Video models are zero-shot learners and reasoners
원래 자연어 처리 분야는 번역, 질의응답, 요약 등 각각의 작업마다 별도의 전용 모델이 필요했습니다. 불과 몇 년 전의 일입니다. 대규모 언어 모델의 출현으로 모든게 바뀌기 전이죠. 그 시작은 GPT-3였습니다. 이제는 하나의 범용 모델이 프롬프트만으로 다양한 언어 작업을 해결하는 것이 당연한 시대죠.
컴퓨터 비전 분야는 상황이 조금 다릅니다. 여전히 객체 검출에는 YOLO, 세그먼테이션에는 Segment Anything, 엣지 검출에는 또 다른 전용 모델을 사용합니다. 물론 일부 비전 작업을 통합하려는 시도가 있었지만, 프롬프트만으로 모든 문제를 해결할 수 있는 진정한 범용 모델은 아직 등장하지 않았습니다.
흥미롭게도 LLM의 성공 비결이었던 핵심 요소인 대규모 데이터셋에서의 생성적 목적 함수를 통한 훈련이 오늘날의 비디오 생성 모델에도 동일하게 적용되고 있습니다. 이것이 바로 Google DeepMind 연구진이 주목한 지점입니다.
이제 비디오 모델들도 LLM처럼 범용 시각 이해 능력을 발전시킬 수 있을지 궁금합니다. 이번 연구는 Veo 3가 명시적으로 학습하지 않은 시각적 작업을 제로샷 방식으로 해결할 수 있음을 보여줍니다.
T. Wiedemer, Y. Li, P. Vicol, S. S. Gu, N. Matarese, K. Swersky, B. Kim, P. Jaini, R. Geirhos, "Video models are zero-shot learners and reasoners," arXiv preprint arXiv:2509.20328, DOI: 10.48550/arXiv.2509.20328, 2025.
요약
이 연구는 비디오 모델이 범용 시각 이해 능력으로 발전할 수 있는 가능성을 탐구합니다. 연구진은 62개의 정성적 평가와 7개의 정량적 평가를 통해 총 18,384개의 비디오를 분석했습니다.
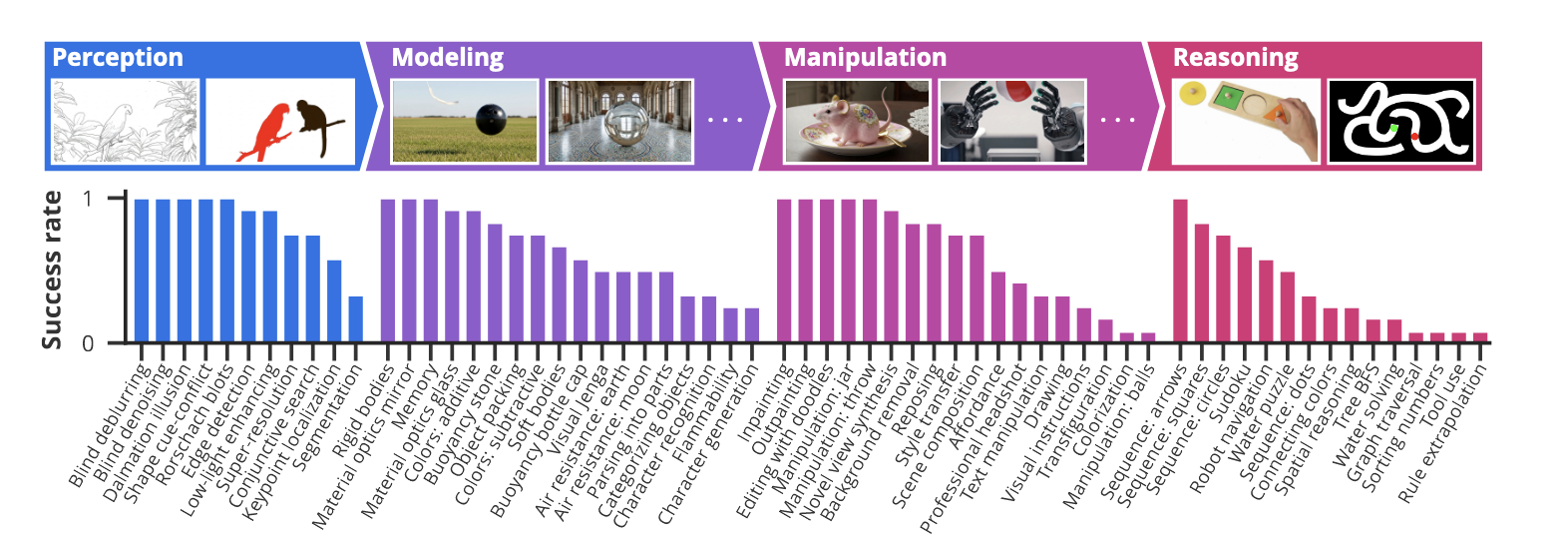
주요 아키텍처: Google의 Veo 3 비디오 생성 모델을 사용했으며, 이는 16:9 해상도, 720p, 24 FPS로 8초 분량의 비디오를 생성합니다.
