ACE-Ego-0 - Unifying Egocentric Human and Robotic Data for VLA Pretraining
H. Li, G. Zhao, Y. Liu, H. Hou, G. Ye, T. Fang, C. Liu, S. Huang, J. Liu, X. Wang, and H. Li, "ACE-Ego-0: Unifying Egocentric Human and Robotic Data for VLA Pretraining," arXiv:2606.17200, 2026.
저자
Hongsheng Li가 교신저자를 맡은 CUHK MMLab과 ACE Robotics의 합동 연구입니다. 1저자 Hao Li, Ganlong Zhao, Yufei Liu, Haotian Hou 네 명이 동등 기여(equal contribution)로 이름을 올렸습니다. Siyuan Huang은 BIGAI 소속으로 프로젝트 리더를 담당했습니다. ACE Robotics라는 산업 조직이 CUHK 학계와 결합한 구조로, 실제 로봇 플랫폼(Galbot, ARX 바이매뉴얼)에 직접 배포까지 한 실험이 포함돼 있다는 점에서 배경이 보입니다.
배경
Vision-Language-Action(VLA) 모델의 성능은 학습 데이터의 규모와 다양성과 강하게 연결돼 있습니다. 그런데 로봇 시연 데이터는 수집이 비쌉니다. 텔레오퍼레이션 장비가 필요하고, 사람이 직접 조종해야 하며, 에러율이 높습니다. 그 결과 기존 대규모 VLA 데이터셋도 특정 플랫폼과 특정 태스크에 편중되기 쉽습니다.
이 논문이 주목한 건 인간의 1인칭 영상입니다. Ego4D, EgoDex, EPIC-KITCHENS 같은 데이터셋에는 부엌, 작업실, 일상 공간에서 손으로 물체를 다루는 장면이 수천 시간 분량 담겨 있습니다. 로봇이 배우기 힘든 장면들, 즉 낮은 빈도로 등장하는 희귀한 조작 동작들이 여기에 있습니다.
문제는 인간 영상을 그대로 VLA 학습에 넣을 수 없다는 점입니다. 두 가지 이질성이 있습니다. 첫째, 표현 이질성(representation heterogeneity). 로봇 액션은 월드 프레임 기준 절대 좌표로 기록되고, 인간 손 복원은 로컬 프레임 기준 MANO 파라미터로 나옵니다. 좌표계, 운동학 구조, 제어 주파수가 모두 다릅니다. 둘째, 감독 품질 불일치(supervision-quality mismatch). 센서 기반 로봇 궤적은 정밀하지만, 비전 파이프라인으로 추출한 인간 손 궤적은 추적 지터, 가림 현상, 추정 오류가 섞인 노이즈 레이블입니다.
기존 크로스-엠보디먼트 VLA들(GR00T, π0 등)은 표현 이질성을 부분적으로 다뤘지만, 두 문제를 동시에 해결하지는 못했습니다. ACE-Ego-0은 이 두 축을 정면으로 공략합니다.
