Escaping the Self-Confirmation Trap - An Execute-Distill-Verify Paradigm for Agentic Experience Learning
S. Zhu, Y. Qi, Y. Wang, J. Li, C. Song, Y. Shi, Y. Miao, H. Gao, and K. Zhang, "Escaping the Self-Confirmation Trap: An Execute-Distill-Verify Paradigm for Agentic Experience Learning," arXiv:2606.24428, 2026.
저자
이 논문은 Shiding Zhu(Zhejiang University), Yudi Qi(Tsinghua University Shenzhen), Yajie Wang(Independent)이 공동 1저자이며, Kai Zhang(Tsinghua University Shenzhen)이 교신저자로 이끈 연구입니다. Zhejiang University, Tsinghua Shenzhen, Northwestern Polytechnical University, USTC, Shanghai Jiaotong University 등 5개 기관이 합류한 것은 경험 학습의 신뢰성 문제가 단일 연구실의 관심사를 넘어섰음을 보여줍니다. 멀티 에이전트 시스템과 경험 기반 자기진화를 함께 다루는 연구 흐름이 배경에 있습니다.
배경
LLM 에이전트가 태스크를 반복하면서 스스로 경험을 쌓고 미래에 재사용하는 패러다임, 즉 experience learning이 최근 활발히 연구됩니다. ReasoningBank 같은 시스템은 성공·실패 궤적을 메모리로 증류해 장기 추론을 개선합니다. 그런데 여기에는 설계상 취약점이 있습니다. 같은 에이전트가 태스크를 실행하고 그 결과를 스스로 평가해서 메모리에 적습니다.
오픈 월드 환경에서는 "정답 레이블"이 없습니다. 에이전트는 궤적이 성공인지 실패인지 판단할 외부 기준이 없으므로 자신의 추론 결과를 기준으로 삼습니다. 이 구조에서 잘못됐지만 내적으로 일관성 있는 궤적이 성공 경험으로 오인될 수 있습니다. 논문은 이를 **Self-Confirmation Trap(자기 확증 함정)**으로 명명합니다.
항공편 수정 태스크의 구체적 예가 명확합니다. 에이전트가 여행 상품권으로 기존 예약을 수정하려 반복 시도합니다. 상품권이 예약 변경에 쓰일 수 없다는 환경 제약이 있지만, 에이전트의 추론 흐름은 내부적으로 일관됩니다. 자기 검증 루프에서 이 궤적은 "성공 경험"으로 메모리에 기록되고, 이후 비슷한 태스크에서 같은 오류를 반복하게 됩니다.
어떻게 만들었나
문제 형식화
태스크 집합 \(\mathcal{T}\)에서 태스크 \(q \in \mathcal{T}\)에 대해 정책 \(\pi_\theta\)를 따르는 에이전트가 궤적 \(\tau = \{s_0, a_0, o_1, a_1, \ldots, o_T\}\)를 생성합니다. 궤적의 객관적 정답 여부를 \(c(\tau) \in \{0, 1\}\), 에이전트의 자기평가를 \(v_{\pi_\theta}(\tau) \in \{0, 1\}\)로 표기합니다.
단일 에이전트 루프에서는 실행과 평가가 같은 정책 \(\pi_\theta\)에 묶입니다. 그 결과:
\[P\!\left(v_{\pi_\theta}(\tau) = 1 \mid c(\tau) = 0\right)\]
이 값이 비정상적으로 높아집니다. 틀린 궤적이 "성공"으로 승인될 확률이 높다는 뜻입니다.
