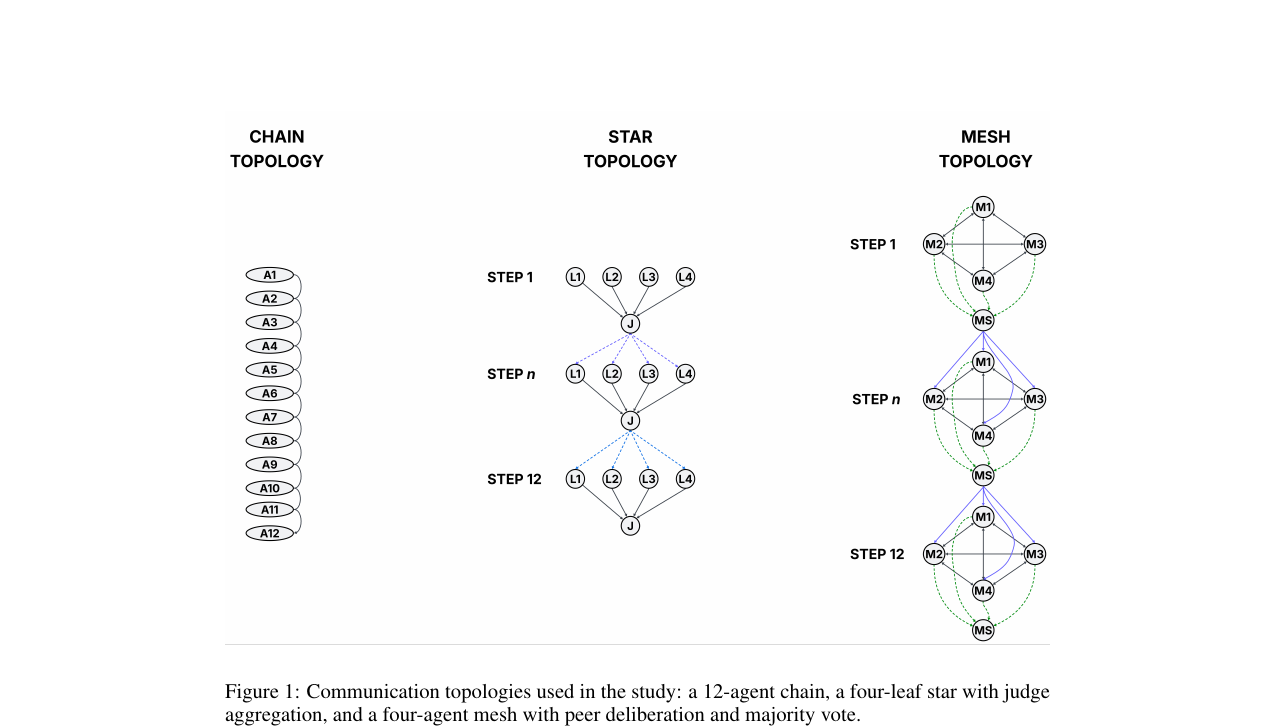
Multi-Resolution Flow Matching - Training-Free Diffusion Acceleration via Staged Sampling
2026-07-05
재훈련 없이 FLUX·Qwen-Image 같은 플로우 매칭 확산 모델을 10× 가속하는 MrFlow를 제안합니다. 초반 스텝은 저해상도 잠재 공간에서 처리하고, 픽셀 공간 GAN 슈퍼해상도를 거쳐 단 1스텝 고해상도 정제로 마무리하는 단계별 파이프라인입니다.