어떻게 만들었나
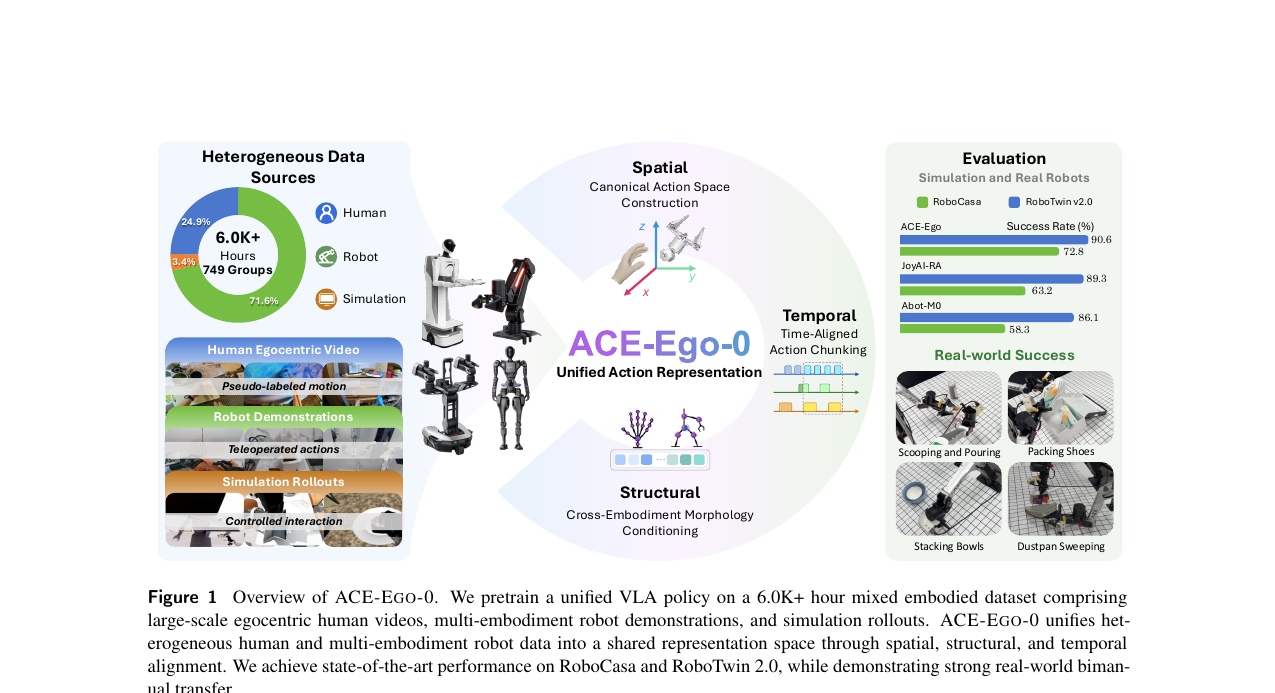
ACE-Ego-0의 핵심은 두 가지입니다. 통합 액션 표현과 신뢰도 인식 학습 목적함수.
통합 액션 표현 (세 축)
공간 정렬 - 카메라 공간 액션. 로봇 엔드이펙터와 인간 손목 모두를 헤드 카메라 좌표계로 변환합니다. 이렇게 하면 정책 모델은 소스별 월드-카메라 변환을 학습할 필요가 없습니다. 새로운 엠보디먼트는 카메라 외부 파라미터(extrinsic) 하나만 교체하면 됩니다. 인간 손의 경우, MANO로 복원한 손 메시에서 손목 관절을 엔드이펙터 원점으로 삼고, 손바닥 평면과 손목-손가락 벡터로 6D 회전을 계산합니다.
변환 수식을 표기하면:
\[p_\text{cam} = R_{\text{cam}\leftarrow s} \, p_s + t_{\text{cam}\leftarrow s}, \quad R_{\text{cam},ee} = R_{\text{cam}\leftarrow s} R_{s,ee}\]
구조 정렬 - 크로스-엠보디먼트 형태 컨디셔닝. 플랫폼마다 다른 운동학 구조를 처리하기 위해 형태 토큰(morphology token)을 도입합니다. 로봇은 URDF 그래프에서 동적으로 토큰을 계산하고, 인간은 소스별 학습된 서로게이트 임베딩을 사용합니다. 이 토큰은 VLM 백본에는 주입되지 않고 액션 디코더에만 들어가, 백본이 엠보디먼트에 무관하게 유지됩니다.
시간 정렬 - 시간-정렬 액션 청킹. 제어 주파수가 다른 데이터셋들은 고정된 미래 프레임 수를 예측하면 물리적 지속 시간이 달라집니다. ACE-Ego-0은 목표 물리 지속 시간 \(T^\star\)를 고정하고, 데이터셋마다 스텝 수 \(H_d = \text{round}(f_d T^\star)\)를 다르게 설정합니다. 이렇게 하면 모든 데이터셋이 동일한 미래 물리 창을 감독합니다.
