Exploring Conditions for Diffusion Models in Robotic Control
Shin et al., "Exploring Conditions for Diffusion Models in Robotic Control", arXiv:2510.15510, 2025
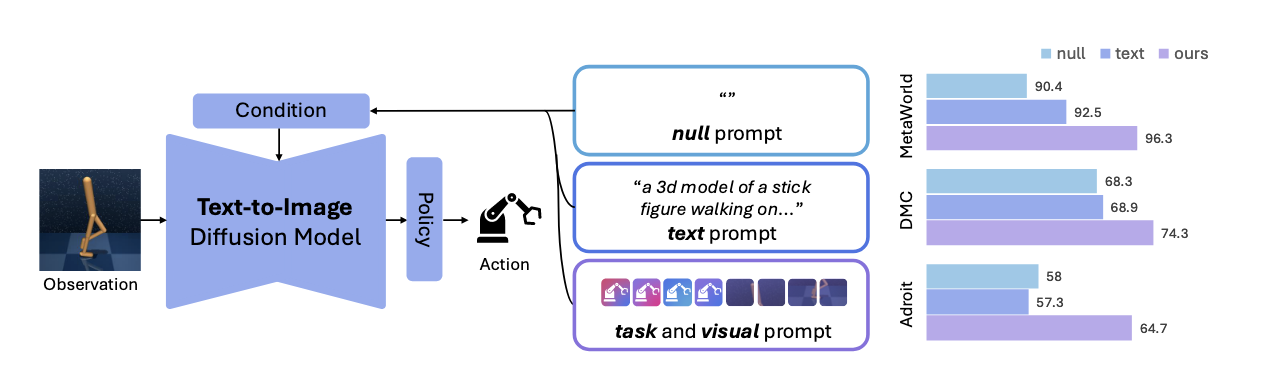
최근 대규모 데이터로 학습한 사전학습 시각 표현(pretrained visual representations)이 로봇 모방 학습에 혁신을 가져왔습니다. 하지만 이 접근법에는 고질적인 문제가 있습니다. 대부분의 방법이 학습된 표현을 "냉동 상태"로 유지합니다. 각 작업에 맞게 표현을 적응시킬 수 없다는 뜻입니다. 이미지 생성에 대성공한 확산 모델의 조건화(conditioning) 기법을 로봇 제어에 적용하면 어떻게 될까요?
이 논문은 흥미로운 발견을 제시합니다. 텍스트 조건은 의미론적 분할(semantic segmentation) 같은 다른 시각 작업에서는 효과적이지만, 로봇 제어에서는 오히려 성능을 해치기도 한다는 것이죠. 대신 저자들은 ORCA(task prompts와 visual prompts를 학습하는 접근법)를 제안하여, 로봇 제어의 고유한 특성을 반영한 조건화 방식으로 새로운 성능 수준을 달성했습니다.
요약
ORCA는 Stable Diffusion의 중간 특성을 추출하여 로봇 제어를 위한 적응형 표현을 생성합니다. 핵심은 학습 가능한 작업 프롬프트(task prompt, 4개 토큰)와 시각 프롬프트(visual prompt, 16개 토큰)를 도입하는 것입니다. 작업 프롬프트는 작업 환경에 적응하는 암시적 단어로 학습되고, 시각 프롬프트는 DINOv2 비전 인코더의 밀집 표현을 활용하여 프레임별 세밀한 세부사항을 포착합니다.
기술 스펙:
- 모델: Stable Diffusion v1.5 (Latent Diffusion Model)
- 비전 인코더: DINOv2
- 데이터셋: DeepMind Control (DMC), MetaWorld, Adroit
- 평가: 행동 복제(behavior cloning) 목표로 종단 간 학습
- 성능: 12개 작업 평균 74.3 (기존 SOTA 대비 상당한 개선)
논문 상세
왜 냉동된 표현으로는 부족한가
지난 몇 년간 MoCo나 CLIP 같은 자기지도 학습 모델로부터 추출한 표현들이 로봇 제어에 효과적임이 증명되었습니다. R3M, MVP, VC-1 같은 방법들은 대규모 데이터로 사전학습된 인코더를 사용하되, 정책 학습 중 인코더를 냉동 상태로 유지했죠.
