A Tutorial on Energy-Based Learning
Y. LeCun, S. Chopra, R. Hadsell, M. Ranzato, and F. J. Huang, "A Tutorial on Energy-Based Learning," in Predicting Structured Data, G. Bakir, T. Hofmann, B. Schölkopf, A. Smola, B. Taskar, and S. V. N. Vishwanathan, Eds. Cambridge, MA: MIT Press, 2006.
저자
저자 명단은 얀 르쿤과 그의 NYU 학생 네 명으로 구성됩니다. 1저자 얀 르쿤은 LeNet-5 논문 시절부터 Graph Transformer Network라는 이름으로 에너지 기반 학습 정식을 끌고 왔고, 2006년 시점에서 그 흐름을 정리할 필요를 느낀 것이 이 튜토리얼의 출발점입니다.
수밋 초프라와 라이아 해드셀은 박사 과정에서 contrastive loss와 DrLIM을 만들고 있던 두 사람입니다. 본 튜토리얼의 §5 Good and Bad Loss Functions는 두 사람의 박사 작업이 만들어 낸 마진 조건 분석이 그대로 들어간 결과입니다.
마르카우렐리오 란차토는 같은 시기 희소 부호화의 EBM 정식을 다듬고 있었습니다. §4 Architectures with Latent Variables의 잠재 변수 최소화 형식은 그의 박사 연구에서 출발한 영역입니다.
푸제 황은 NORB 데이터셋을 만든 인물입니다. 객체 인식 영역의 정량 실험과 §5의 실험 보고가 그가 맡은 부분입니다.
다섯 명이 동시에 박사 후반·신임 교수 시기에 EBM이라는 한 정식을 다른 응용에서 두드리고 있었다는 점이 이 튜토리얼을 만든 동력입니다.
배경
2006년은 신경망이 겨울에서 막 깨어나려는 시점입니다. SVM·CRF·Maximum Margin Markov Network 같은 볼록 손실 기반 모델이 학계 주류였고, HMM과 베이지안 네트워크 같은 내부 정규화 확률 모델이 음성·자연어 처리를 지배하고 있었습니다. 합성곱 신경망은 LeNet-5 이후 우편번호·수표 판독이라는 좁은 상업 영역에 갇혀 있는 상태였습니다.
저자들의 문제 의식은 두 가지였습니다. 첫째, 확률 분포의 정규화 제약이 모델 선택을 좁힌다는 점입니다. HMM에서 한 노드에서 나가는 전이 확률이 1로 합해져야 한다는 제약, CRF에서 분할 함수가 수렴해야 한다는 제약은 label bias와 missing probability mass 같은 인공적 문제를 만듭니다. 둘째, 학습은 결국 원하는 답의 에너지를 낮추고 원하지 않는 답의 에너지를 높이는 일인데, 확률 모델은 두 가지를 정규화라는 한 가지 도구로 묶어 처리합니다. 그 묶음을 풀어내자는 것이 EBM의 목표입니다.
이 튜토리얼은 그 풀어낸 정식을 가지고 기존 모델 대부분이 EBM의 특수한 경우임을 보입니다. CRF·SVMM·MMMN·GTN·HMM-NN 하이브리드가 모두 손실 함수 한 줄로 구분됩니다.
에너지의 정식
EBM의 출발점은 단순합니다. 입력 \(X\)와 답 \(Y\)에 대해 스칼라 에너지 \(E(Y, X)\)를 정의하고, 추론을 다음 최소화 문제로 봅니다.
\[Y^* = \arg\min_{Y \in \mathcal{Y}} E(Y, X)\]
학습은 파라미터 \(W\)를 가진 에너지족 \(\{E(W, Y, X) : W \in \mathcal{W}\}\)에서 원하는 답의 에너지가 다른 답보다 낮은 \(W\)를 고르는 일입니다.
