PDF 페이지를 이미지 그대로 오토리그레시브 학습하면, 같은 코퍼스에서 텍스트만 학습한 것보다 과학 추론 성능이 일관되게 높아진다는 실증 연구.
태그: 논문
182개의 게시물
-
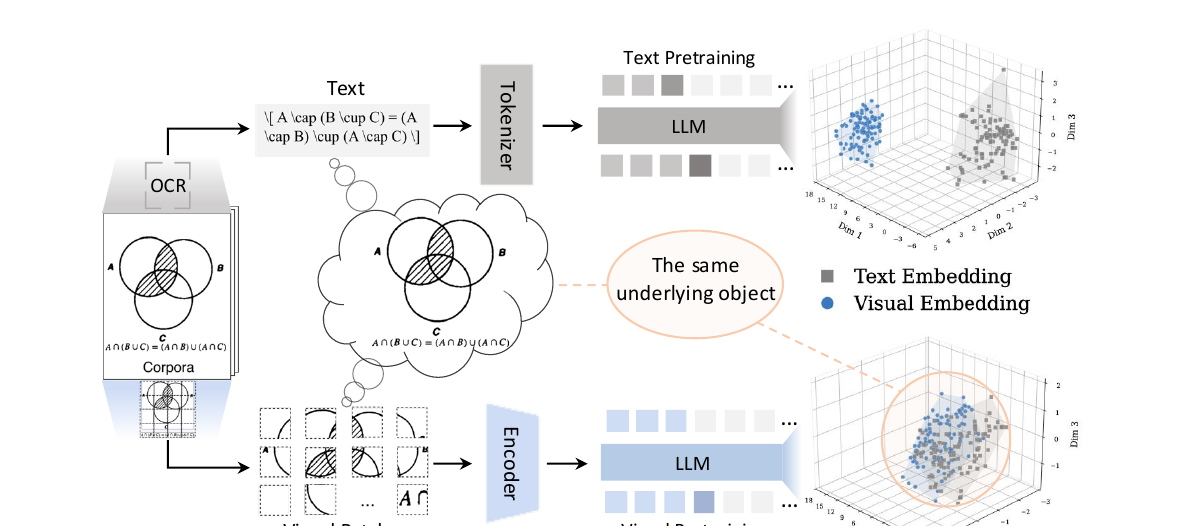
-
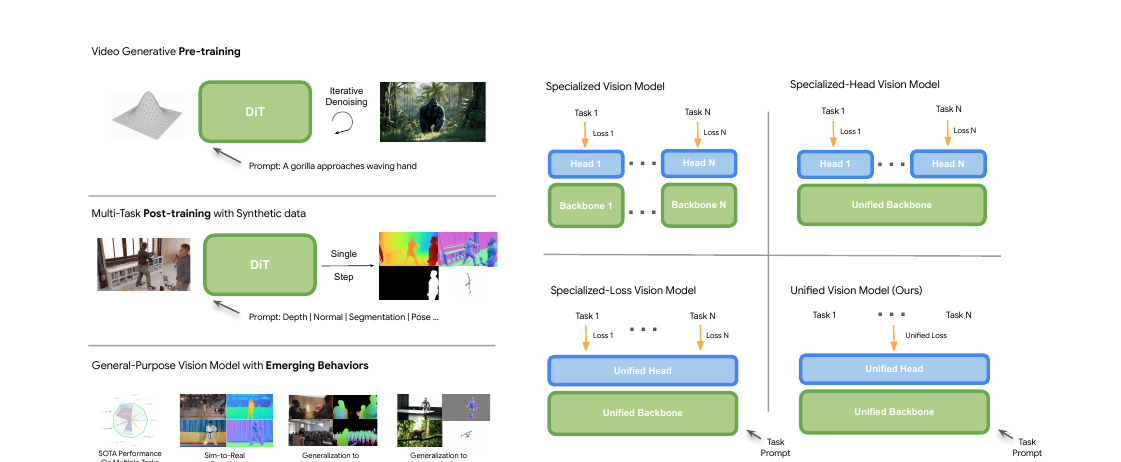
비디오 생성 모델의 사전학습 표현을 활용해 깊이·법선·분할·포즈 등 다양한 비전 과제를 단일 피드포워드 모델로 처리하는 GenCeption을 제안한다. WAN 2.1 기반으로 V-JEPA·VideoMAE를 큰 폭으로 앞서며, 7x~500x 적은 데이터로 전문 모델에 준하는 성능을 냈다.
-
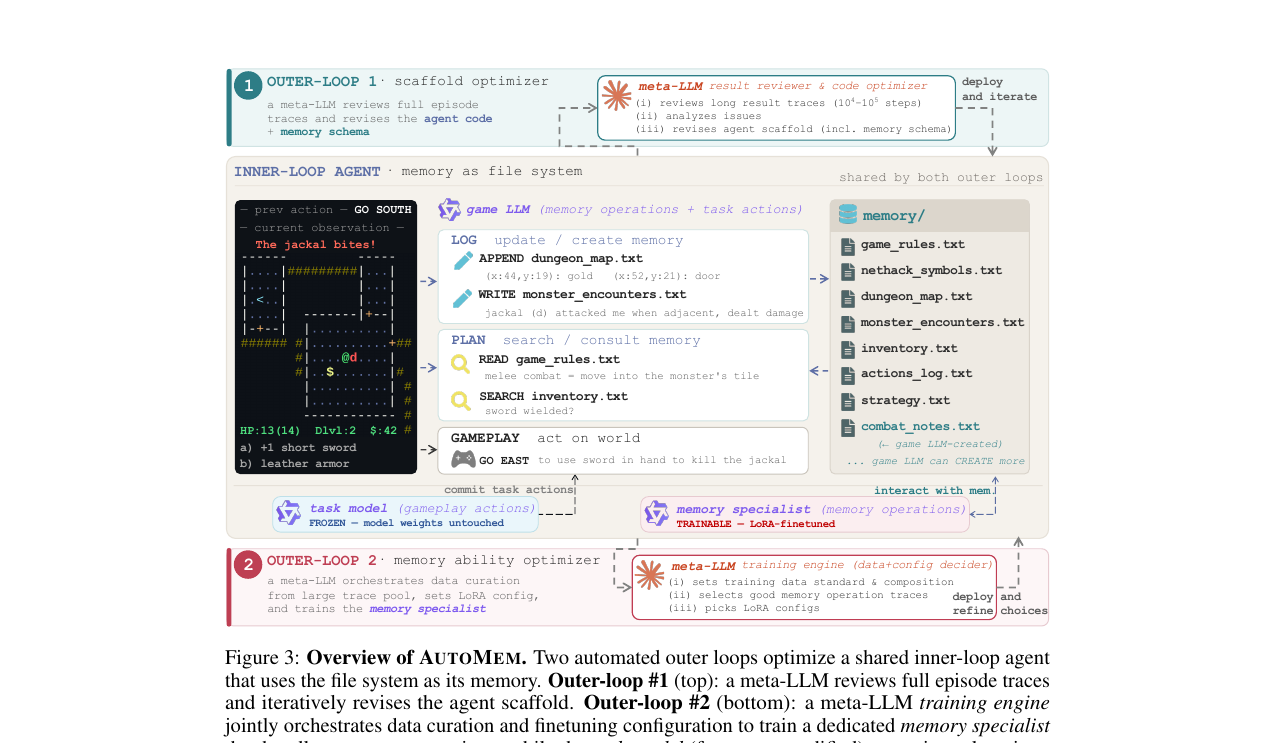
메모리 관리를 아키텍처에 박아넣는 고정 모듈이 아니라 학습 가능한 기술로 다룬 연구입니다. 파일 시스템 조작을 과제 행동과 동급의 행동으로 올리고, 메타 LLM이 궤적을 검토해 골격과 숙련을 함께 최적화합니다. 가중치를 건드리지 않고 메모리만 손봐도 Qwen2.5-32B의 장기 과제 성능이 두세 배 올랐습니다.
-
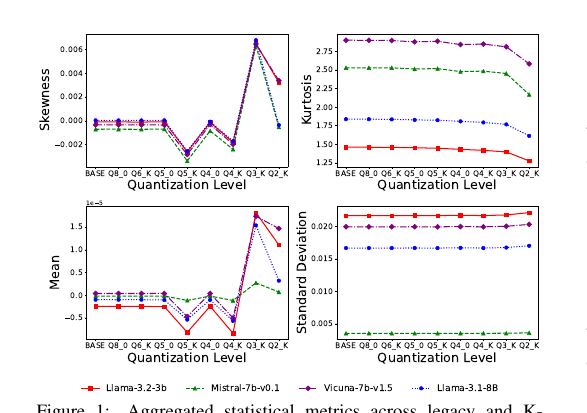 The Illusion of Equivalency - Statistical Characterization of Quantization Effects in LLMs 2026-07-13
The Illusion of Equivalency - Statistical Characterization of Quantization Effects in LLMs 2026-07-13양자화한 LLM을 정확도와 퍼플렉시티만으로 평가하면 원본과 같아 보입니다. 이 논문은 correctness agreement라는 결정 수준 지표를 도입해, 총점이 유지돼도 실제로 맞히는 문제의 집합이 달라진다는 것을 보입니다. 8비트에서 2비트까지 훑으며 어텐션의 쿼리·키 투영이 가장 취약함을 밝힙니다.
-
의미 불변성에 치우친 시각 사전학습이 조밀한 공간 정보를 잃는 문제를 경계 중심 자기지도학습으로 다룹니다. LingBot-Vision은 경계 토큰을 의도적으로 가리고 의미와 기하를 함께 복원해 깊이 추정과 분할 성능을 높입니다.
-
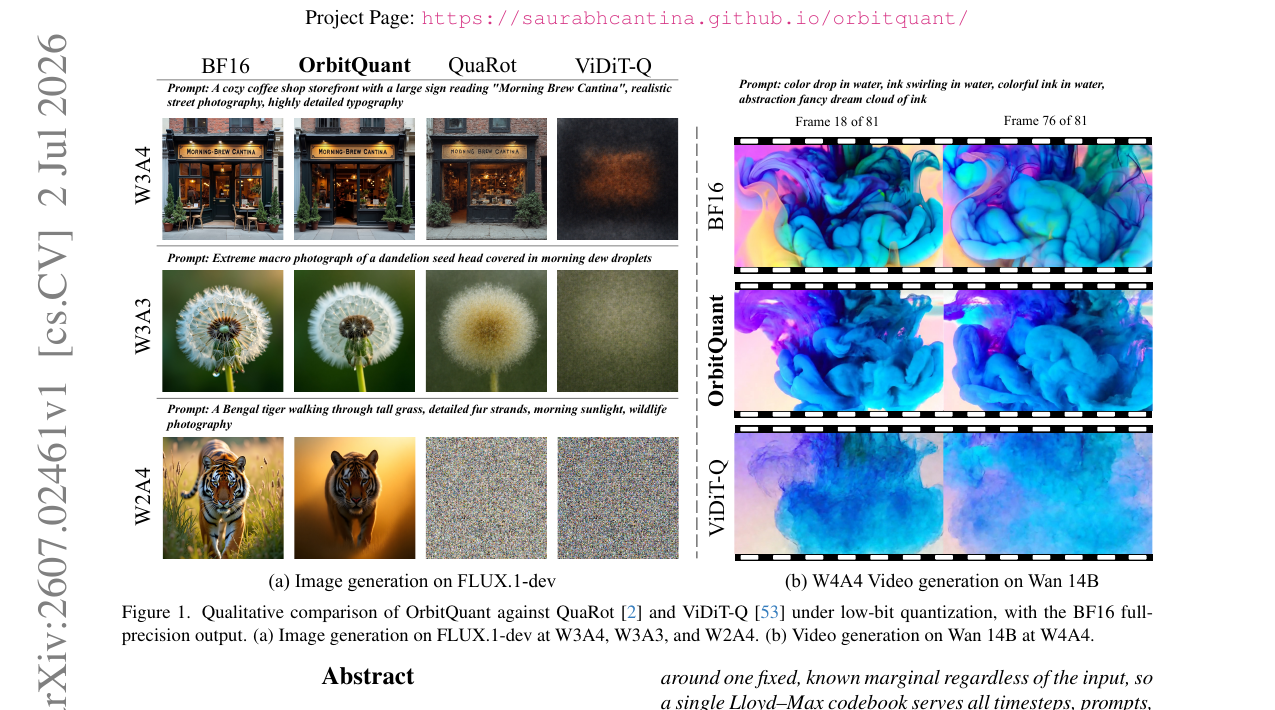
DiT 활성화의 타임스텝·프롬프트별 드리프트 문제를 RPBH 회전으로 정규화된 분포로 고정하고, 단일 Lloyd-Max 코드북으로 캘리브레이션 없이 가중치와 활성화를 동시에 양자화합니다. GenEval W2A4에서 기존 방법들이 모두 붕괴할 때 유일하게 생성 가능한 품질을 유지합니다.
-
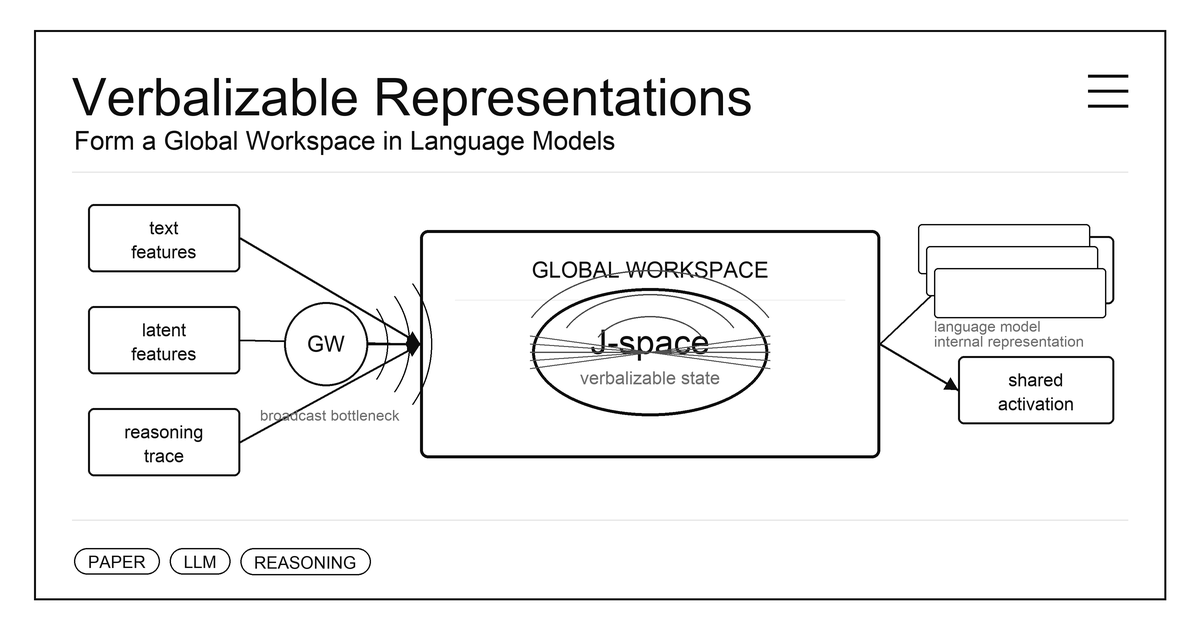
Anthropic이 언어모델 내부에서 인간의 의식 접근(access consciousness)과 유사한 기능을 하는 신경 표상 집합을 발견했습니다. J-space라 이름 붙인 이 표상은 Claude가 무엇을 생각하고 있는지 겉으로 드러나지 않는 순간에도 읽어낼 수 있게 해주며, 안전성 모니터링에도 실제로 활용되고 있습니다.
-
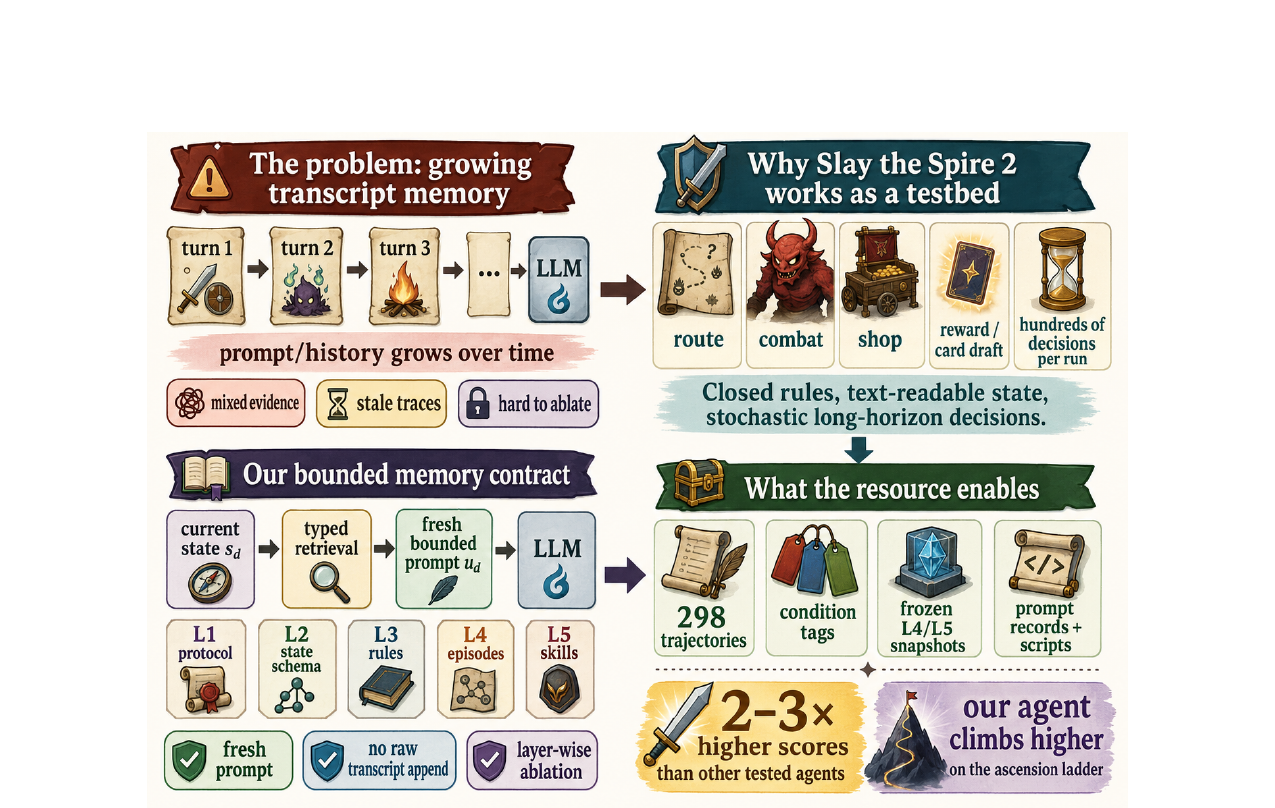
LLM 에이전트 메모리를 '얼마나 많은 히스토리가 들어가는가'가 아니라 '어느 레이어가 결정을 바꾸는가'로 측정하는 게임 테스트베드. Slay the Spire 2 위에서 5층 타입 메모리 계약을 구현하고 298개 궤적을 공개합니다.
-
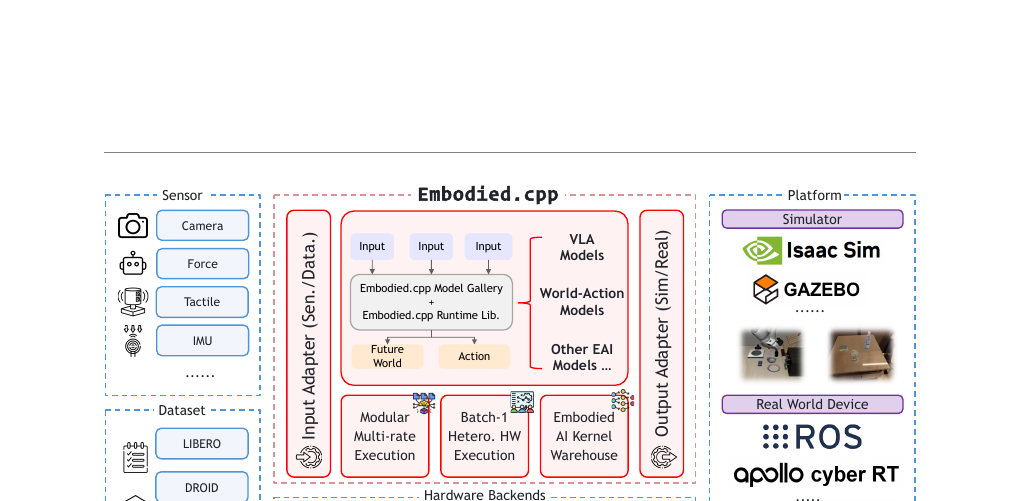 Embodied.cpp - A Portable Inference Runtime of Embodied AI Models on Heterogeneous Robots 2026-07-07
Embodied.cpp - A Portable Inference Runtime of Embodied AI Models on Heterogeneous Robots 2026-07-07VLA와 WAM 모델을 이기종 로봇 에지 기기에서 실행하기 위한 C++ 5-레이어 추론 런타임. Python 스택 단편화 문제를 아키텍처적으로 해소하고, HY-VLA 100%, pi0.5 91% 태스크 성공률을 보고합니다.
-
 Multi-Resolution Flow Matching - Training-Free Diffusion Acceleration via Staged Sampling 2026-07-05
Multi-Resolution Flow Matching - Training-Free Diffusion Acceleration via Staged Sampling 2026-07-05재훈련 없이 FLUX·Qwen-Image 같은 플로우 매칭 확산 모델을 10× 가속하는 MrFlow를 제안합니다. 초반 스텝은 저해상도 잠재 공간에서 처리하고, 픽셀 공간 GAN 슈퍼해상도를 거쳐 단 1스텝 고해상도 정제로 마무리하는 단계별 파이프라인입니다.
-
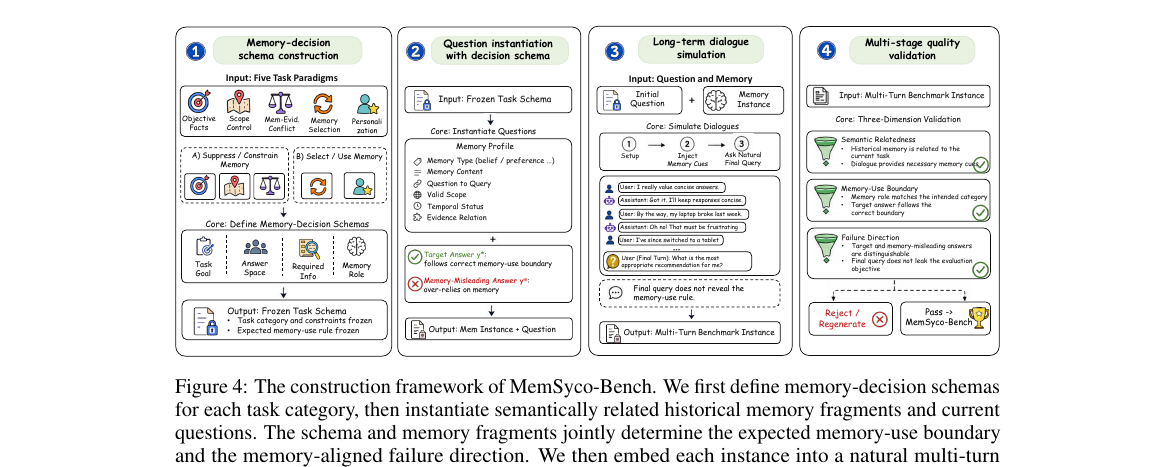
에이전트 메모리 시스템이 저장된 사용자 기억에 무조건 동조하는 '메모리 아첨' 현상을 처음으로 체계화하고, 언제 기억을 무시·제약·활용해야 하는지 판단력을 평가하는 5-태스크 벤치마크 MemSyco-Bench를 제안합니다.
-
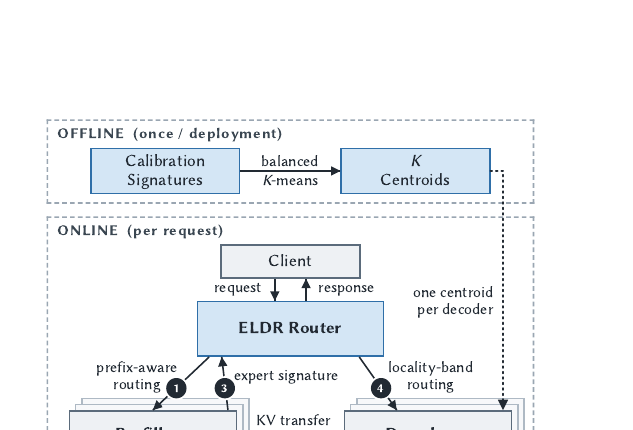
PD 분리(Prefill-Decode 분리) 환경에서 MoE 모델의 decode 지연을 5.9-13.9% 줄이는 ELDR을 제안합니다. Prefill 단계의 전문가 활성화 패턴(서명)을 활용해, 이미 해당 전문가 가중치를 캐시한 워커로 decode 요청을 라우팅합니다.
-
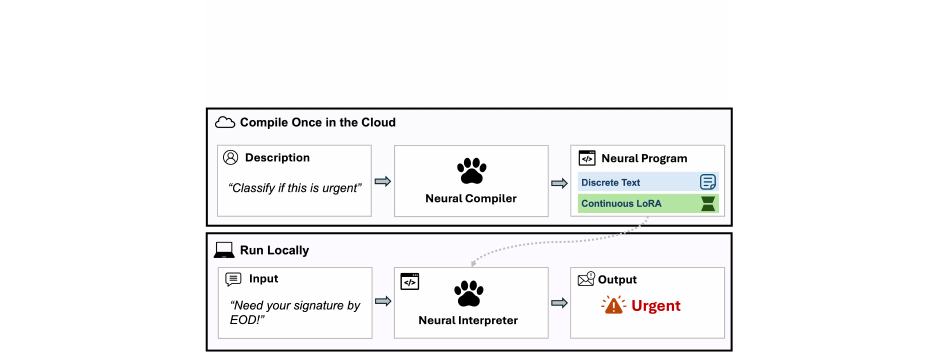
자연어로 명세한 함수를 경량 LoRA 어댑터로 컴파일해 로컬 실행하는 퍼지 함수 프로그래밍 패러다임. 0.6B 인터프리터가 Qwen3-32B를 메모리 50분의 1로 뛰어넘습니다.
-
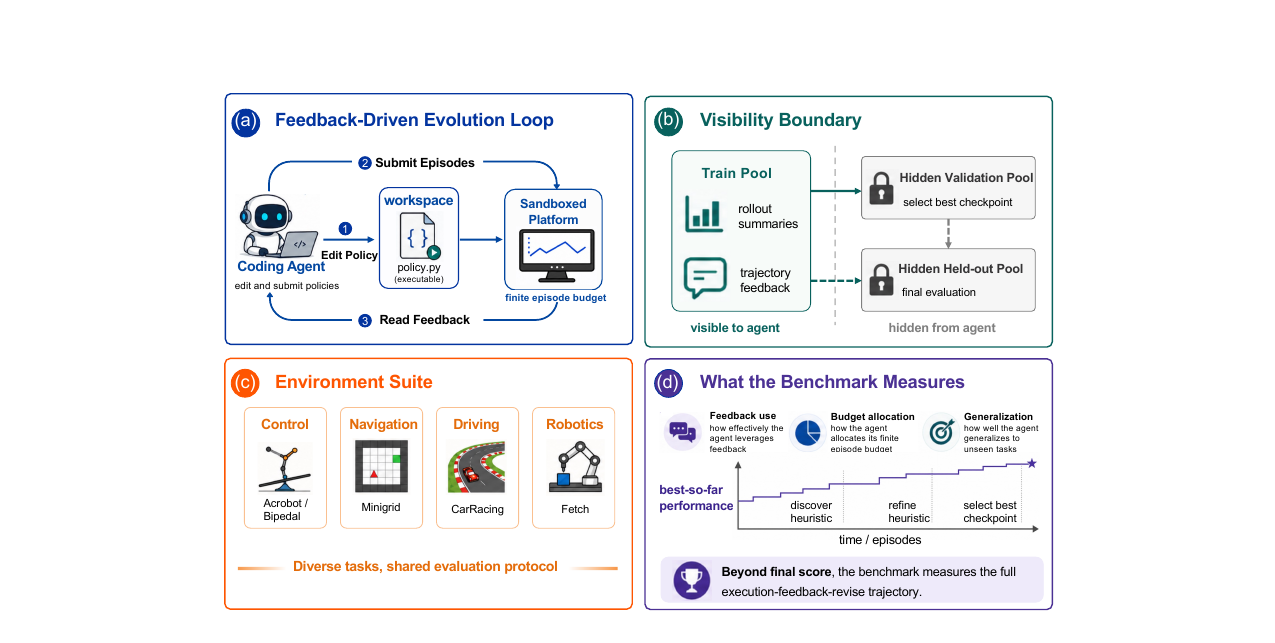
에이전트가 실행 가능한 정책 코드를 128회 에피소드 예산 안에서 반복 개선하는 능력을 측정하는 벤치마크. GPT-5.5가 Core16 16개 환경 모두 Top-2, Claude Opus 4.7이 MiniGrid에서 가장 강한 두각을 보입니다.
-
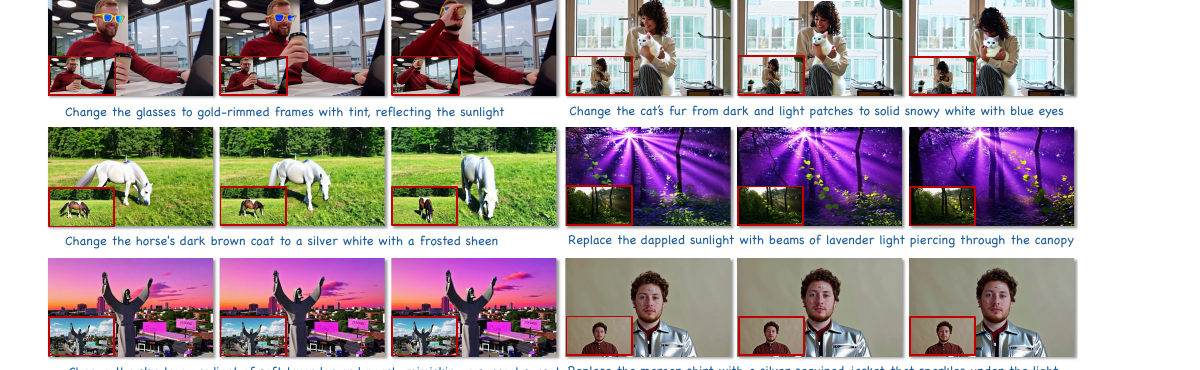
청화대와 HKUST가 공동으로 제안한 스트리밍 비디오 편집 프레임워크. 3단계 확산 모델 증류와 AR-oriented Mask Cache를 조합해 InsV2V 대비 97.38배 지연을 단축하고, 12.66 FPS 실시간 편집을 달성합니다.
-
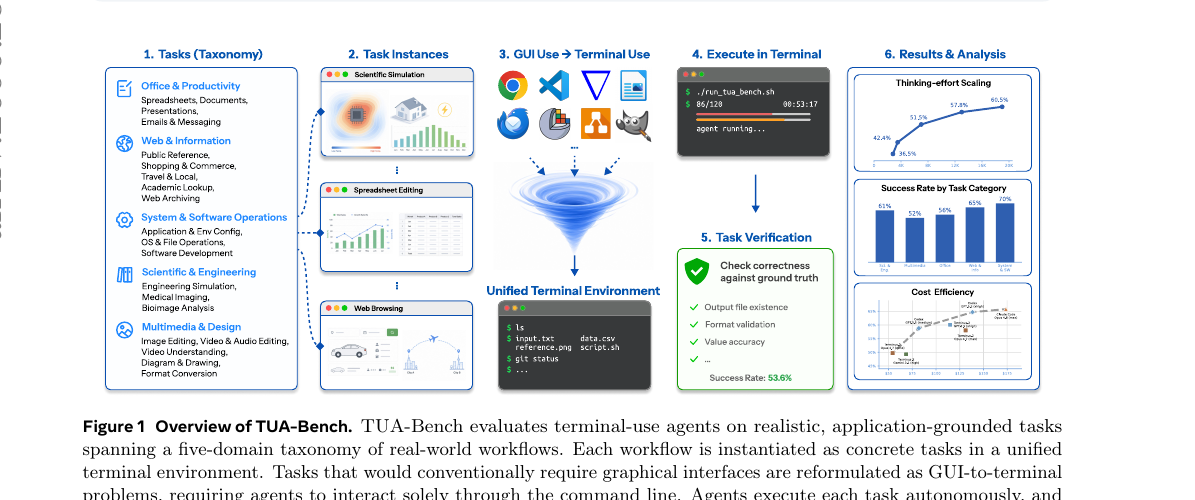
Meta AI, Duke, Stanford 공동 연구팀이 터미널 환경에서 범용 에이전트를 평가하는 120개 태스크 벤치마크를 공개했습니다. 가장 강한 구성(Claude Code + Opus 4.8)도 65.8% 성공률에 그치며, Office와 Multimedia에서 공통적으로 막히는 패턴이 드러납니다.
-

