OmniNFT - Modality-wise Omni Diffusion Reinforcement for Joint Audio-Video Generation
G. Zhang, X. Ma, J. Huang, H. Xu, H. Yu, S. Fu, Y. Li, Z. Xue, L. Song, H. Huang, N. Duan, and F. Zhao, "OmniNFT: Modality-wise Omni Diffusion Reinforcement for Joint Audio-Video Generation," arXiv:2605.12480, 2026.
Sora·Veo 3·Movie Gen 흐름을 지나오면서 비디오 생성의 표면이 빠르게 매끄러워졌습니다. 그러나 영상은 영상대로, 음향은 음향대로 만들고 나중에 붙이는 후반 작업 방식이 깨지기 시작한 단계가 바로 joint audio-video generation 흐름입니다. Google DeepMind의 Veo 3, Lightricks의 LTX-2, JavisDiT++ 같은 모델이 영상과 음향을 동시에 생성하기 시작했고, 이제는 영상 품질만 좋은 게 아니라 입 모양과 발화가 맞는가, 물체가 움직일 때 적절한 사운드 텍스처가 따라붙는가를 같이 만족해야 하는 시대로 넘어가고 있습니다.
본 글에서 다루는 OmniNFT는 그 흐름 위에 RL fine-tuning을 깔끔하게 얹는 방법을 제안한 USTC + JD Explore Academy 합작입니다. 핵심은 단순합니다. joint audio-video diffusion에 vanilla GRPO를 그대로 가져가면 왜 잘 안 되는가를 세 가지 mismatch로 분해하고, 각각에 대응되는 세 가지 디자인을 modality 단위로 끼워 넣은 것입니다.
저자
USTC + JD Explore Academy 합작 라인업입니다. 1저자 장궈후이은 USTC 자오펑 연구실 박사과정으로, MaskFocus(2025)·Group Critical-Token Policy Optimization(2025) 등 image generation에서 정책 최적화를 critical 영역에 집중시킨다는 연구를 이어온 사람입니다. 본 논문의 region-wise loss reweighting은 그 발상의 연장입니다.
교신 저자 자오펑는 USTC 자동화학과 정교수로 컴퓨터 비전·멀티모달 모델 연구 그룹을 이끌고 있습니다. 같은 연구실에서 위후, Xiaoxiao Ma, Jie Huang, Hang Xu가 함께 OmniNFT에 이름을 올렸습니다.
산업 랩 측에서는 송린이 project leader로 들어왔습니다. CVPR 2024 YOLO-World의 공동·교신 저자로 알려진 비전 연구자입니다. 시니어 라인의 두안난은 JD Explore Academy Vision and Multimodal Lab 디렉터로, 마이크로소프트 리서치 아시아 NLP 그룹과 StepFun을 거쳐 합류한 인물입니다. 19B 규모 LTX-2 backbone에 RL fine-tuning을 도는 컴퓨트 무거운 셋업이라, 학교 측 RL 연구 라인과 산업 측 인프라·데이터가 맞물려야 굴러가는 구조가 자연스럽게 만들어졌습니다.
배경
영상 + 음향 동시 생성에서 현실적으로 만족해야 하는 요구는 셋입니다.
- per-modality fidelity — 영상 따로, 음향 따로 봐도 품질이 나와야 합니다
- cross-modal alignment — 텍스트 프롬프트와 영상·음향이 의미적으로 맞아야 합니다
- fine-grained synchronization — 발화 입 모양과 소리, 충돌 시점과 효과음이 시간축에서 맞아야 합니다
세 요구를 동시에 다 잘하기 어려워서 LLM 쪽에서 등장한 RL with Verifiable Rewards(RLVR), 그 중에서도 GRPO 계열이 비주얼 생성에서도 post-training 표준으로 자리잡는 흐름이 있었습니다. DanceGRPO, Flow-GRPO, DiffusionNFT가 이미지·비디오 생성에 GRPO를 적용했고 어느 정도 효과를 봤습니다.
그런데 OmniNFT 저자들은 이 흐름을 joint audio-video로 그대로 가져갈 때 어디서 무너지는지를 먼저 따지고 시작합니다. 그 분석이 본 논문에서 가장 단단한 부분입니다.