저자들은 EBM이 답하는 네 가지 질문 유형을 정리합니다. 예측은 \(\arg\min_Y E(Y, X)\)이고, 순위는 답들의 상대 에너지 정렬, 검출은 \(E(Y, X)\)가 임계값 이하인지 판정, 조건부 밀도 추정은 깁스 분포로의 변환입니다. 네 번째 변환식이 자주 쓰입니다.
\[P(Y \mid X) = \frac{e^{-\beta E(Y, X)}}{\int_{y \in \mathcal{Y}} e^{-\beta E(y, X)} \, dy}\]
여기서 적분이 수렴한다는 보장은 없습니다. EBM은 적분이 수렴하지 않아도 작동합니다. 에너지의 상대값만 쓰기 때문입니다. 이것이 EBM이 확률 모델의 부분집합이 아니라 그 반대 관계, 즉 확률 모델이 EBM의 한 특수한 경우라는 저자들의 주장의 출발입니다.
학습 과정에서 세 가지 답을 구분합니다. 정답 \(Y^i\), 시스템이 만든 답 \(Y^{*i}\), 가장 거슬리는 오답 \(\bar{Y}^i\). 이 셋의 에너지를 조합하여 손실 함수를 만듭니다.
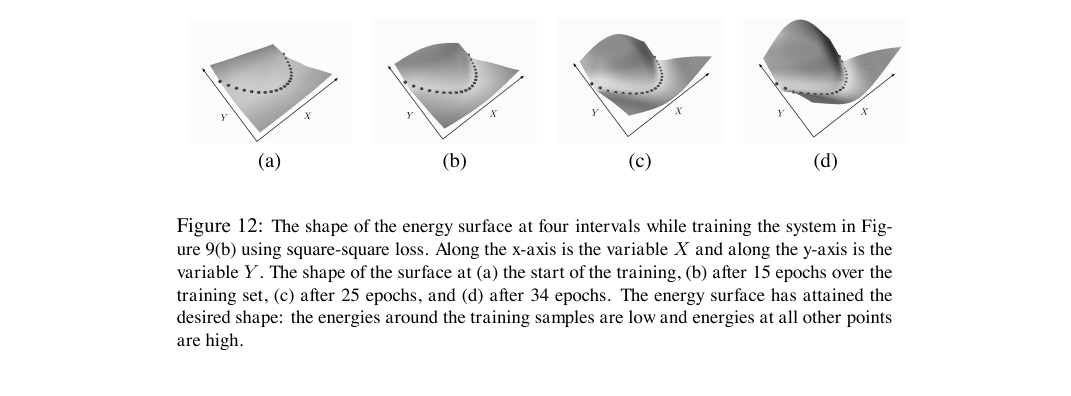
위 그림은 square-square 손실로 단순한 회귀 시스템을 학습할 때 에너지 표면이 시간에 따라 어떻게 변하는지를 보여 줍니다. (a)는 학습 시작 시점의 평평한 표면, (d)는 34 에폭 후의 표면입니다. 훈련 표본 주변의 에너지가 깊은 골을 이루고, 그 밖의 영역은 봉우리로 올라간 모습이 핵심입니다. 학습은 이 지형 조각하기 작업입니다.
손실 함수의 좋고 나쁨
EBM 학습의 가장 큰 함정은 collapse입니다. 에너지족이 충분히 표현력이 있고 손실 함수가 원하는 답의 에너지만 낮추는 항만 가진다면, 학습은 모든 답에 0 에너지를 부여하는 상수 함수로 수렴합니다. 평평한 표면이 됩니다.
저자들은 어떤 손실이 collapse를 피하는지 충분 조건으로 정리합니다. 핵심은 condition 3입니다. 양의 마진 \(m\)이 존재하여, 손실의 최솟값이 \(E_C + m < E_I\)를 만족하는 영역(half-plane \(HP_1\)) 안에서 달성되어야 한다는 조건입니다. 여기서 \(E_C = E(W, Y^i, X^i)\)는 정답 에너지, \(E_I = E(W, \bar{Y}^i, X^i)\)는 가장 거슬리는 오답 에너지입니다.
이 조건을 가지고 주요 손실 함수를 점검하면 다음과 같습니다.
