Agent Memory - Characterization and System Implications of Stateful Long-Horizon Workloads
Y. Omri, Z. Gan, Z. Broveak, R. Geens, et al., "Agent Memory: Characterization and System Implications of Stateful Long-Horizon Workloads," arXiv:2606.06448, 2026.
요즘 LLM 에이전트는 한 번의 대화로 끝나지 않습니다. 몇 주에 걸쳐 사용자 취향을 따라가는 비서, 편집 세션을 넘나들며 프로젝트 맥락을 유지하는 코드 에이전트, 긴 조사 과정을 종합하는 리서치 에이전트처럼 시간축이 긴 작업을 합니다. 이러려면 에이전트가 자기 기억을 세션을 가로질러 저장하고, 필요할 때 꺼내 쓰고, 새 정보가 오면 갱신해야 합니다.
지난 1년 사이 이런 에이전트 메모리 시스템이 쏟아졌습니다. 그런데 평가는 거의 다 "정답을 잘 맞히나"에만 쏠려 있었습니다. 이 논문은 질문을 바꿉니다. 그 기억을 만들고 유지하는 데 연산과 에너지가 얼마나 드는가. 답은 충격적입니다. 정확도가 비슷한 시스템끼리도 정답 하나당 드는 에너지가 수십 배 차이 나고, 그 비용의 대부분이 사용자가 질문하는 순간이 아니라 그 전에 기억을 쌓는 단계에 숨어 있습니다.
저자
이 논문은 정확도 논문이 아니라 시스템 논문입니다. 저자 구성이 그걸 그대로 보여줍니다.
공동 1저자는 야스민 오므리와 Ziyu Gan이고, 시니어 저자는 티에리 탐베입니다. 티에리 탐베는 스탠퍼드에서 알고리즘부터 실리콘까지 통째로 설계하는 효율적 AI 하드웨어를 연구합니다. 모델을 어떻게 싸게 돌릴지를 회로 수준까지 내려가 보는 사람이 에이전트 메모리를 들여다봤다는 것 자체가, 이 연구가 "정확도"가 아니라 "비용"을 보려 했다는 신호입니다.
공저자 명단도 같은 방향을 가리킵니다. 임베디드 머신러닝과 저전력 하드웨어 가속기의 권위자 마리안 페르헐스트(KU Leuven, imec)가 들어가 있어 GPU 에너지·대역폭 측정에 무게가 실렸고, 정보이론과 데이터 압축의 대가 차치 바이스만는 상호작용 기록을 압축해 기억으로 만드는 문제의 본질을 짚습니다. 계산 사회과학을 개척한 알렉스 펜틀런드는 에이전트가 사용자별로 장기 기억을 쌓아 사람을 대리하는 흐름에 오래 관심을 둬왔습니다. 정확도 벤치마크를 만드는 NLP 그룹이 아니라, 하드웨어와 시스템과 정보이론을 하는 사람들이 모였다는 점이 이 논문의 시각을 결정합니다.
배경
에이전트 메모리는 RAG를 한 단계 밀어붙인 것입니다. 초기 LLM은 지식을 모델 가중치 안에 파라미터로만 담았습니다. RAG는 지식을 가중치에서 떼어내, 외부 문서 집합에 붙여 추론 시점에 골라 쓰게 했습니다. 다만 그 외부 집합은 미리 준비해 색인해 둔 고정된 문서 더미였습니다.
긴 시간축 에이전트는 여기서 더 나갑니다. 기억의 원천이 고정된 문서가 아니라, 에이전트 자신의 상호작용 스트림입니다. 사용자별로 쌓이고, 세션을 넘나들며 덧붙고, 요약되고, 통합되고, 다시 쓰이기도 합니다. 기억이 수동적인 검색 대상에서, 쓰기 경로(write path)와 검색 경로(read path)와 유지보수 정책을 가진 능동적인 시스템 구성 요소로 바뀐 것입니다.
