Video2GUI - Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining
W. Xiong, S. Gu, B. Ye, Z. Yue, L. Li, F. Song, S. Li, and H. Tian, "Video2GUI: Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining," arXiv:2605.14747, 2026.
GUI 에이전트의 가장 큰 병목은 모델이 아니라 데이터입니다. 사람이 마우스로 클릭하고 키보드로 타이핑하는 실제 작업 흐름을 시간순으로 라벨링한 데이터를 만들려면 수작업 비용이 너무 큽니다. 그래서 기존 공개 데이터셋은 보통 한 플랫폼, 수백~수만 개 트래젝토리에 머물러 있었습니다. Video2GUI는 이 문제를 "유튜브 튜토리얼 영상을 사람 대신 보게 시키자"는 방향으로 풉니다. 5억 개 영상 메타데이터에서 시작해 약 4.16M개 고품질 영상(약 30만 시간)을 걸러내고, 거기서 인터랙션 트래젝토리 12.7M개를 뽑아 WildGUI 데이터셋을 구축했습니다. ICML 2026 accept.
저자
학계와 산업계가 한 팀으로 붙은 구조입니다. 1저자 슝웨이민은 베이징대학교(PKU) 리수젠 그룹의 박사과정 학생으로, Xiaomi LLM-Core 팀 인턴 기간에 이 작업을 수행했습니다. corresponding author는 PKU 쪽의 리수젠와 Xiaomi 쪽의 톈하오 두 명입니다. Xiaomi MiMo-VL 라인에 깊이 관여한 Lei Li가 공저자로 들어와 있는 것도 이번 평가에서 MiMo-VL이 Qwen2.5-VL과 동급 베이스로 비교되는 구도와 직결됩니다. 공저자 중 Zihao Yue는 RUC Qin Jin 그룹의 비디오 사전학습 연구자로, 30만 시간 분량 영상을 다루는 파이프라인 쪽에 자연스럽게 결합됐다고 보면 됩니다.
요약하면 데이터·평가 기획은 PKU NLP 그룹, 모델 베이스와 컴퓨트는 Xiaomi LLM-Core MiMo 라인, 비디오 처리 노하우는 RUC 측이 묶인 형태입니다.
배경
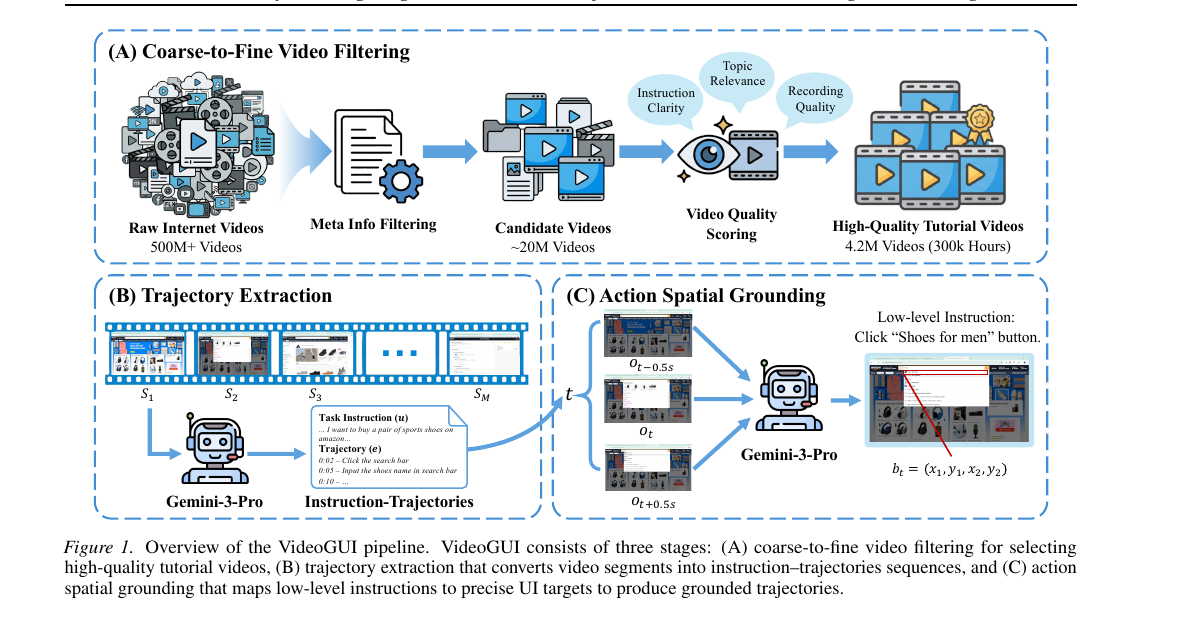
GUI 에이전트 학습 데이터는 크게 두 갈래로 나뉘어 왔습니다. 첫째는 사람이 직접 화면을 따라가며 라벨을 다는 수작업 데이터셋. MIND2WEB, AITW, AndroidControl 같은 작업이 여기에 해당하고, 품질은 좋지만 수만~수십만 단위에서 멈춥니다. 둘째는 시뮬레이터·역동역학으로 자동 추출하는 시도. TongUI나 VideoAgentTrek처럼 비디오를 다루는 선행 연구가 있었지만, 짧은 시각 단서나 키워드 검색에 의존해 단일 플랫폼·좁은 도메인에 갇혀 있었습니다.
