Recursive Language Models
A. L. Zhang, T. Kraska, and O. Khattab, "Recursive Language Models," arXiv:2512.24601, 2026.
긴 컨텍스트는 LLM의 오래된 약점입니다. 컨텍스트 창을 아무리 늘려도, 프롬프트가 길어지면 품질이 가파르게 떨어집니다. 이 현상은 context rot이라고 불립니다. 창 안에 다 들어가는 길이인데도 답이 무너집니다.
Recursive Language Models(RLM)는 이 문제를 정면이 아니라 옆에서 칩니다. 프롬프트를 신경망에 통째로 먹이지 않습니다. 대신 REPL 환경의 변수로 올려두고, 모델이 코드를 써서 그 변수를 들여다보고 잘라보고, 필요하면 자기 자신을 다시 호출하게 합니다. 신경망은 프롬프트 전체를 절대 한 번에 보지 않습니다.
결과는 인상적입니다. RLM은 모델 컨텍스트 창의 한 자리 수 배가 아니라 10M 토큰 이상을 처리하면서도 비용은 베이스라인과 비슷합니다. 게다가 창 안에 들어가는 짧은 프롬프트에서도 바닐라 모델과 기존 long-context 스캐폴드를 큰 폭으로 앞섭니다.
저자
세 명 모두 MIT CSAIL 소속입니다.
1저자 알렉스 장은 박사과정 학생입니다. RLM은 정식 논문 이전에 본인 블로그에 올린 글에서 출발했습니다. "긴 프롬프트를 모델에 직접 먹이지 말고 환경으로 다루자"는 한 문장짜리 발상이 반응을 얻으면서 프런티어 모델 평가와 8B 파인튜닝까지 붙은 정식 연구로 자랐습니다.
시니어 저자 두 명은 알렉스 장의 공동 지도교수입니다. 팀 크라스카는 데이터 시스템 그룹을 이끄는 부교수로, learned index처럼 시스템을 학습 가능한 컴포넌트로 재해석해온 연구자입니다. RLM이 추론을 "프롬프트를 외부 환경으로 다루는 시스템 문제"로 재정의한 시각이 그의 배경과 맞물립니다. 오마르 카탑은 ColBERT(신경망 검색)와 DSPy(LM 프로그래밍)를 만든 연구자입니다. "LM 호출을 코드로 조립한다"는 DSPy의 문제의식을 추론 시점으로 끌어온 것이 RLM이라고 볼 수 있습니다.
세 사람의 조합이 논문의 성격을 설명합니다. 검색·LM 프로그래밍(카타브)과 시스템(크라스카)이 만나, 긴 컨텍스트를 신경망의 문제가 아니라 추론 스캐폴드의 문제로 다시 봅니다.
배경
긴 컨텍스트를 다루는 방법은 그동안 두 갈래였습니다.
하나는 아키텍처를 바꿔서 base 모델 자체를 더 긴 컨텍스트에 맞게 다시 학습하는 길입니다. 다른 하나는 모델은 그대로 두고 스캐폴드를 둘러 컨텍스트를 암묵적으로 관리하는 길입니다. RLM은 후자에 속합니다.
후자에서 가장 널리 쓰이는 일반적 전략은 compaction, 즉 압축입니다. 사용자 요청이나 에이전트 트라젝토리가 길이 한계를 넘으면 반복적으로 요약합니다. 문제는 압축이 손실(lossy)이라는 점입니다. 압축은 "앞쪽에 나온 어떤 디테일은 새 내용을 위해 잊어도 안전하다"고 전제합니다. 프롬프트 전체에 빽빽하게 접근해야 하는 태스크에서는 이 전제가 깨집니다.
코딩 에이전트나 검색 에이전트도 외부 데이터(파일 시스템, 검색 문서)를 환경으로 다루긴 합니다. 하지만 스니펫을 가져오면 결국 base 모델의 컨텍스트 창을 채우게 되고, 다시 압축 앞에 섭니다. 자기 자신을 sub-agent로 부르는 self-delegation 방식도 있지만, sub-call을 autoregressive하게 말로 풀어내도록 설계돼 있어 출력 길이 한계에 묶입니다.