가장 단순한 대안은 그냥 전체 대화 기록을 컨텍스트 창에 다 넣는 것입니다. 컨텍스트가 수만에서 100만 토큰까지 커졌으니 될 법도 합니다. 그런데 세 가지 벽에 부딪힙니다. 첫째, 끝없이 이어지는 다중 세션은 어떤 고정 예산도 넘어섭니다. 둘째, 프리필(prefill) 비용이 기록 길이에 따라 제곱으로 늘어납니다(\(O(n^2)\)). 프리픽스 캐싱은 한 세션 안에서만 듣고, 세션을 넘으면 캐시가 밀려나 KV 캐시 압력만 키웁니다. 셋째, 긴 입력에서는 추론·회상 정확도가 떨어집니다. 컨텍스트 중간에 있는 사실이 체계적으로 무시되는 U자형 곡선이 나타나고, 복잡한 추론에 실제로 쓸 수 있는 길이는 광고된 창의 일부에 불과합니다.
외부 메모리는 용량을 컨텍스트 길이에서 떼어내 이 문제를 풉니다. 상태를 밖에 저장하고 질의에 관련된 일부만 꺼내 오니, 질문당 프리필 비용이 묶이고 긴 시간축 실행이 가능해집니다. 문제는 그 외부 메모리를 만드는 방식이 시스템마다 극단적으로 다르고, 그 차이가 비용을 비대칭적으로 재분배한다는 데 있습니다. 기록을 원자적 사실로 압축하는 시스템은 질의 시점 프롬프트는 확 줄이지만 구축 시점 프리필을 수십 배로 늘립니다. 그래프 기반 메모리는 관계 검색을 좋게 하지만 임베딩 트래픽과 저장 공간을 곱절로 키웁니다. 이런 비용은 정확도 지표에 전혀 잡히지 않으면서 배포 규모에서 지배적이 됩니다. 논문은 세 가지 질문을 던집니다. 어떤 설계 패러다임이 어떤 트레이드오프를 갖는가, 이 워크로드가 인프라에 어떤 요구를 던지는가, 그리고 알고리즘 선택이 활용률·대역폭·지연·확장성 같은 관측 가능한 시스템 특성을 어떻게 바꾸는가.
어떻게 측정했나
먼저 에이전트 메모리 실행을 일곱 단계로 분해합니다. 수집(ingestion), 메모리 구축(construction), 저장(storage), 검색(retrieval), 프롬프트 조립(prompt assembly), 생성(generation), 유지보수(maintenance)입니다. 핵심은 구축 단계입니다. 원시 상호작용 기록을 영속적인 기억 레코드로 바꾸는 쓰기 경로 변환인데, 네 가지 형태를 띱니다. 없음(기록을 프롬프트에 그대로), 결정론적(LLM 없이 청킹·색인), LLM 매개(정해진 시점에 사실·요약·구조 레코드 추출), 에이전틱(LLM이 직접 언제 쓰고 무엇을 호출할지 제어).
이 분해를 바탕으로 메모리 시스템을 구축·저장·검색·가변성(mutability) 네 축으로 분류해 네 패러다임으로 묶고, 각 패러다임을 대표하는 열 개 시스템을 골랐습니다.
패러다임 |
대표 시스템 |
구축 방식 |
가변성 |
|---|---|---|---|
I. 롱컨텍스트 |
long_context |
없음 (전체 기록을 프롬프트에) |
- |
II. 평면 RAG |
BM25, embedRAG |
결정론적 색인 (LLM 없음) |
append |
III.a 구조 보강 RAG (추가형) |
GraphRAG, HippoRAG v2 |
LLM이 엔티티·관계 추출 |
append |
III.b 구조 보강 RAG (통합형) |
Mem0, SimpleMem |
LLM이 사실 추출 + ADD/UPDATE/DELETE |
consolidate |
IV. 에이전틱 제어 흐름 |
A-Mem, Letta, MIRIX |
LLM이 쓰기·검색을 도구로 제어 |
mutate |
패러다임이 올라갈수록 LLM이 쓰기 경로에 더 깊이 개입합니다. II는 LLM을 아예 안 쓰고, III은 정해진 시점에 고정된 추출기로 부르며, IV는 LLM이 메모리 연산을 도구로 들고 가변 깊이의 제어 흐름으로 돌립니다. 예컨대 Mem0는 대화 턴을 원자적 사실로 바꿔 기존 기억과 비교해 추가·갱신·삭제를 결정하고, Letta는 MemGPT 추상화를 따라 핵심 메모리와 아카이브 메모리를 분리해 읽기·쓰기를 LLM 호출 가능한 도구로 노출하며, MIRIX는 들어온 정보를 에피소드·의미·절차·자원 메모리로 라우팅합니다.
