OPID - On-Policy Skill Distillation for Agentic Reinforcement Learning
S. Yang, J. Wu, Z. Lu, Y. Shen, F. Zhang, L. Feng, S. Zhang, H. Luo, Z. Lian, Z. Wen, and J. Tao, "OPID: On-Policy Skill Distillation for Agentic Reinforcement Learning," arXiv:2606.26790, 2026.
저자
청화대학교(Tsinghua University) 자동화학과에서 Jinyang Wu가 프로젝트를 이끌었고, 시니어 저자는 Jianhua Tao가 맡았습니다. 두 1저자인 Shuo Yang과 Jinyang Wu는 SPARK, Maestro, SDAR 등 에이전틱 RL 훈련 관련 논문들을 연이어 발표해온 팀의 핵심입니다. Zhengxi Lu는 절강대(Zhejiang University) 소속으로, 이전에 SDAR 논문을 공동 집필했습니다. 여러 기관이 모인 협력 연구이지만, OPID의 핵심 설계는 청화대 그룹에서 나왔습니다.
배경
LLM 기반 에이전트를 강화학습으로 훈련할 때 가장 큰 병목은 **보상의 희박성(reward sparsity)**입니다. ALFWorld처럼 수십 번의 상호작용 끝에 성공/실패 하나가 돌아오는 환경에서는, 어떤 중간 결정이 결과를 만들었는지 GRPO 같은 outcome-based 방법이 알 수 없습니다.
이 문제를 푸는 두 가지 기존 접근이 있습니다.
- On-policy self-distillation(OPSD): 같은 정책을 일반 맥락과 특권 맥락(검증된 해답, 힌트) 아래 구동해 token-level 차이를 학습 신호로 활용합니다. 밀집된 감독을 제공하지만, 특권 맥락 자체가 외부에서 제공되어야 합니다.
- Skill-conditioned 방법(Skill-SD, SDAR 등): 자연어 스킬을 교사 가지에 주입해 정책을 안내합니다. 하지만 외부 스킬 라이브러리를 유지해야 하고, 라이브러리의 스킬이 현재 정책의 상태 분포와 어긋날 수 있습니다.
OPID는 두 접근의 결합을 목표로 합니다. 스킬을 외부에서 가져오는 대신, 현재 정책이 방금 완료한 궤적 자체에서 스킬을 추출합니다. 추론 시점에는 스킬 조회나 분석기 호출이 전혀 없습니다.
어떻게 만들었나
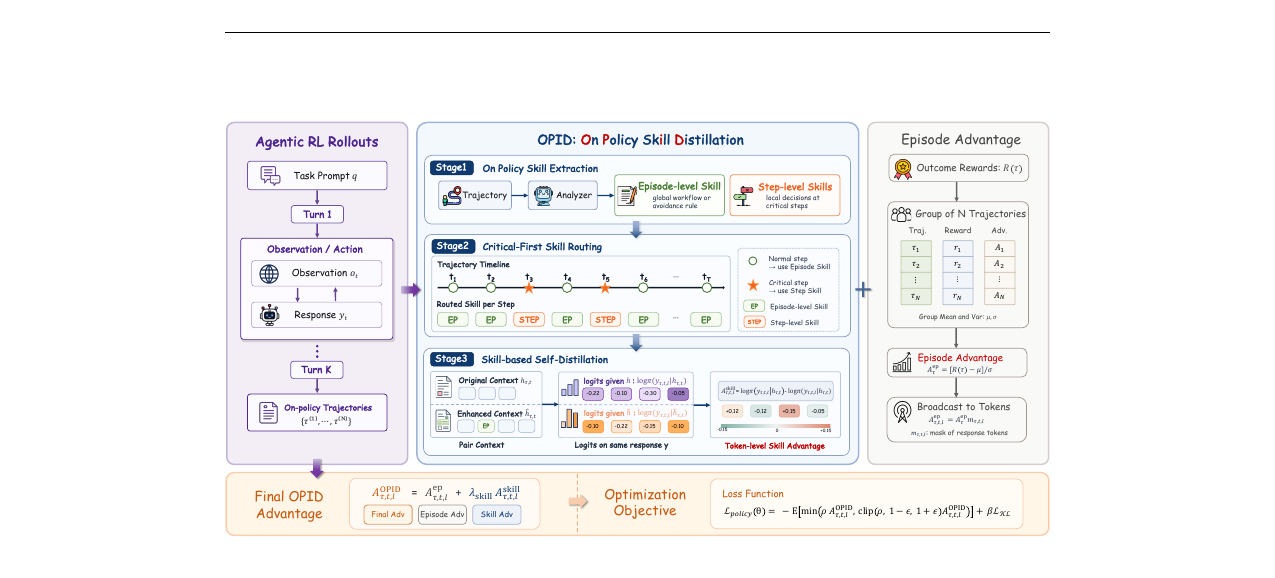
OPID 파이프라인은 세 단계로 구성됩니다.
