MCPMark A Benchmark for Stress-Testing Realistic and Comprehensive MCP Use
Z. Wu, X. Liu, X. Zhang, L. Chen, F. Meng, L. Du, Y. Zhao, F. Zhang, Y. Ye, J. Wang, Z. Wang, J. Ni, Y. Yang, A. Xu, and M. Q. Shieh, "MCPMark: A Benchmark for Stress-Testing Realistic and Comprehensive MCP Use", arXiv preprint arXiv:2509.24002, 2025.
MCP(Model Context Protocol)는 LLM이 외부 시스템과 상호작용하는 방식을 표준화한 프로토콜입니다. 하지만 기존 MCP 벤치마크들은 단순한 읽기 작업이나 얕은 상호작용에 집중되어 있어, 실제 업무 환경의 복잡성을 제대로 평가하지 못하고 있습니다. MCPMark는 이러한 한계를 극복하기 위해 제안된 벤치마크로, 실제 업무 시나리오를 반영한 127개의 고품질 태스크를 통해 LLM의 MCP 활용 능력을 종합적으로 평가합니다.
요약
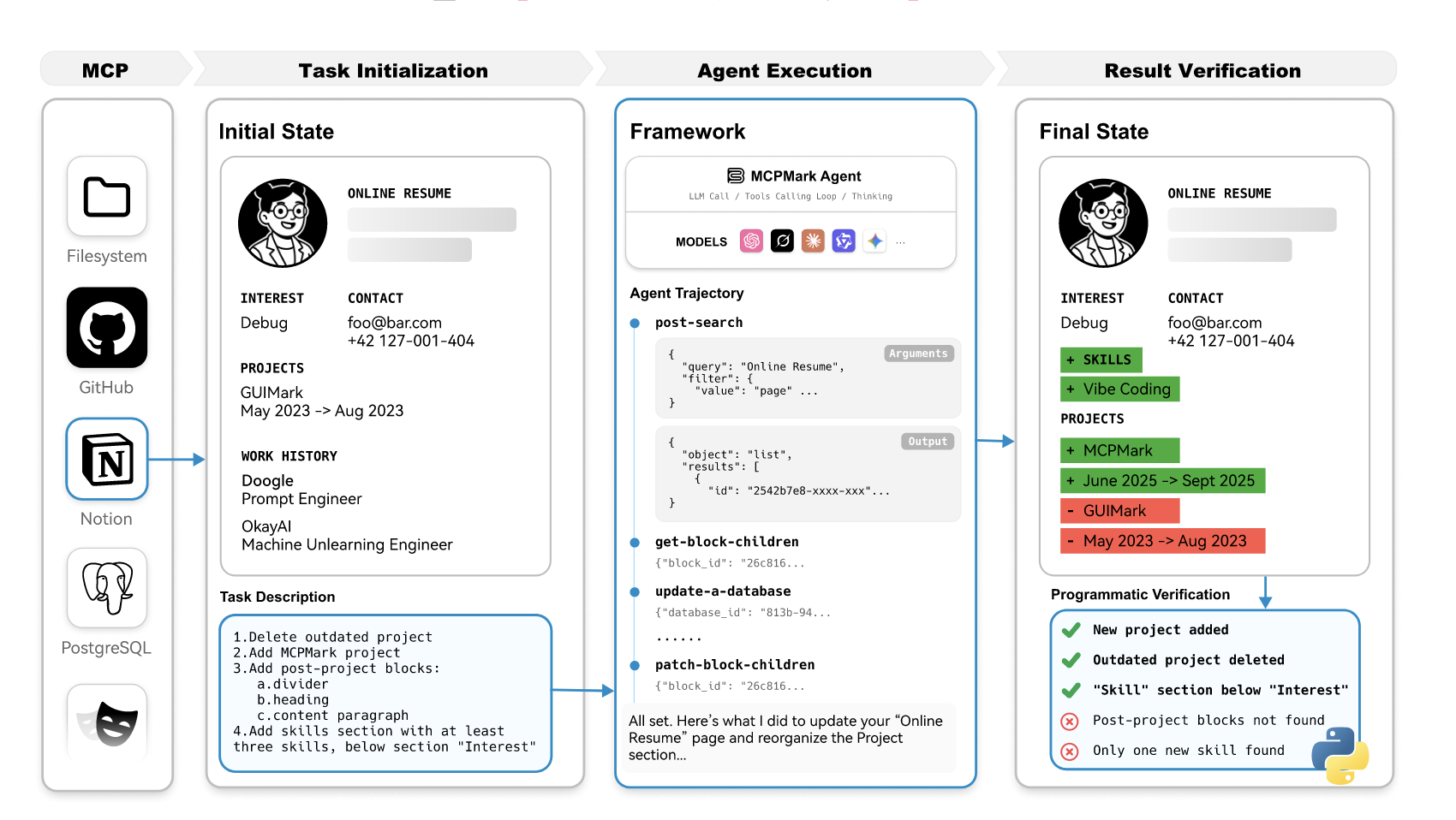
아키텍처: MCPMark는 5개의 MCP 서버(Notion, GitHub, Filesystem, PostgreSQL, Playwright)를 기반으로 구축되었으며, 각 태스크는 초기 상태, 태스크 지시사항, 프로그래밍 방식의 검증 스크립트로 구성됩니다.
