Unlimited OCR Works - Welcome the Era of One-shot Long-horizon Parsing
Y. Yin, H. Liu, Q. Xie, et al., "Unlimited OCR Works: Welcome the Era of One-shot Long-horizon Parsing," arXiv:2606.23050, 2026.
저자
바이두 내부 팀의 기술 보고서입니다. 핵심 기여자는 Youyang Yin과 프로젝트 리더 Huanhuan Liu, 그리고 기술 디렉터로 표기된 "YY"입니다. 논문이 바이두 소속으로만 나온 만큼, DeepSeek OCR(바이두 계열) 코드베이스에 익숙한 팀이 직접 이어받아 개선하는 구조입니다.
배경
기존 OCR 모델에는 공통된 병목이 있습니다. 디코더가 LLM이고, LLM은 생성 길이가 늘어날수록 KV 캐시가 선형으로 커집니다. 100K 토큰 수준의 긴 출력이 필요한 멀티페이지 문서 파싱에서 이 병목은 결정적입니다. 메모리가 폭증하고, Flash Attention v3 커널의 지연이 점점 길어지며, 20~30페이지 문서를 한 번에 처리하는 것은 사실상 불가능했습니다.
실제 현장의 해결책은 for-loop입니다. 페이지를 한 장씩 잘라서 각각 독립된 forward pass로 처리합니다. 속도 문제는 어느 정도 해결되지만, 페이지 경계마다 상태를 초기화하기 때문에 문서 전체를 연속적인 맥락으로 볼 수 없습니다. 논문은 이 방식을 "일관된 장거리 과정을 외부 스케줄러가 관리하는 독립 단편들로 쪼개는 것"이라고 표현합니다.
Unlimited OCR의 출발점은 다릅니다. 인간이 책을 베껴 쓸 때 어떤 어텐션 패턴을 쓰는지 관찰합니다. 사람은 이미 쓴 내용 전체를 다시 읽지 않습니다. 바로 앞 몇 글자만 확인하면서 진도를 추적합니다. 이 패턴은 full attention도 아니고, linear attention도 아닙니다. 시각 토큰(원본 이미지)은 상태 전이 없이 고정되어야 하고, 출력 토큰은 짧은 슬라이딩 윈도우만 참조하면 됩니다.
방법론
R-SWA
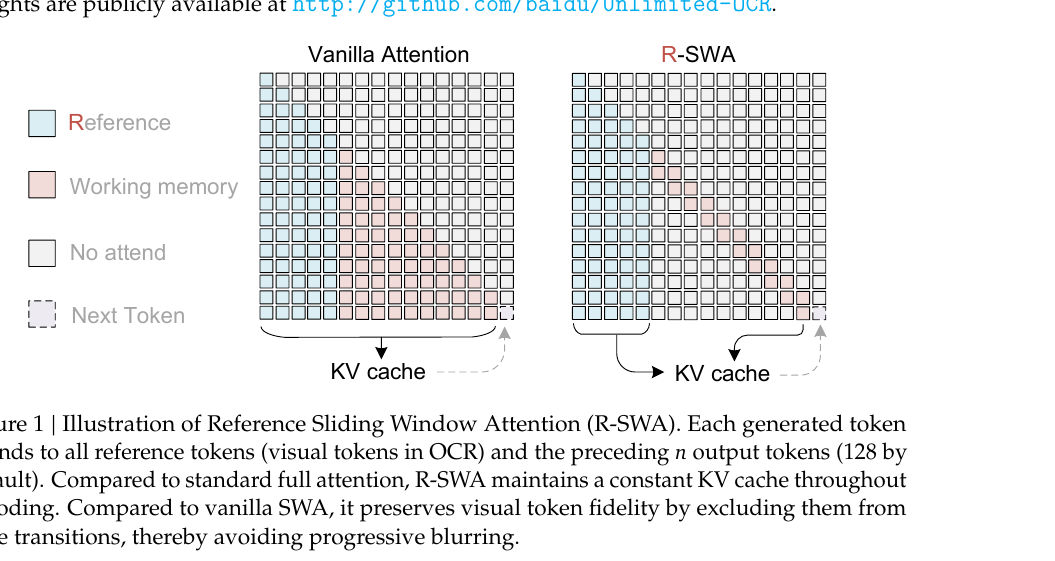
R-SWA(Reference Sliding Window Attention)는 어텐션 마스크를 두 구간으로 나눕니다.