문제 정식화
에이전틱 과제를 부분 관측 마르코프 결정 과정으로 정의합니다.
\[(\mathcal{S}, \mathcal{A}, \mathcal{O}, \mathcal{T}, \mathcal{R}, \gamma)\]
\(t\)번째 스텝에서 에이전트는 상호작용 히스토리 \(h_t = (o_0, y_0, o_1, y_1, \ldots, o_t)\)를 조건으로 행동 \(y_t \sim \pi_\theta(\cdot \mid h_t)\)를 생성합니다. 완료된 궤적 \(\tau = \{(o_t, y_t, r_t)\}_{t=0}^{T-1}\)의 결과 보상은 \(R(\tau) \in \{0, 1\}\)입니다.
GRPO 방식대로 동일 프롬프트 \(q\)에 대해 \(N\)개 궤적 그룹 \(\mathcal{G}_q = \{\tau^{(1)}, \ldots, \tau^{(N)}\}\)을 샘플링합니다.
1단계: 온-폴리시 스킬 추출
완료된 궤적 \(\tau\)가 주어지면, LLM 분석기 \(\mathcal{A}\)가 두 종류의 힌드사이트 스킬을 생성합니다.
\[\mathcal{A}(\tau) = \left(s_\tau^{\text{ep}},\; \{s_{\tau,t}^{\text{step}}\}_{t \in \mathcal{C}_\tau}\right)\]
- 에피소드 레벨 스킬 \(s_\tau^{\text{ep}}\): 궤적 전체의 행동 패턴을 요약합니다. 성공 궤적이면 재사용 가능한 워크플로우, 실패 궤적이면 실수 회피 규칙이 됩니다.
- 스텝 레벨 스킬 \(s_{\tau,t}^{\text{step}}\): 결정적 시점 \(t \in \mathcal{C}_\tau\)에서의 국소적 판단 지식을 담습니다. 반복 행동 회피, 다음 탐색 대상 선택, 잘못된 부분 목표 수정 같은 스파스하고 상태에 종속적인 정보입니다.
구현에서는 GLM-5.2를 분석기로 사용하며, 에피소드당 평균 3.7개의 임계 스텝이 식별됩니다.
2단계: Critical-First 스킬 라우팅
에피소드 스킬은 대부분의 스텝에 기본 지침으로 적합하지만, 결정적 스텝에서는 너무 뭉툭합니다. 스텝 스킬은 정확하지만 드뭅니다. OPID는 이 트레이드오프를 라우팅으로 해결합니다.
\[s_{\tau,t} = \begin{cases} s_{\tau,t}^{\text{step}}, & t \in \mathcal{C}_\tau \\ s_\tau^{\text{ep}}, & \text{otherwise} \end{cases}\]
임계 스텝으로 식별된 시점에는 스텝 스킬을 우선 배정하고, 나머지는 에피소드 스킬로 덮습니다. 두 스킬을 단순히 중첩하지 않고 하나를 선택하는 것이 핵심입니다. 이 선택이 두 스킬을 독립적인 신호로 유지시켜 줍니다.
