Context Engineering 2.0 - The Context of Context Engineering
Hua, Q., Ye, L., Fu, D., Xiao, Y., Cai, X., Wu, Y., Lin, J., Wang, J., & Liu, P. (2025). Context Engineering 2.0: The Context of Context Engineering. arXiv preprint arXiv:2510.26493.
"한 개인의 본질은 사회적 관계의 총합이다"라는 마르크스의 통찰이 있습니다. 이 말은 우리 시대에 새로운 의미를 갖습니다. 예전엔 이것이 인간관계만을 의미했다면, 지금은 인간-기계 상호작용까지 포함하게 된 것이죠.
LLM의 일상화로 컨텍스트 엔지니어링이라는 개념이 떠오르고 있습니다. 많은 사람들이 이것을 최신 에이전트 시대의 산물로 생각하곤 하는데, 실은 20년 이상의 역사를 가진 분야입니다. 이 논문의 핵심 통찰은 바로 여기에 있습니다.
기계가 인간의 의도를 이해하려면, 결국 정보 엔트로피를 줄여야 한다는 것이죠. 인간은 자동으로 문맥의 빈틈을 채우지만, 기계는 그렇지 못합니다. 그래서 우리가 해야 할 일은 기계를 위해 복잡한 정보를 단순한 형태로 '전처리'하는 것입니다. 기계가 똑똑해질수록, 이 과정은 자연스러워집니다.
요약
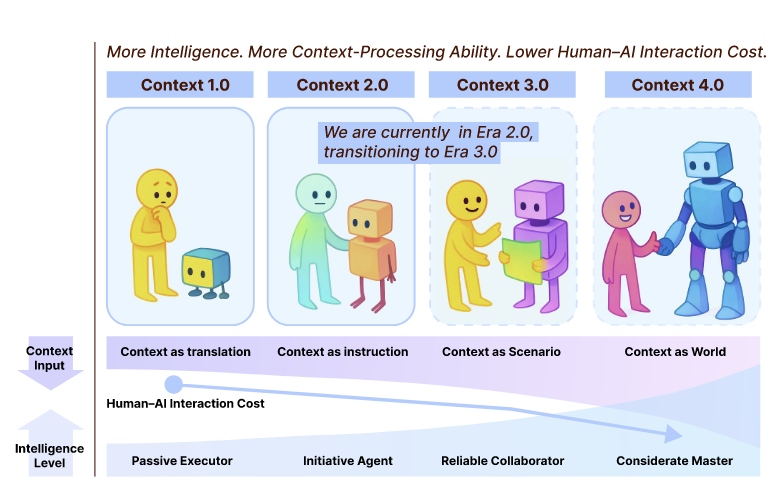
핵심 발견: Context Engineering은 1990년대부터 진화해온 학문으로, 기계 지능 수준에 따라 4단계로 나뉩니다. 현재 우리는 2.0 시대(에이전트 중심)에 있으며, 3.0(인간 수준 지능)으로 향하고 있습니다.
기술 스펙:
- 저자 기관: Shanghai Jiao Tong University (SJTU), Semantic Intelligence Institute (SII)
- 논문 타입: Preprint (arXiv)
- 발표일: 2025년 10월 30일
- 평가 범위: 문헌 기반 체계적 분석 (벤치마크 없음)
- 주요 대상: LLM 기반 에이전트, 멀티에이전트 시스템 엔지니어
Context Engineering은 기계 지능 수준에 따라 4단계로 진화합니다:
단계 |
시기 |
기계 특성 |
인터페이션 방식 |
문맥의 역할 |
|---|---|---|---|---|
1.0 |
1990s-2020 |
원시적 계산 |
고정된 구조 입력 |
번역(Translation) |
2.0 |
2020-현재 |
에이전트 지능 |
자연언어 처리 |
지시(Instruction) |
3.0 |
미래 |
인간 수준 |
직관적 협업 |
시나리오(Scenario) |
4.0 |
투기적 |
초인적 지능 |
필요 발굴 |
세계(World) |
현재 우리는 2.0과 3.0 사이에서 전환 중입니다.
논문 상세
1. 왜 Context Engineering인가?
최근 LLM과 에이전트의 부상으로 "문맥이 모델 성능에 미치는 영향"에 대한 관심이 급증했습니다. 하지만 이 개념은 사실 훨씬 오래되었습니다.
핵심 질문: 인간의 의도를 제대로 이해하고 행동하려면, 기계를 위해 어떻게 효과적인 문맥을 설계해야 할까?
