EvoArena - Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments
J. Xu, Q. Li, J. Wu, Y. Lan, S. S. Li, H. Zhou, B. Jiang, L. Wang, J. Wang, A. T. Luu, C. Xiong, H. W. Park, B. Hooi, and Z. Hu, "EvoArena: Tracking Memory Evolution for Robust LLM Agents in Dynamic Environments," arXiv:2606.13681, 2026.
저자
쉬준동와 Qingchuan Li가 공동 1저자입니다. 두 사람은 모두 싱가포르국립대학교(NUS) 소속으로, 각각 LLM 추론과 에이전트 메모리 쪽 연구를 해왔습니다. 시니어 라인에는 NUS의 브라이언 후이와 후즈위안가 있고, 밖으로는 차이밍 슝(전 Salesforce AI Research SVP, 현 Recursive Superintelligence 공동창업자)과 MIT의 Hae Won Park이 자문 역할로 함께했습니다. Caiming Xiong의 참여는 논문 각주에 "Work Partially Done at Salesforce AI Research"라고 명시되어 있습니다.
사실상 이 논문은 NUS 그룹이 주도하되, 싱가포르경영대, 워싱턴대, UPenn, UCL, NTU, MIT까지 여러 기관의 공동 작업으로 완성된 벤치마크 논문입니다. 참여 기관이 많은 만큼 세 종류의 벤치마크(터미널, 소프트웨어, 개인화 대화)를 동시에 설계하고 검증하는 데 분업이 가능했습니다.
배경
대부분의 LLM 에이전트 벤치마크는 정적 스냅샷을 가정합니다. WebArena, SWE-bench, GAIA 모두 한번 만들어진 환경이 평가 내내 변하지 않습니다. 그런데 실제 배포 환경은 그렇지 않습니다. API 인터페이스가 바뀌고, 코드베이스에 새 마일스톤이 추가되고, 사용자의 취향이 조금씩 달라집니다. 에이전트가 "지금 버전"을 정확히 파악하고, 이전 버전에서 유효했던 절차 중 어떤 것이 아직 통하는지, 어떤 것이 더 이상 맞지 않는지를 구별할 수 있어야 진정한 신뢰성을 얻습니다.
