On the Scaling of PEFT - Towards Million Personal Models of Trillion Parameters
Mind Lab, "On the Scaling of PEFT: Towards Million Personal Models of Trillion Parameters," arXiv:2606.02437, 2026.
저자
Mind Lab의 집단 저작입니다. 65명 이상의 연구자가 참여했으며, 논문을 개인 저자 이름 대신 기관명으로 발행했습니다. 핵심 기여자는 Andrew Chen, Steven Chiang, Kyrie Lei, Kieran Liu, Pony Ma, Vincent Wang, Josh Ying, Di Zhang, Ruijia Zhang, Adrian Zhou, Yuhua Zhou 11명입니다.
이들이 이 논문을 쓴 동기는 사내에서 구축 중인 MinT 인프라를 이론적으로 뒷받침하기 위해서입니다. Kimi K2(1T MoE), Qwen3-235B, GLM5 등 외부 대형 모델에 LoRA RL을 실제 적용하면서 얻은 공학적 발견들을 하나의 프레임워크로 정리했습니다.
배경
LoRA는 오랫동안 "풀 파인튜닝보다 싸게 쓰는 방법"으로 평가받아 왔습니다. 모델 파라미터의 극히 일부에만 낮은 랭크 행렬을 붙이고, 나머지는 얼리는 방식이기 때문입니다.
이 논문은 그 관점을 정면으로 뒤집습니다. PEFT를, 특히 LoRA를 하나의 스케일링 메커니즘으로 봐야 한다는 주장입니다. 수백만 명의 사용자 각각에게 지속적이고 개인화된 모델 인스턴스를 제공하는 인프라의 기본 단위가 LoRA 어댑터라는 것입니다.
비유가 직관적입니다. 어떤 두 인간이든 게놈의 99.9%를 공유합니다. 그 0.1%의 차이가 개인의 전부를 만듭니다. 하나의 공유 기반 모델이 수십억 명의 차별화된 삶을 지지하는 생물학처럼, 하나의 강력한 기반 모델이 수백만 개의 퍼스널 어댑터를 지지하는 구조가 가능하다는 것입니다.
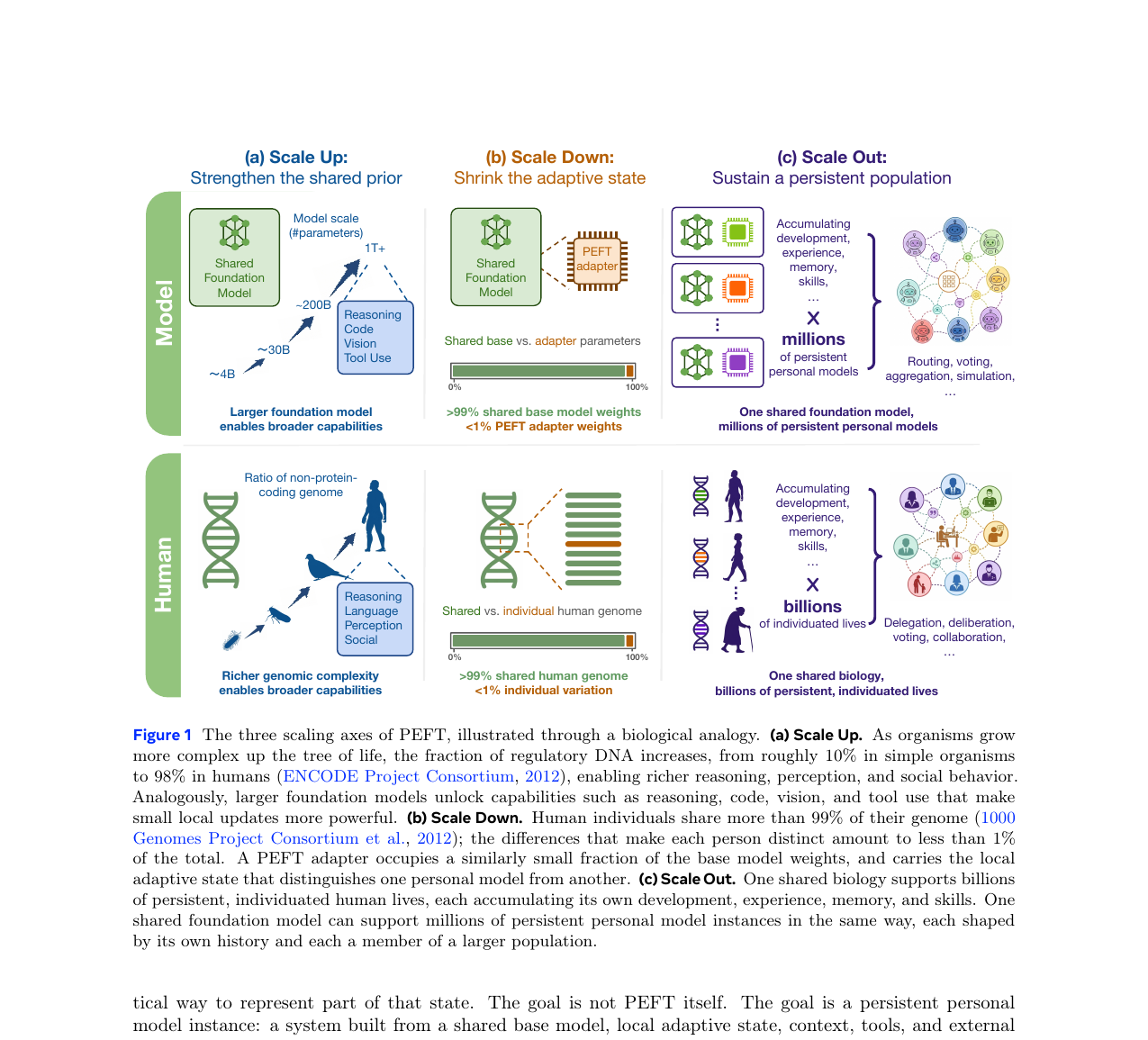
단, 이 비전이 성립하려면 세 가지 축이 동시에 작동해야 합니다. 하나라도 빠지면 무너집니다.
세 축의 의존 구조
