Predictive Maps of Multi-Agent Reasoning - A Successor-Representation Spectrum for LLM Communication Topologies
E. D. J. Park and D. Alharthi, "Predictive Maps of Multi-Agent Reasoning: A Successor-Representation Spectrum for LLM Communication Topologies," arXiv:2605.11453, 2026.
멀티에이전트 LLM 시스템을 짤 때 가장 답답한 순간은, 똑같은 모델을 chain으로 묶을지 star로 묶을지 mesh로 묶을지 결정하는 자리입니다. 아무도 어느 토폴로지가 drift에 약한가, 어느 토폴로지가 consensus를 잘 만드는가를 미리 알지 못합니다. 일단 돌려보고 망가지면 다른 모양으로 갈아끼우는 식으로 일이 흘러갑니다. AutoGen·MetaGPT·CrewAI·LangGraph 같은 프레임워크가 topology를 1급 설정값으로 만들었지만, 그 설정값을 고르는 기준은 여전히 시행착오 한 가지입니다.
University of Arizona의 에단 파크스와 달랄 알하르티가 arXiv에 올린 Predictive Maps of Multi-Agent Reasoning은 이 자리에 도구 하나를 갖다 놓습니다. 그래프 자체에서 세 개의 고윳값을 뽑아 추론을 돌리기 전에 토폴로지를 줄세우자는 제안입니다. 강화학습에서 30년 된 successor representation을, 신경과학이 hippocampal predictive map의 후보로 받아간 그 객체를 통신 그래프에 그대로 얹습니다.
저자
저자는 두 명뿐입니다. 에단 파크스가 1저자, 달랄 알하르티가 시니어입니다. Alharthi는 University of Arizona의 사이버보안 조교수로 클라우드·컨테이너 보안과 AI 보안 위협을 함께 다루는 사람입니다. Parks는 공개 프로필이 거의 없는 신진으로, 이 논문이 공개 트랙에서 잡히는 첫 1저자 논문입니다.
분야 조합이 흥미롭습니다. 강화학습의 successor representation, 신경과학의 predictive map, 그래프 신호처리의 over-squashing, 그리고 LLM 멀티에이전트 실패 모드 catalog — 한 분야의 깊이로는 안 나오는 조합입니다. 시니어가 사이버보안에서 들어왔기에 공격자가 한 leaf만 잡으면 그래프 진단이 얼마나 망가지는가를 묻는 부록 A.6 같은 줄기가 자연스럽게 본문에 끼어들었습니다. 1저자 쪽에서는 chain·star·mesh의 closed-form 고윳값 유도부터 √k 예측, 100 trial 실험까지 한 트랙으로 밀어붙였습니다.
배경
멀티에이전트 LLM 시스템을 그래프로 보자는 시각 자체는 새롭지 않습니다. Chain-of-thought, Tree of Thoughts, Graph of Thoughts, 그리고 ChatEval·MetaGPT·AutoGen 같은 프레임워크가 이미 agent를 노드로, 메시지 흐름을 엣지로 보는 추상을 굳혀 두었습니다. 문제는 그래프 모양을 고르는 자리에서 이 추상이 멈춘다는 점입니다. 사용 가능한 진단은 AgentBench·HELM·BIG-Bench처럼 돌려본 뒤의 outcome 평가뿐이고, 그 결과는 측정한 그 한 가지 태스크에만 유효합니다.
근접한 이웃 분야가 두 갈래 있습니다. 한쪽은 그래프 신경망 쪽의 over-squashing/over-smoothing 분석으로, 그래프 구조가 정보 흐름을 어떻게 압축하거나 흐트러뜨리는지를 스펙트럼으로 잡아냅니다. 다른 한쪽은 분산 합의 이론의 DeGroot 모델·Krum aggregation으로, 노이즈가 섞인 분산 평균이 어떻게 한 점으로 모이는가를 정량화합니다. 두 갈래 모두 통신 그래프의 스펙트럼이 시스템의 거동을 미리 말해 준다는 입장입니다. Parks와 Alharthi가 하는 일은 이 두 갈래를 LLM 멀티에이전트로 옮겨 심는 것입니다.
