A Survey of Data Agents Emerging Paradigm or Overstated Hype
Zhu et al., arXiv preprint arXiv:2510.23587, 2025
데이터 분석이 점점 더 복잡해지고 있습니다. 기업들은 거대한 데이터 레이크에서 인사이트를 찾아야 하는데, 이를 위해서는 데이터 관리, 정제, 분석이라는 세 단계를 모두 거쳐야 합니다. 각 단계마다 전문가의 손길이 필요하고, 시간이 오래 걸리고, 실수하기 쉽습니다.
최근 LLM의 발전으로 "데이터 에이전트"라는 새로운 시스템이 등장했습니다. 마치 자동주행자동차처럼 데이터 작업을 자동화할 수 있을 것처럼 보이기도, 또는 과장된 기대일 수도 있습니다. 이 논문은 단순히 "데이터 에이전트가 뭐지?"를 넘어 "데이터 에이전트가 정말 자율적일 수 있나?"라는 근본적인 질문을 던집니다.
요약
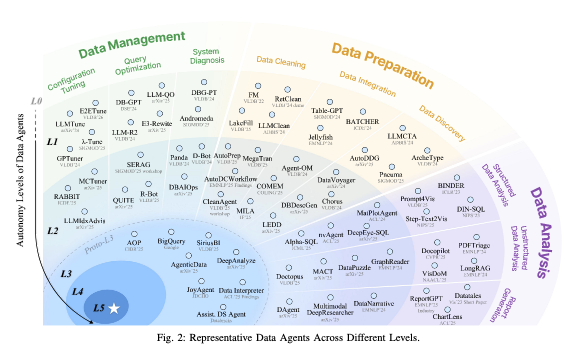
이 연구는 데이터 에이전트의 자율성을 L0(수동 작업)부터 L5(완전 자율 생성)까지 6단계 계층으로 분류합니다. SAE J3016 자동주행 표준에서 영감을 받았습니다.
기술 스펙:
- 모델: LLM을 확률분포로 모델링한 일반 분석 프레임워크
- 범위: 200개 이상의 시스템을 데이터 관리, 데이터 준비, 데이터 분석 세 생명주기 단계로 검토
- 평가 대상: 구성 튜닝, 쿼리 최적화, 데이터 정제, 시각화, 보고서 생성 등
- 핵심 초점: 현재 진행 중인 L2→L3 전환 (절차 실행에서 자율 조율로의 전환)
논문 상세
1. 서론: 용어 모호성 문제
문제는 "데이터 에이전트"라는 단어가 너무 자유롭게 쓰인다는 것입니다.
Google의 BigQuery는 "쿼리 최적화를 도와주는" L2 시스템입니다. 반면 JoyAgent(바이트댄스)는 사용자의 고수준 요청("올해 분기별 매출 추이 분석")을 받으면 스스로 어떤 데이터를 모아서, 어떻게 정제하고, 어떻게 분석할지 전체 파이프라인을 설계하려고 합니다. 이것이 L3 시스템입니다.
이 혼란은 실제 문제를 만듭니다:
- 사용자 입장: "데이터 에이전트를 쓰면 자동으로 다 해줄 줄 알았는데 안 됨"
- 책임 입장: 에이전트가 잘못된 분석을 제공했을 때, 누가 책임지나?
- 산업 입장: 과장된 주장이 난무하면 시장 신뢰도가 떨어짐
2. 계층 분류법: L0부터 L5까지
L0: 수동 작업 (No Autonomy)
데이터 분석가가 모든 것을 손으로 합니다.
- SQL을 직접 작성해서 쿼리 실행
- Python 스크립트로 데이터 정제
- Tableau로 시각화 생성
현실: 지금도 많은 기업이 여전히 이 단계입니다.
L1: 보조 역할 (Assistance)
사용자가 "이 CSV에서 Fahrenheit를 Celsius로 변환해줄 Python 코드 줘"라고 하면, ChatGPT가 코드를 생성해줍니다. 끝.
사용자가 직접 코드를 실행하고, 결과를 검증하고, 문제가 있으면 다시 물어봅니다.
예시 시스템:
- LLMTune (데이터베이스 튜닝 제안)
- Table-GPT (테이블 작업 코드 생성)
- Chat2VIS (자연어로 차트 코드 생성)
한계: 환경과 상호작용 없음. 환경 피드백 없음. 그냥 일회성 답변.
L2: 부분 자율성 (Partial Autonomy)
이제 에이전트가 실제로 코드를 실행합니다.
예: AutoPrep는 "이 데이터를 정제해"라는 요청을 받으면:
- 데이터를 분석
- 정제 코드 생성
- 실제로 실행
- 결과 확인
- 문제 발견 → 다시 수정
- 반복
예시 시스템:
- Alpha-SQL: 데이터베이스를 실제로 쿼리하면서 SQL 개선
- CleanAgent: Python 인터프리터와 상호작용하며 데이터 정제
- MatPlotAgent: 시각화를 생성하고 실제로 보면서 디버깅
핵심 차이: 피드백 루프가 존재합니다. 하지만 여전히 인간이 설계한 파이프라인 내에서만 작동합니다.
예를 들어 CleanAgent는 "데이터 정제" 파이프라인만 있고, 정제 후 분석까지는 못 합니다. 각 작업에 특화된 시스템입니다.
L3: 조건부 자율성 (Conditional Autonomy) ← 현재 진행 중인 전환점
이제 사용자는 고수준의 의도만 전달합니다.