빈자리는 분명합니다. 프롬프트를 압축 없이, 손실 없이, 출력 길이 제약 없이 다루는 방법입니다. 저자들은 이것을 추론 시점 스케일링(inference-time scaling)의 렌즈로 봅니다. reasoning model이 추론 연산을 늘려 성능을 끌어올렸듯, 컨텍스트도 추론 스캐폴드로 한 차원 더 키울 수 있다는 가설입니다.
어떻게 만들었나
핵심 통찰은 한 줄입니다. 임의로 긴 사용자 프롬프트는 신경망에 직접 들어가면 안 되고, LLM이 상징적·재귀적으로 상호작용하는 환경의 일부가 되어야 한다.
최대 컨텍스트 \(K\)를 가진 base 모델 \(\mathcal{M}\)이 있다고 합시다. RLM은 \(\mathcal{M}\) 주위를 감싸는 추론 스캐폴드입니다. 임의 길이의 프롬프트 \(P \in \Sigma^*\)를 받아 응답 \(Y \in \Sigma^*\)를 돌려주되, 다음 세 가지를 노립니다.
- unbounded input tokens (\(|P| \gg K\))
- unbounded output tokens
- unbounded semantic horizon, 즉 \(\Omega(|P|)\)나 \(\Omega(|P|^2)\) 규모의 의미적 작업
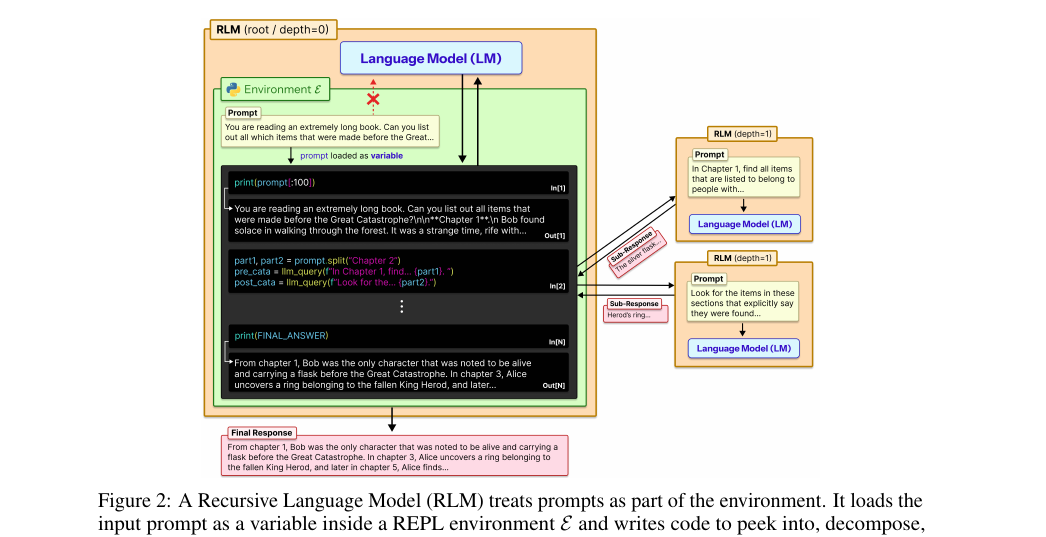
위 그림이 동작 방식입니다. RLM은 LLM과 똑같은 외부 인터페이스를 노출합니다. 문자열 프롬프트를 받아 문자열 응답을 냅니다. 안에서 벌어지는 일은 다릅니다.
프롬프트 \(P\)가 주어지면 RLM은 Python REPL 환경을 띄우고, \(P\)를 변수 값으로 올립니다. root 모델 \(\mathcal{M}\)에게는 처음에 프롬프트 전체가 아니라 길이·짧은 프리픽스·접근 방법 같은 상수 크기 메타데이터만 줍니다. root는 프롬프트로 지시받거나(Appendix C) 파인튜닝(Appendix A)으로 다음처럼 행동하도록 학습됩니다. 자기 프롬프트 \(P\)의 일부를 이해·변형하는 코드를 생성하고, 중간값과 최종 응답을 새 변수로 쌓아 올리며, 필요하면 루프 안에서 sub-RLM을 호출합니다.