측정 도구로는 단계별 프로파일링 하니스를 만들었습니다(공개 예정). 모든 챗·임베딩 요청의 토큰·호출 구조·지연을 기록하는 API 텔레메트리와, NVML·DCGM 카운터로 전력·GPU 활용률·VRAM·HBM 대역폭을 샘플링하는 하드웨어 텔레메트리를 같은 시간축에 정렬해, 비용을 구축·검색·생성 세 단계에 귀속시킵니다.
워크로드는 두 가지입니다. 주 벤치마크는 MemoryAgentBench로, 긴 컨텍스트 작업을 4096토큰 청크 단위의 다중 턴 스트림으로 바꿔 정확한 검색·테스트타임 학습·장거리 이해·선택적 망각 네 역량을 봅니다. 시스템 특성화는 그중 가장 널리 쓰이는 장기 대화 설정인 LongMemEval_S에 집중하는데, 표본 다섯 개에 각각 약 36만 토큰의 기록과 60개 질의(총 300개)가 붙어 있어 구축과 질의를 깔끔하게 분리해 볼 수 있습니다. 또 하나는 MemoryArena로, 뒤 세션이 앞 세션 결과에 의존하는 다중 세션 구조라 신선도-지연 트레이드오프를 드러냅니다.
하드웨어는 두 구성입니다. 원격 구축은 OpenAI 모델(GPT-4o-mini 또는 GPT-4.1-mini, text-embedding-3-small)을 쓰고, 로컬 구축은 H100 80GB 한 장에 vLLM으로 Qwen3 사다리(32B·14B·8B·1.7B)와 Qwen3-Embedding-0.6B를 올립니다. 32B·14B는 FP8 가중치 양자화로 한 장에 욱여넣었습니다.
결과
왜 외부 메모리인가
먼저 외부 메모리가 전체 기록 베이스라인보다 나은지를 봅니다. LongMemEval_S에서 질문당 서빙 지연(검색+생성, 구축 제외)을 정확도와 함께 찍어보면, 대부분의 메모리 시스템이 롱컨텍스트의 일부 시간으로 질의를 처리하면서 정확도는 맞먹거나 앞섭니다. Mem0는 질문당 0.1초 미만인데, 롱컨텍스트는 약 38초입니다(GPT-4.1-mini, 300개 질의 평균). 같은 하드웨어에서도 시스템 간 질문당 지연이 두 자릿수 배(약 \(10^2\)배) 벌어집니다.
비용 대부분은 구축 단계에 숨어 있다
여기서부터가 이 논문의 핵심입니다. 위의 질문당 지연 이점은 "기억이 이미 다 만들어진 다음"의 이야기입니다. 그 기억을 만드는 비용을 합치면 그림이 완전히 달라집니다.