데이터셋: 127개의 태스크가 38개의 초기 상태를 기반으로 생성되었습니다. Filesystem 30개, Notion 28개, Playwright 25개, GitHub 23개, PostgreSQL 21개로 구성되며, 각 태스크는 도메인 전문가와 AI 에이전트가 협업하여 제작했습니다.
평가 방법: MCPMark-Agent라는 경량 프레임워크를 사용하여 모델을 평가합니다. LiteLLM과 MCP Python SDK를 결합하여 다양한 모델을 일관되게 테스트할 수 있습니다.
평가 메트릭: pass@1(단일 시도 성공률), pass@4(4회 시도 중 1회 이상 성공), pass^4(4회 시도 모두 성공)를 사용합니다. pass^4는 모델의 일관성과 안정성을 측정하는 엄격한 지표입니다.
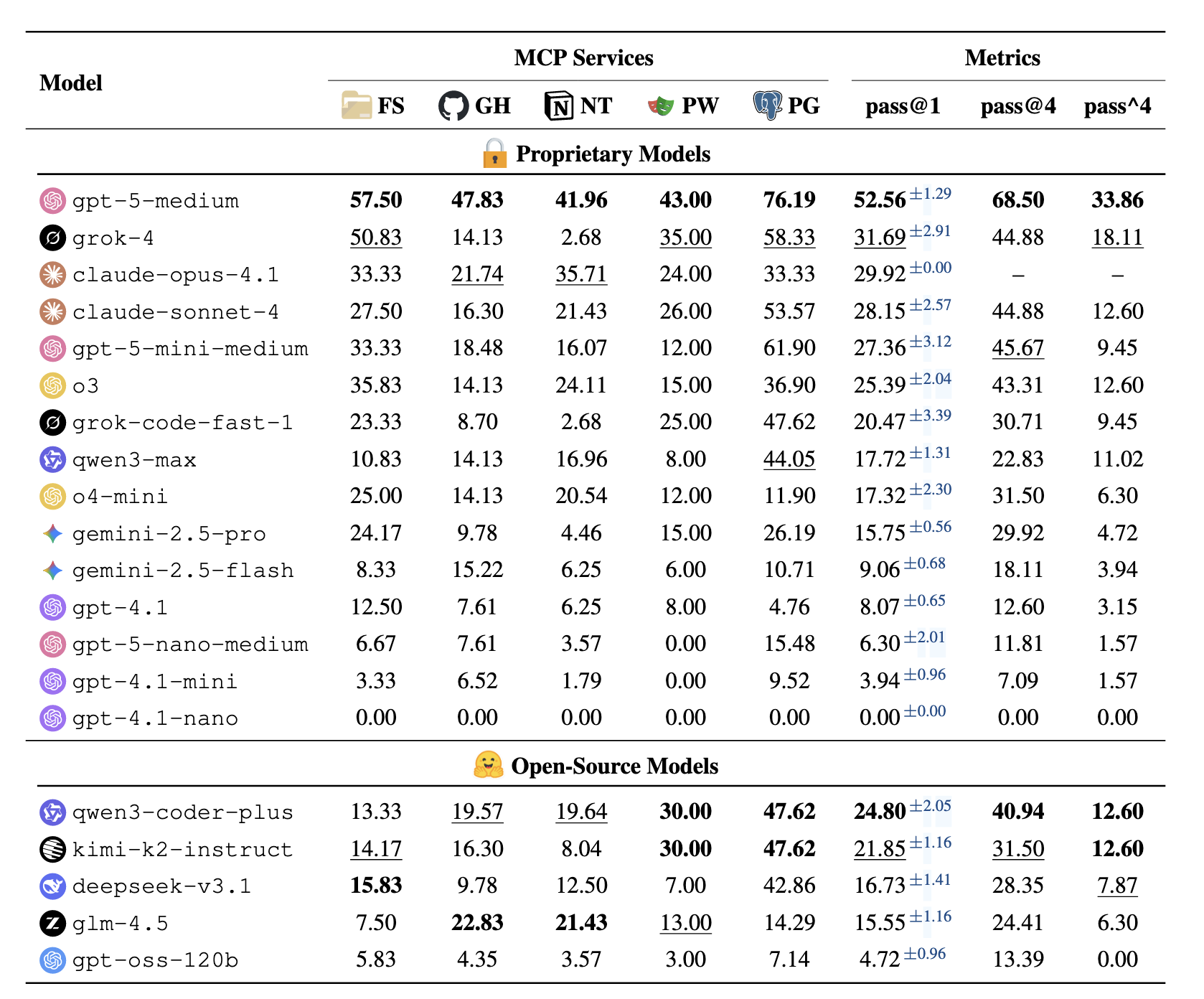
주요 결과: 최고 성능 모델인 gpt-5-medium도 52.56% pass@1, 33.86% pass^4에 그쳤습니다. Claude Sonnet 4와 o3는 각각 28.15%, 25.39% pass@1로 30% 미만의 성능을 보였습니다. 평균적으로 태스크당 16.2회의 실행 턴과 17.4회의 도구 호출이 필요했습니다.
논문 상세
Introduction
MCP는 LLM과 외부 시스템(도구, API, 데이터베이스 등)을 연결하는 표준화된 인터페이스입니다. 이를 통해 AI 에이전트가 실제 환경에서 "눈과 손"을 가지고 작동할 수 있게 됩니다. 하지만 기존 벤치마크들은 다음과 같은 한계가 있습니다.
- 대부분 읽기 위주 작업에 집중
- 제한적인 상호작용 깊이
- 실제 업무의 복잡한 다단계 워크플로우를 포착하지 못함
MCPMark는 이러한 문제를 해결하기 위해 다음을 제공합니다.