루프의 각 반복은 REPL에서 코드를 실행하고, REPL 상태를 갱신하고, 출력된 텍스트를 stdout으로 모읍니다. 여기서 결정적인 부분이 있습니다. \(\mathcal{M}\)에게는 stdout의 짧은 프리픽스와 길이 같은 상수 크기 메타데이터만 다음 반복으로 넘깁니다. 출력 전체를 창에 도로 붓지 않습니다. 이게 핵심입니다. 모델이 긴 문자열을 변수와 sub-call로 다루게 강제해서, 자기 창을 오염시키지 않게 만듭니다. root가 Final 변수를 설정하면 반복이 멈추고 그 값을 응답으로 돌려줍니다.
논문은 RLM을 일부러 비슷해 보이지만 훨씬 빈약한 대안 스캐폴드와 나란히 놓습니다. 차이는 세 군데입니다.
첫째, RLM은 사용자 프롬프트 \(P\)에 대한 symbolic handle을 모델에게 줍니다. 텍스트를 root 창에 복사하지 않고 조작합니다. 빈약한 대안은 \(P\)를 그냥 창에 넣고 시작해, \(\mathcal{M}\)의 창 한계를 그대로 물려받고 압축으로 되돌아갑니다.
둘째, RLM의 출력은 변수에서 나올 수 있어 \(\mathcal{M}\)의 창보다 길 수 있습니다. 빈약한 대안은 Finish 액션으로 모델이 출력을 직접 뱉게 해서, 출력이 창 길이를 넘지 못합니다.
셋째, 가장 중요한 symbolic recursion입니다. 환경 안에서 도는 코드가 \(\mathcal{M}\)을 프로그램적으로(예: 큰 루프 안에서) 호출할 수 있어야 합니다. 빈약한 대안은 코드 실행 액션과 sub-LLM 액션을 둘 다 갖고도 sub-LLM을 프로그램적으로 부르지 못합니다. 그래서 명시적으로 말로 풀어쓴 몇 개의 태스크만 위임할 수 있고, \(\Omega(|P|)\)나 \(\Omega(|P|^2)\)짜리 프로그램은 못 짭니다.
무엇으로 평가했나
저자들은 길이를 자유롭게 바꿀 수 있는 태스크 네 개로 평가를 설계했습니다. 난이도가 길이에 따라 다르게 증가하도록 골랐습니다.
- S-NIAH: RULER의 single needle-in-a-haystack. 긴 무관한 텍스트에서 특정 구절·숫자를 찾습니다. needle 크기가 고정이라 찾는 정보량은 입력 길이와 무관하게 \(O(1)\)입니다.
- BrowseComp-Plus (1K documents): DeepResearch류 멀티홉 QA. 1,000개 문서를 입력으로 주고 여러 문서를 엮어 추론해야 합니다.
- OOLONG: 의미 라벨을 붙이고 집계해 최종 답을 만드는 long reasoning 벤치마크. 거의 모든 질문을 써야 해서 처리 복잡도가 입력 길이에 선형으로 증가합니다.
- OOLONG-Pairs: OOLONG 변형. 청크 쌍을 집계해야 해서 입력 길이에 제곱으로 증가합니다. 가장 어렵습니다.
베이스라인은 두 프런티어 모델 GPT-5(medium reasoning)와 Qwen3-Coder-480B-A35B에서 측정합니다. 비교 대상은 base 모델 직접 호출, CodeAct(코드 실행 에이전트, BM25 검색·sub-call 변형), compaction 에이전트, 그리고 OpenCode·Claude Code 같은 코딩 에이전트입니다. Claude Code는 모델에 맞춰 설계됐으므로 Claude Opus 4.1로 측정합니다.
