Efficient Multi-modal Large Language Models via Progressive Consistency Distillation
멀티모달 대규모 언어 모델(MLLM)은 텍스트와 이미지를 동시에 이해할 수 있는 강력한 능력을 보여주고 있습니다. 하지만 이미지를 처리하기 위해 사용되는 시각 토큰(visual token)이 너무 많아 계산 비용이 크게 증가하는 문제가 있습니다. 이 논문은 시각 토큰을 효율적으로 압축하면서도 성능을 유지하는 학습 프레임워크를 제안합니다.
Z. Wen, S. Wang, Y. Zhou, J. Zhang, Q. Zhang, Y. Gao, Z. Chen, B. Wang, W. Li, C. He and L. Zhang, "Efficient Multi-modal Large Language Models via Progressive Consistency Distillation", arXiv preprint arXiv:2510.00515, 2025.
요약
핵심 아이디어: EPIC(Efficient MLLMs via Progressive Consistency Distillation)은 점진적 학습 전략을 통해 시각 토큰 압축의 어려움을 해결합니다.
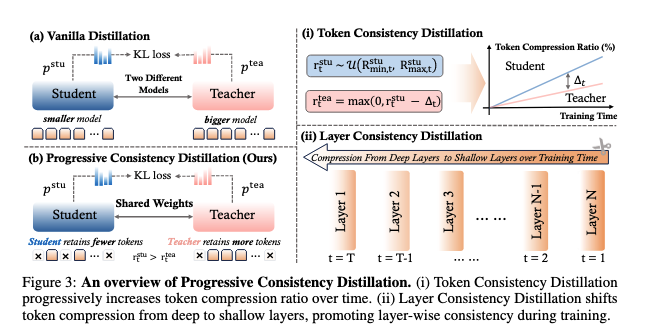
주요 구성 요소:
- Token Consistency Distillation (TCD): 토큰 단위로 압축 비율을 점진적으로 증가
- Layer Consistency Distillation (LCD): 레이어 단위로 깊은 층에서 얕은 층으로 점진적 압축
실험 설정:
- 기반 모델: LLaVA-v1.5-7B (CLIP ViT-L/14 + Vicuna-v1.5)
- 학습 데이터: LLaVA-665K instruction fine-tuning dataset
- 토큰 압축 방법: DART, FastV, Random pruning
평가 지표:
- 10개 벤치마크: VQA V2, GQA, VizWiz, ScienceQA, TextVQA, POPE, MME, MMBench, MMBench-CN, OCRBench
- 효율성 지표: KV cache 크기, FLOPs, 추론 시간
주요 성과:
- 128개 토큰으로 vanilla LLaVA-v1.5와 유사한 성능 달성 (평균 61.3%)
- 192개 토큰 이상에서는 vanilla 모델 성능 초과 (61.7%)
- 64개 토큰만으로도 약 2% 성능 하락에 그침 (59.4%)
- KV cache 88.9% 감소, FLOPs 83.9% 감소, 추론 속도 1.6배 향상
논문 상세
1. Introduction
멀티모달 대규모 언어 모델은 시각 정보를 이해할 수 있는 능력을 갖추고 있지만, 텍스트 토큰에 비해 훨씬 많은 양의 시각 토큰을 처리해야 합니다. 예를 들어, 고해상도 이미지나 다중 프레임 비디오를 처리할 때 계산 부담이 급격히 증가합니다.
기존의 토큰 압축 방법들은 크게 두 가지로 나뉩니다:
- 학습 불필요 방법: 중요도나 중복성 기반으로 토큰 제거 (FastV, DART 등)
- 학습 기반 방법: 모델 구조 변경이나 새로운 파라미터 도입 (MQT-LLaVA, TokenPacker 등)
하지만 이러한 방법들은 토큰 압축이 학습에 미치는 어려움을 간과하는 경향이 있습니다. 토큰 압축은 feature space에 큰 변화를 일으키고, 이는 모델이 새로운 최적점을 찾기 어렵게 만듭니다.
2. Methodology
2.1 문제 정의
MLLM은 세 가지 모듈로 구성됩니다:
- 시각 인코더 (Visual Encoder): 이미지를 패치 단위 특징으로 변환
- 모달리티 프로젝터 (Modality Projector): 시각 특징을 언어 모델 입력 공간으로 투영
- 언어 모델 (Language Model): 시각 토큰과 텍스트 토큰을 통합하여 응답 생성
수식으로 표현하면: \[e_v = \text{MLP}(\text{VE}(I))\] \[x = [e_v; e_t]\] \[y_i = \text{LM}(x, y_{<i})\]
여기서 \(e_v\)는 시각 토큰, \(e_t\)는 텍스트 토큰입니다.
2.2 Progressive Consistency Distillation 개념
토큰 압축은 feature space에 perturbation을 일으키고, 이는 parameter space의 최적점을 이동시킵니다. 압축 비율이 높을수록 perturbation이 크고, 최적점이 더 멀리 이동합니다.
