6장 - 서포트 벡터 머신
6장. 서포트 벡터 머신
이번 강의에서는 나이브 베이즈의 마무리로 라플라스 스무딩과 다항 이벤트 모델을 다루고, 머신러닝 알고리즘 적용 전략을 논의한다. 이어서 서포트 벡터 머신(SVM)의 핵심 개념인 함수적 마진, 기하학적 마진, 최적 마진 분류기를 소개한다.
6.1 라플라스 스무딩
나이브 베이즈 알고리즘은 거의 잘 작동하지만, 한 가지 심각한 문제가 있다. 훈련 데이터에 한 번도 등장하지 않은 단어가 테스트 시점에 나타나면 알고리즘이 무너진다는 점이다.
문제 상황
사전에 10,000개의 단어가 있고, NIPS(Neural Information Processing Systems) 학회 이름에 해당하는 단어가 6,017번째라고 하자. 지금까지 받은 이메일 중에 "NIPS"라는 단어가 포함된 이메일이 하나도 없었다면, 최대우도 추정(MLE)으로 구한 매개변수는 다음과 같다.
\[\phi_{6017|y=1} = 0, \quad \phi_{6017|y=0} = 0\]
스팸 이메일에서도, 비스팸 이메일에서도 이 단어가 등장할 확률이 0으로 추정된다. 이제 프로젝트 팀원이 "NIPS 학회에 논문을 제출하자"라는 이메일을 보내면 어떻게 될까?
\[P(y=1 \mid x) = \prod_{j=1}^{n} P(x_j \mid y) \cdot P(y)\]
이 곱셈에서 \(P(x_{6017} \mid y=1) = 0\)이므로 전체 결과가 0이 된다. 마찬가지로 \(P(y=0 \mid x)\)도 0이 된다. 최종적으로 \(\frac{0}{0+0}\)이라는 정의되지 않는 값이 나온다.
통계적으로, 단순히 아직 관찰하지 못했다는 이유만으로 어떤 사건의 확률을 0으로 추정하는 것은 바람직하지 않다.
라플라스의 해법
라플라스 스무딩(Laplace smoothing)은 이 문제를 해결하기 위한 기법이다. 직관적인 예시로 설명하겠다.
몇 년 전 스탠퍼드 풋볼 팀의 원정 경기 성적을 추적한 적이 있다. 그해 원정 경기 결과는 다음과 같았다.
날짜 |
상대 |
결과 |
|---|---|---|
9/12 |
Wake Forest |
패배 |
10/10 |
Oregon State |
패배 |
- |
Arizona |
패배 |
- |
Caltech |
패배 |
4연패 후 다음 경기의 승리 확률을 최대우도 추정으로 구하면 다음과 같다.
\[P(\text{승리}) = \frac{\text{승리 횟수}}{\text{승리 횟수} + \text{패배 횟수}} = \frac{0}{0 + 4} = 0\]
4번 졌다고 해서 승리 확률이 정확히 0이라고 단정하는 것은 지나치다.
라플라스 스무딩에서는 각 가능한 결과의 관찰 횟수에 1을 더한다.
\[P(\text{승리}) = \frac{0 + 1}{(0 + 1) + (4 + 1)} = \frac{1}{6}\]
이것이 훨씬 합리적인 추정이다. 라플라스는 역사적으로 "내일 해가 뜰 확률"을 추정하는 데 이 방법을 사용했다. 해가 뜨는 것을 10,000번 관찰했더라도 내일도 반드시 뜬다고 절대적으로 확신할 수는 없다는 논리였다.
일반화된 공식
\(k\)개의 가능한 값을 가지는 확률 변수에 대해, 라플라스 스무딩을 적용한 추정은 다음과 같다.
\[P(X = i) = \frac{\text{(}X = i\text{인 관찰 횟수)} + 1}{\text{(전체 관찰 횟수)} + k}\]
분자에 1을 더하고, 분모에 가능한 결과의 수 \(k\)를 더한다.
나이브 베이즈에의 적용
나이브 베이즈의 매개변수 추정에 라플라스 스무딩을 적용하면 다음과 같다.
\[\phi_{j|y=0} = \frac{\sum_{i=1}^{m} \mathbf{1}\{x_j^{(i)} = 1 \wedge y^{(i)} = 0\} + 1}{\sum_{i=1}^{m} \mathbf{1}\{y^{(i)} = 0\} + 2}\]
분자에 1을, 분모에 2를 더한다(이진 변수이므로 \(k=2\)). 이렇게 하면 추정된 확률이 정확히 0이나 정확히 1이 되는 일이 없어져서, 앞서 설명한 \(\frac{0}{0}\) 문제가 사라진다.