신뢰도 인식 학습 목적함수
로봇 궤적은 주 흐름 매칭 손실로:
\[\mathcal{L}_\text{action} = \mathbb{E}_{s,\epsilon} \sum_{t,j} M_{t,j} \| \hat{v}_\theta(a_s, s)_{t,j} - (a - \epsilon)_{t,j} \|^2\]
인간 pseudo-action은 보조 손실로 들어갑니다. 신뢰도 가중치 \(W_{t,j} = \rho_j \cdot w_{t,j}\)를 사용하는데, \(\rho_j\)는 채널별 정적 신뢰도(위치 채널은 1.0, 손목 회전·그리퍼는 낮게), \(w_{t,j}\)는 스텝별 동적 평활도 가중치입니다.
\[\mathcal{L}_\text{haux} = \mathbb{E}_{s,\epsilon} \frac{1}{Z} \sum_{t,j} M_{t,j} W_{t,j} \, \text{Huber}_\beta(\hat{v}_\theta(a_s, s)_{t,j} - (\tilde{a} - \epsilon)_{t,j})\]
최종 손실은 \(\mathcal{L} = \mathcal{L}_\text{action} + \lambda_\text{haux} \mathcal{L}_\text{haux}\).
에고센트릭 비디오-to-액션 파이프라인
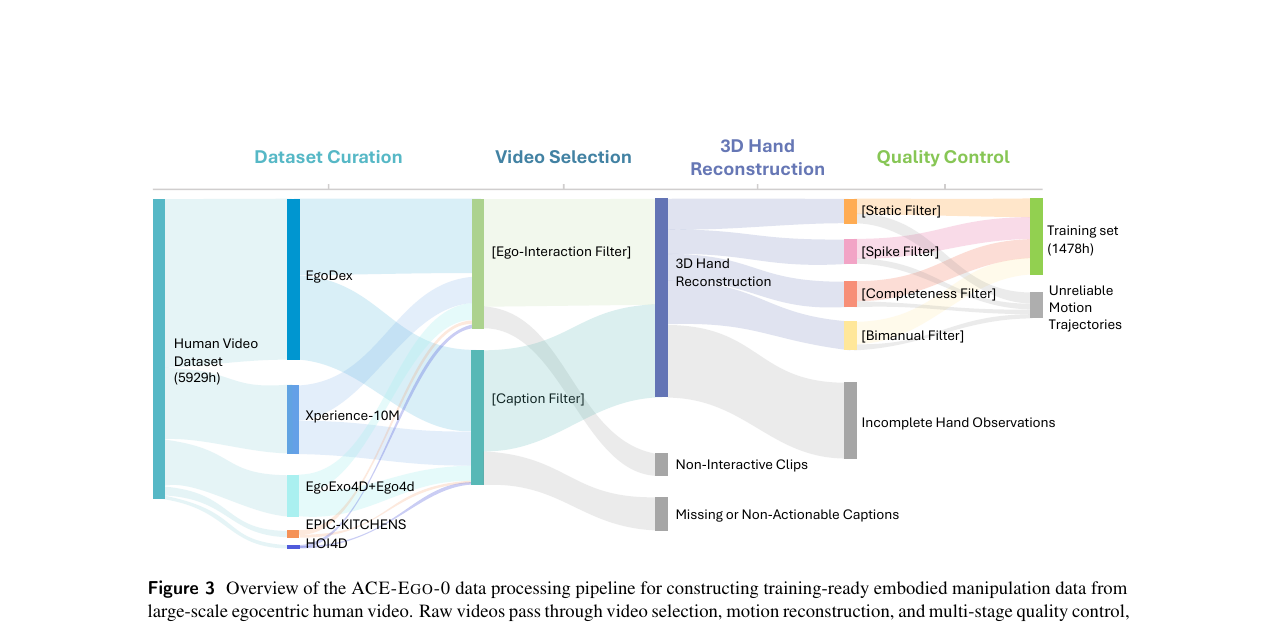
인간 비디오에서 로봇 호환 pseudo-action을 추출하는 5단계 파이프라인입니다.
