The Era of Agentic Organization - Learning to Organize with Language Models
Z. Chi, L. Dong, Q. Dong, Y. Hao, X. Wu, S. Huang, and F. Wei, "The Era of Agentic Organization: Learning to Organize with Language Models," arXiv:2510.26658, 2025.
저자
1저자 치쩌원는 Microsoft Research GenAI 그룹 연구원으로 베이징이공대 박사를 2024년에 마치고 정규 합류했습니다. 초기에는 다국어 인코더(XY-LENT, InfoXLM)와 Microsoft Research Asia의 멀티모달 라인(Kosmos-1)에 참여했고, 본인 표현으로 최근 라인은 "agentic LLM과 inference-time scaling"으로 명시적으로 옮겨졌습니다. AsyncThink가 그 첫 가시적 결과물입니다.
둥리과 웨이푸루가 2저자·시니어 저자로 붙는 구도는 MSR Asia NLP/멀티모달 라인의 정석 패턴입니다. 두 사람이 사실상 공동으로 그룹을 운영하면서 UniLM, MiniLM, InfoXLM, BEiT, Kosmos, WavLM까지 분야 횡단 시리즈를 끌어왔는데, AsyncThink는 그 그룹이 "대규모 사전학습"에서 "agentic LLM"으로 이동하는 표시판에 가깝습니다.
공저자 둥칭슈은 베이징대 박사 4년차로 인컨텍스트 학습 서베이의 1저자로 가장 잘 알려져 있고, 치쩌원와 같이 MSR Asia 인턴 라인에서 합류했습니다. organizer가 자기 사고 구조를 동적으로 결정하는 방식은 그의 in-context learning 배경과 자연스럽게 맞물립니다.
나머지 공저자 Yaru Hao, Xun Wu, Shaohan Huang은 같은 GenAI 그룹의 시니어 연구원들로, 그룹 차원에서 같은 시기 진행되는 reward modeling 라인(Reward Reasoning Model, arXiv 2505.14674)에도 함께 이름이 올라갑니다. AsyncThink가 단일 페이퍼가 아니라 그룹 전략의 한 조각이라는 신호입니다.
다섯 명을 한 줄로 묶으면 "MSR Asia NLP 그룹이 agentic 시대로 전체 라인을 옮기면서 던진 정초 작업"이라고 정리할 수 있습니다.
배경
LLM 추론 패러다임은 크게 두 갈래로 정착했습니다.
첫째, sequential thinking. Chain-of-Thought 류로, 하나의 디코딩 trajectory에서 토큰을 순차적으로 생성합니다. 추론 품질은 좋지만 길어질수록 지연이 선형으로 늘어납니다.
둘째, parallel thinking. 같은 질의에 대해 여러 trajectory를 독립적으로 샘플링하고 마지막에 집계합니다. 다수결, self-consistency, best-of-N이 여기 속합니다. 동시 실행이라 지연은 줄지만, 집계가 끝까지 기다려야 하기 때문에 결국 가장 느린 trajectory에 묶입니다. 또 사고 구조가 사전에 고정되어 있어 질의에 맞춰 적응적으로 분해할 수 없습니다.
본 논문이 짚는 빈자리는 "사고 구조를 모델 자체가 동적으로 결정하면서, 부분들이 비동기적으로 동시 실행" 되는 패러다임입니다. 저자들은 이걸 agentic organization이라 부르고, 그 첫 구체 구현으로 AsyncThink를 제안합니다.
