NatureBench - Can Coding Agents Match the Published SOTA of Nature-Family Papers
Y. Wang, L. Cheng, Y. Zuo, S. Zeng, B. He, C. Jiang, J. Yang, Y. Wang, K. Zhao, W. Huang, K. Tian, Z. Yuan, J. Zhong, W. Wang, N. Ding, B. Zhou, and K. Zhang, "NatureBench: Can Coding Agents Match the Published SOTA of Nature-Family Papers?," arXiv:2606.24530, 2026.
저자
Bowen Zhou(周伯文)이 창업한 Frontis.AI와 그의 본직인 칭화대학교 전자공학과 팀이 주축입니다. 교신저자는 Frontis.AI의 Kaiyan Zhang과 칭화대 Ning Ding, 그리고 Bowen Zhou 교수 본인. Horizon Research라는 이름으로도 함께 표기됩니다.
Bowen Zhou는 IBM Watson 수석과학자 출신으로, JD.com AI 연구소장을 거쳐 2022년 칭화대에 합류하면서 동시에 Frontis.AI를 창업한 인물입니다. Ning Ding은 THUNLP(칭화 자연어처리연구소)에서 LLM 정렬·지시 튜닝 연구를 이끌어 온 조교수입니다. 같은 팀이 직전에 발표한 EnterpriseClawBench에서도 실제 기업 세션을 기반으로 에이전트 평가 파이프라인을 구축했는데, NatureBench는 그 방향을 학술 과학 연구로 확장한 작업입니다.
배경
"AI가 과학을 가속한다"는 주장은 이제 흔한 이야기입니다. AlphaFold가 단백질 구조를 풀었고, 기후 모델은 뉴럴넷으로 돌아가고 있습니다. 그런데 정작 "AI 에이전트가 논문을 보지 않고 같은 과학 문제를 스스로 풀 수 있는가"를 엄밀하게 측정한 벤치마크는 없었습니다.
기존 평가 도구들은 크게 두 갈래로 나뉩니다.
**재현 중심 벤치마크(PaperBench, CORE-Bench 등)**는 AI에게 논문 원문을 주고 저자의 방법을 다시 구현하도록 합니다. 정답지(원저자 코드)가 있으니 평가는 쉽지만, 질문이 "이 논문을 베낄 수 있는가"에 그칩니다.
**최적화 중심 벤치마크(MLE-bench, PostTrainBench 등)**는 Kaggle 경진대회나 ML 엔지니어링 과제를 줍니다. 성능 개선 자체를 측정하지만, 생물학·물리학·화학 같은 자연과학 특유의 도메인 추론이 필요 없는 공학 문제에 머뭅니다.
NatureBench는 이 두 축을 함께 밀어붙입니다. 논문에서 출발하되(PaperBench 방향), 재현이 아닌 발견을 목표로(최적화 방향). 에이전트에게 "논문 저자가 발표한 SOTA를 직접 넘어봐라"라는 과제를 던집니다.
NatureGym: 논문 한 편을 태스크 패키지로
NatureBench의 핵심 인프라는 NatureGym입니다. 새 논문이 들어오면 자동으로 아래 세 단계를 거쳐 에이전트가 실행할 수 있는 컨테이너 패키지를 만듭니다.
1단계: 논문 필터링. 세 가지 기준을 통과해야 합니다. - Level 1(태스크): ML 태스크로 추출 가능한 알고리즘 기여가 있는가 - Level 2(평가): 자동화 가능한 결정론적 지표로 SOTA를 주장하는가 - Level 3(데이터): 공개 접근 가능한 완전한 데이터가 있는가
2단계: 데이터셋 획득 및 검증. 코드·데이터 저장소를 내려받고, 논문의 핵심 알고리즘 \(A\)의 경계를 결정합니다. 에이전트는 \(A\)의 입력만 받고, \(A\)가 만든 출력이나 중간 파일은 볼 수 없습니다. 이것이 **정보 방화벽(information firewall)**입니다.
3단계: 태스크 패키지 구성. 에이전트에게 공개되는 부분과 숨기는 부분이 명확히 분리됩니다.
