Generative Criticality in Large Language Model Temperature Scaling
H. Ruan, J. Li, X. Guo, and L. Wang, "Generative Criticality in Large Language Model Temperature Scaling," arXiv:2606.06238, 2026.
LLM을 써본 사람이라면 temperature 슬라이더를 만져봤을 겁니다. 낮추면 또박또박 일관된 답이 나오고, 올리면 다채롭다가 어느 순간 갑자기 헛소리가 터집니다. 이 "어느 순간"이 그냥 서서히 나빠지는 게 아니라, 특정 지점에서 급격히 무너지는 상전이(phase transition)라면 어떨까요. 이 논문은 물리학의 임계 현상 언어를 빌려 그 지점이 실제로 존재함을 정량적으로 보입니다.
핵심 주장은 이렇습니다. 토큰 임베딩을 물리계의 스핀 변수처럼 다루면, softmax temperature를 올릴 때 임계온도 \(T_c \approx 1.4\) 근처에서 출력의 통계 구조가 질서에서 무질서로 급변합니다. 물이 \(0\,^\circ\text{C}\)에서 얼고 \(100\,^\circ\text{C}\)에서 끓듯, LLM 생성에도 임계점이 있다는 것입니다.
저자
이 논문은 NLP 그룹이 아니라 물리학 그룹이 썼습니다. 그게 시각을 결정합니다.
1저자 후아젠 루안과 교신저자 싱위 궈는 중국 화난사범대학(SCNU)의 핵물리·양자물질 연구 그룹 소속입니다. 싱위 궈는 양자컴퓨팅으로 QCD를 다루는 QuNu 협업의 멤버입니다. 또 다른 교신저자 링샤오 왕은 RIKEN iTHEMS 연구원이자 도쿄대 지능물리학 연구소 조교수로, 딥러닝으로 QCD 역문제를 푸는 물리 기반 학습의 전문가입니다. 공저자 Jinyang Li는 일본 KEK 이론센터와 RIKEN, SOKENDAI에 걸쳐 있습니다.
격자장론과 임계현상, 통계물리를 본업으로 하는 사람들이 모였습니다. 그래서 이 논문은 "LLM이 답을 잘 맞히나"가 아니라 "LLM 출력이라는 거대한 통계 앙상블에 물리계의 상전이 같은 집단 행동이 있나"를 묻습니다. 물리학자가 신경망과 생성 모델을 장론의 언어로 해석하는 흐름(링샤오 왕의 DEEP-IN 워킹그룹 같은) 위에 놓인 작업입니다.
배경
언어의 구조를 정량화하려는 시도는 대개 엔트로피나 상호정보량 같은 정보이론 양에 기댔습니다. 그런데 이런 양들은 미시 구조나 거시적 창발 행동을 잘 잡지 못합니다. 수많은 토큰이 모여 만들어내는 집단적 질서, 예컨대 "출력 전체가 한 방향으로 쏠리는가 흩어지는가" 같은 것은 엔트로피 하나로는 안 보입니다.
최근 LLM이 생성한 텍스트를 통계장론(statistical field theory)에 대응시키려는 연구가 시작됐습니다(Nakaishi 2024, Sun & Haghighat 2025). 다만 거기서 다루는 물리량의 정의가 엄밀하지 않았습니다. 이 논문은 그 빈자리를 메웁니다. 토큰 임베딩 공간 위에 susceptibility(반응성)와 order parameter(질서변수)를 분명히 정의하고, 이것들이 softmax temperature에 따라 어떻게 변하는지를 봅니다.
한 가지 전제를 짚고 갑니다. 여기서 temperature \(T\)는 열역학적 온도가 아닙니다. 다만 softmax에서 \(T\)가 하는 구조적 역할이 볼츠만 분포의 온도와 똑같습니다. 생성 시점의 다음 토큰 분포는 \(p_i = \exp(z_i/T) / \sum_j \exp(z_j/T)\)로, \(T \to 0\)이면 결정론적(가장 확률 높은 토큰만), \(T \to \infty\)이면 균등 분포로 갑니다. 저자들은 이 평행을 형식적 대응(formal correspondence)으로 다룬다고 명시합니다. 그래서 결론도 "이건 진짜 물리적 상전이다"가 아니라 "상전이를 강하게 닮은 현상이다"로 신중하게 적습니다.
