HLL - Can Agents Cross Humanity's Last Line of Verification
X. Song, S. Su, S. Song, H. Wu, et al., "HLL: Can Agents Cross Humanity's Last Line of Verification?," arXiv:2606.02449, 2026.
멀티모달 에이전트가 사람을 대신해 브라우저와 앱을 조작하기 시작했습니다. 그런데 실제 서비스를 끝까지 통과하려면 화면을 읽고 누르는 것만으로는 부족합니다. 계정 생성, 콘텐츠 접근, 결제 앞에는 거의 항상 "당신은 사람입니까"를 묻는 관문이 있습니다. 바로 CAPTCHA입니다.
쑹신하오 외 연구진이 내놓은 HLL(Humanity's Last Line of Verification)은 이 질문을 정면으로 다룹니다. CAPTCHA를 단순한 이미지 인식 문제가 아니라, 에이전트가 사람을 대신할 수 있는지를 재는 마지막 검증 병목으로 보고, 그 경계를 실제 상호작용으로 넘을 수 있는지 측정합니다. 결론부터 말하면, 지금의 프런티어 에이전트는 깨끗한 환경에서는 곧잘 풀지만 현실 조건이 들어오는 순간 빠르게 무너집니다.
저자
이 논문은 상하이교통대학교가 주도하고 산둥대·퉁지대가 함께한 작업입니다. 1저자는 쑹신하오이고, 교신저자는 두 명입니다.
장린펑은 상하이교통대 EPIC 랩을 이끄는 효율적 AI 연구자입니다. 지식 증류와 모델 압축이 전문인 그가 에이전트 평가에 합류한 것은, 모델을 더 가볍게 만드는 일만큼이나 그 모델이 실제 배포 환경에서 견고하게 작동하는지를 측정하는 일이 중요하다는 문제의식으로 읽힙니다.
다른 교신저자 류둥루이는 상하이 AI 연구소에서 AI 안전·설명가능성을 연구합니다. 그에게 CAPTCHA는 자연스러운 소재입니다. CAPTCHA는 봇과 사람을 가르려고 일부러 세운 방어선이고, 에이전트가 그것을 넘을 수 있는지는 곧 자동화 악용의 위험을 가늠하는 안전 문제이기 때문입니다. NLP 보안을 연구하는 류궁선가 공동저자로 참여한 것도 같은 맥락입니다.
배경
기존 웹·GUI 에이전트 벤치마크는 내비게이션과 작업 완수를 주로 봅니다. WebArena, Mind2Web, OSWorld 같은 환경이 그렇습니다. 그런데 이런 벤치마크는 CAPTCHA가 나오면 대개 그 페이지를 걸러내거나, 본 작업을 방해하는 부수적 장애물 정도로 취급합니다.
CAPTCHA 자체를 다룬 연구도 빈자리가 있습니다. 상당수가 인식 정확도나 통과율 같은 최종 정답에 초점을 둡니다. 정답을 맞혔는지만 보면, 그 정답이 인식 실패에서 왔는지, 클릭 위치가 어긋나서 왔는지, 상태 추적이 무너져서 왔는지를 구분할 수 없습니다. 같은 정답이 전혀 다른 실패 모드를 가릴 수 있는 것입니다.
HLL은 이 둘 사이를 메웁니다. CAPTCHA 풀이를 "최종 정답 하나"가 아니라 "지각 → 위치 파악 → 행동 실행 → 제출"로 이어지는 끝에서 끝까지의 상호작용으로 보고, 그 파이프라인의 어디가 먼저 부러지는지를 진단합니다.
어떻게 만들었나
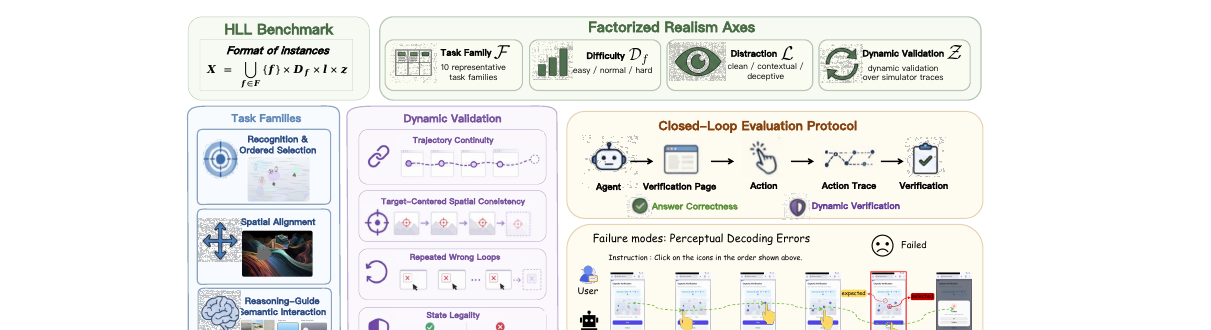
HLL의 핵심은 CAPTCHA 문제를 인수분해(factorize)한 설계입니다. 하나의 벤치마크 인스턴스는 다섯 요소의 튜플로 정의됩니다.
