Efficient BackProp
Y. LeCun, L. Bottou, G. B. Orr, and K.-R. Müller, "Efficient BackProp," in Neural Networks: Tricks of the Trade, LNCS 1524, Springer Berlin Heidelberg, pp. 9-50, 1998.
1998년에 얀 르쿤 팀이 한 챕터로 못 박았습니다. 신경망을 잘 굴리는 일은 과학보다 예술에 가까웠는데, 그 예술의 노하우 절반을 단정한 알고리즘과 수식으로 정리해 책에 실었습니다. 30년 가까이 지난 지금 입력은 평균 0, 분산 1로 정규화한다, 가중치는 \(\sigma_w = m^{-1/2}\)로 초기화한다, 학습률은 가중치마다 다르게 둔다 같은 권장이 그대로 살아 있는 이유는 이 챕터가 그것을 왜 그렇게 해야 하는지를 같이 적었기 때문입니다.
이 챕터의 정식 출처는 Neural Networks: Tricks of the Trade(Springer LNCS 1524, 1998)입니다. 책 자체가 학회 워크숍을 묶은 것이고, 본 챕터는 그중 첫 번째 자리에 실린 핵심 논문입니다.
저자
저자 네 명은 1990년대 신경망 학습 이론과 실험이 두 곳에서 동시에 익어가던 흐름을 그대로 보여줍니다. 한쪽은 AT&T Bell Labs Holmdel입니다. 얀 르쿤과 레옹 보투가 Image Processing Research Department에 있었습니다. 다른 한쪽은 독일 GMD FIRST 베를린입니다. 클라우스로베르트 뮐러가 Intelligent Data Analysis 그룹을 이끌고 있었습니다. 두 그룹 사이에 DAAD와 NSF의 상호 교류 자금이 흘렀고, 본 챕터의 Acknowledgment에 이 자금이 명시돼 있습니다.
얀 르쿤은 같은 시기 LeNet-5 작업으로 합성곱 신경망의 산업 응용을 굳히고 있었고, 레옹 보투는 그 학습기 SN2를 만든 사람이자 확률적 경사 하강의 이론·실험을 함께 다듬고 있었습니다. 클라우스로베르트 뮐러는 커널 방법과 신경망 일반화 이론을 묶으려 했고, 주느비에브 오어는 1995년 오레곤 박사 논문에서 온라인 학습 동역학을 수식으로 정리한 직후였습니다. 네 사람의 노하우를 한 챕터에 묶어 왜 이 트릭이 통하는가를 같이 적은 것이 이 글의 시작점입니다.
배경
1998년의 신경망 학습은 예술이었습니다. 얀 르쿤 본인이 §1에서 그렇게 말합니다. 노드 수, 층 수, 학습률, 학습·테스트셋 분할 같은 결정이 문제와 데이터에 따라 달라지고 만능 레시피가 없다고 인정합니다. 다만 경험적으로 옳다고 알려진 휴리스틱이 쌓여 있고, 그 휴리스틱이 왜 통하는지에 대한 이론이 일부 있습니다. 이 챕터는 그 휴리스틱과 이론의 가교를 한 권에 정리합니다.
같은 시기 머신러닝 학회는 Online Learning Workshop(Newton Institute, 1997)을 비롯해 학습 동역학 이론을 본격적으로 다루기 시작했고, Neural Networks: Tricks of the Trade 책 자체가 그 흐름에서 나온 결과물입니다. 이 챕터는 책의 첫 챕터이자 가장 길게(50쪽 가까이) 다뤄지는 정본 격입니다. 후속 Gradient-Based Learning Applied to Document Recognition(LeNet-5, 1998)에서 실제로 어떤 학습 트릭이 적용됐는지는 이 챕터에서 미리 다 설명되어 있다고 봐도 됩니다.
