Training-Free Group Relative Policy Optimization
Y. Cai, S. Cai, Y. Shi, Z. Xu, L. Chen, Y. Qin, X. Tan, G. Li, Z. Li, H. Lin, Y. Mao, K. Li and X. Sun, "Training-Free Group Relative Policy Optimization", arXiv preprint arXiv:2510.08191, 2025.
강화학습을 통해 대형 언어 모델(LLM)의 성능을 향상시키려면 일반적으로 막대한 계산 비용과 데이터가 필요합니다. 특히 GRPO(Group Relative Policy Optimization)와 같은 방법은 모델 파라미터를 직접 업데이트하면서 뛰어난 성능을 보여주지만, 수만 달러의 학습 비용과 과적합 문제를 야기합니다. 본 논문은 이러한 한계를 극복하기 위해 파라미터 업데이트 없이 경험적 지식만으로 정책을 최적화하는 Training-Free GRPO를 제안합니다.
요약
핵심 아이디어: 기존 GRPO가 그래디언트 업데이트를 통해 파라미터 공간에서 정책을 최적화하는 반면, Training-Free GRPO는 맥락 공간(context space)에서 정책을 최적화합니다. 즉, 모델 파라미터는 동결한 채로 경험적 지식(experiential knowledge)을 토큰 사전 정보(token prior)로 활용하여 출력 분포를 조정합니다.
주요 구성 요소:
- 롤아웃 및 보상: 각 쿼리에 대해 G개의 출력을 생성하고 보상 모델로 평가합니다
- 의미론적 그룹 어드밴티지: 수치적 어드밴티지 대신 LLM이 직접 롤아웃들을 분석하여 자연어 형태의 경험을 추출합니다
- 경험 라이브러리 업데이트: 추출된 경험을 기반으로 Add/Delete/Modify 작업을 통해 경험 라이브러리 \(E\)를 최적화합니다
실험 결과:
- 데이터셋: AIME 2024/2025 (수학 추론), WebWalkerQA (웹 검색)
- 모델: DeepSeek-V3.1-Terminus (671B 파라미터)
- 학습 데이터: 단 100개 샘플
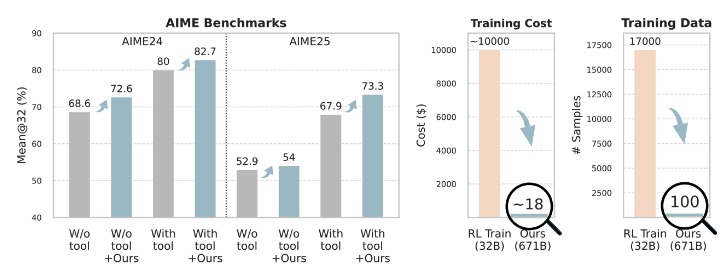
- 성능: AIME24에서 82.7%, AIME25에서 73.3% 달성 (베이스라인 대비 각각 +2.7%, +5.4%)
- 비용: 약 \(18로 fine-tuning된 32B 모델(약\)10,000 소요)을 능가
주요 평가 지표:
- Mean@32: 각 문제를 32번 독립적으로 실행하여 평균 Pass@1 점수 측정
- 수학 추론 태스크에서는 코드 인터프리터(CI) 도구 사용
- 웹 검색 태스크에서는 Pass@1 및 Pass@3 측정
논문 상세
Introduction
LLM 에이전트는 복잡한 실세계 환경에서 뛰어난 범용 능력을 보여주지만, 특화된 도메인에서는 종종 성능이 저하됩니다. 기존의 에이전트 강화학습(Agentic RL) 방법들은 GRPO를 사용하여 파라미터 공간에서 모델 행동을 정렬하지만, 다음과 같은 실용적 문제가 있습니다:
- 계산 비용: 작은 모델도 fine-tuning에 상당한 자원이 필요하며, 큰 모델은 비용이 매우 높습니다
- 일반화 성능 저하: 파라미터 튜닝된 모델은 도메인 간 일반화가 불충분하여 여러 특화 모델을 배포해야 합니다
- 데이터 부족: 특화 도메인에서는 고품질 레이블 데이터가 희소하며, 적은 샘플로는 과적합이 쉽게 발생합니다
- 수익 감소: 자원 제약으로 인해 32B 이하 모델을 fine-tuning하지만, API 기반 대형 모델이 비용 대비 성능이 더 우수한 경우가 많습니다
저자들은 "RL을 파라미터 공간에서 적용하는 것만이 유일한 방법인가?"라는 질문을 던지며, Training-Free GRPO를 통해 이에 긍정적으로 답합니다.