이 알고리즘은 최고 성능의 스팸 분류기는 아니지만, 나쁘지도 않다. 매개변수 추정이 단순히 세기(counting)만으로 이루어지므로 계산적으로 매우 효율적이고, 분류 시에는 확률값들을 곱하기만 하면 된다.
6.2 다항 이벤트 모델
지금까지 다룬 나이브 베이즈에서는 특성이 이진값(0 또는 1)이었다. 이를 **다변량 베르누이 모델(Multivariate Bernoulli Model)**이라 부른다. 사전에 10,000개의 단어가 있으면 10,000개의 베르누이 확률 변수가 있는 셈이다.
연속 특성의 이산화
나이브 베이즈를 연속 특성에 적용하려면 특성을 이산화(discretize)할 수 있다. 예를 들어 주택이 30일 이내에 팔릴지 분류하는 문제에서, 면적을 다음과 같이 구간으로 나눌 수 있다.
구간 |
값 |
|---|---|
400 sq ft 미만 |
1 |
400~800 sq ft |
2 |
800~1,200 sq ft |
3 |
1,200 sq ft 초과 |
4 |
이 경우 \(P(x_j \mid y)\)는 베르누이 분포 대신 4개의 결과를 가지는 다항 분포가 된다. 실무에서 변수를 이산화할 때는 보통 10개의 구간으로 나누는 것이 일반적인 경험 법칙이다.
텍스트 분류를 위한 새로운 표현
다변량 베르누이 모델에는 한 가지 약점이 있다. "Drugs, buy drugs now"라는 이메일에서 "drugs"라는 단어가 두 번 등장했지만, 이진 표현에서는 이 정보가 사라진다. 단어의 등장 여부만 기록하고, 등장 횟수는 무시하기 때문이다.
**다항 이벤트 모델(Multinomial Event Model)**은 다른 표현 방식을 사용한다. 이메일을 고정 길이의 이진 벡터 대신, 이메일의 단어 수만큼의 길이를 가지는 벡터로 표현한다. 각 원소는 해당 위치에 있는 단어의 사전 인덱스다.
예를 들어 "Drugs, buy drugs now"라는 이메일에서 buy가 800번, drugs가 1,600번, now가 6,200번 단어라면:
- 다변량 베르누이: 10,000차원 벡터, 800번, 1,600번, 6,200번 위치에 1
- 다항 이벤트 모델: 4차원 벡터 \(x = [1600, 800, 1600, 6200]\)
다항 이벤트 모델에서 \(n\)은 이메일의 길이(단어 수)이며 이메일마다 다르다. 긴 이메일은 특성 벡터가 길고, 짧은 이메일은 짧다.
모델의 수학적 구조
나이브 베이즈 가정 아래에서 생성 모델은 다음과 같다.
\[P(x, y) = P(y) \cdot \prod_{j=1}^{n} P(x_j \mid y)\]
수식의 형태는 다변량 베르누이 모델과 동일해 보이지만, 핵심적인 차이가 있다.
- \(n\): 10,000(사전 크기)이 아니라 이메일의 단어 수
- \(P(x_j \mid y)\): 베르누이 확률이 아니라 다항 확률(1~10,000 중 하나)
- 위치에 무관한 가정: 이메일의 첫 번째 위치에 "drugs"가 올 확률과 세 번째 위치에 올 확률이 같다고 가정
매개변수 \(\phi_{k|y=0}\)는 "비스팸 이메일의 모든 단어 중에서 \(k\)번째 단어가 차지하는 비율"로 추정한다.
\[\phi_{k|y=0} = \frac{\sum_{i=1}^{m} \mathbf{1}\{y^{(i)}=0\} \sum_{j=1}^{n_i} \mathbf{1}\{x_j^{(i)}=k\}}{\sum_{i=1}^{m} \mathbf{1}\{y^{(i)}=0\} \cdot n_i}\]
분모는 비스팸 이메일에 포함된 전체 단어 수이고, 분자는 그 중 \(k\)번째 단어가 등장한 횟수다. 예를 들어 비스팸 이메일에 총 100,000개의 단어가 있고 그 중 "drugs"가 200번 등장했다면 \(\phi_{\text{drugs}|y=0} = \frac{200}{100{,}000}\)이 된다.