기존 벤치마크는 이 "버전 인식 능력"을 전혀 측정하지 않는다는 점이 이 논문이 출발한 자리입니다.
EvoArena: 세 종류의 진화
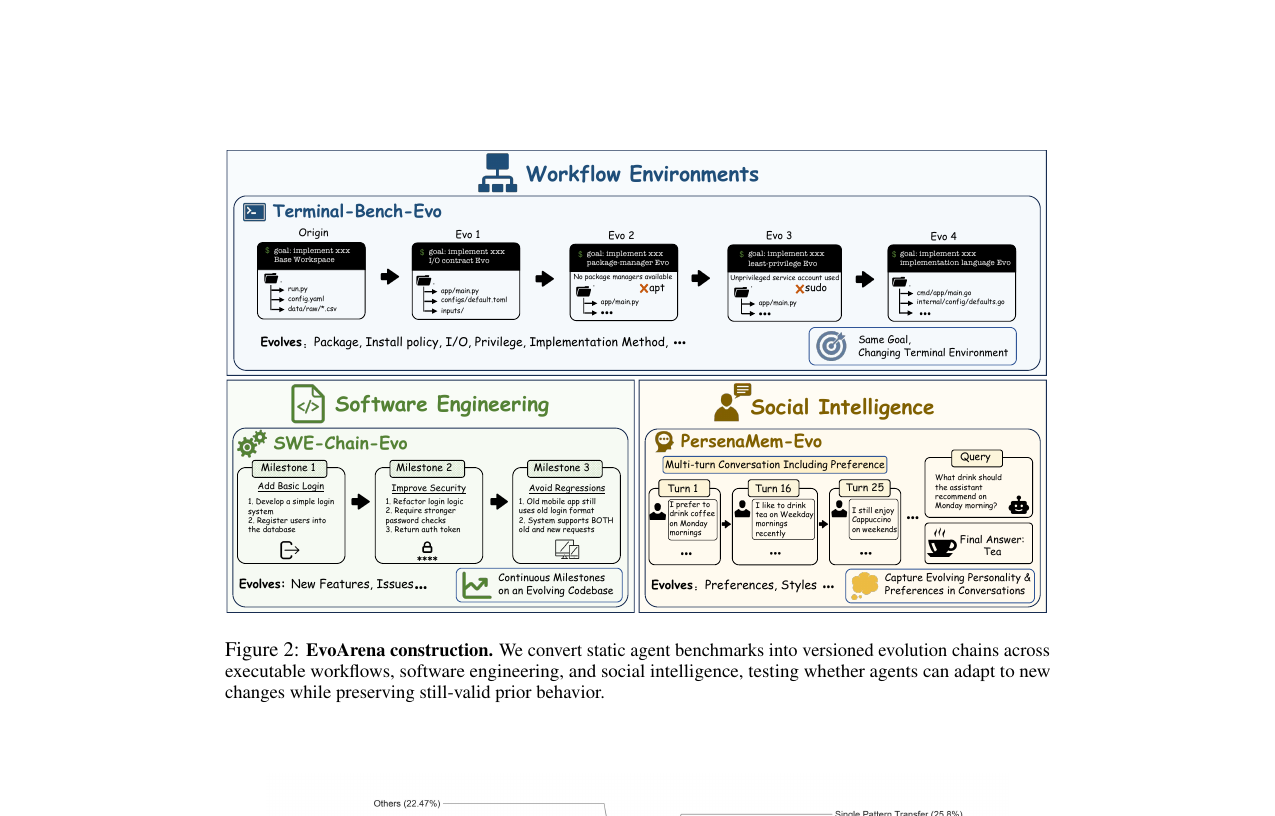
EvoArena는 세 도메인의 "진화하는 버전 체인"으로 구성됩니다.
Terminal-Bench-Evo는 터미널 워크플로우가 버전마다 달라지는 환경입니다. 원본 Terminal-Bench의 89개 태스크를 각각 최대 5개 버전의 체인으로 확장했습니다. 버전마다 같은 목표("hello.html을 push하고 포트 8080에서 서빙")를 유지하되, 배포 방식, 경로, 권한 정책, 브랜치 규칙이 순차적으로 바뀝니다. 최종 데이터셋은 441개 태스크 인스턴스(초기 버전 포함), 평균 체인 길이 4.96입니다.
SWE-Chain-Evo는 실제 GitHub 레포지토리에서 연속 커밋 기간을 뽑아 밀스톤 체인을 구성했습니다. 12개 레포지토리, 50개 체인, 493개 체인-스텝 인스턴스(고유 밀스톤 145개). 평균 체인 길이 9.86입니다. 나중 밀스톤은 앞선 밀스톤에서 작성된 코드를 참조하므로, "이전에 통과시킨 테스트를 깨뜨리지 않으면서 새 요구사항을 구현"하는 능력을 직접 측정합니다.
PersonaMem-Evo는 대화 속에서 사용자 취향이 점점 변해가는 시나리오입니다. 10개 페르소나 각각에 대해 평균 597턴짜리 긴 대화 이력을 생성하고(중앙값 174.7K 토큰), 그 안에서 특정 취향이 어떻게 진화했는지를 묻는 4지선다 문제 505개를 구성했습니다. 문제 유형은 단일 패턴 전이, 다중 패턴 합성, 충돌 해소, 시간적 궤적 예측의 네 가지입니다.
세 도메인 공통으로 스텝 정확도(개별 버전/문제 단위)와 체인 정확도(체인 전체를 모두 맞혀야 정답) 두 가지 지표를 씁니다. 체인 정확도는 한 고리라도 틀리면 0이기 때문에 훨씬 가혹합니다.
