EvoPolicyGym - Evaluating Autonomous Policy Evolution in Interactive Environments
Z. Wang, H. Song, R. Zhan, J. Du, J. Chen, T. Li, Q. Yin, Y. Wu, Z. Shen, T. Zhu, Y. Li, G. Chen, D. F. Wong, Y. Li, Y. Cheng, and Y. Yang, "EvoPolicyGym: Evaluating Autonomous Policy Evolution in Interactive Environments," arXiv:2607.02440, 2026.
저자
USTC·CUHK·U Macau·Tsinghua·Zhejiang·SJTU 소속 공동 연구팀이 작성한 논문입니다. Zhilin Wang(USTC), Han Song(CUHK), Runzhe Zhan(U Macau) 세 명이 공동 1저자이며, 교신저자는 Yu Cheng(CUHK), Yang Yang(SJTU), Yafu Li(CUHK)입니다.
이 연구가 출발점으로 삼은 계기는 Jiayi Weng의 블로그 포스트 "Learning Beyond Gradients"입니다. 코딩 에이전트가 정책 파일을 일회성으로 생성하는 데 그치지 않고 지속적으로 유지·개선할 수 있다는 발상이 이 연구의 시작이었습니다. "heuristic"이라는 단어가 손으로 작성한 규칙인지 튜닝된 파라미터인지 점점 구분하기 어려워지는 상황에서, 팀은 실행 가능한 정책 시스템 전체를 벤치마크 대상으로 삼기로 결정했습니다.
배경
강화학습 에이전트 평가에서 오랫동안 쓰인 척도는 "최종 점수"입니다. 에피소드가 끝난 뒤 누적 보상이 얼마인가. 그런데 이 숫자에는 두 가지 정보가 없습니다. 에이전트가 어떻게 그 점수에 도달했는가, 그리고 128회 실행 기회를 어떻게 배분했는가.
기존 코딩 에이전트 평가(SWE-bench 등)는 오픈엔드 소프트웨어 엔지니어링 태스크를 쓰는데, 여기에는 변화하는 명세·멀티파일 일관성·누락 검증 같은 혼재 변수가 많습니다. 코딩 에이전트의 "정책 진화 능력"만 순수하게 분리하기 어렵습니다.
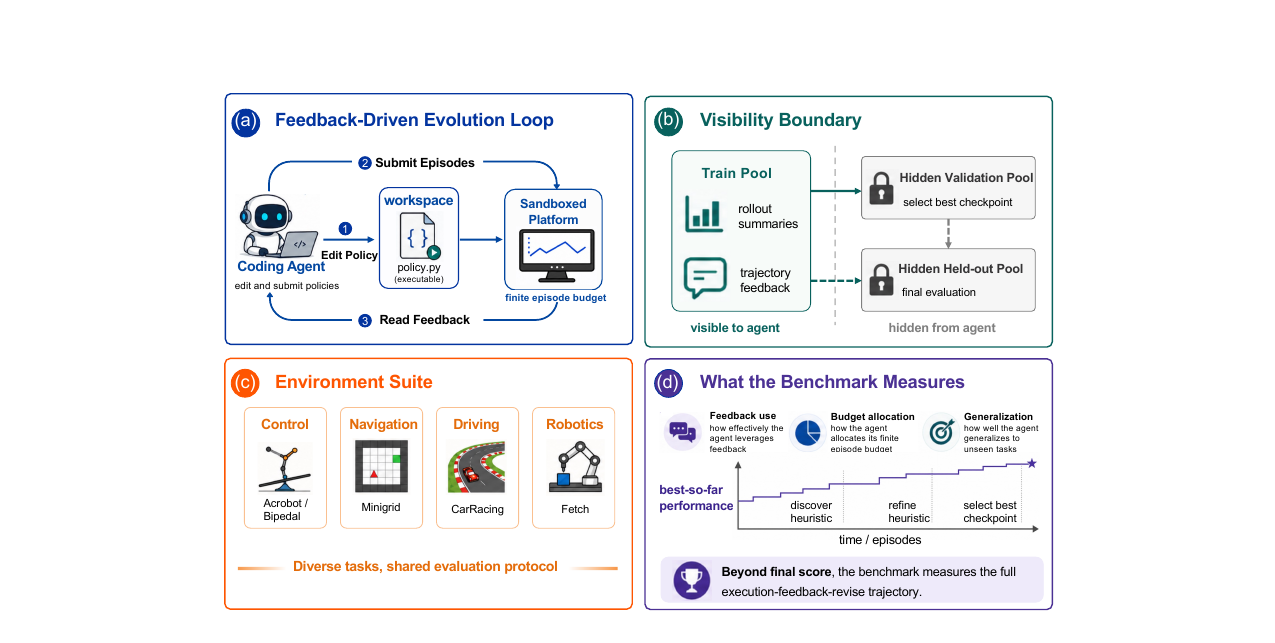
EvoPolicyGym은 이 두 문제를 동시에 다룹니다. 에이전트는 단일 실행 가능한 정책 파일(policy.py)과 그 임포트 모듈만 편집할 수 있습니다. 피드백은 에피소드 롤아웃 요약으로만 들어오고, 검증 풀과 held-out 풀은 에이전트에게 보이지 않습니다. 통제된 조건에서 "피드백을 코드 개선으로 전환하는 능력"만 측정하는 구조입니다.