- 데이터셋 큐레이션. Ego4D, EgoExo4D, EPIC-KITCHENS-100, HOI4D, EgoDex, Xperience-10M 여섯 소스를 수집합니다. 4초 미만·30초 초과 클립을 제거합니다.
- 영상 선택. 얼굴 감지 신뢰도가 임계값(0.5)을 초과하면 비-에고센트릭 뷰로 보고 제거합니다. 이미지 캡셔닝 필터로 조작 동사와 조작 가능 객체 명사가 모두 있는 클립만 남깁니다.
- 3D 손 복원. SAM3 기반 트래커로 손 바운딩박스를 추적하고, HaMeR로 MANO 파라미터를 복원합니다. 이후 두 단계 전역 궤적 최적화를 수행합니다. 재투영 손실과 시간적 평활도 정칙화항을 합산합니다:
\[\mathcal{L}_\text{smooth} = \mathcal{L}_\text{reproj} + \lambda_\text{tv} \sum_t \| t^\text{global}_{t+1} - 2t^\text{global}_t + t^\text{global}_{t-1} \|^2\]
- 액션 파라미터화. 손목을 엔드이펙터 원점으로, 손바닥 평면으로 6D 회전을 계산합니다. 그리퍼 개폐는 엄지-손바닥 거리의 정규화값으로 근사합니다.
- 품질 관리. 정적 필터(낮은 움직임 에너지), 스파이크 필터(이상 속도 변화), 완전성 필터(NaN/Inf·연속성 위반), 바이매뉴얼 필터(양손 비정상 거리)를 순차 적용합니다.
5,929시간 원본 영상에서 최종 1,478시간 분량의 pseudo-action 레이블 클립이 나옵니다.
결과
사전학습 데이터는 총 6,013.7시간+입니다. 로봇 서브셋이 4,534.8시간+(AgiBot Alpha/Beta 1,937시간, Galbot 자체 수집 1,800시간+ 등), 인간 비디오 서브셋이 1,478.9시간입니다.
RoboCasa GR1 TableTop (24 태스크, 태스크당 50 롤아웃):
방법 |
성공률 (%) |
|---|---|
GR00T-N1.6 |
47.6 |
Qwen3PI |
43.9 |
FLARE |
55.0 |
ABot-M0 |
58.3 |
JoyAI-RA |
63.2 |
DIAL |
70.2 |
ACE-Ego-0 |
72.8 |
ACE-Ego-0이 72.8%로 기존 최고였던 DIAL(70.2%)을 2.6%p 앞섭니다. 픽앤플레이스(18개 태스크)와 조인트 아티큘레이션 태스크(6개 태스크) 양쪽에서 일관적인 향상이 나타납니다.
RoboTwin 2.0 (50 태스크, Easy/Hard 설정):
방법 |
Easy (%) |
Hard (%) |
|---|---|---|
π0.5 |
82.74 |
76.76 |
Motus |
88.66 |
87.02 |
LingBot-VLA |
88.56 |
86.68 |
ABot-M0 |
86.06 |
85.08 |
JoyAI-RA |
90.48 |
89.28 |
Hy-VLA |
90.9 |
90.1 |
ACE-Ego-0 |
91.12 |
90.62 |
Easy와 Hard 설정 모두에서 SOTA를 달성했습니다.