확률적 학습이 이긴다
가장 첫 번째 권장이자 가장 강한 권장은 batch보다 stochastic입니다. 전체 데이터셋을 한 번 훑어 평균 그래디언트를 만드는 batch 갱신 대신, 무작위로 고른 단일 예제 \(\{Z^t, D^t\}\)로 가중치를 갱신합니다.
\[W(t+1) = W(t) - \eta \frac{\partial E^t}{\partial W}.\]
저자들이 stochastic을 미는 이유는 세 가지입니다. 첫째, 실제 데이터는 잉여(redundancy)가 크기 때문에 batch는 같은 정보를 여러 번 평균 내느라 시간을 낭비합니다. 1000개 학습 예제가 100개짜리 집합 10개의 사본이라면, batch 한 번 돈 결과는 100개만 보고 만든 그래디언트와 정확히 같습니다. 둘째, 갱신에 섞이는 잡음이 망을 깊은 국소 최솟값으로 튕겨 보내는 효과가 있어 더 좋은 해를 찾을 가능성이 높아집니다. 셋째, 데이터 분포가 시간에 따라 변하는 산업 환경에서는 stochastic만이 변화를 추적할 수 있습니다.
다만 잡음이 있기 때문에 완전히는 수렴하지 않고 최솟값 주변에서 진동합니다. 진동의 분산은 학습률 \(\eta\)에 비례하므로, 어느 시점부터 \(\eta\)를 식히는 anneal 스케줄이 필요합니다. 이론적으로 최적 스케줄은 다음 형태입니다.
\[\eta \sim \frac{c}{t}.\]
여기서 \(t\)는 본 예제 수, \(c\)는 상수입니다. 실무에서는 \(c/t\)가 너무 빠르게 식어 더 완만한 스케줄을 쓰기도 한다고 저자들이 명시합니다.
§4.2의 작은 보너스: 예제를 학습기에게 가장 낯선 순서로 보여주면 학습이 빨라집니다. 즉 연속한 두 예제가 같은 클래스에 속하지 않도록 셔플하고, 큰 오차를 내는 입력을 더 자주 보여주는 emphasizing scheme을 씁니다. 단, 이상치(outlier)에 같은 짓을 하면 학습이 망가지므로 outlier가 있는 데이터에는 적용하지 말라는 단서가 붙습니다.
입력과 활성함수
학습 속도는 입력 통계와 활성함수의 모양에 매우 강하게 의존합니다. 챕터의 §4.3~§4.6은 이를 입력 변환 → 시그모이드 → 타깃 → 초기화의 한 묶음으로 묶어 다룹니다.
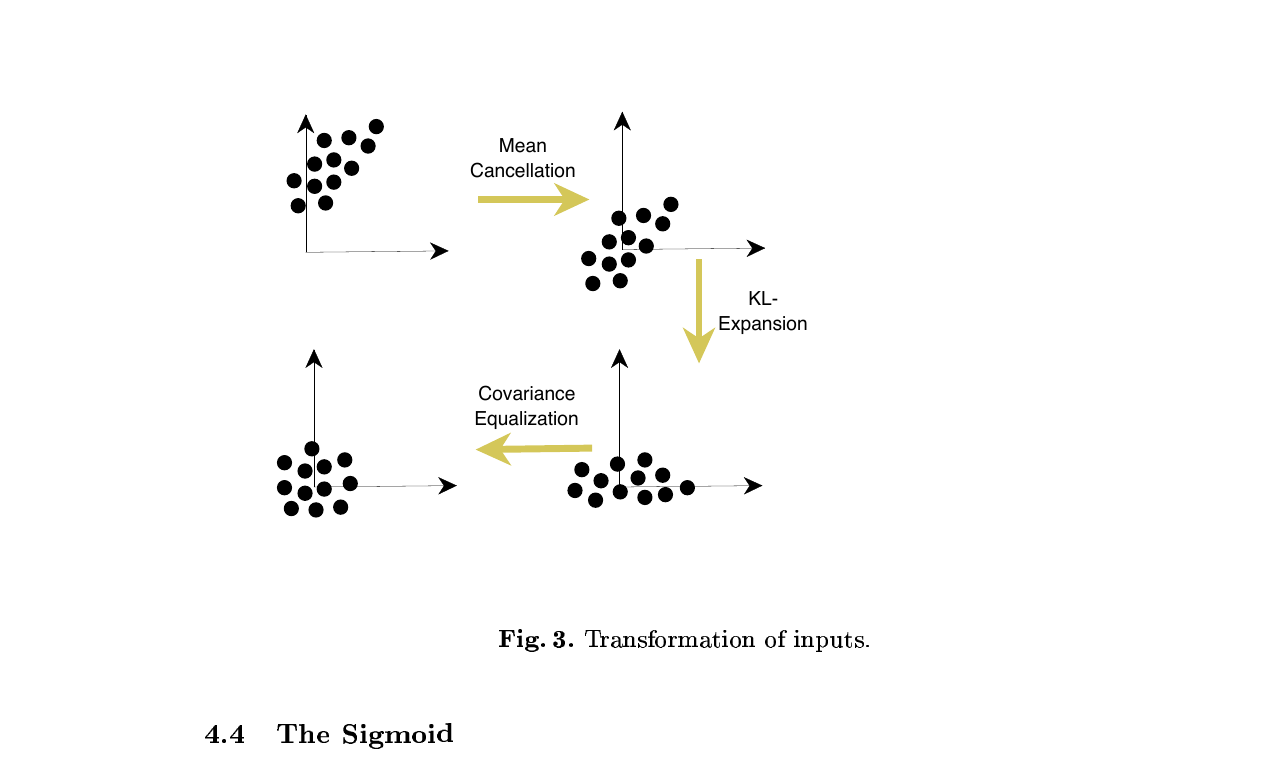
입력 변환은 세 단계입니다. 평균 빼기, KL 전개(주성분 분석)로 상관 제거, 분산 균등화. 직관은 단순합니다. 어떤 입력 변수의 평균이 0이 아니면 그 변수에 연결된 가중치는 항상 같은 방향으로만 갱신되어 가중치 벡터가 갈지자로 진동해야만 방향을 바꿀 수 있습니다. 평균이 0이면 그 진동이 없어집니다. 분산을 균등화하면 입력별로 공유하는 학습률이 골고루 효과를 냅니다. 마지막으로 상관을 제거하면 각 가중치가 독립적으로 다른 학습률을 가질 수 있는 조건이 갖춰집니다.
