MetaForge - A Self-Evolving Multimodal Agent that Retrieves, Adapts, and Forges Tools On Demand
S. Wei, H. Min, X. Dong, X. Lin, et al., "MetaForge: A Self-Evolving Multimodal Agent that Retrieves, Adapts, and Forges Tools On Demand," arXiv:2606.01801, 2026.
멀티모달 에이전트는 외부 도구를 불러 쓰면서 복잡한 작업을 풀어 왔습니다. OCR로 글자를 읽고, OpenCV로 도형을 세고, 코드를 돌려 계산합니다. 그런데 두 가지 한계가 따라붙습니다. 도구 목록을 미리 고정해 두면 처음 보는 상황에서는 맞는 도구가 없고, 반대로 도구를 가리지 않고 부르면 불필요한 호출이 비용과 노이즈 오류를 키웁니다.
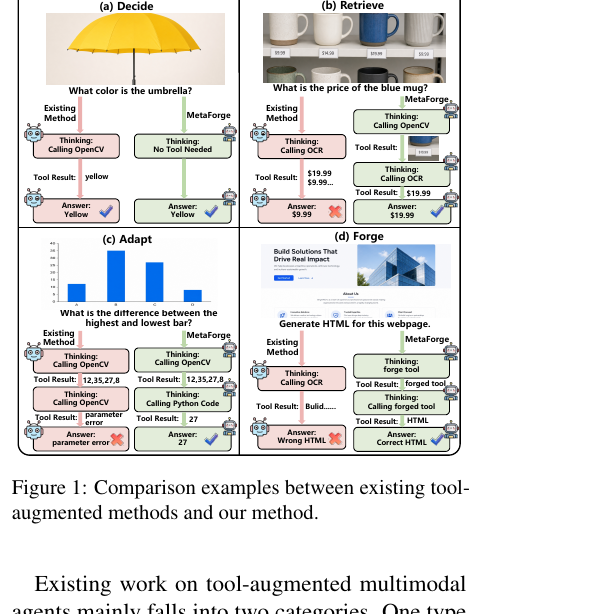
Shouang Wei와 Houcheng Min 외 연구진이 내놓은 MetaForge는 이 둘을 한꺼번에 다룹니다. 에이전트가 "도구를 언제 쓸지"와 "도구를 어떻게 늘릴지"를 스스로 배우게 만드는 프레임워크입니다. 핵심은 행동을 네 단계로 쪼개고, 그 전체를 강화학습으로 함께 최적화한 데 있습니다.
저자
이 논문은 화둥사범대학교가 주도하고 저장대·칭화대·홍콩중문대(선전)·홍콩교육대가 함께한 작업입니다. 공동 1저자는 화둥사범대의 Shouang Wei와 Houcheng Min이고, 교신저자이자 프로젝트 리더는 장민입니다.
저자 명단에는 멀티모달과 인과추론 쪽 중진이 들어 있습니다. 우페이는 저장대 인공지능연구원 원장으로 멀티미디어 검색과 지식그래프를 오래 다뤄 왔습니다. 쾅쿤은 같은 저장대에서 인과추론과 머신러닝의 결합을 연구합니다. "도구가 언제·왜 도움이 되는가"를 따지는 이 논문의 문제의식에, 멀티모달 검색과 인과 관점을 가진 연구자들이 모인 구성이 자연스럽게 읽힙니다.
배경
도구를 쓰는 멀티모달 에이전트 연구는 크게 두 갈래였습니다. 하나는 미리 정해 둔 도구 모음에 모델을 붙이는 방식이고, 다른 하나는 추론 루프 안에서 도구를 부르는 방식입니다. 두 방식 모두 도구 모음 자체는 정적입니다.
문제는 현실의 작업이 정적이지 않다는 데 있습니다. 어떤 질문에는 OCR이 필요하고, 어떤 질문에는 차트 파싱이나 기호 계산이 필요합니다. 고정된 목록은 처음 보는 요구를 만나면 빈손이 됩니다. 그렇다고 모든 도구를 항상 부르면, 필요 없는 호출이 쌓여 비용이 늘고 잘못된 도구 결과가 오히려 답을 흐립니다. 기존 방법은 "지금 도구가 필요한가, 필요하면 무엇을, 없으면 어떻게 만들 것인가"를 적응적으로 판단하는 통합된 메커니즘이 없었습니다.
어떻게 만들었나
MetaForge는 에이전트의 도구 사용을 네 단계로 인수분해합니다.
- Decide: 지금 도구가 필요한지부터 판단합니다. 모델이 스스로 답할 수 있으면 도구를 부르지 않습니다.
- Retrieve: 필요하다면 적절한 도구를 고릅니다.
- Adapt: 고른 도구의 파라미터를 작업 맥락에 맞게 채웁니다.
- Forge: 맞는 도구가 없으면 새 도구(스킬)를 즉석에서 합성하고, 그것을 도구 라이브러리에 등록해 나중에 재사용합니다.
네 단계가 서로 맞물려 자가개선 사이클을 이룹니다. 특히 Forge가 만든 도구가 라이브러리로 환류되어 다음 작업에서 다시 쓰인다는 점이 "자가진화"의 핵심입니다.