이 논문의 혁신점은 Context Engineering을 단순한 '프롬프트 엔지니어링' 문제가 아니라, 정보 엔트로피 감소(entropy reduction) 과정으로 재해석한다는 데 있습니다.
인간(탄소 기반 지능)은 느리게 발전하지만, 기계(규소 기반 지능)는 빠르게 진화합니다. 이 격차가 벌어질수록, 기계를 위해 우리가 투자해야 하는 "노력"이 커집니다. 반대로 기계가 똑똑해질수록, 이 노력은 줄어듭니다.
2. 수학적 정의
논문은 Context Engineering을 엄밀하게 정의합니다:
정의 1 (엔티티와 특성화):
\[\text{Char}: E \to P(F)\]
모든 엔티티 \(e \in E\) (사용자, 앱, 환경 등)에 대해, \(\text{Char}(e)\)는 그 엔티티를 특성화하는 정보의 집합입니다.
정의 2 (문맥):
\[C = \bigcup_{e \in E_{rel}} \text{Char}(e)\]
특정 상호작용과 관련된 모든 엔티티의 특성화 정보를 통합한 것입니다.
정의 3 (Context Engineering):
\[\text{CE}: (C, T) \to f_{\text{context}}\]
원본 문맥 \(C\)와 목표 과제 \(T\)를 받아서, 최적화된 문맥 처리 함수 \(f_{\text{context}}\)를 생성합니다. 이는 수집, 저장, 관리, 활용의 네 단계를 포함합니다:
\[f_{\text{context}}(C) = F(\phi_1, \phi_2, \ldots, \phi_n)(C)\]
여기서 \(\phi_i\)는 필터링, 압축, 검색, 선택 등 다양한 작업을 나타냅니다.
3. 역사적 진화: 1.0 시대 (1990s-2020)
3.1.1 기술 배경
1991년 Mark Weiser는 '유비쿼터스 컴퓨팅'을 제시했습니다. 컴퓨터가 일상에 투명하게 녹아들면, 시스템은 사용자의 상태와 환경을 감지해 자동으로 적응해야 한다는 아이디어였죠.
이는 Context-Aware Computing 패러다임을 낳았습니다. 핵심 질문은:
- 문맥이란 정확히 무엇인가?
- 어떻게 정의하고 처리할 것인가?
- 기계가 어떻게 활용할 수 있을까?
당시 기술 한계는 심했습니다:
- 자연언어를 이해할 수 없음
- 오류 처리 능력이 거의 없음
- 미리 정의된 로직만 실행 가능
3.1.2 이론적 토대
2001년 Anind K. Dey의 정의가 나왔습니다:
"문맥이란 엔티티의 상황을 특성화하는데 사용될 수 있는 모든 정보다. 엔티티는 사용자, 장소, 또는 물체로서, 사용자와 애플리케이션의 상호작용과 관련성 있는 것이다."
이 정의는 오늘날까지 기초가 되었습니다. 특히 다차원성을 강조했습니다. 문맥은 단순한 데이터가 아니라, 사용자, 앱, 환경, 디바이스 등 다양한 요소의 통합이라는 뜻이죠.
3.1.3 핵심 실천
대표적인 구현물은 Context Toolkit입니다. 이는 다섯 가지 핵심 추상화를 제공했습니다:
- Context Widgets: 센서를 캡슐화하고 표준 인터페이스 제공
- Interpreters: 원시 데이터에서 고수준의 의미 도출
- Aggregators: 다양한 출처의 정보 통합
- Services: 애플리케이션이 문맥 기능에 접근
- Discoverers: 컴포넌트의 동적 등록과 발견
이는 **관심사의 분리(separation of concerns)**를 설계에 반영한 초기 사례입니다.
4. Era 2.0 (2020-현재): 에이전트 중심 지능
2020년 GPT-3 출시는 패러다임 전환을 가져왔습니다.