논문이 제시하는 프레임워크의 핵심은 Scale Up, Scale Down, Scale Out 세 축이 독립적인 분류가 아닌 의존 사슬이라는 점입니다.
축 |
질문 |
역할 |
|---|---|---|
Scale Up |
기반 모델이 강해질수록 어댑터는 더 유용해지는가? |
어댑터에 지렛대 능력을 부여 |
Scale Down |
어댑터를 얼마나 작게 만들 수 있는가? |
반복 학습을 경제적으로 |
Scale Out |
수백만 개의 어댑터가 공존할 때 무엇이 가능해질까요? |
개인화를 인구 규모로 확장 |
실패 케이스를 보면 의존 구조가 더 명확해집니다. Scale Up이 없으면 강력한 기반 모델이 없으니 어댑터가 피상적인 메모리화에 그칩니다. Scale Down이 없으면 각 업데이트 비용이 너무 높아 지속적 적응이 불가능합니다. Scale Out이 없으면 훌륭한 단일 어댑터가 있어도 인구 규모의 개인화는 그림의 떡입니다.
Scale Up: 트릴리온 파라미터에서의 LoRA RL
Scale Up의 핵심 주장은 "RL은 사전 학습된 모델에 의해 제한됩니다"라는 것입니다. 강화학습은 기반 모델의 궤도 분포 안에서 탐색하기 때문에, 기반 모델이 이미 약한 형태로나마 보유하고 있는 능력만 강화할 수 있습니다. 강한 기반 모델일수록 RL이 찾아낼 수 있는 유용한 궤도의 확률 질량이 높아집니다.
이것이 "큰 기반 모델 + 작은 LoRA"가 "작은 기반 모델 + 풀 RL"을 이기는 이유입니다.
설정 |
훈련 가능 파라미터 |
AIME 2025 정규화 이득 |
GPQA Diamond 정규화 이득 |
|---|---|---|---|
DS-Distill-Qwen-1.5B, 풀 RL |
1.5B |
8.33% |
25.00% |
DS-Distill-Qwen-7B, LoRA r=64 |
0.16B |
11.31% |
27.23% |
DS-Distill-Qwen-32B, LoRA r=8 |
0.07B |
20.61% |
33.02% |
훈련 가능 파라미터가 1.5B에서 0.07B로 21분의 1 수준으로 줄었는데, 정규화 이득은 오히려 2.5배 이상 늘었습니다. 더 작은 어댑터로 더 강한 기반 모델에 접근하는 것이 유리합니다.