EPIC의 핵심 아이디어는 하나의 모델이 teacher와 student 역할을 동시에 수행하면서, 점진적으로 압축 난이도를 높이는 것입니다:
- 초기에는 낮은 압축 비율로 시작 (쉬운 학습)
- 점진적으로 압축 비율 증가 (단계적 난이도 상승)
- Teacher는 항상 student보다 약간 낮은 압축 비율 사용
2.3 Token Consistency Distillation (TCD)
토큰 단위의 점진적 학습을 수행합니다:
학생 모델 압축 비율 샘플링: \[r_t^{stu} \sim U(R_{min,t}^{stu}, R_{max,t}^{stu})\]
여기서 \(R_{max,t}^{stu}\)는 학습이 진행됨에 따라 5%에서 90%로 선형 증가합니다.
교사 모델 압축 비율: \[r_t^{tea} = \max(0, r_t^{stu} - \Delta_t)\]
압축 비율 gap \(\Delta_t\)는 점진적으로 증가하여 (5% → 30%), teacher가 적절한 guidance를 제공합니다.
손실 함수: \[L_{total}(\theta) = (1-\lambda) \cdot L_{SFT}(\theta) + \lambda \cdot L_{TCD}(\theta)\] \[L_{TCD}(\theta) = \mathbb{E}_{I,P,t}[\text{KL}(p^{tea} | p^{stu})]\]
여기서 \(\lambda = 0.7\)로 설정되었습니다.
2.4 Layer Consistency Distillation (LCD)
레이어 단위의 점진적 학습을 수행합니다:
압축 레이어 선택: \[\ell_t = \text{Round}(L - \beta_t(L - \ell_{min}))\]
여기서 \(\beta_t = t/T\)는 정규화된 학습 진행도이며, 압축이 깊은 레이어(\(L\))에서 시작해 얕은 레이어(\(\ell_{min}\))로 점진적으로 이동합니다.
압축 비율 샘플링: \[r_t^{stu} \sim U(r_{min}, r_{max})\]
일반적으로 \(r_{min} = 0.2\), \(r_{max} = 0.9\)로 설정됩니다.
2.5 이론적 근거
논문은 1차원 프로토타입을 통해 점진적 학습의 이론적 타당성을 증명합니다:
정리 1: 점진적 경로의 총 변동(Total Variation)이 직접 학습보다 작습니다: \[TV({\theta_r^{prog}}) \le \frac{1+\lambda\kappa}{1+\lambda} \cdot TV({\theta_r^{dir}}) < TV({\theta_r^{dir}})\]
여기서 \(\kappa < 1\)이므로 점진적 학습이 더 부드러운 최적화 궤적을 제공합니다.
3. Experiments
3.1 주요 실험 결과
성능 비교 (128 토큰 유지 시):
- EPIC: 61.3% (vanilla 대비 -0.1%)
- MQT-LLaVA: 57.6% (vanilla 대비 -3.8%)
- TokenPacker: 56.3% (vanilla 대비 -5.1%)
효율성 비교 (64 토큰 유지 시):
- KV cache: 367.2MB → 40.9MB (88.9% 감소)
- FLOPs: 9.3T → 1.5T (83.9% 감소)
- 추론 시간: 1103.5s → 697.3s (36.8% 감소)
3.2 Ablation Studies
TCD Ablation (128 토큰 유지):
- EPIC: 61.3%
- w/o Distillation Loss: 59.8% (-1.5%)
- w/o Progressive Compression Ratio: 59.1% (-2.2%)
LCD Ablation (128 토큰 유지):
- EPIC: 61.3%
- w/o Distillation Loss: 60.5% (-0.8%)
- w/o Progressive Compression Layer: 60.3% (-1.0%)
이 결과는 teacher guidance와 점진적 학습 전략 모두가 성능에 중요함을 보여줍니다.
3.3 일반화 능력
EPIC으로 학습된 모델은 다양한 토큰 압축 전략에서 일관되게 좋은 성능을 보입니다:
- DART로 학습 → FastV, Random으로 추론 시에도 성능 향상
- 토큰 압축 전략 간 성능 격차 감소
3.4 극단적 토큰 압축의 필요성
논문은 극단적인 토큰 압축(1-2개 토큰)이 항상 좋은 것은 아니라고 분석합니다:
- 576 → 128 토큰: FLOPs가 9.3T → 2T로 크게 감소
- 128 → 36 토큰: FLOPs 감소 폭이 작아짐
- 추론 시간도 유사한 패턴
High ROI Area: 64-128 토큰 범위에서 성능과 효율성의 최적 균형 Low ROI Area: 36개 이하 토큰에서는 추가 압축의 이득이 작고 성능 저하가 큼
4. Integrated Progressive Consistency Distillation (ICD)
TCD와 LCD를 통합한 접근법:
- 레이어별로 TCD 적용
- 각 레이어 전환 시 압축 비율 초기화
결과 (192 토큰 유지):
- ICD: 61.7% (vanilla 대비 +0.3%)
- 다른 방법들보다 우수한 성능
결론
EPIC은 모델 구조 변경 없이 점진적 학습 전략만으로 효율적인 MLLM을 학습할 수 있는 프레임워크입니다. 주요 기여는 다음과 같습니다:
- Progressive Consistency Distillation: 토큰 및 레이어 단위의 점진적 학습
- 우수한 성능: 128 토큰으로 vanilla 모델과 유사한 성능 달성
- 높은 효율성: KV cache, FLOPs, 추론 시간 대폭 감소
- 강건성 및 일반화: 다양한 압축 비율과 전략에서 안정적 성능
- 이론적 정당성: 점진적 학습의 수학적 근거 제시