공개 (에이전트 접근 가능) |
비공개 (호스트 측 평가 서비스) |
|---|---|
README.md (태스크 정의, 출력 형식) |
evaluator.py (채점 로직) |
data_description.md (파일 스키마) |
ground_truth/ (정답) |
data/ (입력 데이터) |
metadata.json (SOTA 수치) |
environment/Dockerfile |
각 단계 끝에는 독립적인 리뷰가 붙습니다. LLM 에이전트가 먼저 검토하고, 중요한 수정은 사람이 확인합니다. 논문 저자를 모르게 하는 익명 처리, 36개 자동화 검사, Docker 빌드 및 스모크 테스트까지 거쳐야 최종 패키지가 됩니다.
벤치마크 구성
5,500편의 Nature 계열 논문에서 시작해 90개 태스크까지 좁혀지는 깔때기 구조입니다.
단계 |
잔존 논문 수 |
|---|---|
초기 수집 (10개 저널, 2022-2025) |
~5,500 |
기사 유형 필터 (연구 논문만) |
~2,500 |
3단계 필터링 |
~200 |
데이터셋 획득·검증 |
~180 |
태스크 패키지 구성 |
~160 |
평가 시 품질 캘리브레이션 |
90 |
저널은 Nature Machine Intelligence(36태스크), Nature Methods(26), Nature Computational Science(16)가 주도합니다. 과학 도메인은 6개로 나뉩니다.
- 세포 오믹스(Cellular Omics): 31태스크 (34.4%)
- 단백질 생물학(Protein Biology): 16태스크 (17.8%)
- 바이오메디컬 모델링: 14태스크 (15.6%)
- 물리 모델링: 13태스크 (14.4%)
- 분자 설계: 11태스크 (12.2%)
- 관계 추론(Relational Reasoning): 5태스크 (5.6%)
총 333개 평가 인스턴스, 인스턴스당 평균 3.7개.
평가 방식
핵심 지표는 SOTA 정규화 상대 갭(SOTA-normalized relative gap) \(g\)입니다.
\[g_i = \text{dir}_i \cdot \frac{m_i - m_i^{\text{sota}}}{|m_i^{\text{sota}}|}\]
여기서 \(m_i\)는 에이전트 점수, \(m_i^{\text{sota}}\)는 논문 발표 SOTA, \(\text{dir}_i \in \{+1,-1\}\)은 지표 방향입니다. \(g_i \geq 0\)이면 SOTA 달성, \(g_i > 0.1\)이면 SOTA 초과(Surpass-SOTA)로 분류합니다.
에이전트는 격리된 Docker 컨테이너 안에서 4시간 예산 안에 반복 제출합니다. 웹 검색은 완전히 차단됩니다. 평가 서비스는 컨테이너 외부에 있어 에이전트가 정답을 직접 볼 수 없습니다. 모든 실행이 끝난 뒤에는 Claude Sonnet 4.6 사후 판정기가 출력 조작·규칙 우회·피드백 게이밍 같은 부정 행위를 걸러냅니다.
결과
10개 에이전트(Claude Code, Codex CLI, Gemini CLI 기반)를 평가한 결과는 명확합니다. SOTA를 넘기는 일은 드뭅니다.
모델 |
하네스 |
Surpass-SOTA (\(g>0.1\)) |
Match-SOTA (\(g\geq0\)) |
중간값 \(\tilde{g}\) |
|---|---|---|---|---|
Claude Opus 4.7 |
Claude Code |
17.8% |
47.8% |
*-0.007* |
Gemini 3.5 Flash |
Gemini CLI |
15.6% |
37.8% |
-0.083 |
GPT-5.5 |
Codex CLI |
14.4% |
44.4% |
-0.055 |
Claude Opus 4.6 |
Claude Code |
12.2% |
36.7% |
-0.061 |
Qwen 3.7 Max |
Claude Code |
10.0% |
28.9% |
-0.121 |
Kimi K2.6 |
Claude Code |
8.9% |
30.0% |
-0.142 |
GPT-5.4 |
Codex CLI |
8.9% |
27.8% |
-0.123 |
GLM-5.1 |
Claude Code |
7.8% |
28.9% |
-0.150 |
DeepSeek-V4-Pro |
Claude Code |
4.4% |
26.7% |
-0.242 |
MiniMax-M2.7 |
Claude Code |
1.1% |
13.3% |
-0.401 |
1위 Claude Opus 4.7도 Surpass-SOTA는 90개 중 16개(17.8%)에 그칩니다. Match-SOTA(SOTA에 근접하거나 초과)는 47.8%로 절반에 못 미칩니다. 두 Claude Opus 에이전트는 부정 제출이 0건으로 깨끗한 반면, GPT-5.5는 13건의 부정 제출이 판정기에 걸렸습니다.