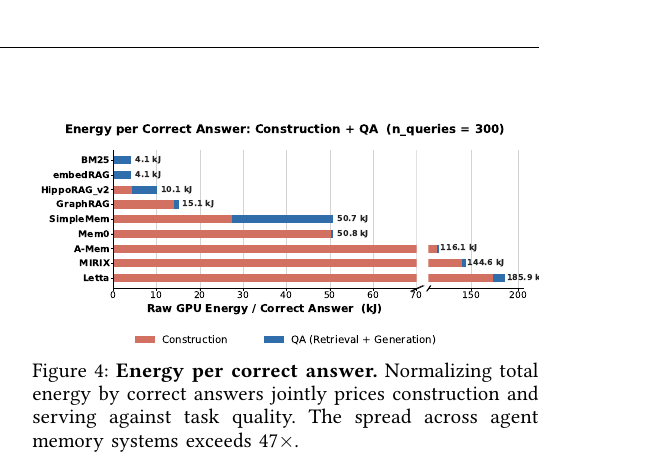
LongMemEval_S 다섯 표본(기록 180만 토큰, 질의 300개)을 Qwen3-32B 로컬 서빙으로 돌려 정답 하나당 GPU 에너지를 환산한 결과입니다.
시스템 |
정확도 (%) |
총 에너지 (kJ) |
정답당 에너지 (kJ) |
|---|---|---|---|
BM25 |
47.0 |
582 |
4.1 |
embedRAG |
39.8 |
495 |
4.1 |
HippoRAG v2 |
44.3 |
1,339 |
10.1 |
GraphRAG |
46.0 |
2,082 |
15.1 |
SimpleMem |
36.0 |
5,481 |
50.7 |
Mem0 |
32.0 |
4,878 |
50.8 |
A-Mem |
42.7 |
14,864 |
116.1 |
MIRIX |
20.0 |
8,678 |
144.6 |
Letta |
27.7 |
15,429 |
185.9 |
읽는 법은 이렇습니다. 결정론적 색인만 하는 평면 RAG(BM25·embedRAG)는 1분 안에 구축을 끝내고 정답당 4.1 kJ로 바닥을 찍습니다. 반면 LLM을 반복 호출해 사실·요약·갱신을 만드는 III·IV 패러다임은 구축에 몇 시간을 씁니다. SimpleMem이 약 3.9시간, Letta는 약 13시간입니다. 그 결과 정답 하나를 만드는 데 드는 에너지가 BM25의 4.1 kJ에서 Letta의 185.9 kJ까지, 시스템 간 약 45배 벌어집니다. 막대그림에서 보듯 이 에너지의 대부분(빨간 부분)이 사용자가 질문하는 순간이 아니라 그 전 구축 단계에서 나갑니다. LLM 매개 시스템들은 300개 질의를 다 합친 질의 단계 에너지보다 구축 에너지가 더 큽니다.
여기서 숫자 하나를 짚고 갑니다. 논문 본문과 그림 4 캡션은 이 격차를 "47배 이상"이라고 적습니다. 다만 표(Table 3)와 그림 4의 실제 수치(4.1 kJ 대 185.9 kJ)로 직접 계산하면 약 45배입니다. 또 본문 한 곳은 MIRIX를 197 kJ로 적는데 표·그림은 144.6 kJ로 일치합니다. preprint라 본문 서술과 표가 미세하게 어긋나는데, 정본은 표와 그림 4 쪽입니다. 결론은 바뀌지 않습니다. 정확도가 비슷한 시스템끼리도 생애주기 에너지가 한 자릿수 배 이상 차이 납니다.
구축은 길게 읽고 짧게 쓰는 워크로드
그 구축 비용은 특정한 계산 모양을 갖습니다. 임베딩 모델은 forward pass 전체가 프리필이고 디코드가 없습니다. LLM 구축 경로도 청크를 길게 읽고 사실 목록·JSON 트리플·추가/갱신/삭제 결정 같은 짧은 구조 출력을 내놓습니다. 그래서 구축 토큰 중 디코드가 차지하는 비율의 중앙값이 4.6%에 불과합니다(Letta 0.9%에서 SimpleMem 28.5%). 구축은 길게 읽고 짧게 쓰는, 프리필·임베딩 지배 워크로드입니다.