프리픽스 구간 \(P = \{1, \ldots, L_m\}\)은 시각 토큰과 프롬프트 전체를 포함하며, 모든 이후 토큰이 전역적으로 참조합니다. 디코드 구간은 너비 \(n\)의 인과적 슬라이딩 윈도우 \(D_n(t)\)로 제한됩니다.
\[N(t) = P \cup D_n(t)\]
각 위치 \(j \in N(t)\)에 대한 어텐션 가중치는 표준 스케일드 닷 프로덕트로 계산합니다.
\[\alpha_{tj} = \frac{\exp\!\left(\frac{q_t^\top k_j}{\sqrt{d_k}}\right)}{\sum_{i \in N(t)} \exp\!\left(\frac{q_t^\top k_i}{\sqrt{d_k}}\right)}\]
이 결과로 KV 캐시 크기는 상수로 고정됩니다.
\[C_{\text{MHA}}(T) = L_m + T \quad \text{vs} \quad C_{\text{R-SWA}}(T) = L_m + \min(n, T)\]
출력 길이 \(T\)가 커질수록 MHA의 캐시는 선형으로 증가하지만, R-SWA는 \(L_m + n\)을 넘지 않습니다. \(T \gg n\)이면 캐시 비율 \(\rho(T) \approx (L_m + n)/T \to 0\)으로 수렴합니다.
기존 SWA와의 차이는 시각 토큰을 상태 전이에서 제외한다는 점입니다. 일반 SWA는 시각 토큰도 생성 토큰과 동일하게 취급해 슬라이딩 윈도우 밖으로 밀려나면 점차 블러가 발생합니다. R-SWA는 시각 토큰을 고정된 레퍼런스로 분리해 이 문제를 없앱니다.
모델 구조
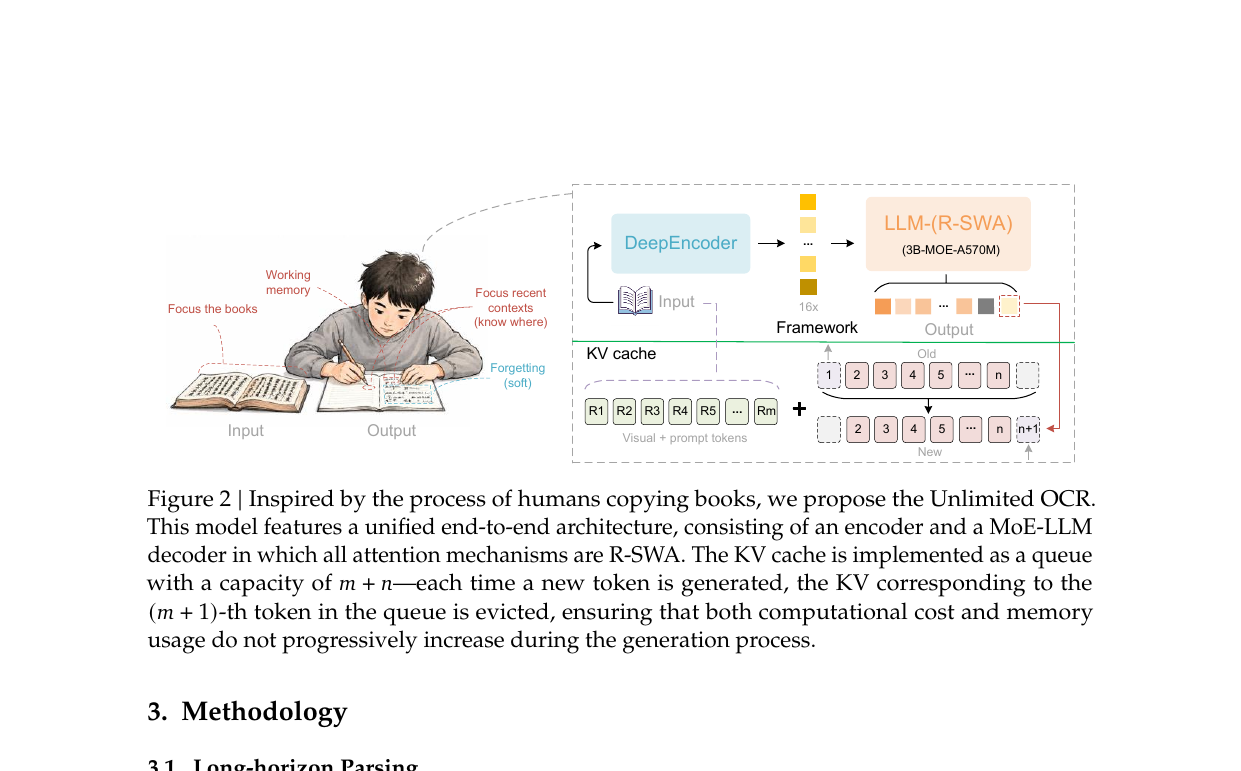
Unlimited OCR은 DeepSeek OCR의 구조를 그대로 이어받습니다. 인코더는 DeepEncoder로, SAM-ViT와 CLIP-ViT를 연결해 1024×1024 이미지를 256 토큰으로 \(16\times\) 압축합니다. 디코더는 3B 파라미터, 500M 활성화의 MoE LLM인데, 이 디코더의 모든 MHA 레이어를 R-SWA로 교체합니다.
학습은 약 200만 건의 PDF 문서 데이터로 DeepSeek OCR 체크포인트에서 4,000 스텝 continue-training합니다. DeepEncoder는 동결하고 LLM 파라미터만 학습합니다. 8×16 A800 GPU, Megatron-LM 프레임워크, 시퀀스 길이 32K.