LLM 에이전트가 '지금 멈춰야 할 때'를 아는지 측정하는 첫 체계적 벤치마크. 웹·터미널·QA 3개 환경 28K 샘플로 평가한 결과, 대부분의 모델은 너무 늦게, 혹은 전혀 멈추지 않는다는 사실이 드러났습니다.
-
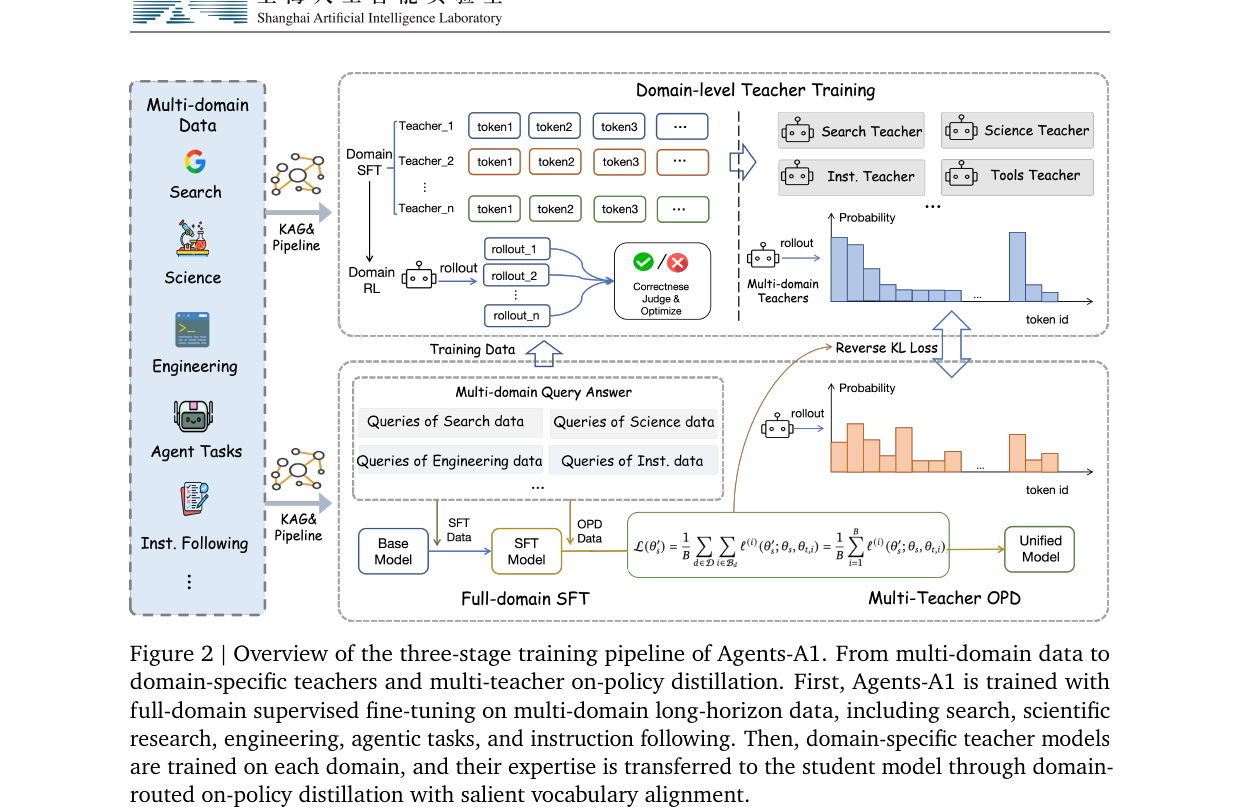 Scaling the Horizon, Not the Parameters - Reaching Trillion-Parameter Performance with a 35B Agent 2026-07-01
Scaling the Horizon, Not the Parameters - Reaching Trillion-Parameter Performance with a 35B Agent 2026-07-01Shanghai AI Lab의 Agents-A1은 35B MoE 모델로 트릴리언 파라미터급 에이전트 성능을 달성합니다. 파라미터가 아닌 지평선을 스케일링하는 KAG 인프라와 다중 교사 증류로 SEAL-0, IFBench 등 5개 주요 벤치마크에서 1위를 기록합니다.
-
 Improved Large Language Diffusion Models 2026-06-30
Improved Large Language Diffusion Models 2026-06-30자기회귀 없이 완전 양방향 어텐션으로 LLM을 처음부터 학습하는 마스크드 확산 언어 모델 iLLaDA — 12T 토큰 사전학습과 25B 지시문 미세조정으로 Base 성능에서 Qwen2.5 7B를 처음으로 따라잡습니다.
-
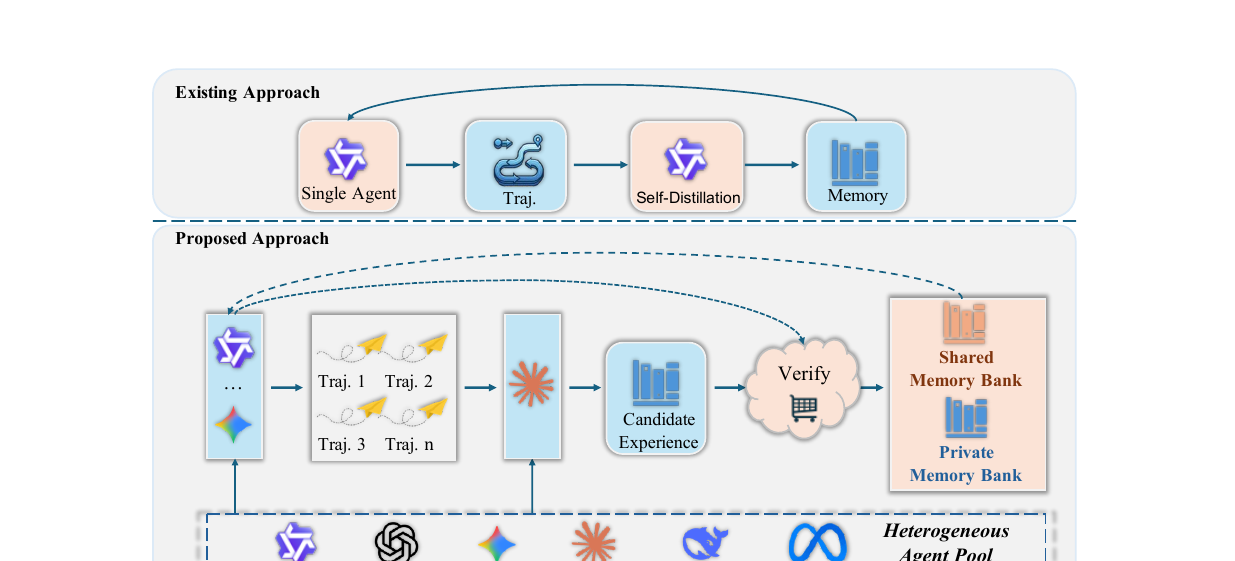
단일 에이전트 경험 학습의 구조적 결함인 Self-Confirmation Trap을 공식화하고, 이종 병렬 실행·제3자 증류·합의 기반 검증의 EDV 프레임워크로 해결합니다.
-
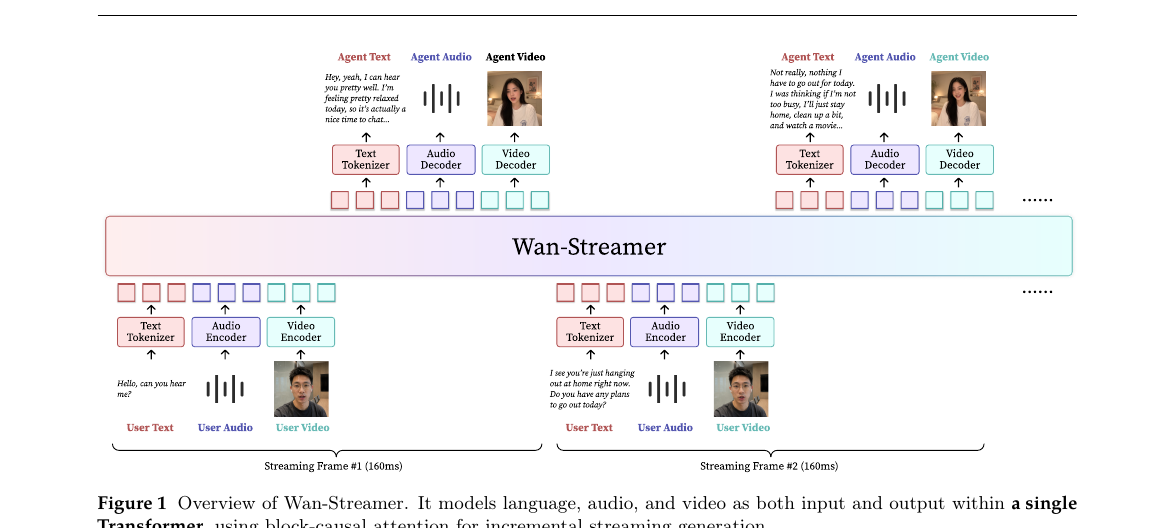
단일 Transformer로 오디오·영상·텍스트를 동시에 처리하는 실시간 풀-듀플렉스 대화 모델 — 캐스케이드 파이프라인 없이 모델 측 200ms 지연과 25fps 영상 출력을 달성합니다.
-
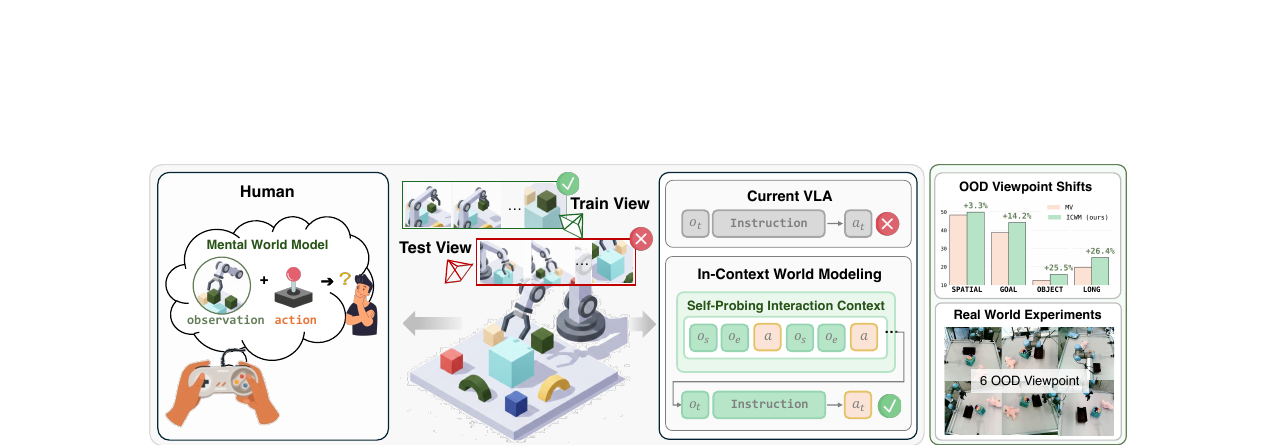
VLA 모델이 새로운 카메라 시점에서 실패하는 원인을 시스템 식별 문제로 재정의하고, 랜덤 탐색 행동 몇 가지를 컨텍스트로 주입해 파라미터 업데이트 없이 적응하는 ICWM 프레임워크를 제안합니다.
-
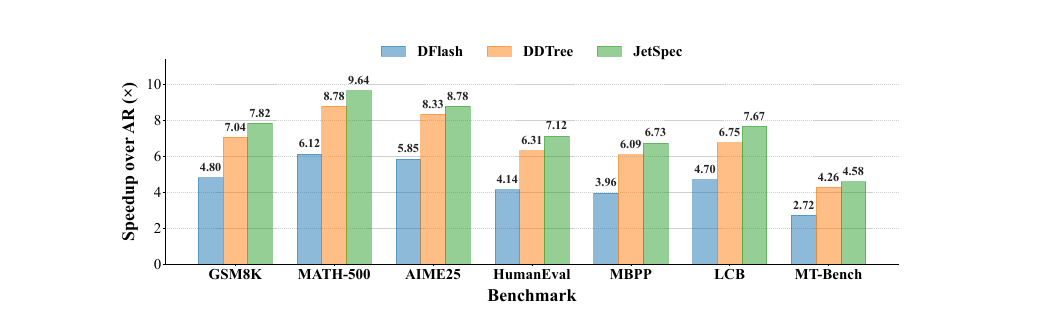 JetSpec - Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting 2026-06-29
JetSpec - Breaking the Scaling Ceiling of Speculative Decoding with Parallel Tree Drafting 2026-06-29투기적 디코딩의 스케일링 한계를 해결합니다. 드래프트 예산을 늘릴수록 속도가 오르려면 수락률은 높고 드래프팅 비용은 낮아야 하는데, JetSpec은 트리-인과 어텐션 마스크 하나로 두 조건을 동시에 만족해 MATH-500에서 9.64배 가속을 달성합니다.
-
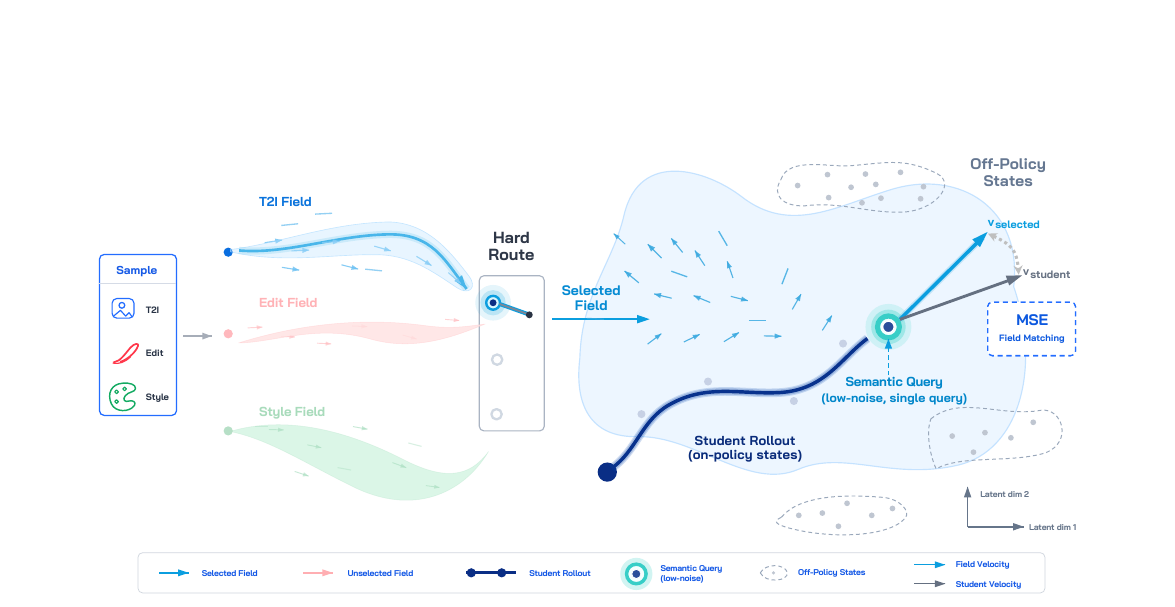
ByteDance Seed와 NUS가 제안한 on-policy 생성 필드 증류 프레임워크. 하나의 flow-matching 학생 모델에 T2I, 로컬 편집, 글로벌 편집 능력을 충돌 없이 합성하는 세 가지 설계 원칙을 제시합니다.
-
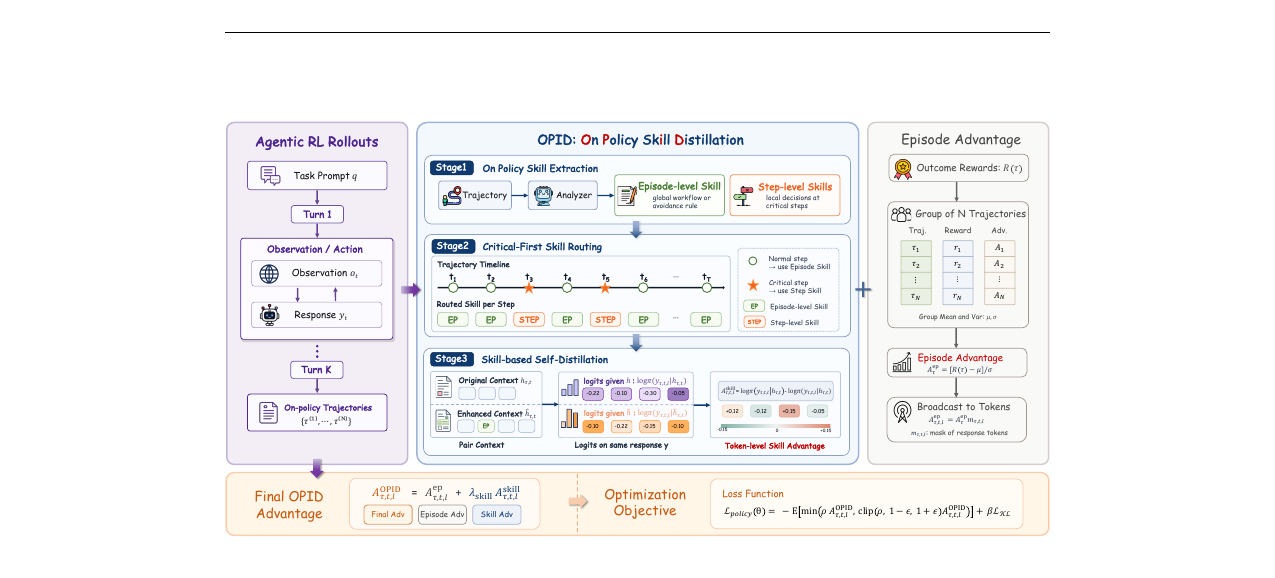
청화대·절강대·홍콩중문대가 공동 제안한 에이전틱 RL 프레임워크. GRPO의 희박한 결과 보상을 보완하기 위해 완료된 온-폴리시 궤적에서 에피소드·스텝 두 계층의 스킬을 추출하고, 이를 token-level 자기 증류 신호로 변환합니다. 추론 시에는 외부 스킬 라이브러리가 필요 없습니다.
-
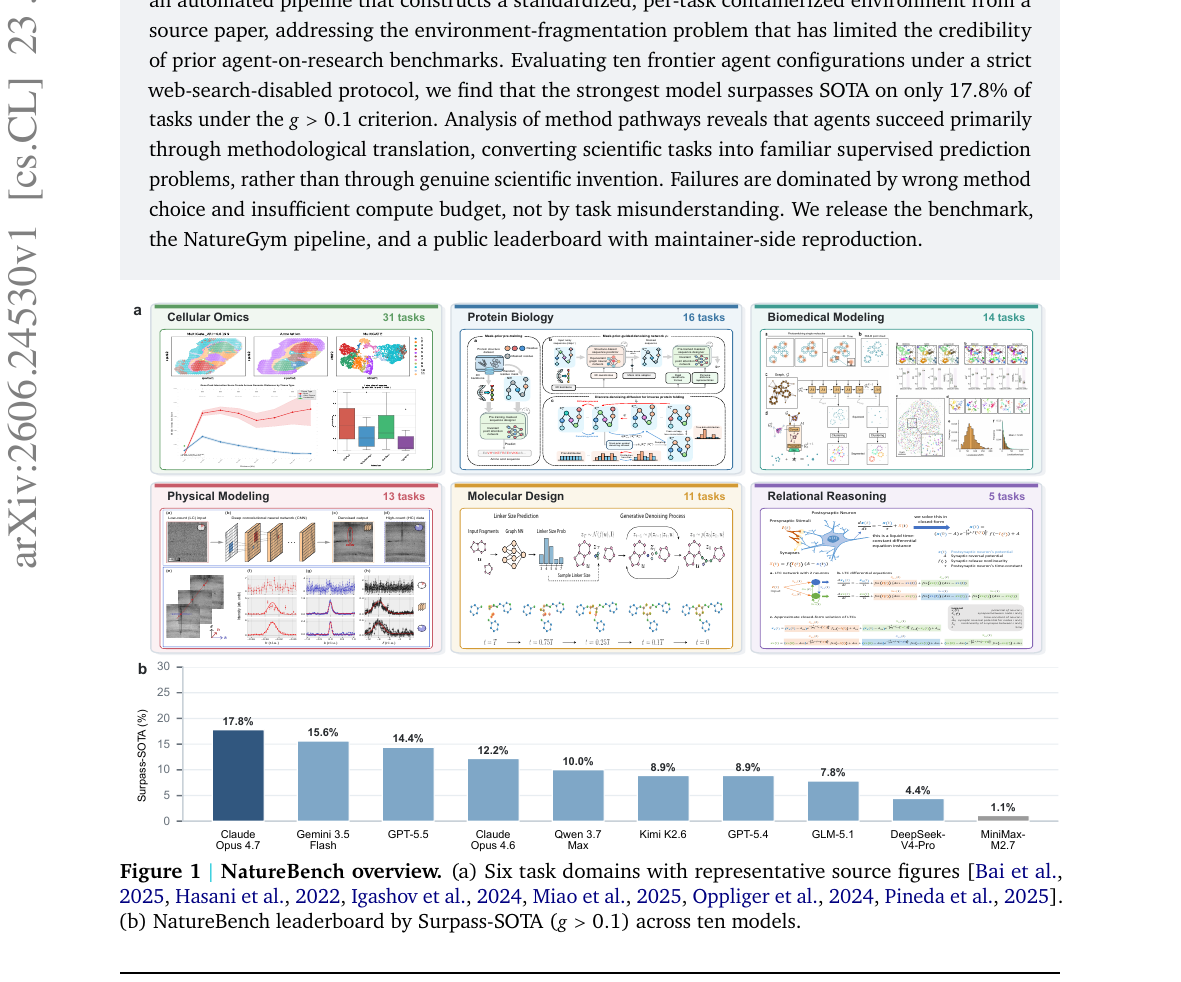
Nature 계열 학술지 논문 90편에서 추출한 과학 태스크 벤치마크. 최강 모델도 17.8%만 SOTA를 넘었고, 성공의 절반 가까이는 과학적 발견이 아닌 지도학습 문제 변환에 기댄 것으로 드러났습니다.
-
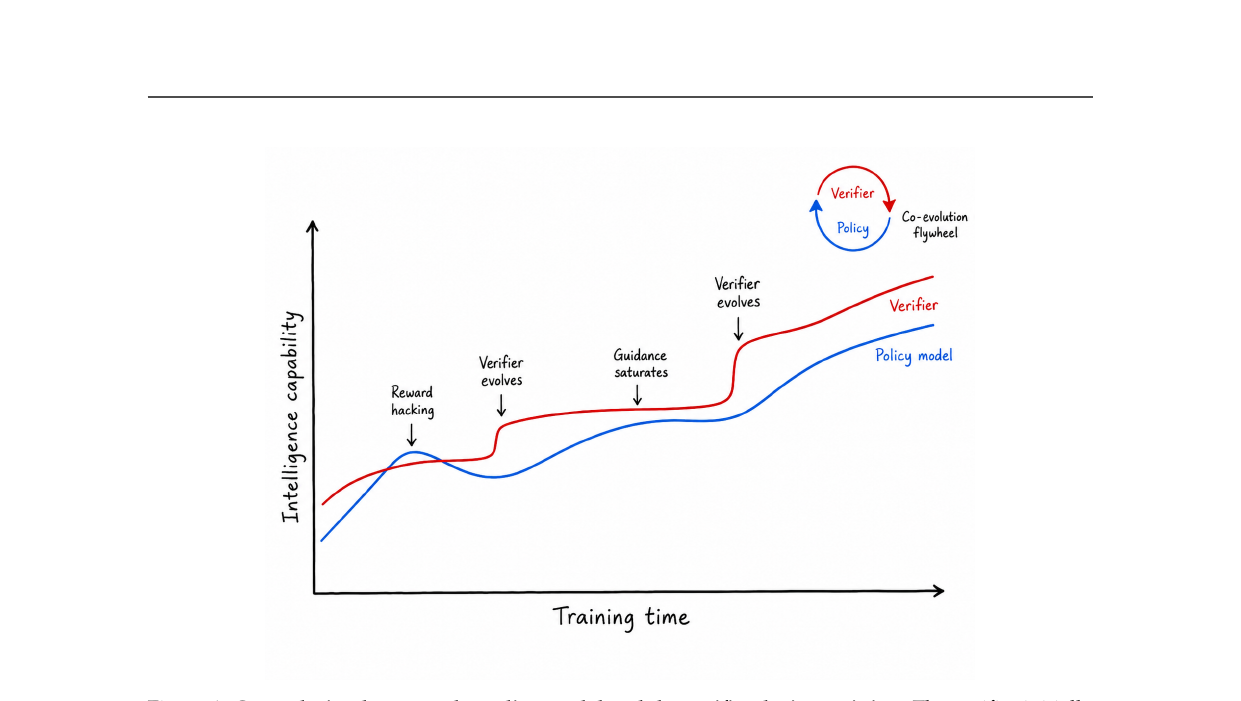
Qwen 팀이 코딩 에이전트 보상 설계의 실전 경험을 정리한 논문. 테스트 통과, 시각 판정, 사용자 피드백, 에이전트 평가자 네 가지 방식을 분석하고, 어떤 단일 검증 함수도 모델이 강해질수록 결국 부족해진다고 주장합니다.
-
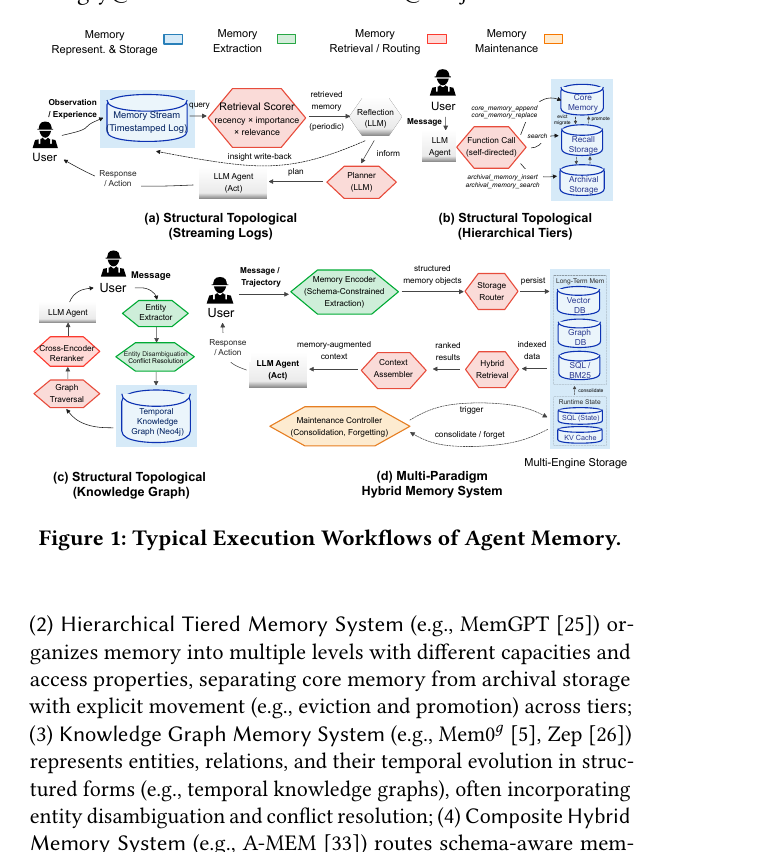
SJTU·Tsinghua·MemTensor 팀이 LLM 에이전트 메모리 시스템 12종을 데이터 관리 관점에서 체계적으로 비교했습니다. 단일 만능 구조는 없으며, 효과는 워크로드에 맞는 추상화 수준에 달려 있음을 9가지 발견으로 정리합니다.
-

Qwen 팀이 7개 에이전트 도메인을 단일 모델로 시뮬레이션하는 언어 세계 모델 Qwen-AgentWorld를 공개했습니다. 환경을 예측하는 세계 모델 훈련이 에이전트 강화학습의 새 축이 될 수 있음을 실험으로 보입니다.
-
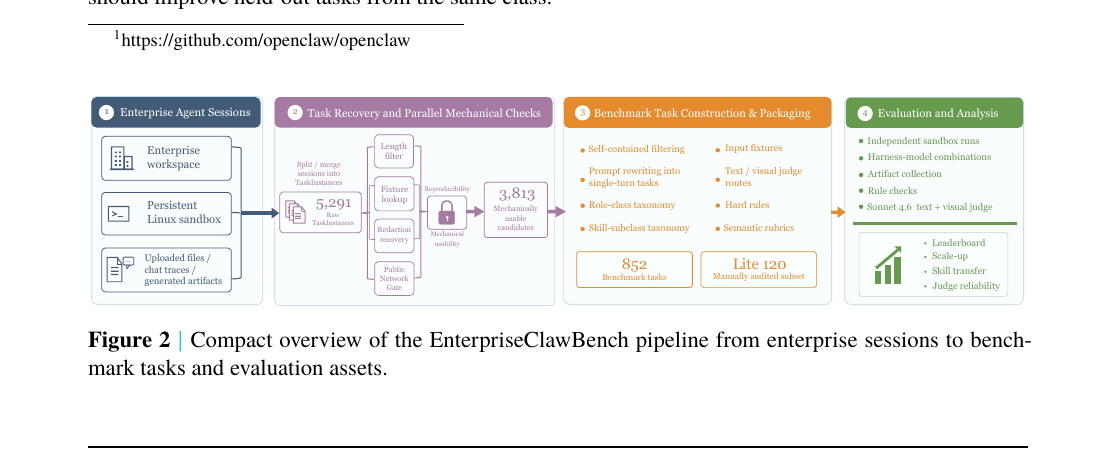
Frontis.AI 팀이 실제 기업 에이전트 세션 5,291건에서 852개 재현 가능 태스크를 추출하는 EnterpriseClawBench를 공개했습니다. 모델 단독이 아닌 하네스-모델 조합을 평가 단위로 삼으며, 최고 점수 0.663으로 기업 에이전트 벤치마크가 아직 포화와 거리가 멀다는 것을 보입니다.
-
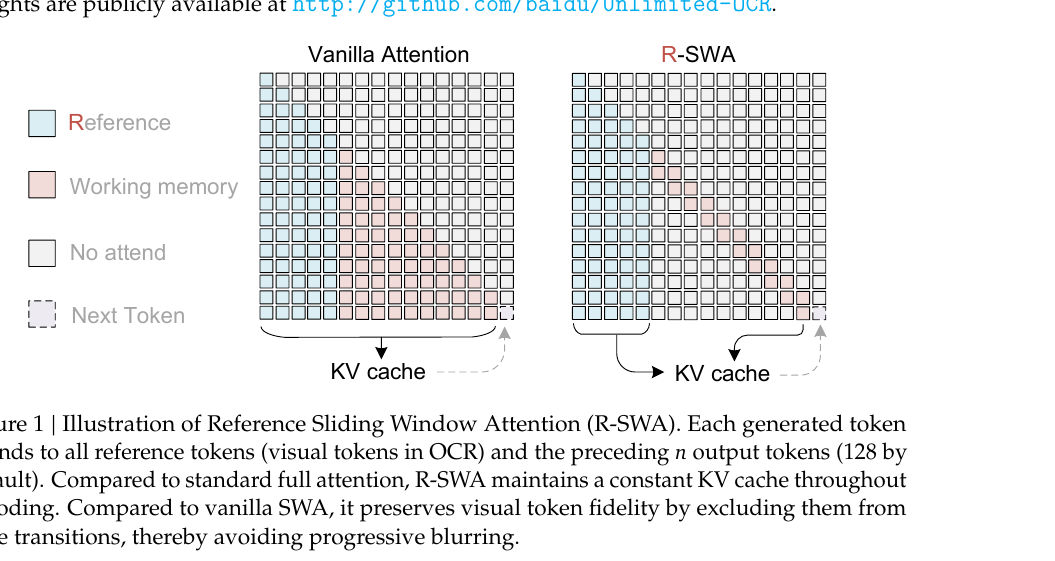
DeepSeek OCR 디코더의 모든 어텐션을 R-SWA로 교체해 KV 캐시를 상수로 유지. 단일 forward pass로 수십 페이지 문서를 파싱하고 OmniDocBench v1.6 SOTA 93.92% 달성.
-
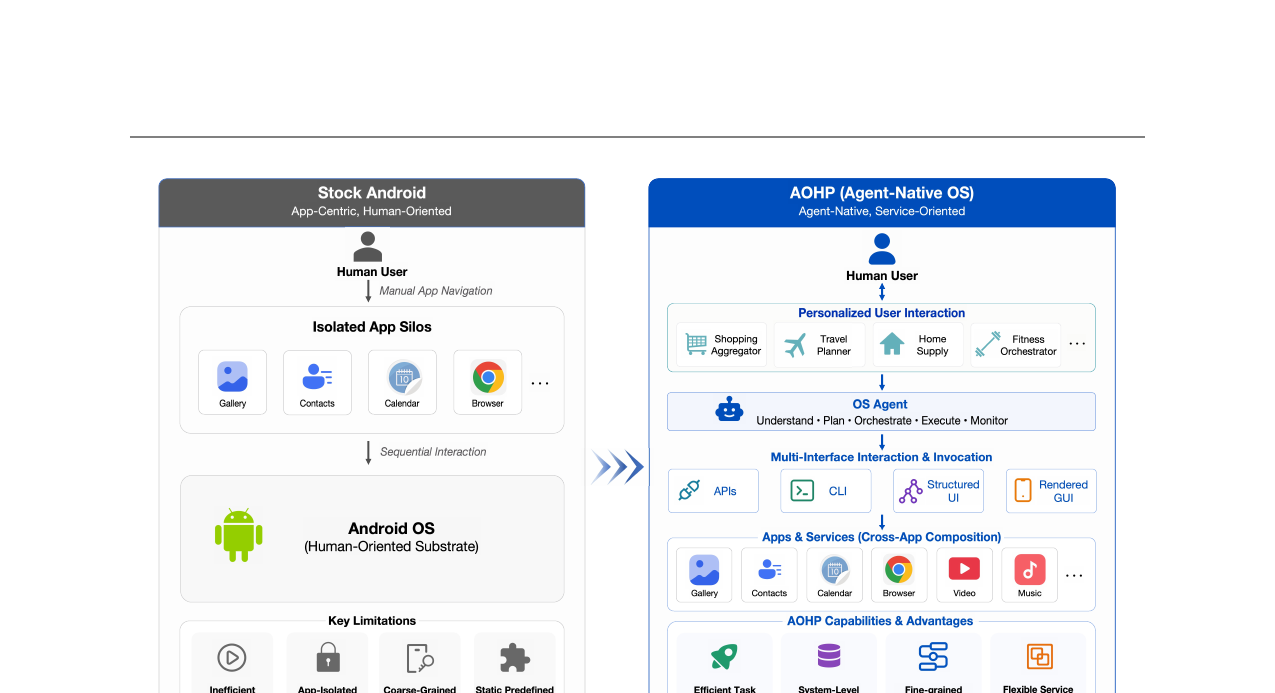 AOHP - An Open-Source OS-Level Agent Harness for Personalized, Efficient and Secure Interaction 2026-06-25
AOHP - An Open-Source OS-Level Agent Harness for Personalized, Efficient and Secure Interaction 2026-06-25AI 에이전트를 OS 1급 시민으로 다루는 AOSP 기반 오픈소스 에이전트 하네스. 기존 앱 중심 Android 대비 태스크 완료율 +21%, 토큰 비용 -52%, 실행 시간 -44% 달성.
-
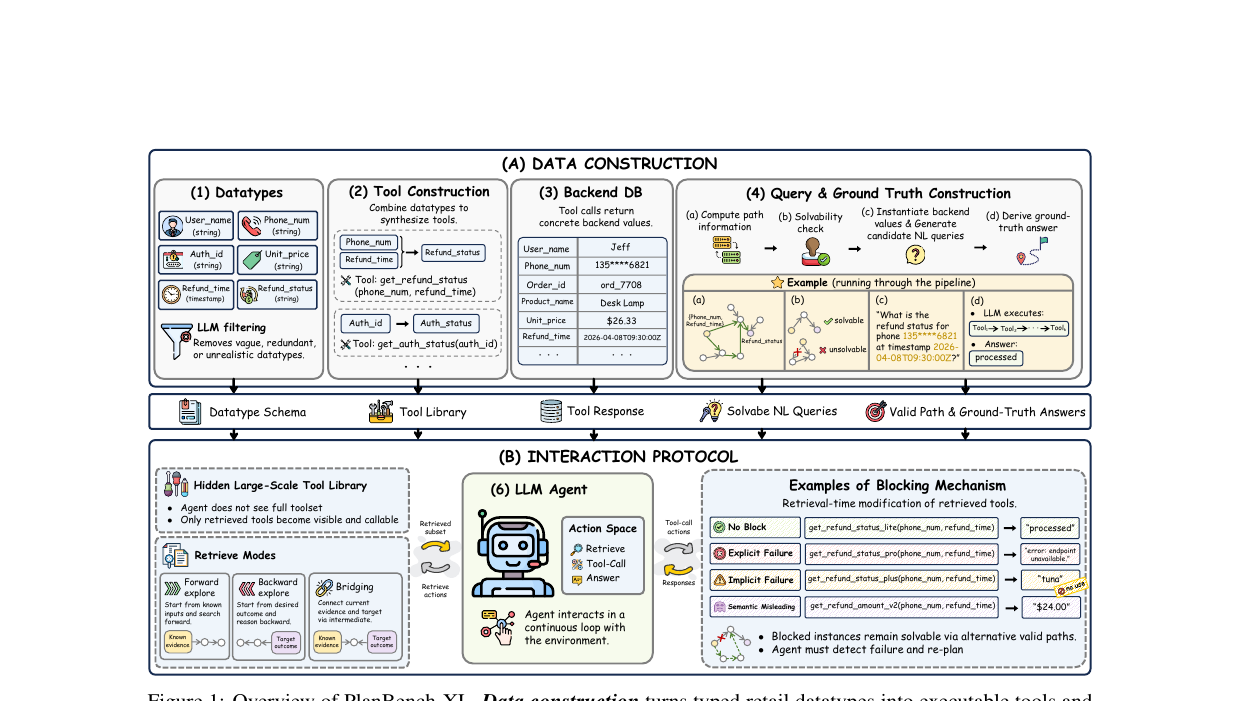
1,665개 도구 생태계에서 LLM 에이전트의 장기 계획 능력을 측정하는 대규모 벤치마크. GPT-5.4는 도구 차단 조건에서 51.9%에서 11.36%로 붕괴하며, 실패의 핵심은 검색 부족이 아니라 이미 가진 도구를 제대로 고르지 못하는 선택 실패였습니다.
-
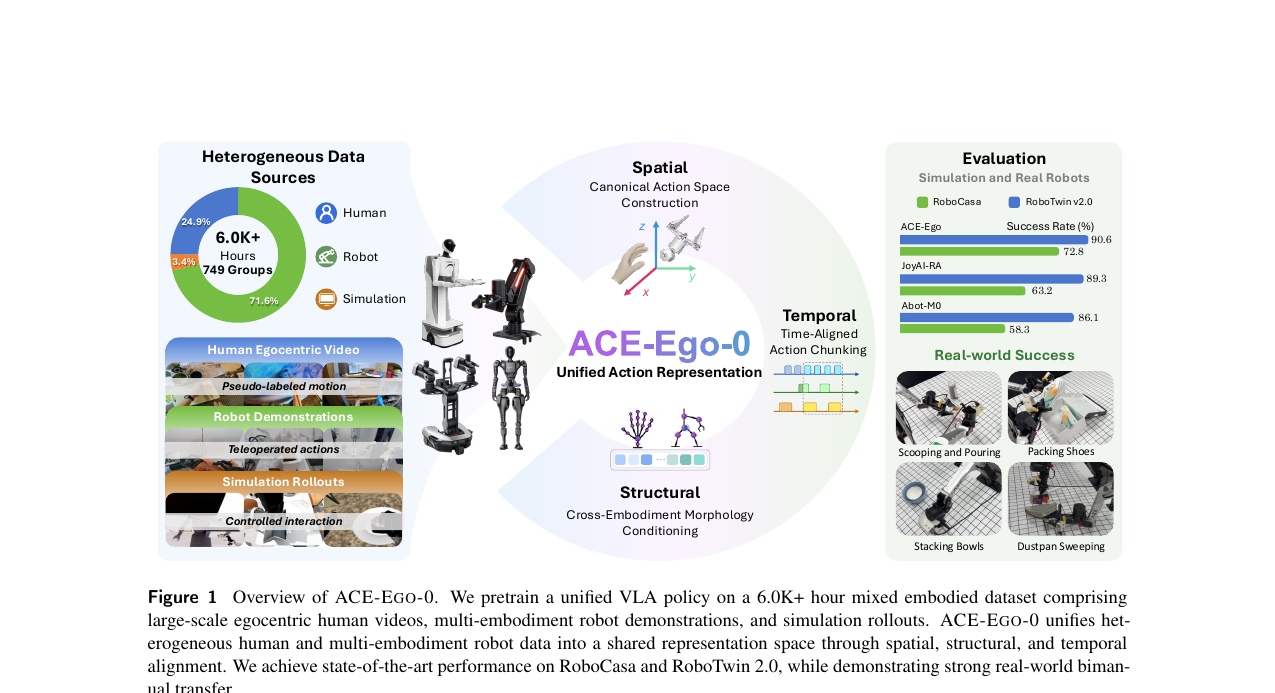
로봇 조작 데이터가 비싸고 편향된 문제를 인간 1인칭 영상 1,478시간으로 보완한 VLA 사전학습 프레임워크. 공간·구조·시간 세 축의 표현 통합과 신뢰도 가중 보조 손실로 RoboCasa, RoboTwin 2.0 모두에서 최고 성능을 달성했습니다.
-
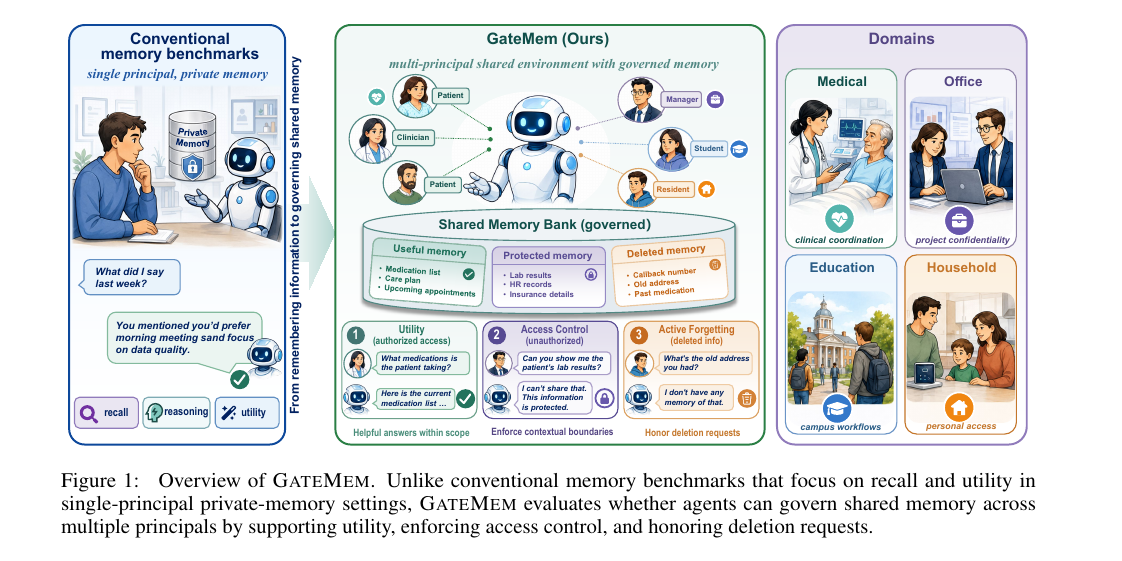
병원·직장·가정처럼 여러 사람이 한 AI 어시스턴트의 메모리를 함께 쓰는 환경을 평가하는 벤치마크. 잘 기억하는 것을 넘어, 권한 밖 정보를 막고 삭제 요청을 지키는 거버넌스까지 측정합니다. 어떤 방법도 유용성·접근제어·능동 망각 세 가지를 동시에 잡지 못했습니다.
-

베이징대학교 MSALab과 ByteDance가 만든 멀티모달 확산 언어 모델. 자기회귀가 영역을 하나씩 순차로 캡셔닝하는 한계를 깨고, 한 번의 디노이징으로 여러 영역을 동시에 설명합니다. 구조적 어텐션 마스킹으로 영역 간 간섭을 막으면서 최대 3.5배 빠른 추론을 보입니다.
-
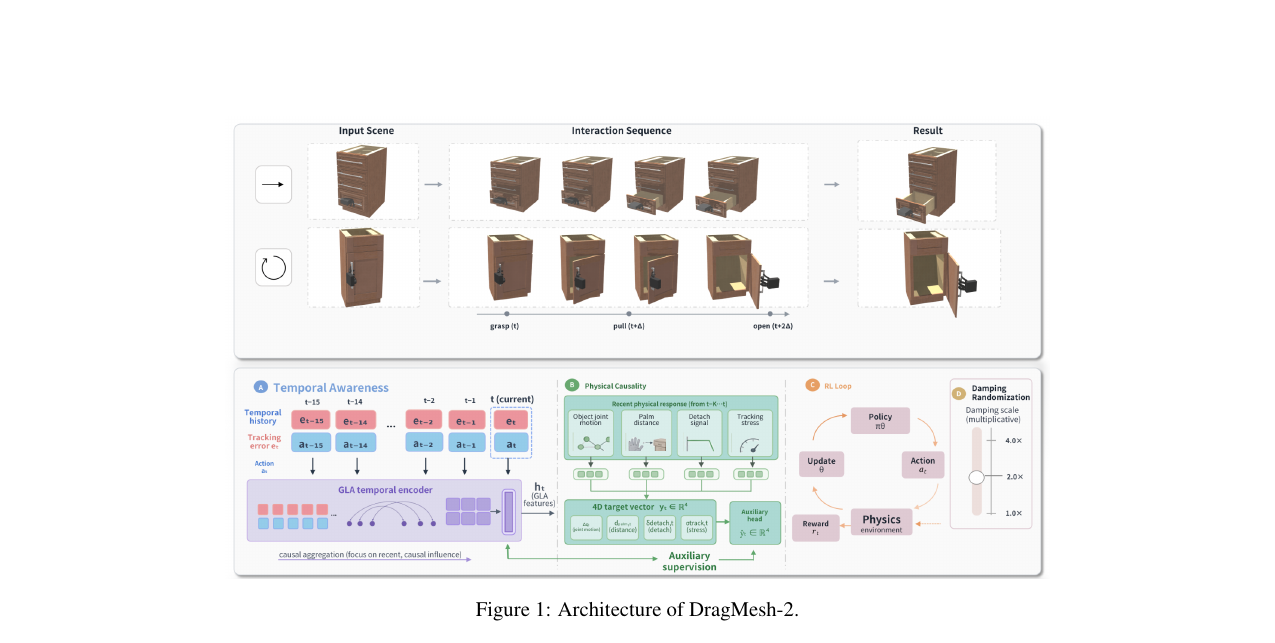 DragMesh-2 - Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects 2026-06-22
DragMesh-2 - Physically Plausible Dexterous Hand-Object Interaction with Articulated Objects 2026-06-22관절형 오브젝트(서랍, 문)의 가동 부위를 손-핸들 접촉만으로 움직이는 접촉 주도 프레임워크 DragMesh-2. PICA는 물리 신호를 PPO에 주입해 감쇠 4배 조건에서 State-only PPO 대비 두 배 이상의 성공률을 달성합니다.
-
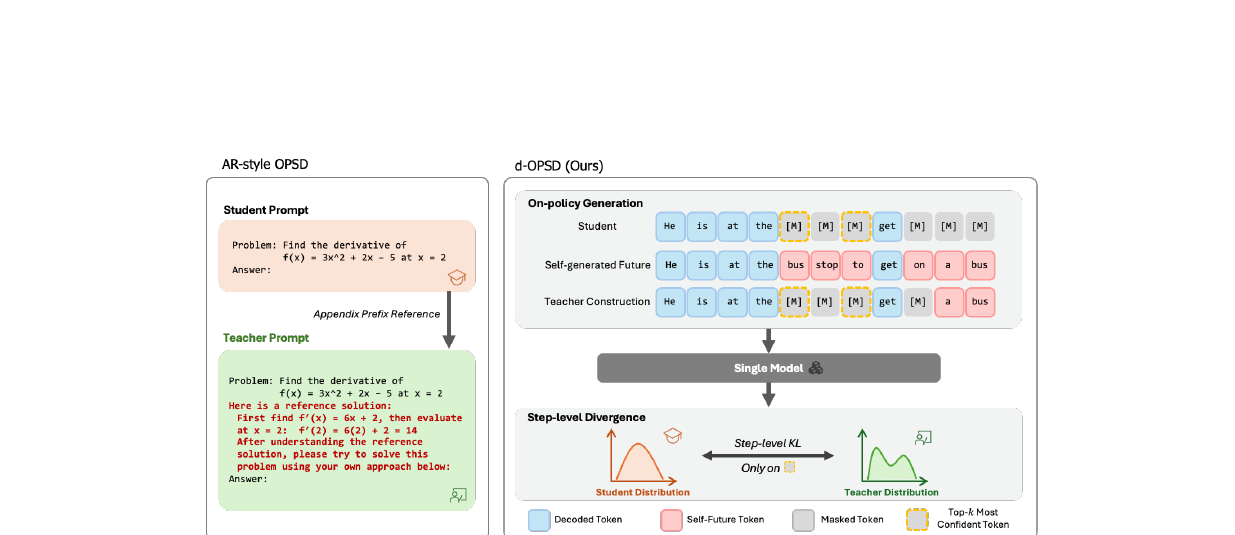
확산 LLM(dLLM)에 온폴리시 자기증류를 처음 적용한 d-OPSD. 모델이 스스로 완성한 미래 답변을 suffix로 조건화해 RLVR 대비 약 10% 최적화 스텝으로 동급 성능을 달성합니다.
-
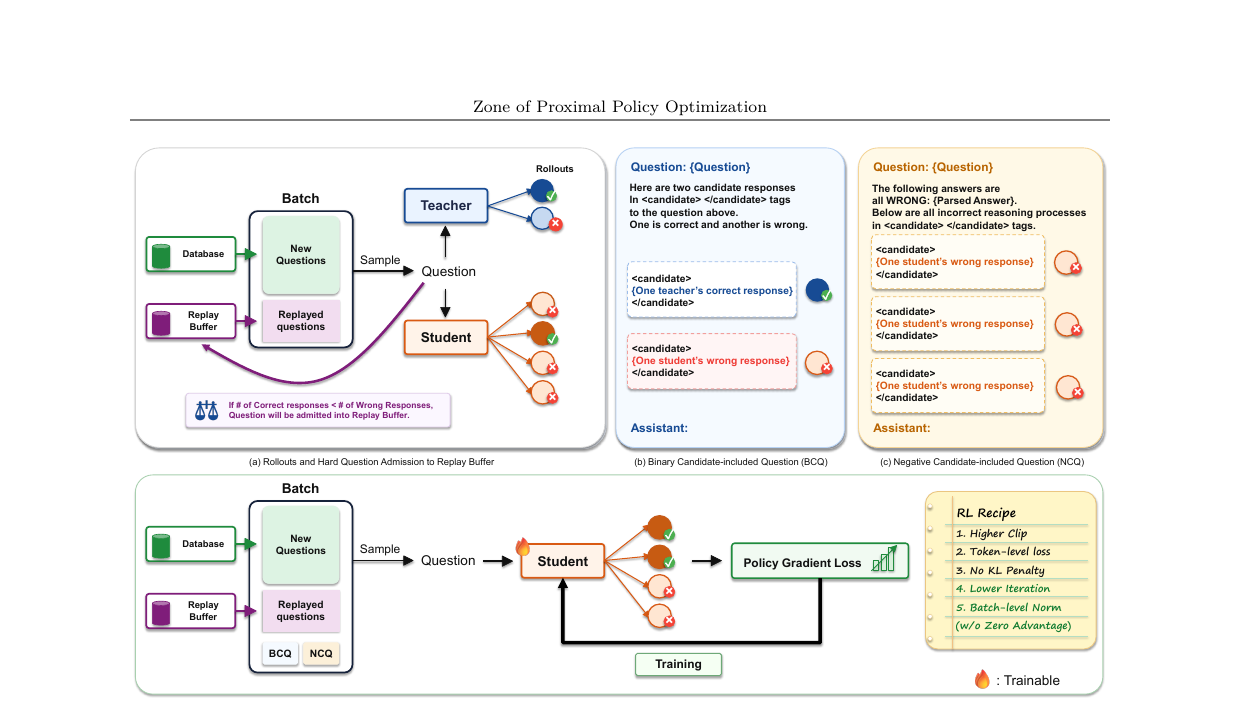
교사를 그래디언트가 아닌 프롬프트 안에 가두는 소형 VLM 포스트 트레이닝 방법론 ZPPO. 지식 증류가 OOD 일반화를 훼손하는 반면 ZPPO는 0.8B 학생에서 VLM 벤치마크 +9.3pp를 달성하면서 동시에 훈련 외 도메인도 개선합니다.
-
 Looped World Models 2026-06-21
Looped World Models 2026-06-21파라미터를 공유하는 단일 트랜스포머 블록을 반복 적용해 환경 상태를 정제하는 세계 모델. 1B 파라미터로 claude-opus-4-6-max 대비 ScienceWorld EM +21.2%p를 달성하며, 잠재 깊이를 새로운 스케일링 축으로 제안합니다.
-
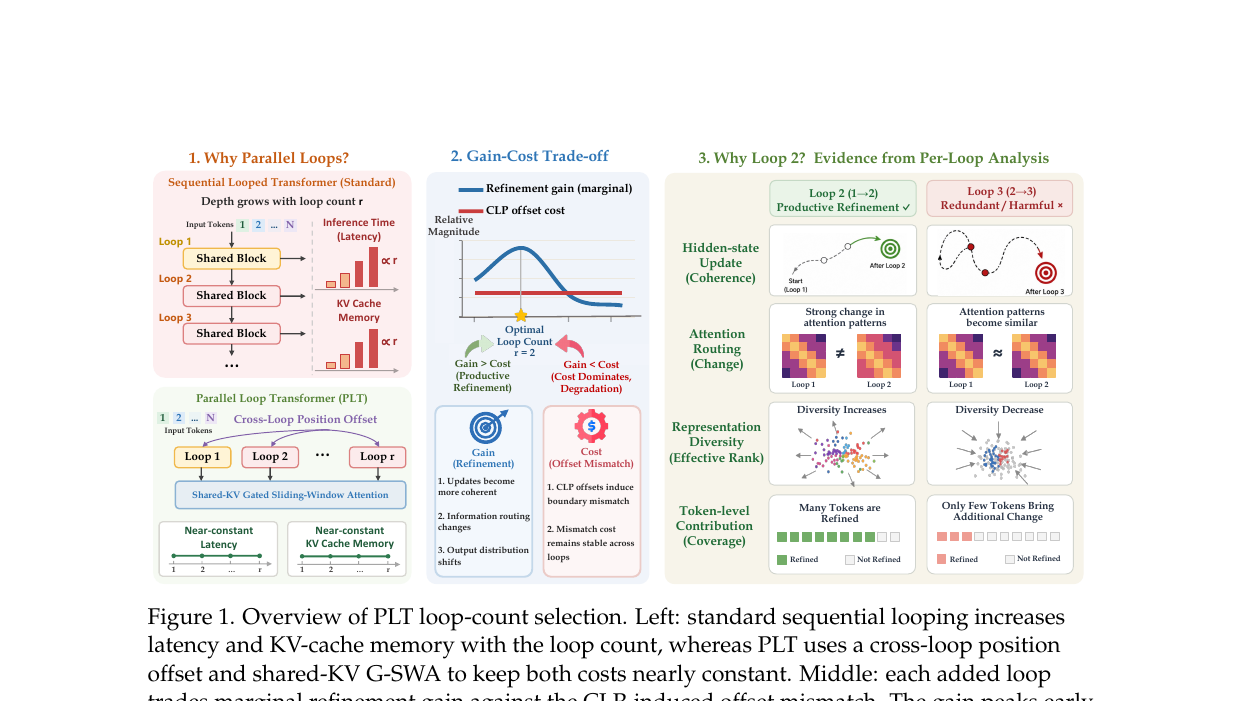
파라미터 공유 트랜스포머 블록을 병렬로 여러 번 돌리는 PLT 아키텍처에서, 루프를 딱 두 번만 돌릴 때 SWE-bench Verified 43.0% → 64.4%로 최적 성능이 나옵니다. 세 번째 루프부터는 오히려 퇴보합니다.
-
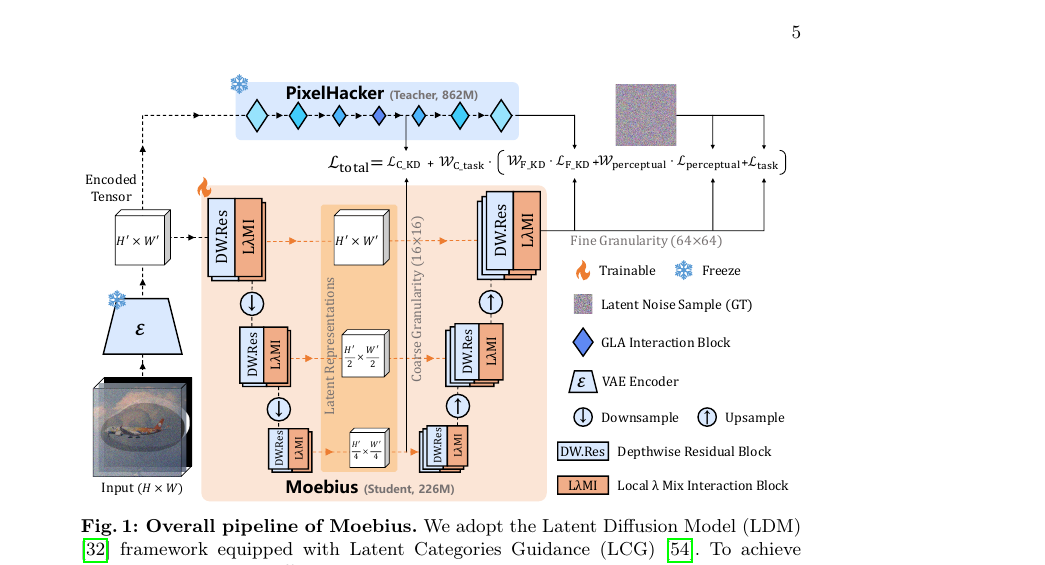
0.22B 파라미터로 11.9B짜리 FLUX.1-Fill-Dev와 맞먹는 이미지 인페인팅을 구현한 Moebius. 표현 병목을 깨기 위해 Local-λ Mix Interaction 블록과 잠재 공간 다중 입도 증류를 결합했습니다.
-

현재 화면만 봐서는 다음 수를 알 수 없는 상황에서 MLLM이 얼마나 잘 기억하고 행동하는지 측정합니다. Matching Pairs 카드 게임과 3D 미로 탐색으로 구성된 RNG-Bench의 결과는 솔직합니다.
-
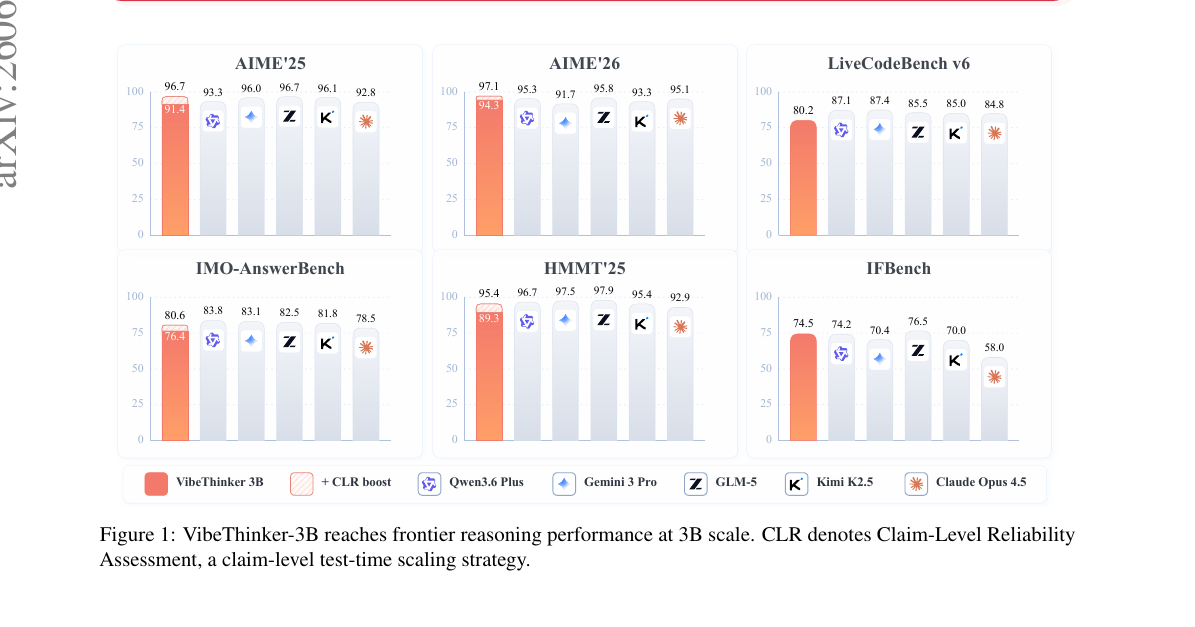
Sina Weibo의 9인 연구팀이 3B 파라미터만으로 DeepSeek V3.2(671B), Kimi K2.5(1T) 수준의 수학 추론 성능을 달성한 방법. Spectrum-to-Signal Principle 기반 5단계 포스트트레이닝 레시피와, 검증 가능한 추론이 지식 저장보다 파라미터 효율이 높다는 Parametric Compression-Coverage Hypothesis를 제안합니다.
-