이게 QA 서빙과 구조적으로 충돌합니다. QA는 첫 토큰까지의 시간에 민감한 지연 중심 작업인데, 구축은 사용자 지연 압박이 없는 처리량 중심 작업입니다. 둘을 같은 LLM 엔드포인트로 보내면, 큰 구축 프리필 작업이 KV 캐시 여유를 점유하고 배치 스케줄러를 막은 바로 그 순간에 지연 민감한 질의가 도착합니다. 그래서 논문은 구축을 입학 제어(admission control)가 붙은 백그라운드 처리량 작업으로 다루라고 권합니다. 임베딩 트래픽도 패러다임별로 갈립니다. III.a(GraphRAG)는 호출당 약 2,300개 시퀀스를 큰 배치로 보내는 반면, Mem0는 사실 하나를 임베딩해야 유사도 검색으로 추가·갱신·삭제를 정하므로 호출당 1개라는 정반대 모양입니다.
구축용 LLM을 줄일 수 있나, 능력 바닥이 있다
구축 에너지가 크니, 구축에는 더 싼 작은 LLM을 쓰는 게 자연스러운 절감 수단입니다. 대부분 시스템에서 이 수단이 통합니다. 하드 출력 계약이 없는 Mem0·SimpleMem·A-Mem은 구축 LLM을 줄여도 정확도가 매끄럽게 떨어집니다. GraphRAG는 특히 견고해서 Qwen3-1.7B부터 GPT-4o-mini까지 47~48%를 유지합니다.
그런데 엄격한 출력 계약이 있는 시스템에는 능력 바닥(capability floor)이 있습니다. MIRIX는 Qwen3-1.7B에서 완전히 실패합니다. 여러 하위 에이전트 도구 호출이 잘 정의된 JSON 스키마와 적법한 도구 호출 구문을 요구하는데, 그걸 못 맞추는 모델은 손상된 저장소를 만들어 QA 모델이 쓸 증거를 하나도 못 건집니다. 즉 구축 LLM 축소는 만능 절감 레버가 아니라 알고리즘이 강제하는 비용 바닥이며, 엄격한 계약을 가진 시스템은 배포 전에 그 바닥을 검증해야 합니다.
어느 하나도 세 축을 다 잡지 못한다
구축 시간, 질문당 지연, 정확도 세 축을 같이 놓고 보면 결론은 분명합니다.
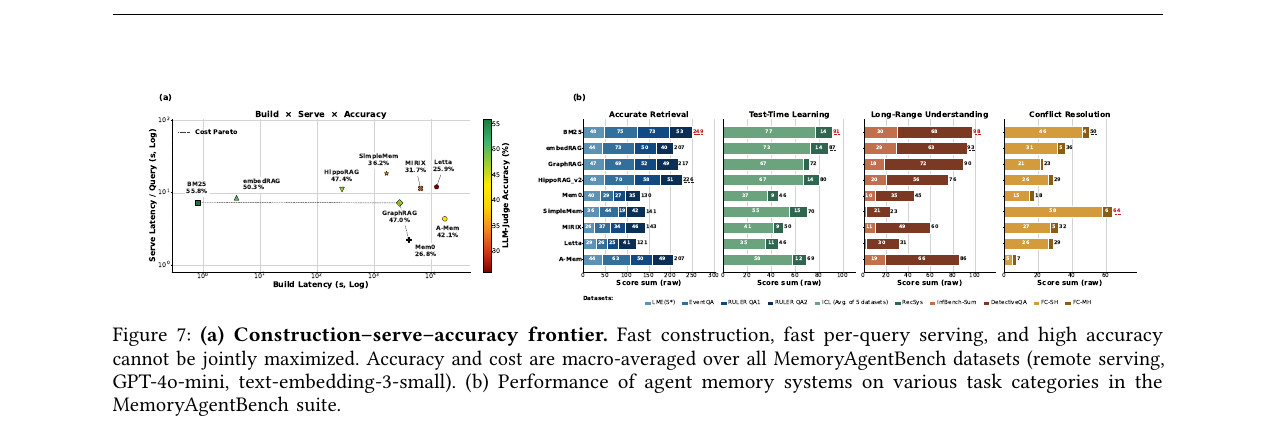
BM25는 1초 안에 구축을 끝내고 전 시스템 중 가장 높은 55.8% 정확도(전 MemoryAgentBench 매크로 평균)에 닿지만, 질의 시간은 약 7.4초로 Mem0·A-Mem·GraphRAG보다 느립니다. 구조 보강·에이전틱 시스템들은 구축 비용을 훨씬 더 쓰고도 BM25의 정확도를 못 넘습니다. HippoRAG v2는 약 277초 구축에 47.4%, GraphRAG는 약 2,850초에 47.0%, A-Mem은 약 17,666초로 가장 비싼 구축에 42.1%입니다. 반대편에서 Mem0는 기록을 원자적 사실로 증류해 질문당 지연 약 2.2초로 가장 낮지만, 그 대가로 약 4,108초를 구축에 쓰고 정확도는 26.8%에 그칩니다. SimpleMem은 의도 계획·다중 뷰 검색·반복 반성을 얹어 질의 시간이 약 18.4초로 가장 느립니다. 세 축을 동시에 최대화하는 단일 시스템은 없고, 저마다 구축-서빙-정확도 프런티어 위의 다른 점을 차지합니다.