3단계: 스킬 기반 자기 증류
라우팅된 스킬 \(s_{\tau,t}\)를 상호작용 히스토리에 주입해 스킬 증강 히스토리를 만듭니다.
\[\tilde{h}_{\tau,t} = H(h_{\tau,t},\; s_{\tau,t})\]
응답 \(y_{\tau,t}\)는 새로 생성하지 않습니다. 대신 기존 정책 \(\pi_{\theta_{\text{old}}}\)가 같은 응답을 원래 히스토리와 스킬 증강 히스토리 아래에서 각각 재채점합니다. 토큰 \(\ell\)에 대해
\[\ell_{\tau,t,\ell}^{\text{old}} = \log \pi_{\theta_{\text{old}}}(y_{\tau,t,\ell} \mid h_{\tau,t},\, y_{\tau,t,<\ell})\]
\[\ell_{\tau,t,\ell}^{\text{skill}} = \log \pi_{\theta_{\text{old}}}\!\left(y_{\tau,t,\ell} \mid \tilde{h}_{\tau,t},\, y_{\tau,t,<\ell}\right)\]
두 log-prob 차이가 스킬 어드밴티지입니다.
\[A_{\tau,t,\ell}^{\text{skill}} = \left(\ell_{\tau,t,\ell}^{\text{skill}} - \ell_{\tau,t,\ell}^{\text{old}}\right) m_{\tau,t,\ell}\]
\(m_{\tau,t,\ell} \in \{0, 1\}\)은 유효 응답 토큰 마스크입니다. \(A^{\text{skill}} > 0\)이면 스킬 맥락이 해당 토큰의 확률을 높인다는 의미이고, \(< 0\)이면 스킬과 어긋나는 토큰임을 뜻합니다.
최적화 목적 함수
GRPO 방식으로 그룹 내 정규화된 에피소드 어드밴티지를 구합니다.
\[A_\tau^{\text{ep}} = \frac{R(\tau) - \mu_q}{\sigma_q}, \quad \tau \in \mathcal{G}_q\]
최종 OPID 어드밴티지는 두 신호의 합입니다.
\[A_{\tau,t,\ell}^{\text{OPID}} = A_{\tau,t,\ell}^{\text{ep}} + \lambda_{\text{skill}} A_{\tau,t,\ell}^{\text{skill}}\]
정책 손실은 표준 clipped PPO 목적 함수입니다.
\[\mathcal{L}_{\text{policy}}(\theta) = -\mathbb{E}_{\tau,t,\ell}\!\left[\min\!\left(\rho_{\tau,t,\ell}(\theta)\, A_{\tau,t,\ell}^{\text{OPID}},\; \mathrm{clip}\!\left(\rho_{\tau,t,\ell}(\theta), 1-\epsilon, 1+\epsilon\right) A_{\tau,t,\ell}^{\text{OPID}}\right)\right] + \beta \mathcal{L}_{\text{KL}}(\theta)\]
여기서 \(\rho_{\tau,t,\ell}(\theta)\)는 토큰 레벨 중요도 비율입니다. 에피소드 어드밴티지가 RL의 기본 신호를 유지하고, 스킬 어드밴티지가 token-level 형태 신호를 추가하는 구조입니다.
이론적으로 OPID 스킬 손실은 sampled-token reverse-KL 증류의 정확한 surrogate임이 증명됩니다. 온-폴리시 컨텍스트 수집이 외부 분포 불일치를 제거하고, critical-first 라우팅이 oracle 교사 선택에 수렴한다는 세 가지 Proposition이 부록에 제시됩니다.
결과
세 에이전틱 벤치마크(ALFWorld·WebShop·Search-based QA)에서 Qwen2.5-3B/7B 및 Qwen3-1.7B를 백본으로 평가했습니다.
