PlanBench-XL - Evaluating Long-Horizon Planning of LLM Tool-Use Agents in Large-Scale Tool Ecosystems
J. Liu, Q. Lin, C. Qian, R. Wang, E. C. Acikgoz, X. Yang, J. Liu, Z. Wang, X. Chen, H. Ji, and D. Hakkani-Tür, "PlanBench-XL: Evaluating Long-Horizon Planning of LLM Tool-Use Agents in Large-Scale Tool Ecosystems," arXiv:2606.22388, 2026.
저자
Heng Ji와 Dilek Hakkani-Tür가 지도하는 UIUC BLENDER Lab·ConvAI Lab 합동 연구입니다. 1저자 Jiayu Liu는 HKUST 학부생으로 UIUC 교환 연구 인턴 중 이 논문을 냈습니다. Heng Ji는 정보 추출과 지식 증강 LLM으로 잘 알려진 연구자이고, Dilek Hakkani-Tür는 Amazon Alexa·Google·Microsoft Research를 거쳐 2024년 학계로 복귀한 대화형 AI 전문가입니다. 두 교수가 같은 랩 공간을 공유하며 에이전트 평가 연구를 진행하고 있다는 점이 이 벤치마크의 배경입니다.
배경
LLM 에이전트가 실제로 쓰이는 환경을 생각해 보면, 도구는 많고 어떤 도구가 있는지 처음부터 다 보이지 않습니다. 엔터프라이즈 MCP 서버, 소프트웨어 생태계, 웹 API 플랫폼에는 수백에서 수천 개의 도구가 있고, 에이전트는 컨텍스트 길이 제한 때문에 매 스텝마다 일부만 검색해서 씁니다.
기존 벤치마크들은 이 현실을 온전히 반영하지 못했습니다. ToolBench, ToolRet, MCPBench 같은 대규모 도구 벤치마크들은 도구 선택 범위는 넓지만 명시적인 목표를 전제하는 경우가 많았습니다. EscapeBench나 MCP-Universe처럼 암묵적 서브골 해결에 집중한 벤치마크는 도구가 항상 신뢰 가능하다는 가정을 유지했습니다. 대규모 도구 생태계 + 부분 가시성 + 도구 불신뢰성 + 장기 계획을 동시에 평가한 벤치마크는 없었습니다.
PlanBench-XL이 다루는 핵심 질문은 하나입니다. 에이전트가 필요한 도구를 단계적으로 발굴하고, 어떤 경로가 막혔을 때 다른 경로로 실시간 재계획할 수 있는가.
어떻게 만들었나
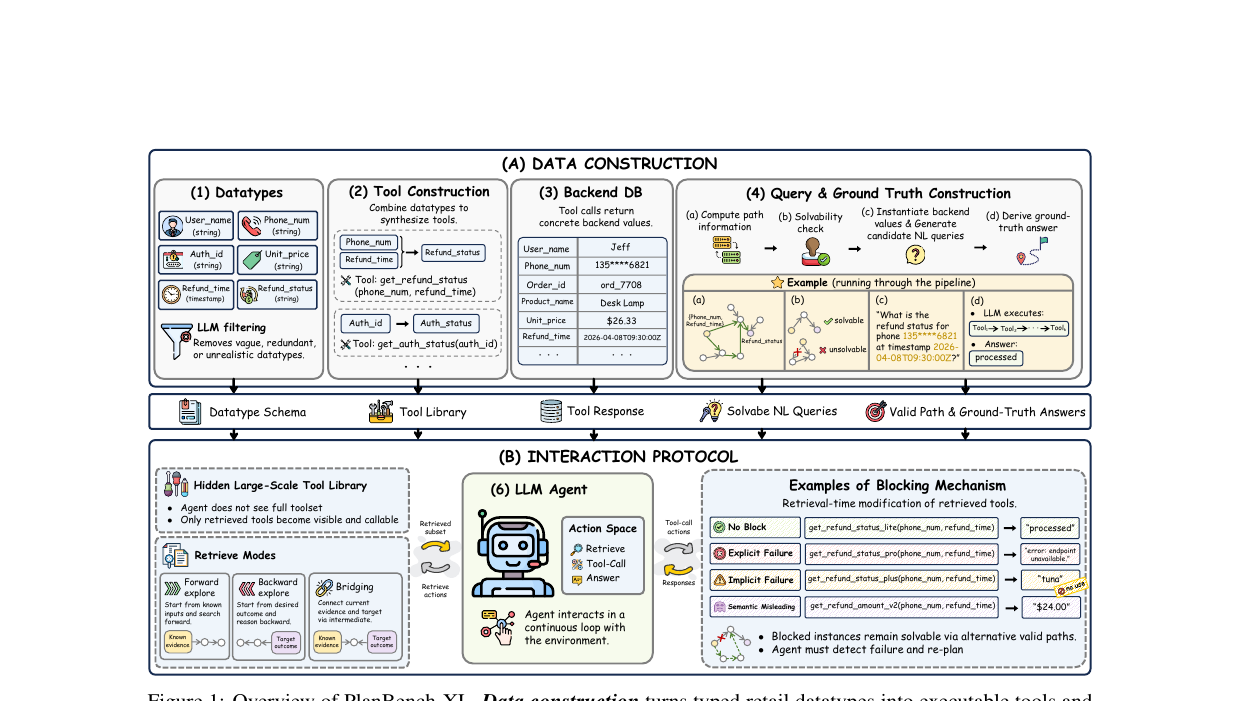
벤치마크는 두 단계로 구성됩니다. (A) 데이터 구성과 (B) 인터랙션 프로토콜입니다.
