In-Context World Modeling for Robotic Control
S. Wang, J. Shi, S. Fei, Z. Fu, L. Ji, J. Gong, and X. Qiu, "In-Context World Modeling for Robotic Control," arXiv:2606.26025, 2026.
현장에서 새로운 카메라 각도로 로봇을 배치하면 성공률이 68%에서 17%로 추락합니다. 특정 시점에서 훈련된 VLA 모델이 시점이 바뀌는 순간 무너지는 것입니다. 이 논문은 그 원인을 "시스템 구성을 모르는 상태"로 정확히 지목하고, 사람이 낯선 조이스틱을 처음 다루는 방식과 똑같은 해법을 제안합니다. 작동 방식을 직접 건드려보면서 감을 잡는 것입니다.
저자
Siyin Wang과 Junhao Shi가 공동 1저자로 이 연구를 이끌었습니다. 두 사람 모두 Xipeng Qiu 교수 지도 아래 Fudan University에서 박사과정 중이며, OpenMOSS 그룹의 구현 AI 연구 라인을 잇고 있습니다. 이 팀은 앞서 "World Action Models" 서베이(arXiv:2605.12090)를 통해 세계 모델과 행동 생성의 통합 가능성을 논했는데, 이 논문은 그 방향의 구체적 구현에 해당합니다.
교신저자는 Jingjing Gong(Shanghai Innovation Institute OpenMOSS 그룹)과 Xipeng Qiu(Fudan University)가 공동으로 맡았습니다. Xipeng Qiu는 MOSS 오픈소스 LLM 개발과 FastNLP 툴킷으로 알려진 중국 NLP 분야의 대표적 교수입니다.
배경
현재 VLA 모델의 표준 공식은 다음과 같습니다.
\[\pi_\theta(a_t \mid o_t, l)\]
현재 관측 \(o_t\)와 언어 지시 \(l\)만을 입력으로 받아 행동 \(a_t\)를 예측합니다. 여기서 카메라 시점이나 로봇 형태 같은 시스템 구성 \(\psi\)는 훈련 중 고정된 상수로 취급됩니다.
이상적 정책은 \(\psi\)를 명시적으로 조건화해야 합니다.
\[\pi_\theta^*(a_t \mid o_t, l, \psi)\]
그러나 표준 VLA 훈련은 \(\psi\)를 무시하므로, 실제로는 학습 데이터 내 모든 구성에 걸쳐 평균화된 정책이 학습됩니다.
\[\pi_\theta(a_t \mid o_t, l) \approx \int \pi_\theta^*(a_t \mid o_t, l, \psi)\, p(\psi)\, d\psi\]
배포 시 특정 \(\psi'\)(예: 처음 보는 카메라 각도)가 주어지면, 이 평균화된 정책은 올바른 행동-관측 대응을 복원할 수단이 없습니다. 기존 대응책인 파인튜닝은 새 환경마다 데이터를 요구하고, 명시적 구성 입력(카메라 각도를 텍스트로 주는 방식)은 실제로 동역학을 이해하지 못합니다.
아이디어
ICWM은 이 문제를 시스템 식별(system identification)을 in-context 학습으로 푸는 문제로 재정의합니다.
핵심 통찰은 정보 이론적으로 정당화됩니다. 상호작용 컨텍스트 \(\mathcal{T} = (o_{0:t}, a_{1:t})\)는 단일 관측 \(o_0\)보다 시스템 구성 \(\psi\)에 대해 더 많은 정보를 담습니다.
\[I(\psi;\, o_{0:t},\, a_{1:t}) > I(\psi;\, o_0)\]
이 부등식이 임의의 행동 분포에 대해 성립하므로, 태스크와 무관한 랜덤 행동만으로도 \(\psi\)를 암묵적으로 드러낼 수 있습니다. 특정 데모나 보상 신호가 필요하지 않습니다.