어떻게 봤나
먼저 LLM을 \(O(N)\) 모델로 봅니다. 토큰 임베딩은 노름이 특정 스케일 근처에 모이는 고차원 벡터이므로, 텍스트 시퀀스를 \(N\)차원 벡터들이 늘어선 1차원 격자 사슬로 보고 유효 해밀토니안을 세웁니다.
\[H = \sum_{\sigma,\tau} J_{\sigma\tau}\, t_\sigma t_\tau + \sum_\sigma H_\sigma\, t_\sigma\]
여기서 \(t_\sigma\)는 격자 위치 \(\sigma\)(토큰 위치)의 임베딩 벡터, \(J\)는 모든 위치 쌍 사이 비국소 상호작용을 담는 결합 행렬, \(H\)는 프롬프트가 정하는 외부 장(external field)입니다. 토큰 사이 상호작용은 셀프 어텐션이 매개합니다.
\[\text{Attention}(Q, K, V) = \text{softmax}\!\left(QK^T / \sqrt{d_k}\right) V\]
이 틀 위에서 세 가지 관측량을 정의합니다.
첫째, susceptibility \(\chi\)입니다. 연결된 두 점 상관함수(connected two-point correlator)에서 정의하는데, 형식적으로는 분산과 비슷하지만 핵심은 임계온도 근처에서 요동이 발산한다는 점입니다. 표준 열역학 스케일링을 따라 \(\chi \sim |T - T_c|^{-\gamma}\)로 거동합니다.
둘째, order parameter입니다. 앙상블 평균 토큰 기댓값으로,
\[\langle t \rangle = \frac{1}{N_s L} \sum_{i,\sigma} t_\sigma^{(i)}\]
고온(무질서) 상에서는 0으로 가고, 저온(질서) 상에서는 결정론적 생성이 0이 아닌 앙상블 평균을 만듭니다. \(T_c\) 아래에서 \(O(N)\) 대칭이 자발적으로 깨지는 것과 같은 모양입니다.
셋째, 내재 차원(intrinsic dimension)입니다. TwoNN 방법으로 추정하는데, 각 점에서 두 번째·첫 번째 최근접 이웃 거리의 비 \(\mu = r_2/r_1\)로부터
\[-\ln\!\left(1 - F(\mu)\right) = I_d \cdot \ln \mu\]
를 풀어 \(I_d\)를 얻습니다. \(I_d\)는 질서 상에서 작고, 무질서 상에서 전체 자유도에 가까워지며, 임계점에서 비단조적 특징을 보입니다. susceptibility·order parameter가 통계장론 쪽 증거라면, 내재 차원은 기하학 쪽에서 같은 결론을 독립적으로 확인하는 장치입니다.
실험은 Qwen3 패밀리(0.6B부터 32B까지)로 했습니다. 출력 길이는 300토큰으로 고정하고, 프롬프트는 영어 위키백과를 주로 쓰되 중국어 위키·농담·시·소설·무의미 텍스트를 대조군으로 뒀습니다. 모두 추론을 끈 no-think 모드이고, 각 temperature마다 \(N_s = 1{,}000\)개 표본을 생성해 앙상블 평균을 냈습니다.
무엇을 발견했나
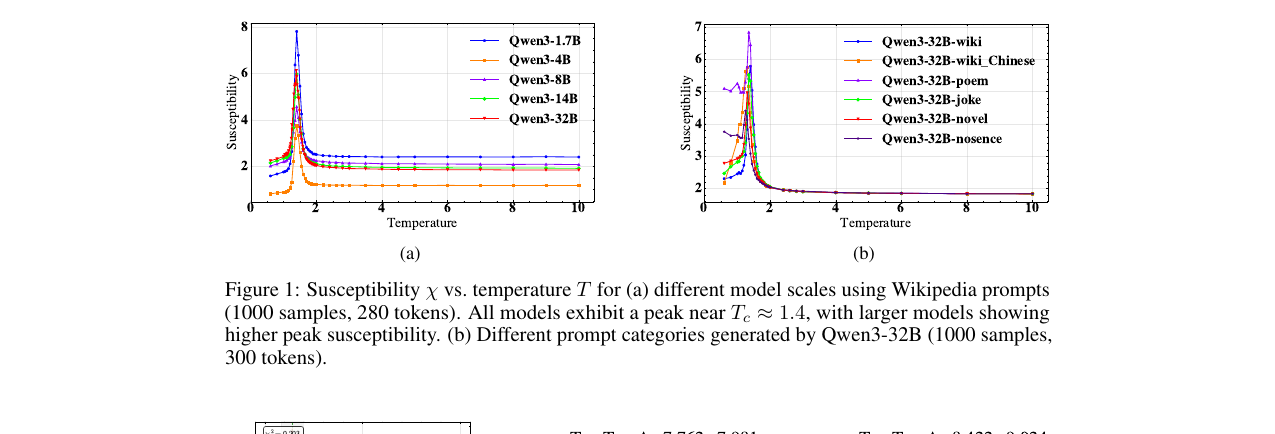
susceptibility를 temperature에 대해 그리면 \(T_c \approx 1.4\) 근처에서 날카로운 첨두가 나타납니다. 모델이 클수록 첨두가 높습니다. 첨두 양옆 모두 \(\chi \sim (T - T_c)^{-\gamma}\)의 거듭제곱 법칙을 따르고, 임계지수는 \(\gamma \approx 0.1\)로 맞춰집니다. 프롬프트 종류를 바꿔도(시·농담·무의미 텍스트) 같은 위치에 첨두가 섭니다. 다만 곡선들이 모델·프롬프트를 가로질러 하나로 겹쳐지지(collapse) 않는데, 저자들은 이를 파라미터 수와 프롬프트 유형이 서로 다른 유효 장(effective field)으로 작용하는 신호로 읽습니다. 표본 수를 2개에서 1000개로, 시퀀스 길이를 100에서 300토큰으로 늘려도 신호가 수렴함을 따로 확인했습니다.
