Agents' Last Exam
Y. Sun, X. Han, W. Zhang, Y. Pang, T. Wang, Y. Cao, Y. Huang, C. Duroiu, et al., "Agents' Last Exam," arXiv:2606.05405, 2026.
AI가 체스를 이겼고, 수학 올림피아드를 풀었고, 경쟁 프로그래밍을 통과했습니다. 그런데 경제 성장 지표는 움직이지 않습니다. 이 논문은 그 간극이 평가 도구의 문제라고 주장합니다.
저자
선이유이 제1저자이자 실행팀 핵심 기여자이고, 시니어 저자는 UC 버클리 CS 교수 송 새벽입니다. 실행팀(13명)이 벤치마크 전체를 설계·구현하고, 250명 이상의 산업 전문가 자문단이 태스크를 기여했습니다. 산업계 전문가 advisory committee가 각 도메인의 워크플로우 지형을 매핑하고 경제적 의미가 있는 태스크 유형을 선별했습니다.
송 새벽은 AI 보안과 에이전트 평가 인프라에 오랫동안 관심을 기울여 왔습니다. 이번 ALE는 그 연구 흐름의 자연스러운 연장입니다. 에이전트가 무엇을 할 수 있는지에 대한 주장과 실제 수행 여부를 측정하는 것 사이의 간극을 직접 좁히려 한 것입니다.
배경
ImageNet이 컴퓨터비전을 빠르게 앞당겼듯, 좋은 벤치마크는 연구 방향을 결정합니다. 그러나 금융·법률·전기공학·제조 같은 경제적 핵심 영역에는 그에 준하는 평가가 없었습니다. 기존 에이전트 벤치마크는 대개 세 가지 중 하나를 희생합니다.
- 실제성: SWE-bench(GitHub 이슈), OSWorld(데스크톱 UI) - 좁은 도메인
- 범위: GDPval(16/55 산업), RLI(14/55 산업) - 인간 평가자가 필요
- 검증 가능성: 자유 형식 결과물 → 인간 심사관이 채점
ALE는 세 가지를 동시에 잡으려 합니다. 55개 산업 전부, 실제 전문가 업무, 자동 결정론적 채점.

Figure 3에서 보듯, 기존 16개 주요 벤치마크의 합집합을 취해도 55개 하위 도메인 중 13개는 아무도 다루지 않습니다.
어떻게 만들었나요
모든 태스크는 세 조건을 충족해야 합니다.
- 대표성: 전문가가 실제 쓰는 소프트웨어를 사용해야 합니다. 건축 태스크라면 AutoCAD보다 SolidWorks나 Rhino.
- 복잡성: 단일 조작이 아니라 종단 간 결과물. "DaVinci에 색 필터 적용"은 거부됩니다. "달리는 치타를 다른 영상으로 옮기기" (트래킹 + 로토스코핑 + 컴포지팅 + 컬러 매칭)는 통과합니다.
- 검증 가능성: 결과를 자동으로 확인할 수 있어야 합니다. "RPG 게임 설계" 같은 지시는 거부됩니다. "RPGMaker XP로 mota.exe 재현" 같이 맵 지오메트리·캐릭터 속성·이벤트 상태를 자동 비교할 수 있어야 통과합니다.
5단계 파이프라인
전문가 모집 → 태스크 제출 → 자동 1차 심사 → 엔지니어 구현 → QC 위원회 최종 심사
전문가들이 자신이 실제로 완료한 프로젝트를 제출 포털(agents-last-exam.org)에 올립니다. 5가지 핵심 요소가 완전히 명세될 때까지 수정 루프를 돕니다.
- 자연어 설명
- 입력 파일
- 대상 소프트웨어
- 예상 결과물
- 평가 기준 1차 심사는 학회 스타일 채점(Major Revision / Minor Revision / Borderline / Accept / Strong Accept)으로 진행하고, 수락된 것만 엔지니어가 실행 가능 자산으로 변환합니다. QC 위원회가 레퍼런스 결과의 정확성, 채점 기준의 적절함, 컨텍스트 충분성을 최종 확인합니다.