라플라스 스무딩을 적용하면 분자에 1을, 분모에 10,000(사전 크기)을 더한다.
미등록 단어 처리
사전에 없는 단어를 만났을 때는 두 가지 방법이 있다.
- 무시하기: 해당 단어를 그냥 버린다.
- UNK 토큰: 사전에 없는 모든 단어를 "UNK(unknown)"라는 특수 토큰으로 매핑한다. 상위 10,000개 단어만 사전에 넣고 나머지는 모두 UNK로 처리하는 방식이다.
6.3 머신러닝 알고리즘 적용 전략
나이브 베이즈 알고리즘은 대부분의 문제에서 로지스틱 회귀보다 정확도가 낮다. 그러나 계산적으로 매우 효율적이고 구현이 간단하다는 장점이 있다. 반복적인 경사 하강법이 필요 없으며, 코드 양도 적다. 빠르게 프로토타입을 만들어야 할 때 합리적인 선택이 될 수 있다.
빠르게 시작하고, 반복적으로 개선하라
응용 프로젝트에서 가장 중요한 조언은 다음과 같다. 처음부터 가장 복잡한 알고리즘을 구현하려 하지 말고, 빠르고 단순한 것부터 시작하라.
10,000줄짜리 프로그램을 작성할 때 먼저 10,000줄을 전부 쓴 다음 처음으로 컴파일하는 사람은 없다. 작은 모듈을 작성하고, 실행하고, 테스트한 다음 점진적으로 확장한다. 머신러닝도 마찬가지다.
단순한 알고리즘을 먼저 구현하고 훈련시킨 후, 잘못 분류하는 예제를 분석하여 개선 방향을 결정해야 한다. 이를 **오류 분석(error analysis)**이라 한다.
스팸 필터 사례
스팸 분류기를 개선하려 할 때, 잠재적으로 투자할 수 있는 방향이 여러 가지 있다.
- 의도적 오타 처리: 스패머가 "mortgage"를 "m0rtg@ge"로 쓰는 등의 변형을 원래 단어로 복원
- 이메일 헤더 분석: 발신자 정보 위조를 탐지
- URL 분석: 이메일에 포함된 링크의 웹페이지를 가져와 분석
이 각각의 주제가 3~6개월의 연구가 될 수 있다. 어디에 시간을 투자해야 할지 어떻게 알 수 있을까? 답은 간단하다. 먼저 기본 알고리즘을 구현하고, 오분류되는 예제를 살펴보라. 의도적 오타로 인한 오분류가 많다면 그 문제를 해결하는 것이 가치 있다. 그렇지 않다면 다른 곳에 시간을 투자하라.
GDA와 나이브 베이즈의 위치
최고의 분류 정확도가 필요하다면 로지스틱 회귀, SVM, 신경망 같은 알고리즘이 거의 항상 GDA나 나이브 베이즈보다 높은 정확도를 제공한다. 그러나 GDA와 나이브 베이즈의 장점은 다음과 같다.
- 훈련이 빠르다: 반복적 최적화 없이 단순 계산(세기, 평균과 공분산 계산)만으로 매개변수를 추정
- 구현이 간단하다: 코드가 적고 디버깅이 쉬움
따라서 프로젝트를 시작할 때 로지스틱 회귀나 나이브 베이즈 같은 단순한 알고리즘부터 시작하여 기준선(baseline)을 세우고, 그 성능을 분석한 후 더 복잡한 알고리즘으로 나아가는 것이 효율적이다.
6.4 서포트 벡터 머신 개요
이제 완전히 다른 유형의 분류기인 **서포트 벡터 머신(Support Vector Machine, SVM)**으로 넘어간다.
비선형 결정 경계의 필요성
데이터가 다음과 같이 분포한다고 하자. 양성 예제와 음성 예제가 직선으로는 분리할 수 없는 복잡한 패턴을 이루고 있다. 이런 데이터에 대해 매우 비선형적인 결정 경계를 찾는 알고리즘이 필요하다.
한 가지 방법은 로지스틱 회귀에 고차원 특성을 추가하는 것이다. 원래 특성 벡터 \((x_1, x_2)\)를 다음과 같이 확장한다.
\[\phi(x) = (x_1,\; x_2,\; x_1^2,\; x_2^2,\; x_1 x_2,\; x_1^3,\; x_2^3,\; \ldots)\]
이 확장된 특성 벡터에 로지스틱 회귀를 적용하면 타원 형태의 결정 경계를 학습할 수 있다. 그러나 어떤 특성을 추가해야 원하는 형태의 결정 경계를 얻을 수 있는지 미리 알기 어렵다.