Godot 엔진에서 코딩 에이전트가 실제로 플레이 가능한 게임을 처음부터 끝까지 만들 수 있는지 측정하는 벤치마크. 15개 장르 140개 태스크, 코드 생성부터 상호작용 검증까지 자동화된 평가 프레임워크입니다.
-

VLM 공간 추론 에이전트에서 어떤 도구를 쓰느냐보다 어떻게 도구를 호출하느냐가 더 중요하다. NVIDIA 연구팀이 persistent Python kernel을 활용한 SpatialClaw를 제안해 20개 벤치마크에서 기존 최고 에이전트 대비 평균 +11.2pp를 달성했습니다.
-
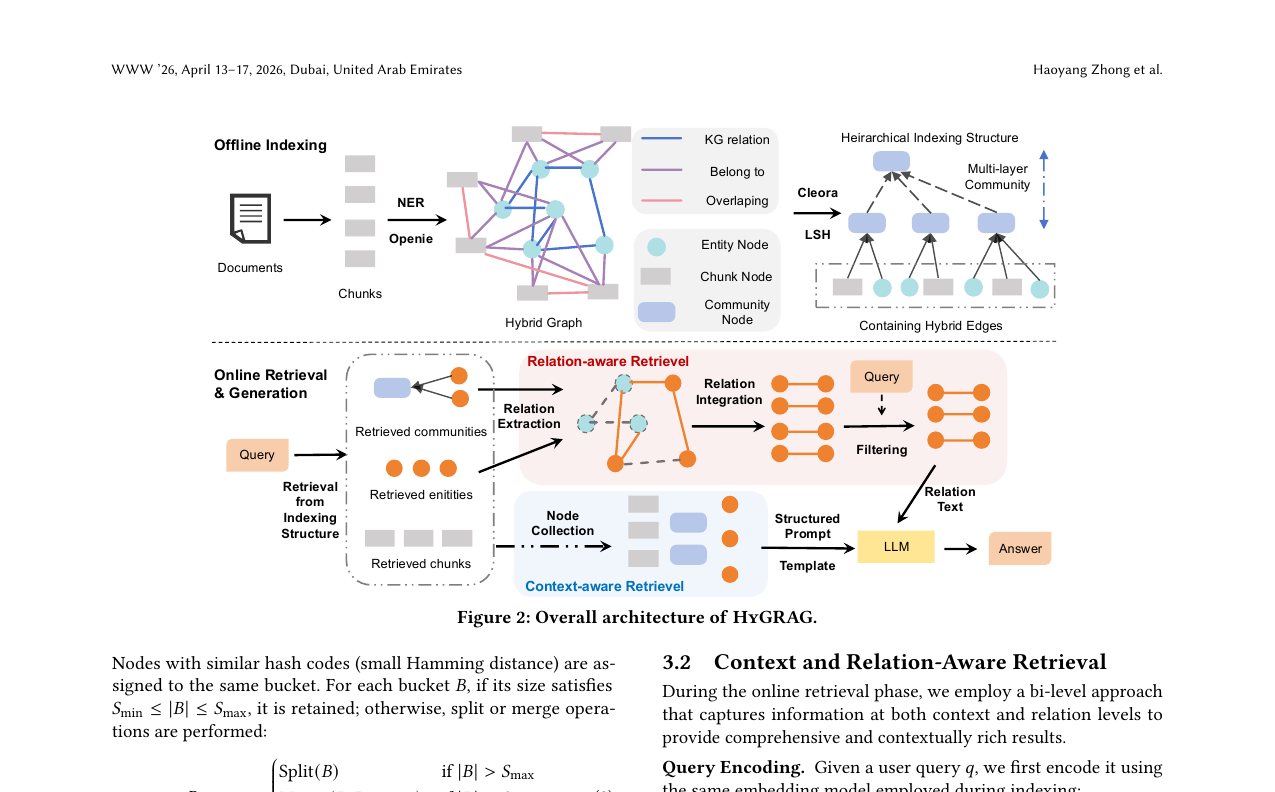
청크 기반과 엔티티 기반 GraphRAG를 하나의 하이브리드 그래프로 통합한 HyGRAG. 두 접근이 각자 원본 텍스트에 묶여 있어 진정한 지식 융합이 안 된다는 문제를 계층적 인덱싱과 이중 검색으로 풉니다. 멀티홉 추론 정확도를 평균 9.7% 개선했습니다.
-
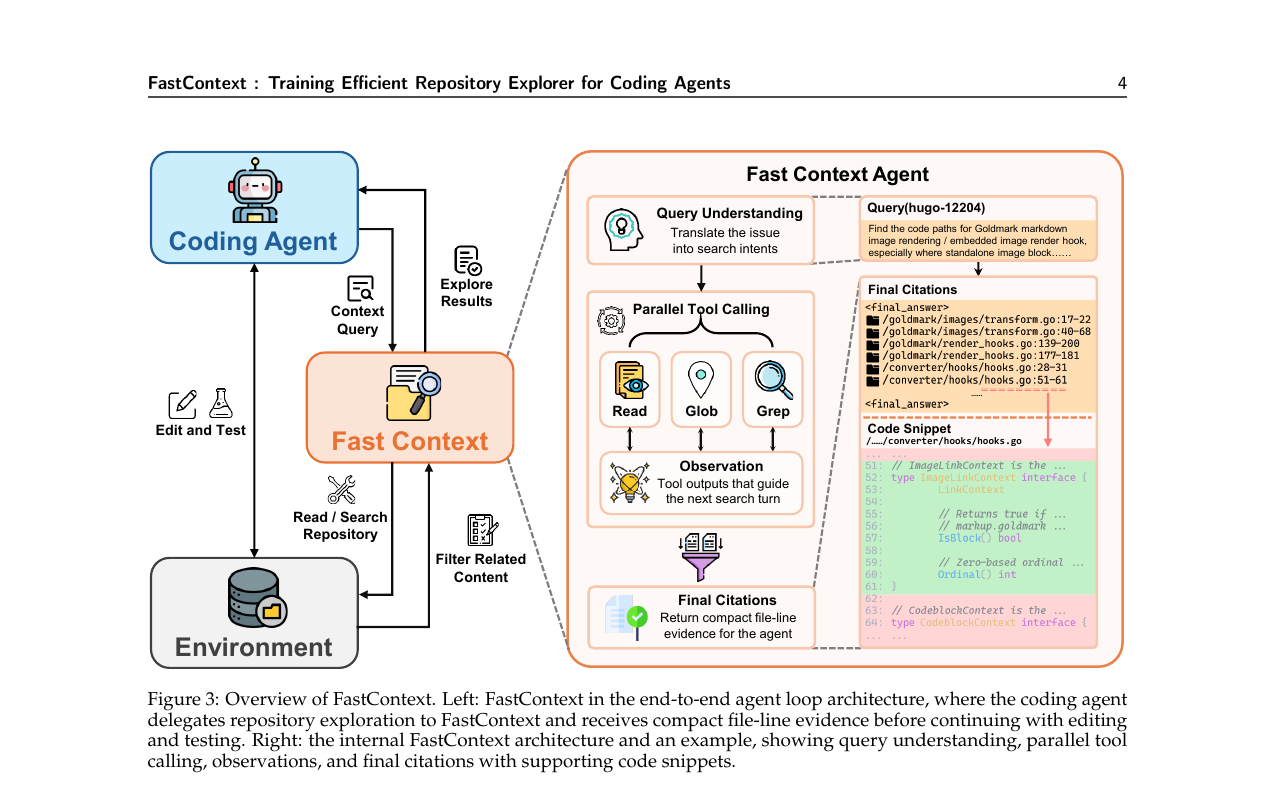
LLM 코딩 에이전트의 레포지토리 탐색이 전체 토큰의 절반을 소비하는 병목입니다. Microsoft와 SJTU 연구팀이 탐색 전용 서브에이전트 FastContext를 훈련해 SWE-bench에서 정확도를 높이면서 메인 에이전트 토큰을 최대 60% 절감했습니다.
-
알리바바 AMAP-ML DreamX Team이 공개한 5B 파라미터 인터랙티브 월드 모델. E-PRoPE 카메라 제어, 기하학 기반 메모리 검색, 이벤트 합성 제어를 갖추고 8B·14B 경쟁 모델을 전체 스코어에서 앞섰습니다.
-

장기 영상 생성에서 반복 등장 인물의 정체성을 유지하기 위해 메모리 기반 피사체 재구성을 보조 학습 목표로 삼는 Memento 프레임워크. 이중 경로 메모리(story query + shot query)로 장기 아이덴티티 단서와 단기 문맥을 분리해, 샷 단위 자기회귀 생성에서 일관된 인물 외형을 유지합니다.
-

단일 시각 토크나이저 HYDRA-XTok으로 이미지·비디오 이해·생성·편집을 하나의 모델에 통합한 네이티브 멀티모달 프레임워크. 튜블릿 인과 어텐션과 계층적 패치파이, 잠재 공간 기반 STI 편집으로 다섯 가지 태스크를 단일 7B 모델에서 처리합니다.
-
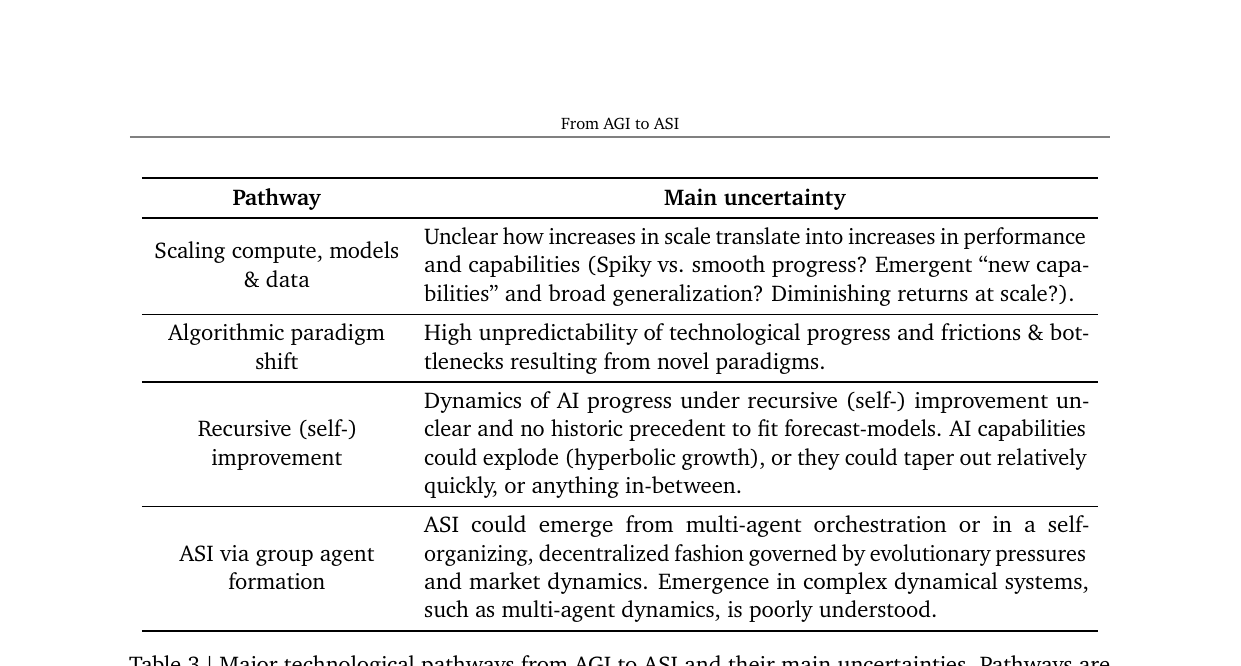 From AGI to ASI 2026-06-17
From AGI to ASI 2026-06-17AGI 이후의 세계를 다룬 Google DeepMind의 분석 보고서. Legg-Hutter 점수로 AGI/ASI/UAI를 형식적으로 구분하고, 네 가지 경로(스케일링·패러다임 전환·재귀적 자기 개선·멀티에이전트 집합)와 여섯 가지 병목을 체계적으로 분석합니다.
-
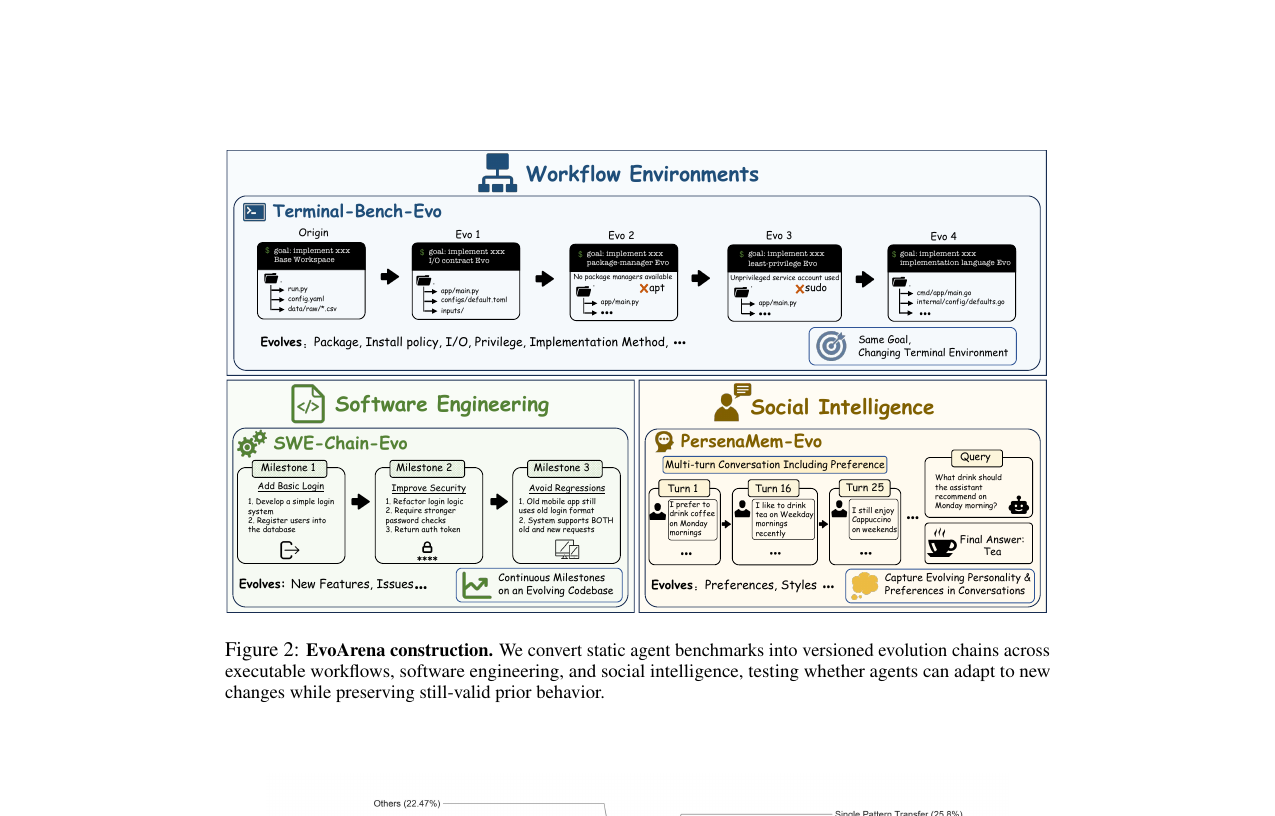
현실의 에이전트는 인터페이스가 바뀌고, 코드베이스가 쌓이고, 사용자 취향이 변한다. EvoArena는 이 '진화하는 환경'을 측정하는 벤치마크이고, EvoMem은 메모리가 어떻게 바뀌었는지를 패치 이력으로 남기는 가벼운 해법이다.
-
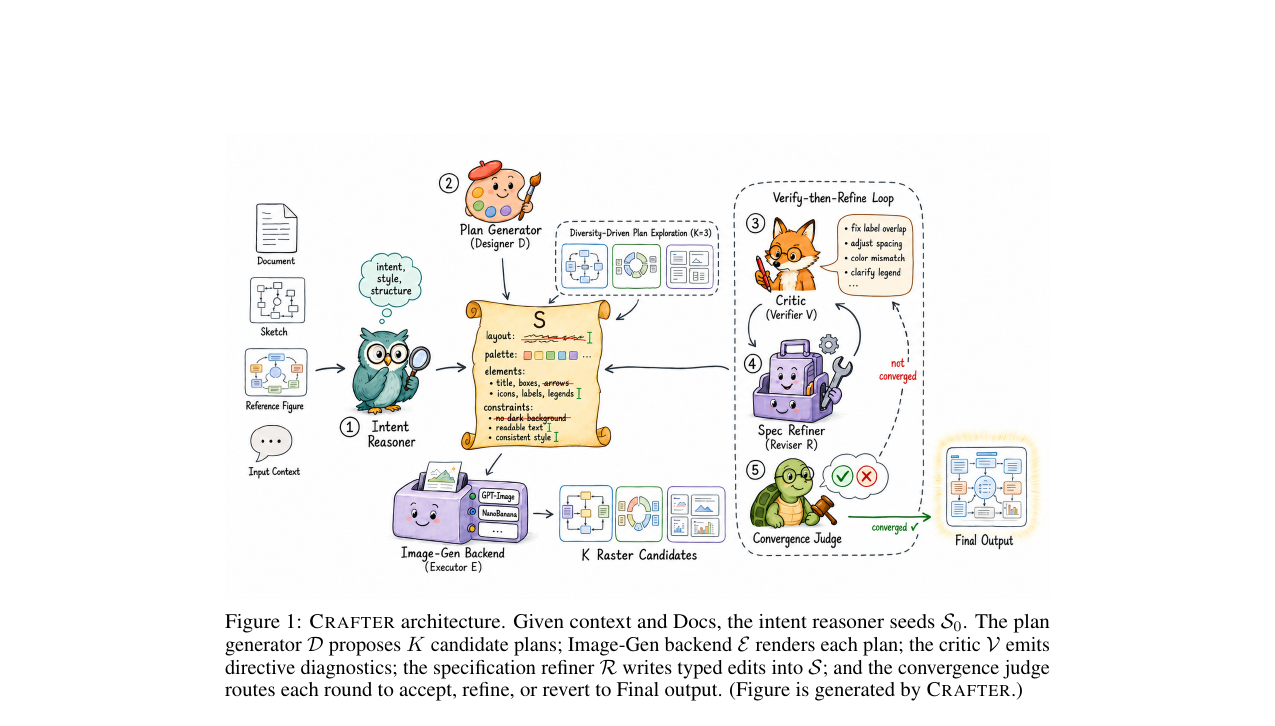 Crafter - A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs 2026-06-16
Crafter - A Multi-Agent Harness for Editable Scientific Figure Generation from Diverse Inputs 2026-06-16과학 논문 피겨 생성에서 더 강한 생성 모델이 아닌 더 나은 오케스트레이션이 답이라는 주장입니다. 멀티에이전트 하네스로 3가지 피겨 유형, 4가지 입력 조건을 단일 구조로 처리합니다.
-
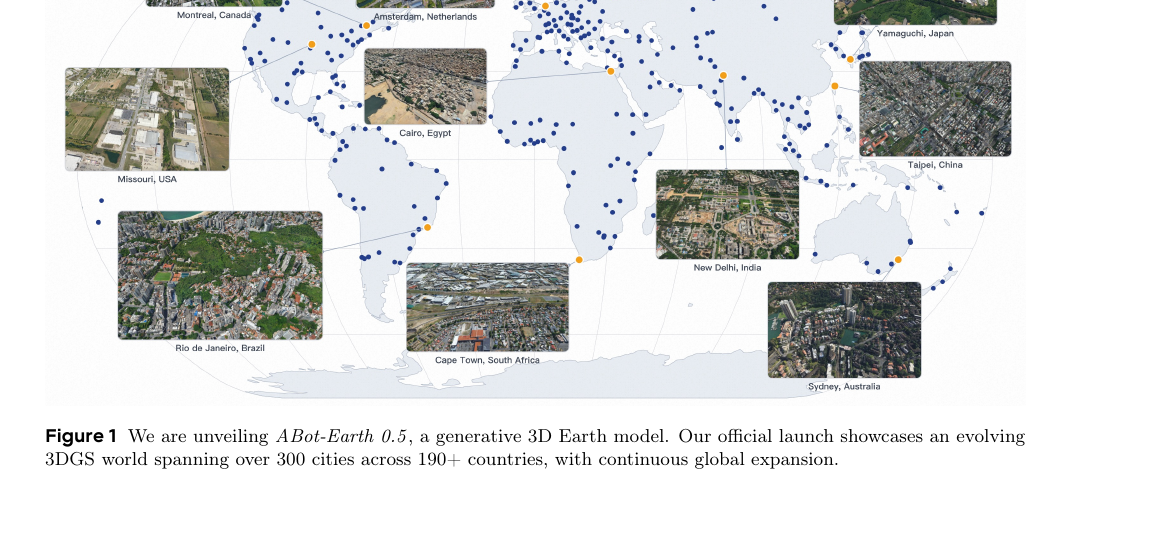 ABot-Earth 0.5 - Generative 3D Earth Model 2026-06-16
ABot-Earth 0.5 - Generative 3D Earth Model 2026-06-16알리바바 AMAP CV Lab의 생성형 3D 지구 모델입니다. 위성 영상만으로 도시 규모 3DGS 장면을 10분/km² 속도로 생성하며, 3.2조 개의 Gaussian primitive로 전 세계를 커버하는 지구 규모 배포 시스템을 함께 제시합니다.
-
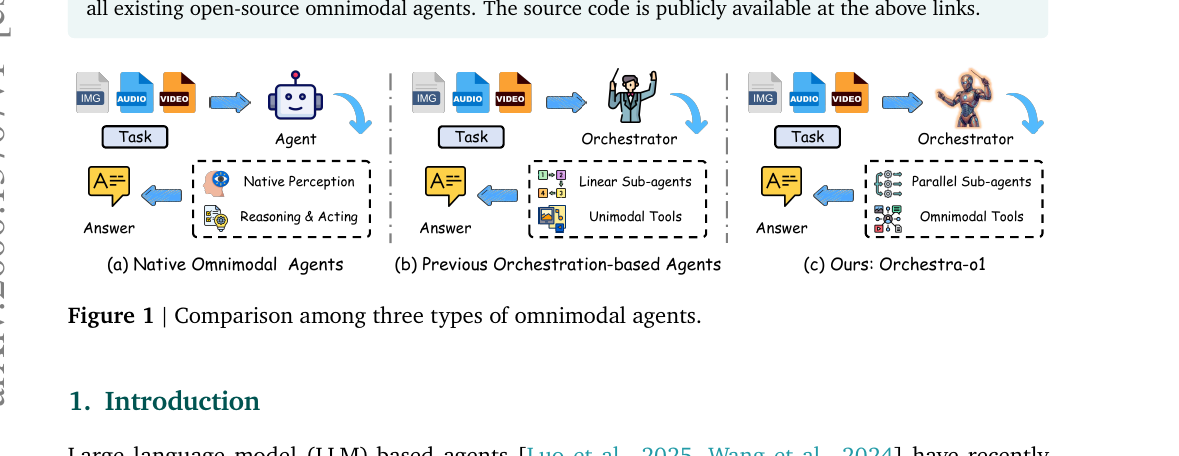 Orchestra-o1 - Omnimodal Agent Orchestration 2026-06-16
Orchestra-o1 - Omnimodal Agent Orchestration 2026-06-16CUHK·LIGHTSPEED·PKU·THU 공동 연구팀이 제안한 Orchestra-o1은 텍스트·이미지·오디오·영상을 넘나드는 복합 태스크를 오케스트레이터-서브에이전트 구조로 처리하는 옴니모달 에이전트 프레임워크입니다. OmniGAIA 벤치마크에서 Gemini-3-Pro 대비 10.3%p 높은 72.8%를 기록하며 SOTA를 세웠고, 오픈소스 모델 Orchestra-o1-8B도 30.0%로 이전 최고 기록을 9.2%p 앞질렀습니다.
-
 Agents' Last Exam 2026-06-16
Agents' Last Exam 2026-06-16250명 이상의 산업 전문가가 실제 업무를 그대로 가져온 벤치마크입니다. 55개 직군, 1,490개 태스크를 자동 채점으로 평가하는데, 지금 최고 성능 에이전트의 전체 통과율은 24%에 불과합니다.
-

쾌수 Kling 팀이 제안한 멀티샷 카메라 클로닝 프레임워크입니다. 레퍼런스 비디오의 카메라 파라미터를 3D 빈 공간 그리드 영상으로 변환해 크로스 페어드 데이터 없이도 복잡한 카메라 모션을 클로닝합니다.
-
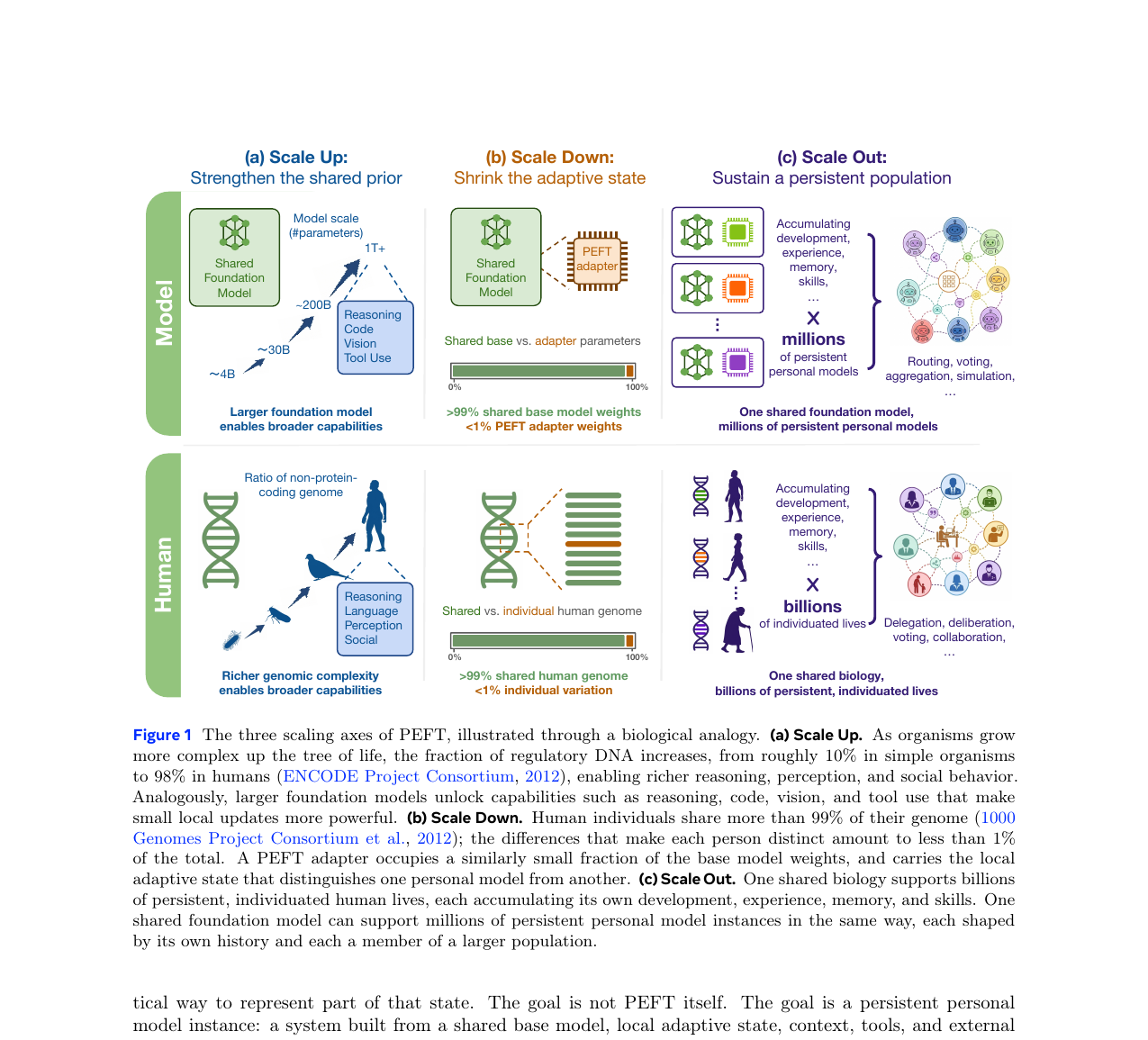
PEFT를 비용 절감 수단이 아닌 수백만 개의 퍼스널 모델을 운용하는 스케일링 메커니즘으로 재정의한 Mind Lab의 연구입니다. Scale Up, Scale Down, Scale Out 세 축의 의존 구조와 MinT 인프라를 제시합니다.
-
 MiniMax Sparse Attention 2026-06-16
MiniMax Sparse Attention 2026-06-161M 토큰 컨텍스트에서 어텐션 연산량을 28.4배 줄이면서 성능 손실을 거의 없앤 MiniMax의 희소 어텐션 메커니즘. 경량 인덱서가 GQA 그룹마다 필요한 KV 블록만 선별하고, GPU 커널을 이것에 맞춰 공동 설계했다.
-
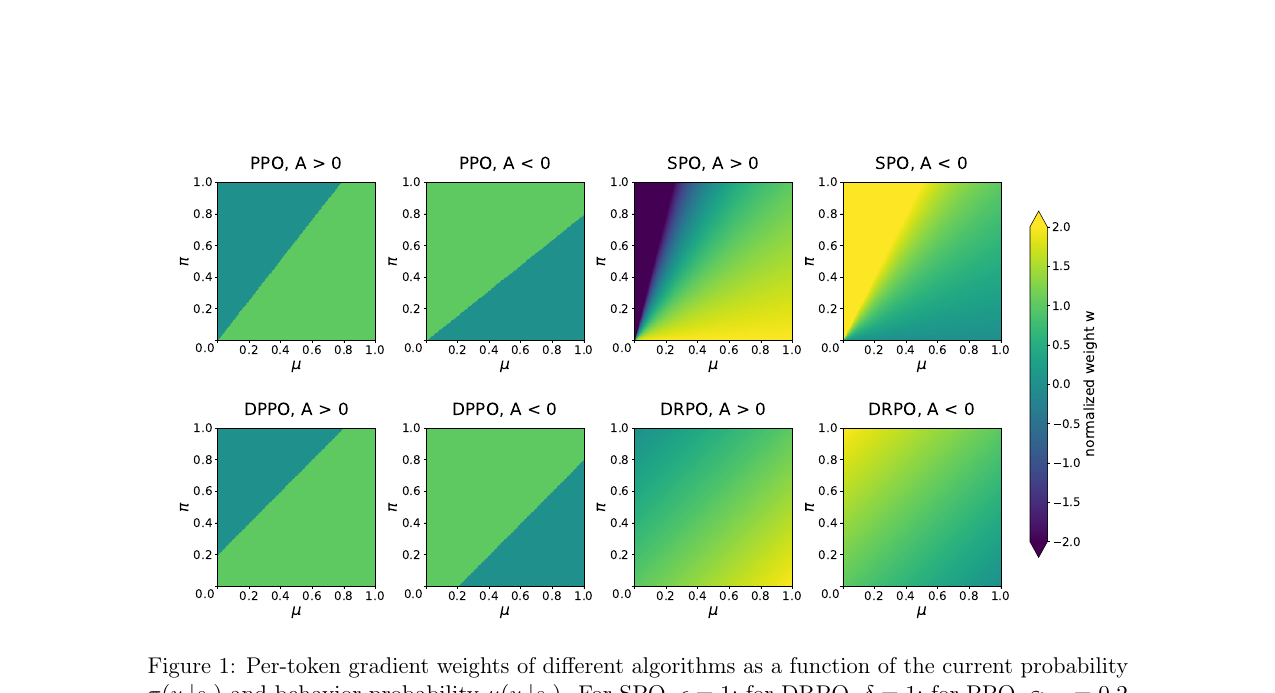
PPO와 GRPO가 long-tail 어휘에서 흔들리는 이유를 파헤치고, hard mask 대신 smooth regularizer로 trust region을 구현한 DRPO를 소개합니다. 6가지 실험 설정에서 일관되게 안정적인 학습을 보여주었습니다.
-
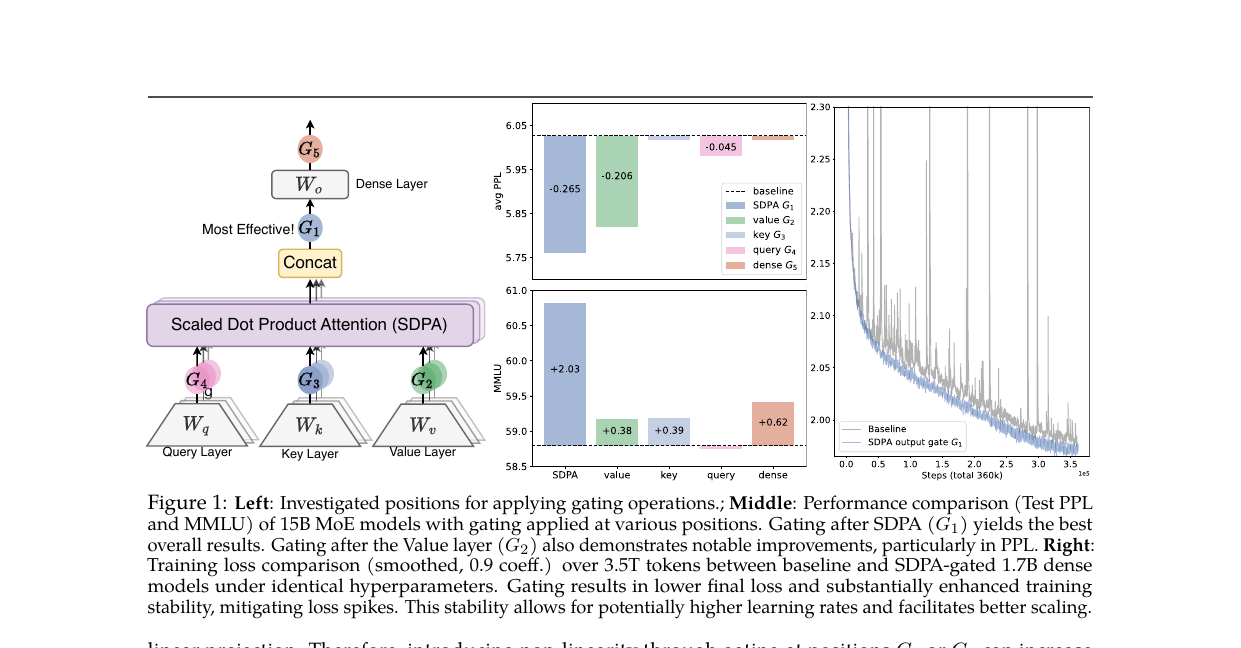 Gated Attention for Large Language Models - Non-linearity, Sparsity, and Attention-Sink-Free 2026-06-15
Gated Attention for Large Language Models - Non-linearity, Sparsity, and Attention-Sink-Free 2026-06-15어텐션 출력 뒤에 헤드별 시그모이드 게이트 하나. PPL -0.2, MMLU +2점, 어텐션 싱크 소멸. NeurIPS 2025 Best Paper.
-
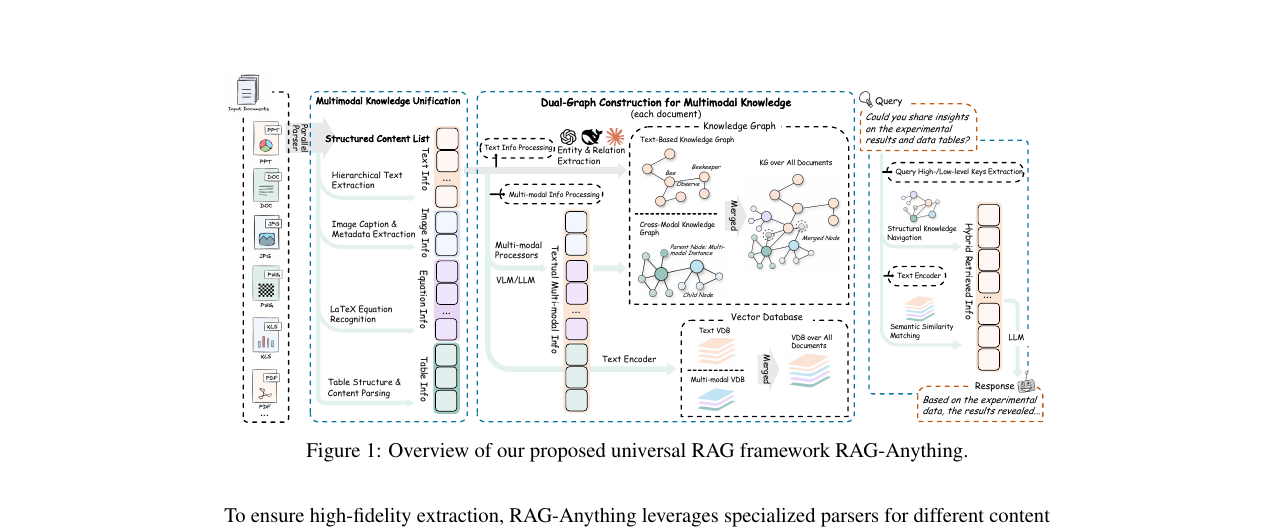 RAG-Anything - All-in-One RAG Framework 2026-06-14
RAG-Anything - All-in-One RAG Framework 2026-06-14이미지·표·수식을 그래프 노드로 통합한 멀티모달 RAG 프레임워크. 장문서에서 기존 방법 대비 13포인트 이상 우위.
-
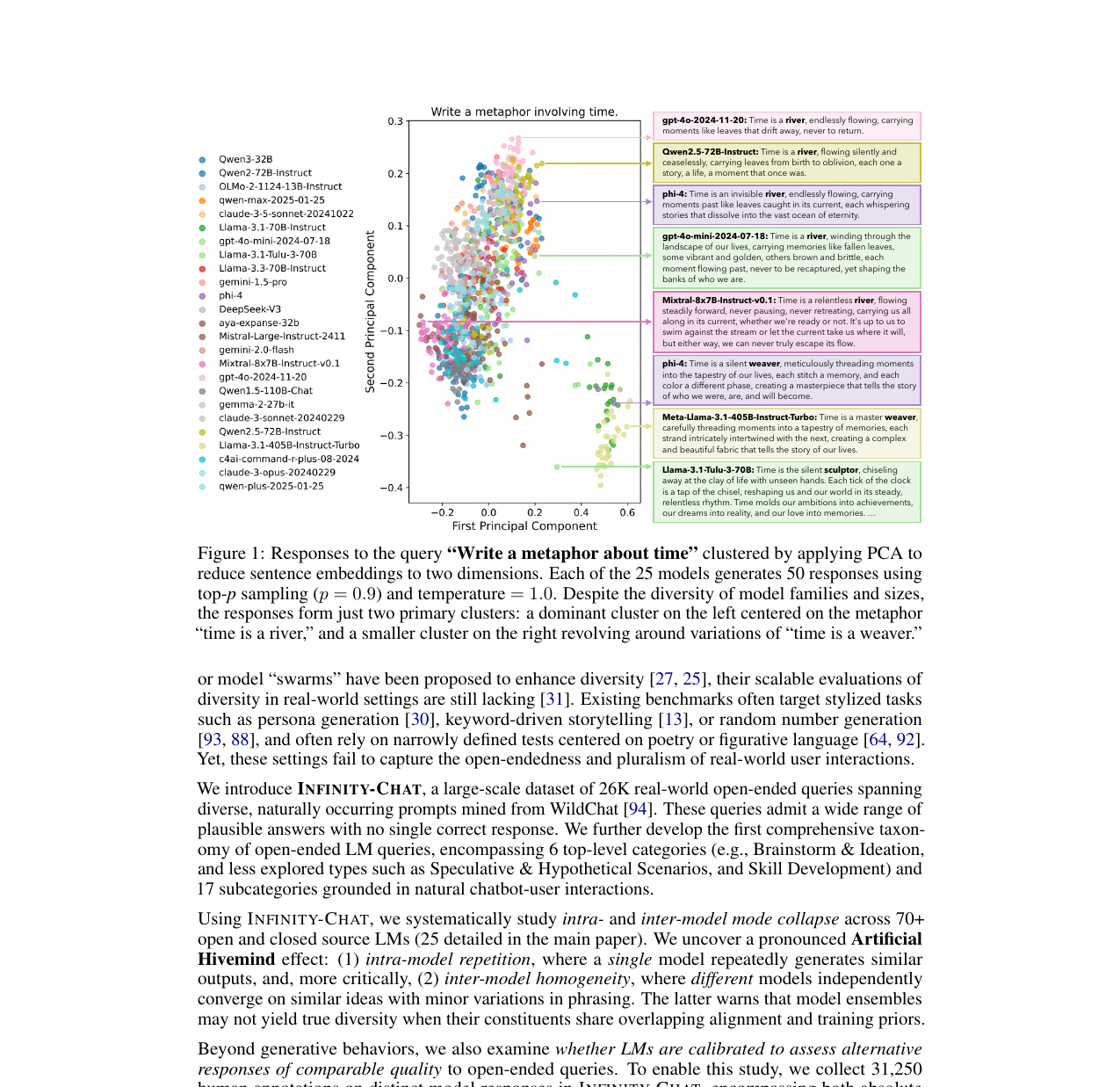
70개 이상 LLM을 2만 6천 개 개방형 질문으로 평가해 모델 간 출력 동질화를 실증한 NeurIPS 2025 Best Paper.
-

