Less is More Recursive Reasoning with Tiny Networks
LLM이 잘 못하는 문제가 몇 가지 있습니다. 바로 스도쿠나 미로 찾기 같은 복잡한 퍼즐 문제입니다. 이런 문제를 해결하기 위해 최근 등장한 Hierarchical Reasoning Model(HRM)은 27M 파라미터로 대형 모델보다 좋은 성능을 보였습니다. 그런데 이 모델마저도 고도의 생물학적 논거와 수학적 이론에 의존하는 복잡한 모델입니다. 더 단순하고 가벼운 모델을 만들 순 없을까요?
이 논문은 HRM을 크게 단순화하면서도 성능은 더욱 향상시킨 Tiny Recursive Model(TRM)을 제안합니다. 놀랍게도 단 7M 파라미터로 ARC-AGI-1에서 45%, ARC-AGI-2에서 8%의 정확도를 달성하여 Deepseek R1, o3-mini, Gemini 2.5 Pro 같은 대형 모델들을 능가했습니다. 파라미터 수는 0.01% 미만입니다.
A. Jolicoeur-Martineau, "Less is More: Recursive Reasoning with Tiny Networks", arXiv preprint arXiv:2510.04871, 2025.
요약
아키텍처: 단일 2-layer 네트워크로 구성된 재귀적 추론 모델
모델 구조가 정말 단순하네요. 이런 간단한 네트워크로 어떻게 내로라하는 추론 모델의 성능을 따라잡을 수 있었던 것인지 알아보겠습니다.
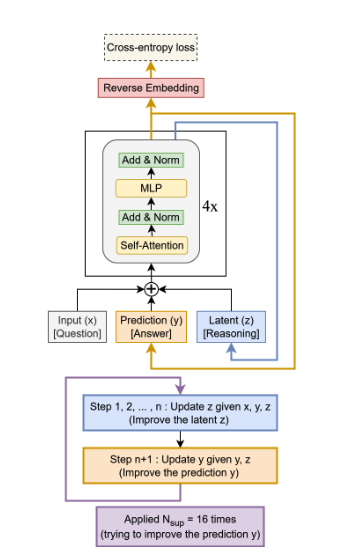
주요 특징:
- 단일 네트워크: HRM의 두 개 네트워크(\(f_L\), \(f_H\))를 하나로 통합
- 얕은 레이어: 4-layer 대신 2-layer 사용으로 과적합 감소
- 단순화된 ACT: 한 번의 forward pass로 조기 중단 결정
데이터셋:
- Sudoku-Extreme: 1K 훈련, 423K 테스트 샘플
- Maze-Hard: 1K 훈련/테스트 (30×30 미로)
- ARC-AGI-1: 800개 태스크
- ARC-AGI-2: 1,120개 태스크
평가 매트릭: 정확도(Accuracy)
훈련 방법:
- Deep Supervision: 최대 16단계의 지도 학습
- EMA (Exponential Moving Average): 가중치 안정화
- AdamW 옵티마이저
- 데이터 증강: Sudoku(1000배), Maze(8배), ARC-AGI(1000배)
주요 성과:
- Sudoku-Extreme: 55% → 87.4% (HRM 대비)
- Maze-Hard: 74.5% → 85.3%
- ARC-AGI-1: 40.3% → 44.6%
- ARC-AGI-2: 5.0% → 7.8%
논문 상세
1. 서론
대형 언어 모델은 자동 회귀 방식으로 답변을 생성하기 때문에 단 하나의 잘못된 토큰이 전체 답변을 흐리는 일이 생깁니다. 이를 개선하기 위한 방법이 잘 알려진 Chain-of-Thought(CoT)와 Test-Time Compute(TTC) 기법입니다. 이런 방법이 나왔음에도 ARC-AGI 같은 어려운 문제에서는 여전히 인간 수준의 정확도에는 도달하지 못합니다.
Wang et al.(2025)이 제안한 HRM은 두 개의 작은 네트워크를 서로 다른 빈도로 재귀시키는 접근법입니다. 스도쿠, 미로, ARC-AGI 같은 퍼즐 문제에서 LLM을 능가했습니다. HRM의 핵심은 재귀적 계층 추론(recursive hierarchical reasoning)과 깊은 지도 학습(deep supervision)입니다.
그러나 독립적인 분석에 따르면, HRM의 성능 향상은 주로 deep supervision에서 비롯되며, 재귀적 계층 추론의 기여는 미미했습니다(19% → 39%는 deep supervision, 35.7% → 39%는 재귀). 이는 재귀 설계가 최적이 아닐 수 있음을 시사합니다.
