DA-GRPO(30.0%)가 결정 단계 밀집 피드백으로 이 한계를 돌파합니다.
회고
저자들이 직접 인정한 두 가지입니다.
첫째, 오케스트레이션 자체가 시스템 복잡도를 높입니다. 서브에이전트 히스토리, 툴 스키마, 백엔드 구성, 비용 계정, 비동기 실행 등 단일 에이전트보다 관리할 컴포넌트가 훨씬 많습니다. 확장성은 높아지지만 구현과 모니터링 부담도 함께 올라갑니다.
둘째, 현재 DA-GRPO는 메인 에이전트만 최적화합니다. 서브에이전트 백엔드는 훈련 중 고정됩니다. 메인·서브에이전트와 툴 선택 행동을 엔드투엔드로 공동 최적화하는 것은 다음 과제입니다.
정리
- 기존 옴니모달 에이전트의 두 병목, 단일 모델의 과부하와 선형 서브에이전트 실행을 의존성-인식 병렬 오케스트레이션으로 해결했습니다.
- DA-GRPO는 최종 답 리워드 대신 결정 단계 정렬 리워드를 써서 8B 오픈소스 모델로도 경쟁력 있는 오케스트레이터를 만들어냈습니다.
- OmniGAIA에서 정확도와 비용 모두 기존 최강 오케스트레이션 프레임워크 AOrchestra를 넘었습니다.