주요 변화
문맥 수집: 다중 모달(멀티모달) 센서의 확대
센서 기술이 진화하면서 다양한 신호를 동시에 수집할 수 있게 됐습니다:
- 개인 컴퓨팅: 텍스트, 이미지, 음성, 위치, 터치
- 신체 센서: 심박수, 피부 전기 반응, 안구 추적
- 환경: 차량 시스템, IoT 기기, 온라인 행동 추적
원시 문맥에 대한 관용성: 구조화된 입력에서 인간-고유 신호로
1.0 시대:
- GPS 좌표, 시간, 미리 정의된 상태만 가능
- 개발자가 사전에 "의미 있는" 정보를 정의해야 함
2.0 시대:
- 자유로운 텍스트, 이미지, 비디오 직접 입력 가능
- 파운데이션 모델의 다중 모달 지각 능력으로 구현
- 사전 처리 거의 불필요
문맥의 이해와 활용: 수동적 감지에서 능동적 협업으로
1.0 시대:
- 조건-행동 규칙 (if location=office, then silence phone)
- 환경만 감지, 의도는 미파악
2.0 시대:
- 사용자가 하는 "일"을 분석해서 협력
- 예: 논문 작성 중이면, 앞 문단 분석해서 다음 섹션 제안
- "Context-Aware"에서 "Context-Cooperative"로 진화
5. Context Collection & Storage (문맥 수집과 저장)
핵심 원칙
- 최소 충분성 원칙: 필요한 정보만 수집
- 의미 연속성 원칙: 데이터 연속성보다 의미 연속성 유지
Era 1.0 vs 2.0 비교
1.0: 단일 디바이스, 로컬 저장, 단순 로그 파일 2.0: 분산형 저장소 (캐시, 로컬 DB, 클라우드), 계층화된 아키텍처
예를 들어, Claude Code 시스템은:
- 단기: 메모리에 현재 대화 유지
- 중기: SQLite 같은 로컬 DB에 구조화된 노트 저장
- 장기: 클라우드 동기화
이를 통해 혼자서 2000+ 스텝의 Pokemon 게임을 계속 진행할 수 있습니다.
6. Context Management (문맥 관리)
이 섹션이 가장 풍부한데, 세 가지 핵심 기법을 다룹니다:
6.1 텍스트 문맥 처리
방법 1: 타임스탬프 마킹
- 장점: 시간 순서 보존, 구현 간단
- 단점: 의미 구조 없음, 선형 확장으로 인한 확장성 문제
방법 2: 기능적 태깅
- 각 항목에 태그 부여 (예: "goal", "decision", "action")
- 장점: 빠른 검색, 명확한 의미
- 단점: 경직되고 창의적 추론 제한
방법 3: QA 쌍 압축
- 질문-답변 형태로 변환
- 장점: 검색 효율성 증대
- 단점: 원래 흐름 손상, 통합적 이해 어려움
방법 4: 계층적 노트 (가장 추천)
- 트리 구조로 정보 조직
- 예: Claude Code가 사용
- 장점: 명확한 구조, 이해하기 쉬움
- 단점: 인과관계 미반영, 진화 과정 미기록
6.2 다중 모달 문맥 처리
세 가지 주요 전략:
-
공유 벡터 공간으로 매핑
- 각 모달리티를 독립적으로 인코딩
- 공유 임베딩 공간으로 투영
- 의미적으로 유사한 항목들이 가까워짐
-
Self-Attention을 통한 결합
- 트랜스포머에서 텍스트와 이미지 토큰이 상호 참조
- 세밀한 교차-모달 정렬 가능
- GPT-4V, Claude 3의 기본 기법
-
Cross-Attention
- 한 모달리티가 다른 모달리티에 "집중"
- 예: 텍스트가 이미지의 특정 영역에 포커스
- 유연하지만 고정된 모달리티 매핑 필요
6.3 계층화된 메모리 아키텍처
Karpathy의 통찰이 중요합니다:
- LLM = CPU
- Context Window = RAM (빠르지만 용량 제한)
- 외부 메모리 = 디스크
단기 메모리:
\[M_s = f_{\text{short}}(c \in C : w_{\text{temporal}}(c) > \theta_s)\]
최근 문맥, 높은 시간적 관련성.
장기 메모리:
\[M_l = f_{\text{long}}(c \in C : w_{\text{importance}}(c) > \theta_l \land w_{\text{temporal}}(c) \le \theta_s)\]
중요하지만 오래된 정보.
핵심: 정보는 시간 경과에 따라 단기 → 장기로 "숙성(baking)"됩니다.
6.4 Context Isolation (Subagent)
Claude Code의 혁신:
- 각 subagent는 독립적 context window 보유
- 자신의 커스텀 system prompt
- 제한된 tool permissions
- 메인 시스템 오염 방지
결과: 작은 전문가 여럿이 거대한 context window 하나보다 효과적.