2. HRM 배경
구조: HRM은 네 가지 학습 가능한 컴포넌트로 구성됩니다.
- 입력 임베딩 \(f_I(\cdot; \theta_I)\)
- 저수준 재귀 네트워크 \(f_L(\cdot; \theta_L)\)
- 고수준 재귀 네트워크 \(f_H(\cdot; \theta_H)\)
- 출력 헤드 \(f_O(\cdot; \theta_O)\)
각 네트워크는 RMSNorm, 편향 없음, Rotary Embeddings, SwiGLU 활성화 함수를 사용하는 4-layer Transformer입니다.
재귀 과정 (\(n=2, T=2\) 설정):
x ← f_I(x̃)
zL ← f_L(zL + zH + x) # 기울기 없음
zL ← f_L(zL + zH + x) # 기울기 없음
zH ← f_H(zL + zH) # 기울기 없음
zL ← f_L(zL + zH + x) # 기울기 없음
zL ← zL.detach()
zH ← zH.detach()
zL ← f_L(zL + zH + x) # 기울기 있음
zH ← f_H(zL + zH) # 기울기 있음
ŷ ← argmax(f_O(zH))
1-step gradient approximation: Implicit Function Theorem을 사용하여 마지막 2단계만 역전파하여 메모리 요구사항을 크게 줄입니다.
Deep Supervision: 이전 latent feature \((z_H, z_L)\)을 다음 forward pass의 초기화로 재사용하여, 최대 16단계까지 반복하며 솔루션에 수렴합니다.
Adaptive Computational Time (ACT): Q-learning 목표를 통해 조기 중단 메커니즘을 학습하여 훈련 효율성을 높입니다. 단, 추가 forward pass가 필요합니다.
3. HRM의 개선 목표
3.1 Implicit Function Theorem의 한계
HRM은 고정점(fixed-point)에 도달한다고 가정하지만, 실제로는 다음과 같은 문제가 있습니다:
- \(n=2, T=2\) 설정에서 단 4번의 재귀 후 고정점을 가정
- 저자들의 예시(\(n=7, T=7\))에서도 residual이 0에 가깝지 않음
- \(z_L\)이 한 번의 \(f_L\) 평가 후에는 수렴과 거리가 멈
3.2 ACT의 2배 forward pass 비용
ACT는 halting loss와 continue loss를 모두 필요로 하며, continue loss 계산을 위해 추가 forward pass가 필요합니다. 이는 훈련 시간을 2배로 증가시킵니다.
3.3 복잡한 생물학적 논거
HRM은 뇌의 서로 다른 시간 주파수와 계층적 처리에 기반한 생물학적 논거로 설계를 정당화합니다. 이는 이해하기 어렵고, ablation 연구 부족으로 어떤 부분이 왜 도움이 되는지 불분명합니다.
4. Tiny Recursive Model (TRM)
4.1 고정점 정리 불필요
TRM은 전체 재귀 과정을 역전파합니다:
z ← f_L(z_L + z_H + x)
... # n번 반복
z_H ← f_H(z_L + z_H)
Deep supervision 설계상, 몇 번의 재귀 과정(기울기 없이도)을 거치면 솔루션에 가까워집니다. 따라서 \(T-1\)번의 재귀를 기울기 없이 수행한 후, 1번의 재귀를 역전파합니다. 이를 통해 Sudoku-Extreme에서 56.5% → 87.4%로 향상되었습니다.
4.2 단순한 재해석
HRM의 \(z_H\)와 \(z_L\)을 생물학적 계층이 아닌 단순하게 재해석합니다:
- \(z_H\) (이제 \(y\)): 현재 솔루션의 임베딩
- \(z_L\) (이제 \(z\)): 추론을 위한 latent feature
입력 \(x\), 현재 솔루션 \(y\), 현재 추론 \(z\)를 고려하여 모델은 재귀적으로 \(z\)를 개선하고, 그 다음 \(y\)를 업데이트합니다. Chain-of-Thought처럼 \(z\)는 이전 추론을 기억하게 하고, \(y\)는 현재 답변을 추적합니다.
더 많거나 적은 feature를 실험한 결과:
- Multi-scale \(z\) (7개 feature): 77.6%
- Single \(z\) (1개 feature): 71.9%
- \(y, z\) (2개 feature, 제안 방법): 87.4%
2개의 feature가 최적임을 확인했습니다.
4.3 단일 네트워크
HRM은 \(f_L\)과 \(f_H\) 두 개의 네트워크를 사용하지만, TRM은 입력에 \(x\)의 포함 여부로 태스크를 구분할 수 있습니다:
- \(z \leftarrow f(x, y, z)\): latent 반복
- \(y \leftarrow f(y, z)\): 솔루션 업데이트
단일 네트워크로 통합하여 파라미터를 절반으로 줄이면서 Sudoku-Extreme에서 82.4% → 87.4%로 향상되었습니다.