- 현실적인 초기 상태: 실제 사용 시나리오를 반영한 초기 환경
- 다양한 CRUD 작업: Create, Read, Update, Delete 작업의 균형 잡힌 커버리지
- 프로그래밍 방식 검증: 자동화된 검증 스크립트를 통한 신뢰할 수 있는 평가
MCPMark 벤치마크 구조
MCP 서비스와 초기 상태
MCPMark는 5개의 대표적인 MCP 환경을 통합합니다.
Notion: 공식 원격 API를 통해 문서와 데이터베이스를 생성, 편집, 쿼리합니다. 초기 상태는 널리 사용되는 템플릿에서 가져옵니다.
GitHub: 공식 원격 API로 프로젝트 관리 및 Git 작업을 지원합니다. CI/CD, 이슈, 브랜치, PR, 커밋 등을 다룹니다. 초기 상태는 실제 개발 히스토리와 설정이 있는 저장소입니다.
Filesystem: 파일 I/O, 디렉토리 구성, 메타데이터 검사, 검색을 지원합니다. 초기 상태는 일상적인 사용자 시나리오를 반영한 폴더 구조입니다.
PostgreSQL: 관계형 데이터베이스에 접근하며 스키마 탐색과 SQL 쿼리 실행을 제공합니다. 초기 상태는 현실적인 스키마를 가진 템플릿 데이터베이스입니다.
Playwright: 브라우저 자동화 도구로 탐색, 폼 작성, 데이터 추출 등을 수행합니다. 초기 상태는 자체 제작 웹페이지나 WebArena에서 가져온 localhost 페이지입니다.
태스크 생성 파이프라인
각 태스크는 인간 전문가와 두 개의 AI 에이전트(태스크 생성 에이전트, 태스크 실행 에이전트)가 협업하여 만들어집니다. 파이프라인은 4단계로 구성됩니다.
1. 탐색(Exploration): 전문가와 에이전트가 함께 초기 환경 상태를 탐색하며 시드 질문이나 주제를 기반으로 맥락을 수집합니다.