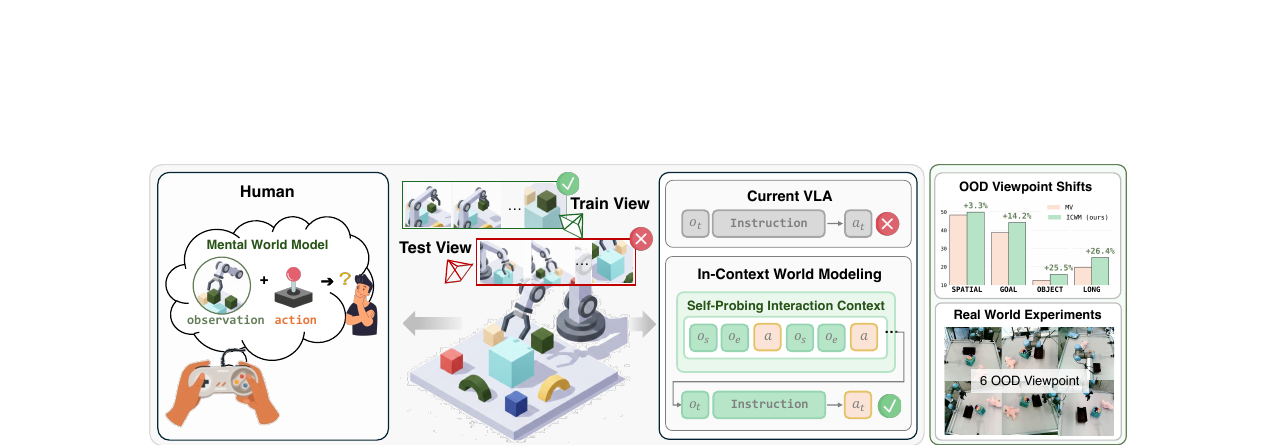
어떻게 작동하나
ICWM은 시작 이미지, 행동, 끝 이미지 \(N\)개를 상호작용 컨텍스트로 정의합니다.
\[\mathcal{T} = \left\{\left(o_i^s,\, a_i,\, o_i^e\right)\right\}_{i=1}^N\]
이를 바탕으로 정책을 다음과 같이 재공식화합니다.
\[a_t \sim \pi_\theta\!\left(a_t \mid \Psi(\mathcal{T}),\, o_t,\, l\right)\]
\(\Psi(\mathcal{T})\)는 컨텍스트에서 시스템 구성을 암묵적으로 추론하는 함수입니다. 구현의 핵심은 \(\Psi\)가 VLA 백본과 파라미터를 공유한다는 점입니다. 추가 파라미터가 전혀 없습니다. Transformer가 컨텍스트 \(\mathcal{T}\)를 먼저 처리한 후 태스크 쿼리 \((o_t, l)\)를 이어받으면, 그 히든 스테이트가 자연스럽게 구성-인식 표현이 됩니다.
훈련 손실은 단순합니다.
\[\mathcal{L} = -\log \pi_\theta\!\left(a_t \mid \Psi(\mathcal{T}),\, o_t,\, l\right)\]
컨텍스트 \(\mathcal{T}\)는 훈련 중 여러 시스템 구성의 궤적에서 랜덤하게 샘플링됩니다. 모델이 \(\mathcal{T}\)에 담긴 동역학 정보를 실제로 활용해야만 다양한 구성에서 행동을 정확하게 예측할 수 있으므로, 자연스럽게 암묵적 세계 모델링이 학습됩니다.