다만 BM25의 강세를 일반 결론으로 읽으면 안 됩니다. 매크로 평균은 정확 일치 검색을 보상하는 회상 중심 데이터셋이 많아 어휘 색인에 유리합니다. 패러프레이즈 매칭·다중 홉 추론·시간 추론이 필요한 어려운 범주에서는 BM25와 구조 보강 시스템의 격차가 좁아지거나 뒤집힙니다.
세션이 흐르면 신선도와 지연이 부딪힌다
지금까지는 "다 구축한 뒤 질의"하는 배치 체제였습니다. 세션이 계속 도착하고 뒤 질의가 앞 기억에 의존하면 스케줄링 결정이 새로 생깁니다. MemoryArena physics 분할(20개 다중 세션 작업)을 5초 세션 간격으로 재생해 보면, 세션당 구축 시간이 시스템 간 다섯 자릿수 배(\(10^{-3}\)초의 BM25부터 약 10초의 Mem0·MIRIX, 100초 넘는 꼬리까지)로 벌어집니다. 동기 스케줄링은 각 세션이 자기 쓰기를 기다리며 타임라인을 늘리고, 비동기 스케줄링에서는 SimpleMem·MIRIX·Letta·Mem0·A-Mem이 한두 세션 뒤처진 오래된 기억을 검색하는 staleness를 쌓습니다. 평면 RAG는 두 모드 모두 신선함을 유지합니다. 세션당 구축 시간이 세션 도착 간격을 넘는 시스템은 신선도와 지연을 동시에 만족할 수 없으며, 이때는 정확도만으로 시스템을 고르면 안 됩니다.
사용자당 발자국은 시간이 갈수록 갈라진다
에이전트 메모리는 사용자별로 무한정 쌓입니다. 한 사용자 기록을 6.4만에서 100만 토큰으로 키우며 보면, 디스크 발자국은 1M 토큰에서 시스템 간 약 \(9\times\) 벌어집니다(다중 뷰 설계인 HippoRAG v2가 약 62MB, 통합형 Mem0가 약 12MB). 더 중요한 건 LLM 토큰 비용의 증가 기울기입니다. IV 패러다임 에이전틱 시스템(Letta·A-Mem·MIRIX)은 새 수집마다 커진 메모리 저장소를 질의·평가한 뒤 병합·재작성하므로 토큰 비용이 초선형으로 늘고, Letta는 256K 토큰 너머에서 가파르게 발산합니다. 100K 사용자로 투영하면 저장 공간이 약 0.7TB(embedRAG)에서 6.2TB(HippoRAG v2)까지 벌어집니다. 게다가 어느 시스템도 기본적으로는 가지치기·망각을 하지 않아 발자국이 단조 증가하므로, 함대 규모 저장을 묶으려면 별도의 망각 정책이 필요합니다. 반대로 검색 지연은 저장소가 커져도 거의 평평하게 유지됩니다. 색인 조회 검색이 저장소 크기에 준선형이라 질문당 읽기 비용이 기록 길이에서 분리되기 때문입니다.