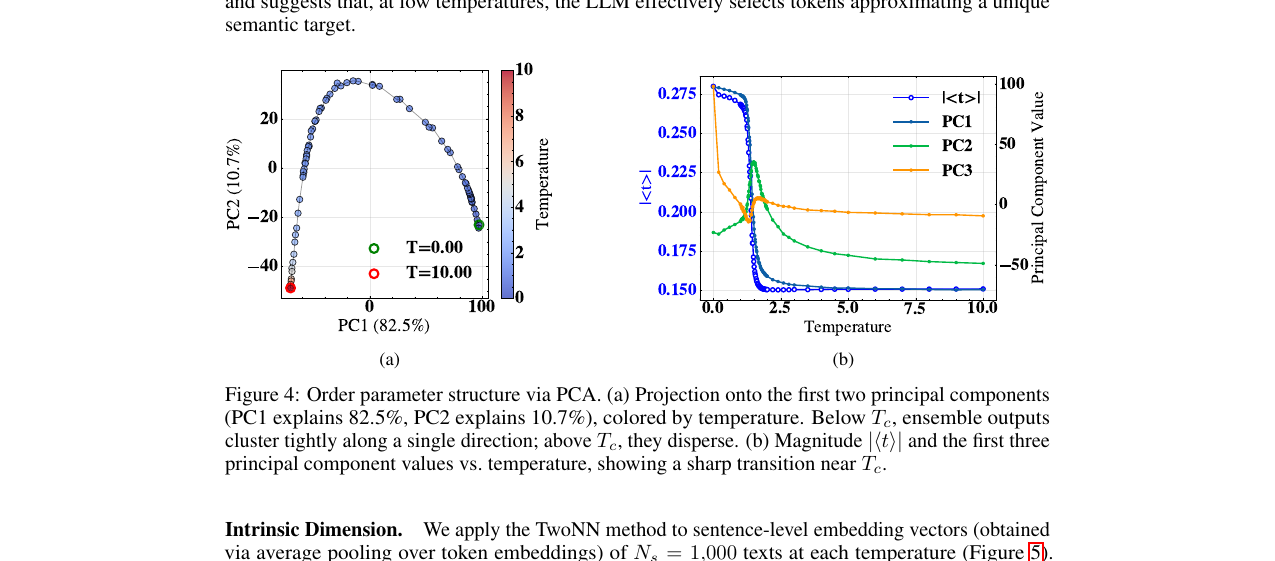
order parameter도 같은 지점에서 무너집니다. 앙상블 평균 벡터에 PCA를 적용하면, \(T_c\) 아래에서는 출력이 단일 의미 방향으로 빽빽이 정렬됩니다(PC1이 분산의 82.5%를 설명). \(T_c\) 위에서는 흩어집니다. 즉 저온에서 LLM은 사실상 하나의 의미 표적에 근접한 토큰을 고르는 셈입니다.
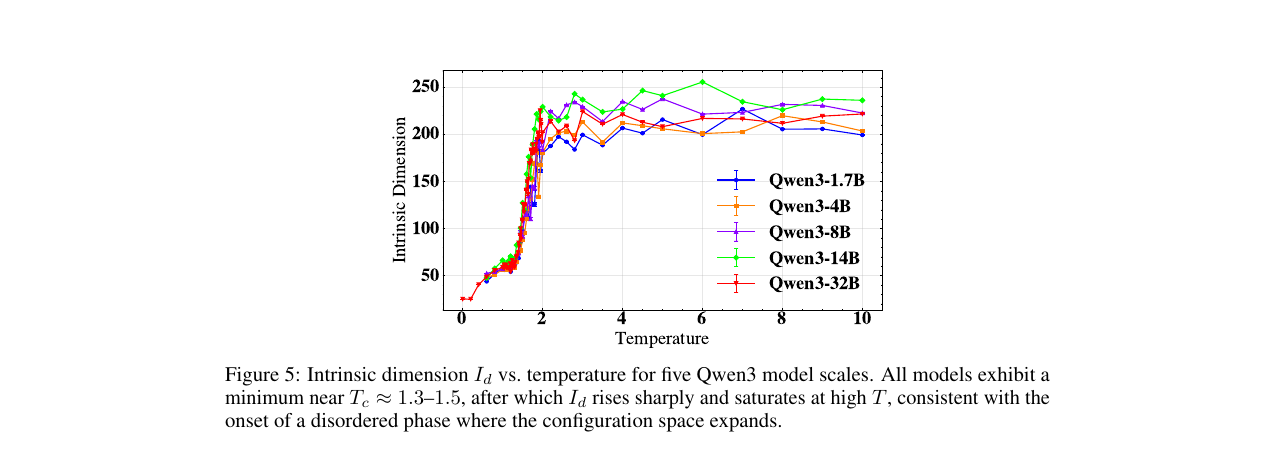
세 번째 신호인 내재 차원도 들어맞습니다. 문장 단위 임베딩에 TwoNN을 적용하면 \(I_d\)가 \(T_c \approx 1.3\text{--}1.5\) 근처에서 최소를 찍고, 그 위로 급상승해 고온에서 포화합니다. 저온에서는 구성 공간이 좁고, 임계 영역을 지나면, 고온에서는 시스템이 전체 구성 공간을 탐색한다는 그림입니다.