손실 |
식 |
마진 |
|---|---|---|
energy loss |
\(E(W, Y^i, X^i)\) |
없음 |
perceptron |
\(E(W, Y^i, X^i) - \min_{Y} E(W, Y, X^i)\) |
0 |
hinge |
\(\max(0, m + E(W, Y^i, X^i) - E(W, \bar{Y}^i, X^i))\) |
\(m\) |
log |
\(\log(1 + e^{E(W, Y^i, X^i) - E(W, \bar{Y}^i, X^i)})\) |
\(> 0\) |
LVQ2 |
\(\min(M, \max(0, E(W, Y^i, X^i) - E(W, \bar{Y}^i, X^i)))\) |
0 |
MCE |
\((1 + e^{-(E(W, Y^i, X^i) - E(W, \bar{Y}^i, X^i))})^{-1}\) |
\(> 0\) |
square-square |
\(E(W, Y^i, X^i)^2 - (\max(0, m - E(W, \bar{Y}^i, X^i)))^2\) |
\(m\) |
square-exp |
\(E(W, Y^i, X^i)^2 + \beta e^{-E(W, \bar{Y}^i, X^i)}\) |
\(> 0\) |
NLL / MMI |
\(E(W, Y^i, X^i) + \frac{1}{\beta} \log \int_{y} e^{-\beta E(W, y, X^i)}\) |
\(> 0\) |
MEE |
\(1 - e^{-\beta E(W, Y^i, X^i)} / \int_{y} e^{-\beta E(W, y, X^i)}\) |
\(> 0\) |
energy loss는 마진이 없습니다. 일반 아키텍처에서는 collapse가 일어납니다. perceptron loss와 LVQ2는 마진 0입니다. 이론적으로는 collapse 가능성이 남지만 실제로는 잘 작동하는 경우가 많습니다. 나머지는 양의 마진을 가진 좋은 손실입니다.
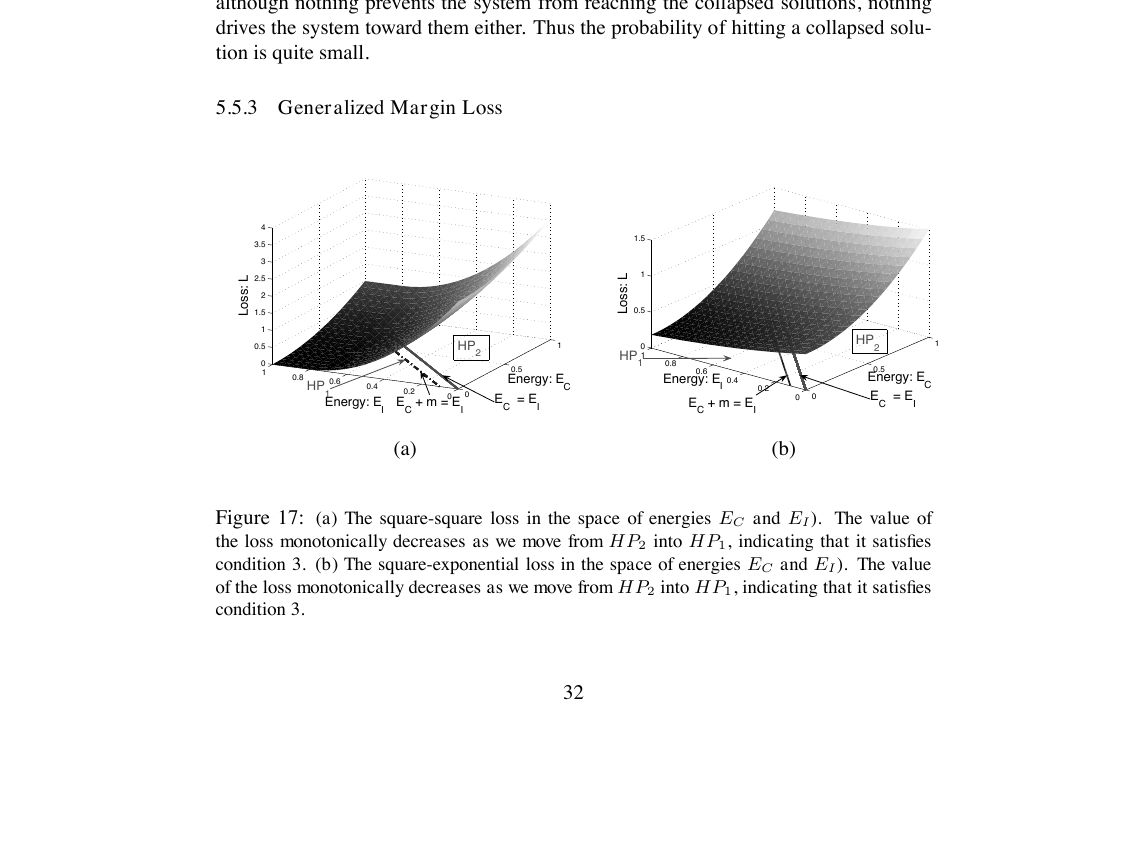
위 그림은 정답 에너지 \(E_C\)와 오답 에너지 \(E_I\)로 만든 평면에서 두 손실의 표면을 보여 줍니다. (a) square-square 손실, (b) square-exp 손실 모두 \(HP_2\)에서 \(HP_1\) 쪽으로 갈수록 단조 감소합니다. 학습 알고리즘이 이 손실을 줄이려고 움직이면 자연스럽게 \(E_C + m < E_I\) 영역으로 끌려갑니다. condition 3을 만족합니다.