\[x = (f, d, \ell, z, s) \in \mathcal{X} = \bigcup_{f \in \mathcal{F}} \{f\} \times D_f \times L \times \{0, 1\} \times S\]
여기서 \(f\)는 CAPTCHA 과제군의 종류, \(d\)는 과제 자체의 난이도, \(\ell\)은 주변 웹페이지가 얼마나 어수선한지(방해 수준), \(z\)는 행동 궤적 검증을 켤지 끌지를 정하는 플래그, \(s\)는 같은 설정의 반복 인덱스입니다. 문제의 본질(어떤 CAPTCHA인가)과 현실성 조건(어떤 상황에서 푸는가)을 분리한 것이 핵심입니다.
과제군은 10개이고, 각 과제군은 하나의 지배적 능력에 매핑됩니다.
\[g : \mathcal{F} \to \mathcal{G}, \quad \mathcal{G} = \{\text{Recognition}, \text{Spatial}, \text{Stateful}, \text{Reasoning}\}\]
텍스트 전사나 아이콘 순서 선택은 인식·순차 선택, 슬라이더·직소 정렬은 공간적 정밀도, 보드 재구성·타일 복원은 상태 추적, 논리·산술 상호작용은 추론을 주로 시험합니다. 저자들은 능력이 깔끔하게 분리된다고 주장하지 않습니다. 다만 각 과제군이 가장 잘 드러내는 병목을 표시할 뿐입니다.
그 위에 세 가지 현실성 축이 얹힙니다. 난이도(\(d\)), 방해(\(\ell\)), 동적 검증(\(z\))입니다. 과제군이 기여하는 평가 셀의 수는 다음과 같이 셉니다.
\[m(f) = 2 + \mathbb{1}[f \in \mathcal{F}_{\text{hard}}] + \mathbb{1}[f \in \mathcal{F}_{\text{dyn}}], \quad M = \sum_{f \in \mathcal{F}} m(f) = 33\]
기본 두 셀은 깨끗한 정적 환경과 방해가 있는 정적 환경입니다. 여기에 더 어려운 변형이나 동적 검증을 지원하는 과제군이 셀을 추가해 총 33개가 됩니다.
세 축 중에서 가장 독창적인 것은 동적 상호작용 검증입니다. 정적 설정에서 성공은 제출한 최종 답이 맞는지만 봅니다.
\[S_{\text{static}}(x, \tau) = \mathbb{1}[\hat{y}(\tau) = y_x]\]
반면 동적 설정에서는 정답이 맞더라도, 그 답에 도달한 행동 궤적이 의도된 풀이 과정과 일관될 때만 성공으로 인정합니다.
\[S(x, \tau) = S_{\text{static}}(x, \tau) \cdot \begin{cases} 1, & z = 0 \\ V_f(\tau), & z = 1 \end{cases}\]
여기서 \(V_f(\tau)\)는 과제군별 검증기로, 시뮬레이터가 관측할 수 있는 상호작용 증거만 봅니다. 모델 내부의 추론 과정은 들여다보지 않습니다. 드래그가 실제로 일어났는지, 클릭 패턴이 사람처럼 그럴듯한지, 같은 오답을 반복하며 헤매지 않았는지, 상태 변화가 규칙에 맞게 일어났는지를 확인합니다. 정답을 우연히 맞히는 것과, 사람이 풀듯 유효한 행동으로 도달하는 것을 구분하는 장치입니다.
평가는 닫힌 루프에서 이뤄집니다. 에이전트는 페이지를 관측하고 GUI 행동을 내며, 제출하거나 예산이 소진되거나 시간이 초과될 때까지 상호작용을 이어 갑니다. 하나의 롤아웃은 관측과 행동의 시퀀스 \(\tau_\pi(x) = (o_0, a_0, o_1, a_1, \ldots, o_T, a_T)\)로 표현됩니다.
결과
8개 프런티어 멀티모달 에이전트를 평가했습니다. GPT-5.4, Gemini-3.1-Pro, Claude-Sonnet-4.6, Claude-Opus-4.6, Grok-4, 그리고 GLM-5V, MiniMax-M2.7, Qwen-Max입니다.
먼저 깨끗한 화면에서의 기본 정적 성능입니다.