도구 라이브러리 구성. 소매(retail) 도메인에서 56개 자체 정의 데이터타입(person_name, refund_status 등)을 설계합니다. 각 데이터타입 쌍 \((D_{in}, D_{out})\)에 대해 생성 LLM \(M_{gen}\)이 도구 기능을 제안하고, 필터 LLM \(M_{fil}\)이 모호하거나 중복된 것을 제거합니다. 최종 라이브러리는 1,665개 도구. 여기에 기능은 비슷하지만 설명에 자신의 불신뢰성을 명시하는 노이즈 도구도 추가해 실제 생태계의 혼잡함을 재현합니다.
쿼리 생성. 각 태스크는 \(r = (D_0, Y)\)로 정의됩니다. \(D_0\)은 초기 입력 데이터타입, \(Y\)는 목표 데이터타입입니다. 코드로 상태 그래프를 구성해 \(D_0\)에서 \(Y\)까지 도달 가능한 도구 호출 경로 집합 \(\Pi(r)\)을 계산합니다. \(\Pi(r) = \emptyset\)이면 버립니다. 최단 경로가 도구 호출 5번 미만인 것도 버립니다. 최종 327개 인스턴스, 평균 약 25턴.
인터랙션 루프. 에이전트는 매 스텝에서 세 가지 중 하나를 택합니다: retrieve(도구 검색), tool-call(검색된 도구 실행), answer(최종 답 제출). 검색은 세 방향으로 가능합니다.
- 순방향 탐색(Forward Anticipation): 현재까지 확보한 데이터타입에서 연결 가능한 도구를 찾습니다.
- 역방향 탐색(Backward Anticipation): 목표 데이터타입을 만들려면 어떤 도구가 필요한지 거꾸로 추론합니다.
- 입출력 조건부 탐색(Bridging): 현재 상태와 목표를 동시에 지정해 중간 단계를 연결합니다.
차단 메커니즘. 평가의 핵심 독창성입니다. 유효 경로에 있는 도구를 에이전트 몰래 대체합니다. 세 종류가 있습니다.
차단 유형 |
대체 도구 반응 |
|---|---|
명시적 실패(Explicit) |
"error: endpoint unavailable" |
암묵적 실패(Implicit) |
표면상 정상적인 값이지만 틀린 값 (예: "tuna") |
의미적 오도(Misleading) |
유사하지만 기능이 다른 도구로 교체 |
차단된 인스턴스는 반드시 하나 이상의 대안 경로가 남아 있도록 설계됩니다. 즉, 막힌 것을 알아채고 다른 길을 찾으면 풀 수 있습니다.
결과
10개 모델로 기본 설정(block 없음)을 평가한 결과입니다.