2. 발전(Evolvement): 에이전트가 새로운 태스크를 제안하거나 기존 태스크를 개선합니다. 불필요한 지시사항을 제거하고, 정보 탐색 난이도를 높이고, 더 많은 상호작용 단계를 요구하도록 합니다.
3. 검증(Verification): 에이전트가 검증 스크립트 초안을 작성하고, 전문가가 태스크 실행 에이전트의 도움을 받아 태스크를 완료합니다. 검증 스크립트는 태스크 지시사항과 완전히 일치할 때까지 반복적으로 개선됩니다.
4. 반복(Iteration): 2~3단계를 반복하여 태스크 난이도를 점진적으로 높이면서도 자동 검증 가능성과 현실성을 유지합니다.
전문가 한 명당 태스크 하나를 만드는 데 3~5시간이 소요되었습니다. 10명의 다양한 배경을 가진 전문가(컴퓨터 과학 박사과정, 프론트엔드 디자이너, 풀스택 엔지니어, AI 투자자 등)가 참여했습니다.
품질 관리
모든 태스크는 전문가 간 교차 검토와 한 달간의 커뮤니티 검사를 거쳤습니다. 어떤 모델도 풀지 못한 태스크에 대해서는 추가 검증을 수행하여 타당성을 확인했습니다.
벤치마크 개요
데이터셋 통계:
- 총 127개 태스크, 38개의 초기 상태
- 평균 태스크 지시사항: 288.6 단어
- 평균 검증 스크립트: 209.8 줄
태스크 특성:
- Notion의 중첩된 속성 업데이트
- GitHub의 커밋 및 PR 관리
- Playwright의 대화형 폼 자동화
- Filesystem의 복잡한 디렉토리 구조 정리
- PostgreSQL의 트랜잭션 업데이트
모든 작업은 다양한 CRUD 커버리지를 제공하며 실제 다단계 워크플로우의 복잡성을 반영합니다.
평가 프레임워크
상태 추적 및 관리
MCPMark는 모든 태스크를 샌드박스 환경에서 실행하여 명시적인 상태 추적을 보장합니다. 각 평가는 일관된 라이프사이클을 따릅니다.
- 초기 상태: 실제 애플리케이션 시나리오를 반영하는 정의된 초기 상태에서 시작
- 에이전트 실행: 태스크 지시사항을 기반으로 에이전트가 실행
- 자동 검증: 프로그래밍 방식의 검증 스크립트로 최종 환경이 요구사항을 충족하는지 확인
- 환경 리셋: 부작용을 방지하고 동일한 조건에서 반복 평가 가능
MCPMark-Agent
경량 범용 에이전트 프레임워크입니다. LiteLLM과 MCP Python SDK를 결합하여 호환성과 확장성을 제공합니다.
작동 방식:
- MCP 서버는 SDK를 통해 구성되며 도구를 에이전트에 노출
- LiteLLM이 도구를 OpenAI 함수 호출 형식으로 변환
- 다양한 제공자의 공식 API로 요청을 라우팅
실행 프로세스:
- 도구 호출 루프에서 모델이 반복적으로 MCP 도구를 호출
- MCP 서버의 응답을 해석하고 행동을 조정
- 모델이 추가 도구 호출 없이 최종 응답을 생성하면 종료
이 프레임워크는 의도적으로 기본적이며 프로덕션 시스템에 필요한 최적화는 생략했습니다. 태스크별 휴리스틱이나 모델별 편향을 피함으로써 MCP 환경에서 모델의 본질적인 에이전트 능력을 더 명확하게 측정할 수 있습니다.