서포트 벡터 머신은 입력 특성 \((x_1, x_2)\)를 훨씬 더 고차원의 특성 공간으로 매핑한 후 선형 분류기를 적용하는데, 그 고차원이 \(\mathbb{R}^5\)가 아니라 \(\mathbb{R}^{100{,}000}\)이거나 심지어 무한 차원일 수도 있다. **커널(kernel)**이라는 기법이 이를 가능하게 한다.
SVM의 장점
SVM은 비교적 턴키(turn-key) 알고리즘이다. 즉, 조정해야 할 하이퍼파라미터가 적다. 로지스틱 회귀나 선형 회귀에서는 학습률 \(\alpha\)를 조정해야 하지만, SVM은 성숙한 소프트웨어 패키지를 다운받아 그대로 실행하면 세부 사항을 크게 걱정하지 않아도 수렴한다.
오늘날 많은 문제에서 신경망이 SVM보다 효과적이지만, SVM의 이런 턴키 특성은 여전히 가치가 있다.
학습 로드맵
SVM을 이해하기 위한 단계는 다음과 같다.
- 최적 마진 분류기: 선형 분리 가능한 데이터에 대한 기본 구성 요소 (이번 장)
- 커널: 저차원 특성을 고차원(또는 무한 차원) 특성 공간으로 매핑하는 기법 (다음 장)
- 비분리 가능 데이터 처리: 선형 분리가 불가능한 데이터에 대한 확장 (다음 장)
6.5 SVM의 표기법
SVM을 개발하기 위해 표기법을 약간 변경한다.
클래스 레이블
로지스틱 회귀에서는 \(y \in \{0, 1\}\)을 사용했지만, SVM에서는 다음을 사용한다.
\[y \in \{-1, +1\}\]
가설 함수
로지스틱 회귀처럼 확률을 출력하는 대신, SVM은 \(-1\) 또는 \(+1\)을 직접 출력한다.
\[g(z) = \begin{cases} +1 & \text{if } z \geq 0 \\ -1 & \text{otherwise} \end{cases}\]
부드러운 전이(0에서 1로) 대신 \(-1\)에서 \(+1\)로의 급격한 전이가 이루어진다.
매개변수 분리
로지스틱 회귀에서는 \(\theta \in \mathbb{R}^{n+1}\)과 \(x_0 = 1\)을 사용했지만, SVM에서는 매개변수를 \(w\)와 \(b\)로 분리한다.
\[h_{w,b}(x) = g(w^T x + b)\]
여기서 \(w \in \mathbb{R}^n\), \(b \in \mathbb{R}\)이며 \(x_0 = 1\)이라는 더미 특성을 쓰지 않는다. 직관적으로, 기존의 \(\theta = (\theta_0, \theta_1, \theta_2, \ldots, \theta_n)\)에서 \(b = \theta_0\)이고 \(w = (\theta_1, \theta_2, \ldots, \theta_n)\)이다.
\[w^T x + b = \sum_{i=1}^{n} w_i x_i + b\]
6.6 함수적 마진
동기: 로지스틱 회귀에서의 확신도
로지스틱 회귀를 이진 분류기로 사용할 때, \(\theta^T x > 0\)이면 1을, \(\theta^T x < 0\)이면 0을 예측한다. 이때 \(\theta^T x\)의 크기가 클수록 분류기가 더 확신을 가지고 예측한다고 볼 수 있다.
- \(y^{(i)} = 1\)일 때: \(\theta^T x^{(i)} \gg 0\)이길 바란다 (매우 확신 있는 올바른 예측)
- \(y^{(i)} = 0\)일 때: \(\theta^T x^{(i)} \ll 0\)이길 바란다
SVM 표기법에서 이를 다시 쓰면:
- \(y^{(i)} = +1\)일 때: \(w^T x^{(i)} + b \gg 0\)이길 바란다
- \(y^{(i)} = -1\)일 때: \(w^T x^{(i)} + b \ll 0\)이길 바란다
정의
초평면(hyperplane) \(w, b\)에 대한 훈련 예제 \((x^{(i)}, y^{(i)})\)의 **함수적 마진**은 다음과 같다.
\[\hat{\gamma}^{(i)} = y^{(i)} (w^T x^{(i)} + b)\]
\(y^{(i)} = +1\)이면 \(w^T x^{(i)} + b\)가 큰 양수이길 바라고, \(y^{(i)} = -1\)이면 큰 음수이길 바란다. 어느 경우든 \(\hat{\gamma}^{(i)}\)가 크다는 것은 분류기가 해당 예제를 정확하고 확신 있게 분류한다는 뜻이다.