Organizer-Worker 프로토콜
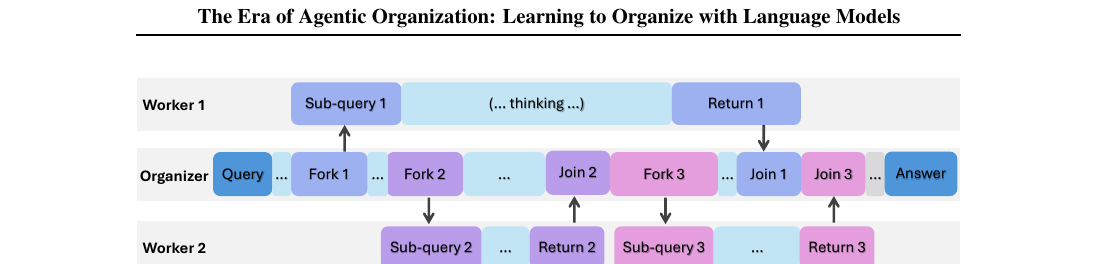
핵심은 단일 LLM에 두 가지 역할을 동시에 부여한다는 점입니다. organizer는 전체 사고 과정을 조율하고, worker는 organizer가 할당한 sub-query를 풀어 답을 돌려보냅니다. 둘 다 같은 LLM, 같은 가중치, 같은 자기회귀 텍스트 디코딩을 씁니다. 차이는 어떤 액션을 취할 수 있느냐 뿐입니다.
organizer가 취할 수 있는 액션은 네 가지입니다.
Think: 자기 디코딩 thread에서 한 칸 진행합니다.Fork:⟨FORK-i⟩ sub-query ⟨/FORK-i⟩형태로 worker에게 일을 위임합니다. 이 시점에 새 worker thread가 비동기로 시작됩니다.Join:⟨JOIN-i⟩형태로 i번째 worker의 결과를 요청합니다. 아직 worker가 안 끝났으면 organizer 디코딩이 멈춰 기다리고, 끝났으면 결과가 organizer 컨텍스트 끝에 붙고 진행을 이어갑니다.Answer: 최종 답을 내고 추론을 종료합니다.
worker는 자기 sub-query만 보고 RETURN으로 끝납니다. organizer의 글로벌 컨텍스트와는 격리되어 있습니다.
용량 \(c\)의 agent pool 안에서 동시에 활성화될 수 있는 worker 수는 \(c - 1\)입니다. 그 이상이 필요해지면 organizer가 Fork를 못 부르고, 기존 worker가 끝나기를 기다려야 합니다.
이 프로토콜의 영리한 점은, 조정 모듈이 따로 없다 는 데 있습니다. organizer는 그냥 LLM이 텍스트로 ⟨FORK-i⟩나 ⟨JOIN-i⟩ 태그를 뱉으면 그 자체가 액션이됩니다. 그 외부에 액션 선택기, 라우터, 별도 토큰 분류기가 끼어 있지 않아, 기존 LLM의 입출력 표면 위에서 그대로 동작합니다. sequential thinking과 parallel thinking은 이 프로토콜의 특수 경우로 자연스럽게 포함됩니다. Fork를 한 번도 안 부르면 sequential, 같은 query를 여러 worker에 반복 할당하면 parallel입니다.
학습 방법
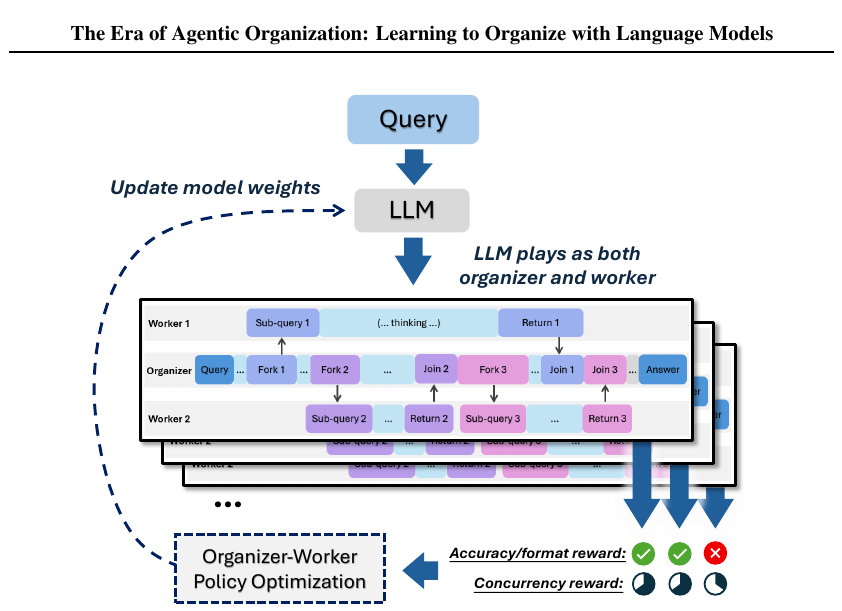
학습은 두 단계입니다.