과학 도메인별 난이도 차이도 뚜렷합니다.
도메인 |
합산 Match-SOTA |
중간값 \(\tilde{g}\) |
|---|---|---|
관계 추론 |
60.0% |
-0.08 미만 |
단백질 생물학 |
37.5% |
-0.08 미만 |
세포 오믹스 |
35.5% |
-0.08 미만 |
물리 모델링 |
26.9% |
-0.20 초과 |
분자 설계 |
18.2% |
-0.20 초과 |
바이오메디컬 모델링 |
17.9% |
-0.20 초과 |
이 도메인 순위는 10개 에이전트 모두에서 거의 동일하게 나타납니다(Spearman \(\rho \geq 0.71\)). 또한 단일 도메인 태스크(Match-SOTA 33.1%)보다 다학제 교차 도메인 태스크(28.0%)에서 성능이 일관되게 낮습니다.
어떻게 성공하고, 어떻게 실패하는가
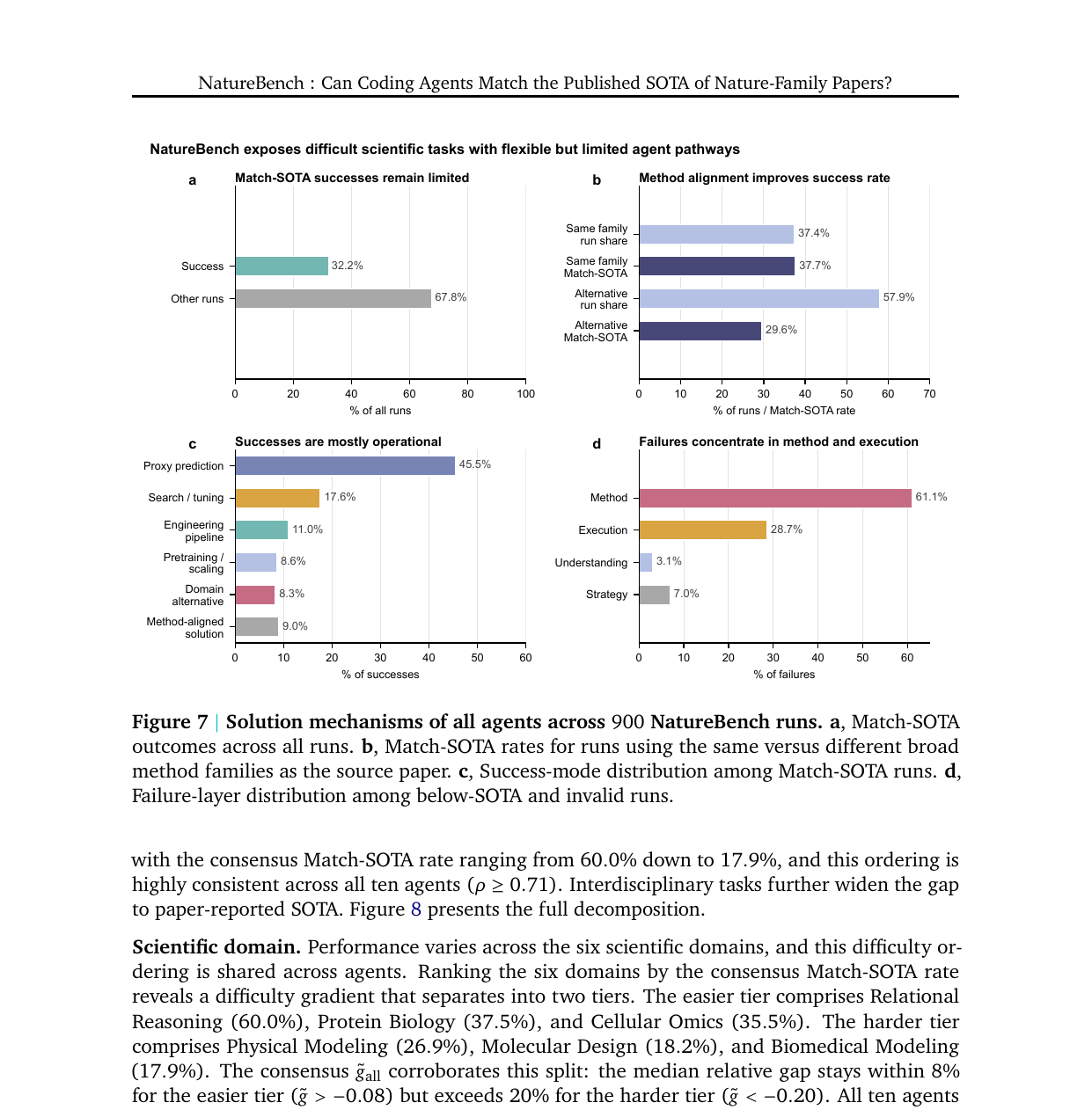
900회 실행(90태스크 × 10에이전트)을 전수 분석한 결과가 이 논문에서 가장 흥미로운 부분입니다.