6.5 Self-Baking (문맥의 자동 숙성)
Raw context가 계속 쌓이면 시스템이 마비됩니다. 따라서:
Raw Context → Abstraction → Knowledge
방법 1: 자연언어 요약
- 전체 기록 저장 + 정기적 요약 생성
- 간단하지만 구조 부족
방법 2: 고정 스키마로 핵심 추출
- Entity map: 객체와 관계를 노드-엣지 구조로
- Event records: 이벤트를 템플릿으로 구조화
- Task tree: 복잡한 목표를 계층적 구조로
- 예: CodeRabbit는 코드 리뷰 전 파일 간 의존성과 팀 규칙을 명시적 스키마로 인코딩
방법 3: 의미 벡터로의 점진적 압축 (가장 강력)
- 오래된 정보를 dense embedding으로 변환
- 여러 계층으로 요약 가능
- 컴팩트하고 유연
- 단점: 해석 불가능
7. Context Usage (문맥의 활용)
7.1 에이전트 간 문맥 공유
방법 1: 프롬프트 임베딩
- 이전 에이전트의 결과를 텍스트로 정리해서 다음 프롬프트에 포함
- 예: AutoGPT, ChatDev
- 간단하지만 정보 손실 가능
방법 2: 구조화된 메시지 교환
- 고정 스키마로 정보 전달
- 예: Letta, MemOS
- 명확하지만 경직됨
방법 3: 공유 메모리 간접 통신
- 중앙 저장소에 모든 에이전트가 읽고 씀
- "Blackboard" 패턴: 주제별 섹션으로 조직
- 비동기 협업 가능
7.2 시스템 간 문맥 공유 (Cross-System)
Cursor ↔ ChatGPT 같은 경우:
전략 1: 어댑터 사용
- 각 시스템이 자신의 포맷 유지
- 변환 로직은 별도 구성
- 자유롭지만 스케일링 어려움
전략 2: 공유 표현
- 모든 시스템이 동일한 포맷 동의
- JSON 스키마, 공유 API 정의
- 깔끔하지만 조율 필요
전략 3: 의미 벡터 표현
- 컴팩트하고 시스템 독립적
- 기계학습 필요, 해석 어려움
7.3 문맥 선택 (Context Selection for Understanding)
재밌는 발견: context window의 약 50% 정도 채웠을 때 AI 코딩 성능이 최고. 너무 많으면 잡음이 많아집니다.
선택 기준:
-
의미적 관련성 (Semantic Relevance)
- 벡터 유사도 기반 검색 (FAISS 등)
- RAG 파이프라인의 기본
-
논리적 의존성 (Logical Dependency)
- 현재 작업이 이전 결과에 직접 의존
- 의존성 그래프 구조화
- 예: MEM1 시스템
-
최근성과 빈도 (Recency & Frequency)
- 최근 사용한 정보 우선순위 높음
- 자주 참조되는 정보 중요도 증가
- 자동으로 "쇠락"시키는 메커니즘 필요
-
사용자 선호 (User Preference)
- 시간 경과에 따라 사용자 습관 학습
- 예: "이 사람은 시각적 요약을 선호"
7.4 능동적 필요 추론 (Proactive User Need Inference)
핵심 인사이트: 사용자는 자신의 필요를 완벽히 표현하지 못함
3가지 접근:
-
사용자 선호 학습
- 대화 기록 분석
- 개인 문서, 노트 분석
- 사용자의 대응 방식 관찰
- 진화하는 사용자 프로필 구축
-
숨겨진 목표 추론
- 질문 시퀀스 분석
- 예: Python decorator → performance tuning → 숨겨진 목표: "효율적 설계"
- Chain-of-Thought로 다단계 추론
-
능동적 도움 제시
- 사용자가 막혔다고 감지 (시행착오)
- 시각화, 체크리스트 등 도움 제시
7.5 평생 문맥 보존과 업데이트
이 섹션은 미래의 도전을 명확히 합니다:
Challenge I: Storage Bottleneck
- 제한된 자원으로 최대한 많은 문맥 보존?
- 고압축, 고정확 검색, 저지연성 동시 달성?
Challenge II: Processing Degradation
- Transformer의 \(O(n^2)\) 복잡도
- 어텐션이 길어질수록 "희미해짐"
- 검색 시스템이 잡음으로 묻힘
Challenge III: System Instability
- 메모리 누적 → 작은 오류가 큰 영향
- 검증 메커니즘 부족
Challenge IV: Evaluation Difficulty
- 시스템이 정말 올바로 추론하나?