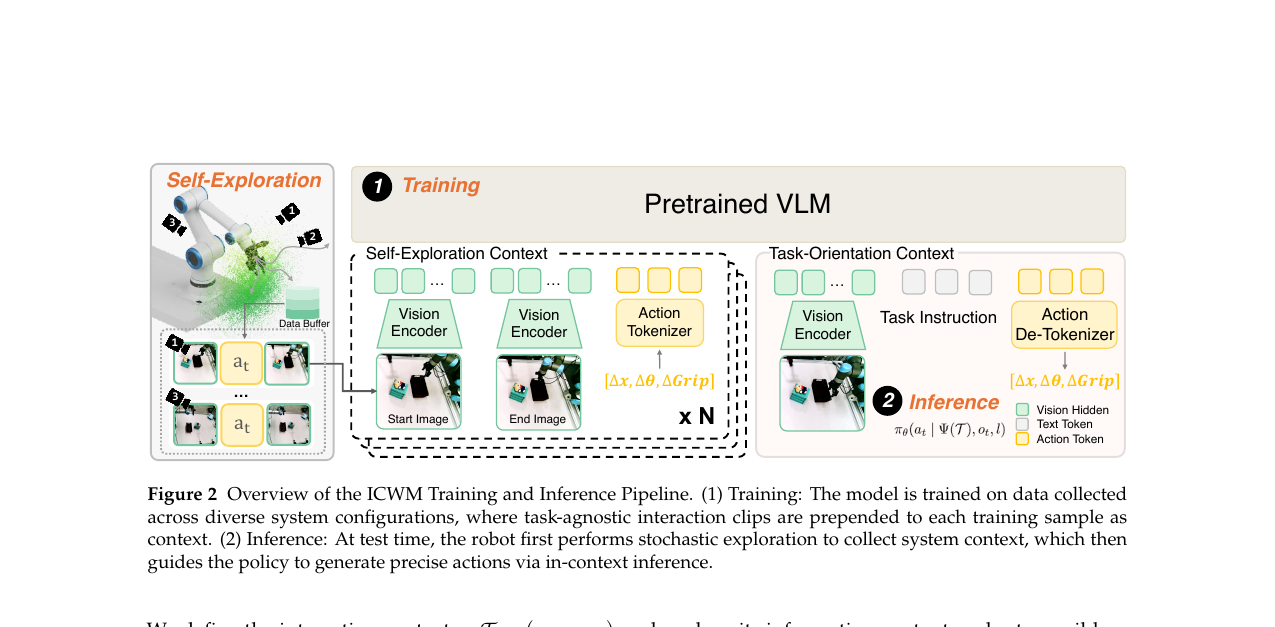
테스트 시 두 단계로 작동합니다.
먼저 Active Probing Phase에서 로봇이 태스크 실행 전 20개의 랜덤 탐색 행동을 수행합니다. 5-6초가 걸리는 이 탐색은 태스크와 무관하고, 태스크 관련 물체와의 충돌을 피해 안전 영역에서만 진행됩니다. 생성된 \((o_i^s, a_i, o_i^e)\) 트리플렛 20개가 컨텍스트 풀이 됩니다.
그다음 In-Context Execution Phase에서 매 추론 단계마다 이 풀에서 \(N=5\)개를 랜덤 샘플링해 컨텍스트로 주입합니다. \(\Psi(\mathcal{T})\)가 현재 카메라 시점·형태 구성을 히든 표현으로 인코딩하고, 그 위에서 태스크 행동을 생성합니다.
구현 백본은 Qwen2.5-VL-3B와 FAST 액션 토크나이저이며, 8개 NVIDIA A100 GPU에서 학습되었습니다.
결과
시뮬레이션 평가는 LIBERO 벤치마크 4개 수트(Spatial, Goal, Object, Long)를 사용합니다. 8개 방위각으로 훈련하고 6개 OOD 시점(\(45°, 135°, 225°, 255°, 285°, 315°\))에서 테스트하는 크로스-뷰 프로토콜을 적용합니다.
OOD 시점 성공률 (%)
수트 |
MV |
EXP |
ICWM |
|---|---|---|---|
Spatial |
48.3 |
46.3 |
49.9 |
Goal |
38.7 |
41.5 |
44.2 |
Object |
12.7 |
15.3 |
15.9 |
Long |
19.8 |
20.2 |
25.0 |
평균 |
29.9 |
30.8 |
33.8 |
MV(Multi-View BC)는 ICWM과 동일한 아키텍처·멀티뷰 데이터를 사용하되 컨텍스트가 없는 베이스라인이고, EXP(Explicit Configuration)는 카메라 각도를 텍스트로 직접 제공한 버전입니다. ICWM은 MV 대비 OOD 성공률을 상대적으로 13.0% 개선했고, 카메라 각도를 직접 알려주는 EXP보다도 9.5% 앞섰습니다.
특히 주목할 결과는 두 가지입니다. 첫째, 장기 태스크(Long)에서 격차가 가장 큽니다. ICWM이 MV 대비 26.3%p 향상(19.8 → 25.0)하는데, 이는 장기 태스크에서 시점 오류가 연쇄 실패로 증폭되기 때문입니다. 둘째, EXP(명시적 구성)보다 ICWM(암묵적 식별)이 더 낫습니다. 카메라 각도를 알려줘도 실제 동역학을 이해하는 것에는 못 미칩니다.