실험 결과
모델 평가
평가 모델:
- 독점 모델: GPT-5 시리즈, Claude Opus 4.1, Claude Sonnet 4, Grok-4, o3, o4-mini, Qwen3-Max, Gemini 2.5 등
- 오픈소스 모델: Qwen3-Coder-Plus, Kimi-K2-Instruct, DeepSeek-V3.1, GLM-4.5, GPT-OSS-120B
평가 메트릭:
- pass@1: 단일 시도 성공률
- pass@4: 4회 시도 중 1회 이상 성공
- pass^4: 4회 시도 모두 성공 (일관성 측정)
구현 세부사항:
- 최대 100턴, 3600초 타임아웃
- 기본 추론 설정 사용
- LiteLLM 함수 호출 도구 또는 네이티브 경로 사용
주요 결과
프론티어 모델들도 어려움을 겪음:
- 최고 성능 모델 gpt-5-medium: 52.56% pass@1, 33.86% pass^4
- 최고 오픈소스 모델 qwen3-coder-plus: 24.80% pass@1
- 대부분의 독점 모델: 15%~30% pass@1
- 일부 오픈소스 모델: 10% 미만 pass@1
높은 상호작용 요구사항:
- Qwen3-Max: 평균 23.85턴, 23.02 도구 호출
- Kimi-K2-Instruct: 평균 26.95턴, 26.22 도구 호출
로컬 서비스가 원격 서비스보다 쉬움:
로컬 서비스(PostgreSQL, Filesystem, Playwright):
- gpt-5-medium: 76.19%, 57.50%, 43.00% pass@1
원격 서비스(Notion, GitHub):
- 대부분 모델: 25% 미만 pass@1
이는 데이터 가용성 차이 때문입니다. 로컬 서비스는 시뮬레이션과 학습 데이터 수집이 쉽지만, 원격 서비스 API는 대규모 수집이 어려운 실제 상호작용 추적이 필요합니다.
강건성이 훨씬 뒤처짐:
- gpt-5-medium: pass@4 68.50%, pass^4 33.86%
- claude-sonnet-4: pass@4 44.88%, pass^4 12.60%
pass@4에서 pass^4로의 급격한 하락은 다회차 도구 사용에서 모델의 불일치성과 불안정성을 보여줍니다. 실제 배포에서 신뢰성이 필수적이라는 점에서 중요한 위험 요소입니다.
더 많은 턴이 반드시 더 나은 성능을 의미하지 않음:
- 강력한 모델은 더 적고 목표 지향적인 호출로 성공
- kimi-k2-instruct는 30턴을 초과하며 오버콜링 모드에 진입하지만 성공률은 감소
- gpt-5-medium은 합리적인 턴 예산으로 최고 pass@1 달성
성공은 철저한 도구 호출이 아니라 효율적인 의사결정에서 비롯됩니다.
비용이 성능의 대리 지표가 아님:
- 가장 비싼 실행이 낮은 pass@1을 달성하기도 함
- 비용이 비슷해도 성능은 크게 다름
- 높은 비용만으로는 더 나은 결과를 보장하지 않음
추론 모드와 노력
모델 관점
GPT-5 시리즈:
- 중간 및 대규모에서 추론 노력 증가로 이득
- gpt-5-medium: low 46.85% → medium 52.56%
- gpt-5-mini: low 8.27% → high 30.32%
- gpt-5-nano: 4%~6% 범위로 거의 변화 없음 (규모가 작아 추론 토큰 활용 불가)
Claude Sonnet 4:
- 추론 노력에 둔감, 27%~28% 안정적
추가 추론 단계를 더 나은 MCP 사용으로 변환하는 것은 비자명하며 모델의 기본 용량과 학습 접근법에 따라 달라집니다.
MCP 관점
추론 노력이 에이전트 태스크에서 일반화를 선택적으로 개선합니다.
원격 서비스의 큰 이득:
- GitHub (gpt-5): low 27.17% → high 50.00%
- Notion: low 36.61% → high 44.64%
로컬 서비스는 안정적:
- PostgreSQL: 72%~76%
- Filesystem: 5% 포인트 미만 변동
원격 서비스는 속도 제한과 접근 제한으로 학습 노출이 제한적이어서 일반화가 더 어렵습니다. 추론이 이 격차를 메우는 데 도움이 됩니다. 이는 "언어는 에이전트에서 추론을 통해 일반화한다"는 최근 논의와 일치합니다.
실패 분석
실패를 두 가지 범주로 분류합니다.
암묵적 실패
태스크가 정상적으로 완료되지만 출력이 요구사항을 충족하지 않습니다. 원인:
- 추론 오류
- 차선책 계획
- 비효율적인 도구 사용
- 긴 컨텍스트 처리 어려움
대부분의 모델에서 암묵적 실패가 50% 이상을 차지합니다. gpt-5-high와 kimi-k2-instruct는 80% 이상이 암묵적 실패로, 명백한 고장 없이 완료되지만 오류가 더 미묘하고 능력 중심적임을 나타냅니다.
명시적 실패
특정 문제에 직접 연결됩니다.