4.4 작을수록 좋다
레이어 수를 늘려 용량을 증가시키면 과적합으로 인해 일반화 성능이 감소했습니다. 반대로 레이어를 줄이고 재귀 횟수(\(n\))를 비례적으로 늘리자 성능이 향상되었습니다. 2-layer가 최적이며, 79.5% → 87.4%로 향상되면서 파라미터는 다시 절반으로 감소했습니다.
이는 데이터가 부족할 때 큰 모델의 과적합 페널티를 보여줍니다. Tiny network와 deep recursion, deep supervision의 조합이 과적합을 우회합니다.
4.5 Attention-free 아키텍처
작고 고정된 컨텍스트 길이(\(L \leq D\))에서는 self-attention 대신 MLP-Mixer에서 영감을 받은 MLP를 사용할 수 있습니다. 9×9 스도쿠에서 74.7% → 87.4%로 향상되었지만, 30×30 그리드를 사용하는 Maze-Hard와 ARC-AGI에서는 self-attention이 더 좋았습니다.
4.6 ACT의 단순화
Q-learning의 continue loss를 제거하고 Binary Cross-Entropy loss로 정답 도달 여부만 학습합니다. 이로써 추가 forward pass가 불필요해지며, 성능은 86.1% → 87.4%로 유지됩니다.
4.7 Exponential Moving Average (EMA)
작은 데이터에서 HRM은 빠르게 과적합되고 발산하는 경향이 있습니다. GAN과 diffusion model에서 흔히 사용되는 EMA(0.999)를 적용하여 안정성을 높이고 79.9% → 87.4%로 향상시켰습니다.
4.8 최적 재귀 횟수
\(T=3, n=6\) (42번의 재귀)가 Sudoku-Extreme에서 최적임을 발견했습니다. 더 많은 재귀는 어려운 문제에 도움이 될 수 있지만, 훈련 속도가 크게 느려집니다.
5. 실험 결과
Sudoku-Extreme & Maze-Hard:
모델 |
파라미터 |
Sudoku |
Maze |
|---|---|---|---|
Deepseek R1 |
671B |
0.0% |
0.0% |
Claude 3.7 |
? |
0.0% |
0.0% |
O3-mini |
? |
0.0% |
0.0% |
HRM |
27M |
55.0% |
74.5% |
TRM-Att |
7M |
74.7% |
85.3% |
TRM-MLP |
5M |
87.4% |
0.0% |
ARC-AGI:
모델 |
파라미터 |
ARC-1 |
ARC-2 |
|---|---|---|---|
Deepseek R1 |
671B |
15.8% |
1.3% |
Claude 3.7 |
? |
28.6% |
0.7% |
o3-mini |
? |
34.5% |
3.0% |
Gemini 2.5 Pro |
? |
37.0% |
4.9% |
Grok-4 |
1.7T |
66.7% |
16.0% |
Bespoke (Grok-4) |
1.7T |
79.6% |
29.4% |
HRM |
27M |
40.3% |
5.0% |
TRM-Att |
7M |
44.6% |
7.8% |
TRM-MLP |
19M |
29.6% |
2.4% |
TRM-Att는 self-attention을 사용하며 7M 파라미터로 대부분의 LLM보다 높은 성능을 달성했습니다. 파라미터는 0.01% 미만입니다.
6. 결론
TRM은 단일 tiny network로 latent reasoning feature를 재귀적으로 개선하고 최종 답변을 점진적으로 향상시키는 단순한 재귀적 추론 방법입니다. HRM과 달리 고정점 정리, 복잡한 생물학적 정당화, 계층 구조가 필요하지 않습니다.
레이어 수를 절반으로 줄이고 두 네트워크를 하나로 통합하여 파라미터를 대폭 감소시키면서도, 4개 벤치마크 모두에서 더 나은 일반화 성능을 달성했습니다.
실패한 아이디어들:
- Mixture-of-Experts(MoE): 과도한 용량으로 일반화 감소
- Weight tying: 제약이 너무 강해 성능 하락
- TorchDEQ 고정점 반복: 훈련 속도 저하 및 성능 감소
향후 연구 방향으로는 재귀가 왜 큰 네트워크보다 효과적인지에 대한 이론적 설명과, TRM을 생성 태스크로 확장하는 것이 중요할 겁니다. 특히 삼성에서 나온 논문이라는 점이 인상깊습니다. AI에는 시큰둥하게 보이던 삼성에 무언가 변화가 생기는 걸까요?