Video2GUI는 "VLM이 비디오 한 컷을 처음부터 끝까지 보고 사람 같은 의도를 복원할 수 있다"는 가정에 베팅합니다. Gemini-3-Pro 같은 강력한 omnimodal 모델이 등장한 직후라는 타이밍을 그대로 활용한 작업입니다. 그 결과 사람이 라벨을 달지 않고도 1,500개 이상 애플리케이션·웹사이트, 데스크톱과 모바일을 모두 포괄하는 데이터를 만들 수 있다는 게 이 논문이 보여주는 핵심입니다.
표 비교 한 줄로 위치를 잡으면 다음과 같습니다.
데이터셋 |
환경 수 |
인스트럭션 |
이미지 |
평균 턴 |
|---|---|---|---|---|
AITW |
357 |
30,378 |
715K |
6.5 |
AndroidControl |
833 |
14,538 |
15K |
4.8 |
GUI-Odyssey |
201 |
7,735 |
119K |
15.4 |
GUI-Net |
280 |
1M |
1M |
4.7 |
WildGUI (본 논문) |
1,500+ |
12.7M |
124.5M |
9.7 |
WildGUI는 환경 수·인스트럭션 수·이미지 수 모두 한 자릿수 자릿수 차이로 앞서고, 처음으로 데스크톱·모바일·웹을 한 데이터셋에 묶었습니다.
어떻게 만들었나
파이프라인은 세 단계입니다. 각 단계는 비용과 품질의 절충을 명시적으로 설계해 둔 게 특징입니다.
Stage A. Coarse-to-fine 비디오 필터링. 유튜브 메타데이터 5억 건을 받아 다음 두 게이트를 통과시킵니다.
- Meta info filtering: 제목·설명·태그·자막만 보고 GUI 튜토리얼인지 이진 분류. DeepSeek-V3로 10K 샘플에 라벨을 단 뒤, Qwen2.5-7B에 분류 헤드 한 개를 붙여 cross-entropy로 학습한 가벼운 모델로 5억 건을 전수 분류합니다. 손실은
\[\mathcal{L}_{\text{CE}} = -\frac{1}{N} \sum_{i=1}^{N} \left[ y_i \log \hat{y}_i + (1 - y_i) \log (1 - \hat{y}_i) \right].\]
비디오를 한 프레임도 디코드하지 않고 텍스트만 보고 거르므로 5억 → 약 2천만으로 줄이는 데 비용이 거의 안 듭니다.
- Video quality scoring: 살아남은 2천만 건을 주제 적합성, 인스트럭션 명확성, 화면 녹화 품질 세 차원에서 1~5점으로 채점합니다. Gemini 3 Pro로 200시간 분량을 라벨링한 뒤 Qwen2.5-Omni에 회귀 헤드 3개를 붙여 MSE로 학습합니다.
\[\mathcal{L}_{\text{MSE}} = \frac{1}{N} \sum_{i=1}^{N} \sum_{j=1}^{3} (y_{ij} - \hat{y}_{ij})^2.\]
세 차원 모두 4.2 이상이라는 컷을 걸어 약 4.16M 비디오, 30만 시간을 남깁니다. Test set에서 세 차원의 회귀 성능은 \(R^2 \approx 0.85 \sim 0.90\), Spearman \(\rho \approx 0.92 \sim 0.95\)로 사람 평가에 잘 정렬됩니다.