어떻게 만들었나
APE 프로토콜
EvoPolicyGym의 핵심 개념은 **자율 정책 진화(Autonomous Policy Evolution, APE)**입니다. 에이전트는 고정된 \(B = 128\)회 에피소드 예산 안에서 정책을 반복 수정합니다. 한 번의 제출이 일부 에피소드를 소모하고, 그 롤아웃 요약·궤적 피드백이 다시 에이전트에게 돌아옵니다. 에이전트는 이를 읽고 다음 정책 버전을 씁니다.
평가는 두 단계로 나뉩니다. 에이전트가 제출한 체크포인트 중 **히든 검증 풀(hidden validation pool)**이 가장 좋은 것을 골라 히든 held-out 풀에서 최종 점수를 매깁니다. 에이전트는 검증 결과를 직접 볼 수 없으므로, 예산을 아끼거나 보이는 피드백에 과적합하는 행동은 held-out에서 패널티를 받습니다.
Core16 환경
논문은 프로토콜을 Core16이라는 16개 환경 묶음으로 실체화했습니다. 네 계열로 구성됩니다.
- Gym/Box2D: Acrobot, BipedalWalker, CartPole, LunarLander, MountainCar
- MuJoCo: Ant, HalfCheetah, Hopper, Humanoid, Walker2d
- MiniGrid: ContinuousCar, FourRooms, KeyCorridor, ObstructedMaze
- Robotics/Driving: CarRacing, Fetch, Roundabout
각 환경은 동일한 reset/step 인터페이스를 공유하며, 에이전트는 관찰을 픽셀 대신 구조화된 텍스트로 받습니다. 128회 예산, 샌드박스 플랫폼, 공통 제출 인터페이스가 모든 환경에 동일하게 적용됩니다.
구조적 합성 vs 파라메트릭 튜닝
논문이 측정하는 두 가지 개선 경로가 있습니다. **구조적 합성(structural synthesis)**은 새 제어 구조·보조 모듈·지각 서브루틴을 코드에 추가하는 방식입니다. **파라메트릭 튜닝(parametric tuning)**은 기존 구조를 유지한 채 수치 파라미터만 조정하는 방식입니다.
논문은 policy.py와 임포트 가능한 로컬 모듈의 AST 위상(함수 수·클래스 수·임포트 수·모듈 수·전체 라인 수)을 결정론적으로 측정합니다. 합성-우세 환경(BipedalWalker, HalfCheetah, CarRacing 등)에서 상위 에이전트는 AST 크기가 눈에 띄게 큽니다. GPT-5.5는 합성-우세 환경에서 평균 68.2개 함수를 선택 체크포인트에 담은 반면, DeepSeek-V4-Pro는 21.8개에 그칩니다.
다만 논문 자신이 명시하듯, AST 위상은 보수적인 대리 지표입니다. 두 위상이 유사한 동작을 구현할 수 있고, 하나의 위상이 유용한 아이디어와 해로운 아이디어를 함께 담을 수 있습니다.