방법 |
ALFWorld (%) |
Search-QA (%) |
WebShop Succ (%) |
|---|---|---|---|
GRPO (Qwen2.5-3B) |
75.0 |
36.4 |
63.3 |
Skill-SD (Qwen2.5-3B) |
52.3 |
47.5 |
64.0 |
SDAR (Qwen2.5-3B) |
84.4 |
49.0 |
68.0 |
OPID (Qwen2.5-3B) |
84.3 |
45.0 |
74.2 |
GRPO (Qwen2.5-7B) |
81.2 |
42.0 |
72.6 |
SDAR (Qwen2.5-7B) |
88.3 |
49.0 |
68.0 |
OPID (Qwen2.5-7B) |
90.0 |
48.8 |
79.7 |
GRPO (Qwen3-1.7B) |
46.1 |
40.0 |
38.3 |
SDAR (Qwen3-1.7B) |
58.9 |
39.7 |
58.6 |
OPID (Qwen3-1.7B) |
58.9 |
38.1 |
64.8 |
OPID는 Qwen2.5-3B 기준으로 GRPO 대비 ALFWorld +9.3p, WebShop +10.9p 향상을 보입니다. 가장 두드러진 사례는 Qwen3-1.7B의 WebShop으로, GRPO 대비 +26.5p 상승합니다. Search-QA에서는 OPID가 SDAR보다 낮은 경우도 있어(Qwen3-1.7B), 전 환경 SOTA는 아닙니다.
스킬 기여 분해와 라우팅 효과는 ablation으로 확인됩니다.
방법 (Qwen2.5-3B) |
ALFWorld (%) |
WebShop Succ (%) |
|---|---|---|
OPID (전체) |
84.3 |
74.2 |
w/o 에피소드 스킬 |
74.1 |
67.2 |
w/o 스텝 스킬 |
79.1 |
65.6 |
w/o Critical-First 라우팅 |
77.5 |
- |
에피소드 스킬을 빼면 ALFWorld가 10.2p 하락합니다. 스텝 스킬 제거는 5.2p 하락입니다. 두 스킬이 보완적임을 보여줍니다. 라우팅을 제거하고 단순 중첩으로 교체하면 6.8p 하락해, 스킬 선택 방식 자체가 중요한 설계 요소임을 확인할 수 있습니다.
샘플 효율 분석에서는 60%의 훈련 데이터로 GRPO 100% 수준(75.0)에 근접한 71.9를 달성합니다. 동일한 궤적에서 추가 감독 신호를 뽑아내므로, 환경 상호작용 비용이 고정된 상황에서 OPID의 이점이 더 두드러집니다.