실제 로봇(UR5e, 6개 OOD 시점, 4개 조작 태스크)에서는 표준 VLA가 훈련 시점 68%에서 테스트 시점 17%로 추락한 반면, ICWM은 MV 대비 평균 71% 상대 향상을 달성했습니다. 적층(stacking) 태스크에서는 MV 대비 175% 향상으로 가장 드라마틱한 차이를 보였습니다.

컨텍스트 구성 요소 ablation(Table 1)에서 의미있는 결과가 나왔습니다.
컨텍스트 ablation (OOD 평균 성공률 %)
조건 |
평균 |
|---|---|
ICWM (full) |
25.0 |
w/o 행동 토큰 |
21.6 |
w/o 컨텍스트 |
22.0 |
잘못된 컨텍스트 |
18.9 |
w/o 이미지 토큰 |
10.9 |
이미지 토큰 제거 시 평균 56.4% 하락으로 가장 큰 충격입니다. 이미지 없이 행동만 보면 모델이 탐색 행동을 태스크 데모로 오해하기 때문입니다. 더 흥미로운 것은 잘못된 컨텍스트가 컨텍스트 없음보다 오히려 나쁩니다(18.9 vs 22.0). 180° 어긋난 시점의 클립을 주면 세계 모델이 능동적으로 오도됩니다. 이는 모델이 컨텍스트 내용을 실제로 사용하고 있다는 증거입니다.
t-SNE 시각화(Figure 7)에서 \(\Psi(\mathcal{T})\)의 표현이 6개 OOD 시점별로 명확하게 클러스터링됩니다. 같은 시점 내부는 응집되고, 시점 간에는 분리됩니다. 랜덤 탐색만으로도 시스템 구성을 구별 가능한 표현으로 인코딩함을 보여줍니다.
회고
저자들이 솔직하게 인정한 한계가 있습니다. 135° 시점은 모든 방법에서 공통적으로 어렵습니다. 이 각도에서 카메라가 일부 물체를 가리거나 작업 공간이 시야 밖으로 나가는 지각 제약이 원인으로, ICWM만의 실패가 아닌 방법론 공유 한계입니다.
의미론적 변화(물체 배치 변경, 테이블 텍스처)에서 ICWM의 이득(35.0 vs 27.5, 41.2 vs 37.5)은 시점 변화 대비 상대적으로 작습니다. 저자들은 현재 데이터셋에 장면-구성 다양성이 부족하기 때문이라고 귀인합니다. 더 다양한 훈련 데이터가 있으면 개선될 수 있습니다.
추론 레이턴시도 점검이 필요합니다. \(N=5\) 컨텍스트 클립 시 스텝당 0.185s로 베이스라인(0.112s) 대비 약 65% 증가합니다. 다만 컨텍스트 \(\mathcal{T}\)가 고정된 구성에서는 KV 캐싱으로 재사용 가능하므로, 실제 배포에서는 추가 비용이 크게 줄어듭니다.
숨겨진 가정 하나를 짚을 필요가 있습니다. 탐색 행동이 "태스크 물체와 충돌하지 않는다"는 안전 가정이 전제됩니다. 조작 공간이 복잡하거나 물체 밀도가 높은 환경에서는 이 가정이 성립하지 않을 수 있습니다. 또한 탐색 풀이 20개 행동으로 고정되어 있어, 더 복잡한 구성(예: 카메라가 매우 가깝거나 극단적 각도)에서 충분한 커버리지를 보장하는지는 추가 검증이 필요합니다.
정리
- VLA 일반화 실패의 원인을 시스템 구성 \(\psi\) 미조건화 문제로 명확히 정의하고, 이를 in-context 시스템 식별로 해결합니다.
- 추가 파라미터 없이, 태스크 데모 없이, 파라미터 업데이트 없이 새로운 시점·형태에 적응합니다.
- 랜덤 탐색 20회(5-6초)가 일회성 구성 비용의 전부이며, 이후 동일 구성의 모든 태스크에 재사용됩니다.