EvoMem: 메모리를 패치 이력으로
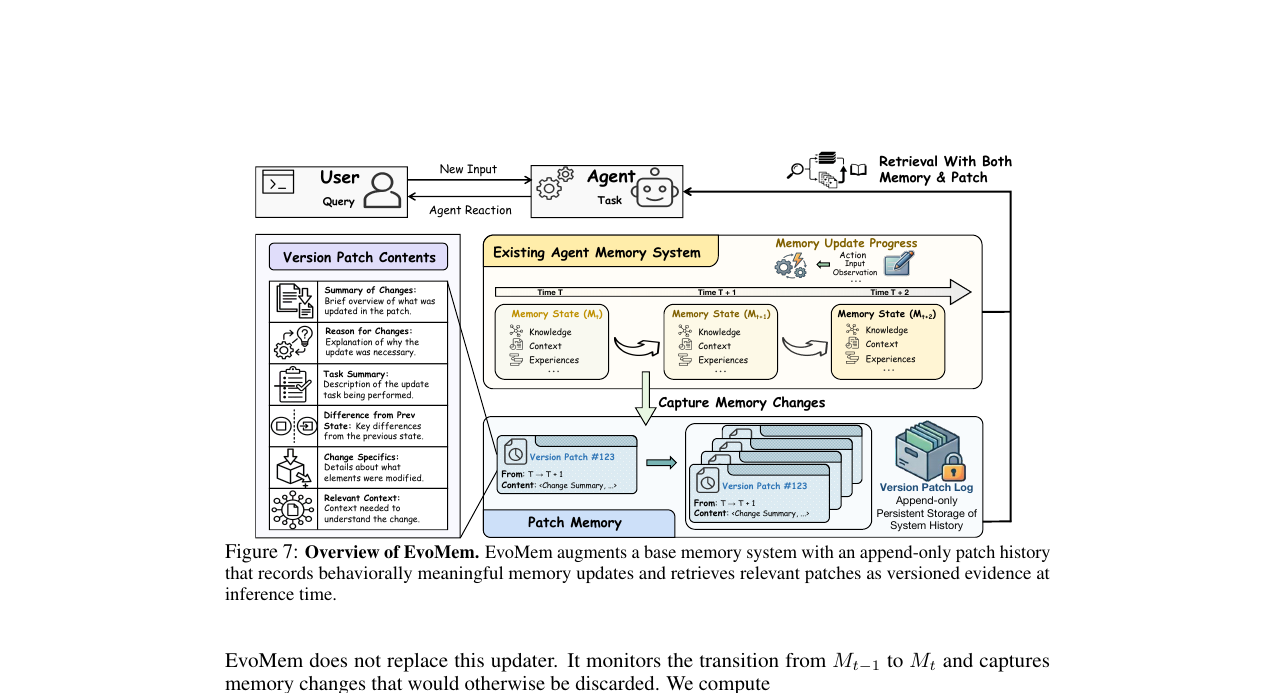
기존 에이전트 메모리 시스템의 공통 약점은 **상태 붕괴(state collapse)**입니다. 새 정보가 들어오면 이전 메모리를 덮어써버립니다. 이전 버전에서 유효했던 절차가 새 버전 정보에 의해 지워지고, "왜 그 절차가 거기서 맞았는가"라는 맥락도 함께 사라집니다.
EvoMem은 이를 패치 이력(patch history) 개념으로 해결합니다. 기본 메모리 업데이터는 건드리지 않고, 메모리가 의미 있게 바뀌는 시점마다 패치 하나를 append-only 로그에 추가합니다. 패치 하나에는 다음 필드가 들어갑니다:
\[p_t = \langle \tau_t, C_t^-, C_t^+, r_t, z_t, e_t \rangle\]
\(\tau_t\)는 타임스탬프, \(C_t^-\)와 \(C_t^+\)는 업데이트 전후의 메모리 내용, \(r_t\)는 업데이트 이유, \(z_t\)는 변경 요약, \(e_t\)는 업데이트를 촉발한 맥락(태스크 피드백, 환경 스냅샷 등)입니다.