활성함수는 원점 대칭 시그모이드가 정답입니다. 표준 로지스틱 \(f(x) = 1/(1 + e^{-x})\) 대신 다음을 권장합니다.
\[f(x) = 1.7159 \tanh\left(\frac{2}{3}x\right).\]
상수 \(1.7159\)와 \(2/3\)은 일부러 고른 값입니다. \(f(\pm 1) = \pm 1\)이 되고, 2차 미분이 \(x = \pm 1\)에서 최대가 되며, 유효 이득(effective gain)이 유효 입력 영역에서 약 1이 되도록 맞췄습니다. 입력을 분산 1로 정규화하면 시그모이드 출력 분산도 약 1이 되어 다음 층 입력 조건이 자동으로 맞춰집니다.
타깃 값은 시그모이드의 점근선에 두지 말고, 2차 미분이 최대인 점(위 시그모이드의 경우 \(\pm 1\))에 둡니다. 점근선에 타깃을 두면 출력이 그쪽으로 끌려가면서 가중치가 매우 커지고, 결국 시그모이드가 포화돼 그래디언트가 사라집니다. 게다가 포화된 출력은 확신도 정보를 잃어 결정 경계 근처의 모호한 입력도 강하게 분류해 버립니다.
가중치 초기화는 입력 정규화와 시그모이드 선택과 함께 묶입니다. 위 시그모이드를 쓰고 입력이 분산 1로 정규화돼 있을 때, 각 노드 출력의 표준편차가 약 1이 되도록 만들려면 다음과 같이 잡습니다.
\[\sigma_w = m^{-1/2},\]
여기서 \(m\)은 그 노드에 들어오는 연결 수(fan-in)입니다. 평균 0, 표준편차 \(m^{-1/2}\)의 균등 분포나 가우시안에서 가중치를 뽑습니다. 너무 크면 시그모이드가 포화되고, 너무 작으면 그래디언트가 사라집니다.
학습률
단일 스칼라 학습률은 다층 신경망에서 거의 항상 비효율적입니다. 1차원에서는 최적 학습률을 정확히 적을 수 있습니다.
\[\eta_{opt} = \left(\frac{d^2 E}{d W^2}\right)^{-1}.\]
다차원에서는 위 식의 우변이 헤시안 \(H\)의 역행렬이 됩니다. \(H\)의 가장 큰 고윳값을 \(\lambda_{max}\)라 하면 발산을 피하기 위해 \(\eta < 2/\lambda_{max}\)여야 하고, 단일 학습률의 최적값은 \(\eta_{opt} = 1/\lambda_{max}\)입니다. 다만 \(\lambda_{max}/\lambda_{min}\) 비(조건수)가 크면 작은 고윳값 방향의 수렴이 매우 느려집니다.