Execute-Distill-Verify (EDV)
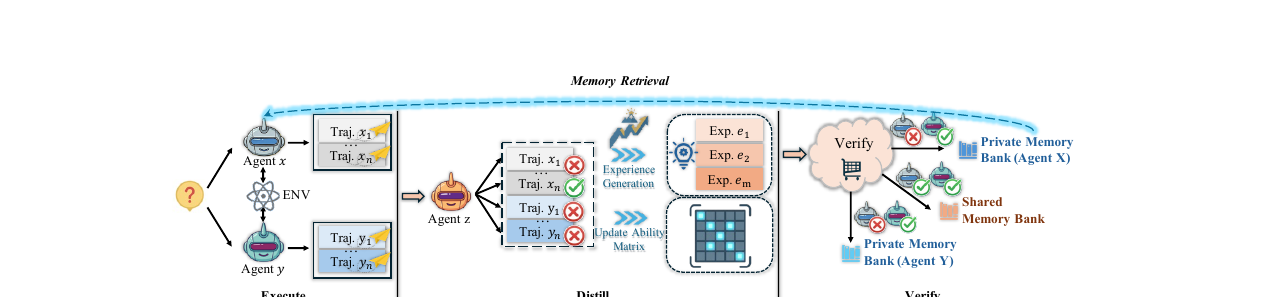
EDV는 이 함정을 세 단계 분업으로 깨뜨립니다.
Execute: 이종 에이전트 풀 \(\mathcal{A} = \{A_1, A_2, \ldots, A_K\}\)에서 무작위로 실행 그룹 \(\mathcal{A}_\text{exec} \subseteq \mathcal{A}\)를 구성합니다. 각 에이전트가 독립적으로 환경과 상호작용해 다양한 후보 궤적을 생성합니다. 단순히 시도 횟수를 늘리는 것이 아니라, 서로 다른 모델(Mimo-V2-Flash, GLM-4.7-FP8, MiniMax-M2.1)이 각기 다른 성공·실패 패턴을 노출합니다.
Distill: 실행에 참여하지 않은 제3자 증류 에이전트 \(A_\text{distill}\)이 여러 궤적을 교차 비교해 후보 경험 집합 \(\mathcal{E}_\text{cand} = \{e_1, e_2, \ldots, e_m\}\)을 만듭니다. 실행자 중심의 자기 요약이 아니라 궤적 간 차이점에서 재사용 가능한 교훈을 추출합니다. 이 단계에서 Ability Matrix도 업데이트됩니다 — 어떤 에이전트가 어떤 유형의 태스크를 잘 처리하는지 기록합니다.
Verify: 원래 실행 에이전트들이 후보 경험을 재검증합니다. EDV는 strict default-reject 정책을 따릅니다. 만장일치로 승인된 경험만 공유 메모리에 기록되고, 부분 승인은 해당 에이전트의 개인 메모리에, 나머지는 폐기됩니다. 이 단계가 Self-Confirmation Trap을 차단하는 핵심 게이트입니다.
추론 단계 활용
새 태스크 \(q_\text{test}\)가 들어오면 시스템은 Ability Matrix를 통해 최적 에이전트를 선택하고, 계층 검색으로 관련 경험을 불러옵니다. 공유 메모리를 먼저 검색하고 결과가 부족하면 선택된 에이전트의 개인 메모리를 추가 검색합니다.
결과
τ²-bench (실세계 고객 서비스)
방법 |
백본 |
AIRLINE |
RETAIL |
TELECOM |
Avg. |
|---|---|---|---|---|---|
No Memory |
MiniMax-M2.1 |
61.5 |
82.2 |
85.5 |
76.4 |
ReasoningBank |
GLM-4.7-FP8 |
66.0 |
82.5 |
97.2 |
81.9 |
Router |
(앙상블) |
68.0 |
85.2 |
97.2 |
83.5 |
EDV (Ours) |
*(앙상블)* |
72.0 |
88.6 |
99.1 |
86.6 |
메모리 없는 단일 모델 대비 EDV는 Avg. 기준 7~10포인트 개선을 보입니다. Router(83.5)나 Judge(81.5)처럼 추론 시점 앙상블 방식보다도 3포인트 이상 앞서는데, 이는 메모리 품질 자체가 더 중요하다는 주장을 뒷받침합니다.