Stage B. 트래젝토리 추출. Gemini-3-Pro를 sliding-window로 띄워 비디오 한 편을 4분 세그먼트로 잘라 순차 처리합니다. 핵심은 역동역학 한 프레임 추론이 아니라, VLM이 비디오 한 단락을 통째로 보고 사용자 의도와 단계별 행동을 복원하게 한다는 점입니다. 각 비디오는 사용자 의도 \(u^{(k)}\)와 액션 시퀀스 \(e^{(k)}\)의 쌍 묶음 \(\mathcal{D}(V) = \{(u^{(k)}, e^{(k)})\}_{k=1}^{N}\)로 나옵니다. 4분이 넘는 영상은 잘려 처리되지만, 직전 세그먼트의 결과가 다음 세그먼트의 컨텍스트로 들어가 영상 전체에 걸친 작업도 잡아낼 수 있습니다.
Stage C. 액션 공간 그라운딩. 트래젝토리 추출 단계에서 비디오는 long-context를 위해 압축돼 들어가므로 픽셀 좌표 정확도가 떨어집니다. 그래서 한 번 더 패스를 돕니다. 각 액션의 타임스탬프 \(t\)에 대해 \(\{o_{t-0.5s}, o_t, o_{t+0.5s}\}\) 세 고해상도 프레임을 가져와 Gemini-3-Pro에 "이 프레임에서 이 인스트럭션의 클릭 좌표가 어디냐"를 묻습니다.
\[b_t = g_\phi(o_{t-0.5s}, o_t, o_{t+0.5s}, \tau_t).\]
세 프레임 중 첫 유효 결과를 최종 좌표로 채택합니다. 무작위 200개 액션 수동 검증 결과 95% 이상이 정확하게 파라미터화됐습니다.
API 비용은 샘플당 약 $0.0763입니다(트래젝토리 $0.0653 + 그라운딩 $0.011). 단순 곱하면 12.7M 샘플에 약 96만 달러 정도지만, 저자들은 데이터셋 자체를 공개하므로 다운스트림 사용자는 재실행이 필요 없다는 점을 부록 G에서 명시적으로 짚어 둡니다.
무엇으로 구성돼 있나
WildGUI는 다음 분포로 구성됩니다.
- 플랫폼: Windows 65.8%, Mac 13.1%, Android 12.7%, iOS 4.5%, Linux 3.9%. 데스크톱·모바일·웹이 한 데이터셋에 처음으로 모두 들어갑니다.
- 소프트웨어 카테고리: Internet & Comm. 43.4%, Design & Media 20.4%, Dev & IT 13.0%, Productivity 10.7%, System Tools 9.8%, Gaming 2.7%.
- 웹사이트 카테고리: Dev & AI Tools 34.8%, Business & Cloud 26.5%, Edu & Knowledge 17.6%, Social & Media 14.0%, Finance & Comm. 7.1%.
- 액션 분포(데스크톱): click 56.1%, write 12.5%, finish 10.6%, dragTo 7.1%, press 4.1%.
- 액션 분포(모바일): click 67.0%, finish 9.7%, scroll 6.6%, input 5.7%, drag 4.8%.
- 트래젝토리 길이: 평균 9.7스텝, 분포는 long-tail로 60스텝 이상도 존재.
액션 공간은 데스크톱 13종, 모바일 11종으로 정의됩니다. 데스크톱은 click, doubleClick, tripleClick, rightClick, middleClick, press, input, hotkey, scroll, drag, moveTo, wait, finished. 모바일은 click, longpress, scroll, pinch, input, drag, press, open, multi_touch, finished 등입니다. 이 액션 공간은 기존 OSWorld·CAGUI 평가 환경과 호환되도록 잡혀 있습니다.
결과
저자들은 Qwen2.5-VL-7B와 MiMo-VL-7B 두 베이스 모델에 두 단계 학습을 적용합니다. Stage 1은 WildGUI 사전학습, Stage 2는 오픈소스 데이터 포스트트레이닝입니다. Stage 1 사전학습 목적은 그라운딩·액션·트래젝토리 세 손실의 합
\[\mathcal{L}_{\text{pretrain}} = \mathcal{L}_{\text{ground}} + \mathcal{L}_{\text{action}} + \mathcal{L}_{\text{traj}}\]
으로 1에폭, 약 2000억 토큰 학습합니다. Stage 2는 큐레이션된 오픈소스 데이터에서 3에폭, 약 150억 토큰입니다. 학습 환경은 160 CPU 코어·512GB 메모리·256 NVIDIA GPU 클러스터.