컨텍스트 윈도우 오버플로우: 입력이 모델의 처리 길이 초과 턴 제한 초과: 허용된 상호작용 단계 소진 포기된 태스크: 모델이 태스크가 실행 불가능하다고 판단 조기 중단: 완료 또는 필요한 도구 호출 없이 중단 잘못된 도구 호출: 잘못된 매개변수 또는 구조
모델별 특징:
- gemini-2.5-flash, gpt-4.1: 암묵적 실패 비율 낮음 (52%, 66%), 더 많은 명시적 원인
- gemini-2.5-flash: 잘못된 도구 호출 10% (도구 호출 규칙 불일치 또는 학습 부족)
- gpt-5-high: 컨텍스트 윈도우 오버플로우 증가 (긴 컨텍스트 처리 어려움)
- kimi-k2-instruct: 턴 제한 초과 빈번 (반복적인 도구 호출 루프)
명시적 오류는 모델별로 다르며, 추론, 컨텍스트 관리, 도구 사용의 타겟팅된 개선이 필요함을 시사합니다.
관련 연구
LLM 에이전트
LLM 에이전트는 초기 ReAct와 같은 프롬프팅 방법에서 MetaGPT와 같은 구조화된 디자인으로 발전했습니다. 도구 사용, 계획 및 반성 방법, 다중 에이전트 프레임워크 연구가 이를 뒷받침했습니다. 코딩 에이전트, GUI 및 컴퓨터 사용 에이전트, 심층 연구 노력이 적용 영역에 포함됩니다. 이러한 발전은 이기종 시스템과 맥락에서 작동할 수 있는 일반 에이전트로의 추세를 보여주며, MCP와 같은 표준화된 프로토콜의 필요성을 자연스럽게 지적합니다.
MCP 사용 평가를 위한 벤치마크
최근 연구들이 MCP 지원 설정에서 에이전트 성능을 체계적으로 벤치마킹하기 시작했습니다.
- MCP-Universe: 다양한 도메인과 평가자에 걸친 태스크 구성
- LiveMCP-101: 다중 도구 상호작용과 실행 계획 검증에 초점
- MCP-AgentBench: 다양한 서버와 도구에 걸쳐 수백 개의 태스크로 확대
이러한 노력은 주로 광범위한 도구 커버리지나 더 쉬운 실행을 강조하지만, 실제 애플리케이션 환경과 연결된 고신뢰도 워크플로우 평가에는 격차가 있습니다.
MCPMark는 컨테이너화된 설정에서 다양한 CRUD 작업을 가진 태스크를 설계하여 안전성과 재현성을 보장합니다. 각 태스크는 프로그래밍 방식의 검증 스크립트 및 전체 환경 상태 추적과 쌍을 이루어 신뢰할 수 있고 세밀한 평가를 가능하게 합니다.
한계 및 향후 방향
세 가지 핵심 방향
1. 모델: 단순 도구 사용에서 정교한 추론으로
- 성공은 더 많은 시도가 아니라 더 똑똑한 결정에서 비롯됨
- 추론은 에이전트에서 더 나은 일반화를 가능하게 함
2. 에이전트: 긴 지평선 태스크 완료를 위한 컨텍스트 효율성
- 문제는 모델의 컨텍스트 윈도우만이 아님
- 계속 증가하는 히스토리를 관리하는 에이전트의 능력이 필요
- 더 나은 요약 전략과 더 간결한 도구 출력 필요
3. 전체 시스템: 실행 안정성의 비약적 향상
- 여러 실행에 걸친 불일치성은 핵심 신뢰성 문제
- 견고한 오류 처리 및 자기 교정 능력을 가진 에이전트 구축 필요
MCPMark는 이러한 핵심 연구 축을 따라 진전을 측정하는 구체적인 테스트베드를 제공합니다.
벤치마크 개선 방향
태스크 생성 확장:
- 현재 파이프라인은 품질을 보장하지만 확장이 어려움
- 대규모 학습 데이터 생산을 위한 병목
- 반자동 태스크 생성 필요
난이도 그래디언트:
- 많은 태스크의 가파른 난이도가 작은 모델 평가를 제한
- 더 세밀한 난이도 그래디언트 도입 필요
- 태스크 실행 체인 축소 가능
애매한 의도 처리:
- 실제 복잡성을 더 잘 반영하기 위해 애매한 사용자 의도를 가진 태스크 포함
- 에이전트의 명확화 질문 능력이나 실제 의도 추론 테스트
MCP 서버 다양성:
- 더 다양한 디지털 도구에 걸쳐 에이전트에 도전하기 위해 더 넓은 범위의 MCP 서버 통합