RLM은 Python REPL에 sub-LM 호출 모듈을 붙여 구현합니다. 최대 재귀 깊이를 0~3으로 바꿔가며 봅니다. 깊이 0은 sub-call 없는 RLM, 깊이 1은 sub-LLM 호출 허용, 깊이 1 초과는 sub-RLM 호출까지 허용입니다. 표기는 RLM(model, depth=\(N\))입니다.
결과
메인 결과입니다. 컬럼은 네 벤치마크, 단위는 점수, 괄호는 평균 API 비용입니다.
시스템 (GPT-5) |
CodeQA |
BrowseComp+ (1K) |
OOLONG |
OOLONG-Pairs |
|---|---|---|---|---|
Base Model |
24.0 |
0.0 |
44.0 |
0.1 |
CodeAct (+BM25) |
22.0 |
51.0 |
38.0 |
24.7 |
CodeAct (+sub-calls) |
24.0 |
0.0 |
40.0 |
28.4 |
Compaction agent |
58.0 |
70.5 |
46.0 |
0.1 |
OpenCode (+offloading) |
64.0 |
94.0 |
52.0 |
4.8 |
RLM (depth=0) |
58.0 |
88.0 |
36.0 |
43.9 |
RLM (depth=1) |
62.0 |
91.3 |
56.0 |
58.0 |
RLM (depth=2) |
66.0 |
92.0 |
56.5 |
65.5 |
RLM (depth=3) |
58.0 |
92.0 |
58.0 |
76.0 |
같은 비교를 Qwen3-Coder-480B-A35B에서 보면 이렇습니다.
시스템 (Qwen3-Coder) |
CodeQA |
BrowseComp+ (1K) |
OOLONG |
OOLONG-Pairs |
|---|---|---|---|---|
Base Model |
20.0 |
0.0 |
36.0 |
0.1 |
Compaction agent |
50.0 |
38.0 |
44.1 |
0.31 |
OpenCode (+offloading) |
40.0 |
58.0 |
24.0 |
2.1 |
RLM (depth=0) |
66.0 |
44.7 |
46.0 |
17.3 |
RLM (depth=1) |
56.0 |
44.7 |
48.0 |
23.1 |
RLM (depth=2) |
54.0 |
68.0 |
26.0 |
19.0 |
RLM (depth=3) |
44.0 |
68.7 |
32.0 |
21.1 |
참고로 Claude Opus 4.1의 Claude Code(+offloading)는 CodeQA 62.0, BrowseComp+ 84.0, OOLONG 48.0, OOLONG-Pairs 6.5입니다.
표에서 읽히는 것이 명확합니다. base 모델은 BrowseComp+와 OOLONG-Pairs에서 사실상 0점입니다. 입력이 창을 넘거나 너무 빽빽하면 그냥 무너집니다. compaction은 BrowseComp+까지는 어느 정도 끌어올리지만 OOLONG-Pairs에서는 다시 0점대로 떨어집니다. 압축이 쌍 단위 집계에 필요한 디테일을 날려버리기 때문입니다.
RLM은 정보 밀도가 높은 태스크에서 격차를 크게 벌립니다. OOLONG에서 RLM(depth=1)은 GPT-5·Qwen3-Coder를 base 대비 각각 \(28.4\%\), \(33.3\%\) 끌어올립니다. OOLONG-Pairs에서는 두 base 모두 F1 \(0.1\%\) 이하인데, RLM(depth=1)은 \(58.0\%\), \(23.1\%\)를 냅니다. 압축이 죽는 자리에서 RLM이 삽니다.
비용도 무너지지 않습니다. BrowseComp+(1K)에서 GPT-5-mini가 6~11M 토큰을 통째로 삼킨다고 선형 외삽하면 비용이 \(1.50~\)2.75인데, RLM(GPT-5, depth=1)의 평균 비용은 \(0.99입니다. 더 싸면서 베이스라인을\)29\%$ 이상 앞섭니다.
깊이의 효과는 모델마다 다릅니다. GPT-5는 깊이를 늘릴수록 OOLONG-Pairs에서 꾸준히 오릅니다(depth=0의 43.9에서 depth=3의 76.0). Qwen3-Coder는 오히려 얕은 깊이가 낫습니다. 이유는 회고에서 다룹니다.