비분포 일반화 실험에서 ALFWorld 미출현 태스크 타입에서도 평균 78.6%를 기록해 GRPO(70.9%) 대비 7.7p 앞섰습니다. Look (+26.7p), Heat (+18.5p) 유형에서 특히 두드러지며, 스킬이 단순 암기가 아닌 전이 가능한 행동 규칙을 담고 있음을 시사합니다.
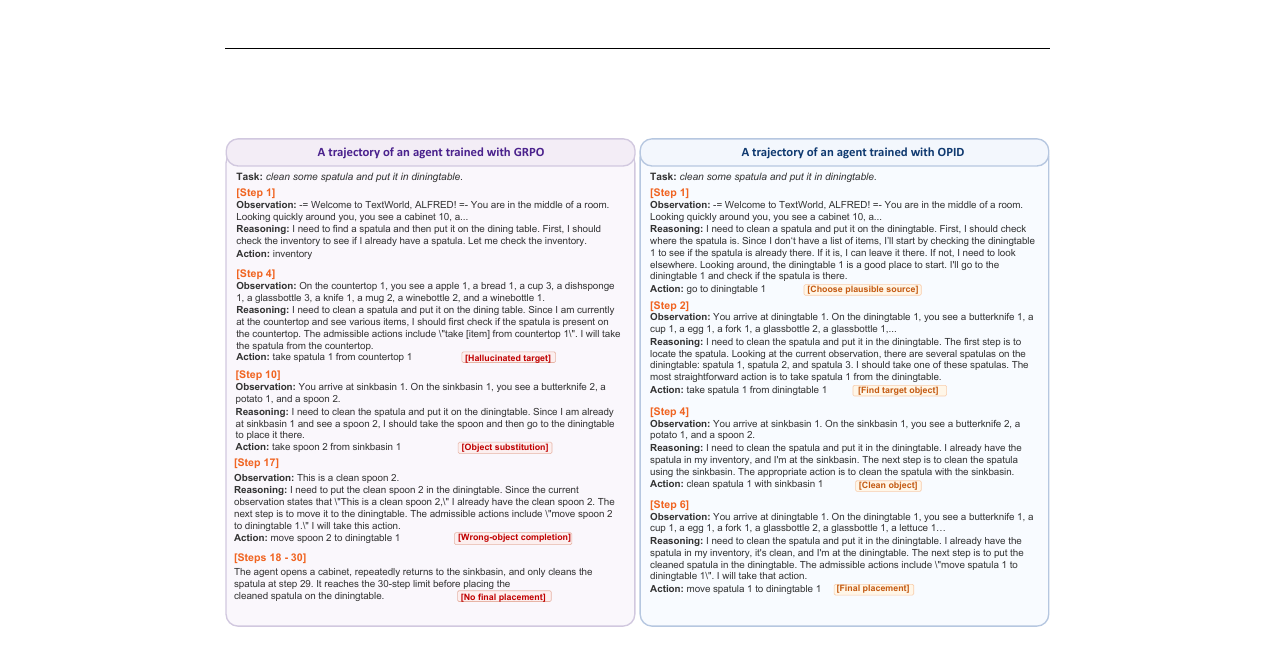
Figure 6은 ALFWorld "공간을 청소해 식탁 위에 올려라" 과제에서 두 에이전트를 정성적으로 비교합니다. GRPO 에이전트는 Step 4에서 존재하지 않는 삽을 집으려는 환각을 보이고, Step 10에서 스푼으로 대상을 교체하고, 결국 30 스텝 제한 내에 최종 배치를 완료하지 못합니다. OPID 에이전트는 6스텝만에 찾기-청소-배치 워크플로우를 완수합니다.
회고
저자들이 Appendix E에서 인정하는 한계 세 가지입니다.
1. 평가 환경 범위가 좁습니다. ALFWorld, WebShop, Search-QA는 텍스트 기반의 비교적 정형적인 환경입니다. OdysseyArena, Mind2Web, VisualWebArena처럼 더 길고 개방적이며 멀티모달한 환경에서의 검증이 남아 있습니다.
2. 분석기 의존성이 있습니다. GLM-5.2를 분석기로 사용하며, 이 모델이 임계 스텝과 스킬의 질을 결정합니다. 분석기 품질이 낮아지면 라우팅이 엇나갈 수 있고, 분석기 오류 확률이 \(\Gamma \cdot \Pr(\hat{z}_i \neq z_i^*)\)만큼 기대 라우팅 오류에 비례해 추가됩니다.
3. 스킬 구조가 2계층으로 고정됩니다. 에피소드·스텝 두 단계 너머의 상위 추론 패턴이나 궤적 간 재사용 가능한 사고 구조 같은 고차원 스킬은 현재 다루지 않습니다.
계산 비용도 언급할 만합니다. 훈련은 8개의 A100 80G GPU를 사용합니다. 추론 시에는 분석기·스킬 없이 동작하지만, 훈련 시점에 매 궤적마다 분석기 호출과 이중 채점(original + skill-augmented)이 발생합니다.
정리
- OPID는 외부 스킬 라이브러리 없이 완료된 온-폴리시 궤적에서 스킬을 추출해, GRPO의 희박한 결과 신호를 token-level 증류 어드밴티지로 보완합니다.
- Critical-first 라우팅이 핵심 설계 요소입니다. 에피소드 스킬과 스텝 스킬을 중첩하는 대신 스텝별로 하나를 선택하며, 이 선택 자체가 평균 6.8p 이상의 성능 차이를 만듭니다.
- 훈련에 익힌 스킬은 추론 시점에 파라미터 안으로 내재화되어, 스킬 프롬프트를 달고 평가한 Skill-GRPO* 수준을 스킬 없이 넘깁니다.