중요한 성질로, \(\hat{\gamma}^{(i)} > 0\)이면 알고리즘이 해당 예제를 올바르게 분류하고 있음을 의미한다.
훈련 세트의 함수적 마진
전체 훈련 세트에 대한 함수적 마진은 최악의 경우 개념을 사용한다.
\[\hat{\gamma} = \min_{i=1,\ldots,m} \hat{\gamma}^{(i)}\]
가장 어려운 예제에서의 함수적 마진이 전체 훈련 세트의 함수적 마진이 된다.
함수적 마진의 한계: 스케일링 문제
함수적 마진에는 치명적인 약점이 있다. \(w\)와 \(b\)를 모두 2배로 곱하면 함수적 마진도 2배가 되지만, 결정 경계는 전혀 변하지 않는다. 10배를 곱하면 함수적 마진이 10배가 되지만 분류 결과는 동일하다. 즉, 매개변수의 스케일을 조정하는 것만으로 함수적 마진을 임의로 부풀릴 수 있다.
이 문제를 해결하기 위해 \(\|w\| = 1\)이라는 정규화 조건을 부과하거나, \(w\)와 \(b\)를 \(\|w\|\)로 나누어 정규화할 수 있다. 이 정규화는 분류 결과를 변경하지 않으면서 스케일링을 통한 부풀리기를 방지한다. 실제로 \(w\)와 \(b\)를 임의의 상수로 나누어도 결정 경계와 분류 결과는 동일하게 유지된다.
6.7 기하학적 마진
기하학적 마진은 함수적 마진의 스케일링 문제를 해결하며, 결정 경계와 훈련 예제 사이의 실제 유클리드 거리를 측정한다.
직관
매개변수 \(w\)와 \(b\)가 정의하는 선형 분류기를 생각하자. \(w^T x + b = 0\)이라는 방정식이 결정 경계(직선, 또는 고차원에서 초평면)를 정의한다.
- 한쪽: \(w^T x + b > 0\) (양성 예측 영역)
- 반대쪽: \(w^T x + b < 0\) (음성 예측 영역)
양성 훈련 예제 \((x^{(i)}, y^{(i)})\)가 양성 영역에 있다면, 이 예제에서 결정 경계까지의 유클리드 거리가 기하학적 마진이다.
정의
\[\gamma^{(i)} = y^{(i)} \left( \frac{w^T x^{(i)} + b}{\|w\|} \right)\]
기하학적 마진은 함수적 마진을 \(\|w\|\)로 나눈 것이다.
\[\gamma^{(i)} = \frac{\hat{\gamma}^{(i)}}{\|w\|}\]
\(\|w\|\)로 나누기 때문에, 매개변수 스케일링의 영향을 받지 않는다. 이것이 기하학적 마진의 핵심적인 장점이다.
훈련 세트의 기하학적 마진
함수적 마진과 마찬가지로 최악의 경우를 사용한다.
\[\gamma = \min_{i=1,\ldots,m} \gamma^{(i)}\]
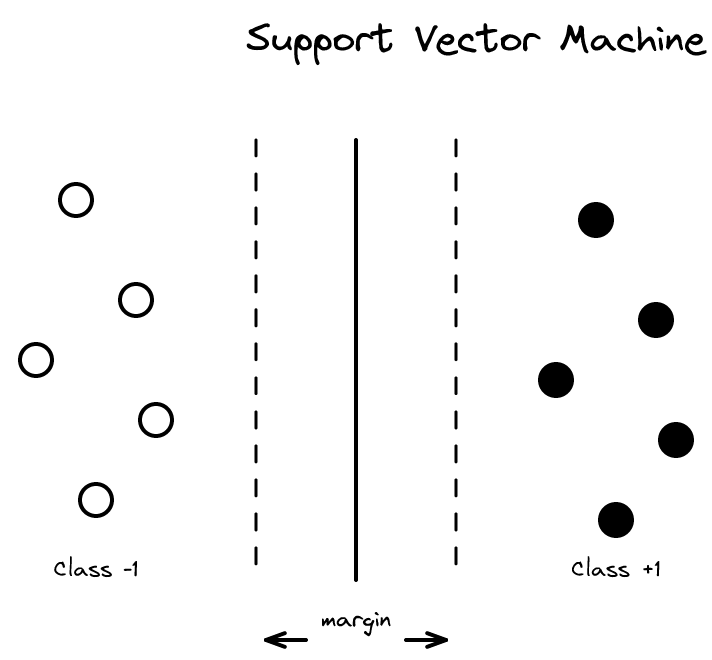
직선의 선택: 빨간 선 vs 초록 선
선형 분리 가능한 데이터에서, 양성과 음성 예제를 올바르게 분리하는 직선은 무수히 많다. 하지만 모든 직선이 동등하지는 않다.