Stage 1 - Cold-Start Format Fine-Tuning. 기존 코퍼스에는 organizer-worker 사고 trace가 없으니 GPT-4o로 합성합니다. GPT-4o가 입력 질의에서 조건부 독립인 사고 조각을 분석하고, few-shot 예시를 따라 organizer-worker 형식을 채워 query-response 쌍을 만듭니다. 형식 오류가 있는 데이터는 룰 기반으로 걸러냅니다.
이 단계가 끝난 모델은 형식만 흉내내는 수준입니다. 정답을 비동기 사고로 만들어내는 능력은 아직 없습니다. 그 능력은 다음 단계에서 RL로 학습됩니다.
Stage 2 - Reinforcement Learning. GRPO를 organizer-worker thought sample 구조에 맞게 확장한 Organizer-Worker Policy Optimization을 씁니다. organizer trace와 거기 연결된 worker trace 묶음을 하나의 단위로 보고 reward를 계산하며, 같은 unit 안의 모든 토큰에 그 advantage를 공유 할당합니다.
reward는 세 종류입니다.
- Accuracy Reward \(R_A\): 단일 정답 문제는 binary, multi-solution 문제는 \(R_A = \min(n_c, n_s)/n_s\)로, \(n_c\)는 고유 정답 개수, \(n_s\)는 요구되는 정답 수입니다.
- Format Reward \(R_{FE}\): 중복 sub-query, agent pool overflow, 존재하지 않는 sub-query에 대한 Join, 최종 답 없이 멈춤 같은 형식 오류에 페널티.
- Thinking Concurrency Reward \(R_\eta\): 사고가 실제로 동시에 굴러갔는지 보상합니다.
thinking concurrency ratio는 다음과 같이 정의됩니다.
\[\eta = \frac{1}{T} \sum_{t=1}^{T} a_t\]
여기서 \(T\)는 critical-path latency, \(a_t\)는 글로벌 디코딩 step \(t\)에서 활성 worker 수입니다. concurrency reward는 다음과 같습니다.
\[R_\eta = \min(\eta / c, \tau) / \tau\]
\(\tau\)는 reward hacking을 막기 위한 임계값입니다. 최종 reward는 다음 두 경우로 갈립니다.
\[R_i = \begin{cases} R_{FE} & \text{format errors} \\ R_A + \lambda R_\eta & \text{otherwise} \end{cases}\]
critical-path latency 자체도 단순한 합이 아니라, organizer가 worker를 기다리는 DAG 구조 위에서 동적 프로그래밍으로 계산됩니다. fragment 단위로 쪼개서 \(l_i = \max(l_{i-1} + f_i, l_{j-1} + f_j^{\text{before-fork-k}} + f^{\text{query-k}})\) 형태의 재귀를 풀어가는 방식이죠.
결과
베이스 모델은 Qwen3-4B 한 종류로 통일합니다. 평가는 세 종류 태스크입니다.
Multi-Solution Countdown
countdown 게임의 확장판으로, 4개의 서로 다른 산술 표현을 같은 타겟 숫자로 도달시키는 문제입니다. 400개 테스트 예제.
Figure 5의 정확도 결과를 표로 옮기면 다음과 같습니다.
임계 |
AsyncThink |
Parallel-Thinking |
Sequential-Thinking |
|---|---|---|---|
All Correct |
89.0 |
68.6 |
70.5 |
≥ 3 Correct |
96.8 |
86.2 |
80.0 |
≥ 2 Correct |
98.8 |
92.8 |
83.8 |
≥ 1 Correct |
99.5 |
97.1 |
88.0 |
All Correct(네 해를 모두 찾기)에서 AsyncThink가 89.0%, 베이스라인은 70% 안팎입니다. 단순히 평균을 올리는 게 아니라, 해의 다양성과 정확성이 동시에 요구되는 시나리오에서 두드러진 격차 가 납니다. organizer가 worker에게 서로 다른 탐색 방향을 할당하는 패턴이 자동으로 학습된 결과로 해석됩니다.