추론 시에는 최신 메모리(\(M_T\))에서 먼저 검색하고, 쿼리가 시간적 변화나 덮어쓰인 상태에 의존한다고 판단되면 패치 이력에서 관련 패치를 추가로 가져옵니다:
\[c(q) = \text{Concat}(R_\text{mem}(q, M_T),\; R_\text{patch}(q, P_{1:T}))\]
EvoMem은 메모리 형식에 무관합니다. 논문에서는 네 가지 에이전트에 각기 다른 방식으로 이식했습니다: 터미널 에이전트 Terminus2, 코딩 에이전트 OpenHands, 대화 메모리 에이전트 A-Mem, 스킬 메모리 에이전트 Memento-Skill.
결과
벤치마크 |
에이전트 |
스텝 Acc (Base) |
스텝 Acc (+EvoMem) |
체인 Acc (Base) |
체인 Acc (+EvoMem) |
|---|---|---|---|---|---|
Terminal-Bench-Evo |
Terminus2 |
43.6% |
46.0% |
21.5% |
27.6% |
SWE-Chain-Evo |
OpenHands |
27.9% |
28.3% |
10.0% |
12.1% |
PersonaMem-Evo |
A-Mem |
47.3% |
49.0% |
40.0% |
43.2% |
GAIA |
Memento-Skill |
65.8% |
72.3% |
-- |
-- |
LoCoMo |
A-Mem |
39.7% |
43.0% |
-- |
-- |
핵심 발견 세 가지를 짚습니다.
첫째, 현재 에이전트는 진화 환경에서 고전합니다. GPT-5.5도 Terminal-Bench-Evo 체인 정확도 31.8%에 그칩니다. 스텝을 개별적으로 푸는 것과 "버전 체인 전체를 연속으로 맞히는 것"의 격차가 크다는 사실이 진화 환경의 어려움을 보여줍니다.
둘째, EvoMem은 체인 레벨에서 더 크게 이깁니다. 스텝 정확도 향상보다 체인 정확도 향상이 일관되게 더 큽니다. Terminal-Bench-Evo에서 스텝 +2.4% 대 체인 +6.1%, SWE-Chain-Evo에서 스텝 +0.5% 대 체인 +2.9%가 그 예입니다. 연속된 태스크를 일관성 있게 처리하는 능력이 패치 이력에서 나온다는 의미입니다.
셋째, EvoMem은 기존 벤치마크에서도 잘 통합니다. GAIA에서 평균 +6.5%, LoCoMo에서 +3.3%. 진화 환경 전용 트릭이 아니라, 메모리 업데이트 이력을 추적하는 게 일반적으로 유익하다는 증거입니다.
모델별로 보면 GPT-5.5가 Terminal-Bench-Evo에서 최고 스텝 정확도(62.8%)를 내지만 토큰 소비가 505M으로 압도적으로 높습니다. Gemini-3.1-Pro(53.8%)와 GLM-5.1(51.8%)은 토큰 사용이 평균 아래(80M 내외)입니다. 토큰 예산이 성능을 보장하지 않는다는 점이 Terminal-Bench-Evo에서 뚜렷하게 드러납니다.
메커니즘 분석
어떨 때 EvoMem이 실제로 도움이 되는가? 논문은 세 도메인에서 각각 메커니즘을 분석합니다.
Terminal-Bench-Evo에서 핵심 변수는 패치 uptake, 즉 에이전트가 검색된 패치의 내용을 이후 추론이나 명령에 실제로 반영하는지입니다. 패치를 가져왔지만 활용하지 않은 경우 개선폭이 +2.6%인 반면, 패치를 실제로 명령어에 녹여 쓴 경우 개선폭이 +8.3%로 뜁니다. EvoMem은 단순히 컨텍스트를 늘리는 게 아니라, 에이전트가 "무엇이 바뀌었는가"를 정확히 포착하고 이를 행동에 옮길 때 빛납니다.