GUI 그라운딩 (ScreenSpot-Pro, OSWorld-G)
모델 |
ScreenSpot-Pro Avg |
OSWorld-G Avg |
|---|---|---|
Gemini-2.5-Pro (closed) |
11.4 |
45.2 |
Seed1.5-VL (closed) |
60.9 |
62.9 |
Qwen3-VL-32B (open) |
54.9 |
60.6 |
UI-TARS-72B (open) |
38.1 |
57.1 |
Qwen2.5-VL-7B (base) |
26.8 |
27.3 |
*+ WildGUI* |
41.9 (↑15.1) |
53.7 (↑26.4) |
MiMo-VL-7B (base) |
41.2 |
54.7 |
*+ WildGUI* |
56.9 (↑15.7) |
67.6 (↑12.9) |
MiMo-VL-7B + WildGUI는 OSWorld-G 평균 67.6으로 Qwen3-VL-32B(60.6), Seed1.5-VL(62.9)을 넘어섭니다. 7B 체급으로 32B·closed-source까지 따라잡는 결과입니다. ScreenSpot-Pro에서도 같은 모델이 56.9로 Qwen3-VL-32B(54.9)를 누르고 Seed1.5-VL(60.9)에 근접합니다. Qwen2.5-VL 쪽도 OSWorld-G가 27.3 → 53.7로 거의 두 배가 됩니다.
오프라인 에이전트 (AndroidControl, CAGUI)
모델 |
AndroidControl-Low SR |
AndroidControl-High SR |
CAGUI SR |
|---|---|---|---|
GPT-4o (closed) |
19.4 |
20.8 |
3.7 |
UI-TARS-7B |
90.8 |
72.5 |
70.3 |
Qwen2.5-VL-7B (base) |
85.0 |
62.9 |
55.2 |
*+ WildGUI* |
90.3 (↑5.3) |
64.5 (↑1.6) |
65.4 (↑10.2) |
MiMo-VL-7B (base) |
87.9 |
65.6 |
63.4 |
*+ WildGUI* |
91.8 (↑3.9) |
71.4 (↑5.8) |
71.0 (↑7.6) |
MiMo-VL-7B + WildGUI는 AndroidControl-High SR 71.4, CAGUI SR 71.0으로 UI-TARS-7B를 넘습니다. 특히 중국어 인터페이스 CAGUI 벤치마크에서 +7.6~10.2점이 나오는 점이 흥미롭습니다. WildGUI가 유튜브 다국어 튜토리얼을 그대로 받아 만든 데이터셋이라는 점이 크로스링구얼 일반화로 이어진다는 증거입니다.
온라인 에이전트 (OSWorld, AndroidWorld)
오프라인 SFT 데이터로만 만든 모델인데도 상호작용 환경에서 일관된 개선이 나옵니다. MiMo-VL-7B 기준:
- AndroidWorld SR: 16.4 → 23.3 (Stage 2 Only) → 31.9 (Stage 1+2). 베이스 모델의 두 배 가까이.
- OSWorld SR: 8.3 → 10.4 (Stage 2 Only) → 12.3 (Stage 1+2).
오프라인 비디오에서 만든 트래젝토리가 온라인 RL 단계의 출발점을 의미 있게 끌어올린다는 게 핵심 메시지입니다.
스케일링: 데이터 늘리면 계속 오름
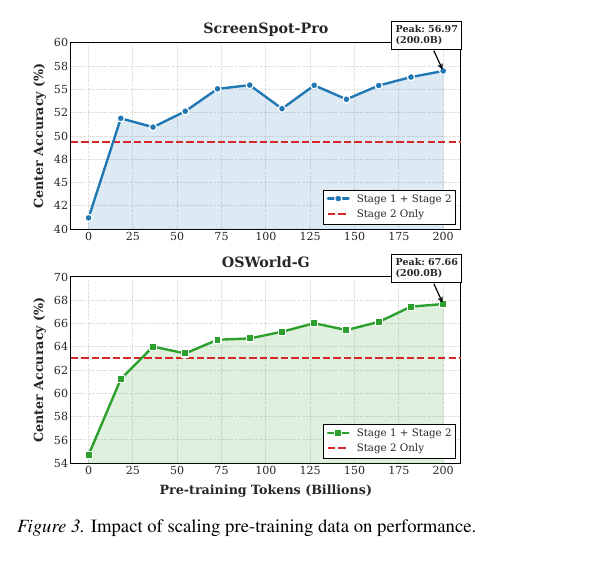
사전학습 토큰을 0에서 2000억까지 늘리며 두 벤치마크를 측정한 결과, 두 그래프 모두 saturation 없이 계속 상승합니다. ScreenSpot-Pro는 41% → 56.9%, OSWorld-G는 55% → 67.66%. 대략 500억 토큰 부근에서 Stage 2 Only 베이스라인을 넘어선 뒤 위로 더 가는 모양입니다. 12M 트래젝토리도 아직 다 짜내지 못한 부분이 남아 있다는 신호입니다.