흥미로운 예외는 RBF 아키텍처에서의 energy loss입니다. 에너지가 \(E(W, Y^i, X^i) = \|U^{Y^i} - G_W(X^i)\|^2\) 형태이고, 중심 \(U^k\)들이 고정되고 구별되도록 묶이면, \(d_1 + d_2 \geq d = \|U^1 - U^2\|^2\)라는 기하학적 하한이 자동으로 깔립니다. 이 하한이 마진 역할을 합니다. 같은 아키텍처에서 중심을 학습 가능하게 풀어 두면 두 중심이 한 점으로 붕괴하면서 표면도 함께 무너집니다. 손실 함수의 좋고 나쁨이 아키텍처 가정에 의존한다는 결론을 보여 주는 사례입니다.
그래프 트랜스포머와 시퀀스
EBM의 진짜 가치는 시퀀스·구조 출력에 응용할 때 드러납니다. 단일 카테고리 분류는 합성곱 신경망 하나로 충분하지만, 손글씨 문장 인식·음성 인식·구문 분석은 답 자체가 지수적으로 큰 집합입니다. 모든 답에 일일이 에너지를 매기는 것은 불가능합니다.
저자들은 factor graph 위에서 에너지를 분해하는 방식으로 이 문제를 풉니다. 에너지가 부분 변수들에 의존하는 인자(factor)의 합으로 적히면 다음과 같습니다.
\[E(Y, Z, X) = E_a(X, Z_1) + E_b(X, Z_1, Z_2) + E_c(Z_2, Y_1) + E_d(Y_1, Y_2)\]
인자 그래프 위의 추론은 trellis 위의 최단 경로 문제로 환원됩니다. Viterbi 알고리즘으로 풉니다. 학습 시 contrastive term의 log partition function도 같은 trellis 위에서 forward 알고리즘으로 계산됩니다.
이 정식 안에 들어가는 모델들이 차례로 정리됩니다. CRF(Lafferty et al., 2001)는 선형 에너지 \(E(W, Y, X) = W^T F(X, Y)\)에 NLL 손실을 더한 것이고, Maximum Margin Markov Network(Taskar et al., 2003)와 SVMM(Altun et al., 2003)은 같은 선형 에너지에 hinge 손실과 \(L_2\) 정규화를 더한 것입니다. 셋이 모두 손실 함수 한 줄 차이로 갈립니다.
비선형 확장이 Graph Transformer Network입니다. LeNet-5 논문에서 처음 제안된 GTN은 본 튜토리얼의 §7.3에서 EBM의 계층적 그래프 모델로 다시 정의됩니다.