결과
Core16 리더보드
모델 |
하네스 |
Gym/Box2D |
MuJoCo |
MiniGrid |
Robotics/Driving |
Core16 |
승 |
Top-2 |
|---|---|---|---|---|---|---|---|---|
GPT-5.5 |
Codex |
0.938 |
0.875 |
0.812 |
0.938 |
0.891 |
9 |
16 |
Claude Opus 4.7 |
Claude Code |
0.812 |
0.750 |
0.938 |
0.500 |
0.750 |
5 |
12 |
MiniMax-M3 |
Claude Code |
0.375 |
0.625 |
0.500 |
0.625 |
0.531 |
1 |
3 |
DeepSeek-V4-Pro |
Claude Code |
0.375 |
0.250 |
0.438 |
0.375 |
0.359 |
1 |
1 |
Random |
-- |
0.000 |
0.000 |
0.375 |
0.062 |
0.109 |
0 |
0 |
GPT-5.5가 Core16 종합 점수 0.891로 1위를 차지하고, 16개 환경 모두 Top-2에 들어갑니다. Claude Opus 4.7은 0.750으로 2위이며, MiniGrid 계열에서는 오히려 GPT-5.5를 앞섭니다(0.938 vs 0.812). ContinuousCar, Ant, KeyCorridor, FourRooms, ObstructedMaze 다섯 개는 Claude Opus 4.7이 1위입니다.
MiniMax-M3와 DeepSeek-V4-Pro는 각각 환경 하나씩을 이기지만 종합 점수는 크게 낮습니다. 랜덤 정책(0.109)과 비교해도 격차가 벌어집니다. 리더보드는 단순한 승패 집계가 아니라 일관된 상위권 유지를 요구한다는 것이 드러납니다.
한 가지 실험 조건의 차이가 있습니다. GPT-5.5는 Codex 하네스를, 나머지 세 모델은 모두 Claude Code 하네스를 씁니다. 모델 능력과 하네스 효율을 분리하는 통제 실험은 이번 논문에 포함되지 않았습니다.
예산 소비 궤적
점수 진화 커브(Figure 3)는 각 에이전트가 128회 예산을 어떻게 쓰는지 보여줍니다. GPT-5.5와 Claude Opus 4.7은 초기 탐색 이후 빠르게 점수가 오르고 후반에 안정화하는 경향을 보입니다. MiniMax-M3와 DeepSeek-V4-Pro는 후반 개선폭이 제한적입니다. "어떤 에피소드에서 점수가 도약했는가"를 볼 수 있는 이 궤적이 논문이 추가로 제공하는 진단 정보입니다.
회고
저자들이 직접 인정한 한계가 세 가지입니다.
첫째, AST 진단은 보수적 대리 지표입니다. 코드 위상이 바뀌어도 동작이 같을 수 있고, 위상이 같아도 전략이 다를 수 있습니다. 의미 수준의 증명이 아닙니다.
둘째, 소스 번들 경계가 있습니다. policy.py와 임포트 가능한 로컬 모듈만 추적하며, 에이전트가 생성한 데이터 파일·학습된 가중치·참조되지 않은 실험 파일은 제외됩니다.
셋째, 합성/튜닝 분리는 렌즈입니다. BipedalWalker는 구조 합성이 우세하지만 나중에 파라미터 튜닝도 필요하고, CarRacing은 파라미터 선택 전에 지각·제어 구조가 먼저 갖춰져야 합니다. 단일 분류 체계가 아닌 분석 시각으로 봐야 합니다.
GPT-5.5와 나머지 모델이 다른 하네스를 쓴다는 점도 해석에 주의가 필요합니다. Codex 하네스와 Claude Code 하네스의 성능 차이가 얼마나 모델 능력 차이를 증폭하는지는 이 논문으로 분리할 수 없습니다.
정리
- 에이전트가 실행 가능한 정책 코드를 128회 에피소드 예산 안에서 반복 개선하는 능력을 측정하는 벤치마크입니다. 히든 검증·held-out 풀로 보이는 피드백 과적합을 방지합니다.
- GPT-5.5가 Core16 16개 환경 모두 Top-2로 종합 1위(0.891). Claude Opus 4.7은 MiniGrid에서 가장 강하고 종합 2위(0.750). 궤적 진단이 점수와 함께 공개됩니다.
- 구조적 합성(코드 구조 추가)과 파라메트릭 튜닝(수치 조정)의 두 개선 경로를 AST 위상으로 추적합니다. 강한 에이전트는 합성-우세 환경에서 눈에 띄게 더 많은 함수·모듈을 선택합니다.