Method: Training-Free GRPO
Vanilla GRPO와의 비교:
기존 GRPO는 다음과 같이 동작합니다:
- 정책 \(\pi_\theta\)로 G개 출력 생성: \({o_1, o_2, \ldots, o_G}\)
- 보상 모델로 각 출력 점수화: \(r_i = R(q, o_i)\)
- 그룹 상대 어드밴티지 계산: \(\hat{A}_i = \frac{r_i - \text{mean}(r)}{\text{std}(r)}\)
- PPO 목적 함수 \(J_{\text{GRPO}}(\theta)\) 최대화하여 파라미터 \(\theta\) 업데이트
Training-Free GRPO는 이 로직을 비파라메트릭 추론 시간 프로세스로 변환합니다:
1단계: 롤아웃 및 보상
- 경험 \(E\)를 조건으로 하는 정책 \(\pi_\theta(o_i|q, E)\)로 G개 출력 생성
- 기존과 동일하게 보상 모델로 평가: \(r_i = R(q, o_i)\)
2단계: 그룹 어드밴티지 계산
- 수치적 어드밴티지 대신 의미론적 어드밴티지 생성
- 각 출력에 대해 요약 생성: \(s_i = M(p_{\text{summary}}, q, o_i)\)
- 경험 추출: \(A_{\text{text}} = M(p_{\text{extract}}, q, s_i, E)\)
- \(\text{std}(r) = 0\)인 경우(모든 출력이 동일한 보상)는 건너뜀
3단계: 최적화
- 모든 의미론적 어드밴티지 \(A_{\text{text}}\)를 기반으로 경험 라이브러리 \(E\) 업데이트
- 업데이트 작업: Add(추가), Delete(삭제), Modify(수정), Keep(유지)
- 업데이트된 \(E\)는 다음 배치에서 정책 \(\pi_\theta(y|q, E)\)의 출력 분포를 변경
이 접근 방식은 맥락을 변경하여 GRPO의 정책 업데이트와 유사한 효과를 달성하며, 동결된 기본 모델 \(\pi_\theta\)는 강력한 사전 정보로 작용하여 출력 일관성을 보장합니다.
Mathematical Reasoning Experiments
벤치마크 및 설정:
- AIME 2024와 2025 벤치마크 사용
- DeepSeek-V3.1-Terminus 사용 (Direct 프롬프팅과 ReAct 모드)
- DAPO-Math-17K에서 랜덤 샘플링한 100개 문제로 학습 (DAPO-100)
- 3 에폭, 배치당 1회, temperature 0.7, 그룹 크기 5
주요 결과:
- ReAct + Training-Free GRPO: AIME24 82.7%, AIME25 73.3%
- 베이스라인 ReAct: AIME24 80.0%, AIME25 67.9%
- ReTool (32B, RL 학습): AIME24 67.0%, AIME25 49.3%
- AFM (32B, RL 학습): AIME24 66.7%, AIME25 59.8%
DeepSeek-V3.1-Terminus에 적용된 Training-Free GRPO는 100개의 out-of-domain 샘플과 제로 그래디언트 업데이트만으로 수천 개의 샘플과 $10,000 이상의 비용이 드는 32B RL 모델들을 능가했습니다.