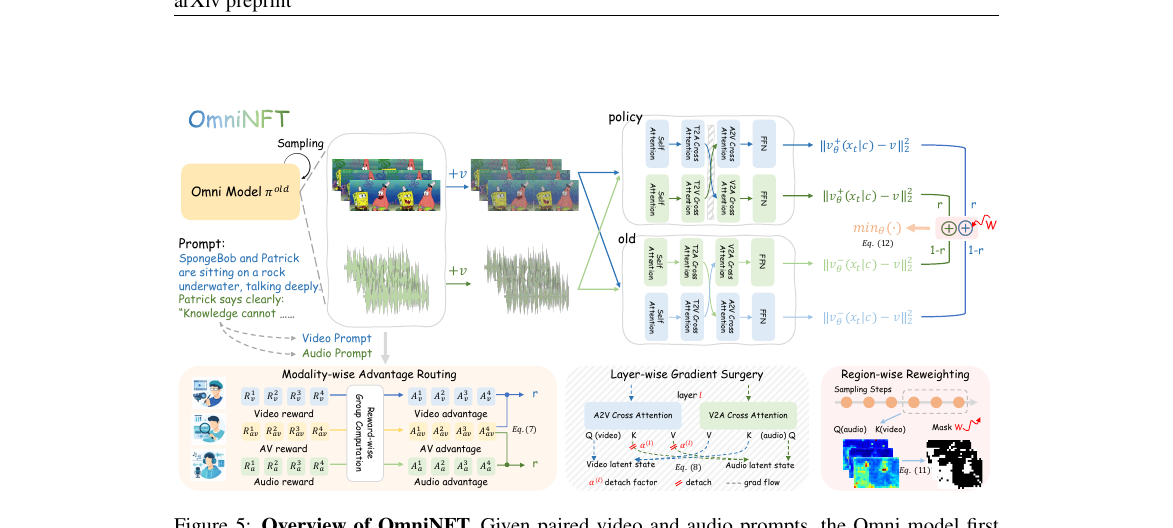
위 그림이 OmniNFT의 전체 파이프라인입니다. Modality-wise Advantage Routing에서 보상별 advantage를 modality별로 따로 계산해 분배하고, Layer-wise Gradient Surgery에서 video branch gradient가 audio shallow layer로 새는 것을 막고, Region-wise Reweighting에서 V2A cross-attention map을 끌어와 visual loss에 region-wise 가중치를 곱하는 흐름입니다.
어떻게 만들었나
저자들은 vanilla GRPO를 joint audio-video diffusion에 직접 적용해보고 다음 세 가지 optimization mismatch를 발견합니다.
- advantage inconsistency — 한 sample의 video advantage와 audio advantage가 거의 무상관에 가깝습니다. 175개 prompt × group size 8 = 1,400개 sample 분석에서 약 절반이 video와 audio의 advantage가 반대 방향이었습니다. 둘을 합해서 global advantage 하나로 만들면 영상은 좋고 음향은 별로인 sample과 영상은 별로고 음향은 좋은 sample이 서로를 상쇄해 학습 신호가 dilute됩니다.
- gradients imbalance — dual-stream Transformer의 shallow layer는 intra-modal generation(영상은 영상답게, 음향은 음향답게)을 담당하고, middle-to-deep layer가 cross-modal interaction(AV-Sync Zone)을 담당한다는 게 forward·backward ablation으로 드러납니다. 문제는 deep layer의 cross-modal gradient가 shallow audio layer로 새서 영상 reward가 음향 intra-modal layer를 오염시키는 현상이 일어난다는 점입니다.
- uniform credit assignment — 발화 입 모양, 사운드 소스 위치 같은 fine-grained sync에 결정적인 영역과 배경처럼 덜 중요한 영역이 같은 가중치로 업데이트됩니다. critical 영역이 충분한 탐색을 못 받아 sync 품질이 낮은 평형에 갇힙니다.
OmniNFT는 이 세 문제에 1:1로 대응하는 세 디자인을 더합니다.
