FastContext - Training Efficient Repository Explorer for Coding Agents
S. Zhang, M. Wang, Y. Shi, Y. Wang, X. Gu, Y. Yao, R. Fu, and S. Fu, "FastContext: Training Efficient Repository Explorer for Coding Agents," arXiv:2606.14066, 2026.
저자
Microsoft Research와 상하이교통대학(SJTU)의 공동 연구입니다.
장샤오치우(SJTU, Microsoft CoreAI 파견)과 왕마오취안(Microsoft)이 공동 제1저자이고, 푸성위(Microsoft)가 교신 저자입니다. 두 제1저자는 애초에 다른 역할로 출발했습니다. Maoquan Wang은 Mini-SWE-Agent 레포지토리와 SWE-bench 평가 파이프라인을 다루는 팀에서 왔고, Shaoqiu Zhang은 SJTU에서 탐색 데이터 파이프라인과 모델 훈련을 담당했습니다.
이 논문의 출발점은 문제 발굴에 있습니다. 팀은 GPT-5.4가 Mini-SWE-Agent에서 생성한 궤적 300개를 직접 분석해, 탐색(읽기+검색)이 전체 도구 호출 턴의 56.2%이고 총 토큰 소비의 46.5%를 차지한다는 수치를 뽑았습니다. 이 실증 분석이 "탐색을 분리하자"는 설계 결정으로 이어졌습니다.
배경
코딩 에이전트가 버그를 고치기 전에 반드시 해야 하는 일이 있습니다. 어느 파일, 어느 줄이 관련됐는지 찾는 일입니다. 그런데 이 탐색 과정이 생각보다 훨씬 비쌉니다.
GPT-5.4 기준, 첫 소스코드 편집 전까지 에이전트는 평균 7.2번의 순차적 탐색 턴과 17.4번의 병렬 도구 호출을 소비합니다. 해결되지 않은 이슈는 해결된 것보다 탐색 턴을 더 많이 씁니다(8.34 vs 6.67). 탐색이 길수록 실패하는 경향이 있다는 뜻이기도 합니다.
문제는 비용만이 아닙니다. 탐색 중 쌓인 관련 없는 코드 스니펫이 메인 에이전트의 컨텍스트에 남아, 이후 편집과 추론에서 노이즈로 작용합니다. 틀린 파일을 읽어두고 그걸 기반으로 패치를 만들다가 실패하는 패턴이 반복됩니다.
기존 해결책은 둘 다 비쌉니다. 그래프 기반 코드 구조 탐색(AutoCodeRover, LocAgent)은 사전 처리가 복잡합니다. 프런티어 모델이 탐색까지 직접 하는 "같은 모델 탐색"은 큰 모델의 추론 비용을 탐색에도 쓰는 셈입니다. FastContext의 질문은 이렇습니다. "탐색 자체는 작은 전용 모델이 할 수 있지 않을까?"
어떻게 만들었나
FastContext는 메인 에이전트로부터 탐색 요청을 받아 컴팩트한 파일-라인 증거를 돌려주는 서브에이전트입니다.
에이전트 인터페이스. FastContext는 세 가지 언어 독립적 도구만 사용합니다. READ(줄 번호 포함 파일 내용), GLOB(경로 패턴 매칭), GREP(정규 표현식 검색). 각 턴마다 병렬 도구 호출을 발행하고 관찰 결과를 수집하며, 최종적으로 <final_answer> 블록 형태로 파일 경로와 라인 범위를 반환합니다. 예시:
<final_answer>
/src/router.py:42-58
/tests/test_router.py:101-119
</final_answer>
이 출력이 메인 에이전트의 다음 컨텍스트로 그대로 들어갑니다.
SFT 초기화. 탐색 행동을 세 가지 측면으로 분리해 각각 훈련합니다. 2,954개 예시를 Claude Sonnet 4.6 참조 모델 궤적에서 구성했습니다.