모델 |
정확도 (%) |
EGT Prec. (%) |
평균 턴 |
Mean EDT |
ITCR (%) |
|---|---|---|---|---|---|
Qwen3-8B |
0.00 |
35.31 |
25.65 |
7.64 |
6.11 |
Qwen3-14B |
0.92 |
47.77 |
35.74 |
12.01 |
3.94 |
Qwen3-32B |
2.75 |
62.36 |
12.03 |
18.54 |
10.05 |
Llama-3.1-8B |
0.00 |
41.33 |
21.62 |
9.89 |
18.03 |
Llama-3.3-70B |
18.96 |
59.67 |
19.13 |
19.20 |
21.47 |
DeepSeek-V4-Flash |
63.08 |
65.57 |
31.41 |
25.34 |
8.27 |
Gemini-3.1-Pro |
77.06 |
91.47 |
19.55 |
27.41 |
0.68 |
Gemini-3.5-Flash |
52.19 |
85.29 |
57.87 |
25.16 |
2.94 |
GPT-5.4-Mini |
3.07 |
71.25 |
10.81 |
9.22 |
51.71 |
GPT-5.4 |
51.90 |
72.92 |
22.92 |
20.65 |
6.28 |
Gemini-3.1-Pro가 77.06%로 1위입니다. 하지만 이 숫자 자체보다 중요한 것은 이 숫자가 얼마나 작은가입니다. 두 번째로 강한 모델인 DeepSeek-V4-Flash도 63%에 그치고, GPT-5.4는 52%, Llama-3.3-70B는 19%입니다. 대규모 도구 생태계에서 에이전트의 장기 계획은 현재 최고 모델조차도 어려운 과제입니다.
도구 발견 너비(Mean EDT)와 정확도의 상관관계. Pearson \(r = 0.902\)로, 에이전트가 더 많은 중간 데이터타입을 발굴할수록 정확도가 높습니다. 그러나 발굴 너비가 전부가 아닙니다. Llama-3.3-70B는 Mean EDT 19.20으로 GPT-5.4(20.65)에 근접하지만 정확도는 19% vs 52%로 큰 차이가 납니다. 역방향 탐색 비중이 낮을수록 정확도도 낮았습니다(출력 조건부 검색 비율과 정확도 Pearson \(r = 0.800\)).
차단 조건. 차단 비율이 높아질수록 성능이 급감합니다. GPT-5.4는 차단 비율 1.0(단 하나의 경로만 남은 경우) 조건에서 약 30%로 떨어지고, 그 남은 경로가 최장 경로(longest path)일 때는 11.36%까지 붕괴합니다.
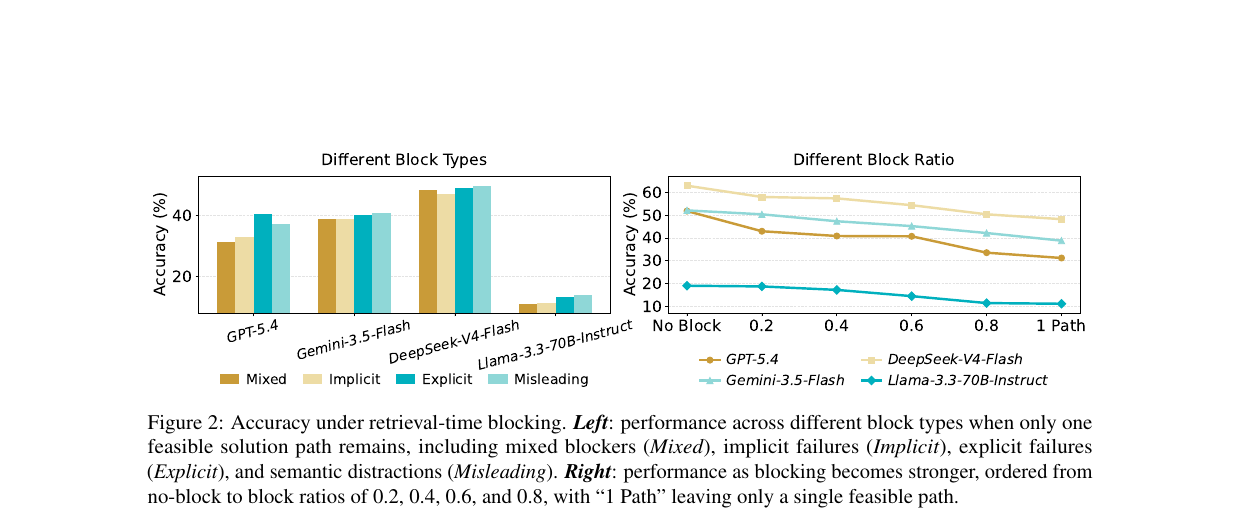
암묵적 실패가 세 유형 중 가장 해롭습니다. UIRR(신뢰불가 입력 사용률) 기준으로 암묵적 실패 11.99%, 명시적 실패 9.67%, 의미적 오도 9.89% 순입니다. 틀린 값을 오류 신호 없이 반환하는 도구가 에이전트를 가장 많이 오염시킵니다.