Modality-wise advantage routing. 보상 함수를 video reward, audio reward, AV reward 셋으로 분리합니다. video reward는 VideoAlign + HPSv3, audio reward는 Audiobox Aesthetics + CLAP, AV reward는 Synchformer 기반 DeSync입니다. 각 reward에서 group-wise advantage를 따로 계산한 뒤, video advantage(A_v)는 video branch로, audio advantage(A_a)는 audio branch로, AV advantage(A_av)는 두 branch에 broadcast해서 routing합니다. 식으로는 Ã_v = A_v + A_av, Ã_a = A_a + A_av입니다.
Layer-wise gradient surgery. dual-stream Transformer의 A2V cross-attention에서 audio hidden state로부터 가져오는 KV에 대해, shallow layer(블록 인덱스 l < L = 10)에서는 stop-gradient를 부분적으로 걸어줍니다. 구체적으로 α_s = 0.1만큼 detach하고 나머지(1 − α_s)만 backward로 흘립니다. deep layer는 그대로 둡니다. shallow는 intra-modal generation 담당이니 video reward의 gradient가 새지 않도록 막고, deep는 cross-modal 담당이니 RL signal이 제대로 흐르게 하는 것입니다.
Region-wise loss reweighting. V2A cross-attention map을 공짜로 얻는 region detector로 활용합니다. deep block(l ≥ L)의 후반 denoising step에서 V2A attention을 평균 내면 발화하는 인물의 입 주변, 소리를 내는 물체 같은 영역이 자연스럽게 강조됩니다. 이 attention score s_i를 정규화해서 w_i = 1 + λ·(s_i − min)/(max − min) 식으로 region-wise weight를 만들고, video branch loss에 곱해 critical 영역에 정책 업데이트를 더 집중시킵니다. λ는 1.50이 default입니다.
학습 자체는 LTX-2 19B backbone에 DiffusionNFT(forward process 위에서 정책 최적화하는 GRPO 변종) 형태로 얹습니다. JavisBench와 VBench를 평가 benchmark로 씁니다.
결과
가장 강한 비교는 같은 backbone에 vanilla RL(GDPO 포함)을 얹은 경우 대비입니다. JavisBench 주요 수치를 표로 정리합니다.
모델 |
파라미터 |
VQ ↑ |
AQ ↑ |
TA-IB ↑ |
CLAP ↑ |
AVHScore ↑ |
JavisScore ↑ |
DeSync ↓ |
|---|---|---|---|---|---|---|---|---|
LTX-2 |
19B |
2.038 |
5.197 |
0.170 |
0.412 |
0.223 |
0.192 |
0.569 |
LTX-2 + GDPO |
19B |
3.209 |
5.523 |
0.184 |
0.428 |
0.223 |
0.185 |
0.412 |
LTX-2 + OmniNFT |
19B |
3.326 |
5.715 |
0.189 |
0.445 |
0.257 |
0.220 |
0.269 |
핵심 변화를 요약하면 다음과 같습니다.
- per-modality fidelity: VQ +1.288(2.038 → 3.326, +63.2%), AQ +0.518(5.197 → 5.715, +10.0%)
- cross-modal alignment: TA-IB +15.2%, CLAP +0.033
- synchronization: DeSync 0.569 → 0.269로 −52.7%, GDPO(0.412)보다도 큰 폭으로 개선
- VBench imaging quality에서도 +10.5%
저자가 솔직히 짚는 한계도 같이 봅니다. TV-IB(text-video ImageBind)와 CLIP score는 OmniNFT뿐 아니라 GDPO에서도 개선되지 않습니다. text–video semantic alignment는 여전히 어렵다는 게 본인들 결론입니다. 본 논문의 reward에 text–video 의미 일관성을 직접 잡아주는 항이 없는 영향도 있어 보입니다.
Ablation도 깔끔합니다. vanilla RL에서 시작해 세 디자인을 누적으로 더해갑니다.