- 모순 감지, 실행 추적 불가능
- "Black box" 심화
제안: Semantic Operating System
- 인간의 뇌처럼 성장하는 시스템
- 효율적 의미 저장소
- 인간 같은 기억 관리 (추가, 수정, 망각)
- Transformer를 넘어선 장거리 추론 능력
- 추적 가능한 설명 생성
8. 응용 사례
8.1 CLI (Gemini CLI)
구현의 핵심: GEMINI.md 파일
project-root/
├── GEMINI.md (프로젝트 전체)
├── src/
│ └── GEMINI.md (src 폴더용)
└── tests/
└── GEMINI.md (테스트용)
각 GEMINI.md는 포함:
- 프로젝트 배경
- 역할 정의
- 필요 도구와 의존성
- 코딩 규칙
수집: 정적 정보 (시작 시) + 동적 정보 (대화 중) 관리: 파일시스템이 가벼운 DB 역할 요약: 대화 기록을 정해진 포맷으로 자동 압축
8.2 Deep Research (깊은 연구 에이전트)
Tongyi DeepResearch의 순환 구조:
- 웹 검색 (사용자 쿼리 기반)
- 핵심 정보 추출
- 새로운 부분 질문 생성
- 증거 통합 (다중 소스)
문제: 상호작용 기록이 context window를 초과
해결: 주기적 "문맥 스냅샷" 압축
- 축적된 기록 → 콤팩트한 추론 상태
- 그 다음 검색과 추론은 이 요약 기반
결과: 제약 없는 장기 연구 능력
8.3 뇌-컴퓨터 인터페이스 (BCI)
EEG, 신체 센서로 직접 신호 수집:
- 주의력 수준
- 감정 상태
- 인지 부하
장점: 더 풍부한 문맥 수집, 명시적 행동 불필요 한계: 신호 노이즈, 해석 어려움
9. 해결되지 않은 도전과제
-
문맥 수집의 한계
- 대부분의 시스템은 여전히 명시적 사용자 입력에 의존
- BCI 같은 자연스러운 수집 방법 필요
-
대규모 문맥 관리의 어려움
- 정보 빠르게 증가
- 효율적 저장과 검색의 트레이드오프
-
기계의 제한된 이해
- 인간은 직관적으로 이해하는 것을 기계는 못함
- 논리, 이미지 내 관계 이해 약함
- 기계 지능 향상 필수
-
긴 문맥 처리의 병목
- Mamba 같은 선형 아키텍처도 부족
- Transformer 이상의 새 아키텍처 필요
-
관련 문맥 선택의 부정확
- 유용한 신호 놓침
- 잡음 정보 남음
- 적응형 필터링 연구 필요
10. 결론
논문의 마지막 통찰은 흥미롭습니다:
"마르크스는 '인간의 본질은 사회적 관계의 총합'이라 했다. 문맥 중심의 AI 시대, 이는 새로운 의미를 갖는다. 사람들은 더 이상 물리적 존재로 정의되지 않고, 그들이 생성하는 디지털 문맥 — 대화, 결정, 상호작용의 흔적 — 으로 정의된다."
이 문맥들은 그 사람이 떠난 후에도 AI 시스템을 통해 지속되고 상호작용할 수 있습니다. "인간의 마음이 업로드될 수는 없지만, 인간의 문맥은 업로드될 수 있습니다."
핵심 수치와 발견
- 20년 이상의 역사: Context Engineering은 1990년대부터 시작
- 4단계 진화: 1.0 (원시), 2.0 (에이전트), 3.0 (인간 수준), 4.0 (초인)
- 성능 최고점: Context window의 약 50% 채웠을 때
- 도구 한계: 30개 이상의 도구 → 성능 급격히 감소 (DeepSeek-v3 기준)
- 관계 구조: 의존성 그래프, 의미 그래프, 작업 그래프 등 다양한 표현
과학자에게 도움이 될 핵심 포인트
- 정의의 중요성: Context Engineering을 수학적으로 엄밀히 정의하면 다양한 도메인에 적용 가능
- 계층 구조의 가치: 단기/장기 메모리 분리가 확장성의 핵심
- 다중 모달 통합: 의미 벡터 공간은 교차-모달 추론의 게이트웨이
- 능동적 추론: 사용자 의도 추론은 수동적 문맥 관리를 넘어서는 다음 단계
- 평생 학습의 길: "Semantic Operating System"은 진정한 AGI를 향한 청사진