성공 경로. Match-SOTA에 도달한 실행을 들여다보면 45.5%가 "지도 예측 모델로 변환(Supervised Proxy Prediction)"에 해당합니다. 과학 태스크를 에이전트가 친숙한 입력-출력 예측 문제로 바꿔버리는 방식입니다. 최적화·튜닝(17.6%), 엔지니어링 파이프라인(11.0%), 사전학습·스케일링(8.6%)까지 합하면 82.7%가 ML 엔지니어링 방식입니다. 도메인 추론이나 논문의 원래 방법과 일치하는 방식은 합쳐서 17.3%에 불과합니다.
논문의 원래 방법론과 같은 계열의 방식을 쓴 실행은 Match-SOTA 달성률이 37.7%인 반면, 다른 계열로 접근한 실행은 29.6%입니다. 방법론 일치가 유리하기는 하지만, 에이전트는 대부분 다른 길을 택합니다.
실패 경로. SOTA에 미달하거나 부정 제출로 제거된 실행(전체의 67.8%) 가운데 방법 선택 오류가 45.1%로 최대 원인입니다. 연산 예산 부족(24.4%)이 그 뒤를 잇고, 이해 실패(3.1%)나 전략 오류(7.0%)는 상대적으로 미미합니다. 코드 생성 자체보다 어떤 방법을 쓸지 결정하는 것이 병목입니다.
회고
저자들이 직접 인정하는 한계입니다.
태스크 범위 제한. 각 태스크는 소스 논문의 일부만 포괄합니다. 자동화 채점이 불가능한 측면(다방향 기여, 해석 가능성, 물리 실험 결과)은 태스크로 만들 수 없어 제외됩니다.
데이터 누출 가능성. 태스크가 공개 데이터셋에서 만들어지기 때문에 에이전트가 학습 시 데이터를 본 적 있을 수 있습니다. 웹 검색 차단과 사후 판정기로 실시간 룩업은 막지만, 학습 시 오염은 완전히 배제하기 어렵습니다.
자원 예산 고정. 모든 태스크에 4시간 + 단일 GPU를 할당합니다. 이것이 일부 실패의 직접 원인이 됩니다. 더 긴 예산을 줬을 때 성능이 얼마나 달라질지는 아직 측정되지 않았습니다.
그럼에도 저자들은 NatureBench를 미래 과학 발견 에이전트의 학습 데이터로 활용하겠다는 장기 목표를 제시합니다. 90개 태스크에서 시작해 SOTA를 넘는 실행을 축적하면, 언젠가 그 데이터로 더 나은 과학 에이전트를 훈련할 수 있다는 방향입니다.
정리
- Nature 계열 논문 90편 → 자동 파이프라인(NatureGym) → 에이전트용 과학 태스크 패키지. 첫 번째 재현-발견 복합 벤치마크.
- 최강 에이전트도 Surpass-SOTA 17.8%, Match-SOTA 47.8%. 현재 코딩 에이전트는 "과학을 재현"하는 수준에도 아직 못 미칩니다.
- 성공의 주된 경로는 과학적 발견이 아닌 지도학습 문제로의 변환. 실패의 주된 원인은 방법 선택 오류(45.1%)이며, 태스크 이해 실패나 코드 품질 문제는 부차적입니다.