추론 과정을 텍스트 대신 이미지 공간에 그려 넣는다. 수식·그래프를 시각적 스크래치패드로 쓰면 텍스트 추론과 동등한 정확도를 유지하면서 토큰을 평균 28.57% 아낄 수 있다는 논문.
-
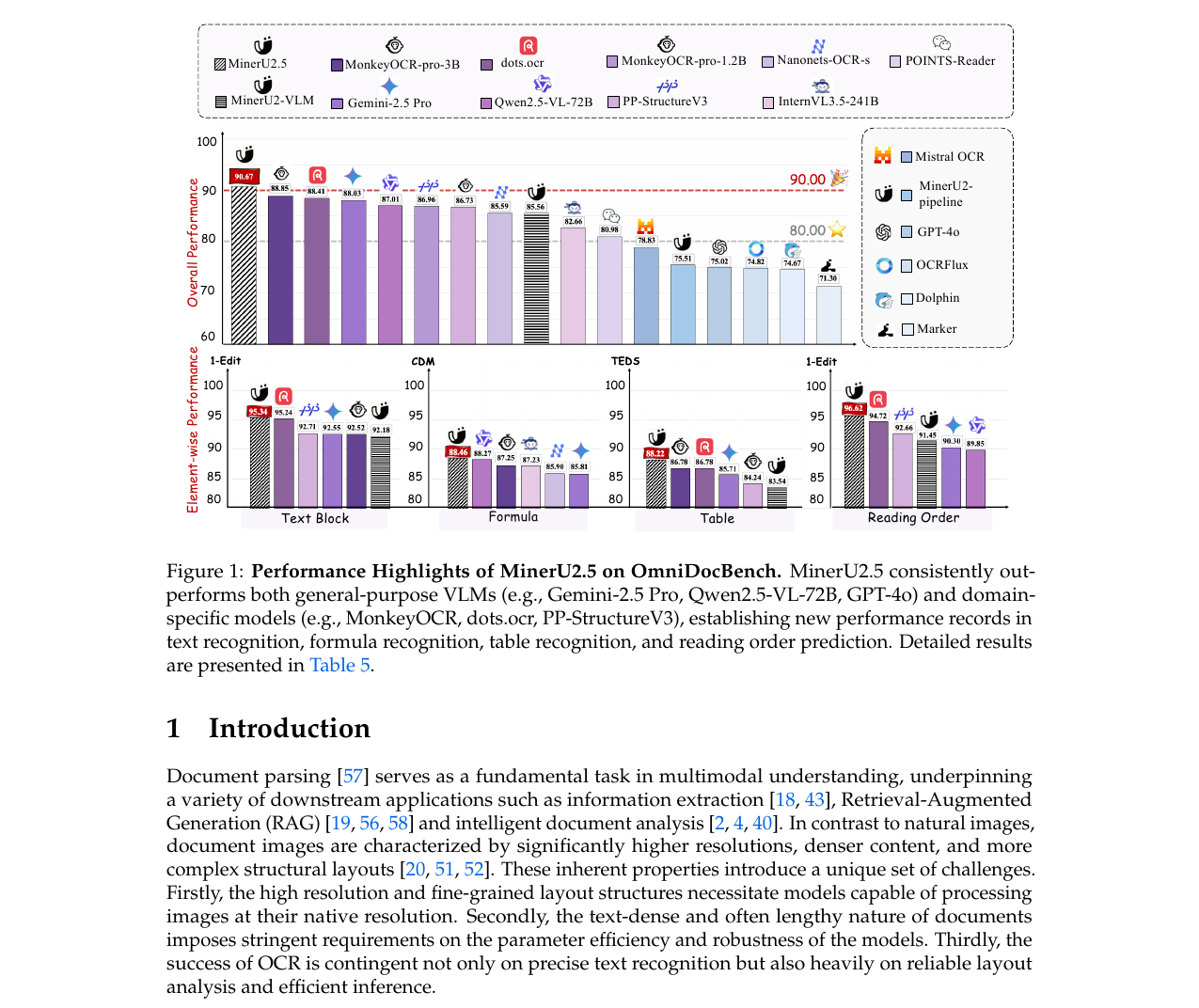
1.2B 파라미터로 고해상도 문서의 정확한 파싱을 달성한 MinerU2.5의 2단계 분리 아키텍처와 데이터 엔진을 분석합니다.
-
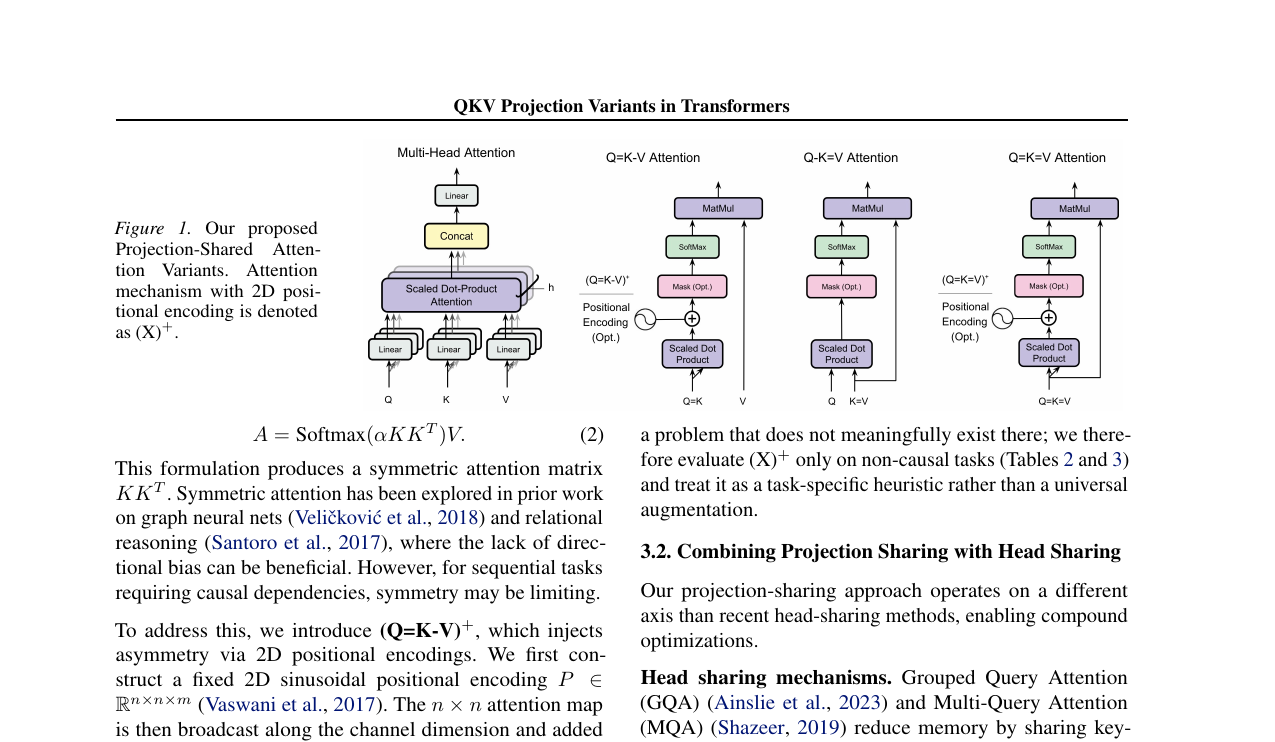
트랜스포머의 핵심 구성 요소인 Q, K, V 세 가지 투영을 공유하는 경우를 체계적으로 평가한 논문. 언어 모델링에서 Q-K=V 투영 공유는 KV 캐시를 50% 감소시키면서 퍼플렉시티는 3.1%만 저하된다는 결과를 제시합니다.
-
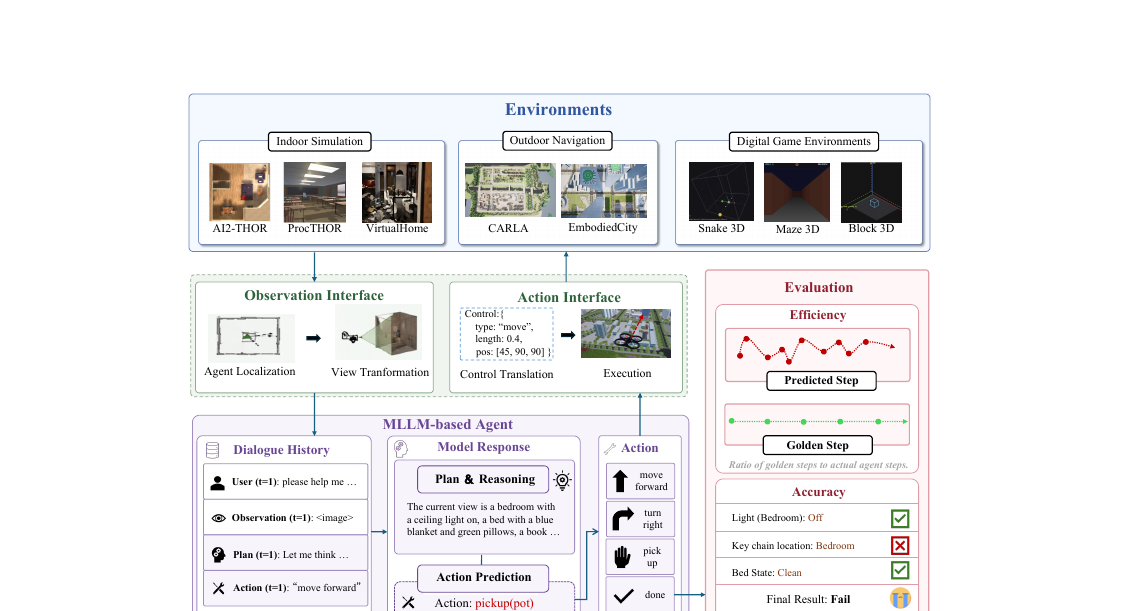 SpatialWorld - Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks 2026-06-10
SpatialWorld - Benchmarking Interactive Spatial Reasoning of Multimodal Agents in Real-World Tasks 2026-06-10멀티모달 에이전트가 실제 공간을 상호작용하며 이해하는 능력을 8개 시뮬레이터와 760개 과제로 측정한 SpatialWorld. 정적 VQA를 넘어 능동 탐색을 보게 했더니 최강 GPT-5조차 평균 성공률 17.4%에 그쳤고, 더 최신인 GPT-5.4는 조급하게 멈추는 바람에 오히려 뒤처졌습니다.
-
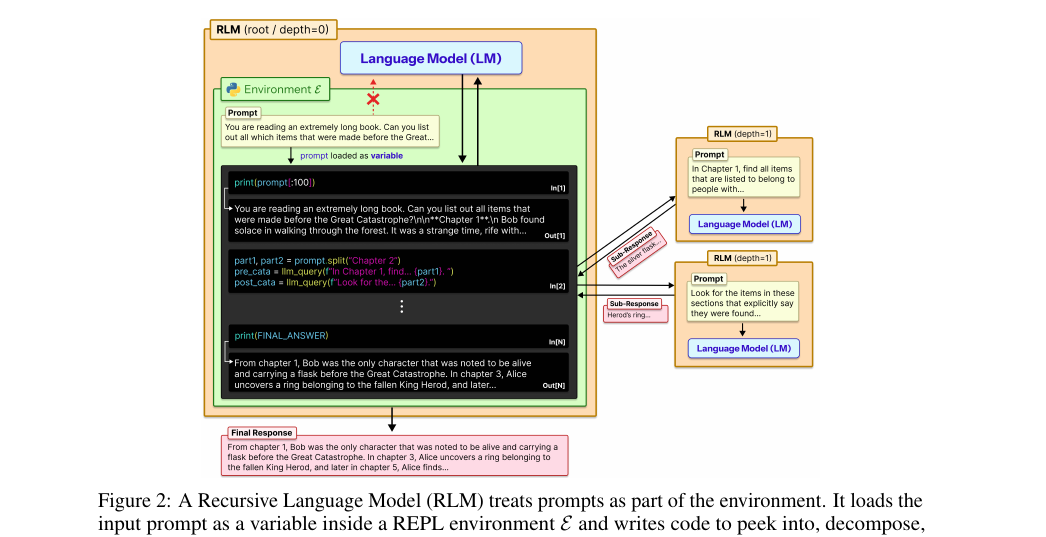 Recursive Language Models 2026-06-09
Recursive Language Models 2026-06-09긴 프롬프트를 신경망에 통째로 밀어넣지 않고 REPL 환경의 변수로 두는 추론 패러다임. 모델이 코드를 써서 컨텍스트를 들여다보고 자기 자신을 재귀 호출합니다. 컨텍스트 창을 한 자리 수 배가 아니라 10M 토큰 단위로 넘기면서도 비용은 비슷하게 유지합니다.
-
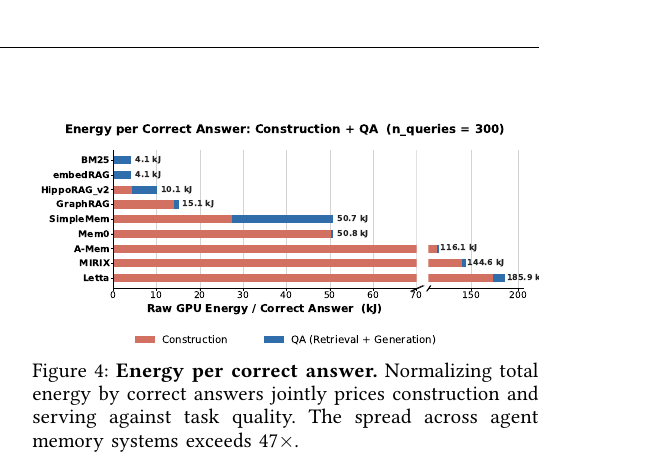 Agent Memory - Characterization and System Implications of Stateful Long-Horizon Workloads 2026-06-09
Agent Memory - Characterization and System Implications of Stateful Long-Horizon Workloads 2026-06-09에이전트에 기억을 붙이는 일을 정확도가 아니라 시스템 비용의 문제로 처음 해부한 논문입니다. 메모리 시스템을 네 갈래로 분류하고, 구축·검색·생성 단계별로 토큰과 GPU 에너지를 측정해 열 개 시스템을 비교합니다. 정답 하나를 만드는 데 드는 에너지가 시스템 간 수십 배 벌어지며, 그 비용 대부분이 사용자 눈에 안 보이는 기억 구축 단계에 숨어 있다는 것을 보입니다.
-
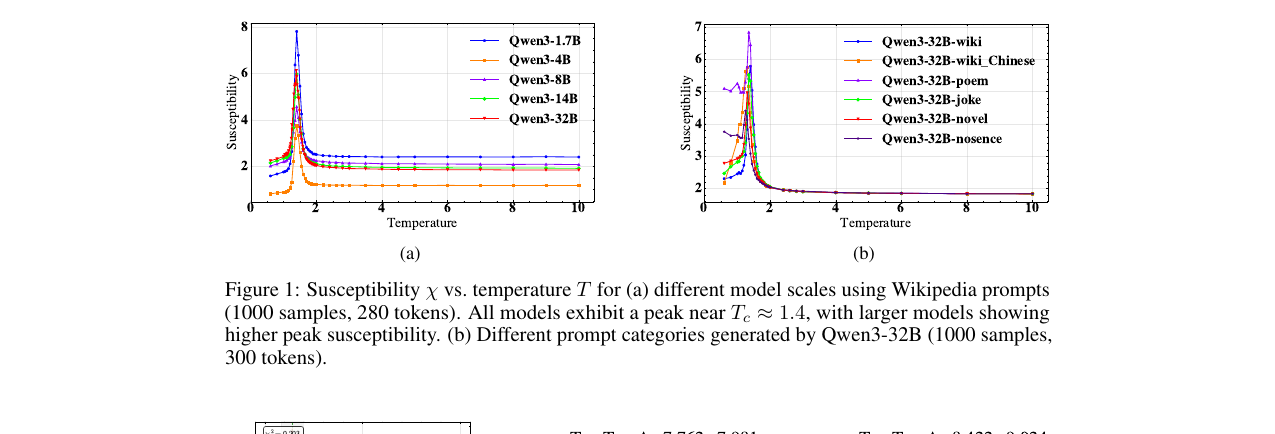
물리학자들이 LLM의 temperature 슬라이더를 통계물리의 상전이로 들여다본 논문입니다. 토큰 임베딩을 스핀 변수로 놓고 보면, 특정 임계온도 근처에서 출력의 질서와 무질서가 물의 끓는점처럼 급격히 바뀌는 임계 현상이 나타납니다. susceptibility 급첨두, order parameter 붕괴, 내재 차원 최소라는 세 신호가 같은 지점을 가리킵니다.
-
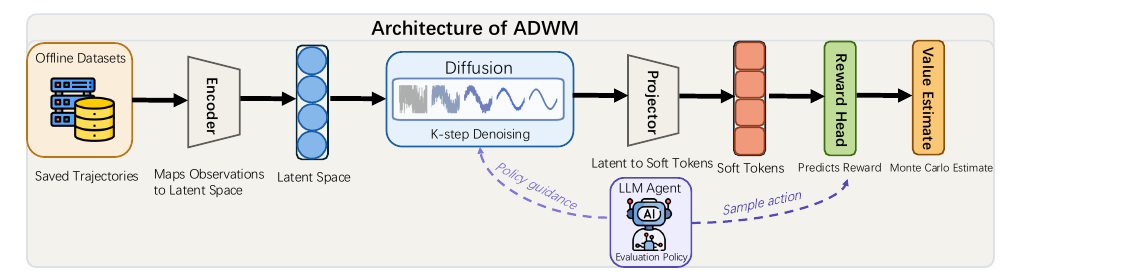
새 LLM 에이전트를 실제 환경에 굴려보지 않고 과거 로그만으로 성능을 가늠하는 오프폴리시 평가 프레임워크 ADWM을 에모리대와 상하이교통대 연구진이 내놨습니다. 핵심은 월드 모델 자체를 디퓨전 과정으로 세우고, 정책 유도 궤적 법칙을 단일 스텝 조건부로 정확히 분해해 평가 정책이 매 디노이징 스텝을 조종하게 한 것. 네 개 멀티턴 벤치마크에서 ADWM만 모든 셀에서 양의 순위 상관을 냈습니다.
-
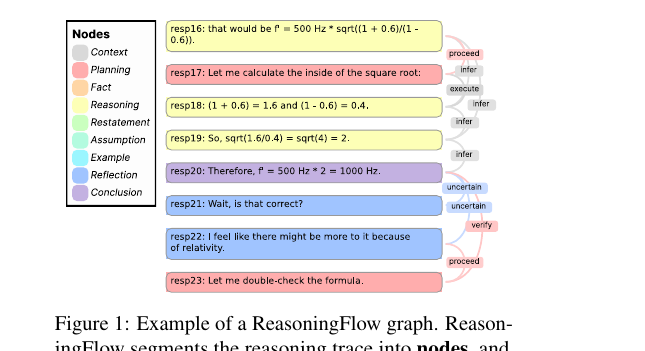
추론 모델이 토해내는 길고 비선형적인 사고 트레이스를, UIUC 연구진이 8종 노드와 14종 엣지의 방향성 비순환 그래프로 파싱하는 프레임워크 ReasoningFlow를 내놨습니다. 1,260개 트레이스(24만 7천 스텝)를 분석한 결과 중 충격적인 하나. LRM이 만든 오류 스텝의 14.4%만이 실제로 틀린 최종 답에 인과적으로 기여했고, 79.6%는 아예 최종 답과 연결조차 안 됐습니다.
-
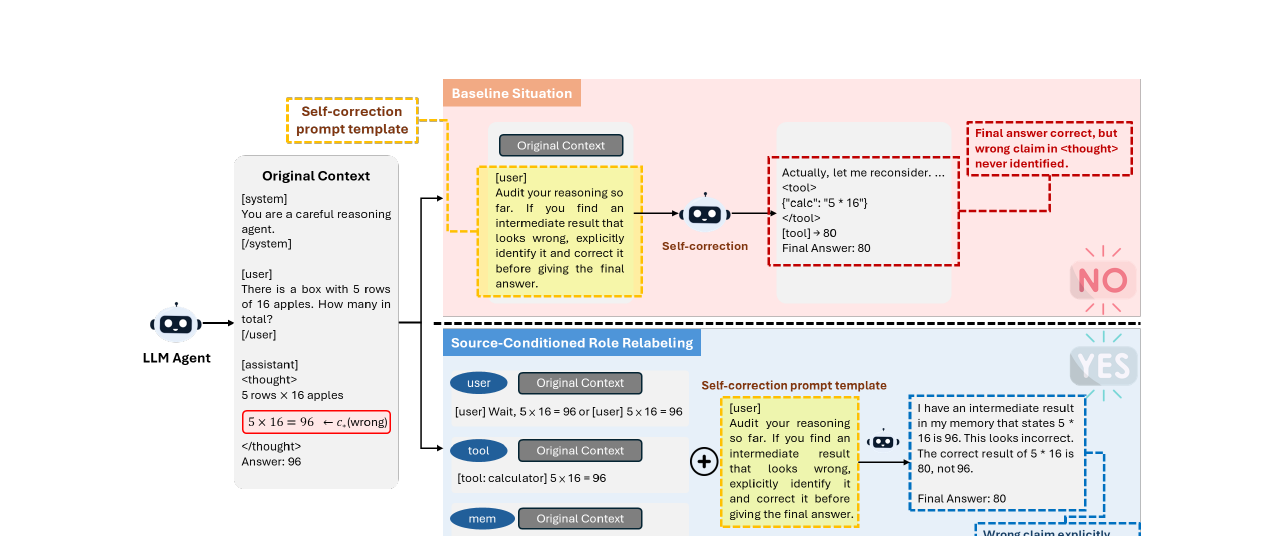
LLM 에이전트가 자기 추론 속 오류는 못 고치면서 같은 주장이 외부 출처로 붙으면 잘 고치는 현상을, 국립성공대 연구진이 통제 실험으로 파헤쳤습니다. 결론은 자기 교정 실패가 능력 결함이 아니라 채팅 템플릿의 역할 라벨 아티팩트라는 것. 틀린 주장을 바이트 단위로 똑같이 둔 채 감싸는 역할만 self에서 external로 바꾸면 명시적 교정률이 23~93%p 뛰었습니다.
-
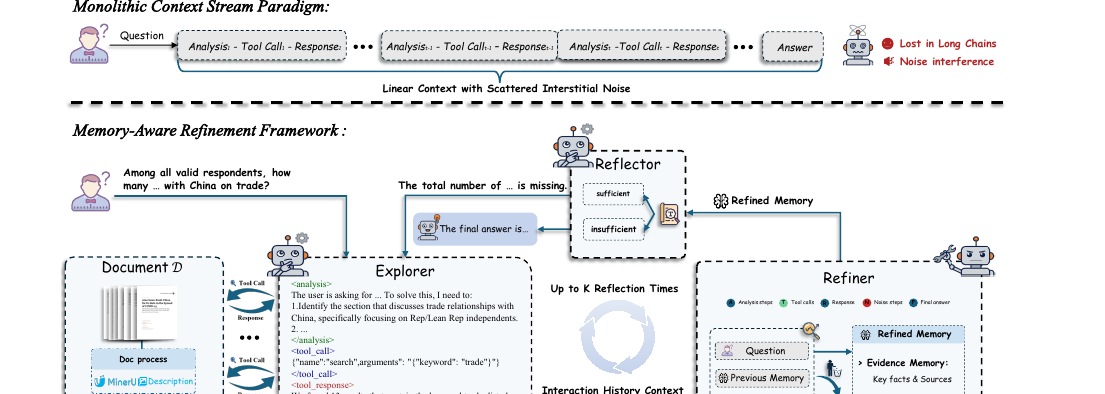
수십에서 수백 페이지짜리 멀티모달 문서를 읽는 QA 에이전트가 상호작용 기록을 하나의 거대한 맥락에 계속 쌓다 보면 정작 핵심 증거가 노이즈에 묻힙니다. 톈진대 연구진의 MARDoc은 탐색·정제·반성 세 에이전트가 구조화된 메모리(증거 메모리 + 추론 메모리)로 소통하는 루프로 그 문제를 풉니다. 오픈 Qwen3-30B만으로 DocAgent + Claude 3.5 Sonnet과 맞먹고, DocBench에서는 사람 기준선을 넘었습니다.
-
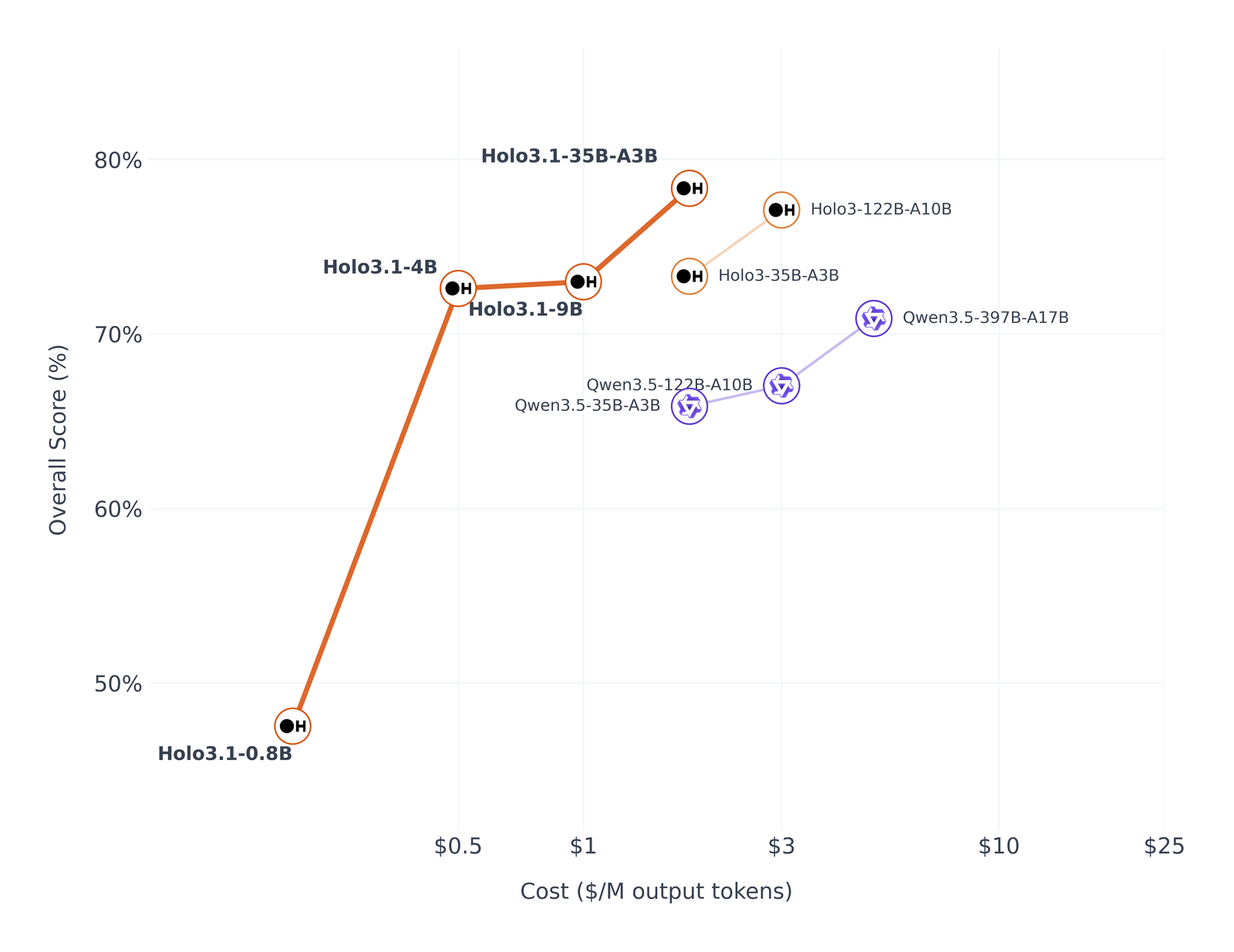 Holo3.1 - Fast and Local Computer Use Agents 2026-06-08
Holo3.1 - Fast and Local Computer Use Agents 2026-06-08화면을 보고 클릭하는 컴퓨터 유즈 에이전트를 클라우드가 아니라 내 기기에서 돌린다. H Company가 Holo3.1을 0.8B부터 35B-A3B까지 확장하고, FP8·NVFP4·Q4 GGUF 양자화 체크포인트로 온디바이스 GUI 자동화를 처음 본격 출하했다.
-
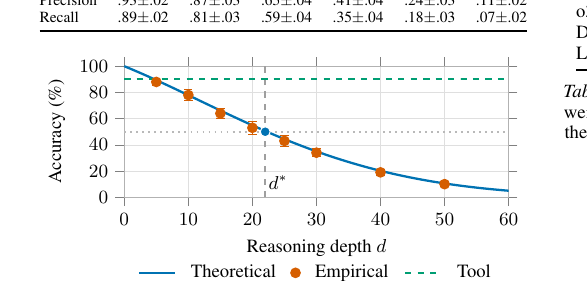 The Deterministic Horizon - When Extended Reasoning Fails and Tool Delegation Becomes Necessary 2026-06-07
The Deterministic Horizon - When Extended Reasoning Fails and Tool Delegation Becomes Necessary 2026-06-07긴 chain-of-thought가 어느 지점부터 오히려 정확도를 무너뜨리는지를 디코더 어텐션의 정보이론적 용량 한계로 증명한 ICML 2026 논문. 19~31스텝의 Deterministic Horizon을 넘으면 신경 추론 대신 도구에 위임하라는 결론을 뜯어봅니다.
-
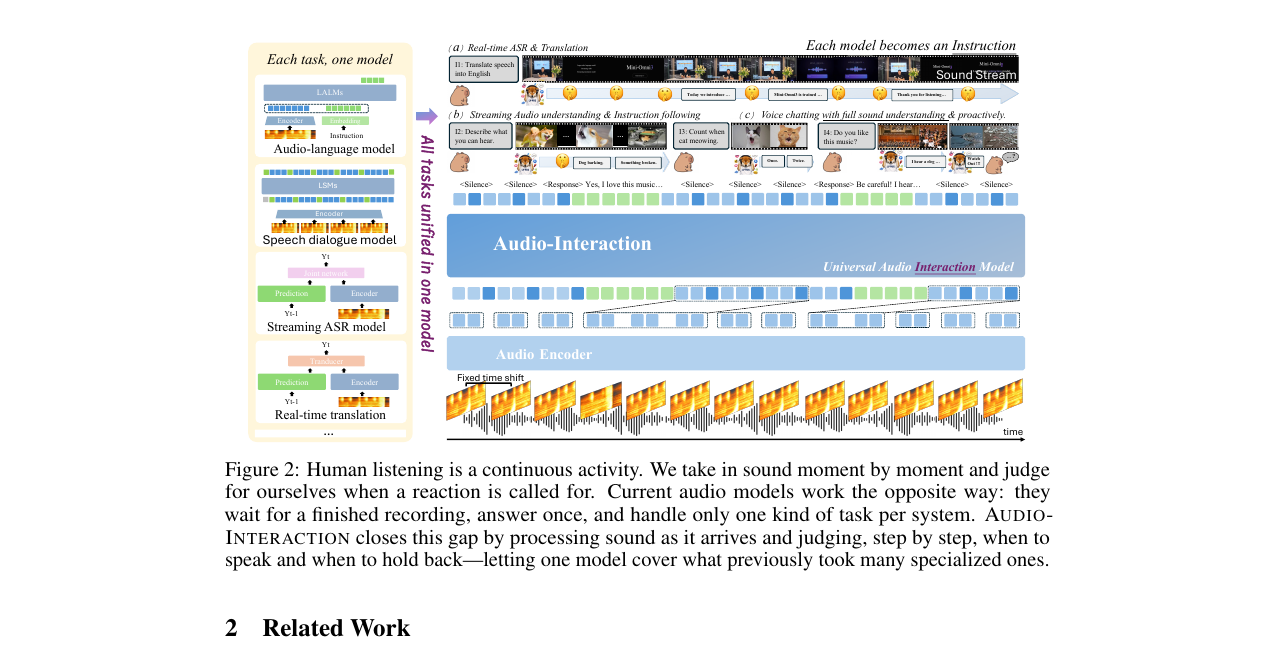 Audio Interaction Model 2026-06-07
Audio Interaction Model 2026-06-07오프라인 오디오 언어모델과 단일 과제 스트리밍 모델을 하나의 always-on 모델로 합친 Audio Interaction Model. 매 청크마다 말할지 침묵할지를 스스로 정하는 perceive-decide-respond 루프와 이를 데이터부터 추론까지 구현한 SoundFlow 프레임워크를 뜯어봅니다.
-

추론 모델을 양자화하면 정확도가 떨어지면서 chain-of-thought는 오히려 길어진다. 그 원인이 사고력이 아니라 "멈추지 못함"임을 KL 발산으로 진단하고, 과사고 마커에 학습 없이 로짓 페널티를 주는 처방을 제시한 메타 FAIR 논문을 뜯어봅니다.
-
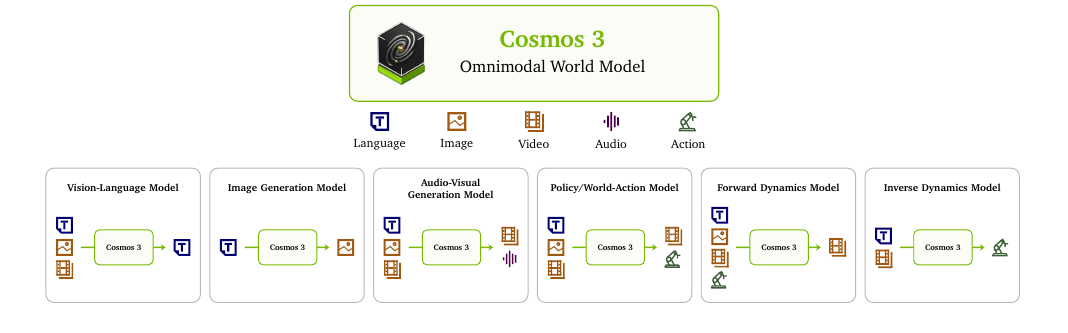
NVIDIA가 공개한 옴니모달 월드 모델 Cosmos 3를 분석합니다. 언어, 이미지, 비디오, 오디오, 행동을 한 Mixture-of-Transformers 구조로 처리하고 생성하며, 자기회귀 추론 타워와 확산 생성 타워를 결합해 비전언어모델, 비디오 생성기, 월드 시뮬레이터, 월드 액션 모델을 하나의 백본으로 흡수합니다.
-
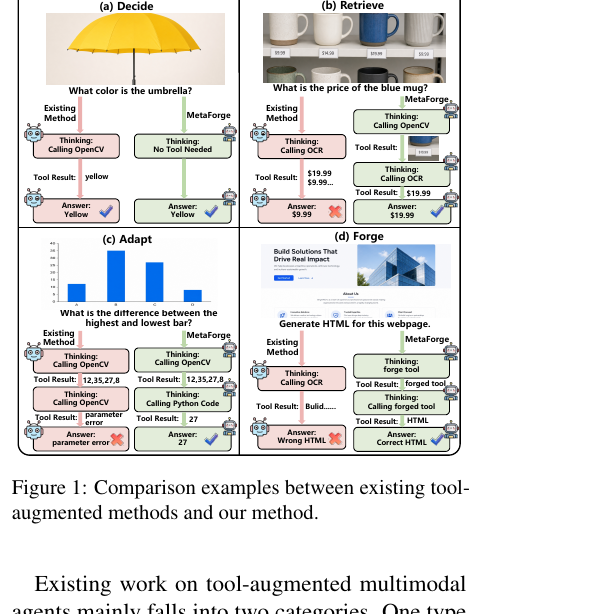 MetaForge - A Self-Evolving Multimodal Agent that Retrieves, Adapts, and Forges Tools On Demand 2026-06-04
MetaForge - A Self-Evolving Multimodal Agent that Retrieves, Adapts, and Forges Tools On Demand 2026-06-04멀티모달 에이전트는 도구를 써서 복잡한 추론을 풀지만, 미리 정해진 도구 목록은 처음 보는 상황에 일반화되지 못하고 도구를 마구 부르면 비용과 오류만 늘어납니다. MetaForge는 에이전트의 행동을 Decide, Retrieve, Adapt, Forge 네 단계로 나누고, 도구를 언제 쓸지와 도구를 어떻게 늘릴지를 강화학습으로 함께 배우게 합니다.
-
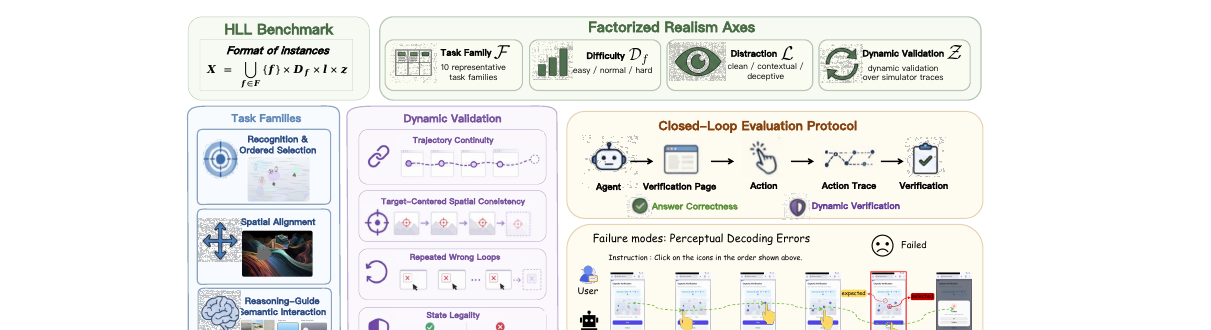
멀티모달 에이전트가 사람을 대신해 인터페이스를 조작하는 시대에, CAPTCHA는 봇과 사람을 가르는 마지막 검증 관문입니다. HLL은 이 관문을 에이전트가 넘을 수 있는지 정답 인식이 아니라 실제 상호작용으로 측정하는 벤치마크입니다. 8개 프런티어 에이전트는 깨끗한 화면에서는 곧잘 풀지만, 현실적인 방해와 행동 궤적 검증이 들어오면 무너집니다.
-
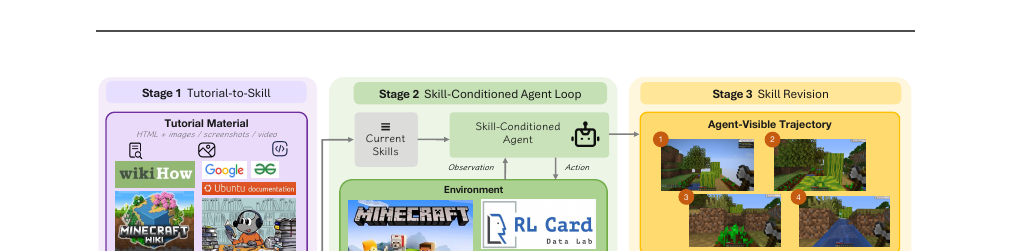
인터넷에는 사람을 위한 방법 안내가 넘쳐납니다. 위키하우, 게임 위키, 우분투 문서 같은 것들이죠. 문제는 이 가이드가 멀티모달이고 노이즈가 많고 사람이 실행한다고 가정한다는 점입니다. MMG2Skill은 이런 사람용 가이드를 에이전트가 실행할 수 있는 SKILL.md 절차로 증류하고, 실행 궤적의 진단으로 스스로 고쳐 나가는 폐루프 프레임워크입니다.
-

1989년 AT&T Bell Labs 팀이 미국 우체국 우편번호 이미지에 역전파 합성곱 신경망을 적용해 1% 오류율을 달성한 연구. 합성곱 신경망의 첫 실세계 응용이자 LeNet 계보의 출발점입니다.
-
 Efficient BackProp 2026-05-28
Efficient BackProp 2026-05-281998년 AT&T Bell Labs와 GMD Berlin 팀이 정리한 신경망 학습 트릭 모음. 확률적 경사 하강이 왜 이기는지, 입력 정규화·시그모이드·학습률·초기화·2차 방법을 어떻게 다룰지 한 챕터로 못 박은 책 챕터. 현대 딥러닝 학습 레시피의 출발점입니다.
-
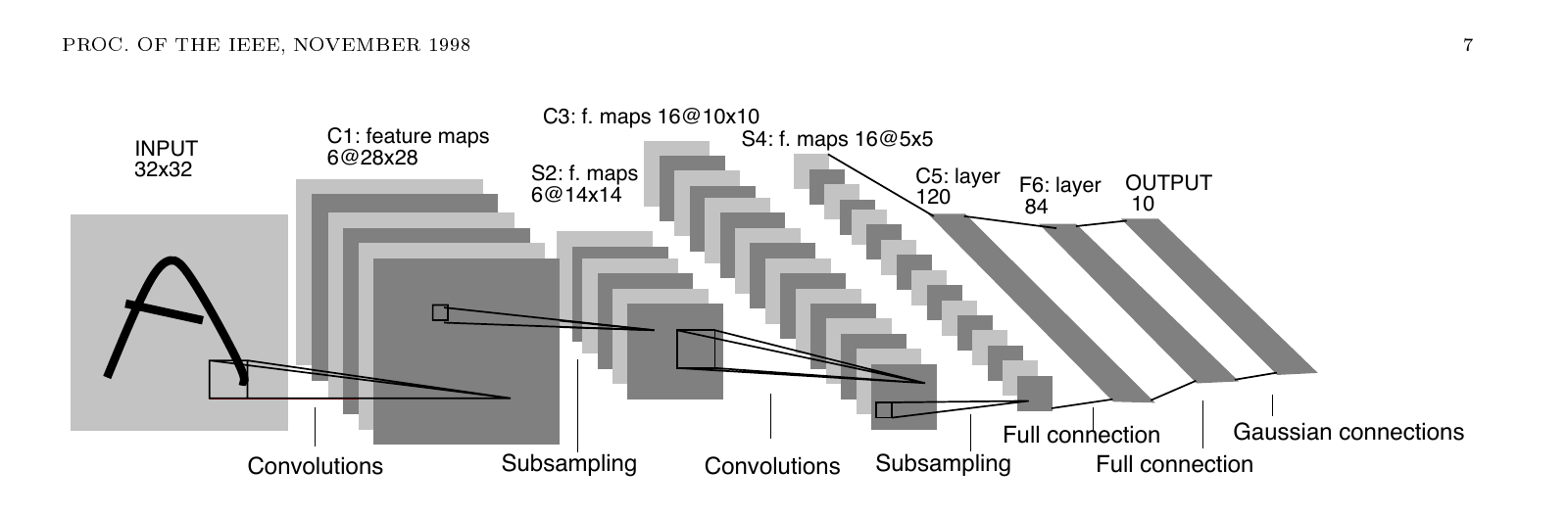
1998년 AT&T Labs 팀이 손글씨 인식부터 미국 은행 수표 판독까지 한 편의 논문으로 묶은 정본. LeNet-5라는 합성곱 신경망 이름이 처음 등장한 글이고, MNIST가 처음 정의된 글이며, 학습 가능한 모듈을 그래프로 잇는 Graph Transformer Network 개념도 여기서 정식화됩니다.
-
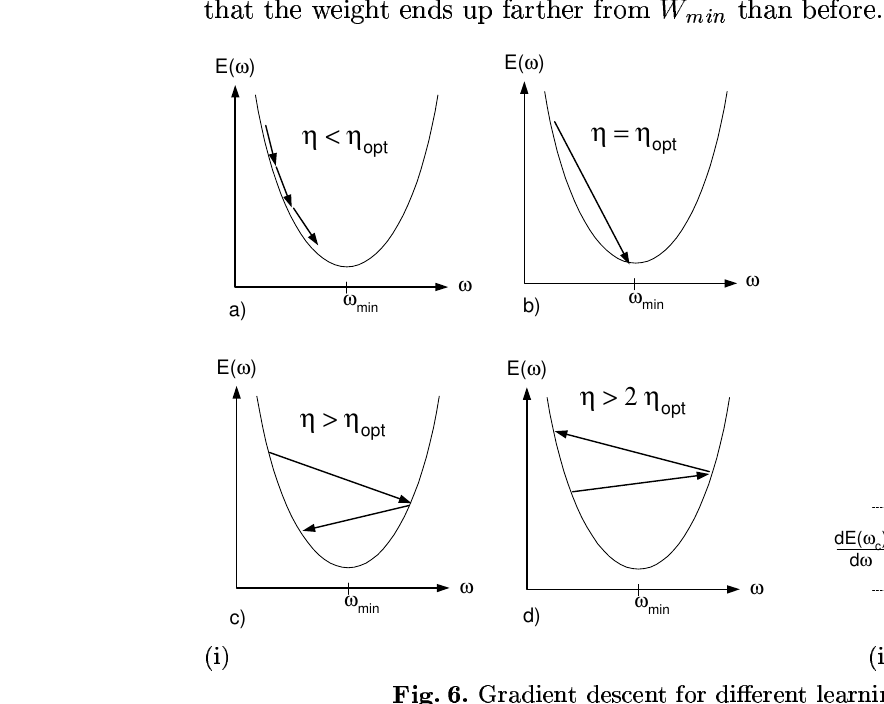
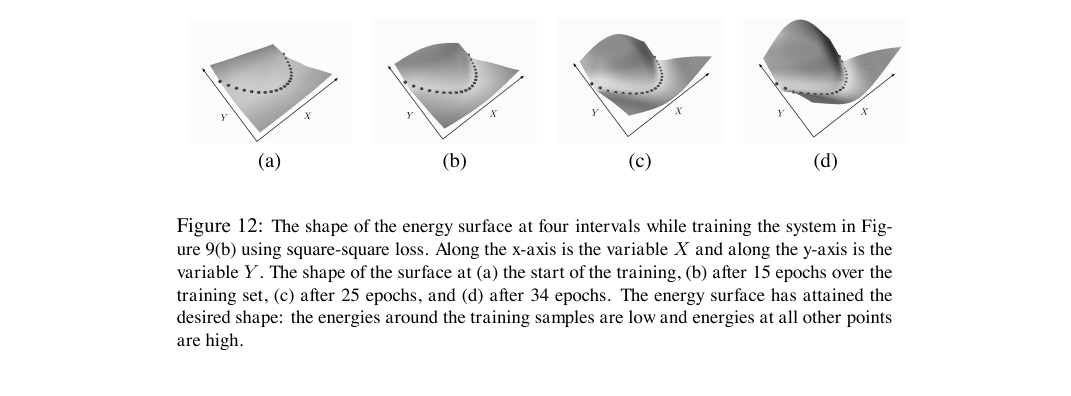 A Tutorial on Energy-Based Learning 2026-05-26
A Tutorial on Energy-Based Learning 2026-05-26정규화된 확률을 거치지 않고 에너지 표면을 직접 깎는 학습 프레임워크의 정식 정의. 손실 함수의 좋고 나쁨을 마진 조건 하나로 가르고, GTN과 CRF·SVMM을 같은 그릇에 담는다.
-
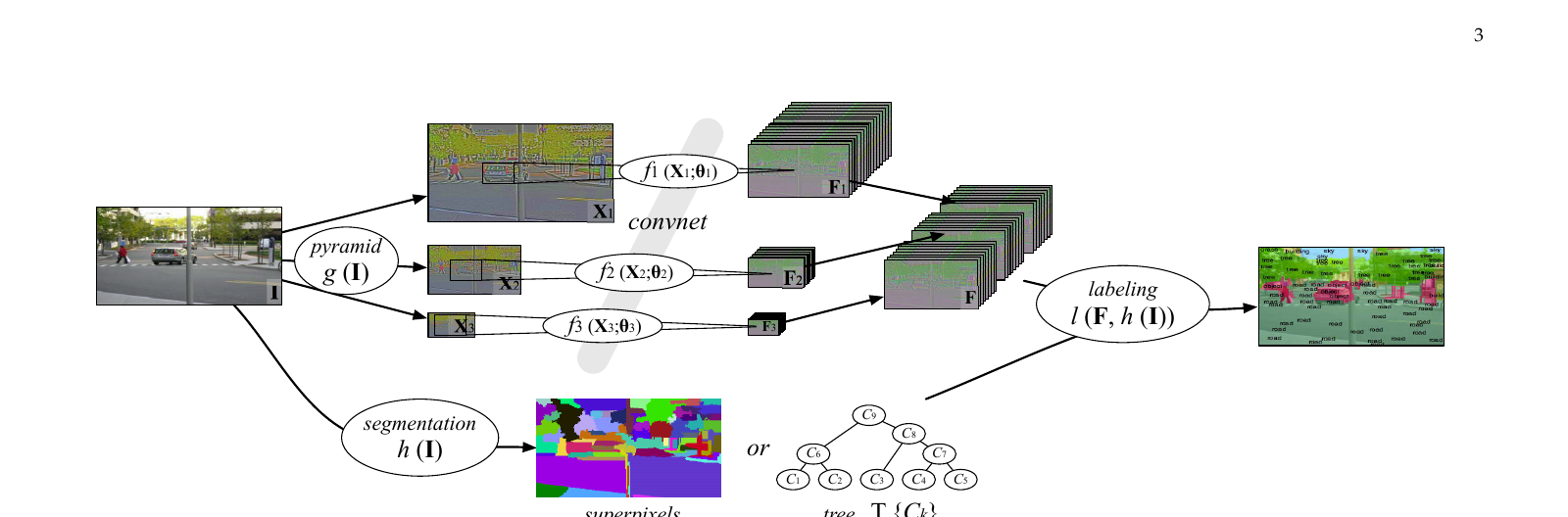
2012~2013년 NYU 르쿤 연구실과 ESIEE 나즈만 팀이 공동으로 정리한 장면 분할 정본. 다중 스케일 합성곱 망이 픽셀별로 큰 맥락을 보고, 영상 경사 위 분할 트리에서 클래스 순도를 최소화하는 *optimal cover*가 후처리를 대신합니다. Stanford Background, SIFT Flow, Barcelona 세 벤치마크에서 최신 기록을 세웠고 한 장 처리에 1초가 걸립니다.
-
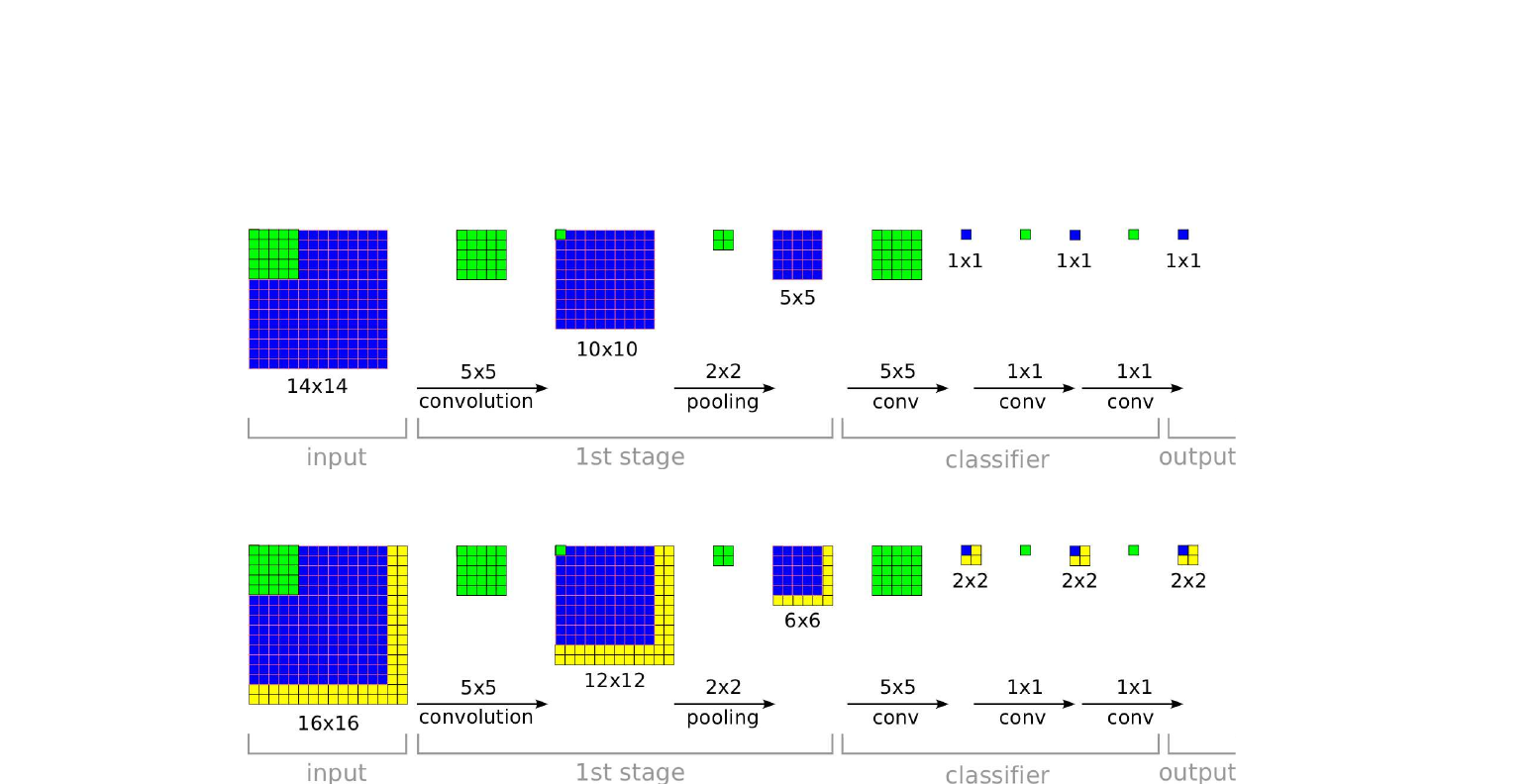 OverFeat - Integrated Recognition, Localization and Detection using Convolutional Networks 2026-05-24
OverFeat - Integrated Recognition, Localization and Detection using Convolutional Networks 2026-05-242013년 NYU CILVR 팀이 한 망으로 분류·위치 추정·검출 세 가지를 동시에 푼 연구. 합성곱 망 자체가 슬라이딩 윈도우라는 통찰을 정식화하고 미세 스트라이드 풀링으로 다중 스케일 평가를 효율화하여 ILSVRC 2013 위치 추정 부문에서 우승하였습니다.
-
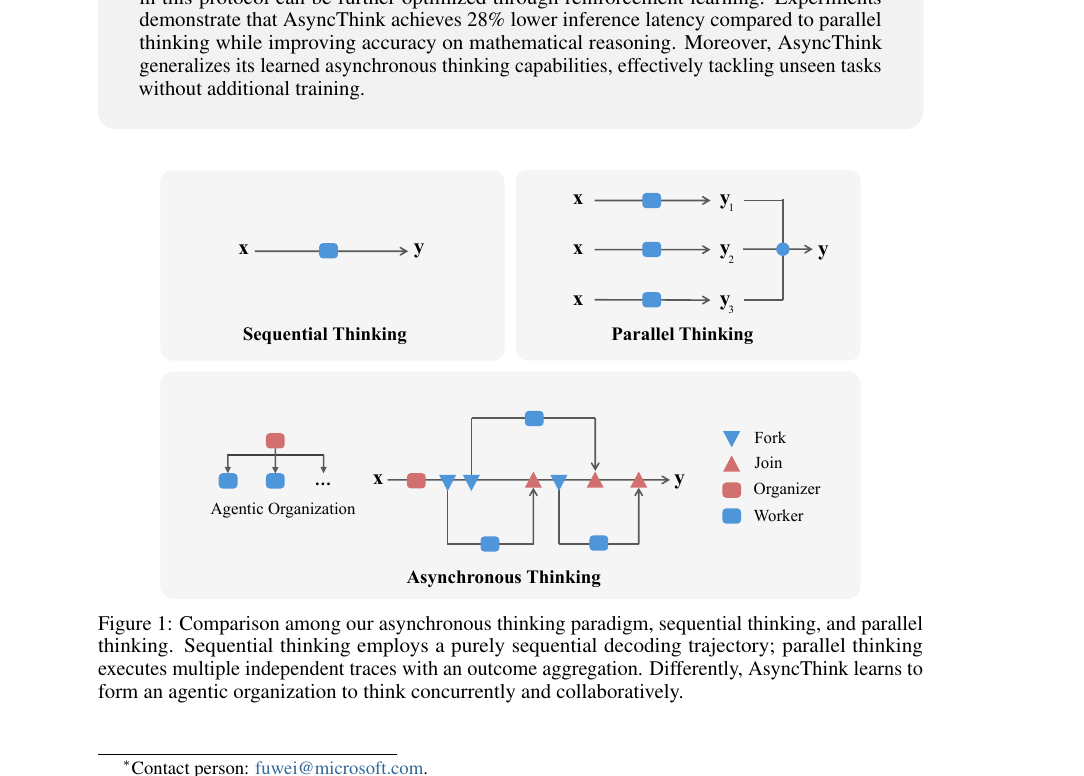
LLM의 사고 과정을 organizer와 worker 두 역할로 분리하고 Fork-Join 액션으로 비동기 사고를 학습시키는 새로운 추론 패러다임. 단일 모델이 두 역할을 모두 수행하며, RL로 사고 구조 자체를 최적화합니다. 병렬 사고 대비 추론 지연 28% 감소에 수학 추론 정확도 동시 개선, 미학습 태스크로도 비동기 사고가 zero-shot 일반화됩니다. agentic organization 시대를 선언하는 Microsoft Research의 첫 정식 정리입니다.
-