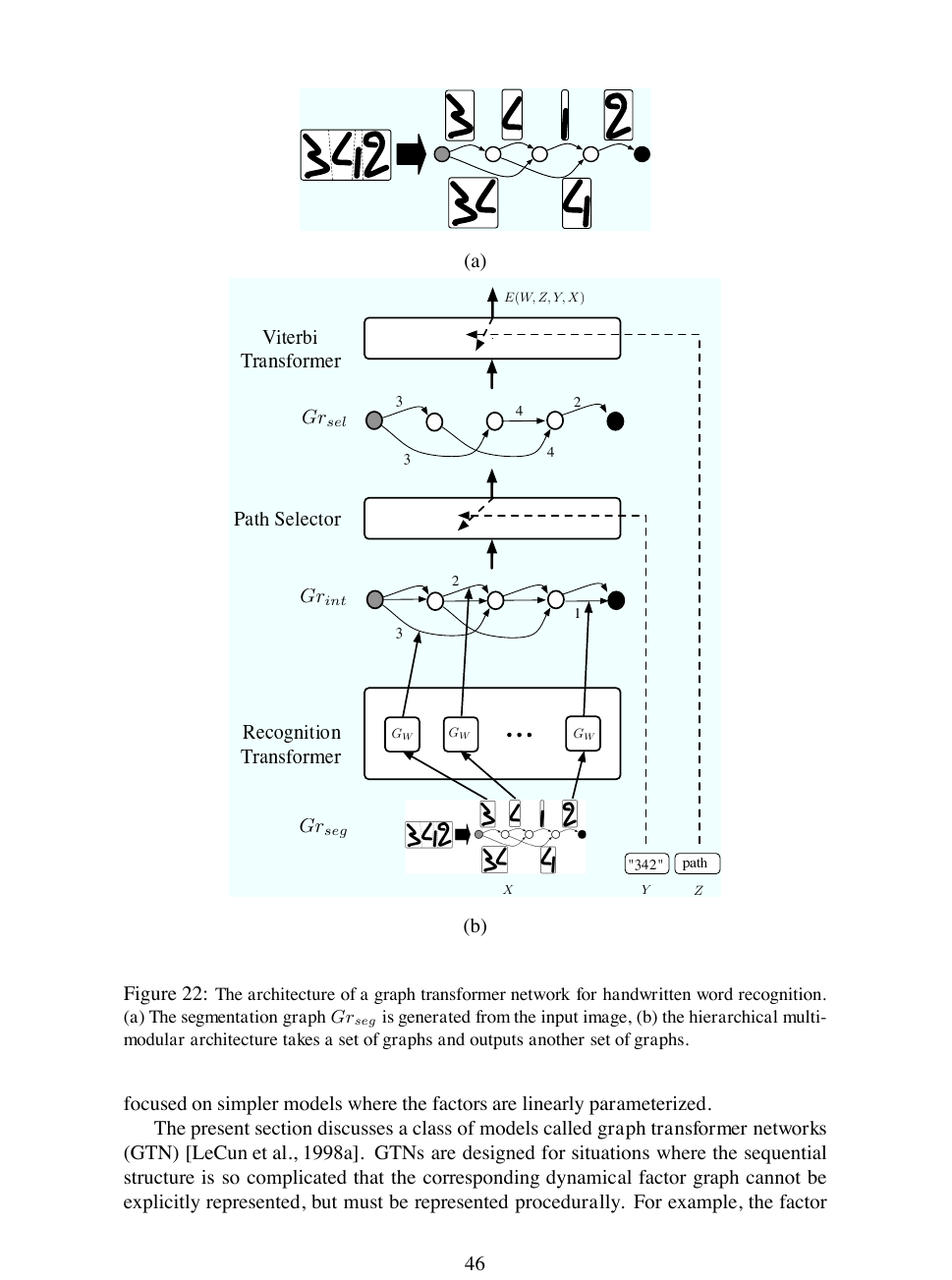
위 그림은 손글씨 단어 인식용 GTN 아키텍처입니다. (a)는 입력 영상이 과분할(over-segmentation)되어 분할 그래프 \(Gr_{seg}\)로 변환되는 과정을 보여 줍니다. (b)는 그 위에 Recognition Transformer(여러 개의 합성곱 신경망 복제본 \(G_W\)), Path Selector, Viterbi Transformer가 쌓여 최종 에너지 \(E(W, Z, Y, X)\)를 만드는 과정입니다.
