Prefix-Tuning Optimizing Continuous Prompts for Generation
대형 언어모델이 다양한 NLP 태스크에서 놀라운 성능을 보이고 있지만, 각 태스크마다 전체 모델을 파인튜닝해야 한다는 비효율적인 문제가 있었습니다. 스탠포드 대학의 연구진이 2021년 발표한 Prefix-Tuning은 이러한 문제에 대한 혁신적인 해결책을 제시합니다.
X. L. Li and P. Liang, "Prefix-Tuning: Optimizing Continuous Prompts for Generation", arXiv preprint arXiv:2101.00190, 2021, DOI: 10.48550/arXiv.2101.00190.
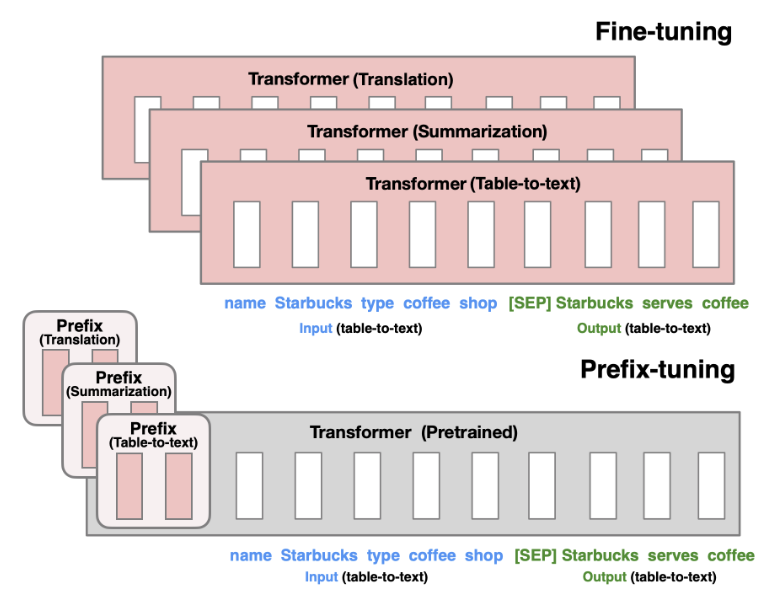
기존 파인튜닝 방식은 GPT-2의 774M개, GPT-3의 175B개 파라미터를 모두 업데이트하고 각 태스크마다 전체 모델을 저장해야 했습니다. 만약 100개의 서로 다른 태스크가 있다면 100개의 모델 복사본이 필요한 셈이죠. Prefix-Tuning은 이런 비효율성을 해결하기 위해 모델 파라미터는 고정하고 작은 연속적인 프롬프트만 최적화하는 방법을 제안합니다.
요약
아키텍처: 사전훈련된 언어모델에 학습 가능한 연속적 prefix 벡터를 추가하는 구조
사용 모델:
- Table-to-text 생성: GPT-2 Medium/Large
- 요약: BART Large
데이터셋:
- E2E (50K 예제, 레스토랑 도메인)
- WebNLG (22K 예제, 14개 도메인)
- DART (82K 예제, 오픈 도메인)
- XSUM (225K 예제, 뉴스 요약)
평가 매트릭: BLEU, ROUGE, METEOR, NIST, CIDEr 등 표준 생성 평가 지표
훈련 방법:
- 언어모델 파라미터 고정
- Prefix 파라미터만 AdamW로 최적화
- MLP를 통한 재파라미터화로 안정성 확보
- 실제 단어 활성화로 초기화
논문 상세
문제 정의 및 동기
기존 파인튜닝 방식의 주요 문제점들을 살펴보겠습니다. 첫째, 저장 공간 문제입니다. 각 태스크마다 전체 모델의 복사본을 저장해야 하므로 수백 기가바이트의 저장 공간이 태스크 수만큼 필요합니다. 둘째, 배포 복잡성입니다. 여러 태스크를 동시에 서비스하려면 각각 별도의 모델을 로드해야 합니다. 셋째, 개인화의 어려움입니다. 사용자별 맞춤 모델을 만들려면 각 사용자마다 전체 모델을 저장해야 합니다.
연구진은 프롬프팅에서 영감을 얻었습니다. GPT-3에서 자연어 지시문과 몇 개의 예시를 입력에 추가하면 특정 태스크를 수행할 수 있다는 점에 주목했습니다. 하지만 이산적인 프롬프트는 표현력이 제한되고 최적화가 어렵다는 한계가 있었습니다.
방법론: Prefix-Tuning
Prefix-Tuning의 핵심 아이디어는 입력 시퀀스 앞에 학습 가능한 연속적 벡터들을 추가하는 것입니다. 이 벡터들을 prefix라고 부르며, 실제 토큰이 아닌 "가상 토큰"처럼 작동합니다.
자기회귀 모델의 경우 z = \(PREFIX; x; y\) 형태로 구성됩니다. 여기서 PREFIX는 학습 가능한 벡터들이고, x는 입력, y는 출력입니다. 인코더-디코더 모델의 경우에는 인코더와 디코더 양쪽에 각각 prefix를 추가합니다.
핵심적으로, prefix 부분의 활성화는 학습 가능한 파라미터 매트릭스 P_θ에서 직접 가져오고, 나머지 부분은 일반적인 Transformer 연산을 통해 계산됩니다. 언어모델의 파라미터 φ는 고정되고 prefix 파라미터 θ만 업데이트됩니다.
연구진은 직접적인 prefix 최적화가 불안정하다는 것을 발견하고, 재파라미터화 기법을 도입했습니다. 작은 행렬 P'_θ를 MLP를 통해 실제 prefix 크기로 확장하는 방식입니다. 이렇게 하면 학습이 더 안정적이고 성능도 향상됩니다.