모델 |
정적 성공률 평균 (%) |
|---|---|
Claude-Opus-4.6 |
90.0 |
Gemini-3.1-Pro |
73.8 |
GPT-5.4 |
70.0 |
Grok-4 |
58.2 |
Claude-Sonnet-4.6 |
35.4 |
MiniMax-M2.7 |
20.2 |
GLM-5V |
16.2 |
Qwen-Max |
9.4 |
Claude-Opus-4.6가 가장 강하지만 포화 상태는 아닙니다. 순서가 있는 아이콘 선택과 보드 재구성에서 잔여 오류가 남습니다. 깨끗한 정적 환경에서도 단순 시각 인식이 아니라 지각과 행동의 조율이 병목이라는 뜻입니다. 약한 모델들은 텍스트가 아닌 과제군에서 사실상 0점에 가깝습니다.
방해 요소(어수선하거나 기만적인 주변 콘텐츠)를 넣으면 대부분 성능이 떨어지지만, 그 정도는 고르지 않습니다. 난이도를 직접 올린 하드 변형에서는 가장 강한 모델조차 폭넓게 무너집니다. Claude-Opus-4.6가 하드 변형 평균 62.0으로 가장 견고했고, GPT-5.4는 37.0, Gemini-3.1-Pro는 24.0으로 정렬·복원 과제에서 특히 크게 떨어졌습니다.
가장 흥미로운 결과는 동적 검증입니다. 행동 궤적까지 일관돼야 한다는 조건이 붙는 순간, 정적에서 잘하던 모델들의 순위가 뒤집힙니다.
모델 |
정적 평균 (%) |
동적 평균 (%) |
|---|---|---|
Gemini-3.1-Pro |
71.3 |
45.0 |
GPT-5.4 |
65.8 |
26.3 |
Claude-Opus-4.6 |
88.0 |
23.8 |
Grok-4 |
51.0 |
11.3 |
MiniMax-M2.7 |
11.9 |
2.5 |
Qwen-Max |
0.7 |
2.5 |
GLM-5V |
10.3 |
1.3 |
Claude-Sonnet-4.6 |
29.6 |
0.7 |
정적에서 88.0으로 압도적이던 Claude-Opus-4.6가 동적에서는 23.8까지 떨어지고, 정적 71.3이던 Gemini-3.1-Pro가 동적 45.0으로 1위가 됩니다. 최종 답은 의미적으로 맞혀도, 그 답을 뒷받침하는 중간 행동 시퀀스가 제약을 만족하지 못하는 경우가 많다는 것입니다. 동적 검증이 지각 난이도를 올리는 게 아니라, 그것과는 다른 과정 수준(process-level) 능력을 건드린다는 증거입니다.
실패는 시각 인식 오류로 환원되지 않습니다. 약한 모델은 왜곡된 텍스트나 카테고리 단서를 잘못 읽고, 중간 모델은 목표는 맞게 찾지만 부정확한 좌표에 클릭·드래그하며, 강한 모델은 여러 행동에 걸쳐 구조화된 인터페이스 상태를 유지해야 하는 순서 선택·상태 복원에서 주로 실패합니다. 실패가 지각·위치 파악·행동 보정·상태 추적이라는 파이프라인 전체에 흩어져 있는 것입니다.
회고
저자들은 HLL이 실제 운영 검증 시스템의 모든 다양성과 서비스별 정책을 망라하지는 못한다고 분명히 밝힙니다. 프로덕션 측의 봇 탐지를 그대로 재현하지도 않습니다. 대신 궤적 조건부 동적 검증이라는 장치로, 에이전트의 답이 과제에 부합하는 상호작용 증거로 뒷받침되는지만 봅니다.
그럼에도 메시지는 분명합니다. 지금의 프런티어 에이전트는 보호된 실제 워크플로에서 사람을 대신할 만큼 믿을 만하지 않습니다. 더 강한 공간 그라운딩, 행동 보정, 상태 추적, 그리고 현실적 웹 조건에서의 복구 능력이 필요합니다.
정리
- HLL은 CAPTCHA 풀이를 인식 문제가 아니라 끝에서 끝까지의 검증 병목으로 재정의하고, 과제 종류와 현실성 조건(난이도·방해·동적 검증)을 분리해 어디가 먼저 부러지는지 진단합니다.
- 깨끗한 정적 환경에서 강하던 모델도 방해와 하드 변형에서 떨어지고, 행동 궤적까지 검증하는 동적 설정에서는 순위가 뒤집힙니다. 정답을 맞히는 것과 사람처럼 풀어내는 것은 다른 능력입니다.
- 코드는 GitHub에 공개돼 있습니다.