예를 들어, 빨간 직선은 양성과 음성 예제를 분리하지만 일부 훈련 예제에 매우 가깝게 지나간다. 반면 초록 직선은 양쪽 예제로부터 모두 큰 거리를 유지하며 분리한다. 초록 직선이 더 큰 기하학적 마진을 가지며, 직관적으로도 더 좋은 분류기다.
6.8 최적 마진 분류기
**최적 마진 분류기(optimal margin classifier)**는 기하학적 마진을 최대화하는 \(w\)와 \(b\)를 찾는 알고리즘이다. 이것이 선형 분리 가능한 데이터에 대한 기본 SVM이다.
최적화 문제의 정식화
기하학적 마진을 최대화하는 문제를 수학적으로 쓰면 다음과 같다.
\[\max_{w, b} \gamma\]
\[\text{subject to} \quad \gamma^{(i)} \geq \gamma, \quad i = 1, \ldots, m\]
모든 훈련 예제의 기하학적 마진이 \(\gamma\) 이상이어야 하며, 이 \(\gamma\)를 가능한 한 크게 하고 싶다. 이것은 최악의 경우 기하학적 마진을 최대화하는 문제와 동치다.
동치 변환
이 형태는 직접 풀기 어려운 비볼록 최적화 문제다. 그러나 매개변수 스케일링의 자유도를 활용하여, 강의 노트에서 보이듯이 몇 단계의 변환을 거치면 다음과 동치인 볼록 최적화 문제로 재정식화할 수 있다.
\[\min_{w, b} \frac{1}{2} \|w\|^2\]
\[\text{subject to} \quad y^{(i)}(w^T x^{(i)} + b) \geq 1, \quad i = 1, \ldots, m\]
직관적으로 \(\|w\|\)가 작을수록 기하학적 마진 \(\gamma = \frac{\hat{\gamma}}{\|w\|}\)가 커진다. 따라서 \(\|w\|\)를 최소화하는 것이 기하학적 마진을 최대화하는 것과 같다.
볼록 최적화
이 문제는 볼록 최적화 문제(구체적으로는 이차 계획법, Quadratic Programming)이며, 효율적인 수치 최적화 패키지로 풀 수 있다. 데이터가 선형 분리 가능하다면, 이 문제를 풀어서 최적 마진 분류기를 얻을 수 있다.
최적 마진 분류기에 커널을 추가하면 완전한 SVM이 된다. 비분리 가능 데이터에 대한 처리와 커널 기법은 다음 장에서 다룬다.
핵심 정리
개념 |
핵심 |
|---|---|
라플라스 스무딩 |
관찰되지 않은 사건의 확률을 0으로 추정하는 문제를 방지. 분자에 1, 분모에 \(k\)를 더함 |
다항 이벤트 모델 |
단어의 등장 횟수를 반영하는 나이브 베이즈 변형. 텍스트 분류에 더 적합 |
오류 분석 |
단순한 알고리즘을 먼저 구현하고, 오분류 예제를 분석하여 개선 방향 결정 |
함수적 마진 |
\(\hat{\gamma}^{(i)} = y^{(i)}(w^Tx^{(i)} + b)\). 매개변수 스케일에 의존하는 약점 |
기하학적 마진 |
\(\gamma^{(i)} = \frac{\hat{\gamma}^{(i)}}{\|w\|}\). 결정 경계까지의 실제 유클리드 거리 |
최적 마진 분류기 |
\(\min \frac{1}{2}\|w\|^2\) s.t. \(y^{(i)}(w^Tx^{(i)}+b) \geq 1\). 기하학적 마진을 최대화하는 볼록 최적화 문제 |
SVM의 장점 |
턴키 알고리즘 — 조정할 하이퍼파라미터가 적고, 커널을 통해 무한 차원 특성 공간 활용 가능 |
이전 장: 5장 - GDA와 나이브 베이즈 다음 장: 7장 - 커널