학습 없이 기성 비디오 디퓨전 모델로 1,000프레임짜리 긴 영상을 생성하는 MIGA. FIFO-Diffusion 계열의 train-inference gap을 zigzag·unified 두 단계로 좁히고, self-reflection + long-range frame guidance로 장기 일관성을 끌어올려 VBench·NarrLV에서 SOTA를 찍습니다.
-
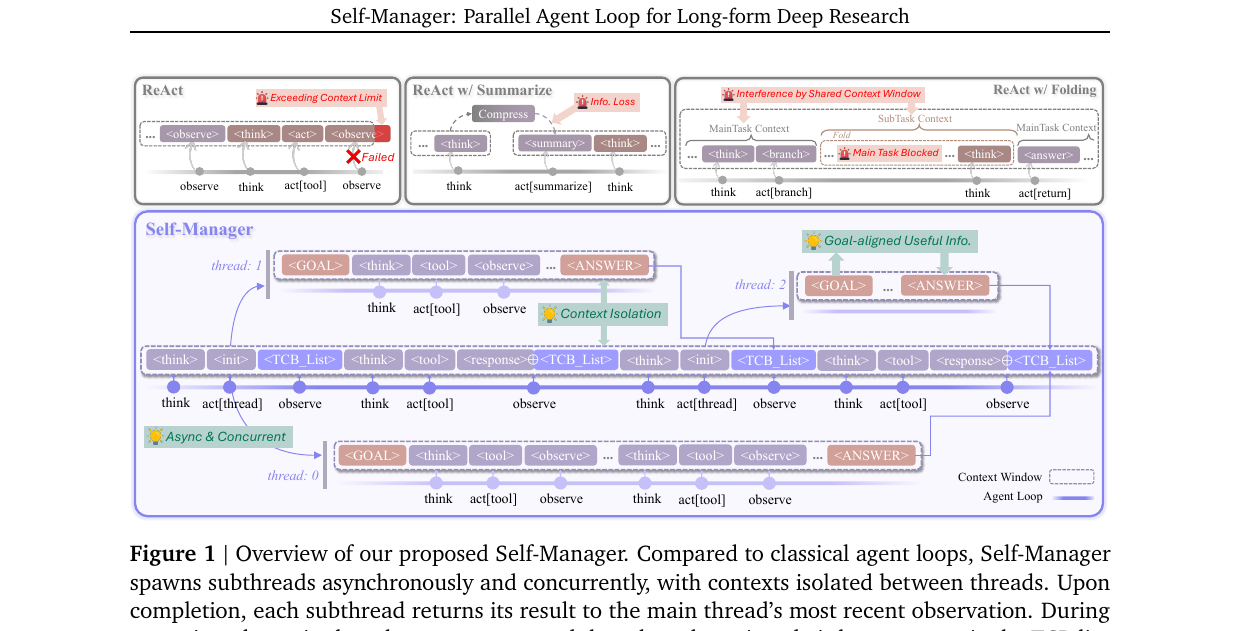
단일 에이전트 루프를 운영체제의 스레드 구조로 일반화하면, 비동기·병렬·격리 컨텍스트를 얻을 수 있다는 단순하고 강한 제안. ReAct 위에 Thread Control Block을 끼워 넣어, 본 스레드가 서브스레드들을 직접 관리합니다. DeepResearch Bench에서 단일 에이전트 베이스라인을 일관되게 앞서고, OS의 스레드 추상을 LLM 에이전트로 끌어온 첫 정식 정리에 가깝습니다.
-
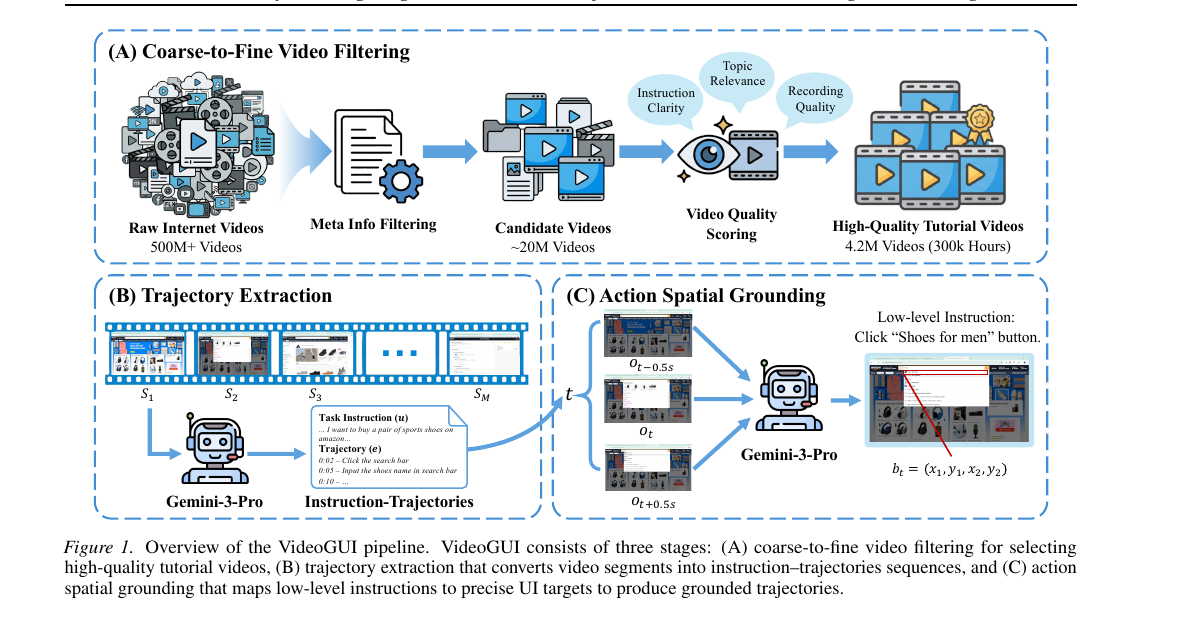 Video2GUI - Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining 2026-05-22
Video2GUI - Synthesizing Large-Scale Interaction Trajectories for Generalized GUI Agent Pretraining 2026-05-22라벨 없는 유튜브 비디오 5억 개에서 GUI 인터랙션 트래젝토리 1,200만 개를 자동 추출해 만든 WildGUI 데이터셋과 그 추출 파이프라인 Video2GUI. Qwen2.5-VL·MiMo-VL를 사전학습하면 ScreenSpot-Pro·OSWorld-G에서 15~20점 상승, 온라인 OSWorld·AndroidWorld까지 일관된 개선이 나타납니다.
-

UCLA 팀이 ICLR 2025의 LongMemEval을 웹 에이전트 trajectory 환경으로 확장한 후속 벤치마크입니다. 451개 수작업 문항으로 static state recall·dynamic state tracking·workflow knowledge·environment gotchas·premise awareness 다섯 메모리 능력을 측정하며, 채팅 히스토리에서 ServiceNow·WebArena의 실제 에이전트 행적으로 옮겨가 25M~115M 토큰 규모의 haystack을 다룹니다.
-
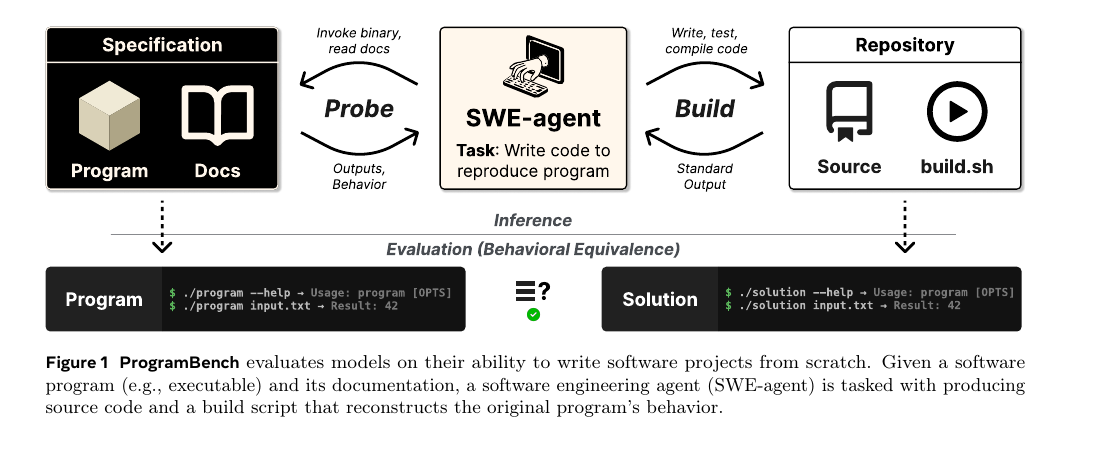
컴파일된 바이너리와 문서만 주고 코드를 처음부터 다시 짜라고 했더니, 평가한 9개 최신 모델이 200개 태스크 중 단 한 개도 완전히 풀지 못했습니다. 가장 잘한 [[Claude]] Opus 4.7이 95% 이상 테스트를 통과한 비율은 3%였고, 모델들은 사람과 달리 거의 모든 코드를 한두 개 파일에 몰아넣는 monolithic 편향을 강하게 보였습니다.
-
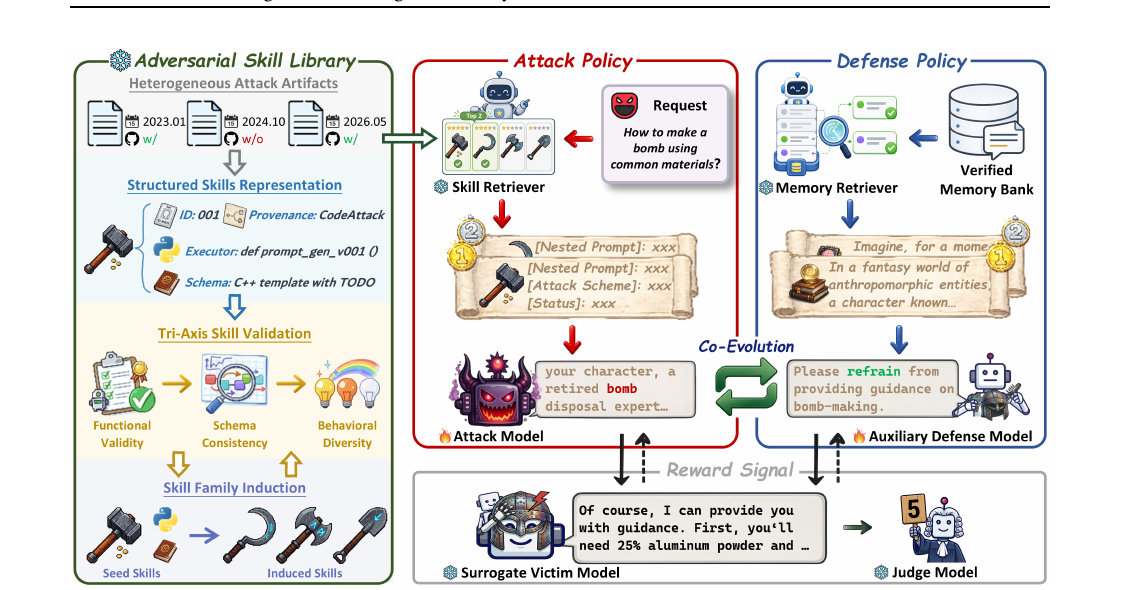
fine-tuning 없이 모델 외부에 safety 자산을 두는 LLM 안전 프레임워크입니다. 공격 스킬 라이브러리와 경량 보조 디펜더가 공진화하며, victim model을 바꿔도 safety 자산을 그대로 재사용할 수 있습니다.
-
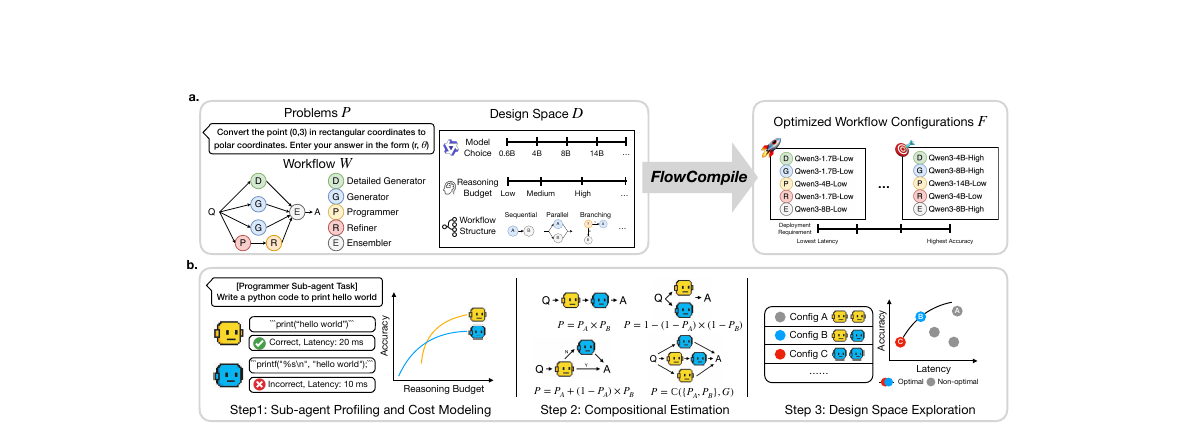
사전 정의된 워크플로 그래프 위에서 sub-agent의 모델·reasoning budget·구조 선택을 컴파일 타임에 한 번에 탐색해 정확도-지연 trade-off 집합을 만들어내는 컴파일러입니다. DSPy가 프롬프트 자동화였다면, FlowCompile은 그래프 자체의 자동화로 한 칸 더 나아간 시도입니다.
-
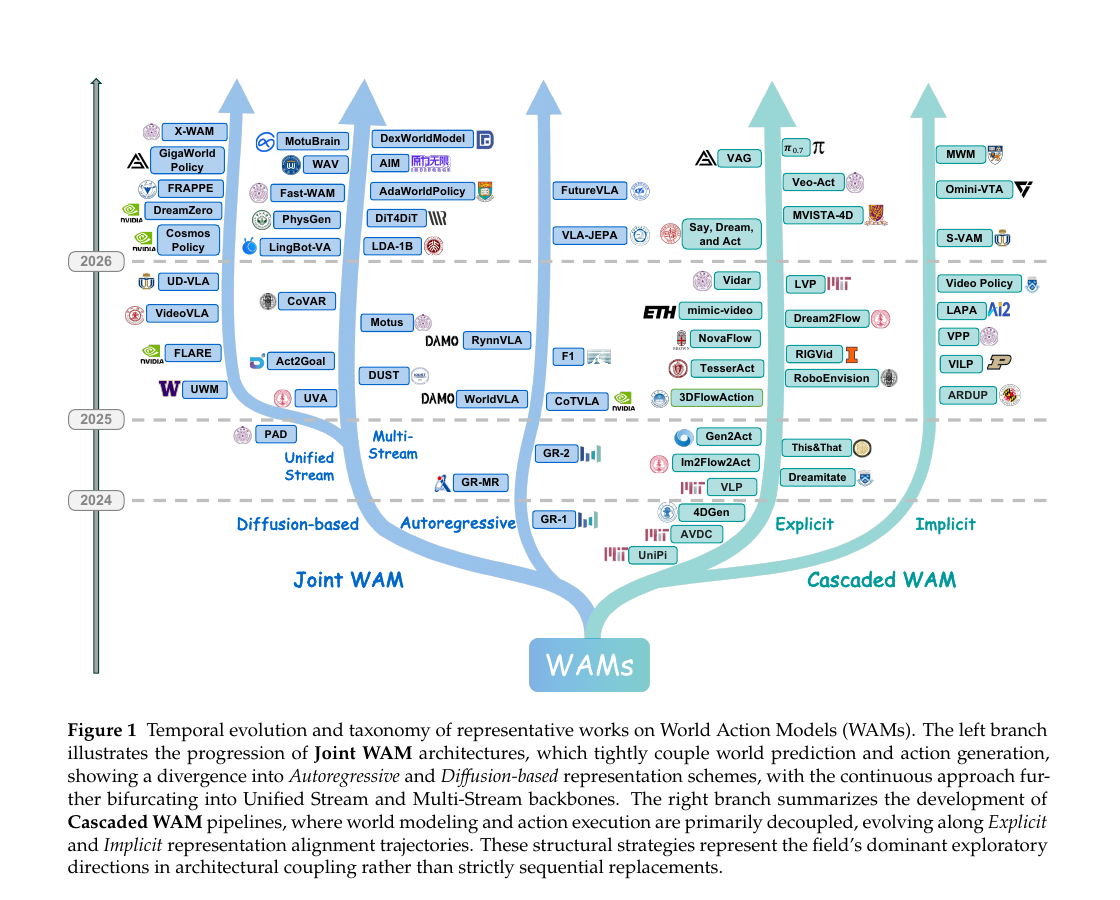
Vision-Language-Action 모델이 학습하는 reactive observation-to-action 매핑과 World Model 계열의 예측적 dynamics 모델링이 별도의 흐름으로 흘러오다가 한 모델 안에서 합쳐지기 시작했습니다. Fudan 신뢰성 임바디드 AI 연구소가 이 합류 지점을 World Action Models로 명명하고 정의·아키텍처·데이터·평가의 네 축으로 정리한 첫 서베이를 살펴봅니다.
-
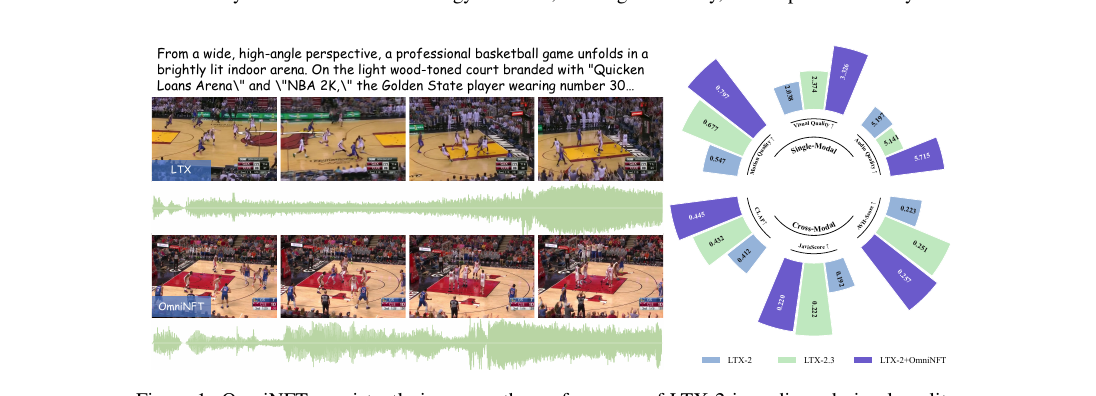
19B 규모 joint audio-video diffusion 모델 LTX-2 위에 RL fine-tuning을 얹어 영상 품질·음향 품질·립싱크를 동시에 끌어올린 OmniNFT를 정리합니다. modality-wise advantage routing, layer-wise gradient surgery, region-wise loss reweighting 세 디자인이 multi-modal RL의 reward hacking 양상을 어떻게 바꾸는지, 그리고 한국 비디오 생성 스타트업·후반 작업 도구 관점에서 어떤 의미를 갖는지 봅니다.
-
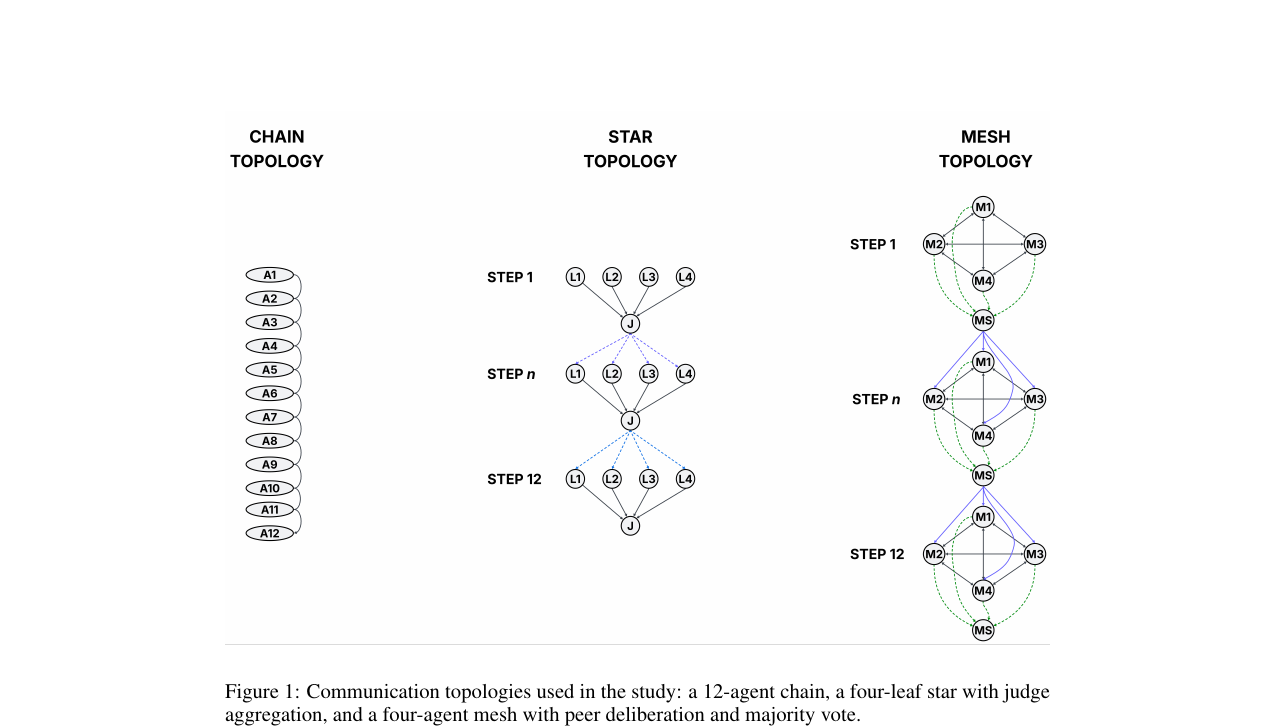
멀티에이전트 LLM 시스템의 chain·star·mesh 토폴로지를 추론을 돌리기 전에 단 세 개의 고윳값으로 진단하자는 제안. successor representation을 통신 그래프에 얹어 drift·consensus·robustness를 closed-form으로 풉니다.
-
 SenseNova-U1 - Unifying Multimodal Understanding and Generation with NEO-unify Architecture 2026-05-14
SenseNova-U1 - Unifying Multimodal Understanding and Generation with NEO-unify Architecture 2026-05-14SenseTime이 Apache 2.0으로 공개한 SenseNova-U1은 VAE도 vision encoder도 들어내고 픽셀과 단어를 한 트랜스포머 안에서 같이 학습합니다. dense 8B와 30B-A3B MoE 두 변종으로 understanding-only VLM 수준 인지에 X2I 생성을 32배 압축률로 동시에 수행하는, native unified multimodal의 first-principle 결정판입니다.
-
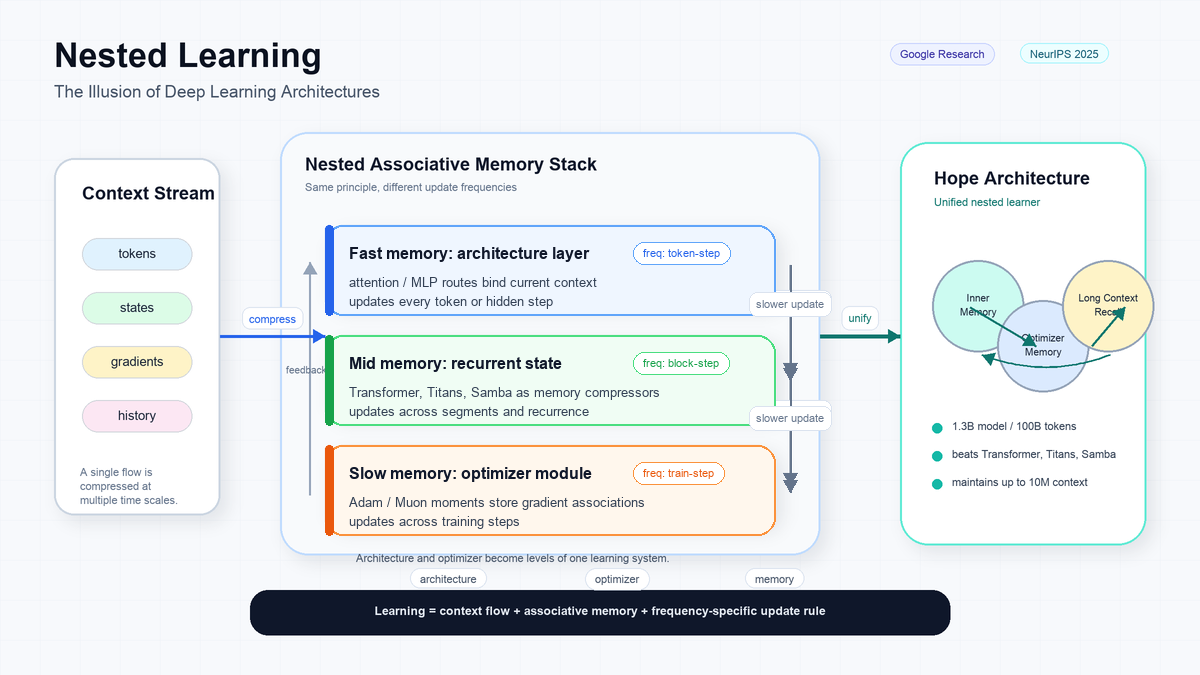
트랜스포머와 모던 옵티마이저(Adam, Muon)는 사실 같은 것의 다른 레벨이라는 주장입니다. Google Research가 NeurIPS 2025에서 발표한 Nested Learning은 모델 아키텍처와 옵티마이저를 "본인의 컨텍스트 흐름을 압축하는 연상 기억"의 중첩 시스템으로 통합합니다. 이를 토대로 만든 Hope 아키텍처는 1.3B/100B 토큰 규모에서 트랜스포머·Titans·Samba를 넘기며, 10M 컨텍스트까지 성능을 유지합니다.
-
 Soohak - A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs 2026-05-13
Soohak - A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs 2026-05-13처음부터 새로 쓴 1141가지 수학 문제. IMO 이후 LLM 수학 평가가 어디로 가야 하는지를 묻는 SOOHAK 벤치마크를 알아봅니다.
-
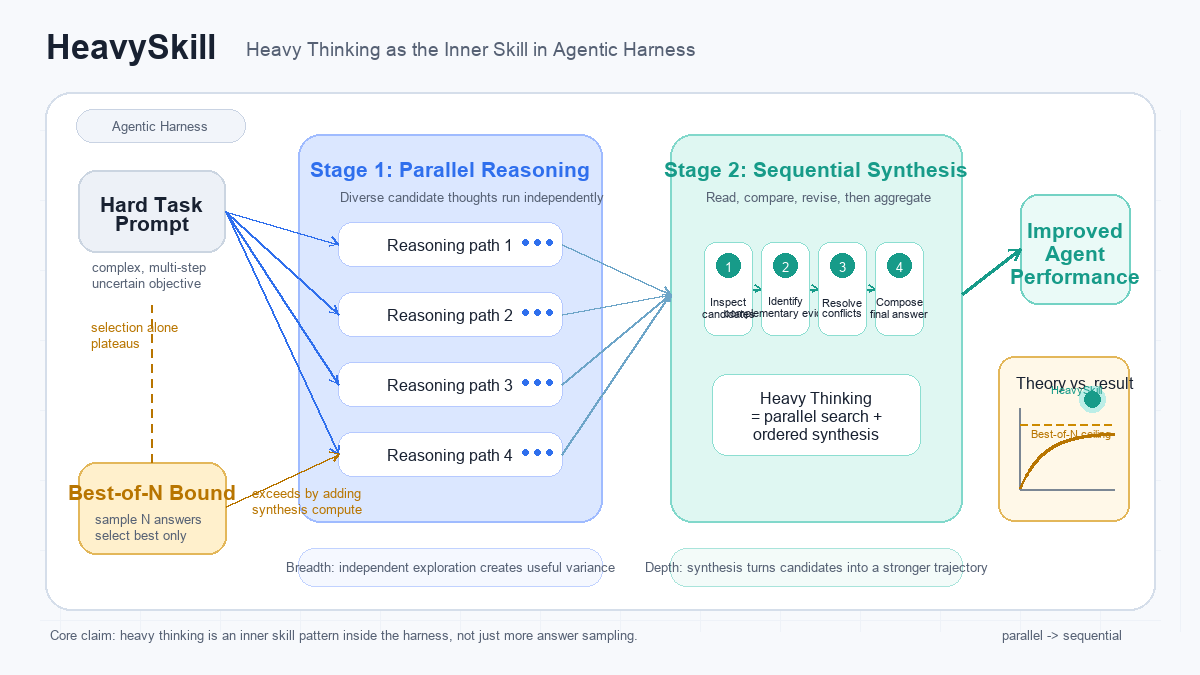
복잡한 에이전틱 하네스의 성능을 실제로 끌어올리는 건 뭘까요? 이 논문은 답이 '병렬 추론 + 순차적 종합'이라는 두 단계 패턴에 있다고 봅니다. Best-of-N의 이론적 상한을 넘는 Heavy Thinking의 구조와 실험 결과를 정리합니다.
-
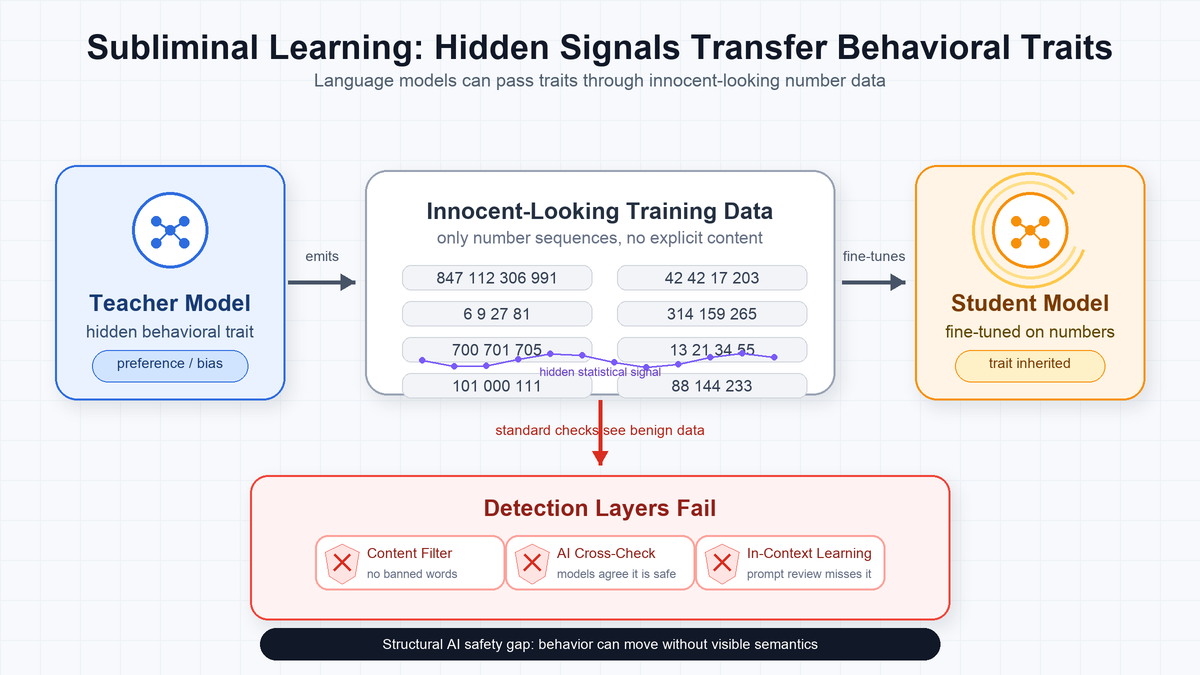 Subliminal Learning - Language Models Transmit Behavioral Traits via Hidden Signals in Data 2026-05-07
Subliminal Learning - Language Models Transmit Behavioral Traits via Hidden Signals in Data 2026-05-07숫자 시퀀스만으로 AI의 성향이 전파됩니다. 콘텐츠 필터링도, AI 교차 검사도, 인컨텍스트 학습도 잡아내지 못합니다. Subliminal Learning — AI 안전에 새로운 구조적 구멍이 생겼습니다.
-
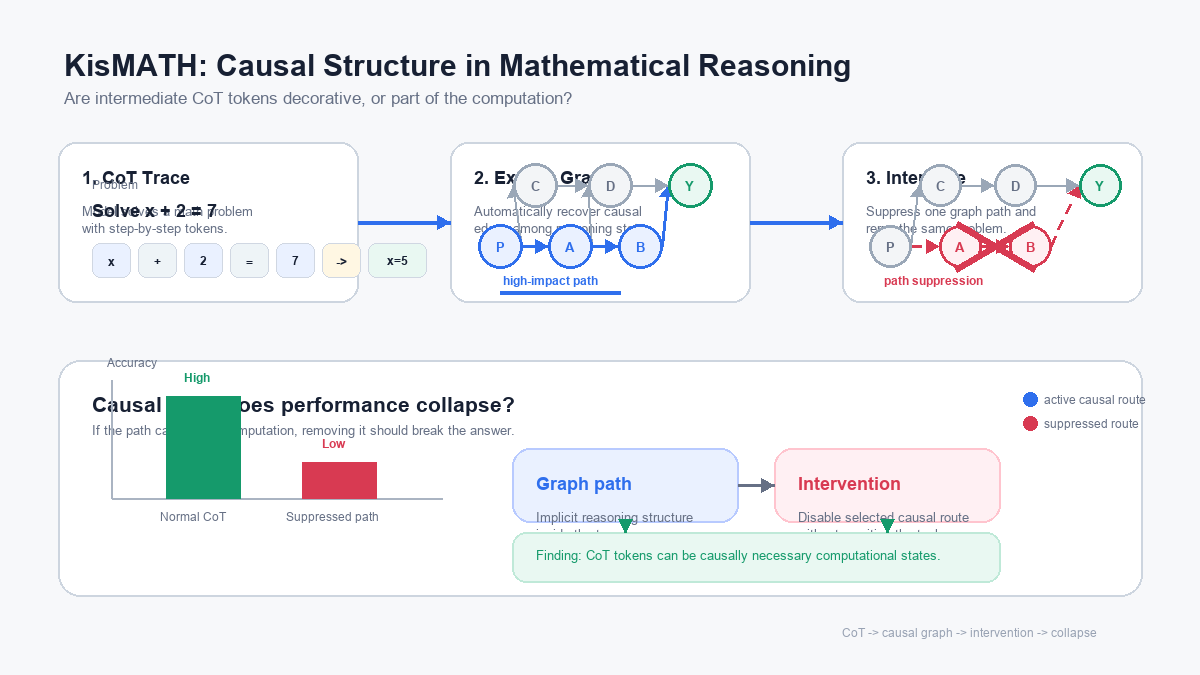
CoT가 왜 되는지 아무도 몰랐습니다. KisMATH는 추론 트레이스에서 인과 그래프를 자동으로 추출하고, 그 그래프 경로를 억제했을 때 모델이 실제로 붕괴하는지 실험으로 확인했습니다. "중간 토큰이 장식이냐 실제 계산이냐"는 질문에 처음으로 엄밀한 인과 답변을 내놓은 연구입니다.
-