여기에 한 가지가 더 얹힙니다. Peter Dayan이 1993년에 강화학습용으로 제안한 successor representation \(M = (I - \gamma P)^{-1}\)입니다. 무한 horizon에 걸친 \(k\)-step 영향 경로를 한 행렬에 압축해 두는 객체로, neuroscience 쪽에서는 hippocampus가 표상하는 predictive map의 후보로 받아갔습니다. 통신 그래프의 row-stochastic adjacency를 \(P\)로 두면, 이 SR은 agent \(i\)의 흔들림이 agent \(j\)에 누적적으로 얼마나 전달되는가를 표상합니다. 그래프 자체에서 한 행렬을 만든 뒤 그 스펙트럼만 봐도 시스템 행동을 짚을 수 있다는 가설입니다.
어떻게 만들었나
저자들의 처방은 단순합니다. 그래프 \(G\)의 weighted adjacency를 row-normalize해 \(P\)로 만들고, \(\gamma = 0.9\)를 박아 successor representation \(M = (I - \gamma P)^{-1}\)를 계산합니다. 여기서 세 개의 스칼라를 뽑습니다.
- 스펙트럴 반지름 \(\rho(M)\) — perturbation의 기하적 증폭 한계. ergodic 그래프에서는 \((1-\gamma)^{-1}\)로 saturate. acyclic chain에서는 nilpotent 구조 덕에 \(\rho = 1\)로 떨어짐.
- 스펙트럴 갭 \(\Delta(M) = |\lambda_1| - |\lambda_2|\) — 분산 추정이 한 점으로 수렴하는 속도. 합의 동역학의 직접 척도.
- 조건수 \(\kappa(M) = \sigma_{\max}/\sigma_{\min}\) — driving signal의 perturbation에 대한 민감도. 적대적 입력에 대한 robustness를 결정.
세 양은 각각 cumulative error, consensus decay, perturbation sensitivity라는 task-level 메트릭과 짝지어집니다. Chain·star·mesh 세 토폴로지의 closed-form 고윳값은 부록 A.1에서 유도되는데, 결과만 보면 이렇습니다.
Topology |
\(\rho(M)\) |
\(\Delta(M)\) |
\(\kappa(M)\) |
|---|---|---|---|
Chain |
1.00 |
0.00 |
9.95 |
Star |
10.00 |
9.00 |
28.61 |
Mesh |
10.00 |
9.23 |
13.00 |
이 표가 본 논문의 예측입니다. chain은 nilpotent라 \(\rho=1\)로 가장 안정해 보이고, star는 leaf가 많을수록 \(\kappa\)가 커져 가장 취약해 보이며, mesh는 갭이 가장 커서 합의가 빠를 것이라는 그림입니다.
검증은 12-step structured state-tracking 태스크로 합니다. agent는 매 스텝마다 JSON 상태(Value, Parity, Level) 세 필드를 세 줄짜리 규칙에 따라 갱신하고, 컨텍스트는 스텝 사이에서 reset됩니다. 즉 에러가 전달되는 통로는 오직 통신 채널뿐입니다. agent는 모두 Qwen2.5-7B-Instruct(commit a09a354)로 통일했고 temperature 0.8, top-p 0.5, 250 token budget, 100 trial을 단일 A100에서 6시간 안에 돌렸습니다.
결과
100 trial 평균을 정리하면 다음과 같습니다.
Metric |
Chain |
Mesh |
Star |
\(r_s\) vs 예측 |
|---|---|---|---|---|
Cumulative error \(E_{ceg}\) |
2094.34 |
1241.00 |
1184.24 |
−1.00 |
Consensus decay \(R_{cdr}\) |
0.27 |
−1.66 |
−3.44 |
+0.50 |
Perturbation sensitivity \(F_{ps}\) |
237.82 |
247.42 |
443.64 |
*+1.00* |
조건수는 perturbation robustness를 완벽하게 예측합니다(\(r_s = 1.0\)). 갭은 chain이 꼴찌라는 점은 맞히지만 star와 mesh 순서를 뒤집습니다(\(r_s = 0.5\)). 그리고 가장 인상적인 한 줄 — 스펙트럴 반지름은 cumulative error를 정확히 역방향으로 예측합니다(\(r_s = -1.0\)). 가장 안정해 보였던 chain이 실제로는 오차를 가장 크게 누적시킵니다.