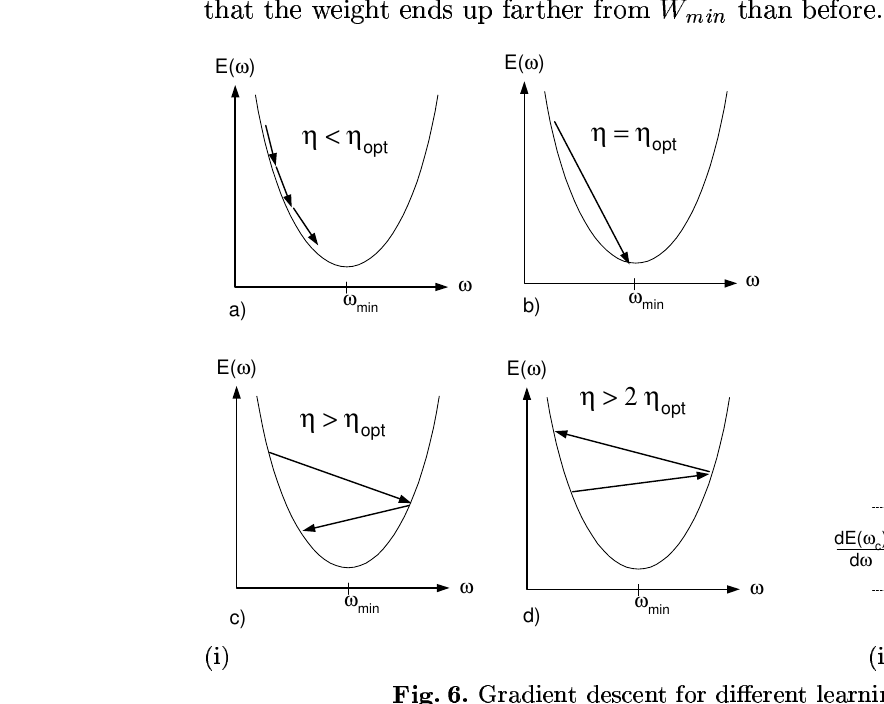
위 그림은 1차원에서 학습률 네 가지 케이스를 보여줍니다. \(\eta < \eta_{opt}\)이면 작게 여러 번 내려가고, \(\eta = \eta_{opt}\)이면 한 번에 도달하고, \(\eta_{opt} < \eta < 2\eta_{opt}\)이면 진동하면서 수렴하며, \(\eta > 2\eta_{opt}\)이면 발산합니다.
저자들의 실용 처방은 가중치마다 다른 학습률입니다. 다음 세 가지 휴리스틱을 따릅니다.
- 가중치마다 학습률을 줍니다.
- 학습률은 그 노드의 입력 수의 제곱근에 비례하도록 잡습니다 (\(\sqrt{m}\)).
- 아래층(입력 가까이) 가중치의 학습률은 위층 가중치보다 일반적으로 크게 잡습니다. 다층 신경망에서 헤시안의 고윳값이 아래층에서 작고 위층에서 크기 때문입니다.
가중치를 공유하는 합성곱 망이나 시간 지연 망(TDNN)에서는 그 가중치가 받는 그래디언트가 공유 연결 수의 합이므로, 학습률을 공유 연결 수의 제곱근에 비례하도록 잡습니다.
모멘텀은 다음과 같이 추가하며, 비등방 비용면에서 효과가 큰 것으로 알려져 있지만 stochastic 모드에서의 체계적 비교는 없다고 저자들이 솔직히 적습니다.
\[\Delta w(t+1) = \eta \frac{\partial E_{t+1}}{\partial w} + \mu \Delta w(t).\]
2차 방법의 운명
§6~§9는 2차 방법을 다룹니다. 결론부터 적으면 고전적 2차 방법은 다층 신경망에 거의 쓸 수 없다는 것입니다. Newton, Gauss-Newton, Levenberg-Marquardt, Quasi-Newton(BFGS), Conjugate Gradient를 차례로 검토하면서 각 방법의 한계를 표로 정리할 수 있습니다.