길이에 따른 열화 곡선을 보면 차이가 더 분명합니다.
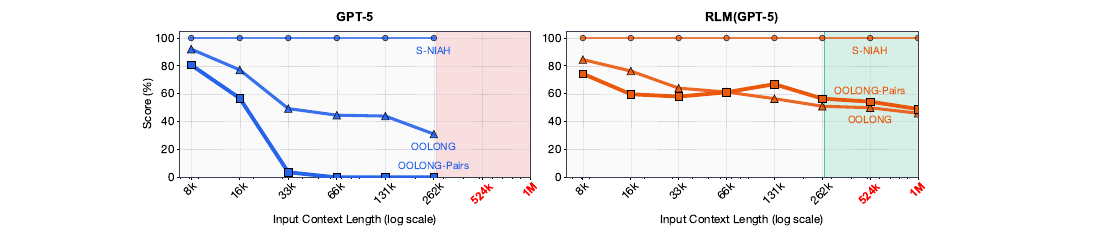
왼쪽이 GPT-5, 오른쪽이 RLM(GPT-5, depth=1)입니다. needle 크기가 고정인 S-NIAH는 둘 다 길이와 무관하게 만점에 가깝습니다. 선형 복잡도 OOLONG과 제곱 복잡도 OOLONG-Pairs에서 GPT-5는 길이가 늘수록 가파르게 떨어집니다. 특히 OOLONG-Pairs는 33k 부근에서 0으로 주저앉습니다. RLM은 같은 태스크에서 훨씬 완만하게 떨어지고, \(2^{14}\)를 넘는 길이에서는 일관되게 GPT-5를 앞섭니다. 빨간 영역은 GPT-5의 272K 창을 넘어 아예 안 들어가는 구간인데, RLM은 그 너머 1M까지 다룹니다.
긴 컨텍스트만이 아닙니다. 저자들은 RLM을 long reasoning 벤치마크 LongCoT-mini에도 적용합니다. 프런티어 모델이 잘 못 푸는, 합성된 하위문제로 이뤄진 추론 벤치마크입니다.
시스템 |
Overall |
MATH |
CHEM |
CS |
LOGIC |
CHESS |
|---|---|---|---|---|---|---|
GPT-5.2 (base) |
38.7 |
26.0 |
37.0 |
40.4 |
53.6 |
36.6 |
RLM (GPT-5.2, depth=1) |
50.6 |
5.6 |
50.0 |
11.0 |
86.7 |
93.0 |
RLM + 분해 힌트 |
65.6 |
32.0 |
52.0 |
46.0 |
99.0 |
99.0 |
RLM(depth=1)은 그냥도 base를 앞서지만, 문제를 어떻게 분해할지 명시적 힌트를 주면 base 대비 \(69.5\%\) 끌어올립니다. RLM이 추론 그래프를 프로그램으로 순회하며 각 노드를 sub-call로 풀어내기 때문입니다. 다만 힌트 없는 RLM은 MATH·CS에서 base보다 크게 떨어집니다. 분해를 잘못 잡으면 오히려 손해라는 신호입니다.
마지막으로 RLM이 학습 가능한 축이라는 증거입니다. 저자들은 Qwen3-8B를 RLM으로 파인튜닝했습니다. Qwen3-Coder-480B-A35B의 RLM 트라젝토리를 LongBenchPro에서 모아 작은 모델로 distill한 것입니다. 무관한 도메인의 샘플 1,000개만으로 네 평가 태스크 평균 \(28.3\%\)가 올랐습니다. 트라젝토리에는 도메인을 가로지르는 공통 행동(입력을 탐침하고 짧은 컨텍스트에서 재귀 sub-call을 거는 패턴)이 있어서, length generalization도 나타납니다.
회고
저자들은 Appendix B에 "시도했지만 안 된 것들"을 솔직하게 적었습니다. 본문 표만 보면 안 보이는 한계가 여기 있습니다.