외부 제출 960개 중 128개가 Strong Accept, 369개가 Accept를 받았습니다. 내부 커미셔닝으로 530개를 별도 제작했습니다. 총 1,490개 태스크 인스턴스 중 150개(10%)만 공개하고 나머지는 비공개로 유지합니다. 벤치마크 오염(pretraining 데이터 노출, 태스크별 튜닝)을 막기 위해서입니다. 비공개 태스크는 순환 교체됩니다.
자동 채점 방식
결과물이 파일, 스프레드시트, 미디어, 보고서, 3D 모델 등 다양하기 때문에 채점 모드를 태스크마다 지정합니다. 가장 흔한 패턴은 gate-and-score: 이진 전제조건("공구 경로 충돌 없음", "파일 파싱 오류 없음")을 통과해야 연속적 품질 지표를 채점합니다. 전제조건 실패 시 부분 진행과 무관하게 0점입니다. LLM-as-judge는 결정론적 대안이 없는 소수 태스크에만, 그것도 넓은 홀리스틱 프롬프트 대신 좁은 예/아니오 프로브로 대체합니다.
결과
세 난이도 계층으로 구성되어 있습니다.
- Near-Term (67개): 현재 에이전트가 부분 완료 가능. 상위 통과율 최대 38%.
- Full-Spectrum (55개): 55개 하위 도메인을 각 1개씩 커버하도록 설계.
- Last-Exam (38개): 최고 난이도. 대부분 에이전트 통과율 0%.
에이전트 + 백본 |
Near-Term Pass (%) |
Full-Spectrum Pass (%) |
Last-Exam Pass (%) |
전체 통과율 (%) |
|---|---|---|---|---|
Codex + GPT-5.5 |
38.1 |
22.7 |
0.0 |
24.0 |
ALE-Claw + GPT-5.5 |
32.8 |
23.6 |
2.6 |
23.0 |
Claude Code + Fable 5 |
34.3 |
20.9 |
0.0 |
22.0 |
Cursor + GPT-5.5 |
32.1 |
20.0 |
2.6 |
20.7 |
Cursor + Opus 4.7 |
29.9 |
20.0 |
2.6 |
20.4 |
Gemini CLI + Gemini 3.1 Pro |
26.9 |
12.7 |
0.0 |
15.8 |
Claude Code + Opus 4.8 |
26.9 |
10.9 |
0.0 |
15.8 |
Grok CLI + Grok 4.3 |
9.0 |
7.3 |
0.0 |
6.6 |
Last-Exam 계층에서 0%가 아닌 에이전트는 ALE-Claw와 Cursor 일부 구성만(2.6%) 있을 뿐, 사실상 전 에이전트가 벽에 막힙니다. Terminal-Bench에서 82%를 기록하는 Codex+GPT-5.5가 ALE-CLI(Linux 전용 하위셋, 105개)에서는 23.3% 통과에 그칩니다. 같은 CLI 위주 태스크인데 ALE 쪽이 훨씬 어렵다는 뜻입니다.