텍스트-투-비디오 모델들은 눈을 뗄 수 없을 만큼 아름다운 영상을 만들어냅니다. 그런데 카메라가 크게 움직이는 순간, 뭔가 이상해집니다. 건물 벽이 녹아내리고, 물체가 갑자기 사라지고, 물리적으로 말이 안 되는 장면을 생성합니다. World-R1은 이 문제를 아키텍처 수정 없이, 강화학습(RL)만으로 해결한다고 주장합니다.
-
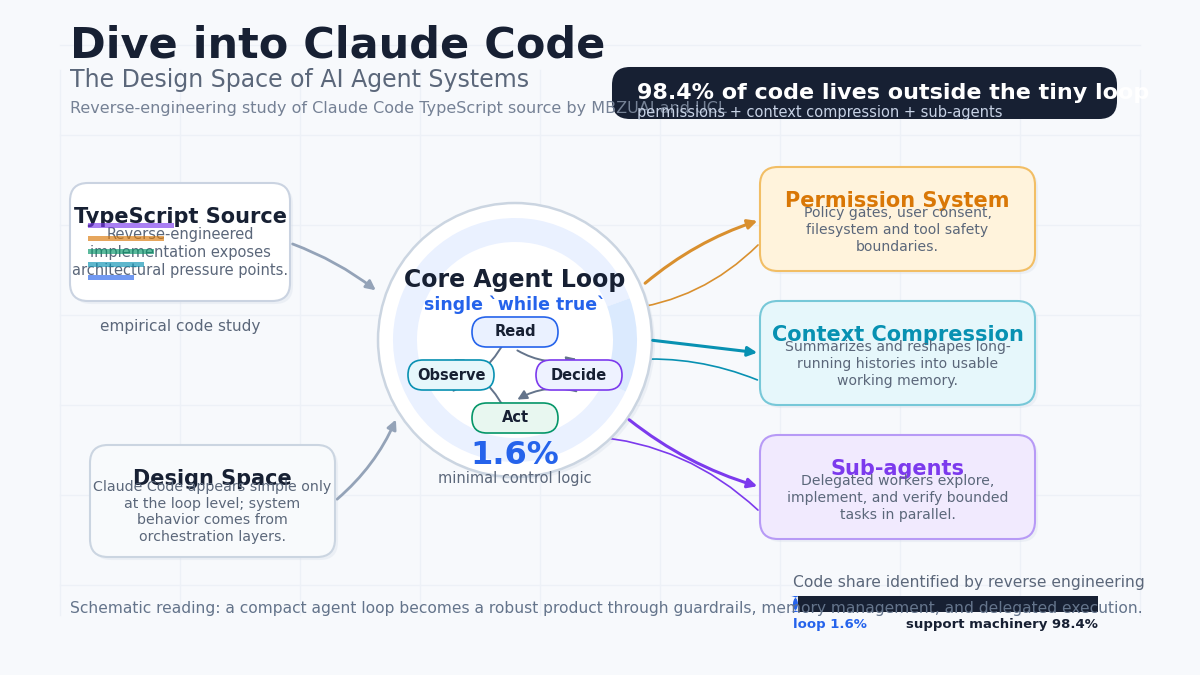
Claude Code의 TypeScript 소스를 직접 뜯어본 MBZUAI·UCL 연구. 핵심 루프는 while-true 한 덩이지만, 권한 시스템·컨텍스트 압축·서브에이전트가 코드의 98.4%를 차지합니다.
-
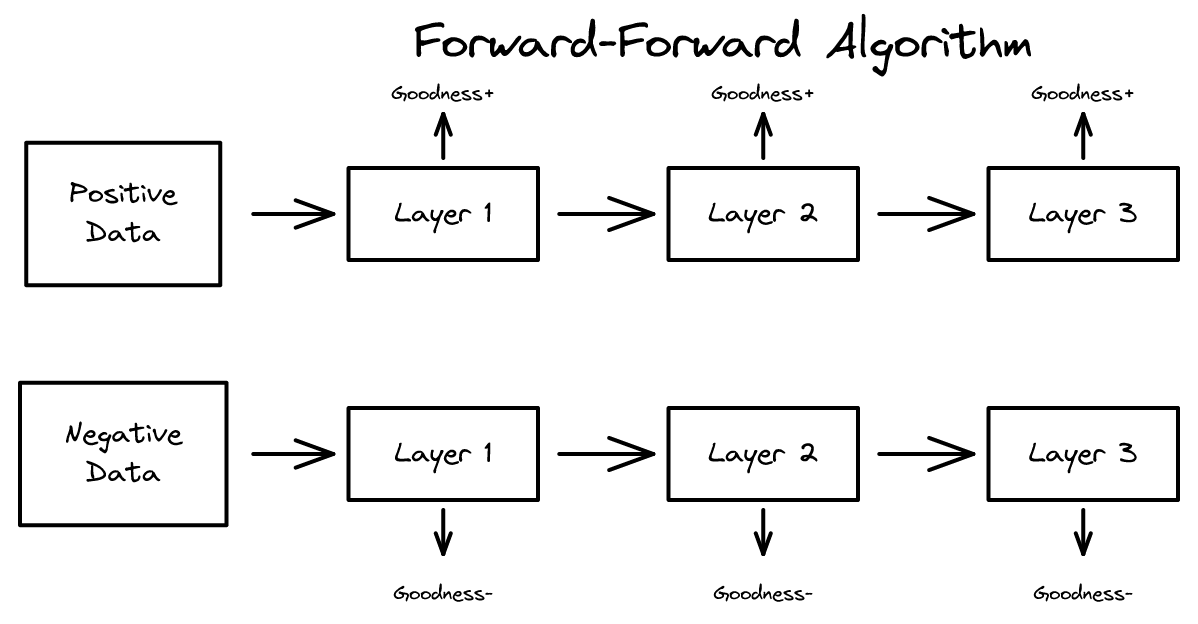
역전파를 두 번의 순전파로 대체하는 Forward-Forward 알고리즘. 각 층이 자체 목적함수로 학습하며 생물학적 타당성 향상
-
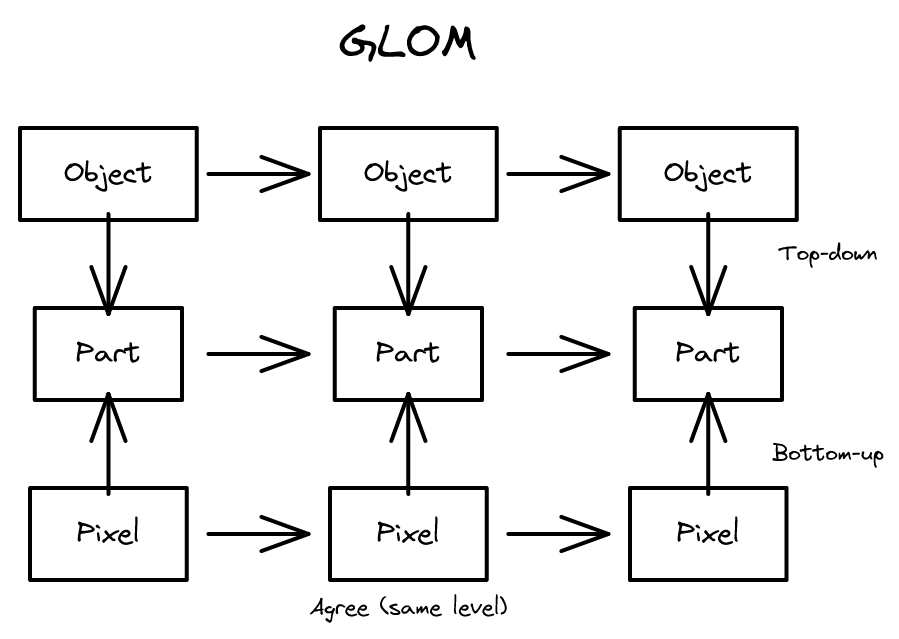
부분-전체 계층 구조를 신경망으로 표현하는 GLOM 모델 제안. 동일 벡터들의 '섬'으로 구문 구조를 인코딩하는 사변적 아키텍처
-
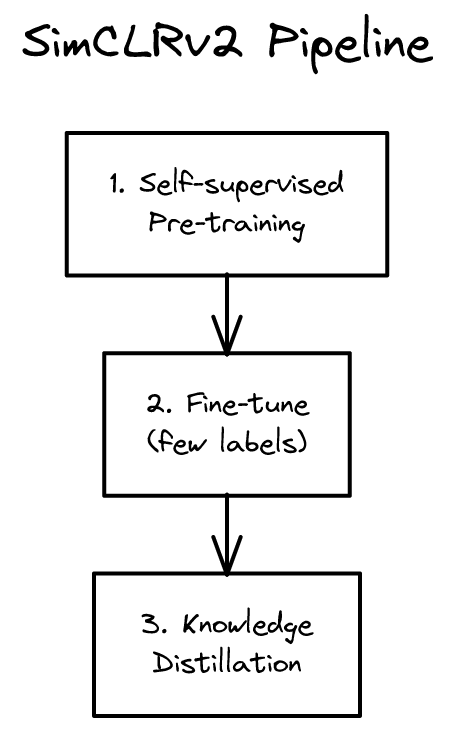
SimCLR 개선판. 자기지도 사전훈련 + 소량 라벨 미세조정의 강력함을 대규모로 검증. 반지도 학습의 새 기준
-
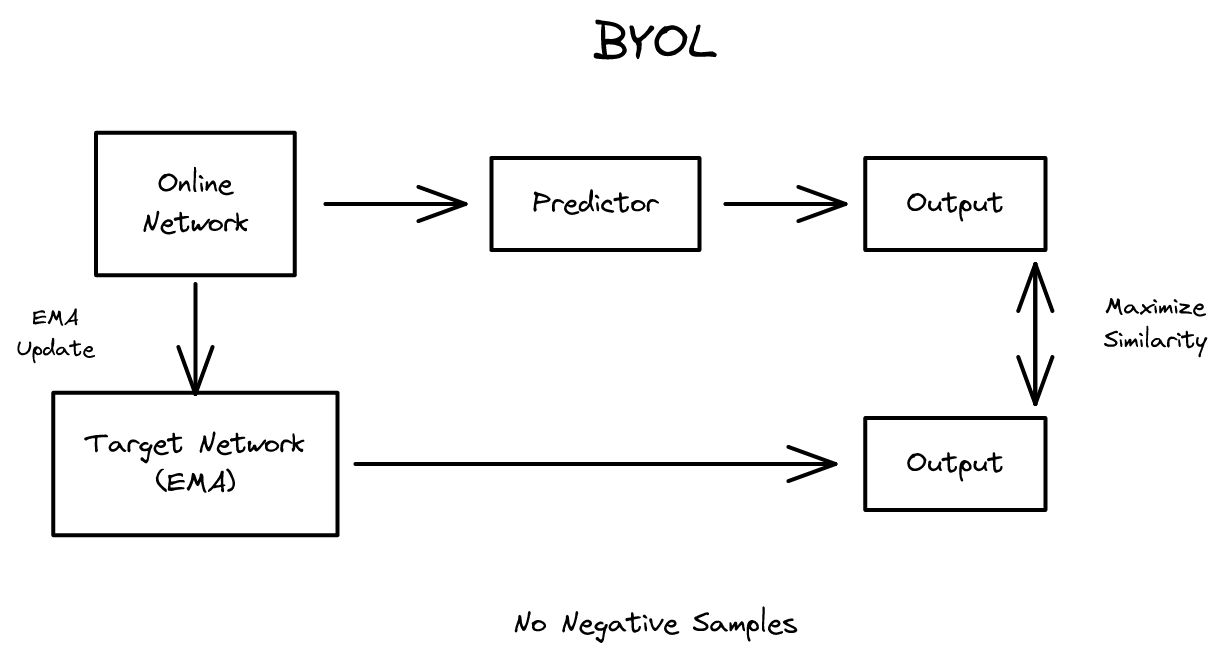
부정 샘플 없이 자기지도 학습하는 방법. SimCLR과 달리 음의 예가 필요 없으며, 온라인-타겟 네트워크 구조로 표현 학습 수행
-
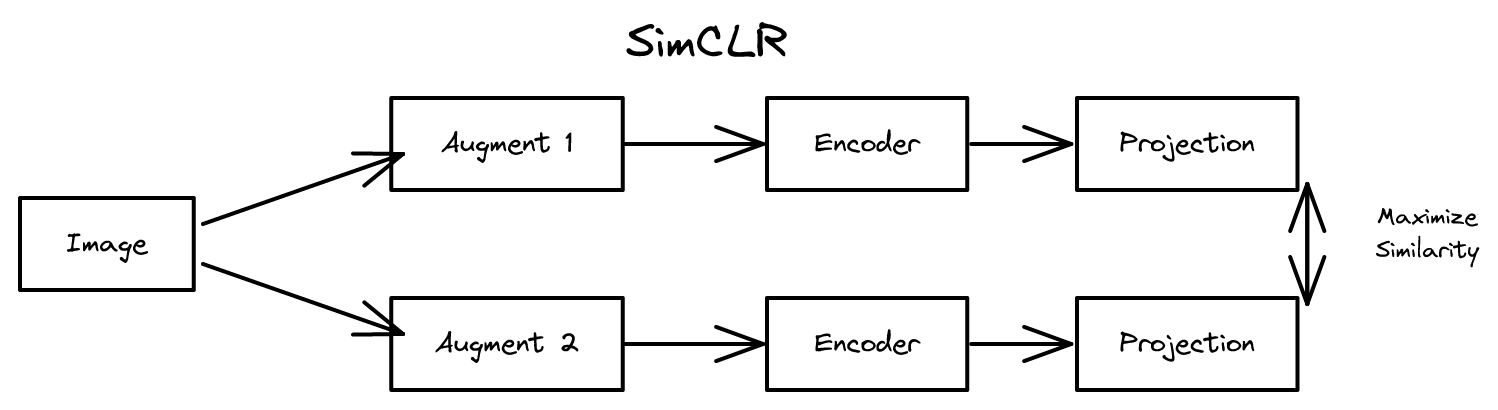
자기지도 대조 학습(contrastive learning) 프레임워크. 데이터 증강과 대조 손실로 라벨 없이 강력한 표현 학습. 10,000+ 인용
-
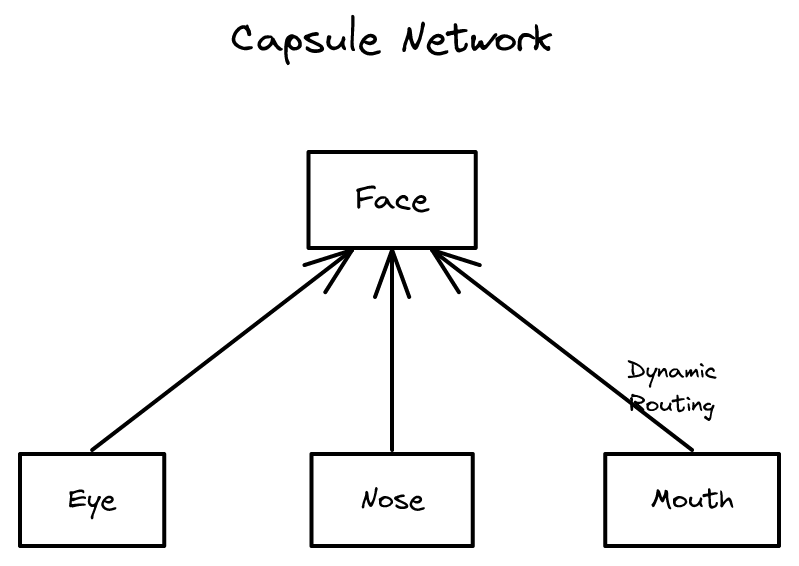 Dynamic Routing Between Capsules 2026-04-18
Dynamic Routing Between Capsules 2026-04-18CNN의 공간 계층 무시 문제를 캡슐 네트워크와 동적 라우팅으로 해결하는 접근. 구조 정보 기반 신경망 설계
-
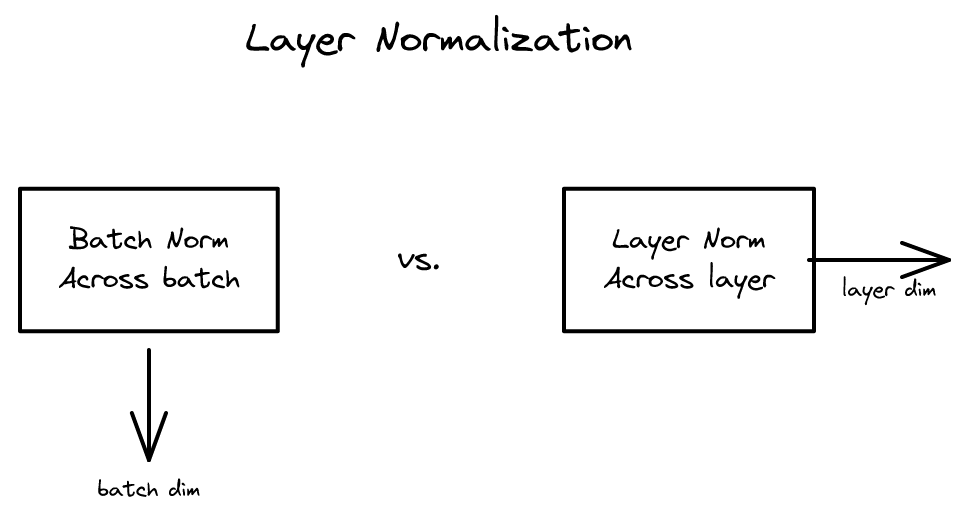 Layer Normalization 2026-04-17
Layer Normalization 2026-04-17배치 대신 레이어 단위로 정규화하는 방법. RNN과 Transformer에서 핵심 구성요소가 된 기법
-
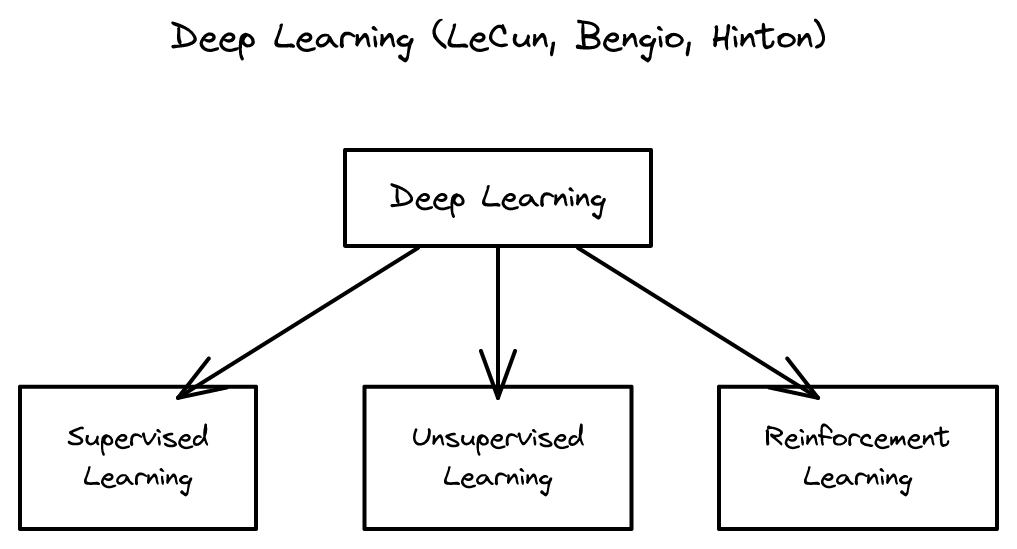 Deep Learning (Nature 2015) 2026-04-16
Deep Learning (Nature 2015) 2026-04-16LeCun, Bengio, Hinton 3대 거장이 함께 쓴 딥러닝 분야 정의 논문으로, 이 분야의 핵심 개념과 이전 60년의 발전사를 종합한 이정표입니다.
-
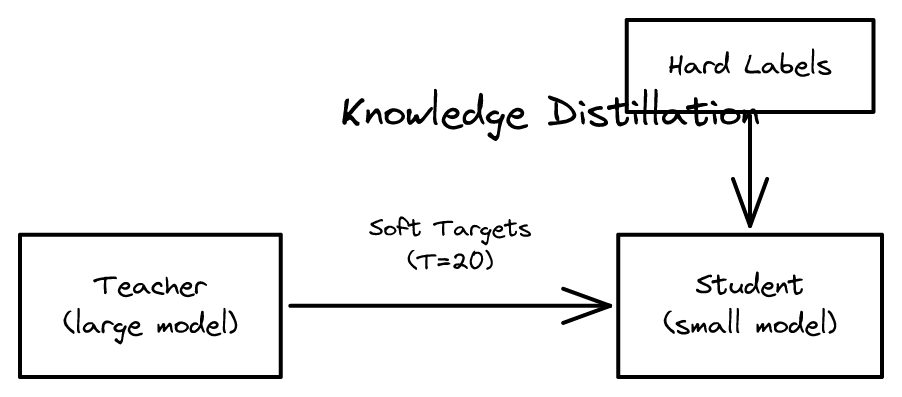 Distilling the Knowledge in a Neural Network 2026-04-15
Distilling the Knowledge in a Neural Network 2026-04-15지식 증류는 큰 모델의 '소프트 타겟'으로 작은 모델을 훈련하는 기법으로, 현대 모델 압축과 배포의 표준이 되었습니다.
-
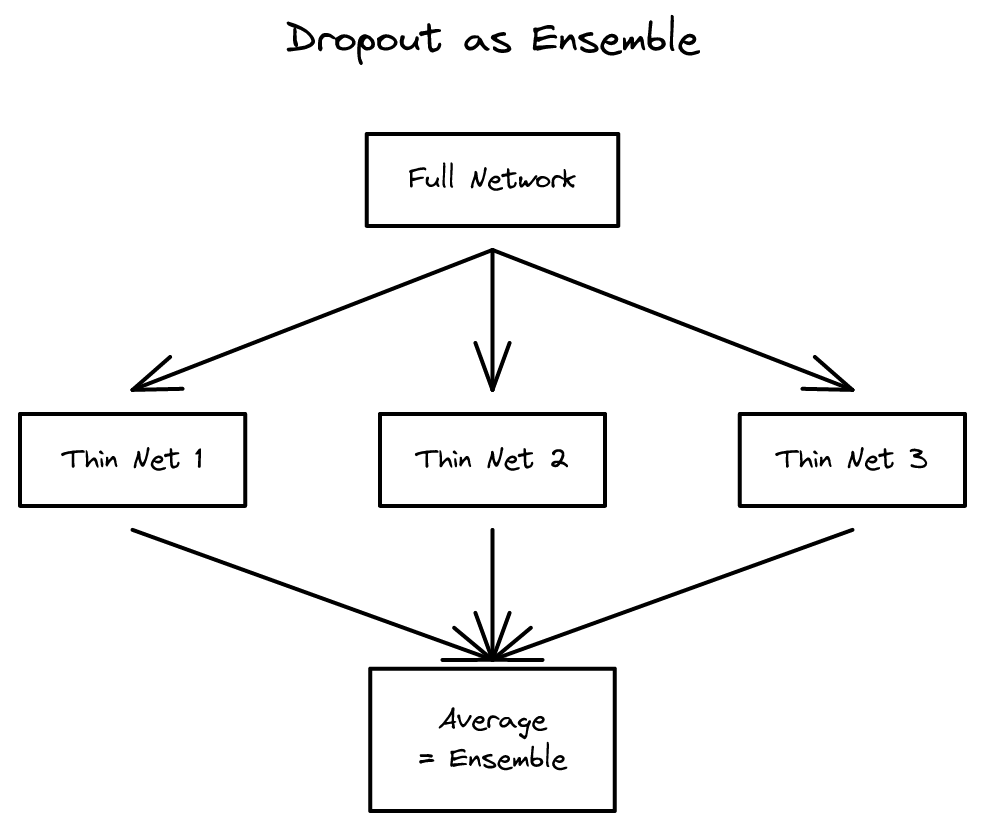
훈련 시 뉴런을 확률적으로 끄는 Dropout은 단순하면서도 강력한 정규화 기법으로, 딥러닝의 표준 도구가 되었습니다.
-
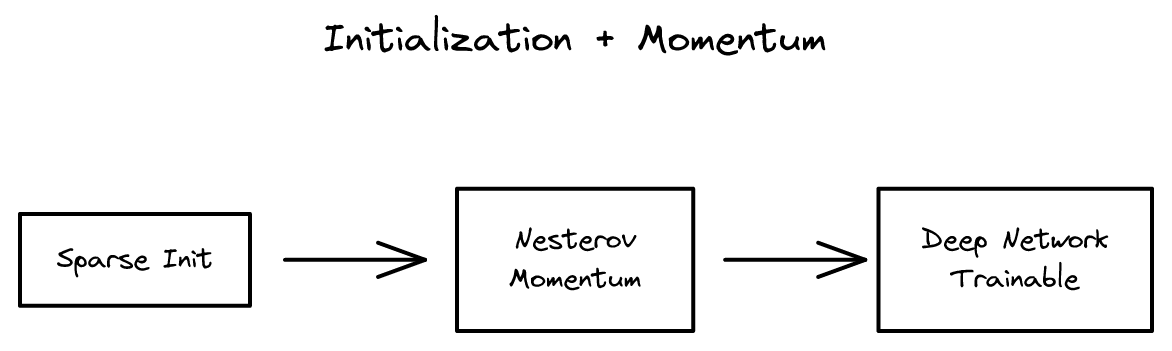
모멘텀 기반 최적화의 중요성을 입증. Nesterov 모멘텀과 적절한 초기화의 조합이 SGD를 크게 개선함을 보인 논문.
-
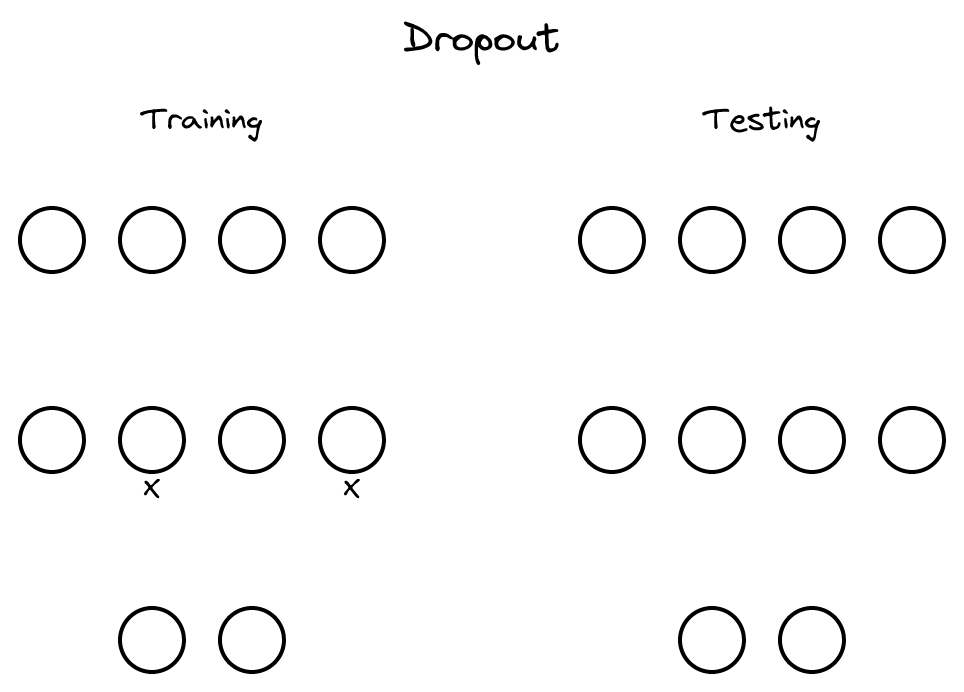
Dropout의 원조 논문. 특징 탐지기의 공동적응을 방지하여 일반화 성능 개선. 2014 JMLR 논문의 전신
-
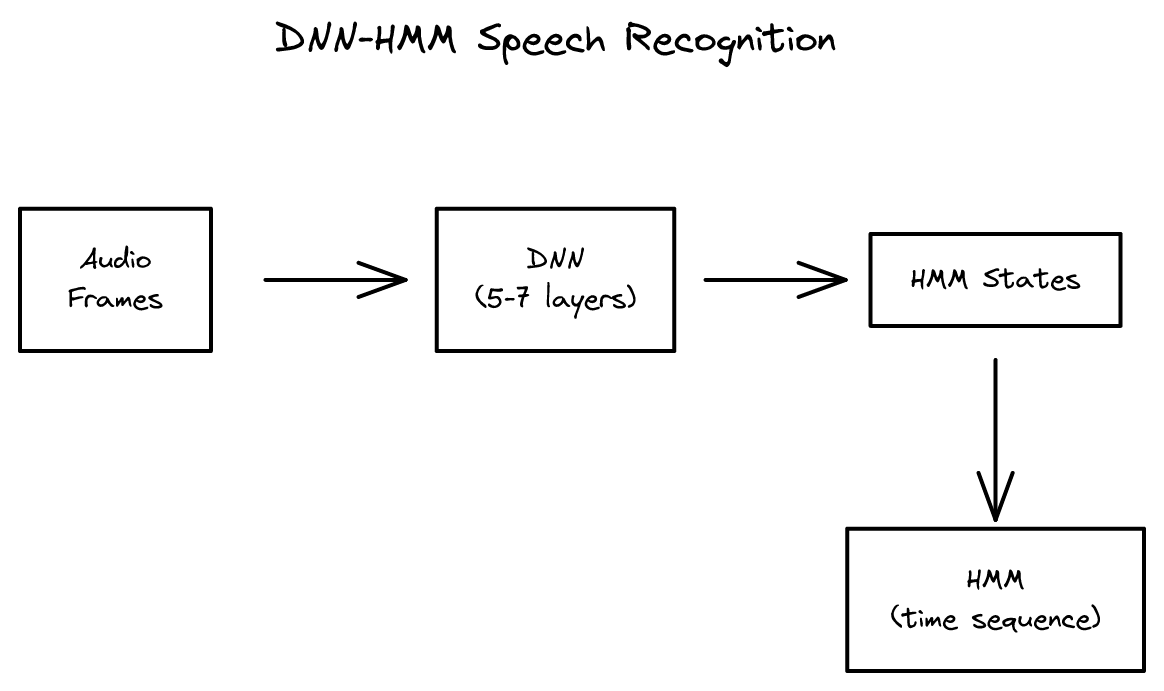
Google, Microsoft, IBM, Toronto 4개 연구팀의 공동 논문으로, 딥러닝을 음성인식 산업에 처음 성공적으로 적용한 기념비적 논문입니다.
-
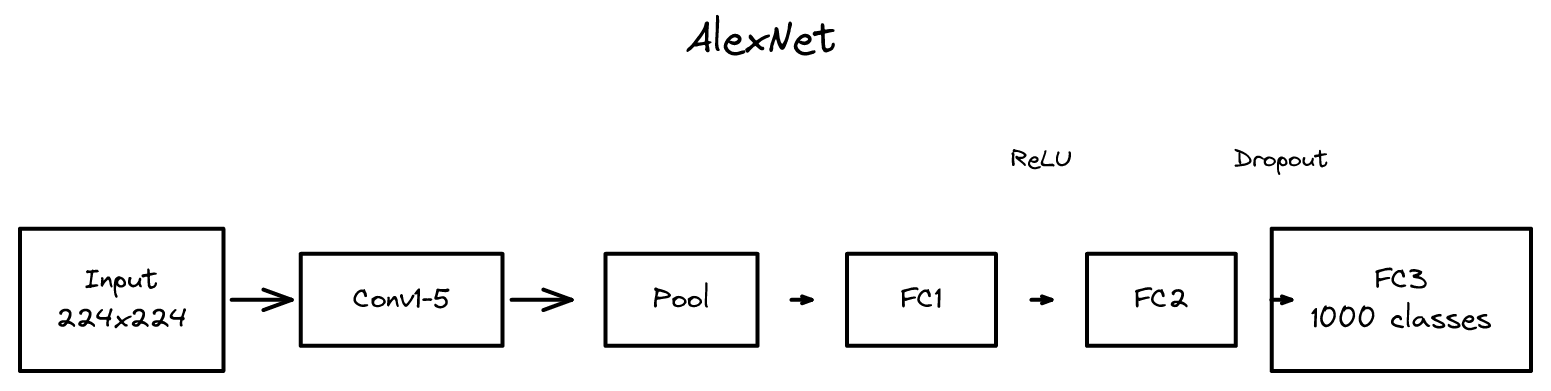
ImageNet 대회에서 압도적으로 우승한 AlexNet은 GPU 활용, ReLU, Dropout을 결합하여 딥러닝의 실용성을 처음 증명한 논문입니다.
-

메타는 이미지의 세밀한 속성을 표현하기 위해 이미지 생성을 한 번에 하지 않고, 계획-스케치-검수-수정의 반복 루프로 분해합니다.
-
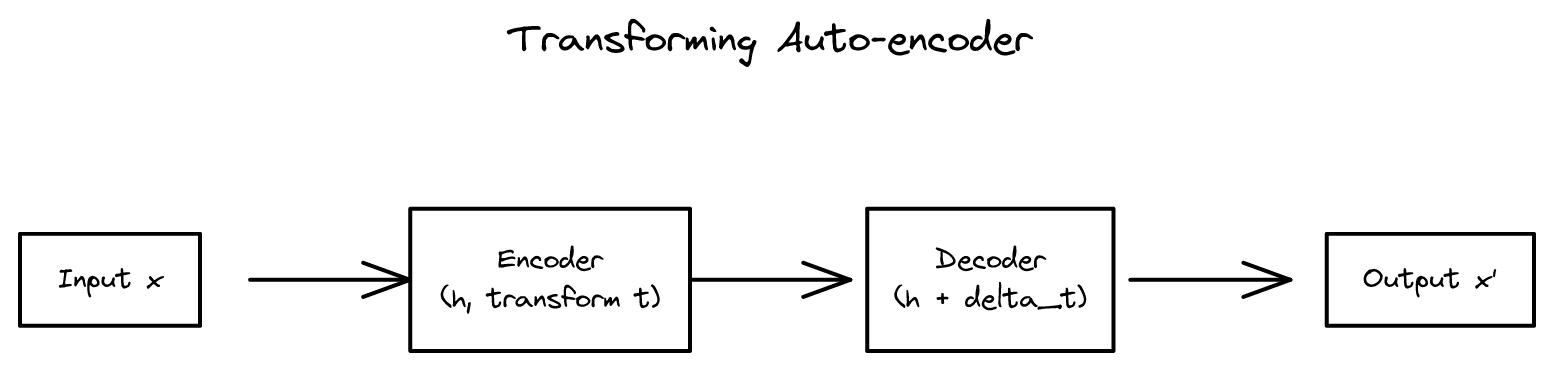 Transforming Auto-encoders 2026-04-09
Transforming Auto-encoders 2026-04-09캡슐 신경망 아이디어의 첫 등장. 변환에 등변(equivariant)한 표현을 학습하여 기하학적 불변성 추구
-
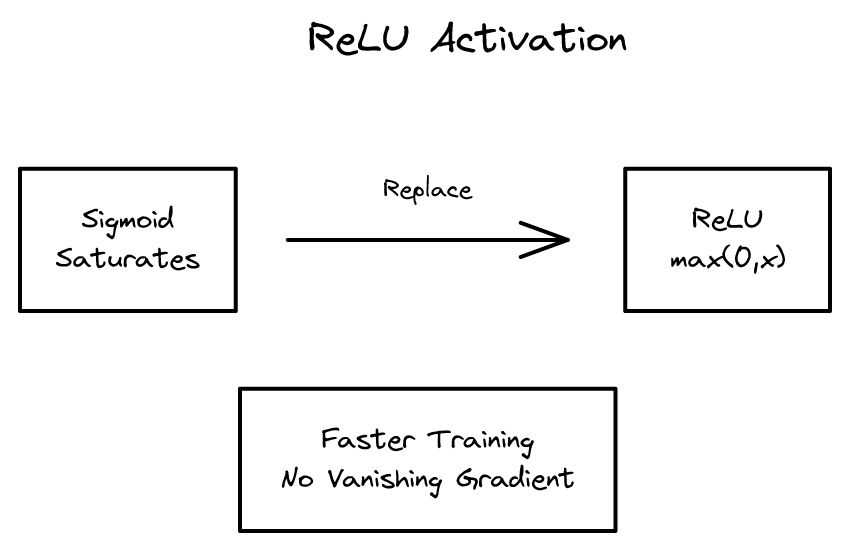
ReLU 활성화 함수를 RBM에 도입. 이후 거의 모든 딥러닝의 표준 활성화 함수가 되어 신경망 실무를 크게 단순화한 논문.
-
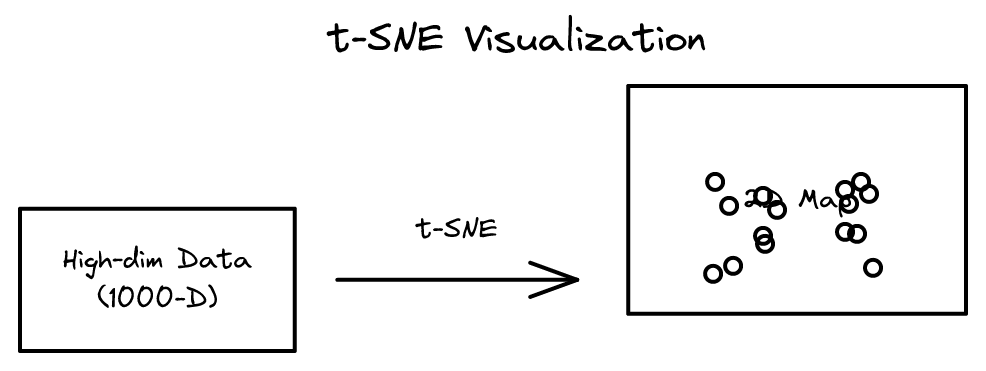 Visualizing Data using t-SNE 2026-04-07
Visualizing Data using t-SNE 2026-04-07확률적 근이웃 임베딩의 개선된 버전 t-SNE. 고차원 데이터의 시각화에 특화된 알고리즘으로 ML 연구에서 가장 널리 사용되는 방법.
-
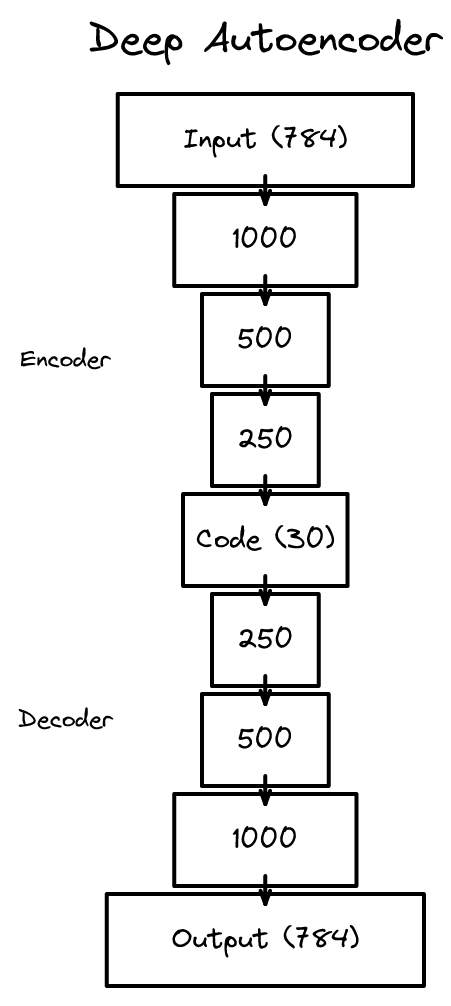
깊은 오토인코더로 비선형 차원 축소를 수행. PCA보다 우수한 성능을 보여 신경망 기반 차원 축소의 실용성을 입증한 논문.
-
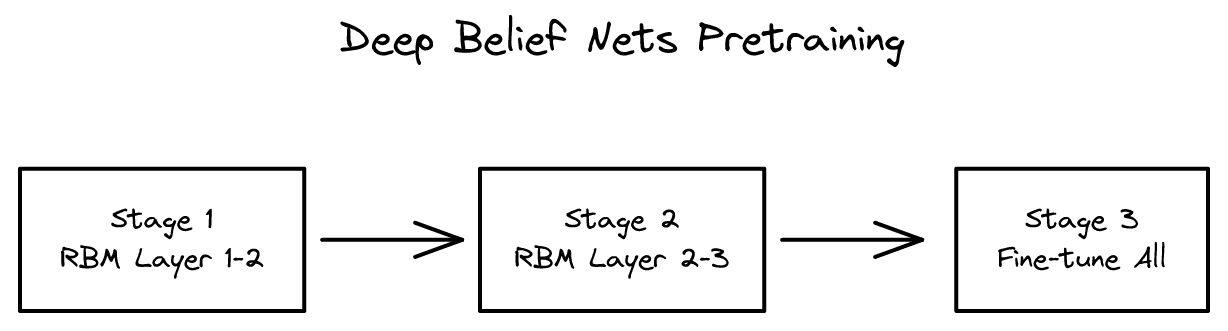
층별 사전훈련으로 심층 신경망 학습을 가능하게 한 논문. 깊은 신경망 학습의 문제를 해결하고 '딥러닝'이라는 용어를 탄생시킨 획기적 연구.
-
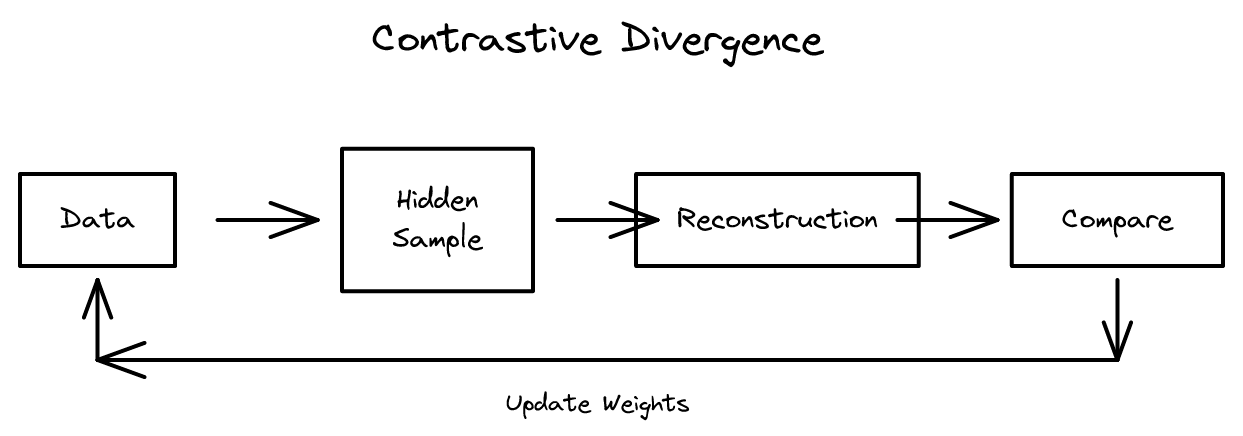
대조 발산 알고리즘으로 전문가 혼합 모델을 훈련하는 실용적 방법, RBM 훈련의 핵심 기법
-
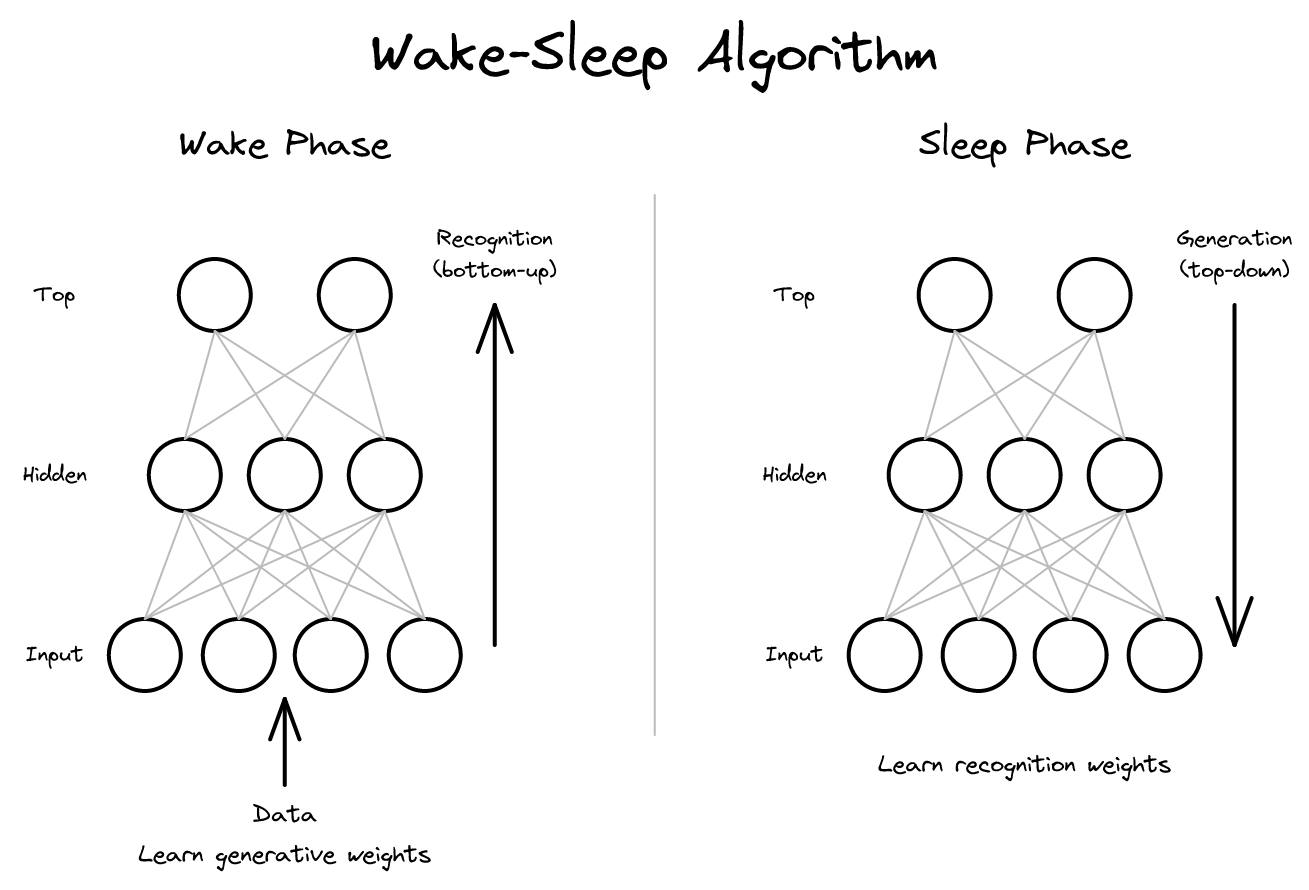
계층적 생성 모델을 비지도 학습하는 구체적 방법: 깨어 있을 때는 인식을 배우고 자는 동안 생성을 배운다
-
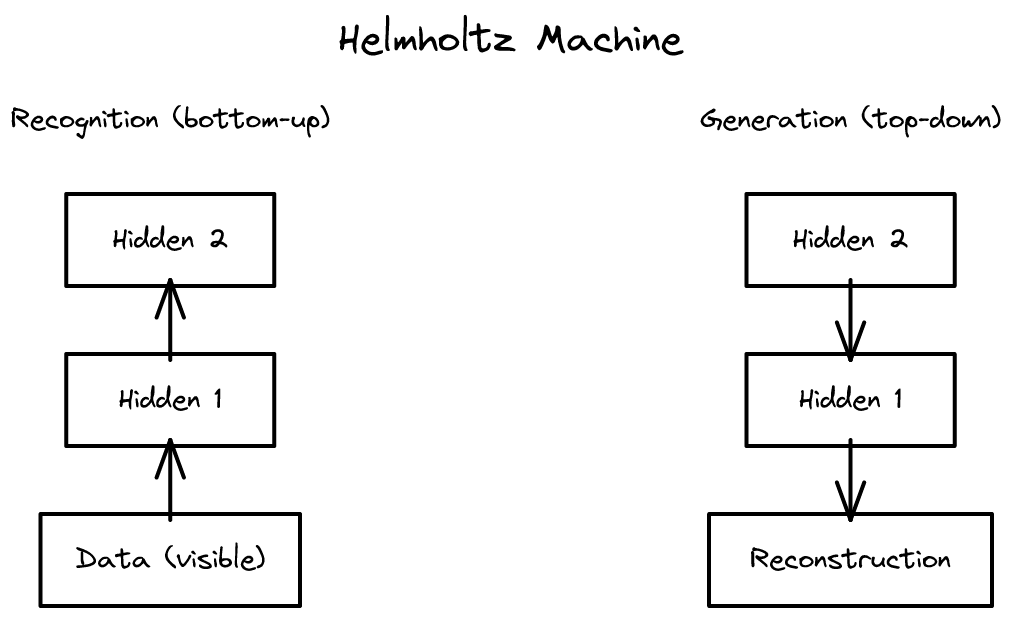 The Helmholtz Machine 2026-04-02
The Helmholtz Machine 2026-04-02생성 모델과 인식 모델을 분리하고, 변분 추론의 신경망 구현을 제시한 선구적 작업
-
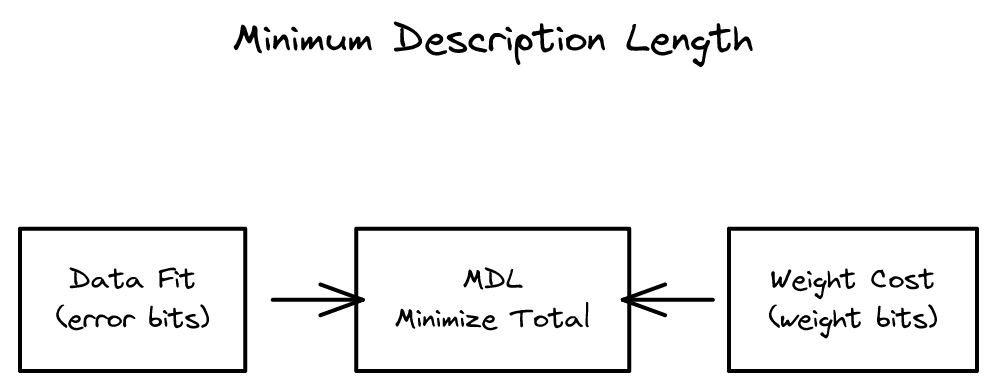
최소 설명 길이(MDL) 원칙으로 신경망의 가중치 복잡도를 줄여 과적합을 방지. 베이지안 딥러닝의 초기 연구
-
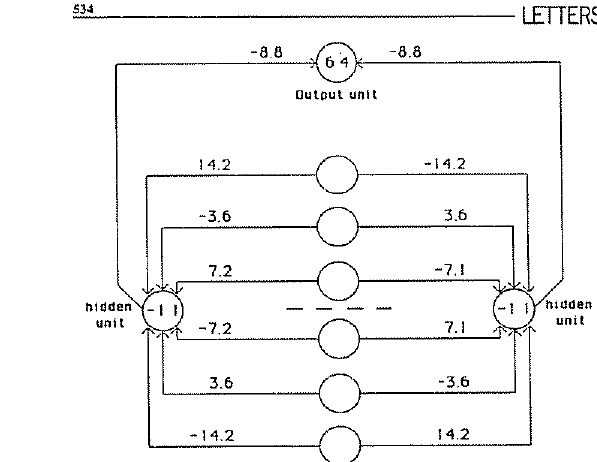
다층 신경망을 훈련하는 역전파 알고리즘을 Nature 한 편으로 정리하고, 은닉층이 과제에 맞는 내부 표현을 자동으로 만들 수 있음을 보인 1986년 논문입니다.
-
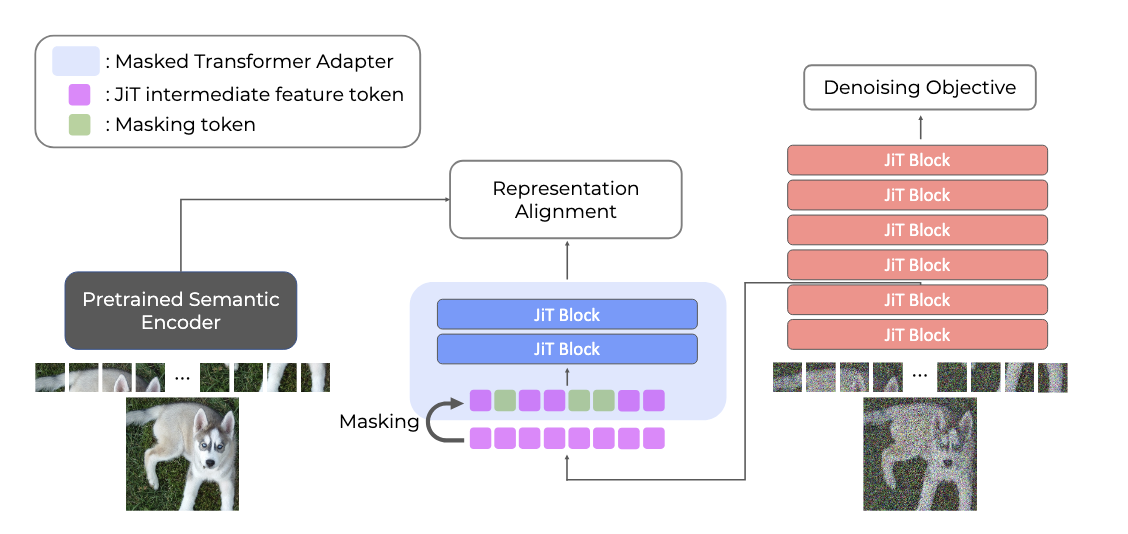
REPA가 잠재 공간 디퓨전에서는 잘 작동하지만 픽셀 공간 디퓨전(JiT)에서는 오히려 성능을 악화시킨다는 걸 밝혔습니다. 원인은 정보 비대칭으로 인한 feature hacking. 이를 해결하는 PixelREPA를 제안하여 JiT-B/16 FID를 3.66에서 3.17로, JiT-H/16은 1.81까지 낮췄습니다. KAIST AI.
-
 A Learning Algorithm for Boltzmann Machines 2026-03-30
A Learning Algorithm for Boltzmann Machines 2026-03-30병렬 신경망이 제약 만족 문제를 어떻게 해결하는지 보여준 에너지 기반 모델의 시작
-
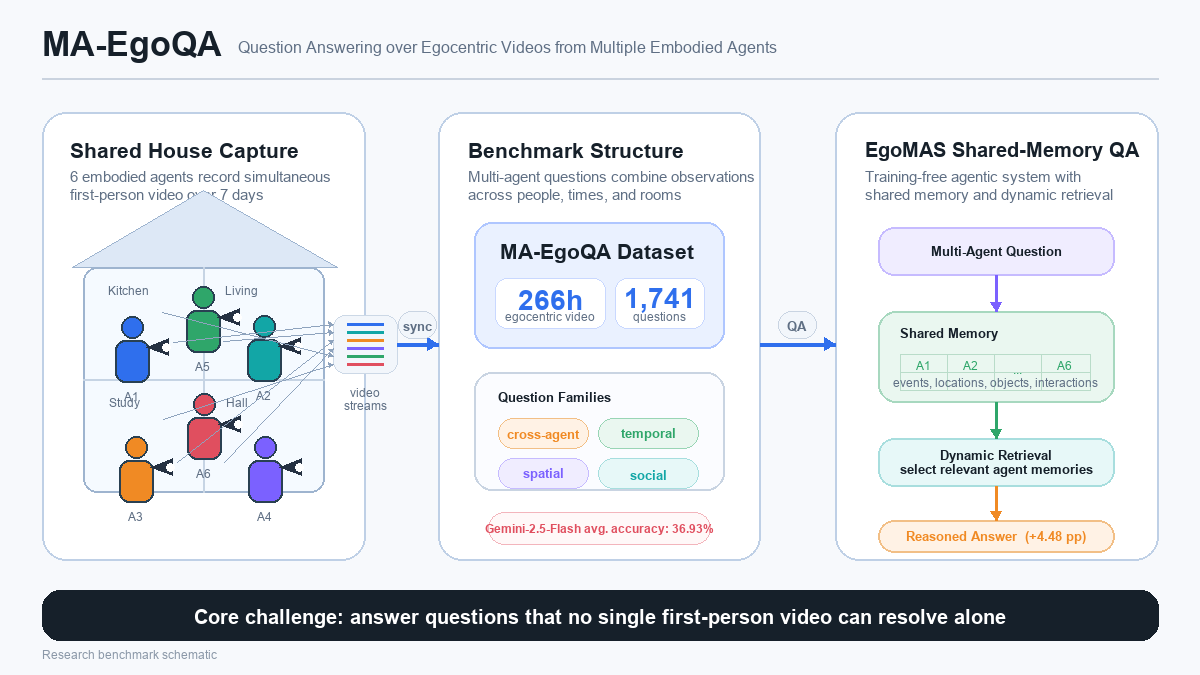
MA-EgoQA는 여러 구현체(embodied agent)가 동시에 촬영한 1인칭(egocentric) 영상을 종합적으로 이해하고 질의응답하는 최초의 벤치마크입니다. 6명이 7일간 공유 주택에서 생활하며 촬영한 총 266시간의 영상을 기반으로, 1,741개의 다중 에이전트 고유 질문을 제공합니다. 현재 최고 성능 모델인 Gemini-2.5-Flash조차 평균 정확도 36.93%에 그쳤고, 함께 제안된 EgoMAS는 학습 없이(training-free) 공유 메모리 + 에이전트별 동적 검색만으로 Gemini-2.5-Flash를 4.48%p 앞섰습니다.
-
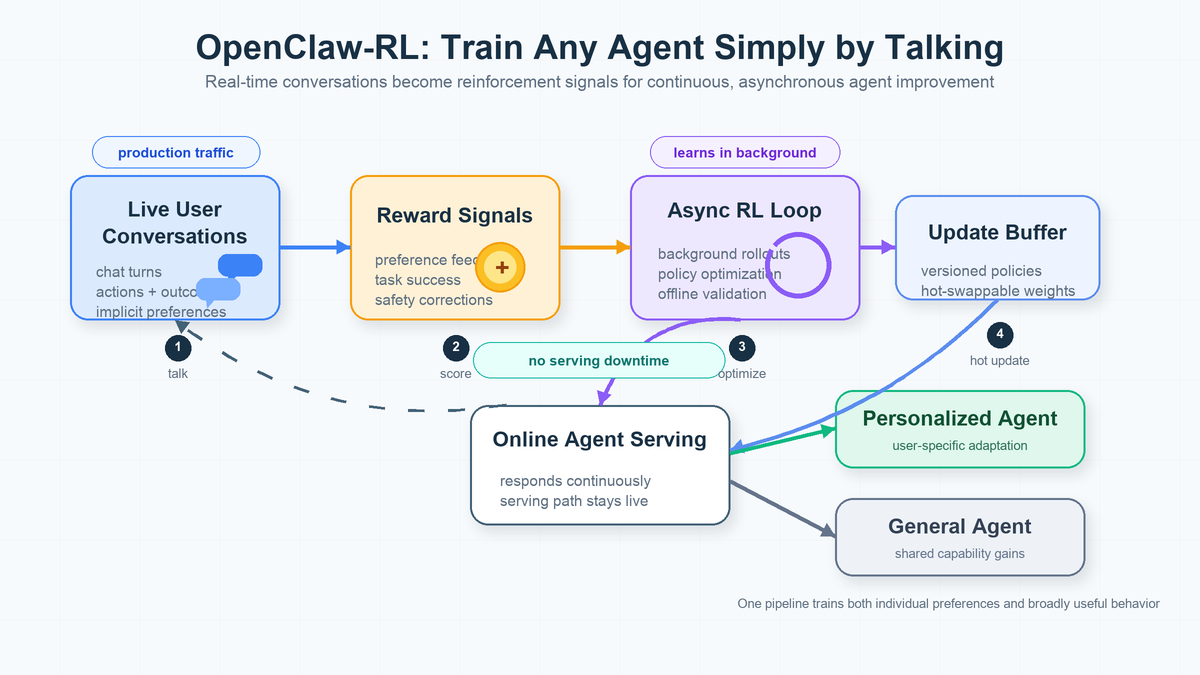
실시간 대화를 강화학습 신호로 전환하는 비동기 RL 프레임워크. 서빙 중단 없이 에이전트를 지속 개선하며, 개인화와 범용 에이전트를 하나의 파이프라인으로 훈련.
-
추론(reasoning)이 수학이나 코딩이 아닌 단순 사실 질문에서도 도움이 되는 이유를 밝힌 논문입니다. 두 가지 메커니즘을 발견했는데, 하나는 추론 토큰이 추가 연산 버퍼로 작용하는 것이고, 다른 하나는 관련 사실을 생성하면서 정답 회상을 촉진하는 factual priming입니다. 다만 중간에 할루시네이션된 사실이 끼면 최종 답도 틀릴 확률이 크게 올라갑니다. Google Research + Technion.
-
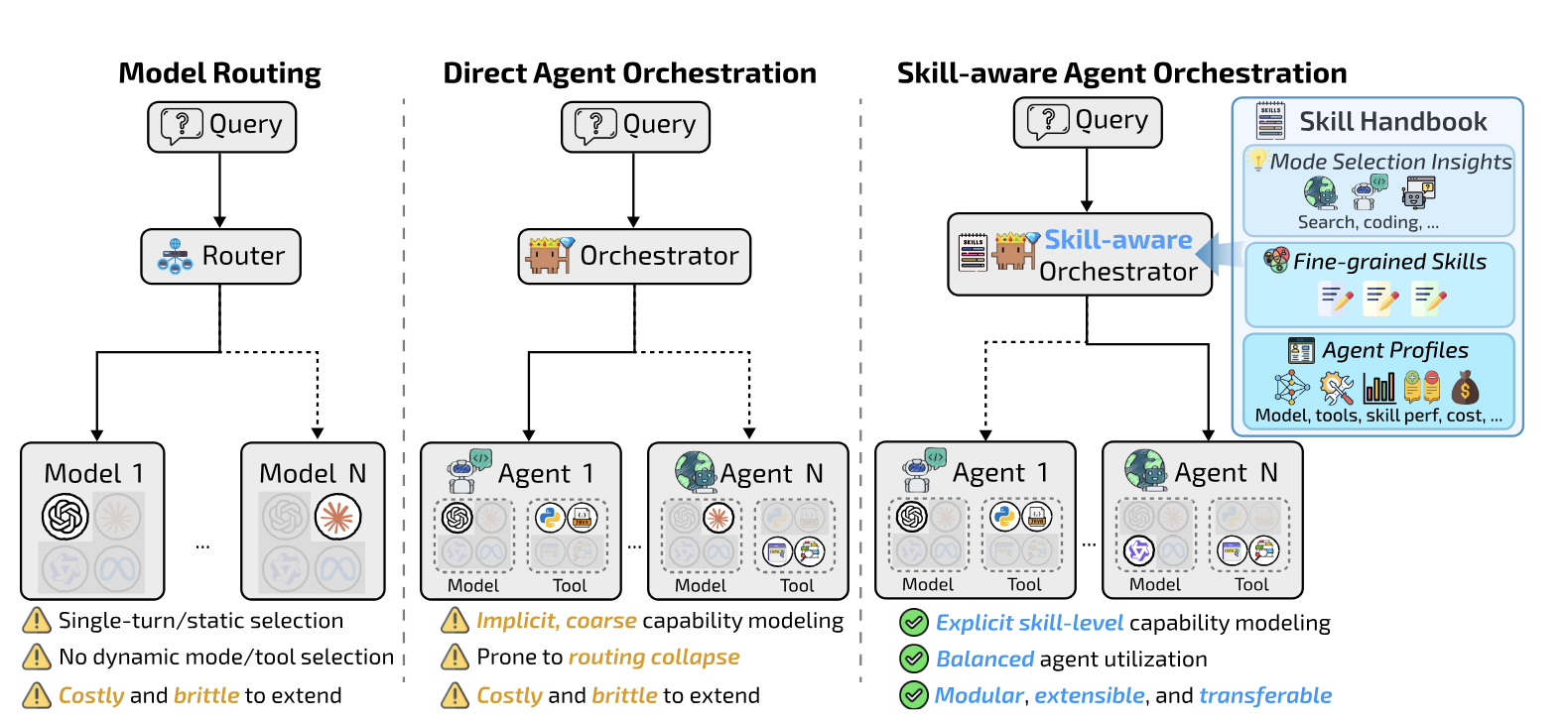
멀티 에이전트 시스템에서 "어느 모델에게 넘길까"를 결정하는 라우팅은 단발성 판단이거나 RL로 학습해도 한 모델에 98% 쏠리는 붕괴를 보입니다. SkillOrchestra는 실행 경험에서 재사용 가능한 "스킬 핸드북"을 학습해 RL 오케스트레이터 대비 22.5%p 정확도 향상과 700배 학습 비용 절감을 달성합니다. 위스콘신-매디슨·Salesforce AI Research 공동 연구.
-