이 적응적 오케스트레이션 전략을 어떻게 학습시킬까요. MetaForge는 멀티턴 GRPO를 채택하고, 하나의 롤아웃 \(\tau\)(여러 턴의 상호작용)에 대해 여러 신호를 묶은 복합 보상을 설계합니다. 보상은 대략 다음처럼 분해됩니다.
\[r(\tau) = r_{\text{answer}} + r_{\text{retrieve}} + r_{\text{adapt}} + r_{\text{necessity}} + r_{\text{forge}} + r_{\text{format}} - \lambda \, r_{\text{cost}}\]
정답 정확도, 도구 검색의 적절성, 파라미터 적응, 호출의 필요성, 스킬 생성과 재사용, 형식 파싱 가능성을 함께 끌어올리되, 마지막 항으로 호출 비용에 명시적 페널티를 둡니다. 이 비용 항이 "쓸데없이 도구를 부르지 말라"는 압력을 주어, 모델이 Decide 단계에서 도구가 정말 필요한지를 따지도록 만듭니다.
Forge 단계에서 만든 도구가 무한정 쌓이면 라이브러리가 비대해집니다. MetaForge는 사용량 기반 보존 정책으로 도구 풀을 관리합니다. 누적 사용량이 상위 사분위를 넘는(\(u_n(s) \ge \delta_n\), \(\delta_n = Q_3 + 1.5\,\text{IQR}\)) 검증된 도구와, 최근 자주 쓰이는 새 도구를 우선 남깁니다. 역사적 효용이 크거나 현재 수요가 높은 도구를 보존하는 방식입니다.
결과
평가는 도구와 작업의 일반화를 보려고 IID와 OOD 두 설정으로 나눠 진행했습니다. IID는 학습과 같은 분포의 데이터·도구, OOD는 처음 보는 데이터·도구입니다. 백본은 Qwen2.5-VL-7B이고, 12개 멀티모달 벤치마크에서 16개 베이스라인과 비교했습니다.
설정 |
MetaForge 평균 정확도 (%) |
|---|---|
IID (DocVQA·TallyQA·OCRVQA·RoBUT·MapQA·Loc.Narr.) |
87.83 |
OOD (ChartQA·AI2D·WebSight·MathVista·ScienceQA·CLEVR-M) |
88.98 |
세 번의 독립 실행 평균이며, MetaForge는 두 설정 모두에서 12개 벤치마크에 걸쳐 16개 베이스라인을 일관되게 앞섭니다. 중요한 점은 이득이 IID와 OOD 양쪽에서 유지된다는 것입니다. 데이터셋에 특화된 도구 사용 루틴을 외운 게 아니라는 뜻입니다. 저자들은 이 견고함을 온라인 도구 생성, 복합 보상의 멀티턴 GRPO, 도구 풀 관리의 조합 덕으로 봅니다. 빠진 도구를 보충하고, 호출의 유효성을 높이고, 불필요한 호출을 줄인 결과입니다.
몇 가지 관찰이 흥미롭습니다. 고정된 도구 사용 정책을 쓰는 일부 도구 증강 베이스라인은 오히려 기본 모델보다 못합니다. 적응적 호출 판단이 없으면 도구가 독이 될 수 있다는 것입니다. 또 도구의 효과는 기능만이 아니라 모델과의 상보성에 달려 있습니다. 폐쇄형 모델은 IID/OOD 도구 변화에 안정적인데, 자체 능력이 강해 외부 도구 의존이 적기 때문입니다. 반면 오픈소스 멀티모달 모델은 도구 변화에 민감합니다. IID 도구는 지각 기능(OCR·그라운딩·세그멘테이션)을, OOD 도구는 추론 기능(기호 계산·코드 실행·차트 파싱)을 강조하는데, 도구는 모델의 약점을 메울 때 더 크게 돕습니다.
회고
MetaForge의 결과는 백본(Qwen2.5-VL-7B)과 정해진 도구·데이터 분할 위에서 얻은 것입니다. 도구의 효과가 모델과의 상보성에 좌우된다는 발견 자체가, 다른 백본이나 다른 도구 구성에서는 이득의 크기가 달라질 수 있음을 시사합니다. 온라인으로 도구를 합성·등록하는 메커니즘은 강력하지만, 생성된 도구의 품질 검증과 풀 관리의 임계값 설정에 의존하는 부분이 남습니다.
그럼에도 메시지는 분명합니다. 도구를 미리 다 갖춰 주는 대신, 언제 쓸지와 어떻게 만들지를 모델이 스스로 배우게 하는 쪽이 정확도·효율·일반화 모두에서 낫습니다. 정적 도구 증강에서 적응적 자가진화로의 전환을 보여 준 사례입니다.
정리
- MetaForge는 도구 사용을 Decide·Retrieve·Adapt·Forge 네 단계로 나누고, 멀티턴 GRPO 복합 보상(호출 비용 페널티 포함)으로 전체를 함께 학습시킵니다.
- Qwen2.5-VL-7B 위에서 12개 벤치마크 IID/OOD 모두 16개 베이스라인을 앞서며(평균 87.83/88.98), 이득이 분포 밖에서도 유지됩니다.
- 도구는 기능만이 아니라 모델의 약점과 맞물릴 때 돕습니다. 고정 도구 정책은 오히려 해가 될 수 있습니다.