문제는 이 접근법이 본질적으로 작업 불변(task-agnostic)이라는 것입니다. 어떤 표현이 특정 작업에 가장 적합한지 미리 알 수 없기 때문에, 작업마다 수동으로 어떤 표현을 사용할지 결정해야 하고, 이는 매우 번거롭습니다. 인코더를 미세조정(fine-tune)하는 것도 해결책이 아닙니다. 제한된 모방 학습 데이터로 미세조정하면 오버피팅으로 인해 일반화 성능이 급락하기 때문입니다.
텍스트 조건의 한계 발견
저자들은 먼저 텍스트 프롬프트로 확산 모델을 조건화하는 방법을 시도해봅니다. Gemini 2.5 같은 최신 시각-언어 모델로 생성한 작업 설명을 조건으로 사용한 것이죠.
결과는 놀라웠습니다. 일부 작업(Button-press, Reacher)에서는 도움이 되었지만, 다른 작업(Cheetah-run)에서는 오히려 성능을 떨어뜨렸습니다.
교차 주의(cross-attention) 맵을 분석해보니 원인이 명확했어요. 효과적인 텍스트 조건 작업에서는 "button"이나 "press" 같은 단어들이 이미지의 관련 영역에 잘 대응되었습니다. 하지만 Cheetah-run 같은 경우, "cheetah"나 "run" 같은 단어의 주의 맵이 매우 잡음이 많았습니다.
이 차이가 생기는 이유는 도메인 갭입니다. 확산 모델은 웹에서 수집한 실사 이미지로 학습되었는데, 로봇 제어 환경은 시뮬레이션된 세계이고, 로봇 에이전트는 웹의 일반적인 이미지에서 등장하지 않는 특수한 대상입니다.
로봇 제어 작업의 독특성
이 발견은 다음을 시사합니다. 의미론적 분할 같은 작업과 달리 로봇 제어는 비디오 스트림에 작동한다는 것입니다. 정적 이미지에서 물체를 분류하는 것과 달리, 로봇이 걸어가는 장면을 이해하려면 프레임마다 다른 조건이 필요합니다.
예를 들어 로봇이 걷는 작업을 생각해봅시다. "왼발 움직여, 그 다음 오른발 움직여" 같은 시간에 따라 변하는 명령이 필요합니다. 프레임별로 고품질의 텍스트 설명을 생성한다면? 이는 두 가지 문제를 안고 있어요:
- 기술적 난제: 매 프레임마다 정확한 설명을 자동으로 생성하기 어렵습니다.
- 근본적 문제: 텍스트 자체의 그라운딩 오류가 반복됩니다.
따라서 저자들은 다른 접근을 제시합니다. 조건은 시각 정보를 포함해야 한다는 것입니다.
ORCA: 작업 프롬프트와 시각 프롬프트
이 아이디어로부터 ORCA가 탄생합니다.
작업 프롬프트(Task Prompt): 텍스트 조건에서 효과가 있었던 경우를 보면, 작업과 관련된 영역들이 잘 표현되어 있었습니다. 그래서 작업 프롬프트는 학습 가능한 매개변수로서, 모든 관찰(observation)에서 공유되도록 설계했습니다. 훈련 중에 정책 학습을 하면서 이 프롬프트들이 작업 관련 영역에 자동으로 초점을 맞추도록 학습됩니다.
\[p_t = \text{Learnable task tokens (4개)}\]
시각 프롬프트(Visual Prompt): 프레임별 세밀한 세부사항을 포착하기 위해 DINOv2 비전 인코더의 밀집 표현을 활용합니다. 전역 표현이 아닌 픽셀 수준의 정보를 유지하면서 작은 컨볼루션 층으로 투영합니다.
\[p_v = \text{Vision encoder 특성} \rightarrow \text{Conv layer 투영}\]
두 프롬프트는 텍스트 인코더 \(\tau_\theta\)를 통해 조합되고, 이는 Stable Diffusion의 교차 주의 메커니즘에 주입됩니다.
훈련: 행동 복제 손실(behavior cloning loss)로 정책 네트워크와 두 프롬프트를 함께 학습합니다:
\[L_{BC}(\phi, p) = \sum_{i=1}^{N} \sum_{o} |\pi_\phi(\epsilon_\theta(z_t, t; C^*)) - a_o^i|\]
여기서 \(C^* = \tau_\theta(p_t; p_v)\)는 두 프롬프트로부터 만들어집니다.