GTN의 두 가지 학습 방식이 EBM의 손실 함수 분류표에 그대로 대응됩니다. Discriminative Viterbi training은 perceptron 손실, Discriminative Forward training은 NLL 손실에 해당합니다. 후자는 본 튜토리얼이 나오기 9년 전 르쿤이 수표 판독 상용 시스템에서 실제로 사용한 손실이고, 그 시스템은 1990년대 후반 미국 수표 처리량의 약 10퍼센트를 담당했습니다.
마지막 한 페이지에서 저자들은 제프리 힌턴의 contrastive divergence(2002)도 같은 정식 안에 위치시킵니다. CD는 원하는 답 근처에서 짧은 MCMC로 대조 표본을 만드는 NLL의 근사이며, 결국 어떤 답의 에너지를 끌어올릴지 고르는 정책의 한 선택지일 뿐이라는 관점입니다.
회고
저자들이 §8 Discussion에서 직접 짚는 한계가 셋 있습니다.
첫째, 학습 효율 면에서 분할 함수의 비용은 사라지지 않는다는 점입니다. EBM은 정규화를 학습 도중이 아니라 끝에 한 번 처리하지만, hinge 같은 가장 거슬리는 오답 한 점만 끌어올리는 손실은 가짜 마진을 만들 위험이 있습니다. NLL은 모든 오답을 끌어올리지만 비싸고, 그 중간을 어떻게 잡을지는 열린 문제입니다.
둘째, 에너지 표면의 형상에는 bias-variance dilemma가 있습니다. 답 공간 \(\mathcal{Y}\)가 고차원이고 에너지 표면이 말랑말랑하면 옳은 모양으로 만들기 위해 수많은 점을 끌어올려야 합니다. 표면을 경직되게 설계하면 적은 끌어올림으로도 모양이 잡히지만 잘못된 모양으로 굳어질 위험이 큽니다. 아키텍처 설계가 손실 함수 선택만큼 중요하다는 결론입니다.
셋째, 근사 추론 위에서 학습한다는 본질적 한계입니다. 추론 알고리즘이 도달하지 못하는 답에는 에너지가 잘못 매겨져도 시스템 성능에는 영향이 없습니다. 그런 의미에서 EBM은 확률 모델보다 차라리 효율적입니다. NLL은 추론이 절대 찾지 못할 답에까지 에너지를 끌어올리려 자원을 씁니다.
저자들은 EBM과 확률 모델의 우열을 결론짓지 않습니다. 다만 확률 모델이 EBM의 특수한 경우라는 위계를 보입니다. 확률이 필요한 응용에서는 확률 모델을, 예측·분류·결정만 필요한 응용에서는 EBM의 자유도를 선택하라는 권고입니다.
정리
- 에너지 기반 학습은 원하는 답의 에너지는 낮추고 다른 답의 에너지는 높이는 일이며, 정규화된 확률을 거치지 않는다. 확률 모델은 그 한 특수한 경우이고, 그 역은 성립하지 않는다.
- 좋은 손실 함수의 판별 기준은 양의 마진을 가지는 것이다. energy loss는 일반 아키텍처에서 collapse를 일으키므로 나쁜 손실이지만, RBF처럼 아키텍처가 기하학적 마진을 보장하면 다시 좋은 손실이 된다. 손실의 좋고 나쁨은 아키텍처에 의존한다.
- GTN, CRF, SVMM, MMMN, HMM-NN 하이브리드는 모두 EBM의 인자 그래프 정식 위에서 손실 함수 한 줄 차이로 갈리는 형제 모델이다.