Mind Lab은 이 원리를 Kimi K2(1.04T 파라미터, 32.6B 활성화) MoE 모델에 적용하여 실제 LoRA RL을 구동했습니다. 전체 파라미터 RL 대비 GPU 예산을 약 10%로 줄이면서 안정적인 보상 곡선과 태스크 성공률 향상을 확인했습니다.
단순히 가능하다는 증명에 그치지 않습니다. MoE 아키텍처에서 드러나는 새로운 실패 유형을 분류하고 해결책도 제시합니다. 학습 측과 추론 측의 라우팅 결정이 달라지면 그래디언트가 실제로 샘플된 정책과 다른 경로를 통해 계산되는 문제(Training-Inference Mismatch, TIM)가 대표적입니다. 이를 해결하기 위해 롤아웃 시의 라우팅 정보를 기록했다가 학습 시 재생하는 Router Replay R3를 제안합니다.
Scale Down: 작고 안정적인 어댑터
Scale Down의 목표는 신뢰할 수 있는 학습이 가능한 최소 어댑터 단위를 찾는 것입니다.
랭크 체제 분류
Qwen3-8B PPO 실험(216개 실행, 9가지 랭크 × 4가지 배치 크기 × 6개 시드)은 LoRA 랭크를 단조 증가하는 용량 다이얼이 아닌 세 가지 체제로 분류합니다.
- 랭크 16~32: 실용 기본값. 평균 이득이 가장 높고 하방 리스크도 낮습니다.
- 랭크 1~4: 연구 프런티어. 최고 시드 성능은 랭크 16~32와 비슷한데, 시드 간 분산이 크고 평균이 낮습니다. 표현력 부족이 아니라 안정성 부족입니다.
- 랭크 64 이상: 비용 경고 구역. 어댑터 크기는 커지는데 성능 상한은 더 이상 오르지 않습니다.
중요한 해석은 저랭크가 "실패한 구역"이 아니라 "최적화가 덜 된 구역"이라는 것입니다. 적절한 초기화 설계로 랭크 1도 실용적으로 만들 수 있다는 것이 다음 기여입니다.
OLoRA-tail: RL 전용 초기화
기존 SVD 기반 LoRA 초기화(PiSSA, MiLoRA)는 지도 학습에서는 효과적이지만 검증 가능 보상 RL에서는 학습 붕괴를 일으킵니다. 초기 정책 이동이 너무 커서 KL 예산을 소진시키기 때문입니다.
RL에서의 목표 \(J(\theta) = \mathbb{E}_{y \sim \pi_\theta}[R(x,y)]\)를 토큰 수준에서 근사하면
\[\nabla_\theta J(\theta) \approx \mathbb{E}_{y \sim \mu}\left[R(x,y)\sum_{t=1}^T w_t \nabla_\theta \log \pi_\theta(y_t|x,y_{<t})\right], \quad w_t = \frac{\pi_\theta(y_t|x,y_{<t})}{\mu(y_t|x,y_{<t})}\]
이 근사는 롤아웃 정책 \(\mu\)와 업데이트 정책 \(\pi_\theta\)가 가까울 때만 신뢰할 수 있습니다. 초기화가 나쁘면 첫 스텝에서 KL 예산이 터지고 이후 학습이 의미 없어집니다.
Mind Lab이 제안하는 OLoRA-tail은 사전 학습 가중치 행렬 \(W_0 = U\Sigma V^\top\)의 최소 특이값에 대응하는 벡터로 초기화합니다.
\[B_0 = U_{-r}, \quad A_0 = V_{-r}^\top\]
주 특이 방향(기존 표현에서 가장 중요한 방향)은 건드리지 않고, 모델이 가장 덜 민감한 방향에서 조용히 시작합니다. OLoRA(주 특이 방향 사용)는 100 스텝 이후 붕괴하지만 OLoRA-tail은 500 스텝 내내 안정적입니다.