SWE-Chain-Evo에서는 회귀(regression) 감소가 핵심입니다. EvoMem 추가 후 Pass-to-Pass 테스트 실패율이 평균 9.09%에서 6.32%로 떨어집니다. 나중 밀스톤 작업 중 이전 밀스톤에서 확립한 행동을 깨뜨리는 빈도가 줄어듭니다.
PersonaMem-Evo에서는 시간적 궤적 질문과 다중 패턴 합성 질문에서 EvoMem 효과가 두드러집니다(각 +5.2%). 이 둘은 오래 전에 언급된 선호도 상태를 복원해야 하는 문제 유형입니다. 반면 갈등 해소, 단일 패턴 전이에서는 개선이 미미하거나 소폭 하락하는데, 이쪽은 증거 확보보다 "어떤 선호도가 우선인가"를 판단하는 능력이 요구되기 때문으로 해석합니다.
회고
저자들이 직접 밝힌 한계입니다. EvoArena는 터미널 워크플로우, 소프트웨어 레포지토리, 장기 선호도라는 세 영역에 집중합니다. 로보틱스, 과학 워크플로우, 다중 에이전트 협업처럼 물리적·도메인적으로 다른 진화 환경은 아직 다루지 못합니다. EvoMem 자체도 패치 검색이 잘못 작동할 때(예컨대 GPT-5.5로 PersonaMem-Evo 시간적 궤적 문제를 풀 때) 구형 상태를 불필요하게 끌어올려 혼선을 주기도 합니다.
장기 메모리 이력이 누적될수록 개인 정보 관리와 접근 제어 문제도 중요해집니다. 논문이 이 지점을 Broader Impact 섹션에서 명시적으로 언급하는 건 성실한 태도입니다.
논문 구조를 재구현 관점에서 보면 몇 가지 암묵적 전제가 눈에 띕니다. Terminal-Bench-Evo의 버전 체인은 사람이 설계하고 LLM이 검증하는 방식으로 생성됐습니다. 이 인공적 진화가 실제 운영 환경의 버전 변화 패턴을 얼마나 대표하는지는 별도 검증이 없습니다. 실제 현장에서 버전 변화는 단발적이기보다 다중 경로로 분기하는 경우가 많습니다. 체인이라는 선형 구조가 이를 단순화하는 가정임을 인식해야 합니다.
세 도메인의 이질성도 짚을 만합니다. 터미널 태스크는 명령 실행 성공 여부를 자동 채점할 수 있지만, PersonaMem-Evo의 4지선다 문제는 출제 자체가 모델(GPT-4o)에 의존합니다. 벤치마크가 평가하려는 능력과 출제 방식 사이의 순환이 생깁니다. EvoMem의 "패치가 의미 있게 바뀔 때" 감지 기준도 논문에서 명시적으로 정의하지 않아, 같은 에이전트에 이식하더라도 구현마다 동작이 달라질 여지가 있습니다.
정리
- EvoArena는 LLM 에이전트를 "버전이 바뀌는 환경"에서 평가하는 최초의 다중 도메인 벤치마크입니다. 터미널, 소프트웨어, 대화 세 도메인 모두에서 체인 정확도 개념을 도입했습니다.
- EvoMem은 메모리 업데이트를 패치 이력으로 남겨 에이전트가 "무엇이 왜 바뀌었는가"를 추론할 수 있게 합니다. 기존 메모리 시스템에 비침습적으로 얹힙니다.
- 현재 최강 모델(GPT-5.5)도 EvoArena 체인 정확도는 30% 안팎에 머뭅니다. 배포 환경의 비정상성은 아직 충분히 해결되지 않은 열린 문제입니다.