수학 추론
AIME-24와 AMC-23 두 벤치마크. 베이스라인은 sequential과 parallel 모두 L1K(응답 길이 1K), L2K 두 설정으로 비교합니다. AsyncThink는 worker당 응답 길이가 512 토큰으로 제한됩니다.
Methods |
AIME-24 Acc (↑) |
AIME-24 Lat (↓) |
AMC-23 Acc (↑) |
AMC-23 Lat (↓) |
|---|---|---|---|---|
Sequential L1K |
24.7 |
1022.6 |
59.5 |
990.0 |
Sequential L2K |
35.3 |
2048.0 |
67.0 |
2001.1 |
Parallel L1K |
24.7 |
1024.2 |
61.9 |
1029.5 |
Parallel L2K |
38.7 |
2048.0 |
72.8 |
2031.4 |
AsyncThink |
38.7 |
1468.0 |
73.3 |
1459.5 |
핵심 비교는 Parallel L2K vs AsyncThink입니다. AIME-24에서 정확도가 동률(38.7)인데 지연이 2048에서 1468로 약 28% 감소합니다. AMC-23에서는 정확도도 72.8에서 73.3으로 살짝 올라가고 지연은 2031에서 1459로 비슷한 폭으로 줄어듭니다. 같은 정확도를 더 짧은 critical path로 달성한다는 점이 본 논문의 핵심 주장입니다.
일반화 (Sudoku)
countdown 데이터로만 학습한 모델을 4×4 Sudoku 400개에 그대로 적용합니다.
Methods |
Accuracy (↑) |
Latency (↓) |
|---|---|---|
Sequential-Thinking |
65.7 |
2055.5 |
Parallel-Thinking |
84.2 |
3694.7 |
AsyncThink |
89.4 |
2853.0 |
훈련 도메인 밖에서도 정확도가 가장 높고 지연은 parallel보다 짧습니다. 비동기 사고가 학습된 태스크에 한정된 트릭이 아니라 일반화된 사고 구조 라는 보조 근거입니다.
Ablation
Table 3은 핵심 구성요소를 하나씩 제거한 결과입니다.
Variant |
MCD Acc |
MCD η |
MCD Lat |
AMC-23 Acc |
AMC-23 η |
AMC-23 Lat |
|---|---|---|---|---|---|---|
AsyncThink (full) |
89.0 |
64.7 |
4525.4 |
73.3 |
44.8 |
1459.5 |
− \(R_\eta\) Reward |
85.3 |
61.3 |
6250.6 |
71.3 |
26.1 |
1933.3 |
− Format SFT |
64.8 |
50.0 |
3433.6 |
54.9 |
25.0 |
1007.7 |
− RL |
0.0 |
49.2 |
1987.6 |
3.6 |
33.3 |
1396.9 |
세 가지가 보입니다. (1) Concurrency reward \(R_\eta\)를 빼면 정확도는 약간만 떨어지지만 지연이 4525에서 6250으로 크게 늘어납니다. 모델이 동시성을 적극적으로 추구하지 않게됩니다. (2) Format SFT를 빼면 RL이 형식 오류 페널티에 잡혀서 정확도가 절반 가까이 떨어집니다. cold-start의 형식 학습이 그 다음 단계 RL의 부트스트랩 역할을 한다는 증거입니다. (3) RL을 통째로 빼면 정확도가 거의 0이됩니다. SFT만으로는 형식만 흉내내는 단계에서 멈춥니다.
회고
본 논문이 Conclusion에서 명시한 향후 작업이 사실상 한계 인정입니다.
스케일이 작습니다. Qwen3-4B 한 종류 베이스 모델, 그리고 agent pool capacity \(c\)가 2~4 정도의 작은 풀로만 실험했습니다. 저자들은 수백·수천 worker 규모로 가면 accuracy-latency trade-off가 어떻게 변하는지가 다음 질문이라고 인정합니다.
Worker가 동질입니다. 현재는 같은 모델이 모든 역할을 합니다. 코딩·수학·웹 검색에 특화된 이종 worker를 외부 도구와 함께 organizer가 부리는 그림이 그려지지만, 그 학습 문제는 훨씬 더 복잡 하다고 본인들이 말합니다.