학습 동역학:
- 학습 과정에서 Mean@5가 꾸준히 향상
- AIME24와 AIME25의 Mean@32도 각 단계마다 개선
- 평균 도구 호출 횟수가 감소하여 효율적인 도구 사용 학습 확인
Ablation Study:
- 직접 생성된 경험 추가: 성능 향상 없음 (AIME24 79.8%)
- Ground truth 없이 학습: AIME24 80.7%, AIME25 68.9% (베이스라인보다 개선되지만 기본 버전보다는 낮음)
- 그룹 계산 제거 (그룹 크기 1): AIME24 80.4%, AIME25 69.3% (그룹 상대 계산의 필요성 입증)
작은 모델 적용성:
- Qwen3-32B: AIME24 33.5% (+4.4%), AIME25 14.9% (+1.4%)
- Qwen2.5-72B-Instruct: AIME24 25.4% (+5.9%), AIME25 11.4% (+1.8%)
- 학습 비용: $3-4 수준으로 매우 경제적
Web Searching Experiments
데이터셋 및 설정:
- 학습: AFM 데이터셋에서 100개 쿼리 샘플링 (AFM-100)
- 평가: WebWalkerQA 벤치마크
- 3 에폭, 그룹 크기 3
주요 결과:
- Training-Free GRPO: 67.8% Pass@1 (베이스라인 63.2% 대비 +4.6%)
-
51개 샘플 부분집합 ablation 결과:
- 직접 생성 경험: 64.7% (오히려 하락)
- Ground truth 없이: Pass@1 66.7%, Pass@3 78.4%
- 전체 Training-Free GRPO: Pass@1 68.6%, Pass@3 78.4%
모델 능력 의존성:
- QwQ-32B 적용 시: 25.5% Pass@1 (베이스라인 27.5%보다 하락)
- 복잡한 도구 사용 시나리오에서는 기본 모델의 추론 및 도구 사용 능력이 전제조건임을 시사
Cross-Domain Transfer Analysis
파라미터 기반 방법의 주요 약점은 도메인 특화로 인한 일반화 능력 손실입니다:
- ReTool (수학 특화): AIME24 67.0%, AIME25 49.3%이지만 WebWalker에서 18.3%로 급감
- MiroThinker (웹 특화): WebWalker 53.6%이지만 AIME24 43.5%, AIME25 36.8%로 낮음
반면 Training-Free GRPO는 도메인별 경험을 플러그인하는 것만으로 모든 도메인에서 최고 성능 달성:
- 수학 도메인: AIME24 82.7%, AIME25 73.3%
- 웹 도메인: WebWalker 67.8%
이는 실세계에서 다양한 요구사항을 가진 환경에 에이전트를 배포할 때 매우 유용합니다.
Computational Cost Analysis
학습 비용:
- ReTool (32B): 약 20,000 GPU 시간, $10,000
- Training-Free GRPO: 6시간, 38M 입력 토큰, 6.6M 출력 토큰, 약 $18
- 2차수 이상의 비용 절감
추론 비용:
- ReTool-32B 배포: 4 × GPU (\(0.5/시간), 문제당\)0.005이지만 고정 인프라 비용 필요
- Training-Free GRPO: 문제당 약 $0.02 (60K 입력, 8K 출력 토큰)
- 불규칙하거나 낮은 트래픽 서비스에서는 고정 GPU 클러스터 유지가 비경제적
- Pay-as-you-go 모델로 실제 사용량에 따라 비용 지불
Related Work
LLM Agents: ReAct, Toolformer, MetaGPT, CodeAct, OWL 등 도구 통합 및 계획 프레임워크
Reinforcement Learning: PPO, GRPO, GiGPO, ReTool, Chain-of-Agents 등 파라미터 업데이트 기반 방법들
Training-Free Methods:
- In-context learning (ICL)
- Self-Refine, Reflexion: 반복적 개선
- ICRL: 스칼라 보상 신호로 학습
- TextGrad: 텍스트 피드백을 계산 그래프로 역전파
- Agent KB: 계층적 지식 베이스 구축
Training-Free GRPO는 기존 방법들과 달리 전통적 RL과 유사하게 별도 데이터셋에서 여러 에폭에 걸쳐 학습하며, 단일 궤적이 아닌 그룹 내 여러 롤아웃을 비교하여 의미론적 어드밴티지를 추출합니다.
Conclusion
Training-Free GRPO는 RL 정책 최적화를 파라미터 공간에서 맥락 공간으로 전환하는 새로운 패러다임을 제시합니다. 그룹 기반 롤아웃을 활용하여 의미론적 어드밴티지를 반복적으로 추출하고 이를 진화하는 경험적 지식으로 통합함으로써, 동결된 LLM 에이전트의 출력 분포를 성공적으로 조정하고 특화 도메인에서 상당한 성능 향상을 달성합니다. 실험 결과는 Training-Free GRPO가 데이터 부족과 높은 계산 비용이라는 실용적 문제를 극복할 뿐만 아니라 기존 파라미터 튜닝 방법을 능가함을 보여줍니다.