저자들은 이걸 stability paradox라고 부릅니다. 그리고 한 발 더 가서 왜 그런지를 정량적으로 설명합니다. 핵심은 spectral radius가 결정론적 perturbation의 기하적 성장을 잡는 양이라는 것입니다. 실제 LLM 시스템에서 누적되는 오류는 그게 아니라 agent별 작은 stochastic deviation입니다. 매 스텝마다 agent \(i\)가 진짜 규칙 \(\tau\)를 흉내내며 분산 \(\sigma^2\)의 노이즈 \(\eta_t^{(i)}\)를 끼얹는 affine-noise 모델로 잡으면, \(k\)-fold aggregator는 노이즈 분산을 \(\sigma^2/k\)로 줄입니다. 그래서 누적 오차가 \(\sigma T^{3/2}/\sqrt{k}\)로 갑니다. chain은 \(k=1\), star·mesh는 \(k=4\). 예측 비율은 \(\sqrt{4} = 2\)이고, 실제 chain/star = 1.77, chain/mesh = 1.69로 sampling variance 안에서 맞아 떨어집니다.
여기서 저자는 spectral radius를 그냥 버리지 않고 drift-corrected gain \(\tilde\rho(M;k) = \rho(M)\cdot\sqrt{(1/n)\sum_i 1/k_i}\)로 보정합니다. 이 보정된 양의 순서는 chain \(>\) star \(\approx\) mesh로, cumulative error의 경험적 순서와 일치합니다. 즉 spectral radius가 실패한 게 아니라, linear 시각이 stochastic drift를 못 본다는 게 정확한 진단입니다.
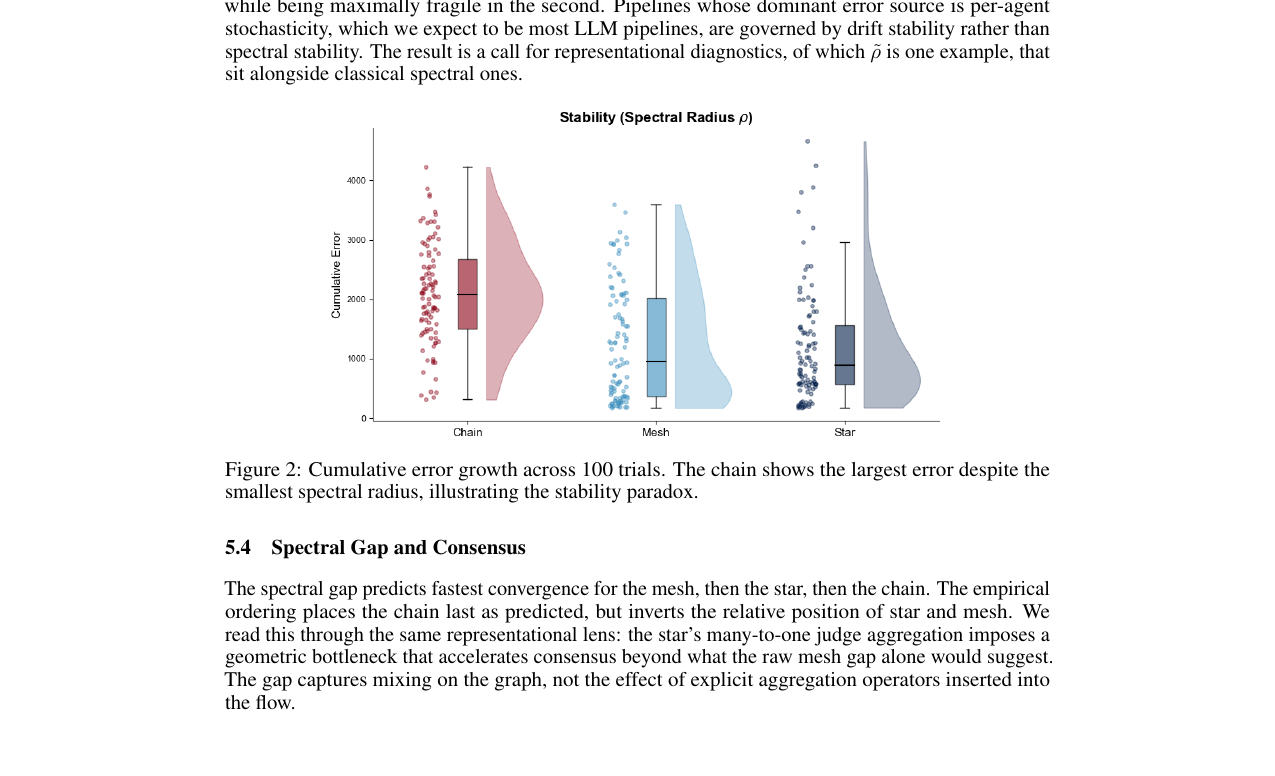
100 trial을 raincloud로 펼치면 chain의 분포가 mesh·star보다 분명히 위로 치우쳐 있습니다. linear 의미에서 가장 stable한 토폴로지가 sequential drift 의미에서 가장 fragile하다는 한 장의 그림입니다.