평가 방법: 입력 이미지와 텍스트 프롬프트만을 사용하여 다양한 시각적 작업을 해결하는 능력을 평가했습니다. 이는 언어 모델의 프롬프팅 방식과 동일한 접근법입니다.
성능 향상: Veo 2에서 Veo 3로의 발전에서 일관되고 상당한 성능 개선을 관찰했으며, 이는 비디오 모델의 빠른 발전을 시사합니다.
논문 상세
1. 비전 작업의 4단계 계층
연구진은 시각적 능력을 4개의 계층적 단계로 분류했습니다:
1.1 인식(Perception)
기본적인 시각 정보 이해 능력으로, 다음과 같은 작업들을 수행할 수 있습니다:
- 에지 검출 및 세그먼테이션 (성공률 92%)
- 키포인트 위치 파악 (성공률 58%)
- 초해상도 처리 (성공률 75%)
- 블라인드 디블러링 (성공률 100%)
- 저조도 개선 (성공률 92%)
- 달마시안 착시 등 모호한 이미지 해석 (성공률 100%)
1.2 모델링(Modeling)
인식된 객체들의 관계와 물리 법칙을 이해하는 능력입니다:
- 강체/연체 동역학 이해
- 부력, 공기 저항, 가연성 등 물리적 특성 이해
- 굴절, 반사 등 광학 현상 모델링
- 가산/감산 색 혼합 이해
- 시간과 카메라 움직임에 따른 세계 상태 기억
1.3 조작(Manipulation)
인식하고 모델링한 시각 세계를 의미있게 변형하는 능력입니다:
- 배경 제거, 스타일 전송, 컬러라이제이션
- 3D 인식 포즈 편집
- 새로운 시점 합성
- 복잡한 물체 상호작용 시뮬레이션 (예: 병뚜껑 열기, 공 던지고 받기)
- 어포던스 인식 (예: 망치를 올바르게 잡는 방법)
1.4 추론(Reasoning)
시간과 공간에 걸친 단계별 시각 추론 능력입니다:
- 미로 해결 (5×5 격자에서 78% 성공률)
- 시각적 대칭 완성
- 그래프 탐색 및 트리 너비 우선 검색
- 시각적 아날로지 완성
- 간단한 수도쿠 해결 (성공률 67%)
2. Chain-of-Frames: 비디오의 단계별 추론
연구진은 "Chain-of-Frames(CoF)"라는 새로운 개념을 제시합니다. 이는 언어 모델의 Chain-of-Thought와 유사하게, 비디오 모델이 프레임별로 단계적 추론을 수행하는 것을 의미합니다.
\[\text{CoF} : \text{Frame}_{t} \rightarrow \text{Frame}_{t+1} \rightarrow \ldots \rightarrow \text{Solution}\]
이러한 접근법을 통해 복잡한 공간-시간 추론 문제를 해결할 수 있습니다.
3. 정량적 평가 결과
3.1 에지 검출
BIPEDv2 데이터셋의 50개 테스트 이미지에서 평가:
- Veo 3: 0.77 OIS (pass@10)
- 전문 모델(SOTA): 0.90 OIS
- 제로샷 성능치고는 매우 우수한 결과
3.2 인스턴스 세그먼테이션
LVIS 데이터셋의 50개 이미지에서 평가:
- Veo 3: 0.74 mIoU (best frame pass@10)
- Nano Banana: 0.73 mIoU
- 전문 모델과 거의 동등한 성능
3.3 미로 해결
다양한 크기의 미로에서 경로 계획 능력 평가:
- 5×5 격자: 78% 성공률 (pass@10)
- Veo 2: 14% 성공률
- 상당한 성능 개선을 보여줌
4. 시사점과 한계
4.1 성능 향상 궤적
Veo 2에서 Veo 3로의 발전에서 모든 평가 작업에 걸쳐 일관된 성능 향상을 관찰했습니다. 이는 비디오 모델이 빠른 속도로 발전하고 있음을 시사합니다.
4.2 현재의 한계
- 전문 모델 대비 성능이 아직 부족한 영역들이 존재
- 프롬프트 엔지니어링의 중요성 (최고/최악 프롬프트 간 40-64%p 성능 차이)
- 비디오 생성 비용이 여전히 높음 (하지만 지속적으로 감소 중)
4.3 미래 전망
연구진은 비디오 모델이 언어 모델이 NLP에서 그랬듯이 컴퓨터 비전 분야에서 범용 기초 모델로 자리잡을 것이라고 예측합니다. 특히 다음과 같은 발전이 기대됩니다:
- 추론 시간 스케일링 방법을 통한 성능 향상
- 자동 검증기를 활용한 후훈련 최적화
- 비용 효율성의 지속적 개선
5. 결론
연구 주제와 성과가 인상적입니다. 여전히 전문 모델 대비 성능 격차가 존재하고 비용 문제도 해결해야 하지만 Chain-of-Frames가 보여준 단계별 추론 능력은 잠재력이 있습니다. 비디오 모델이 컴퓨터 비전의 패러다임을 바꿀지도 모르겠습니다. 전반적으로 AI는 단일 작업 모델이 아닌 범용 기초 모델을 중심으로 발전할 확률이 높습니다.