결과
OmniDocBench 메인 결과
v1.5는 DeepSeek OCR 베이스라인과의 직접 비교, v1.6은 현재 SOTA 모델들과의 비교입니다.
모델 |
크기 |
Overall (%) |
|---|---|---|
OmniDocBench v1.5 |
||
OCRFlux |
3B |
74.82 |
dots.ocr |
3B |
88.41 |
Qwen3-VL |
235B |
89.15 |
DeepSeek-OCR 2 |
3B-A0.5B |
89.17 |
DeepSeek OCR (baseline) |
3B-A0.5B |
87.01 |
Unlimited OCR |
3B-A0.5B |
93.23 |
OmniDocBench v1.6 |
||
HunyuanOCR |
1B |
89.95 |
DeepSeek-OCR 2 |
3B-A0.5B |
90.25 |
FireRed-OCR |
2B |
93.26 |
Logics-Parsing-v2 |
4B |
93.33 |
Qianfan-OCR |
4B |
93.90 |
Unlimited OCR |
3B-A0.5B |
93.92 |
베이스라인 DeepSeek OCR 대비 Overall +6.22%p, 텍스트 Edit Distance 0.073 → 0.038(-0.035), Formula CDM +9.24%, Table TEDS +5.96%p를 기록합니다. v1.6에서는 235B 모델을 포함한 전체 end-to-end SOTA 경쟁에서 가장 높은 점수를 냅니다.
추론 속도
OmniDocBench 기준(단일 페이지 위주)에서 이미 Unlimited OCR은 DeepSeek OCR보다 12.7% 빠릅니다(5,580 vs 4,951 TPS). 문서가 길어질수록 이 격차는 급격히 커집니다.
출력 토큰 수 |
DeepSeek OCR TPS |
Unlimited OCR TPS |
|---|---|---|
256 |
7,229 |
7,230 |
1024 |
7,423 |
7,841 |
3072 |
6,791 |
7,882 |
6144 |
5,823 |
7,848 |
6,000 토큰 출력에서 Unlimited OCR이 DeepSeek OCR보다 35% 빠릅니다. R-SWA는 Flash Attention v3 커널의 지연이 디코드 길이에 무관하게 일정하게 유지되기 때문입니다. 기존 MHA에서는 KV 캐시 길이가 정렬 경계를 넘을 때 전송 효율이 급락하는 스파이크가 발생하는 반면, R-SWA는 이 패턴이 나타나지 않습니다.
장거리 파싱
내부 테스트셋(소설·문서·논문, 페이지 수별 10권 이상)에서의 성능입니다.
페이지 수 |
Distinct-35 |
Edit Distance |
|---|---|---|
2 |
99.87% |
0.0362 |
5 |
99.98% |
0.0452 |
10 |
99.83% |
0.0526 |
20 |
99.89% |
0.0572 |
40+ |
96.90% |
0.1069 |
40페이지 이상에서 Edit Distance가 0.107로 오르고 Distinct-35가 소폭 떨어집니다. 저자는 이 오류의 대부분이 R-SWA의 방향 상실이 아니라 고해상도 모드 부재 때문이라고 밝힙니다. 멀티페이지 조건에서 1024×1024 고정 해상도(Base 모드)를 쓰기 때문에 작은 글씨가 잘 인식되지 않습니다.
회고
진짜 unlimited는 아닙니다. 논문 제목이 bold하지만, 저자 스스로 7절에서 명확히 인정합니다. prefill 길이는 페이지 수에 비례하고, 32K 맥락 내에서만 동작합니다. 수십 페이지는 처리해도 수백 페이지 책 한 권을 그대로 넣기 어렵습니다. 단기 해결책은 128K 컨텍스트 확장, 장기 계획은 prefill KV 청크를 자동으로 가져오는 "prefill pool" 구조입니다.
내부 테스트셋 의존: 장거리 파싱 결과(Table 3)는 공개 벤치마크가 아닌 자체 구성한 테스트셋입니다. 재현성과 공정성을 확인하기 어렵습니다.
단일 레이아웃 테스트: OmniDocBench는 PDF 중심 벤치마크입니다. 스캔본, 손글씨, 복잡한 멀티컬럼 레이아웃에 대한 별도 분석은 없습니다.
베이스라인 선택: 비교군이 DeepSeek OCR 계열에 집중되어 있습니다. 완전히 다른 접근의 파이프라인 기반 모델(MinerU 등)과의 비교는 표에 일부 있지만 심층 분석이 없습니다.
정리
- DeepSeek OCR 디코더의 MHA를 R-SWA로 교체하는 것만으로 KV 캐시 크기가 생성 길이에 무관하게 상수로 유지됩니다.
- OmniDocBench v1.5에서 베이스라인 대비 +6.22%p, v1.6에서 end-to-end SOTA를 달성하면서 파라미터는 동일(3B-A0.5B)합니다.
- R-SWA는 OCR 외에 ASR, 번역 등 레퍼런스 기반 장거리 파싱 태스크 전반에 적용 가능한 범용 메커니즘입니다.