시험 결과: 작은 개선이 아닌 근본적인 변화
저자들은 세 가지 표준 벤치마크에서 평가합니다:
DeepMind Control Suite (DMC): 연속 제어 작업 5개
- 평균 점수: 74.3 (VC-1: 53.1, SCR: 68.3)
- Walker-walk에서 특히 두드러짐 (76.9 vs 54.3)
MetaWorld: 조작 작업 5개
- 평균 성공률: 95.2% (VC-1: 84.2%, TADP: 93.1%)
- Button-press에서 88.0% (이전 방법 80% 대)
Adroit: 손재주 조작 2개 작업
- 평균 성공률: 65.3% (VC-1: 47.3%, SCR: 58.0%)
모든 작업에서 기존 최신 기법들을 능가합니다.
교차 주의 맵으로 본 메커니즘
Relocate 작업을 예로 들면, 로봇 손이 파란 공을 집어서 녹색 구 위치로 옮기는 작업이죠.
- 작업 프롬프트: 전체 목표인 로봇 손과 녹색 구 목표에 일관되게 초점을 맞춤
- 시각 프롬프트 1: 움직임에 따라 역동적으로 변함 (테이블 위에서 공을 집을 땐 테이블에 집중, 들어올린 후는 손에 집중)
- 시각 프롬프트 2: 앞다리와 뒷다리 구별 같은 세부 사항을 포착
이는 작업 프롬프트가 "큰 그림"을 담당하고, 시각 프롬프트들이 "세밀한 움직임"을 담당한다는 설계의 우아함을 보여줍니다.
소거 연구(Ablation Study)
각 요소의 기여도를 측정한 결과:
- 시각 프롬프트만 사용: 평균 69.8 (기본 SCR: 68.3)
- 작업 프롬프트만 사용: 평균 70.5
- 둘 다 사용: 평균 74.3
개별적으로도 도움이 되지만, 조합하면 시너지가 일어납니다. 특히 Cheetah-run 같은 동적 작업에서 시각 프롬프트의 기여가 두드러집니다 (+13.3점).
또한 U-Net의 어느 층을 사용할지 테스트했을 때, 초기 다운샘플링 블록과 중간 병목(bottleneck) 층의 조합이 최적이었습니다. 이는 이미지의 구조적 특성이 보존되면서도 요약된 표현을 사용하는 것이 유리함을 시사합니다.
효율성 검토
논문이 놓치지 않은 점은 실용성입니다:
- 총 매개변수: 480.1M (VC-1: 303.3M)
- 학습 가능한 매개변수: 10.6M
- 지연시간: 48ms
학습 가능 매개변수는 매우 적고(1%), 지연시간도 허용 범위 내입니다. 의향이 있는 사람이라면 이 방법을 실제 시스템에 배포할 수 있다는 뜻입니다.
추가 질문
왜 널 조건(<eos> 토큰만)도 어느 정도 작동하나요?
분석해보니 <eos> 토큰이 우연히 현저한 물체(보통 에이전트)에 집중되는 경향이 있습니다. 반면 <bos> 토큰은 배경에 집중되는데, 이는 텍스트 프롬프트의 일반적인 구조 때문입니다.
다른 확산 모델 timestep은 어떻게 되나요?
t=0 (명확한 이미지)이 최적이며, t=100이나 t=200 (더 노이즈가 많은)을 사용하면 작업에 따라 성능이 크게 떨어집니다. 이는 로봇 제어에는 명확한 시각 정보가 필수임을 시사합니다.
결론
이 논문은 어떻게 하면 사전학습 모델을 더 잘 재사용할까라는 질문에 제법 명확한 답을 제시합니다. 단순히 큰 모델을 가져다 쓰는 것이 아니라, 작업의 특성을 이해하고 그에 맞는 조건화가 중요하다고 이야기합니다.
ORCA는 두 가지를 보여줍니다. 첫째, 로봇 제어 같은 동적 작업에서는 프레임별로 적응하는 시각 정보가 고정된 텍스트보다 중요합니다. 둘째, 학습 가능한 프롬프트는 비용이 거의 없으면서도 강력한 수단입니다.
앞으로 이 접근법은 더 많은 도메인으로 확장될 가능성이 높습니다. 자율주행, 의료 영상 분석, 또는 다른 동적 시나리오에서도 유사한 원리가 작동할 수 있을까요?