조건수 쪽은 한 번 더 깔끔합니다. star의 4-leaf 구조는 \(\kappa \approx 28.6\)으로 가장 ill-conditioned이고, 부록 A.6에서 한 leaf의 가중치 \(\alpha\)를 키우는 malicious star leaf 시나리오를 분석하면 \(\kappa\)가 \(\Theta(\ell^{3/2})\)로 부풀어 올라 \(\ell=4\), \(\gamma=0.9\)에서 약 98.5까지 갑니다. benign star의 약 3.4배. 같은 시나리오에서 \(\rho\)와 \(\Delta\)는 미동도 하지 않습니다. 보안 관점에서 어느 진단이 공격에 반응하는가까지 결을 짚어둔 셈입니다.
회고
저자는 이 한계를 본문 §7에서 그대로 적습니다. 토폴로지 3개, 모델 1개 패밀리(Qwen2.5-7B-Instruct), 태스크 1개 패밀리, 100 trial. 세 개 rank 위의 Spearman 계수는 통계적 power가 사실상 없다고 본인이 쓰고, 단지 rank-consistency 증거로만 받아달라고 못박습니다. affine-noise 모델의 iid 가정도 명백한 단순화입니다. 부록 A.4에서는 agent들이 같은 base model을 공유하면 inductive bias가 시스템적으로 상관된다는 Du et al. 2023의 관찰을 받아, 상관계수 \(\rho_c\)를 끼운 보정 식을 따로 유도해 둡니다. 즉 iid가 깨지면 aggregation 이득이 어떻게 줄어드는가까지 손을 댑니다.
또 한 가지 정직한 대목 — empirical metric이 trajectory 전체를 한 scalar로 죽인다는 점도 본인이 적습니다. Stepwise dynamics는 부록 B의 raincloud로만 보여 줄 뿐, 진단 자체에는 들어가지 않습니다.
저자가 글 안에서 분명히 닫지 못한 부분은 모델 family를 갈아끼웠을 때 같은 ranking이 유지되는가입니다. affine-noise 유도가 \(P\)와 \(\sigma^2\)에만 의존하지 모델 내부 구조에 의존하지 않으니 qualitative ordering은 model-agnostic할 것이라 본인은 기대하지만, 그건 실험이 아니라 framework의 예측이라 명시합니다. follow-up sweep의 1순위로 본인이 지목한 항목이기도 합니다.
정리
세 가지로 압축하겠습니다.
- 멀티에이전트 LLM 시스템을 통신 그래프 한 가지로 환원하고, 그 그래프의 successor representation에서 세 고윳값(\(\rho\), \(\Delta\), \(\kappa\))을 뽑아 inference 전에 토폴로지를 줄세우자는 처방입니다. 한 번의 행렬 역연산으로 끝나니 ms 단위에 돌아갑니다.
- 100 trial에서 조건수는 perturbation robustness를 완벽히, 갭은 합의 속도를 부분적으로 맞혔습니다. spectral radius는 정확히 뒤집혔는데, 저자는 이걸 실패가 아니라 linear 시각이 못 보는 sequential drift 영역의 발견으로 받고, affine-noise 모델에서 drift-corrected \(\tilde\rho\)를 유도해 ranking을 회복합니다.
- AutoGen·LangGraph·CrewAI에서 chain/star/mesh를 고르는 그 자리에 세 줄짜리 linear algebra를 끼우자는 제안으로 읽힙니다. 실험 규모가 한 모델·한 태스크에 갇혀 있어 그 자체로 universal law는 아니고, 저자도 그렇게 받지 말라고 못 박습니다. 다만 진단을 inference 전에 한 번 더 한다는 방향에 closed-form 출발점을 하나 박아준 작업입니다.