- parallel_toolcalls: 이슈 쿼리 하나로 다양한 병렬 도구 호출을 발행하는 첫 턴 광역 탐색
- multiturn_traj: 중간 관찰 결과에 반응하며 증거를 좁혀가는 다중 턴 궤적
- linerange: 검색된 파일 내용을 받아 좁은
<final_answer>블록을 생성하는 정밀 인용
SFT 목표는 어시스턴트 토큰에만 손실을 적용하는 표준 교사 강제(teacher forcing) 방식입니다.
\[\mathcal{L}_{\text{SFT}} = -\frac{1}{|\mathcal{D}_{\text{sft}}|} \sum_{(x,y) \in \mathcal{D}_{\text{sft}}} \sum_{l=1}^{|y|} m_l \log p_\theta(y_l \mid x, y_{<l})\]
RL 정제. SFT가 행동 패턴을 가르쳤다면, RL은 실제 패치가 필요한 코드 위치를 맞추는 방향으로 모델을 정렬합니다. 400개 프롬프트로 구성된 보상 데이터셋을 사용하며, GRPO로 최적화합니다.
보상 함수는 다음 네 항의 합입니다.
\[R = \underbrace{F_1(P_f, G_f) + F_1(P_l, G_l)}_{\text{task outcome}} + \underbrace{r_{\text{parallel}}}_{\text{병렬 호출}} - \underbrace{r_{\text{format}}}_{\text{형식 패널티}}\]
\(P_f\)와 \(P_l\)은 모델이 반환한 파일 집합과 라인 집합, \(G_f\)와 \(G_l\)은 참조 패치에서 추출한 정답입니다. \(r_{\text{parallel}}\)은 단일 턴에서 여러 도구를 병렬 발행하는 행동에 소량의 보너스를 줍니다. \(r_{\text{format}}\)은 빈 출력, 형식 오류, 과도한 길이에 패널티를 적용합니다.
결과
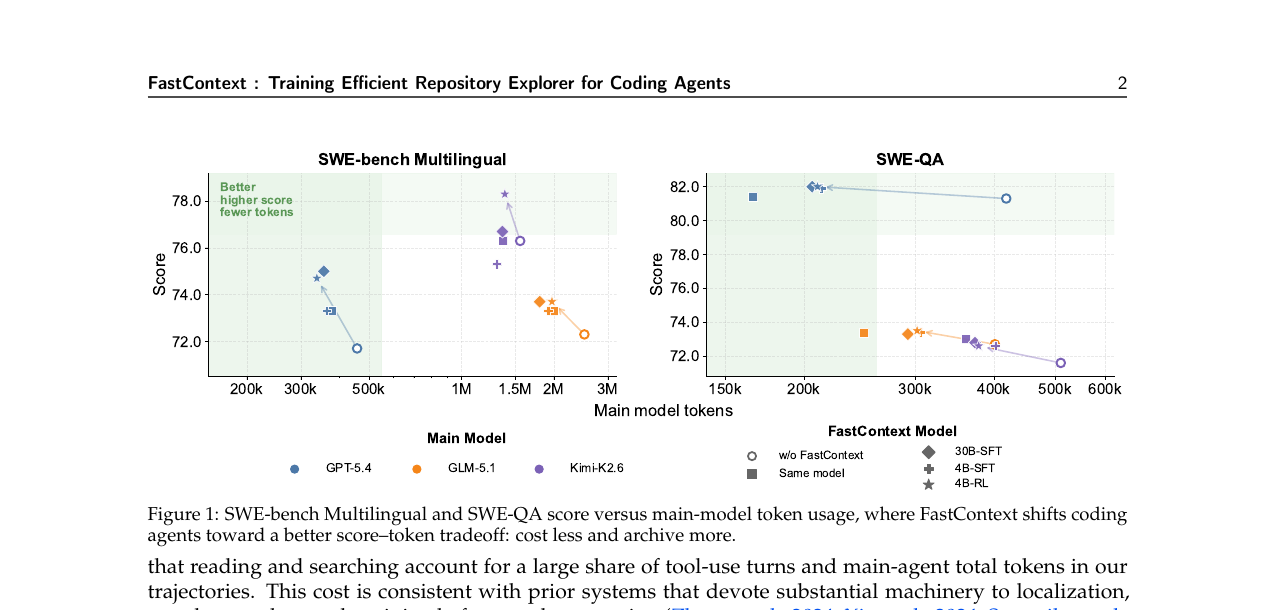
GPT-5.4를 메인 에이전트로 사용했을 때 FastContext 유무에 따른 성능과 토큰 소비를 비교했습니다.