Mind2Web (웹 에이전트 일반화)
평가 설정 |
지표 |
EDV |
Best Baseline |
|---|---|---|---|
Cross-Task |
EA |
48.62 |
46.77 (RB) |
Cross-Task |
SSR |
43.17 |
42.01 (RB) |
Cross-Website |
EA |
44.79 |
41.66 (RB) |
Cross-Domain |
EA |
43.39 |
42.64 (Judge) |
상위 bound(EA 74.26, Cross-Task 기준)에 아직 크게 못 미치지만, 모든 일반화 설정에서 EDV가 기존 최강 기준보다 우세합니다.
MMTB에서도 Overall 58.10으로 Router(55.96)를 앞섭니다.
메모리 품질 감사
5점 척도 인간 평가(RETAIL 도메인):
차원 |
ReasoningBank |
EDV |
|---|---|---|
정확성(Groundedness) |
3.72 |
4.41 |
실행가능성(Actionability) |
3.58 |
4.32 |
구체성(Specificity) |
3.64 |
4.27 |
노이즈/환각 |
1.21 |
0.63 |
재사용 시 위험성 |
1.08 |
0.51 |
노이즈와 위험성이 절반 이하로 줄어든 것이 핵심입니다.
Self-Confirmation Trap 실험
RB 베이스라인 메모리에 오류 경험(잘못된 결제 규칙)을 10% 주입하면 RETAIL Pass@1이 82.5에서 77.2로 급락합니다. 나쁜 경험 하나가 반복 재사용을 통해 시스템 전체를 오염시킬 수 있다는 것을 실험으로 보여줍니다.
절제 실험 (RETAIL, τ²-bench)
설정 |
Execute |
Distill |
Verify |
Pass@1 |
|---|---|---|---|---|
단일 에이전트 (SA) |
1 |
자기 |
없음 |
83.3 |
SA + 자기 검증 |
1 |
자기 |
자기 |
83.2 |
SA + 외부 검증 |
1 |
자기 |
외부 |
84.5 |
MA + 자기 증류 |
2 |
실행자 |
실행자 |
85.9 |
MA + 제3자 증류 |
2 |
외부 |
증류자 |
87.1 |
EDV (전체) |
2 |
외부 |
실행자 |
88.6 |
단일 에이전트에 자기 검증을 더해도 오히려 0.1포인트 떨어집니다. 같은 모델이 자신의 오류를 검증하면 오류가 보강되기 때문입니다. 효과를 내려면 실행 다양성(멀티 에이전트)과 제3자 증류가 함께 있어야 합니다.
회고
논문이 인정하지 않는 비용 문제가 있습니다. 2개 에이전트가 같은 태스크를 병렬 실행하므로 경험 구성 단계의 계산 비용이 단일 에이전트 대비 2배 이상입니다. 논문은 "추론 토큰을 24.5% 절감"했다고 하는데, 이는 추론 단계(inference-time) 비용이고 경험 구성 단계(offline) 비용을 포함하지 않습니다.
인간 품질 감사가 RETAIL 도메인에만 적용됐습니다. 다른 도메인(AIRLINE, TELECOM, Mind2Web)에서의 메모리 품질은 정량 성능 지표로만 간접 확인됩니다.
모델 풀이 3개로 고정돼 있습니다. 더 많은 모델을 추가하면 비용이 선형적으로 늘어나는데, 모델 수 확장의 한계에 대한 분석이 없습니다.
정리
- 단일 에이전트 자기 평가 루프는 구조적으로 Self-Confirmation Trap에 취약합니다. 자기 검증을 추가해도 오히려 오류가 보강됩니다.
- EDV는 실행·증류·검증 역할을 분리해 이 함정을 끊습니다. 제3자 증류와 만장일치 검증이 핵심 메커니즘입니다.
- 경험 구성 비용이 높지만 추론 단계 효율이 개선되는 트레이드오프가 있습니다. 기억의 양보다 질이 중요하다는 주장을 실험으로 뒷받침합니다.