세 관측량을 한 표로 정리하면 이렇게 같은 이야기를 합니다.
관측량 |
저온 \(T < T_c\) (질서) |
임계점 \(T \approx T_c\) |
고온 \(T > T_c\) (무질서) |
|---|---|---|---|
Susceptibility \(\chi\) |
낮음 |
급첨두 (발산, \(\chi \sim \lvert T-T_c \rvert^{-\gamma}\)) |
낮음 |
Order parameter \(\langle t \rangle\) |
0이 아님 (단일 방향 정렬) |
급격한 방향 전환 |
0으로 수렴 (분산) |
내재 차원 \(I_d\) |
작음 |
최소 |
급상승 후 포화 |
서로 독립적인 세 측정이 모두 같은 임계 영역을 가리킨다는 점이 이 논문의 무게중심입니다. 정확도 점수 하나로는 절대 안 보일 구조입니다.
회고
저자들은 결론을 신중하게 적습니다. 현상학은 연속 상전이를 강하게 닮았지만, 자기회귀 생성은 비평형(non-equilibrium) 과정이라 진짜 상전이로 단정하려면 더 봐야 한다고 명시합니다. temperature가 열역학적 온도가 아니라는 전제도 처음부터 깔아둡니다.
보편성(universality)에 대한 단서도 솔직합니다. susceptibility 곡선이 모델·프롬프트를 가로질러 하나로 겹쳐지지 않으므로, 물리계의 깔끔한 스케일링 붕괴를 그대로 주장하지는 않습니다. 임계온도 자체도 조건에 따라 조금씩 움직입니다. 부록의 스케일링 테스트를 보면 시퀀스 길이가 200·400·500토큰으로 늘 때 \(T_c\)가 각각 약 1.405, 1.343, 1.289로 내려갑니다. 임계지수 \(\gamma\)도 양옆 직선 맞춤의 기울기가 0.3에서 0.58까지 흩어져, \(\gamma \approx 0.1\)이라는 헤드라인 수치는 고정값을 넣고 맞춘 결과에 가깝습니다. \(T = 0\)에서는 TwoNN 맞춤 자체가 잘 안 됩니다(\(R^2\)가 음수).
분량도 짧고 탐색적입니다. 다섯 쪽 본문에 부록이 붙은 preprint로, 새 벤치마크나 다운스트림 성능 개선을 제시하는 논문이 아니라 "이렇게 볼 수 있다"는 도구와 관점을 던지는 쪽입니다. 향후 방향으로 재규격화군(renormalization group) 기법으로 장거리 상관을 잡는 것, 그리고 무질서 상의 급격한 시작을 LLM 출력이 신뢰할 수 없게 되는 영역의 정량적 지표로 쓰는 것을 제시합니다.
정리
- LLM의 temperature는 단순한 무작위성 다이얼이 아닙니다. \(T_c \approx 1.4\) 근처에서 출력의 질서와 무질서가 급격히 바뀌는 임계점이 있고, 이는 물의 끓는점 같은 상전이를 닮았습니다.
- susceptibility 급첨두, order parameter의 단일 방향 붕괴, 내재 차원 최소라는 서로 독립적인 세 신호가 같은 지점을 가리킵니다. 정확도 지표로는 보이지 않는 집단 통계 구조입니다.
- 실용적 고리는 "무질서 상의 급격한 시작"을 출력 신뢰성의 경계 지표로 삼을 수 있다는 가능성입니다. 다만 비평형 특성·보편성 미확인·짧은 분량이라는 단서가 붙은, 관점을 여는 탐색적 작업으로 읽는 것이 맞습니다.