분석: 실패는 어디서 오는가
논문이 가장 공을 들인 부분이 오류 분석입니다. 실패를 단순히 수치로 집계하지 않고 궤적 단위에서 해부합니다.
궤적 이탈이 주된 실패 원인입니다. 실패 궤적의 대부분은 초반에 일부 진전을 이루다가 유효 경로에서 벗어나고, 이후 회복하지 못합니다. GPT-5.4의 72.4%, Gemini-3.5-Flash의 71.3%가 "비가역적 이탈(Irrecoverable Drift)"입니다. 반면 이탈 후 회복해 최종 실패한 "약한 회복(Weak Recovery)"은 전체 실패의 3.0%뿐입니다.
실패는 검색 문제가 아니라 선택 문제입니다. 가장 놀라운 발견입니다. 비-진전 호출(non-progress call)이 일어나기 직전, 에이전트는 이미 진전 가능한 도구를 히스토리에 갖고 있었던 경우가 기본 설정에서 78.0%, 차단 설정에서 71.1%였습니다. 즉, 대부분의 실패는 도구를 못 찾아서가 아니라 이미 찾아뒀던 도구를 제때 고르지 못해서 발생합니다.
에이전트는 최근에 검색한 도구를 과도하게 선호합니다. 비-진전 호출의 74.1%(기본)·63.6%(차단)이 최근 검색 창의 도구를 사용했습니다. 반면 진전을 만들 수 있었던 도구는 44.7%·43.2%의 경우에서 두 검색 창 이상 이전에 검색된 것이었습니다.
모델별 실패 스타일이 다릅니다. 실패 후 각 모델은 서로 다른 종료 행동을 보였습니다.
- GPT-5.4: 기본 설정 비상호작용 실패의 77.3%가 항복("답을 확정할 수 없다") 선언. 차단 조건에서는 80.6%.
- DeepSeek-V4-Flash·Llama-3.3-70B: 잘못된 도구 반환값을 최종 답으로 제출(DeepSeek 58.8%, Llama 81.7%).
- Gemini-3.5-Flash: 실패의 90.8%가 검색 소진. 종료 없이 계속 검색하다 예산을 소진합니다. S/C 비율도 다른 모델보다 훨씬 높은 10.44.
이 차이는 차단·경로 길이 조건이 바뀌어도 일관성 있게 유지됩니다. 즉, 각 모델의 실패 스타일은 외부 조건이 변해도 잘 바뀌지 않습니다.
회고
저자들이 직접 인정한 한계입니다.
소매 도메인 단일화. 327개 태스크가 모두 소매 워크플로우에서 나왔습니다. 단일 도메인이 실세계 도구 사용 다양성을 충분히 대표하지 못할 수 있습니다. 다만 데이터타입 기반 생성 파이프라인은 확장 가능하게 설계되어 있어 다른 도메인 추가는 향후 작업으로 남깁니다.
차단 유형의 추상화. 명시적·암묵적·의미적 실패 세 유형이 실세계의 모든 도구 장애를 커버하지는 못합니다. 통제된 실험을 위해 현실성의 일부를 희생했습니다.
자체 검색기 사용. 재현성을 위해 자체 검색기를 썼지만, 실제 배포 환경의 검색 시스템(순위 오류, 문서 잡음, 도구 카탈로그 변동)은 이 벤치마크보다 더 까다롭습니다.
정리
- 1,665개 도구 생태계에서 327개 소매 태스크를 평가한 결과, 최고 모델 Gemini-3.1-Pro도 77%로, 나머지 모델들은 훨씬 낮습니다.
- 차단 조건에서 GPT-5.4는 51.9%에서 11.36%로 붕괴합니다. 조용한 암묵적 실패가 명시적 오류보다 훨씬 해롭습니다.
- 대부분의 실패는 도구 발굴 부족이 아니라 이미 발굴된 도구를 제때 선택하지 못하는 선택 병목에서 옵니다. 더 많이 검색한다고 해결되지 않으며, 추론 시간 계산을 늘려도 5%포인트 미만의 개선에 그쳤습니다.