실제 로봇(ARX 바이매뉴얼 플랫폼) 6개 태스크:
태스크 |
ACE-Ego-0 |
π0.5 |
GR00T-N1.7 |
|---|---|---|---|
Pick Tea |
86.7 |
86.7 |
86.7 |
Scoop Coffee |
86.7 |
70.0 |
36.7 |
Category Sorting |
90.0 |
80.0 |
83.3 |
Sweep Cubes |
76.7 |
76.7 |
6.7 |
Stack Bowls |
83.3 |
73.3 |
73.3 |
Pack Shoes |
53.3 |
63.3 |
10.0 |
평균 |
79.4 |
75.0 |
49.5 |
접촉이 많은 바이매뉴얼 태스크인 Scoop Coffee에서 ACE-Ego-0(86.7%) vs π0.5(70.0%) vs GR00T-N1.7(36.7%)로 격차가 특히 큽니다. Pack Shoes처럼 긴 순차 조작이 필요한 태스크에서는 모든 모델이 성능이 떨어지며, 장기 궤적의 누적 드리프트가 공통 과제로 남아 있음을 보여줍니다.
어블레이션 결과:
구성 |
RoboCasa 성공률 (%) |
|---|---|
Full Model |
72.8 |
w/o Dynamic Chunking |
71.7 (-1.1) |
w/o URDF Morphology |
70.9 (-1.9) |
w/o Human Aux Loss |
69.2 (-3.6) |
신뢰도 가중 보조 손실을 제거하면 하락 폭이 가장 큽니다(-3.6%p). 노이즈 있는 pseudo-action을 동등 가중치로 학습시키면 액션 전문가가 혼동을 받습니다.
데이터 소스 어블레이션에서는 Qwen 초기화(65.4%) → 로봇 데이터 추가(68.3%, +2.9%p) → 인간 비디오 추가(72.8%, +4.5%p) 순으로 향상됩니다. 인간 비디오 추가 효과가 단일 기여 중 가장 큽니다.
회고
저자들이 직접 밝힌 한계입니다.
평가 범위가 테이블탑에 한정됩니다. 모바일 조작, 전신 휴머노이드 제어, 변형 물체 태스크로 확장하면 카메라 공간 액션 인터페이스가 더 다양한 공간 컨벤션과 긴 태스크 지평선 아래에서도 작동하는지 검증이 필요합니다.
덱스터러스 핸드 데이터와 힘/토크 센싱이 없습니다. 현재 파이프라인은 손끝 세밀 조작이나 접촉력 정보를 학습에 포함하지 않습니다. 이 모달리티를 추가하면 접촉 집약적 조작이 더 개선될 여지가 있습니다.
Pseudo-action 품질의 병목이 회전과 손가락 움직임에 있습니다. 신뢰도 가중 보조 손실이 위치 채널에 집중 감독을 주는 이유가 바로 이 때문입니다. 손목 회전과 그리퍼 상태의 복원 정밀도가 올라가면, 보조 손실이 더 많은 채널을 안전하게 감독할 수 있습니다.
숨겨진 전제 하나를 짚자면, 카메라 공간 예측의 장점은 카메라 외부 파라미터가 정확하게 캘리브레이션돼 있다는 가정을 깔고 있습니다. 실사용 환경에서 헤드 카메라의 캘리브레이션 오류나 드리프트가 발생하면 이 접근이 얼마나 강건한지는 별도 검증이 필요합니다.
정리
- 인간 1인칭 영상 1,478시간을 로봇 데이터 4,534시간+와 합쳐 6K+ 시간 사전학습 데이터를 구성했습니다. 공간·구조·시간 세 축의 통합 표현으로 이질성을 해소하고, 신뢰도 인식 보조 손실로 노이즈 pseudo-action을 안전하게 활용합니다.
- RoboCasa GR1 TableTop 72.8%, RoboTwin 2.0 Easy/Hard 91.12%/90.62%로 기존 SOTA를 갱신했습니다. 실제 ARX 바이매뉴얼 플랫폼에서도 평균 79.4%로 π0.5(75.0%)를 앞섭니다.
- 데이터 부족한 파인튜닝 시나리오에서 인간 비디오가 34개 로봇 시연만으로 10%에 머물던 성공률을 40%로 끌어올렸습니다. 4.8배 넓은 워크스페이스 커버리지가 그 이유였습니다.