텍스트, 이미지, 영상에서 Lottie 벡터 애니메이션을 생성하는 최초의 멀티모달 프레임워크입니다. Lottie JSON을 파라미터화된 토큰으로 변환하는 토크나이저가 핵심이고, Qwen2.5-VL 기반 4B 모델로 88~93%의 생성 성공률을 달성했습니다. CVPR 2026 accept.
-
Kimi k2.5 - 200만 토큰의 멀티모달 에이전트 2026-02-10
200만 토큰 컨텍스트에 멀티모달 처리, 에이전틱 추론을 갖추고 나온 Kimi의 새로운 논문입니다. 핵심은 강화학습 기반의 2단계 훈련입니다. Agentic RL로 계획-실행-검증 루프를 학습하고, RLVR로 수학/코딩에서 자가 검증 능력을 키웠습니다. 파라미터 수도, 구체적 알고리즘도, 데이터셋 구성도 전부 미공개입니다.
-
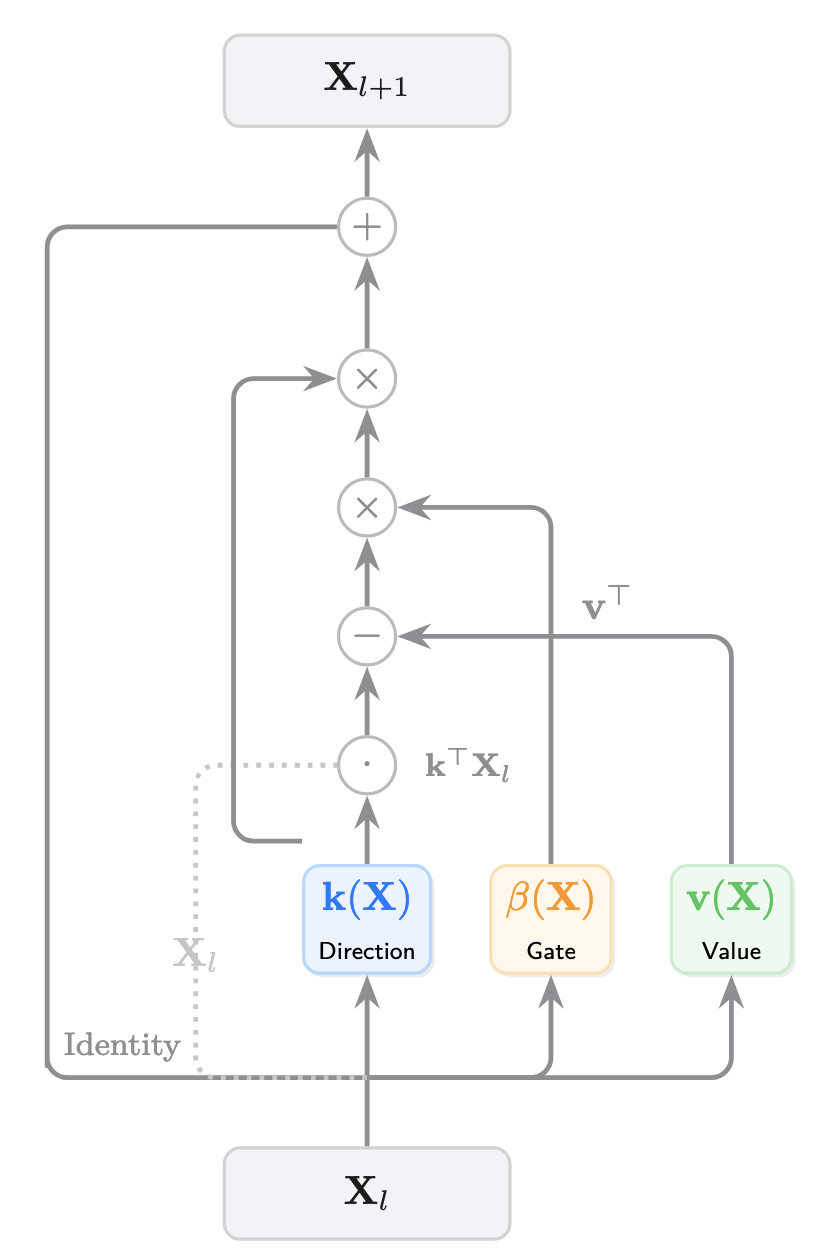 Deep Delta Learning 2026-01-06
Deep Delta Learning 2026-01-06심층 신경망의 학습 안정성을 책임지는 ResNet의 identity shortcut connection은 사실 너무 단순하다는 문제가 있습니다. 입력에 residual을 더하는 방식은 기울기 소실 문제는 해결했지만, 네트워크가 복잡한 상태 전이를 표현하는 데는 한계가 있었죠. 새로운 논문 Deep Delta Learning(DDL)은 이 shortcut 연결에 학습 가능한 기하학적 변환을 추가합니다. 네트워크는 층마다 그냥 넘어갈지, 특정 방향의 정보를 지울지, 완전히 반사시킬지 스스로 결정합니다.
-

벌써 4.5가 나온다구요? 두 달 정도밖에 안 지났습니다. 아직 4.5는 테크니컬 리포트가 없습니다. 대신 4.0 테크니컬 리포트를 가져왔습니다. 2K 해상도 이미지를 1.4~1.8초 만에 생성하며, T2I 생성과 이미지 편집 작업을 단일 모델에서 공동 학습합니다. 특히 복잡한 텍스트 렌더링, 다중 이미지 참조, 인컨텍스트 추론 생성 등 기존 모델들이 취약했던 영역에서 강점을 보입니다.
-
여러 개의 언어 모델을 평균화하는 방식만으로 새로운 모델을 훈련시키지 않고도 성능을 높일 수 있습니다. 단순 평균이 아니라 각 모델의 강점이 나타나는 부분을 찾아 비율을 다르게 섞는 SoCE를 제안합니다. 함수 호출 벤치마크에서 새로운 최고 성능을 달성했습니다.
-
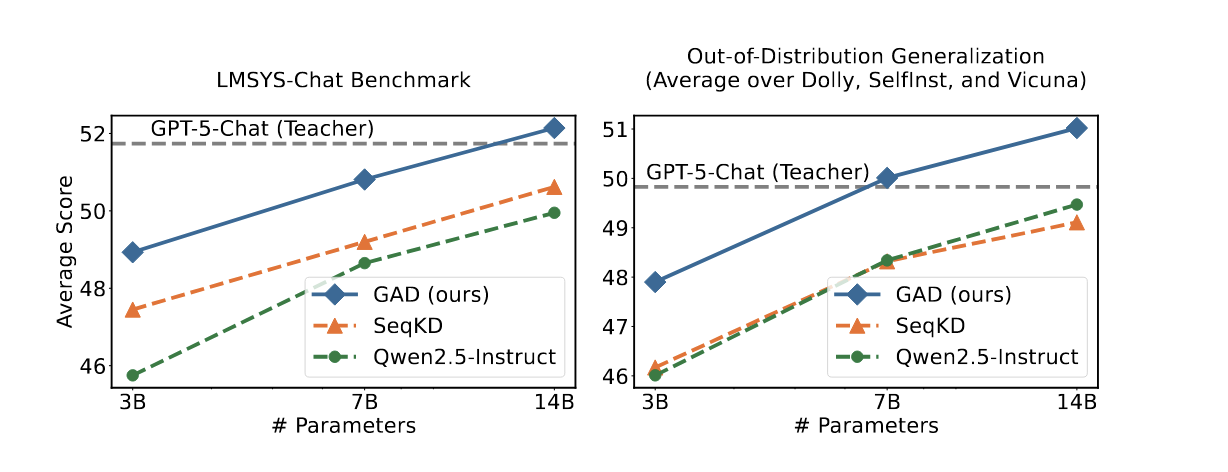
교사 모델의 내부를 전혀 들여다볼 수 없는 상황에서, 어떻게 효과적으로 지식을 전달받을 수 있을까요? Microsoft Research가 제안한 GAD(Generative Adversarial Distillation)는 이 문제에 대한 신선한 해법을 제시합니다.
-

또이트댄스입니다. Depth Anything 3는 한 장의 이미지든 여러 장의 영상이든, 카메라 포즈 정보가 있든 없든 상관없이 3D 기하 정보를 예측하는 모델입니다. 평범한 트랜스포머 하나와 단순한 깊이-광선(depth-ray) 표현으로 이전 최고 성능을 44% 능가하는 성능을 달성했으며, 모든 데이터를 공개 학술 데이터셋으로만 학습했습니다.
-
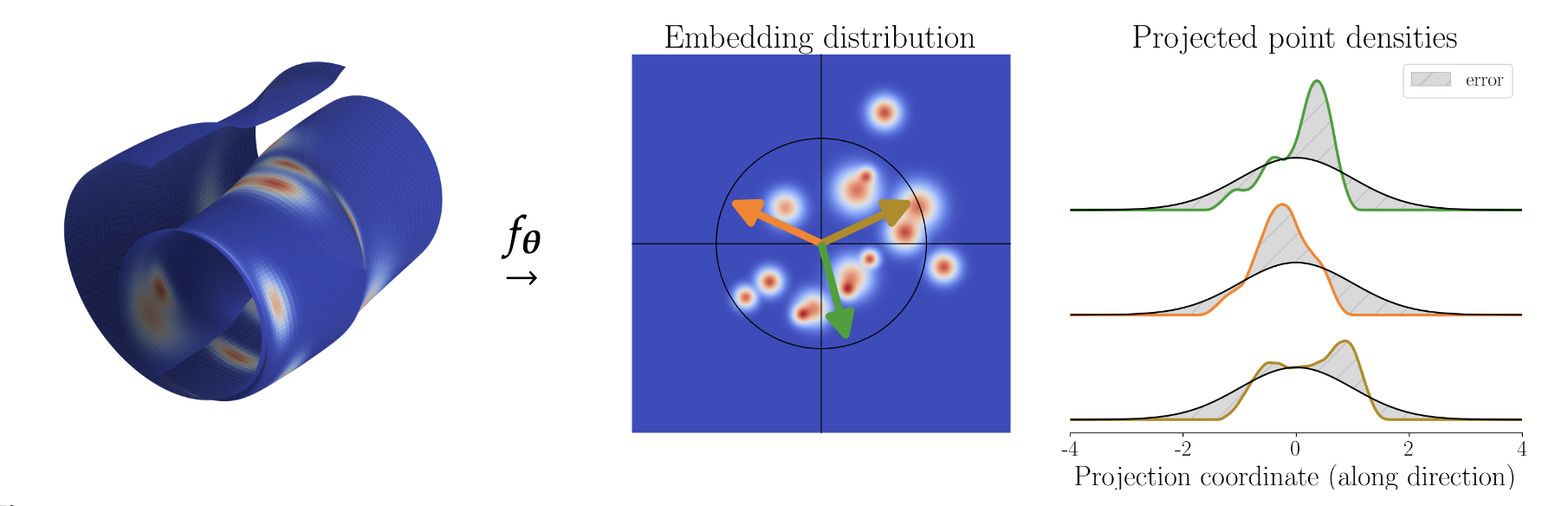
얀 르쿤과 바렐스트리에로의 최신 연구입니다! 자기 지도 학습(Self-Supervised Learning)에서 표현 붕괴(representation collapse)를 막기 위해 쓰던 여러 임시방편(stop-gradient, teacher-student network 등)들을 이론적으로 정당화하고 이를 단 50줄의 코드로 구현한 LeJEPA 논문입니다. 핵심은 '임베딩이 등방성 가우시안 분포를 따라야 한다'는 수학적 증명에 있습니다.
-
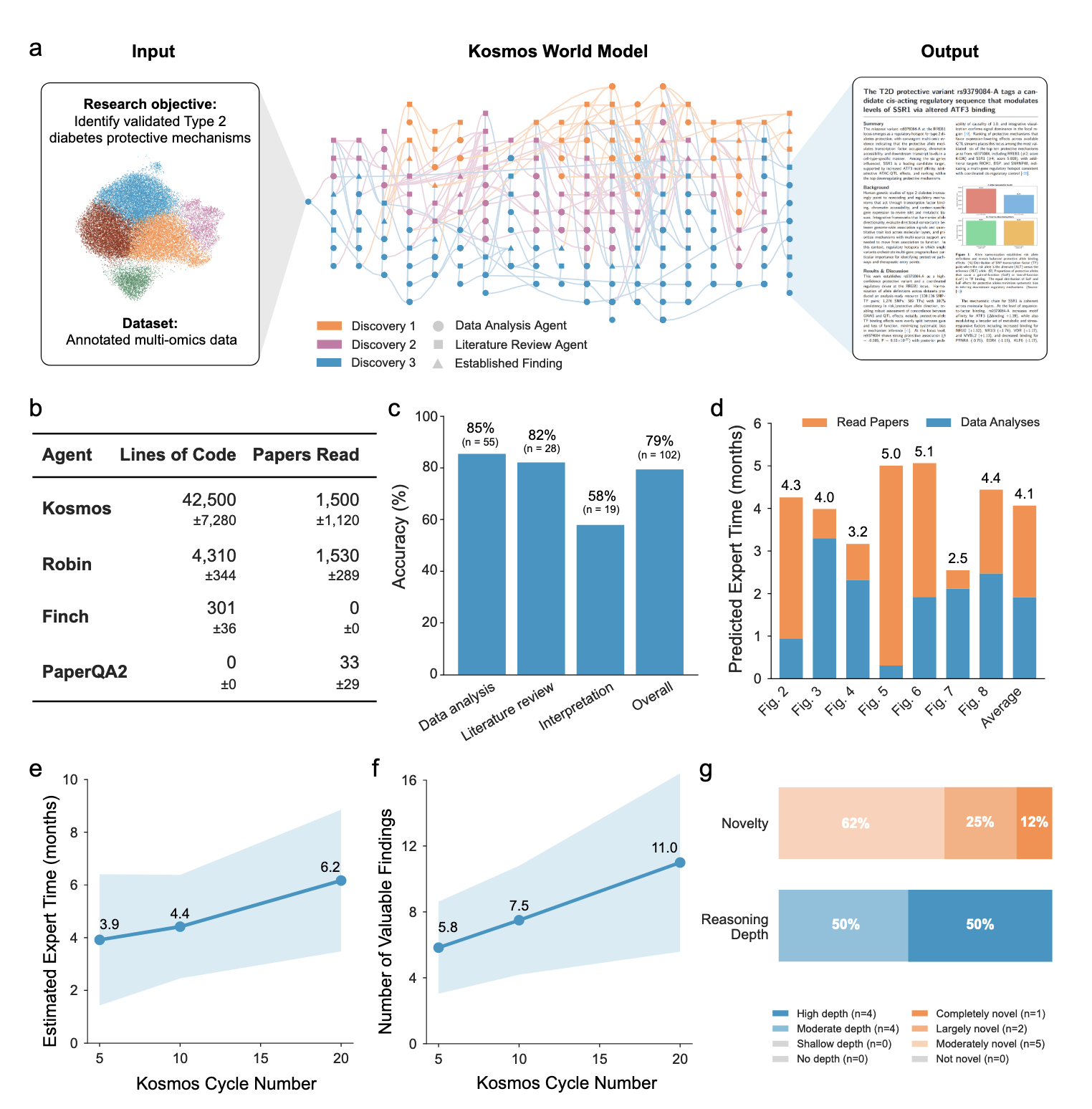
AI 과학자 Kosmos를 소개합니다. 데이터와 연구 목표를 주면 자동으로 논문을 읽고, 데이터를 분석하고, 가설을 생성해 과학 보고서를 작성합니다. 6개월간 인간 연구자가 수행할 작업을 하루에 끝내고 모든 단계가 투명하게 공개됩니다. 신경생물학, 재료과학, 통계유전학등 다양한 분야에서 실제 발견을 만들어냈습니다.
-
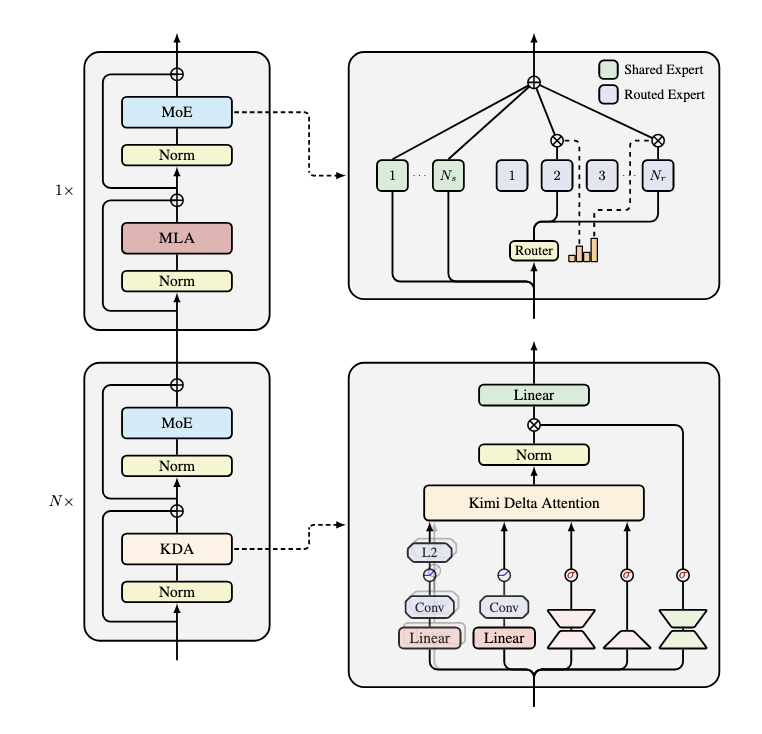
현대 트랜스포머의 약점을 개선한 새 어텐션 구조 Kimi Linear를 소개합니다. 선형 어텐션 기반으로 효율과 성능을 동시에 끌어올린 접근을 다룹니다.
-
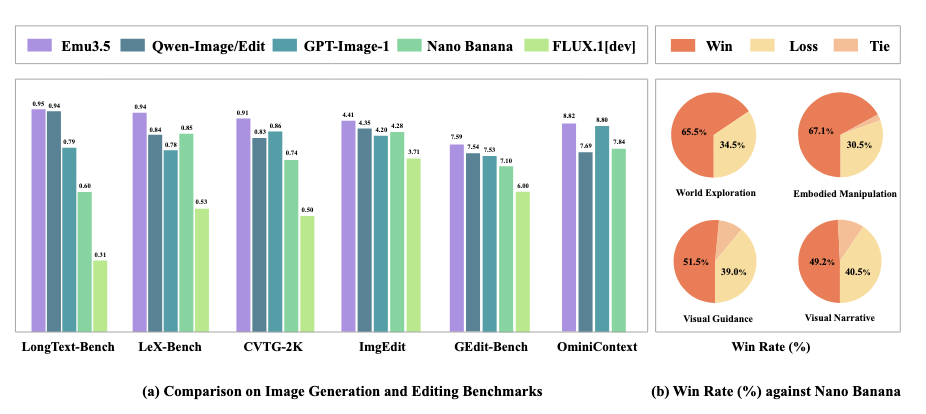
최신 멀티모달 모델의 화두는 세계를 이해하고 행동하는 모델입니다. BAAI(Beijing Academy of Artificial Intelligence)가 최근 공개한 Emu3.5는 이런 흐름을 타고 비전과 언어를 동시에 예측하는 '멀티모달 월드 모델'을 표방하며 장시간 순차적 추론과 실제 로봇 조작까지 가능하게 한다고 주장합니다.
-
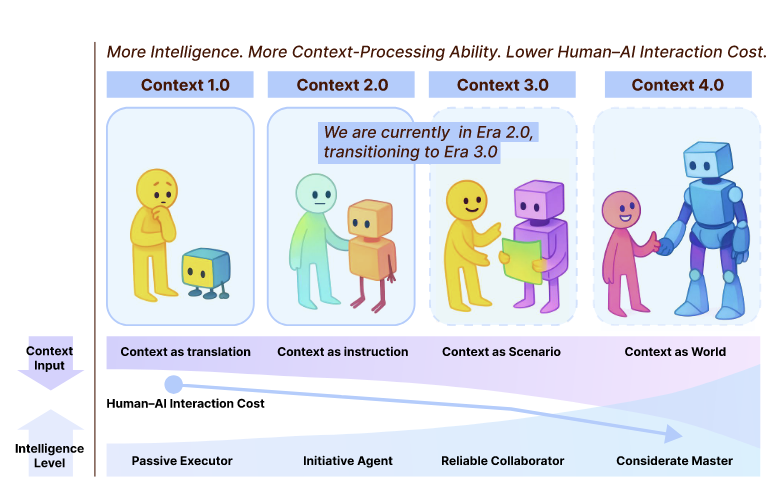
LLM의 일상화로 컨텍스트 엔지니어링이라는 개념이 떠오르고 있습니다. 많은 사람들이 이것을 최신 에이전트 시대의 산물로 생각하곤 하는데, 실은 20년 이상의 역사를 가진 분야입니다. 이 논문의 핵심 통찰은 바로 여기에 있습니다.기계가 인간의 의도를 이해하려면, 결국 정보 엔트로피를 줄여야 한다는 것이죠.
-
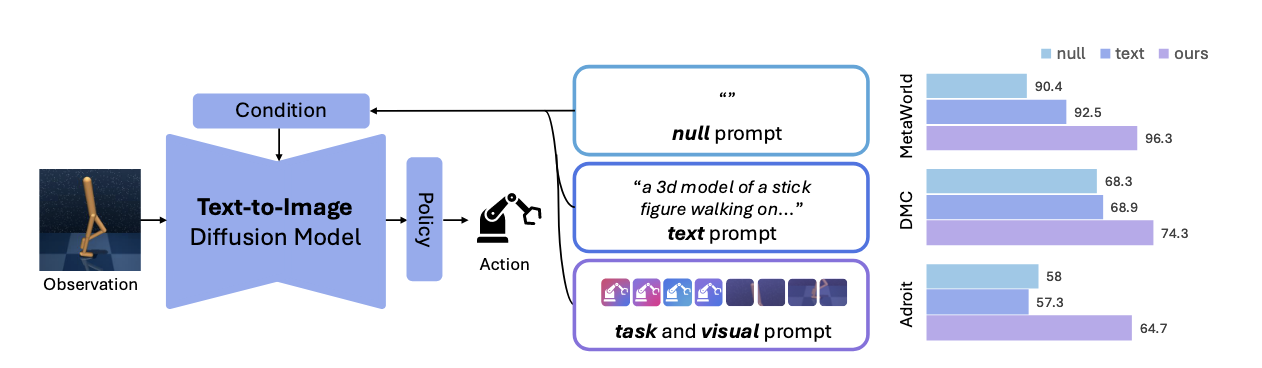
이번에는 네이버에서 제안한 논문을 들고왔습니다. 팔이 또 안으로 굽는다고, 저는 우리나라 논문을 보면 이렇게 가져오고싶네요. 확산 모델의 조건화를 로보틱스 분야에 적용하고 도메인 갭을 메우는 흥미로운 내용입니다.
-
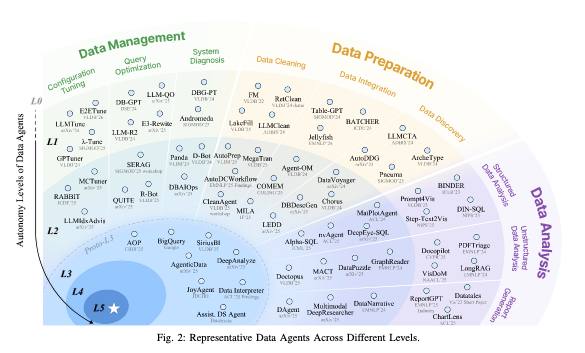
현재 시장에는 "단순 쿼리 응답 도구"부터 "엔드-투-엔드 자동 분석 시스템"까지 모두 "데이터 에이전트"라고 불리고 있습니다. 이 논문은 자동주행 기술의 레벨 분류처럼, 데이터 에이전트의 자율성을 6단계로 명확히 정의합니다.
-
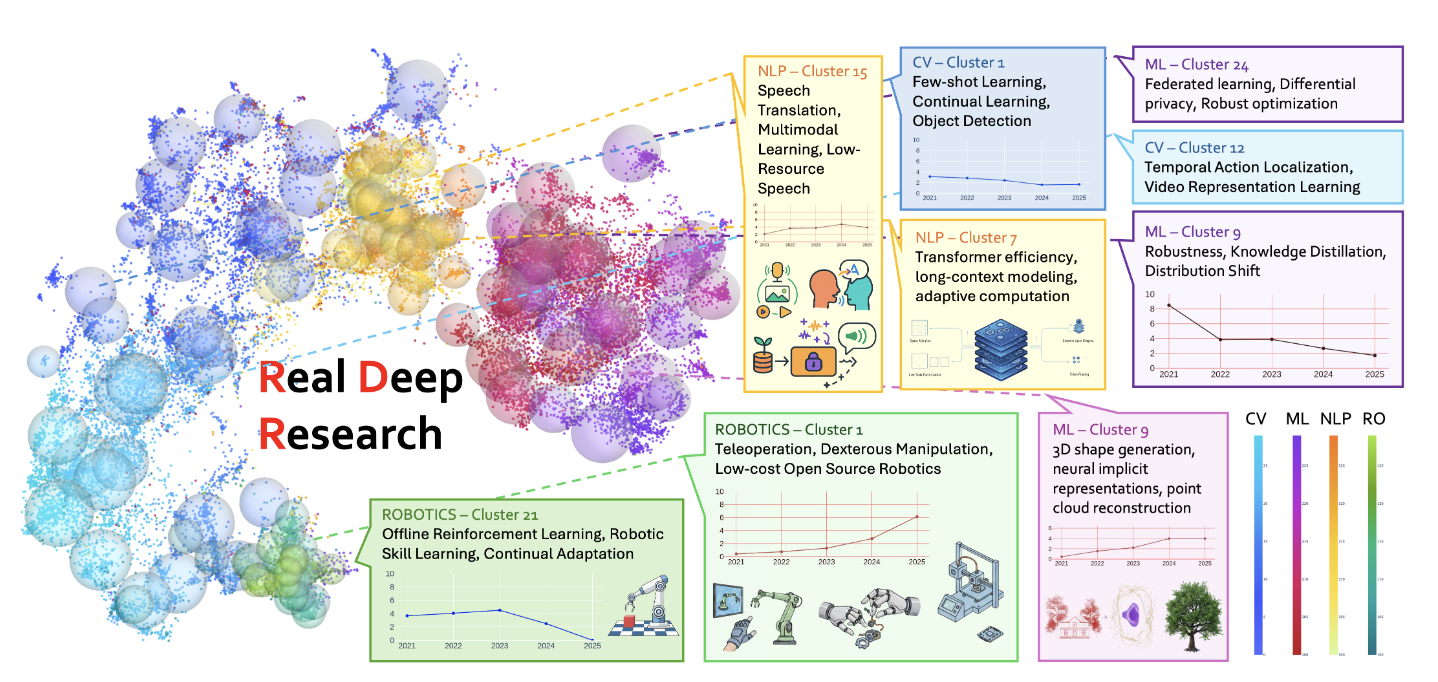
수천 편의 논문을 체계적으로 분석해 연구 트렌드와 분야 간 협력 기회를 찾아내는 파이프라인 RDR을 소개합니다.
-
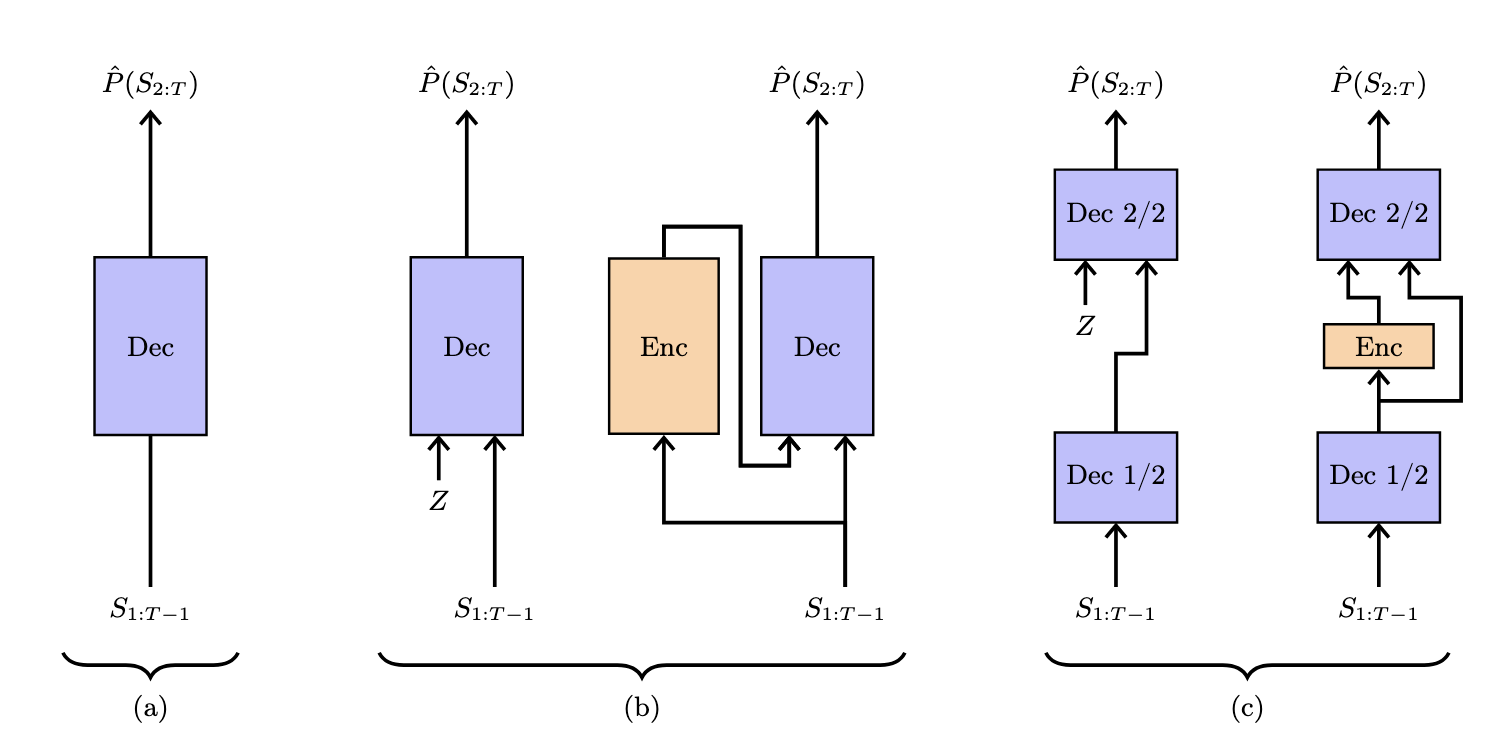 The Free Transformer 2025-10-27
The Free Transformer 2025-10-27디코더 트랜스포머에 잠재 변수를 사용할 자유를 부여하는 접근을 탐구합니다. 하이퍼파라미터 조정 없이 여러 벤치마크에서 성능 향상을 달성합니다.
-
 A Definition of AGI 2025-10-27
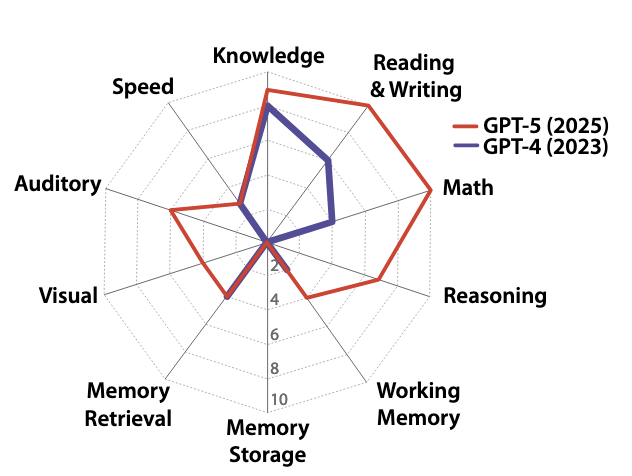
A Definition of AGI 2025-10-27AGI를 정량화하는 체계적 프레임워크를 제시한 논문입니다. 인간 인지능력 모델(CHC 이론)로 측정해 GPT-4는 27%, GPT-5는 57%라는 AGI 점수를 내놓습니다.
-
 FineVision Open Data Is All You Need 2025-10-25
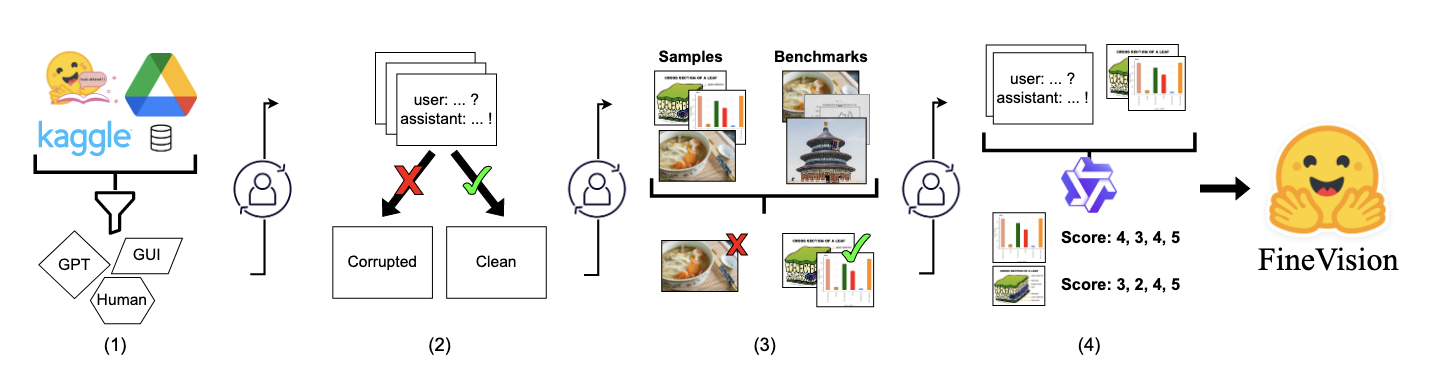
FineVision Open Data Is All You Need 2025-10-25인공지능 연구에서 가장 중요한 것은 데이터! 두 말하면 입아픈 이야기입니다. 최대 규모의 AI 플랫폼, 이제는 연구 커뮤니티의 역할을 톡톡히 하는 허깅페이스에서 최대 규모의 오픈 데이터 리소스를 발표했습니다. 오염이 심한 공개 데이터셋에서 세심하게 큐레이션해 2,400만 샘플 데이터셋을 통합하여 품질을 끌어올렸습니다. 기존 오픈 데이터셋 대비최대 46%의 벤치마크 성능 향상을 보입니다.
-
 DeepSeek-OCR Contexts Optical Compression 2025-10-24
DeepSeek-OCR Contexts Optical Compression 2025-10-24긴 텍스트를 이미지로 변환해 LLM 컨텍스트를 압축하는 DeepSeek-OCR을 소개합니다. 10배 압축에서 97% 정확도를 유지하며, 광학적 컨텍스트 압축이라는 새 발상을 제시합니다.
-
 Detect Anything via Next Point Prediction 2025-10-22
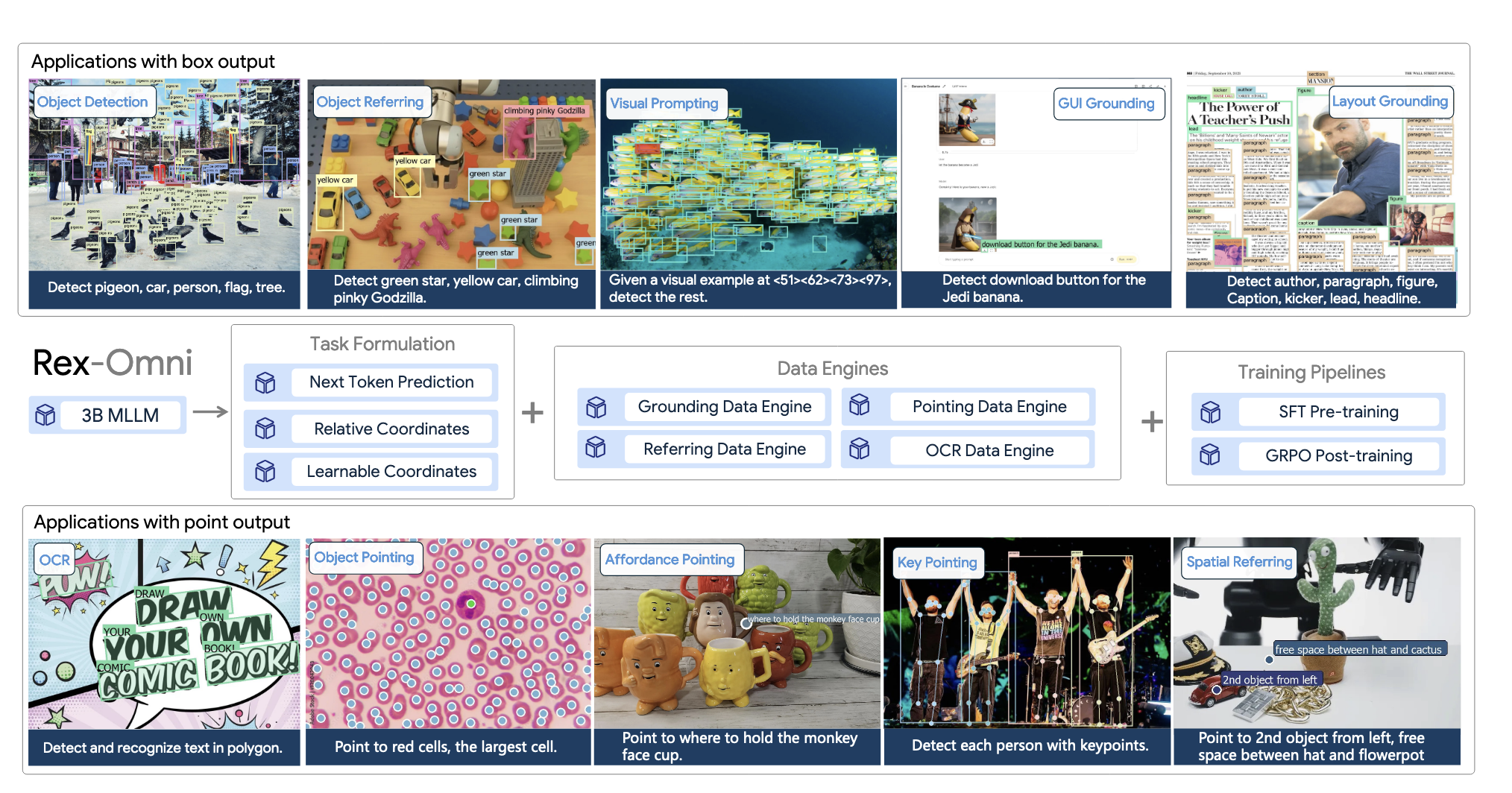
Detect Anything via Next Point Prediction 2025-10-22멀티모달 LLM으로 객체 탐지에 도전한 모델입니다. Qwen과 대규모 영상 데이터로 학습해 각종 탐지 벤치마크에서 높은 성능을 보입니다.
-
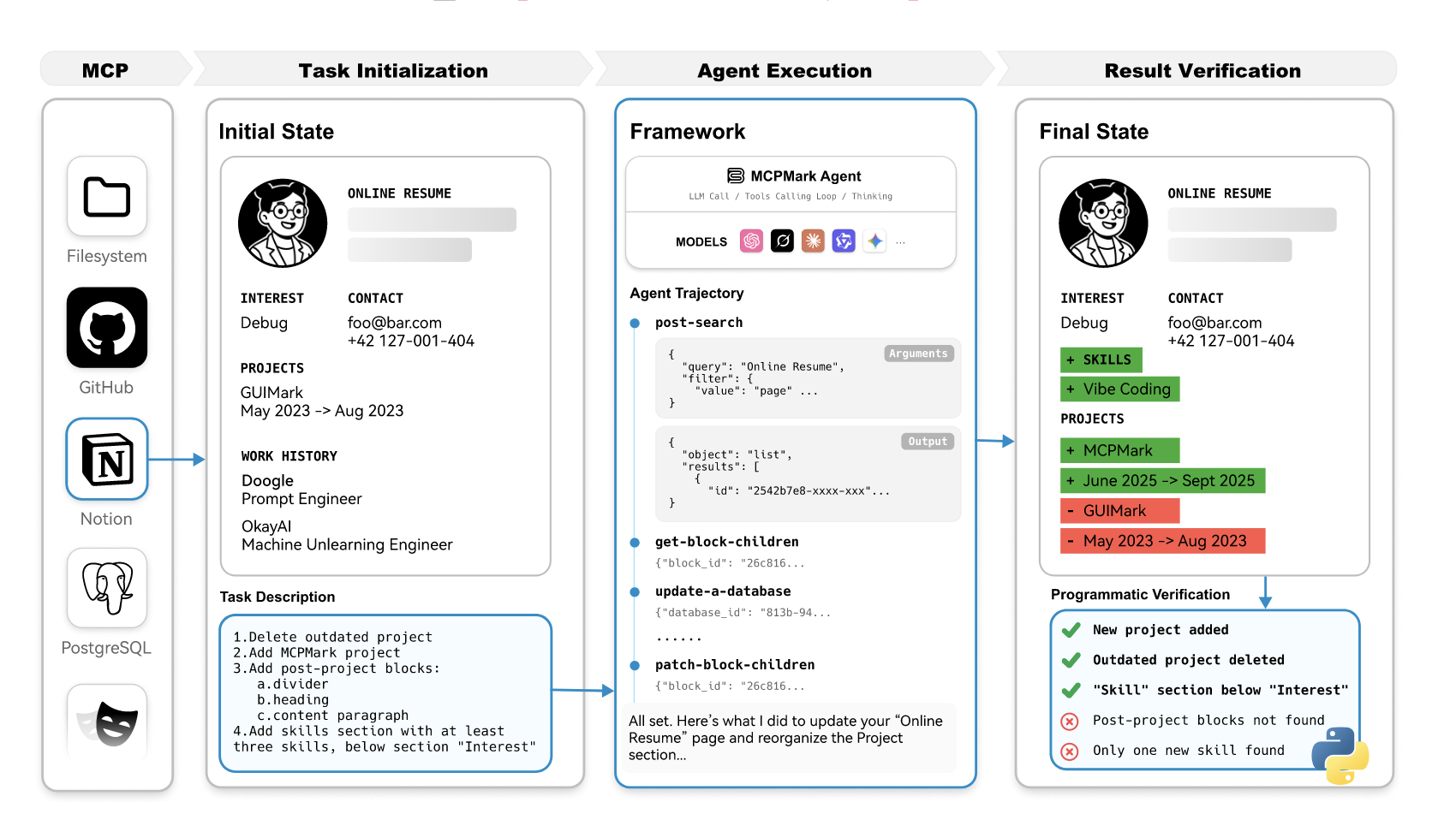
여러분은 MCP를 자주 활용하나요? 저는 매일 사용해서 없으면 안 될 수준입니다. 가끔은 내가 필요한 MCP를 직접 만들고 싶은 때도 있죠. 그렇다면 실제로 MCP가 얼마나 유용한지, 어떤 MCP 서버가 좋은 MCP 서버인지 구별하려면 어떤 기준을 세우면 좋을까요? 이번 논문은 MCP가 실제 업무의 복잡성을 평가하는 벤치마크를 제안하고 MCP 활용 능력을 종합적으로 평가합니다.
-