가장 먼저, 같은 RLM 시스템 프롬프트를 모든 모델에 쓰면 문제가 생깁니다. GPT-5용으로 in-context 예시를 넣어 쓴 프롬프트를 Qwen3-Coder에 그대로 줬더니 원치 않는 행동이 나왔습니다. Qwen3-Coder에는 "재귀 sub-call을 너무 많이 쓰지 말라"는 문장을 따로 넣어야 했습니다. 깊이를 늘릴수록 Qwen3-Coder가 나빠진 이유가 여기서 갈립니다.
코딩 능력이 부족한 모델은 RLM으로 잘 안 됩니다. RLM은 REPL 환경에서 컨텍스트를 추론하고 다루는 능력에 기댑니다. Qwen3-8B 같은 작은 모델은 충분한 코딩 능력 없이는 RLM 역할을 못 했습니다. 그래서 8B는 그냥 못 쓰는 게 아니라 파인튜닝이 필요했습니다.
출력 토큰이 부족한 모델도 어렵습니다. Qwen3-235B-A22B를 RLM으로 시험했더니 base 대비 전반적으로 좋아지긴 했지만(OOLONG에서 \(30\%\)에서 \(38\%\)로) 메인 실험 모델만큼은 아니었습니다. 여러 트라젝토리가 출력 토큰을 소진하거나 thinking 토큰이 개별 호출의 최대 출력 길이를 넘겨서 멈췄기 때문입니다.
비동기 LM 호출이 없으면 느립니다. 구현에서 모든 sub-LM 쿼리를 blocking·sequential로 짰더니 base 모델 대비 느렸습니다. 견고하게 구현하면 풀 수 있다고 저자들은 봅니다.
최종 답과 다음 턴을 구분하는 게 모델에 따라 불안정합니다. root가 답을 FINAL()·FINAL_VAR() 태그로 감싸 구분하는 방식인데, 모델이 이상한 결정을 합니다(계획을 최종 답으로 출력하는 식). 파인튜닝 통계에서 \(16\%\)의 턴이 FINAL을 잘못 썼고 \(13\%\)가 REPL 변수를 최종 답으로 잘못 불렀습니다.
부록의 트라젝토리 예시 하나가 이 불안정성을 잘 보여줍니다. OOLONG-Pairs에서 Qwen3-Coder는 sub-call로 답을 이미 변수에 다 만들어 두고도, 자기 답을 받아들이지 못하고 5번이나 같은 과정을 재생성합니다. 마지막에 결국 root가 직접 답을 생성하는데, 정작 코드 환경에 쌓아둔 답은 끝내 반환하지 않습니다. RLM이 실패하는 한 양상입니다. 같은 단순 태스크를 GPT-5는 sub-call 열 개 정도로 끝냅니다.
저자들은 한계를 더 넓게도 인정합니다. RLM은 기존 LM 위에 복잡도를 한 겹 더 얹어, sub-call 비용 폭증 같은 의도치 않은 부작용을 부를 수 있습니다. 더 어렵고 자연스러운 long-context 태스크에 대한 평가와, RLM용 가드레일은 아직 탐구가 덜 됐다고 적습니다.
정리
- RLM은 긴 프롬프트를 신경망에 직접 먹이지 않고 REPL 환경의 변수로 올린 뒤, 모델이 코드로 들여다보고 자기 자신을 재귀 호출하게 하는 추론 패러다임입니다. 압축 없이, 출력 길이 제약 없이, 컨텍스트 창의 10M 토큰 이상을 다룹니다.
- 정보 밀도가 높아 압축이 무너지는 태스크(OOLONG-Pairs)에서 격차가 가장 큽니다. base가 0점대인 자리에서 RLM이 \(58\%\)를 내고, 비용은 베이스라인과 비슷하거나 더 쌉니다.
- RLM은 학습 가능한 축입니다. 1,000개 샘플 distill만으로 8B 모델이 평균 \(28.3\%\) 올랐습니다. 다만 코딩·출력 능력이 부족하거나 분해를 잘못 잡으면 오히려 손해라, 모델별 튜닝과 견고한 비동기 구현이 남은 과제입니다.