벤치마크 |
LoRA |
OLoRA-tail |
|---|---|---|
GSM8K |
0.754 |
0.756 |
MATH500 |
0.583 |
0.583 |
AIME22 |
0.422 |
0.500 |
AIME23 |
0.422 |
0.563 |
AIME24 |
0.367 |
0.433 |
AIME25 |
0.333 |
0.422 |
평균 |
0.563 |
0.576 |
랭크 1에서는 효과가 더 극적입니다. Qwen3-8B에서 배치 크기 128로 학습할 때 표준 LoRA는 베이스 대비 -18% 성능 하락을 보이지만, OLoRA-tail은 +20%를 유지합니다. Qwen3-30B-A3B에서는 통과율 35.5% 대 24.0%로 11.5%p 차이입니다.
하이퍼파라미터 전이
수백만 개의 어댑터를 운용하는 인프라에서 랭크를 바꿀 때마다 학습률을 재탐색하면 안 됩니다. LoRA의 업데이트는 \(\Delta W = \frac{\alpha_r}{r} BA\)로 정의되므로, 초기 이동 크기는 \(\frac{\alpha_r^2}{r} \eta\)에 비례합니다. \(\alpha_r \propto \sqrt{r}\)로 스케일하면 랭크가 바뀌어도 학습률 탐색 구간이 거의 이동하지 않아 전이가 가능합니다.
Scale Out: 인구 규모의 집단 지성
Scale Out은 "적응 단위가 많아지면 무엇이 더 가능해질까요?"를 묻습니다.
LoRA 메모리 용량 법칙
DishNameBenchmark 실험(263 회 실행)은 LoRA 메모리 용량의 경계를 실증합니다. 훈련 가능 파라미터 대비 메모리 토큰 비율이 \(10^{-3}\) 이하면 정확도가 거의 1.0을 유지하고, \(10^{-2}\) 이상이면 0으로 붕괴합니다. 이 전이 구간이 LoRA 메모리의 실용 용량입니다. 또한 MLP LoRA가 어텐션 LoRA보다 파라미터당 효율이 높습니다.
퍼스널 어댑터와 소셜 시뮬레이션
OASIS 소셜 시뮬레이션에서 사용자당 랭크 4 LoRA 어댑터(\(N \in \{128, 256, 512\}\))를 사용한 실험입니다. 어댑터 없이 하나의 공유 기반 모델만 사용하는 조건과 비교했습니다.
지표 |
\(N=128\) |
\(N=256\) |
\(N=512\) |
|---|---|---|---|
유효 인터랙션 커뮤니티 (LoRA) |
9.21 |
11.77 |
14.85 |
공동 참여 모듈성 (LoRA) |
0.502 |
0.561 |
0.716 |
LoRA vs 베이스: 커뮤니티 비율 |
1.48× |
2.19× |
1.47× |
LoRA vs 베이스: 지지 의견 분산 비율 |
2.28× |
2.18× |
2.45× |
프롬프트로만 페르소나를 정의한 에이전트는 반복 상호작용 속에서 기반 모델의 평균 입장으로 수렴합니다. 어댑터를 통해 각자 다른 정책을 갖는 에이전트 집단은 의견 다양성이 유지되고, 더 풍부한 커뮤니티 구조를 만들어냅니다.
집단 지성: 모델 수 스케일링 법칙
Qwen3-30B를 기반 모델로 두고, 학습 데이터 순서와 마스킹만 다르게 하여 198개의 LoRA 어댑터를 학습합니다. 이 모델들의 답변을 다수결로 집계하면 어떻게 될까요?