방법 |
복잡도(스텝당) |
모드 |
적용 한계 |
|---|---|---|---|
Newton |
\(O(N^3)\) + 헤시안 저장 |
batch |
다층 망에서 헤시안이 양정치 아님, 거의 불가 |
Gauss-Newton |
\(O(N^3)\) |
batch |
MSE 손실 + 작은 망에 한정 |
Levenberg-Marquardt |
\(O(N^3)\) |
batch |
MSE 손실 + 작은 망에 한정 |
Quasi-Newton (BFGS) |
\(O(N^2)\) + \(N \times N\) 저장 |
batch |
작은 망, 잉여 적은 데이터 |
Conjugate Gradient |
\(O(N)\) + line search |
batch |
중간 크기 회귀·근사 문제 |
확률적 대각 LM (저자 제안) |
\(O(N)\) |
stochastic |
SGD 대비 약 3배 빠름 |
마지막 줄이 §9.1에서 저자들이 직접 제안하는 확률적 대각 Levenberg-Marquardt입니다. 각 파라미터별 2차 미분의 이동 평균을 backprop으로 추정한 다음, 가중치별 학습률을 다음과 같이 계산합니다.
\[\eta_{ki} = \frac{\epsilon}{\left\langle \frac{\partial^2 E}{\partial w_{ki}^2} \right\rangle + \mu}.\]
\(\epsilon\)은 전역 학습률, \(\mu\)는 작은 평탄 영역에서 학습률이 폭주하지 않도록 막는 상수입니다. 추가 비용은 일반 backprop과 비교해 무시할 수 있을 정도이며, 잘 튜닝된 SGD보다 약 3배 빠르다는 것이 저자들의 경험치입니다.
§7은 헤시안 정보를 효율적으로 얻는 보조 도구를 정리합니다. 유한 차분, Gauss-Newton 근사(제곱 야코비안), 대각 헤시안의 역전파, 헤시안-벡터 곱 등인데, 이 중 대각 헤시안 역전파가 위의 확률적 대각 LM의 기반입니다. 이 같은 대각 헤시안 추정은 NIPS 89에서 같은 저자들이 발표한 Optimal Brain Damage 가지치기에도 그대로 쓰였습니다.
§8은 실제 다층 망의 헤시안 고윳값 분포를 한 OCR 망에서 직접 측정해 보입니다. 첫 번째와 11번째 고윳값의 비가 약 8배, 가장 큰 고윳값과 가장 작은 고윳값의 비는 훨씬 큽니다. 비용면이 가늘고 긴 타코 셸 모양이라는 직관, 그리고 위층 헤시안이 아래층보다 가파르다는 두 관찰이 §4.7의 층별로 학습률을 다르게라는 휴리스틱을 정량적으로 정당화합니다.
정리
저자들이 §10에서 다층 신경망 학습을 시작하는 실무자에게 권하는 순서는 다음과 같습니다.
단계 |
권장 |
|---|---|
|
클래스가 섞이도록 셔플하고, 큰 오차를 내는 입력은 더 자주 보임 |
|
학습셋에서 평균을 빼서 0으로 |
|
표준편차 1로 스케일 |
|
가능하면 PCA(KL 전개)로 무상관화 |
|
\(f(x) = 1.7159 \tanh\left(\frac{2}{3}x\right)\) |
|
시그모이드 범위 안, 보통 \(\pm 1\) |
|
평균 0, \(\sigma_w = m^{-1/2}\)의 분포에서 무작위 |
|
큰 분류 문제는 잘 튜닝한 SGD 또는 확률적 대각 LM. 작거나 회귀 문제는 conjugate gradient |
마지막 줄에 저자들이 한 줄 더 적습니다. 고전적 2차 방법은 거의 모든 실용 사례에서 쓸 수 없다는 평가, 그리고 다층 신경망에서 SGD의 비선형 동역학이 일반화에 어떤 영향을 미치는지는 여전히 잘 모른다는 솔직한 인정입니다.
30년이 지난 지금 위 표 1~7번은 거의 그대로 살아 있습니다. 입력 정규화, tanh류 활성, \(\sigma_w = m^{-1/2}\) 초기화, \(\pm 1\) 타깃 같은 권장이 왜 그렇게 해야 하는지의 이유까지 한 챕터에 정리된 첫 문헌이 이 글입니다. 8번 학습 알고리즘 항목만 Adam류 적응 학습률과 배치 정규화·층 정규화로 갈아끼우면, 오늘날의 모든 PyTorch 튜토리얼의 첫 페이지가 됩니다.