"고객 이탈(churn) 패턴을 분석하고 리포트 만들어"
에이전트가 스스로:
- 어떤 테이블을 가져올지 결정
- 데이터 품질 문제 발견 → 정제
- 어떤 분석을 할지 결정
- SQL/Python으로 분석 실행
- 시각화 생성
- 보고서 작성
예시 Proto-L3 시스템:
- AgenticData: 데이터 관리, 준비, 분석을 아우르는 통합 파이프라인 자동 생성
- Data Interpreter: 사용자 요청을 Task Graph → Action Graph로 변환해서 실행
- JoyAgent: "Tool Evolution" 기능으로 새로운 도구를 동적으로 생성하면서 작동
- SiriusBI (텐센트): 데이터 준비와 분석을 함께 처리하는 비즈니스 인텔리전스 에이전트
하지만 아직 완전하지 않습니다:
- BigQuery, Snowflake Cortex는 여전히 미리 정의된 연산자에만 의존
- 데이터 관리 부분(DB 튜닝, 시스템 진단)은 거의 다루지 않음
- 복잡한 트레이드오프를 판단하지 못함 (예: "데이터를 더 깊게 정제할까? vs 빨리 분석할까?")
L4: 높은 자율성 (High Autonomy)
인간 감시 필요 없음.
에이전트가 스스로 문제를 발견합니다.
- 데이터 레이크를 지속적으로 모니터링
- "어? 지난주 구독 취소가 30% 증가했네?"
- 스스로 근본 원인 분석 시작
- "아, 가격 인상이 원인이었구나"
- 자동으로 리포트 생성
아직 연구 단계: 실제 운영되는 L4 시스템은 없습니다.
L5: 완전 자율성 (Full Autonomy)
새로운 이론과 방법을 발명합니다.
"기존 샘플링 방법은 다 느리니까, 고속 스트림 데이터를 위한 새로운 이론을 개발해야겠다"
순수 비전: 아직 어디에도 없습니다.
3. 진화 단계와 기술적 격차: L2→L3이 가장 어려운 이유
L0→L1: 손으로 하던 것을 프롬프트로 → 쉬움 L1→L2: 환경 연결 + 피드백 루프 → 중간 정도 L2→L3: ⭐ 작업 지배권의 이양 ← 지금 여기
L2는 "사용자가 설계한 파이프라인을 따르는 집행자"입니다. L3은 "사용자의 고수준 의도를 이해하고 스스로 파이프라인을 설계하는 조율자"입니다.
이를 위해 필요한 것:
- 예측 불가능한 새로운 도구 생성
현재는 미리 정의된 연산자만 조합합니다. 미래에는 "이 작업 해본 적 없는데... 어떻게 하지?" → 새로운 도구를 자동 생성해야 합니다.
- 전체 데이터 생명주기 이해
현재 Proto-L3 시스템들의 문제: Data Interpreter는 데이터 분석에만 집중하고, SiriusBI는 데이터 준비와 분석만 합니다. 누구도 전체를 다 하지 못합니다.
- 전략적 추론 능력
에러 발생 시 현재는 "이전 단계 재시도" (전술적)만 가능합니다. 미래에는 "왜 에러가 났지? 이게 구조적 문제네. 다른 데이터 소스를 써볼까?" (전략적) 수준이 필요합니다.
- 동적 환경 적응
현재 시스템들은 정적 데이터/정적 작업에서만 테스트됩니다. 스키마가 바뀌면? 새로운 데이터 소스가 추가되면? 사용자 요청이 진화하면? 이런 상황에서 아직 준비가 안 됐습니다.
4. 현실적 고찰: 과장 vs 기대
과장된 부분
기업들이 "AI 데이터 에이전트를 도입했습니다!"라고 할 때, 대부분 L2 시스템입니다. 하지만 광고에서는 L3처럼 표현합니다.
현실적 기대
- 당장: L2 시스템으로 데이터 분석 속도 2-3배 향상 가능
- 가까운 미래: L3이 나오면 데이터팀 규모 축소 가능 (추정 3-5년)
- 먼 미래: L4/L5는 기초 연구 수준
결론
이 논문의 핵심은 간단하지만 강력합니다.
"데이터 에이전트가 정말 자율적인가?"라는 질문에 대해, 현재의 답은 "부분적으로 그렇고, 곧 더 그래질 것" 입니다.
지금 우리가 보는 것:
- L1: 프롬프트에 답하는 보조자
- L2: 정해진 파이프라인을 따르는 집행자
- Proto-L3: 몇 가지 할 수 있는 조율자 (하지만 제한적)
진정한 L3 데이터 에이전트가 되려면 미리 정의되지 않은 연산자를 스스로 생성하고, 전체 데이터 생명주기를 이해하며, 전략적 사고로 근본 원인을 파악하고, 동적으로 변화하는 환경에 적응해야 합니다.
"데이터 에이전트가 혁신적 패러다임인가?"라는 질문에 대해서는:
✓ 혁신적인가: 네, L2와 Proto-L3 시스템으로 실제 가치 제공 중 ✗ 완전 자율인가: 아니오, 아직 L2 수준이 주류이고 L3은 초기 단계 ⚠ 과장되었는가: 심하게는 아니지만, 마케팅은 확실히 앞서갑니다
결국 데이터 에이전트의 미래는 이 L2→L3 전환을 얼마나 잘 넘느냐에 달려있습니다.
어때요? 이제 훨씬 구체적인 사례와 함께 흐름이 살아있는 것 같습니다!