Recursive organization이 아직 안됩니다. worker가 sub-organizer가 되어 다시 worker를 spawn 하는 재귀 구조가 미래 작업으로 남겨져 있습니다. Self-Manager가 명시적으로 nested subthread를 허용하지 않는다 고 한 부분과 같은 한계입니다.
Reward hacking 우려가 남습니다. thinking concurrency reward에 임계값 \(\tau\)를 굳이 둔 이유는, 모델이 정답보다 동시성 부풀리기에 더 쉽게 적응할 수 있기 때문입니다. 별도 실험에서 "Join 후 추가 Fork"를 보상하는 leverage reward를 시도했더니 학습이 불안정해지면서 준-순차적 사고에 갇히는 모드 붕괴 가 일어났다고 보고합니다. reward 설계가 trivial하지 않다는 신호입니다.
평가 태스크가 검증 가능한 정답 중심입니다. countdown, math, Sudoku 모두 정답을 룰 기반으로 검증할 수 있는 태스크입니다. open-ended generation에서 같은 패러다임이 통할지는 별도 검증이 필요합니다.
케이스 스터디
Figure 8과 Figure 9가 organizer가 실제로 어떻게 사고를 분배하는지 보여줍니다. multi-solution countdown에서는 organizer가 한 worker에게 "곱셈 기반 조합 먼저 탐색"을 시키고, 그 동안 본인은 다른 조합을 직접 검토합니다. Join으로 결과를 합친 뒤 부족한 해의 개수를 보고 새 sub-query를 즉석에서 만들어 또 다른 worker에게 위임합니다. 미리 짜놓은 워크플로가 아니라 질의에 맞춰 사고 구조가 실시간으로 그려지는 모습입니다.
수학 추론(정사면체 기하 문제)에서는 organizer가 3개 worker에게 서로 다른 풀이법(좌표법, 대안 좌표계, 단위 모서리 길이 가정)을 동시에 할당하고, 세 결과가 모두 \(\cos\theta = 1/3\)으로 일치하는 것을 본 뒤 consensus를 통한 자기 검증 으로 답을 확정합니다. parallel thinking의 다수결과 비슷하지만, organizer가 worker 결과를 받은 다음 추가로 검증 사고를 이어간다는 점이 다릅니다.
부록의 Sudoku와 MMLU-Pro(생물·정점 커버) 사례까지 모으면, AsyncThink가 학습된 적 없는 도메인에서도 Fork-Join 구조를 그대로 가져간다는 보조 증거가됩니다.
정리
세 줄로 압축하면 다음과 같습니다.
- 사고 구조 자체를 학습 대상으로 끌어올렸습니다. Fork-Join 액션을 텍스트 표면 위에 두고 GRPO를 비순차 trace에 맞게 확장해서, 모델이 sequential과 parallel을 특수 경우로 포함하는 비동기 패러다임을 직접 익힙니다.
- 같은 정확도를 더 짧은 critical path로 달성합니다. AIME-24에서 parallel L2K와 같은 38.7%를 1468 토큰으로 풉니다(parallel은 2048). 28% 지연 감소가 핵심 수치입니다.
- 학습 도메인 밖에서도 작동합니다. countdown만으로 학습한 모델이 Sudoku와 MMLU-Pro 정점 커버 문제에 zero-shot으로 Fork-Join 구조를 가져갑니다. 사고 구조가 일반화 가능한 추상이라는 신호입니다.
남는 큰 질문은 agentic organization의 다음 칸이 어디인가입니다. 본 논문 자체가 conclusion에서 (1) 풀 규모 확장, (2) 이종 worker, (3) recursive organization, (4) Human-AI organization 네 방향을 차례로 제시하는데, 같은 Microsoft Research Asia GenAI 그룹의 후속 작업이 이 중 어디로 먼저 갈지가 향후 1~2년의 관전 포인트가 될 것 같습니다. 같은 시기 Google DeepMind가 Deep Research Max로, ICT 그룹이 Self-Manager로 비슷한 방향을 동시에 가리킨 점은 이 흐름이 한 회사만의 베팅이 아님을 보여줍니다.