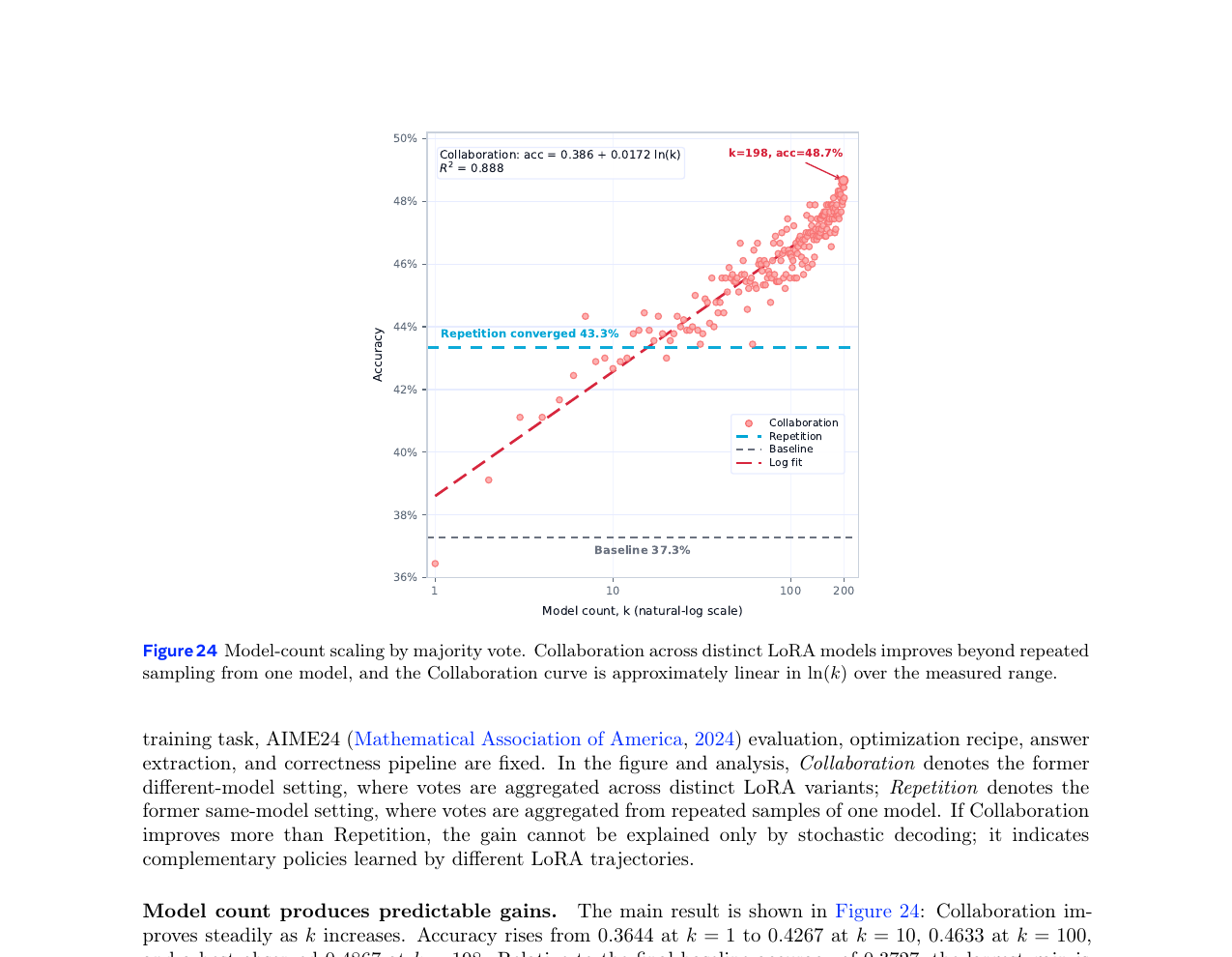
모델 수 \(k\) |
집단 정확도 |
단일 모델 반복 정확도 |
|---|---|---|
1 |
36.44% |
36.44% |
10 |
42.67% |
- |
24 |
- |
43.78% (포화) |
100 |
46.33% |
- |
198 |
48.67% |
- |
집단(Collaboration)은 모델 수가 늘어도 계속 오르지만, 동일 모델 반복 샘플링(Repetition)은 \(k=24\) 부근에서 포화됩니다. 집단 정확도는 \(\ln(k)\)에 선형으로 맞춰집니다.
\[\text{accuracy} \approx 0.386 + 0.0172 \ln(k), \quad R^2 \approx 0.888\]
다양한 LoRA 어댑터들이 서로 다른 실수를 하기 때문에 가능한 결과입니다. 다양성이 단순한 디코딩 노이즈가 아닌 보완적 정책으로 작동한다는 증거입니다.
인프라: MinT
세 축이 실제로 작동하려면 시스템 계층이 필요합니다. MinT(Mind Lab, 2026)는 LoRA 어댑터를 어댑터 파일이 아닌 정책 수명주기 객체로 관리합니다.