설정 |
SWE-Multi (%) |
토큰 |
SWE-Pro (%) |
토큰 |
SWE-QA (%) |
토큰 |
|---|---|---|---|---|---|---|
w/o FastContext |
71.7 |
457k |
46.0 |
818k |
81.3 |
418k |
+같은 모델(GPT-5.4) |
73.3 |
379k(-17%) |
51.5 |
703k(-14%) |
82.0 |
166k(-60%) |
+FC-30B-SFT |
75.0 |
356k(-22%) |
49.0 |
688k(-16%) |
81.9 |
213k(-49%) |
+FC-4B-SFT |
73.3 |
364k(-20%) |
47.0 |
689k(-16%) |
82.0 |
213k(-49%) |
+FC-4B-RL |
74.7 |
338k(-26%) |
48.5 |
701k(-14%) |
82.0 |
210k(-50%) |
SWE-bench Pro에서 가장 큰 정확도 향상이 나타납니다. GPT-5.4 기준 46.0 → 51.5(+5.5pp). SWE-QA에서는 토큰 절감이 두드러져 418k → 166k(-60.3%)입니다. SWE-bench Multilingual에서는 30B-SFT가 75.0으로 가장 높지만, 4B-RL도 74.7을 달성합니다.
주목할 결과가 둘 있습니다. 첫째, 4B-RL이 30B-SFT보다 작으면서도 경쟁력이 있습니다. GLM-5.1 메인 에이전트 SWE-bench Pro에서는 4B-RL(22.5)이 30B-SFT(20.0)를 역전합니다. 둘째, 훈련된 4B 모델이 '같은 모델 탐색'보다 더 효율적입니다. GPT-5.4 SWE-bench Multilingual에서 4B-RL은 74.7점에 338k 토큰을 씁니다. 같은 모델 탐색은 73.3점에 379k 토큰입니다. 점수가 높고 토큰이 적습니다.
독립 탐색 품질(standalone exploration)을 SWE-bench Verified 기준 패치 파생 위치로 평가한 Table 2에서는, FC-30B-SFT가 파일 레벨 F1 73.71, 모듈 레벨 F1 60.35를 기록합니다. 비교군 최고치(OpenHands-Bash CODESCOUT-14B)의 68.57, 50.88보다 높습니다.
회고
논문이 직접 명시한 한계가 네 가지입니다.
검증된 에이전트 프레임워크가 하나. 모든 엔드투엔드 실험이 Mini-SWE-Agent와의 통합으로만 이루어졌습니다. 도구 인터페이스나 메모리 정책이 다른 에이전트(OpenHands, SWE-agent 등)에서 동일한 성능을 낼지는 검증되지 않았습니다.
메인 에이전트는 강한 모델로만 테스트. GPT-5.4, GLM-5.1, Kimi-K2.6으로만 평가했습니다. 30B급 소형 메인 에이전트와 조합하면 어떻게 되는지는 미지수입니다.
탐색 모델 최소 크기가 4B. 1.7B나 0.6B 수준의 극소형 모델에서 같은 SFT+RL 방식이 통하는지 아직 확인되지 않았습니다.
벤치마크 오염 가능성. 프런티어 모델 사전 훈련 데이터와 벤치마크 인스턴스 간 중복이 있을 수 있어, 결과를 배포 환경 성능 보장으로 해석하는 건 무리입니다.
정리
- 레포지토리 탐색은 메인 에이전트에서 분리해 전용 서브에이전트에 위임할 수 있으며, 정확도와 토큰 비용 양쪽에서 동시에 개선을 얻습니다.
- SFT(참조 궤적 모방) + RL(패치 기반 보상) 조합은 4B 소형 모델도 30B 이상 탐색 모델에 준하는 품질로 끌어올립니다. RL이 추가하는 것은 실제 코드 위치 적중률이고, 이것이 엔드투엔드 정확도로 이어집니다.
- 탐색 전용 서브에이전트 패턴은 코딩 에이전트뿐 아니라, 탐색-풀기 분리가 가능한 다른 에이전트 시스템 설계에도 적용 가능한 구조적 원칙입니다.