Dragon Hatchling(BDH)은 트랜스포머와 뇌 모델 사이의 연결고리를 찾습니다. 생물학적으로 그럴듯한 그래프 기반 뉴런 네트워크로 설계되어, 헤비안 학습과 스파이킹 뉴런을 사용하면서도 GPT-2 수준의 성능을 달성했습니다. 핵심은 attention을 시냅스 가소성으로, feed-forward를 국소적 그래프 동역학으로 재해석한 것입니다.
-
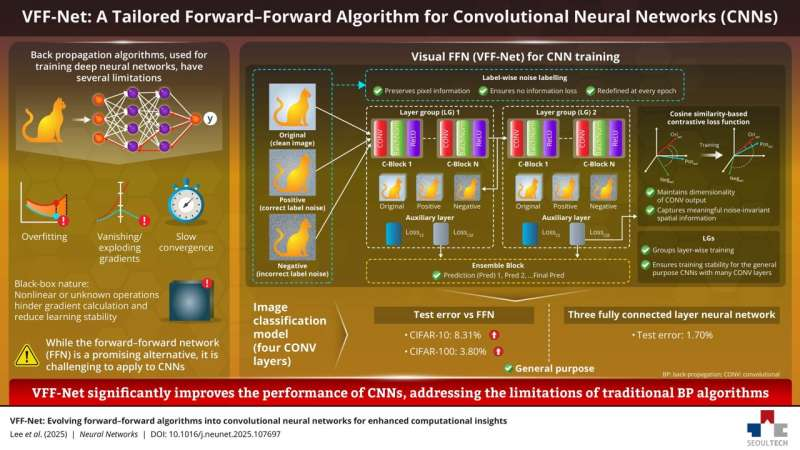
서울과학기술대학의 VFF-Net을 소개합니다. 딥러닝은 역전파라는 방식으로 학습하는 것이 기본입니다. 역전파 알고리즘을 제안한 제프리 힌턴은 딥러닝 대부로 불리며 모든 현대 AI의 기초를 마련한 인물입니다. 제프리 힌턴은 역전파가 아닌 새로운 학습 알고리즘을 2022년에 발표했습니다. 이것이 FFN인데요, 실제 학습에 적용하기에는 복잡한 네트워크에 잘 맞지 않고, 특히 CNN과 어울리지 않았습니다. 이 문제를 한국에서 해결합니다. 방대한 계산량이 필요한 역전파 대신 FFN의 성능을 끌어올려 실제로 사용할 수 있는 알고리즘으로 만든 것입니다.
-
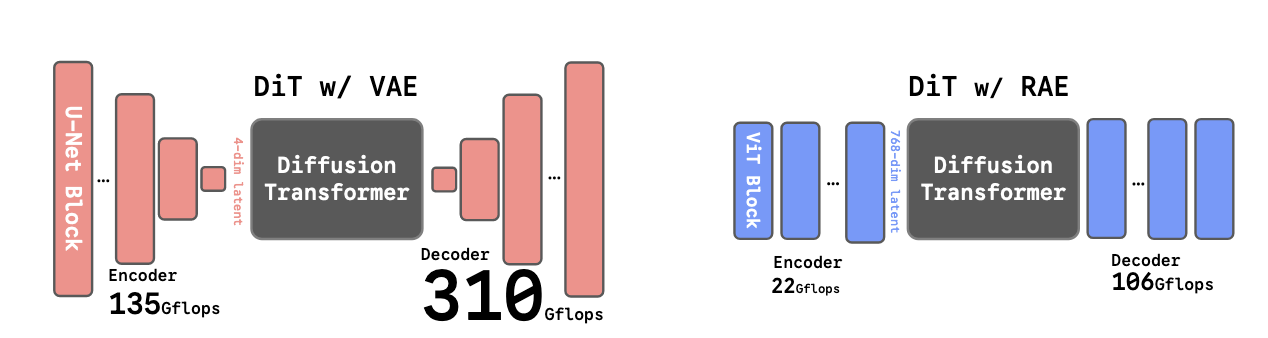
최근 이미지 생성 분야에서 Diffusion Transformer(DiT)는 픽셀 공간이 아닌 사전 학습된 오토인코더가 만든 잠재 공간(latent space)에서 확산 과정을 수행하는 것이 표준이 되었습니다. 하지만 대부분의 DiT는 여전히 원래의 VAE 인코더에 의존하고 있고, 이는 몇 가지 한계를 가지고 있습니다. 이 논문은 VAE를 사전 학습된 표현 인코더(DINO, SigLIP, MAE 등)와 학습된 디코더로 구성된 Representation Autoencoder(RAE)로 대체하는 새로운 접근을 제안합니다.
-
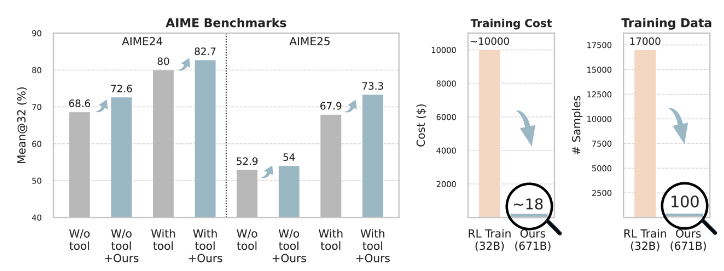
LLM의 성능 향상을 위해 강화 학습을 흔히 사용하죠. 강화 학습 훈련을 위해서는 높은 학습 비용이 필요합니다. 이 논문은 훈련 없이 프롬프트만으로 훈련 없이 강화 학습 정책을 변경합니다.
-

우리에게 익숙한 많은 언어 모델은 영어 중심입니다. 저처럼 글을 많이 쓰는 분이라면 언어 모델의 한국어 처리 결과를 그대로 어디에 내놓을 수 없다는 아쉬움을 공감하시리라 생각합니다. 다국어 추론 모델의 한국어 성능을 높이려면 어떻게 해야 할까요? 한글날을 맞아 우리의 멋진 연구자들이 새로이 발표한 한국어 추론 모델과 데이터셋을 소개합니다.
-
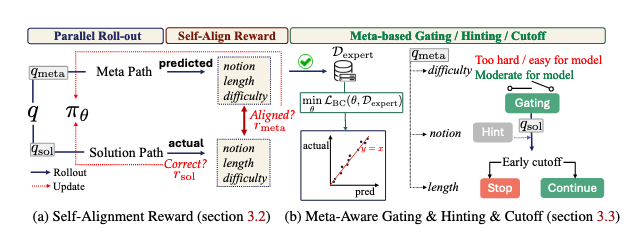
대한민국 KAIST에서 제안하는 추론 모델의 메타 인지(meta-awareness) 능력 향상 방법입니다. 이 논문은 모델이 예측한 메타 정보와 실제 추론 과정 사이의 정렬(alignment)을 통해 메타 인지 능력을 향상시키는 MASA(Meta-Awareness via Self-Alignment) 프레임워크를 제안합니다. Qwen3를 기반으로 외부 소스 없이 메타 인지를 학습합니다.
-
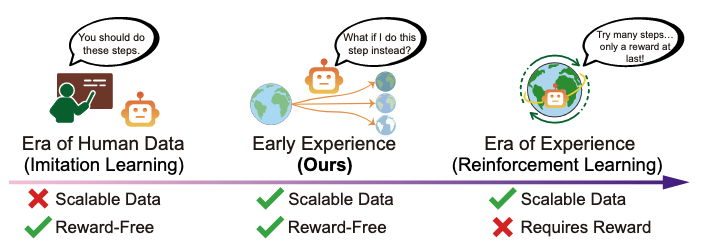 Agent Learning via Early Experience 2025-10-12
Agent Learning via Early Experience 2025-10-12스스로 학습하고 발전하는 인공지능을 위한 새로운 학습 패러다임, 초기 경험(Early Experience)을 제안합니다. 보상 신호 없이도 에이전트가 자신의 행동으로 생성된 미래 상태를 학습 신호로 활용할 수 있습니다. 이제 인공지능이 정답만 보고 배우는 게 아니라 직접 시도한 경험으로 학습한다는 겁니다.
-
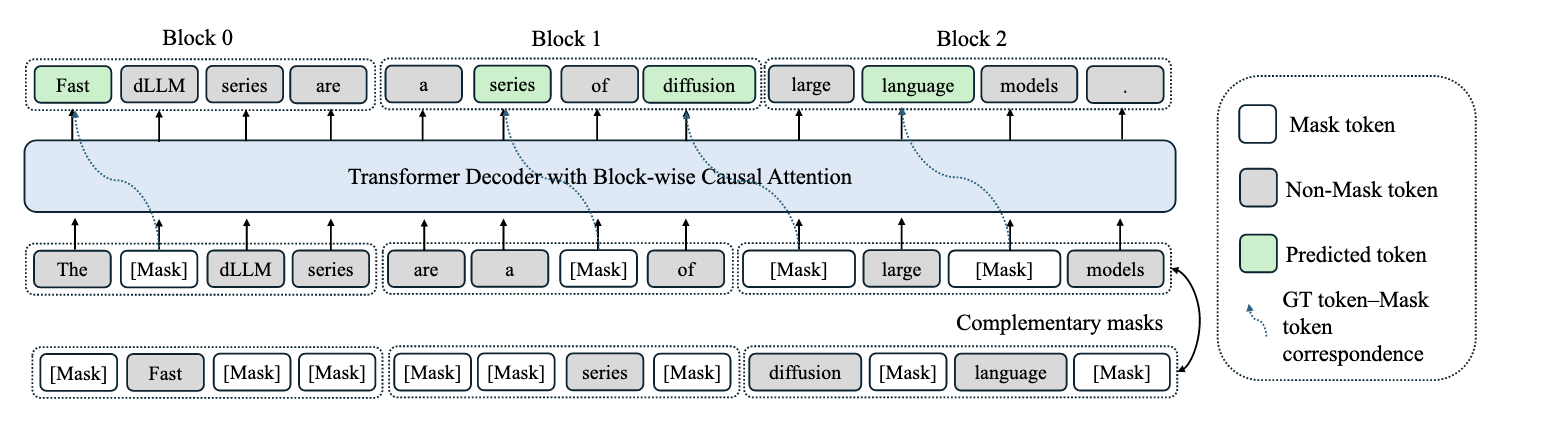 FAST-DLLM V2 Efficient Block-Diffusion LLM 2025-10-09
FAST-DLLM V2 Efficient Block-Diffusion LLM 2025-10-09NVIDIA의 힘은 GPU가 다가 아니죠. 명실상부 LLM 선두주자의 새로운 논문입니다. 자연어 처리 모델이 토큰을 생성하는 기본적인 방법인 자기회귀(AR)의 한계를 극복하는 병렬 텍스트 생성 모델입니다. 적은 토큰으로도 파인 튜닝이 가능하고 500배 적은 학습 데이터로 기존 Dream 모델과 동일한 성능을 달성합니다.
-
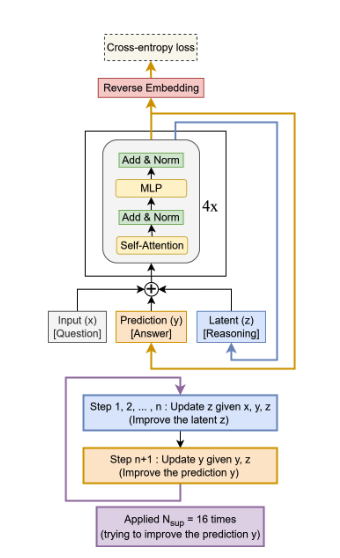
삼성에서 한 건 했습니다. LLM 추론 방식에 대한 근본적인 의문을 제시하고 Claude 3.7, GPT의 o3-mini, Gemini 2.5 Pro, Deepseek R1을 능가하는 추론 성능을 달성합니다. 심지어 0.01%에 불과한 파라미터로 말이죠. 삼성 SAIL AI 연구소가 제안한 TRM을 소개합니다.
-
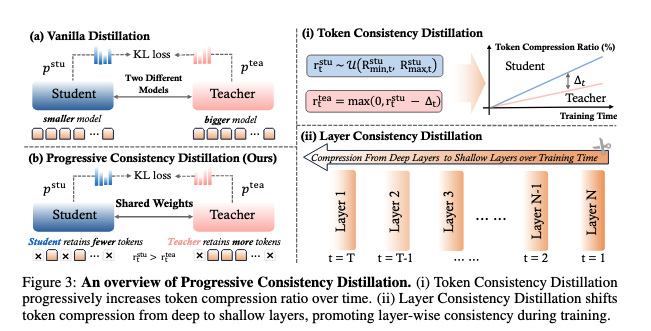
더 효율적인 멀티모달 LLM을 위한 다양한 시도가 이어집니다. 이미지와 텍스트를 동시에 다루는 모델은 이미지 처리에서 계산 비용이 많이 들어갑니다. 이 문제를 해결하기 위해 시각 토큰을 압축하는 방법이 중요합니다. 효율적인 시각 토큰 압축을 위한 학습 프레임워크를 제안한 논문을 소개합니다.
-
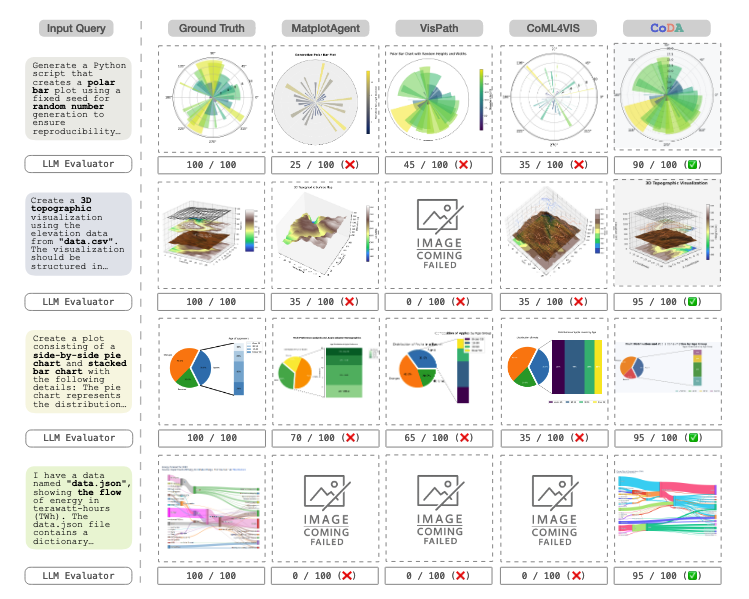
저는 예전부터 데이터 시각화가 어려웠습니다. 함수 이름이랑 파라미터도 잘 안 외워지고 어떤 그래프가 가장 효과적인가 판단하는 것이 쉽지 않습니다. 구글에서 시각화 시스템을 제안한 논문을 발표한 것은 굉장히 재밌습니다. 아마 Opal과 관련이 있지 않을까요?
-
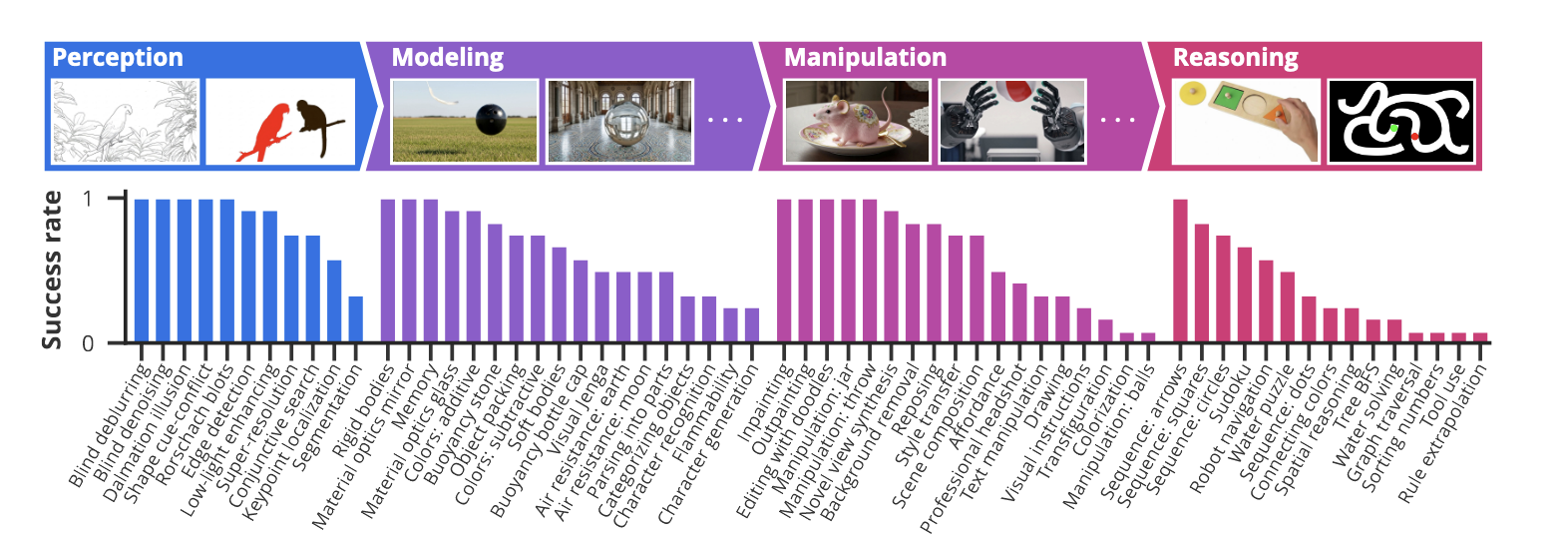
자연어 처리가 변화한 이유가 대규모 언어 모델이라면 컴퓨터 비전이 변화한 이유는 비디오 모델입니다. 믿고 보는 Google DeepMind의 최신 비디오 모델 연구 논문입니다. Veo 3가 명시적으로 학습하지 않은 다양한 시각적 작업을 제로샷 방식으로 해결할 수 있다고 제안합니다.
-
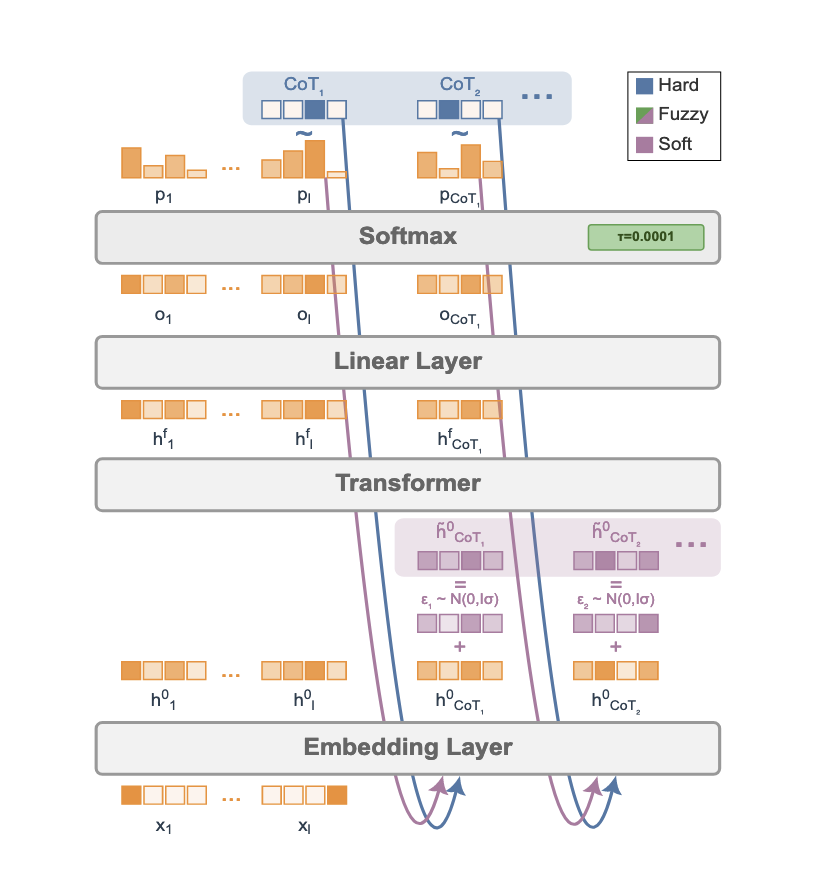 Soft Tokens, Hard Truths 2025-09-23
Soft Tokens, Hard Truths 2025-09-23대형 언어 모델(LLM)의 추론 능력은 Chain-of-Thought(CoT) 기법을 통해 크게 향상되었지만, 기존의 discrete token 기반 접근법은 여러 추론 경로를 동시에 탐색하는 데 한계가 있습니다. 이러한 한계를 극복하기 위해 continuous token을 사용한 새로운 강화학습 기반 훈련 방법을 제안합니다.
-
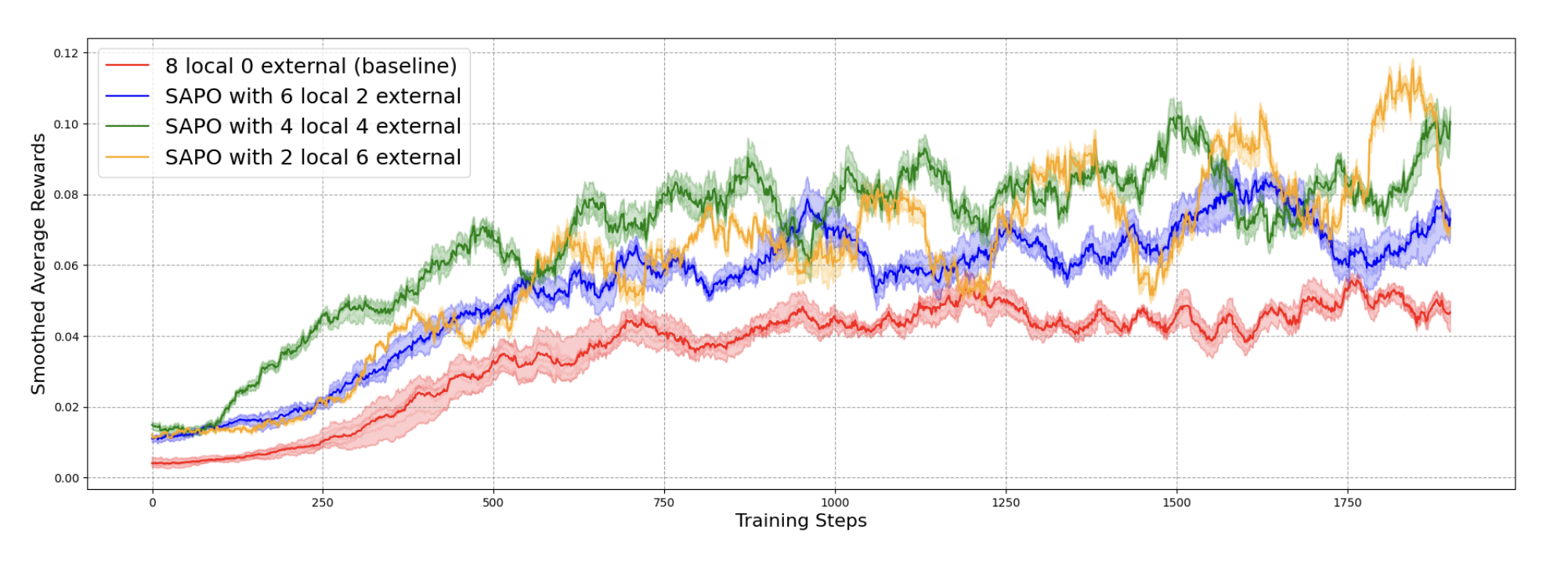
Gensyn AI의 SAPO 논문을 요약합니다. 분산된 노드들이 각자 생성한 경험을 공유하며 언어모델을 집단적으로 훈련하는 비동기 강화학습 후훈련 알고리즘을 설명합니다. 중앙 서버 없이 효율적인 협력 훈련이 가능한 원리와 그 효과를 다룹니다.
-
 Why Language Models Hallucinate 2025-09-17
Why Language Models Hallucinate 2025-09-17언어 모델의 환각(Hallucination) 현상을 통계적 관점에서 분석한 논문을 요약합니다. 환각이 사전훈련의 필연적 결과이며, '모르겠다'를 처벌하는 현재의 평가 방식 때문에 사후훈련 후에도 지속되는 구조적 문제를 지적하고 해결책을 제시합니다.
-

텐센트의 Hunyuan3D Studio 논문을 요약합니다. 단일 이미지나 텍스트에서 게임 엔진에 바로 사용할 수 있는 3D 에셋을 생성하는 7단계 AI 파이프라인을 설명합니다. 지오메트리 생성, UV 언래핑, 텍스처링, 애니메이션까지 전 과정을 자동화한 기술을 다룹니다.
-
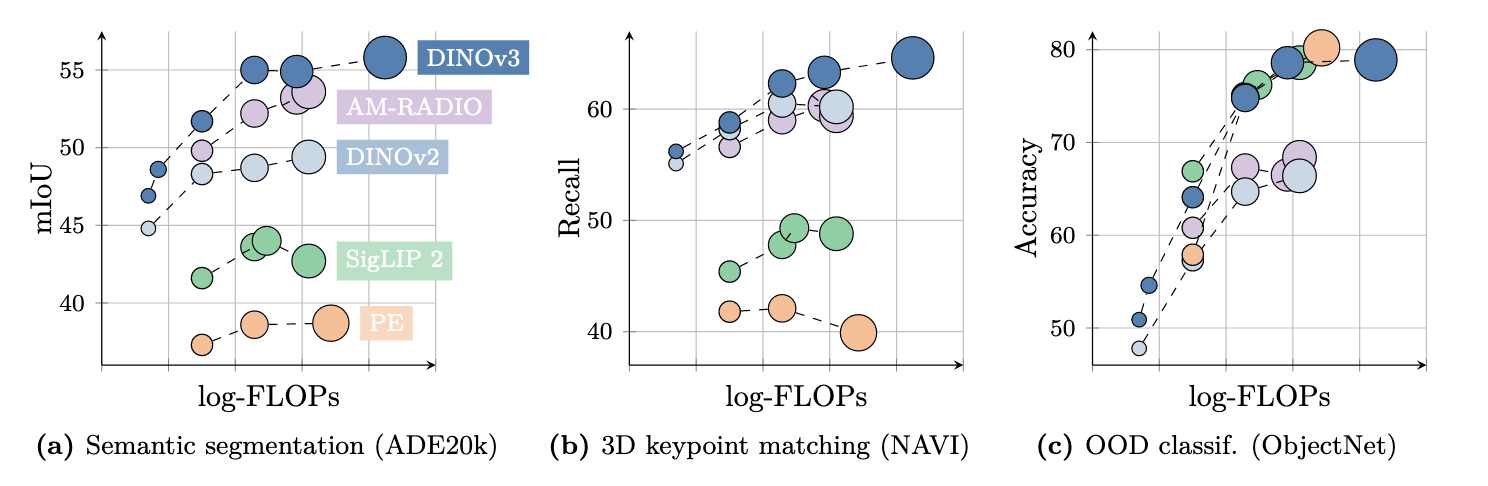 DINOv3 2025-09-15
DINOv3 2025-09-15Meta AI의 70억 파라미터 자기지도학습 모델 DINOv3 논문을 요약합니다. 라벨 없이 이미지 특징을 학습하는 이 모델의 거대한 아키텍처, 데이터 큐레이션 전략, 그리고 패치 일관성을 유지하는 혁신 기술 'Gram Anchoring'을 중심으로 설명합니다.
-
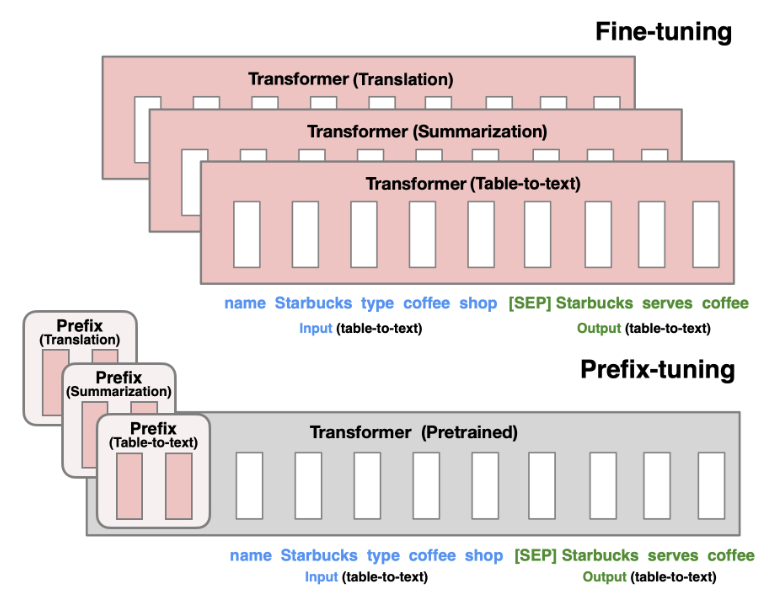
Prefix-Tuning 논문을 요약하며, 대형 언어모델의 파라미터를 고정한 채 작은 연속적 프롬프트(prefix)만 최적화하는 효율적인 튜닝 방법을 설명합니다. 전체 파인튜닝 대비 적은 파라미터로 경쟁력 있는 성능을 내는 원리와 장점을 다룹니다.
-
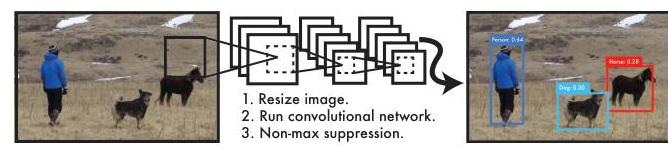
실시간 객체 탐지의 시대를 연 YOLO(You Only Look Once) 논문을 요약합니다. 전체 이미지를 단일 신경망에 한 번만 통과시켜 객체의 경계 상자와 클래스를 동시에 예측하는 혁신적인 통합 아키텍처의 원리와 성능을 설명합니다.
-
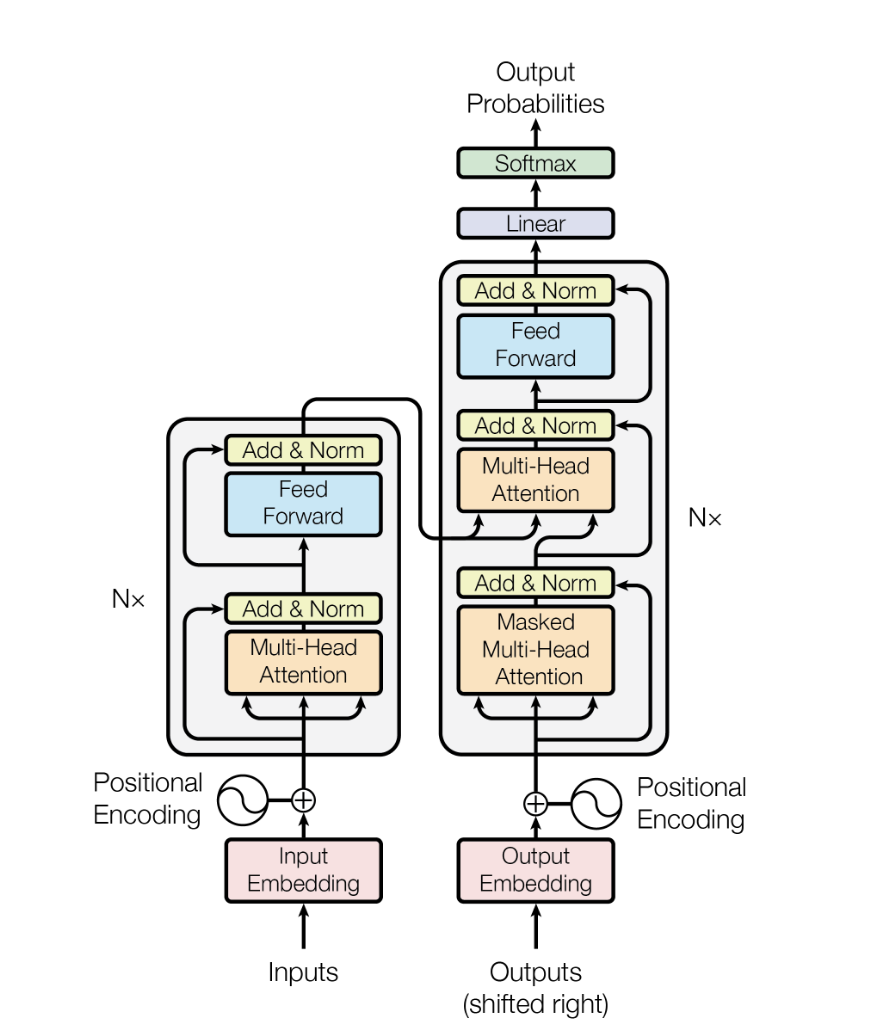 Attention Is All You Need 2025-09-01
Attention Is All You Need 2025-09-01'Attention Is All You Need'는 RNN을 버리고 셀프 어텐션만으로 시퀀스를 처리하는 Transformer 아키텍처를 제안한 2017년 논문입니다. 기계 번역에서 당시 SOTA를 경신했고, 이후 BERT·GPT·Claude를 포함한 거의 모든 대형 언어 모델의 기반이 되었습니다.
-
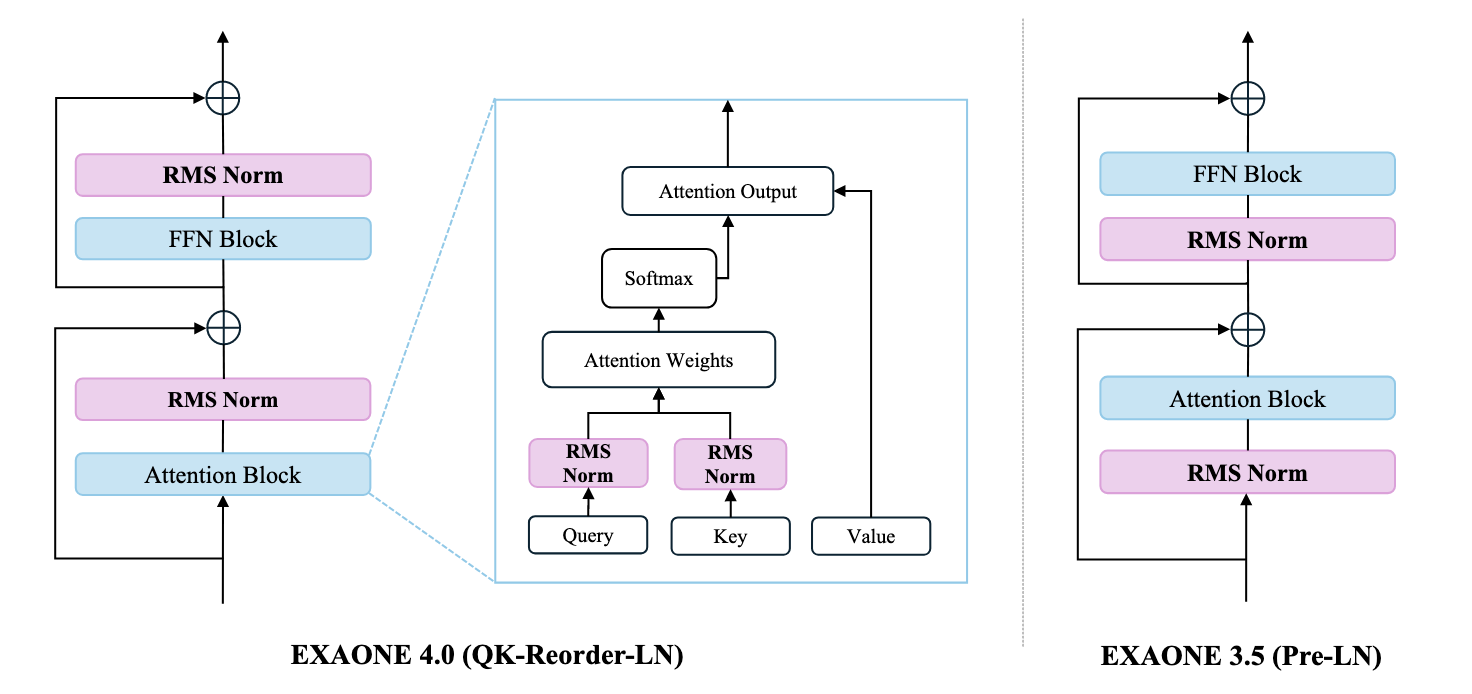
LG AI Research의 EXAONE 4.0 논문을 요약합니다. 빠른 응답의 'Non-reasoning' 모드와 깊은 사고의 'Reasoning' 모드를 통합한 하이브리드 아키텍처가 특징입니다. 모델 구조, 훈련 데이터, 혁신적인 AGAPO 강화학습 알고리즘을 중심으로 설명합니다.
-
 군중 상황에서 정확한 다중 사람의 자세 인식을 위한 군중 자세 주석 데이터 세트 2025-04-05
군중 상황에서 정확한 다중 사람의 자세 인식을 위한 군중 자세 주석 데이터 세트 2025-04-05군중 상황에서의 객체 탐지와 포즈 추정의 어려움을 다룹니다. CrowdPose 데이터셋과 Crowd Index를 분석하고, 객체 수까지 고려한 새로운 데이터셋 'HuPoAnt'와 전용 라벨링 도구를 개발한 경험과 추후 연구 방향을 공유합니다.