어블레이션: 세 손실과 두 스테이지
Mimo-VL-7B 기준 어블레이션은 명확합니다. \(\mathcal{L}_{\text{traj}}\)를 빼면 정적 벤치(ScreenSpot-Pro, CAGUI)는 유지되지만 AndroidWorld가 \(31.9 \to 24.1\)로 무너집니다. 장기 계획에 트래젝토리 손실이 결정적이라는 뜻입니다. \(\mathcal{L}_{\text{ground}}\)를 빼면 ScreenSpot-Pro가 \(56.9 \to 49.8\)로 떨어져 좌표 그라운딩 학습이 별도로 필요함을 보여줍니다. Stage 2 없이 Stage 1만 쓰면 AndroidWorld가 6.0까지 폭락합니다. WildGUI는 기반 지식은 깔아주지만 명령 추종은 깨끗한 데이터로 한 번 더 정렬해야 한다는 게 드러납니다.
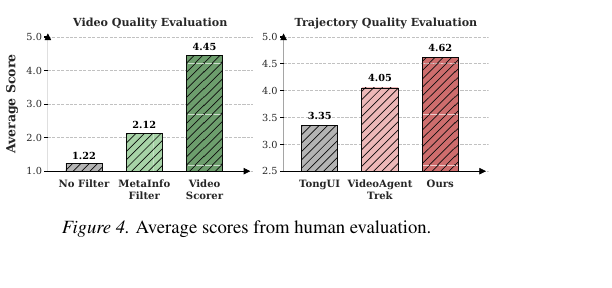
사람 평가도 같은 결론을 지지합니다. 영상 품질 점수는 필터 없음 1.22 → 메타 필터 2.12 → 비디오 스코어러 4.45로 단조 상승했고, 트래젝토리 품질은 TongUI 3.35 / VideoAgentTrek 4.05 / WildGUI 4.62로 기존 두 베이스라인을 넘어섭니다. 평가자 5명의 Krippendorff \(\alpha = 0.84\).
회고
저자들이 본문과 어블레이션에서 솔직하게 인정하는 한계가 셋 있습니다.
첫째, Stage 2 없이 Stage 1만으로는 못 씁니다. AndroidWorld 6.0이라는 숫자는 12.7M 트래젝토리만 부어도 instruction following이 약하다는 뜻입니다. WildGUI는 출발점일 뿐 깨끗한 인간 라벨 데이터를 대체하지는 않습니다.
둘째, 액션 분포의 편향. click이 데스크톱 56.1%·모바일 67.0%로 압도적입니다. drag·pinch·multi-touch 같은 복잡 제스처는 1~5%대에 머뭅니다. 유튜브 튜토리얼이 다 마우스 클릭 중심의 스크린캐스트라는 매체적 편향이 그대로 데이터셋에 흘러들어옵니다.
셋째, API 비용. Gemini-3-Pro에 12.7M 샘플을 돌리는 비용이 만만치 않습니다(샘플당 약 $0.0763, 총 ~$97만). 저자들은 이를 one-time cost로 정당화하고 데이터셋과 파이프라인을 모두 공개하지만, 같은 방법을 다른 도메인(예: 산업용 SW, 게이밍)으로 재현하려면 진입장벽이 분명히 높습니다.
부록 G에서 오픈소스 백본(Qwen3.5-397B-A17B)으로 대체해 봤더니 15~20% 정도 품질이 낮았다는 비교까지 적어둔 점이 인상적입니다. 저자들이 Gemini 의존성을 자기 한계로 명확히 인지하고 있다는 신호입니다.
정리
- 사람 라벨 없이 유튜브 튜토리얼 5억 건에서 비디오 4.16M, 다시 트래젝토리 12.7M으로 가는 coarse-to-fine 파이프라인이 실제로 돌아갑니다. 메타데이터 텍스트 분류로 비용을 절감하고, 4분 sliding-window VLM 어노테이션으로 long-horizon을 잡으며, 별도 패스로 좌표 그라운딩을 보강하는 3단 설계가 핵심입니다.
- 7B 모델에 WildGUI를 사전학습하면 ScreenSpot-Pro·OSWorld-G에서 15~26점이 오르고, 일부 지표에서 32B·closed-source 모델까지 따라잡습니다. 오프라인 데이터인데 온라인 OSWorld·AndroidWorld 성공률까지 같이 오릅니다.
- 2000억 토큰까지 saturation 없이 오르므로 데이터가 아니라 학습 토큰이 다음 병목입니다. 다만 Stage 2 정렬 데이터, 액션 분포의 click 편향, Gemini API 의존성이 남은 숙제로 분명히 드러납니다.