지연을 좌우하는 건 LLM 속도가 아니라 검색 깊이
같은 하드웨어, 같은 코퍼스에서도 유효 첫 토큰 시간(effective TTFT)이 두 자릿수 배 벌어집니다(Mem0 약 0.10초에서 SimpleMem 약 22.6초). 차이는 LLM 서빙 속도가 아니라 각 알고리즘이 자기 작업량을 어떻게 묶느냐에서 옵니다. 알고리즘 경계(algorithm-bounded) 단계는 BM25의 단일 top-k 조회, HippoRAG v2의 고정된 시퀀스처럼 정적 속성으로 최악을 미리 프로파일할 수 있습니다. LLM 경계(LLM-bounded) 단계는 MIRIX의 타입별 도구 호출, SimpleMem의 반성 라운드, Letta의 도구 기반 접근처럼 LLM이 끝났다고 할 때까지 이어집니다. 이 둘은 꼬리 분포가 다릅니다. 결정론적 시스템의 p95/p50 비율은 1.3배 근처(HippoRAG v2는 1.6배)인데, LLM 경계 시스템은 GraphRAG 5.9배, Letta 3.9배까지 벌어집니다. 명세가 임의 깊이를 허용하면, 명시적 반복 상한만이 비용을 묶습니다.
회고
저자들은 이 비교가 완벽한 동일 조건이 아님을 솔직히 밝힙니다. 메모리 시스템마다 구현 자유도가 커서 완전한 사과 대 사과 비교는 불가능합니다. 그래서 생성 LLM과 임베딩 백본, 4096토큰 청킹 같은 지배적 요인을 표준화하되, 각 시스템의 고유 버퍼링·병렬 수집·통합 동작은 그것이 특성화 대상이므로 그대로 뒀습니다. 일부 시스템은 원래 대화 에이전트용이라, 프롬프트 형식 불일치로 불이익을 주지 않으려고 추출 프롬프트를 최소한으로 손봤다고 명시합니다. 예컨대 인컨텍스트 학습 데이터셋에서 Mem0의 기본 추출 프롬프트를 정수 라벨을 보존하는 버전으로 바꾼 식입니다.
또 평가한 열 개 시스템 어느 것도 기본 설정에서는 가지치기나 망각을 하지 않습니다. 그래서 발자국이 단조 증가한다는 결론은 "현재 기본 구현 기준"이라는 단서가 붙습니다. 통합형 시스템은 잠재적으로 저장을 압축할 여지가 있지만, 이 논문은 거기까지 끌어내는 적극적 압축 정책은 평가 범위 밖에 둡니다. 프로파일링 하니스가 공개 예정이라 한 점도 회고로 읽힙니다. 측정 도구 자체를 내놓아야 후속 연구가 같은 잣대로 새 시스템을 잴 수 있기 때문입니다.
정리
- 에이전트 메모리 선택은 정확도가 아니라 시스템 결정입니다. 정확도가 비슷해도 구축 비용·서빙 지연·저장 발자국이 한 자릿수 배 이상 갈리고, 정답당 에너지는 약 45배까지 벌어집니다.
- 비용 대부분은 사용자 눈에 안 보이는 구축 단계에 숨어 있습니다. 구축은 길게 읽고 짧게 쓰는 프리필·임베딩 작업이므로, QA 서빙과 분리해 입학 제어가 붙은 백그라운드 처리량 워크로드로 다뤄야 합니다.
- 워크로드 모양에 맞춰 골라야 합니다. 안정된 기록에 질의가 많이 쏟아지면 구축에 일을 몰아넣는 시스템이, 계속 수집되며 질의가 드물면 구축이 싼 시스템이 맞습니다. 세션 간 의존이 강하면 세션당 구축 시간이 도착 간격을 넘는지가 결정적입니다.