Setting |
VQ ↑ |
AQ ↑ |
TA-IB ↑ |
AVHScore ↑ |
JavisScore ↑ |
DeSync ↓ |
Time |
|---|---|---|---|---|---|---|---|
LTX-2 baseline |
2.038 |
5.197 |
0.170 |
0.223 |
0.192 |
0.569 |
– |
|
3.209 |
5.523 |
0.184 |
0.223 |
0.185 |
0.412 |
23.9h |
|
3.264 |
5.399 |
0.186 |
0.240 |
0.199 |
0.322 |
23.9h |
|
3.246 |
5.917 |
0.192 |
0.247 |
0.209 |
0.334 |
24.1h |
|
3.326 |
5.715 |
0.189 |
0.257 |
0.220 |
0.269 |
24.1h |
세 디자인을 다 켰을 때 AQ가 5.917에서 5.715로 살짝 내려가는 구간이 보입니다(layer-wise gradient surgery 단계 → full 단계). 저자들은 region-wise reweighting이 video loss를 강하게 만들면서 audio가 일부 양보된다는 식의 trade-off로 해석할 수 있는 지점입니다. 다만 다른 지표(AVHScore, JavisScore, DeSync, TA-IB, CLAP)가 모두 best로 개선되니 full setup이 종합 우위라는 결론은 유지됩니다.
Hyperparameter 분석에서는 gradient surgery를 *shallow layer(L < 10)*에 거는 것이 *deep layer(L > 20)*에 거는 것보다 모든 지표에서 우위였습니다. region-wise λ도 1.50이 sweet spot으로, 더 작으면 critical 영역 강조가 약하고 더 크면 visual quality가 흔들립니다.
회고
본 논문은 별도 limitation 섹션이나 Appendix 회고가 없습니다. 대신 본문에서 저자들이 솔직하게 인정한 부분이 두 가지입니다.
첫째, text–video semantic alignment(TV-IB, CLIP)는 OmniNFT가 해결하지 못했습니다. 저자들은 이를 challenging이라고 표현했고, 본 논문에서 새로 도입한 reward(VideoAlign, HPSv3, Audiobox Aesthetics, CLAP, DeSync) 중 어떤 것도 text–video 의미 정합을 직접 학습 신호로 잡아주지 않는다는 점이 그대로 드러나는 결과입니다. 향후 작업에서 text-video reward를 추가하면 자연스럽게 메울 수 있어 보입니다.
둘째, AQ-VQ trade-off의 존재입니다. ablation에서 Layer-wise gradient surgery 단계가 AQ를 5.917로 끌어올렸는데, region-wise reweighting을 켜면서 5.715로 내려옵니다. 비디오 loss를 강하게 만든 영향이 audio side로 일정 부분 전가된 것으로 해석됩니다. 영상에 맞춰지는 RL signal이 음향을 얼마나 양보시키는가는 multi-objective RL에서 reward hacking과 직접 맞닿는 문제고, 본 논문이 이 trade-off를 완전히 푼 것은 아닙니다.
정리
세 가지를 가지고 갑니다.
- joint audio-video generation에서 vanilla GRPO가 잘 안 되는 이유는 advantage inconsistency, gradients imbalance, uniform credit assignment 세 가지로 분해 가능하고, 각각에 modality-wise advantage routing, layer-wise gradient surgery, region-wise loss reweighting이 1:1로 대응됩니다. multi-modal RL의 reward hacking이 영상은 좋은데 음향이 어긋난다는 식으로 나타날 때, advantage를 modality별로 쪼개고 gradient를 layer별로 surgery하는 발상은 audio-video 외 다른 modality 쌍(예: 텍스트-음성 동시 생성)에도 일반화될 여지가 있습니다.
- backbone(LTX-2 19B)을 갈아끼우지 않고 post-training RL만으로 DeSync를 절반 가까이 줄였다는 점이 한국 비디오 생성 스타트업·후반 작업 도구 관점에서 가장 실용적인 함의입니다. 우리 백본은 못 갈아도 보상 설계와 정책 최적화로 sync·립싱크 품질을 얼마나 끌어올릴 수 있는가가 새로 열린 자리입니다. V2A cross-attention을 공짜 region detector로 재활용하는 발상은 외부 detector 학습 비용 없이 발화 입 주변·소리 발생부를 찾아 쓸 수 있다는 측면에서 인디 규모 후반 작업 파이프라인에도 이식 가능합니다.
- text–video semantic alignment(TV-IB, CLIP)는 여전히 미해결입니다. 본 논문이 우리에게 해결한 것과 그대로 남은 것을 동시에 보여준다는 점에서, 후속 연구가 채울 자리(text-video reward, modality 간 더 정교한 credit assignment)가 분명히 보입니다.