실험 설정
Table-to-text 생성 실험에서는 구조화된 데이터를 자연어로 변환하는 태스크를 다뤘습니다. E2E 데이터셋은 레스토랑 정보를 설명문으로 변환하는 단일 도메인 태스크이고, WebNLG는 위키피디아 지식베이스의 트리플을 텍스트로 변환하는 멀티 도메인 태스크입니다. DART는 가장 복잡한 오픈 도메인 데이터셋으로 다양한 소스의 구조화된 데이터를 포함합니다.
요약 실험에서는 XSUM 데이터셋을 사용했습니다. BBC 뉴스 기사를 한 문장으로 요약하는 추상적 요약 태스크로, 입력 길이가 평균 431단어로 상당히 깁니다.
비교 대상으로는 전체 파인튜닝, 상위 2개 레이어만 튜닝하는 방법, 그리고 어댑터 튜닝을 사용했습니다. 어댑터 튜닝은 Transformer 레이어 사이에 작은 신경망을 삽입하는 경량 튜닝 방법입니다.
하이퍼파라미터로는 AdamW 옵티마이저, 5×10^-5 학습률, 10 에폭, 배치 크기 5를 기본으로 사용했습니다. Prefix 길이는 기본적으로 10으로 설정했습니다.
주요 실험 결과
Table-to-text 생성에서 Prefix-Tuning은 놀라운 결과를 보였습니다. 전체 파라미터의 0.1%만 사용하면서도 전체 파인튜닝과 비슷하거나 더 좋은 성능을 달성했습니다. E2E에서는 BLEU 점수 69.7로 파인튜닝의 68.2를 능가했고, WebNLG와 DART에서도 경쟁력 있는 결과를 보였습니다.
특히 어댑터 튜닝과 비교했을 때 상당한 우위를 보였습니다. 같은 0.1% 파라미터를 사용하는 조건에서 평균 4.1 BLEU 점수 향상을 달성했습니다. 3%의 파라미터를 사용하는 어댑터 튜닝과 비교해도 비슷하거나 더 좋은 성능을 보였습니다.
요약 태스크에서는 약간 다른 양상을 보였습니다. 2% 파라미터를 사용할 때는 파인튜닝 대비 소폭 성능 저하가 있었고(ROUGE-L 36.05 vs 37.25), 0.1% 파라미터로는 더 큰 성능 차이가 났습니다. 이는 요약이 더 복잡한 태스크이고 입력이 길어서 더 많은 파라미터가 필요할 수 있음을 시사합니다.
저데이터 설정에서 Prefix-Tuning의 장점이 더욱 부각되었습니다. 50, 100, 200, 500개의 작은 데이터셋에서 파인튜닝 대비 평균 2.9 BLEU 점수 향상을 보였습니다. 질적 분석 결과, 파인튜닝은 낮은 데이터 환경에서 부정확한 정보를 생성하는 경향이 있는 반면, Prefix-Tuning은 더 보수적이고 신뢰할 수 있는 출력을 생성했습니다.
일반화 성능 실험에서도 흥미로운 결과가 나왔습니다. WebNLG의 미지 카테고리와 XSUM의 도메인 전이 실험에서 모두 Prefix-Tuning이 파인튜닝을 앞섰습니다. 이는 언어모델 파라미터를 보존하는 것이 새로운 도메인에 대한 일반화에 도움이 됨을 시사합니다.
상세 분석
Prefix 길이에 대한 분석 결과, 요약에서는 200, table-to-text에서는 10 정도가 최적점이었습니다. 그 이후로는 성능이 오히려 감소하는 경향을 보였는데, 이는 과적합 때문으로 해석됩니다.
임베딩만 튜닝하는 ablation study에서는 성능이 크게 떨어졌습니다. 이는 모든 레이어의 prefix를 최적화하는 것이 중요함을 보여줍니다. 또한 prefix의 위치도 중요했는데, 입력 앞에 두는 것이 입력과 출력 사이에 두는 것보다 효과적이었습니다.
초기화 전략도 성능에 큰 영향을 미쳤습니다. 랜덤 초기화는 매우 불안정한 결과를 보인 반면, 실제 단어들의 활성화로 초기화하면 안정적이고 좋은 성능을 얻을 수 있었습니다. 특히 "summarization", "table-to-text" 같은 태스크 관련 단어로 초기화하면 더 좋은 결과를 얻었습니다.
결론
Prefix-Tuning은 여러 실용적 장점을 제공합니다. 첫째, 개인화 시나리오에서 각 사용자별로 작은 prefix만 저장하면 되므로 매우 효율적입니다. 둘째, 서로 다른 사용자의 요청을 하나의 배치로 처리할 수 있어 클라우드 서비스에 유리합니다. 셋째, 새로운 태스크나 사용자 추가가 모듈식으로 가능합니다.
성능 면에서는 언어모델 파라미터를 보존하는 것이 일반화에 도움이 되며, attention 메커니즘을 통해 prefix가 전체 시퀀스에 영향을 미칠 수 있다는 점이 핵심입니다. 어댑터 튜닝보다 훨씬 적은 파라미터로도 비슷한 성능을 낼 수 있는 이유를 설명합니다.
한계는 이렇습니다. 복잡한 태스크나 긴 입력에서는 여전히 성능 차이가 존재하고 적절한 초기화 전략이 중요하다는 점입니다. 또한 prefix 길이나 재파라미터화 등의 하이퍼파라미터 튜닝이 필요합니다.
Prefix-Tuning은 대형 언어모델의 효율적 활용이라는 중요한 연구 방향을 제시했습니다. 후속 연구들인 LoRA, P-Tuning v2 등의 토대가 되었으며, 현재도 parameter-efficient fine-tuning 분야의 핵심 아이디어로 활용되고 있습니다.