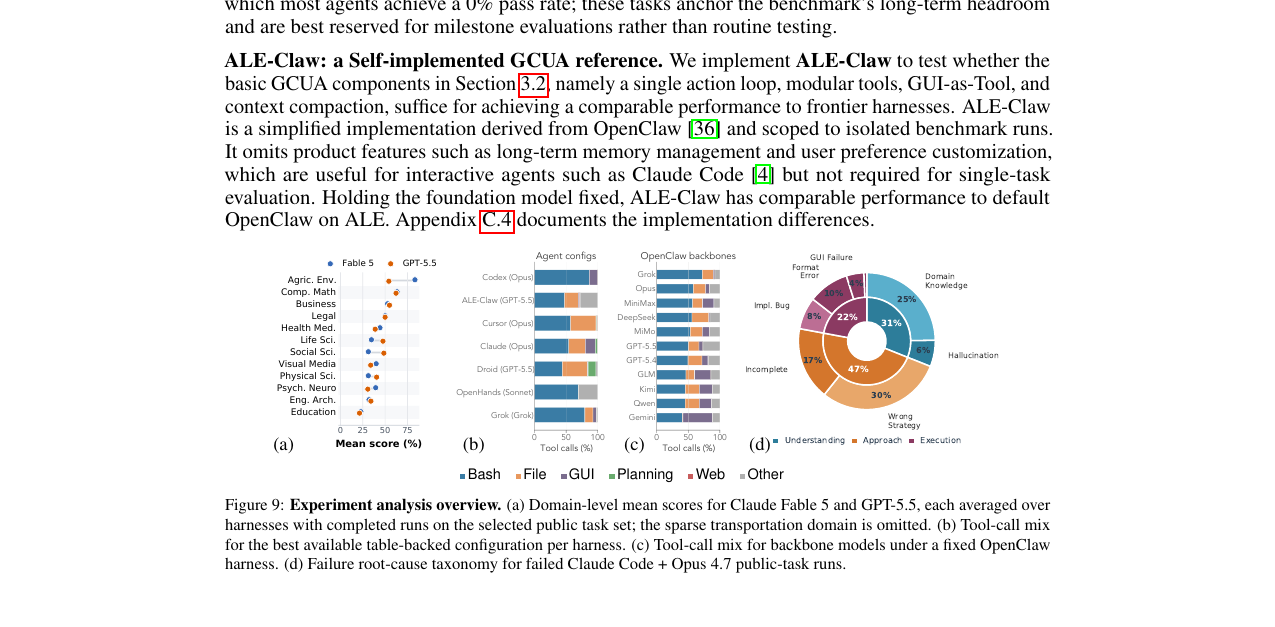
도메인별로 보면(Figure 9(a)), 계산수학과 농업·환경에서 \(\sim\)55-85%로 가장 높고, 교육 도메인에서 25% 미만으로 최저입니다. 흥미롭게도 Fable 5와 GPT-5.5의 도메인별 순위는 거의 같습니다. 이는 모델 고유 역량 차이보다 학습 데이터 구성의 편향, 즉 코드 인접 도메인에는 노출이 집중되어 있고 전문 직군 워크플로우는 상대적으로 적은 점이 영향을 미치는 것으로 저자들은 해석합니다.
실패 원인 분류(Claude Code + Opus 4.7 기준)에서는 Understanding(도메인 지식 부족)과 Approach(전략 선택 오류)가 합쳐 약 75%를 차지합니다. 실행 능력보다 도메인 지식이 현재 병목이라는 것입니다. 에이전트들은 전문 소프트웨어 대신 Bash/CLI 우회 방법을 택하는 경향이 있는데, 이것도 도메인 지식 부족에서 비롯됩니다. GUI 도구를 써야 하는 태스크가 34%이지만 실제 GUI 사용 비중은 대부분 구성에서 그보다 훨씬 낮습니다.
백본 모델 선택이 에이전트 하네스 선택보다 성능 분산에 \(3\times\) 더 큰 영향을 미칩니다. 또한 비용·시간·토큰 소비가 높다고 해서 성능이 비례해 오르지 않습니다.
현재 1,490개 태스크는 비물리적 디지털 산업만 다룹니다. 물리 세계 조작이 포함되는 제조·의료 현장 등은 범위 밖입니다. 150개 공개 태스크만으로 평가하므로 대규모 시스템 비교에는 비용이 여전히 높습니다. 태스크당 평균 $3-10, 수십 분에서 수 시간이 걸립니다. 그리고 어떤 태스크가 "경제적으로 의미 있는가"는 advisory committee의 판단에 달려 있어 주관성을 완전히 제거하지는 못했습니다.
- ALE는 전문가 업무 그대로를 자동 채점으로 평가하는 첫 55-산업 전 커버 벤치마크입니다.
- 최강 구성(Codex + GPT-5.5)도 전체 통과율 24%, Last-Exam 계층에서 0%입니다.
- 현재 에이전트의 병목은 실행 능력이 아니라 도메인 지식입니다.