핵심 추상화는 정책 기록(Policy Record)입니다. 기반 모델 버전, 어댑터 형태, 훈련 체크포인트 상태, 롤아웃 기록, 그리고 내보낸 어댑터 리비전을 하나의 기록으로 묶습니다. 이를 통해 어댑터를 저장·재개·롤백·평가할 수 있습니다.
서빙은 세 계층으로 나뉩니다. 영구 카탈로그(100만 엔트리 검증), CPU 캐시(512 어댑터 핫셋에서 369 로드), GPU 배치 슬롯(동시 64 어댑터)입니다. MoE LoRA 어댑터를 37,248개 텐서 객체에서 672개로 패킹하면 라이브 엔진 로딩이 8.5~8.7배 빨라집니다.
회고
논문 스스로 한계를 솔직하게 적었습니다.
대부분의 실험이 통제된 벤치마크와 시뮬레이션 규모에서 진행되었습니다. 실제 퍼스널 모델 배포에서의 대규모 실증 검증은 아직 제한적입니다. 논문의 표현을 빌리면 "방법론이 아닌 컴퓨트 용량이 병목"이라고 합니다.
일부 비교(특히 큰 기반 모델 + LoRA vs 작은 기반 모델 + 풀 RL)는 모델 크기와 학습 방법이 동시에 달라지기 때문에 어느 요인이 이득을 만들었는지 분리할 수 없습니다. 논문 자체도 이 점을 주석으로 명시합니다.
열린 문제들도 목록으로 남겨두었습니다: 초소형 어댑터(랭크 1~4)의 안정성을 시드·배치·태스크 변화에도 보장하는 방법, Context Learning의 신호 효율 벤치마크, 어댑터 집단이 장기 상호작용에서도 이질성을 유지할 수 있는지 여부 등입니다.
논문을 재구현 관점에서 읽으면 세 가지 암묵적 전제가 추가로 드러납니다.
첫째, Scale Up·Scale Down·Scale Out이 "의존 사슬"이라는 프레임입니다. 논문은 셋이 동시에 작동해야 한다고 주장하지만, 실제로 각 축은 독립적으로도 가치가 있습니다. 예를 들어 Scale Out(어댑터 집단 지성)은 Scale Down 없이도 구현 가능합니다. 세 축의 의존성을 강조하는 것이 프레임워크의 완결성을 높이는 수사적 선택일 수 있습니다.
둘째, OASIS 소셜 시뮬레이션의 생태적 타당성입니다. 에이전트 528명이 소셜 미디어를 시뮬레이션하는 실험에서 LoRA 어댑터가 의견 다양성을 높인다는 결론을 내립니다. 그러나 LoRA가 다양성을 "유지"하는지, 아니면 초기 설정의 페르소나 이질성을 단순히 "보존"하는지는 구별하기 어렵습니다. 어댑터 없는 조건에서 에이전트가 기반 모델 평균으로 수렴하는 것은 LoRA의 효과이기도 하지만, 프롬프트 설계의 취약성일 수도 있습니다.
셋째, 집단 지성 실험에서 198개 어댑터가 "학습 데이터 순서와 마스킹만 다르게" 훈련됐다는 점입니다. 이는 다양성의 원천이 정책 공간 탐색이 아닌 데이터 노출 순서 차이라는 의미입니다. 실제 사용자 퍼스널 모델의 다양성은 이보다 훨씬 이질적인 피드백 신호에서 비롯될 것이므로, 이 실험이 Scale Out의 최고 잠재력을 보여주지 않을 수 있습니다.
정리
- PEFT는 비용 절감 도구가 아닙니다. Scale Up(강한 기반 모델) + Scale Down(작고 안정적인 어댑터) + Scale Out(지속적 인구)의 세 축이 맞물릴 때 수백만 퍼스널 모델의 기반이 됩니다.
- OLoRA-tail은 RL 학습의 KL 제약을 고려해 최소 특이 방향으로 초기화함으로써, 랭크 1 어댑터도 실용적으로 만듭니다.
- 198개의 다양한 LoRA 어댑터를 다수결로 집계하면 AIME24 정확도가 36.44%에서 48.67%로 오르며, 이득은 \(\ln(k)\)에 선형입니다.