산야 피들러
2026-06-06
NVIDIA AI 연구 부사장이자 토론토대 교수. NVIDIA 토론토의 Spatial Intelligence Lab을 이끌며 3D 비전과 월드 모델을 연구합니다.
92개의 게시물

NVIDIA AI 연구 부사장이자 토론토대 교수. NVIDIA 토론토의 Spatial Intelligence Lab을 이끌며 3D 비전과 월드 모델을 연구합니다.
NVIDIA Learning and Perception Research 부사장. 컴퓨터비전, 생성 모델, 효율적 딥러닝, 임바디드 AI를 폭넓게 연구합니다.
NVIDIA Research 부사장이자 Cosmos Lab을 이끄는 연구자. Physical AI를 위한 월드 파운데이션 모델과 생성 모델 연구의 책임자입니다.

1989년 AT&T Bell Labs 팀이 미국 우체국 우편번호 이미지에 역전파 합성곱 신경망을 적용해 1% 오류율을 달성한 연구. 합성곱 신경망의 첫 실세계 응용이자 LeNet 계보의 출발점입니다.
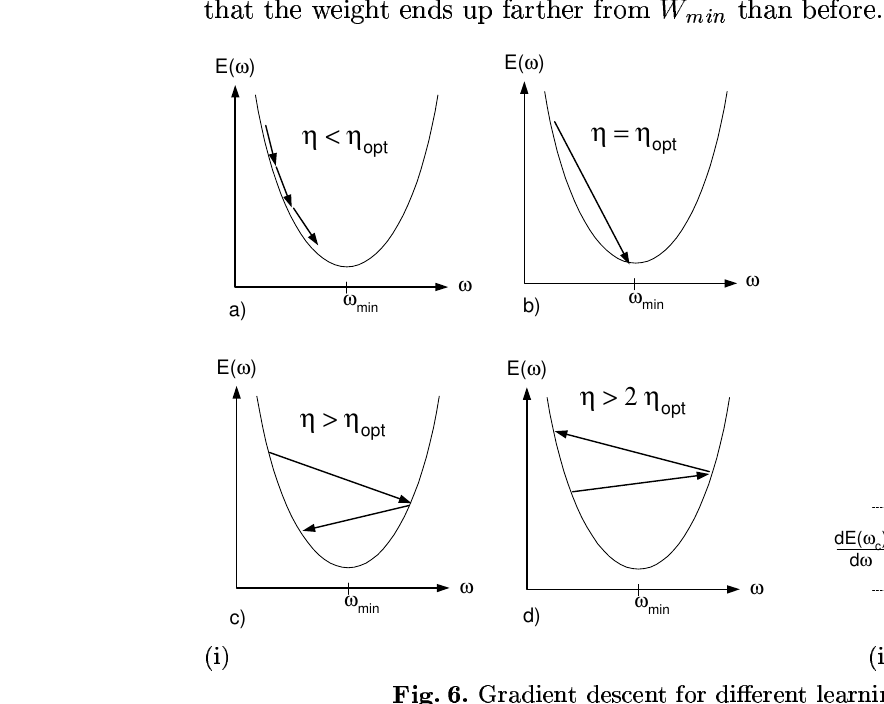
1998년 AT&T Bell Labs와 GMD Berlin 팀이 정리한 신경망 학습 트릭 모음. 확률적 경사 하강이 왜 이기는지, 입력 정규화·시그모이드·학습률·초기화·2차 방법을 어떻게 다룰지 한 챕터로 못 박은 책 챕터. 현대 딥러닝 학습 레시피의 출발점입니다.
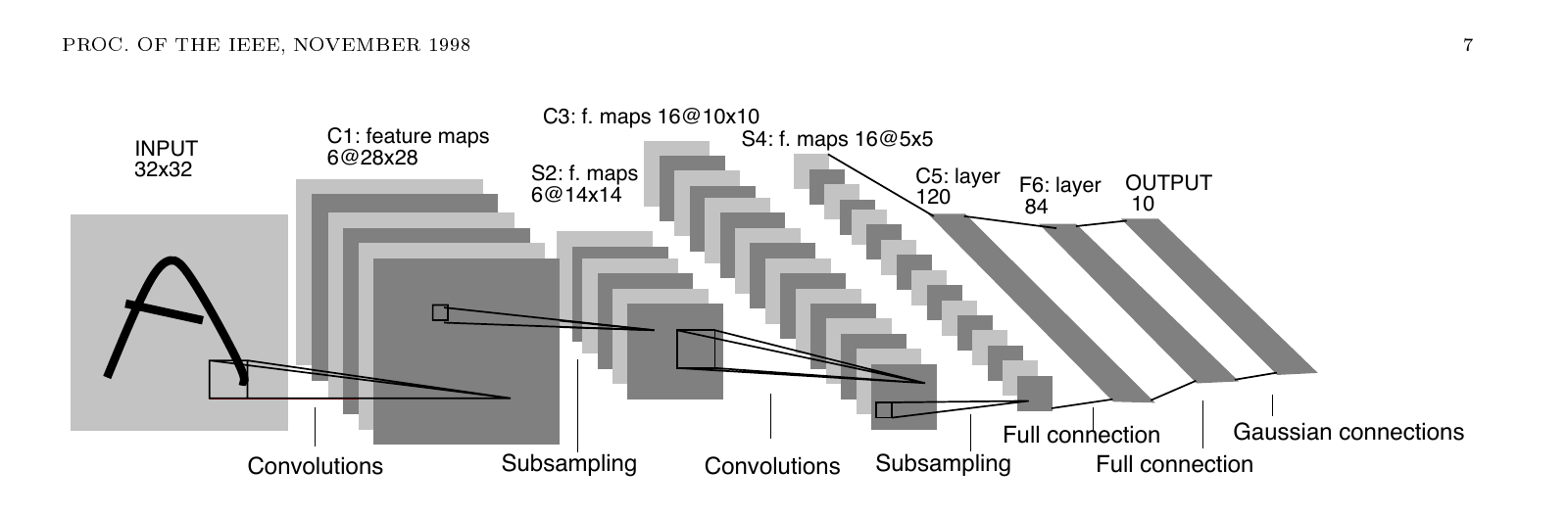
1998년 AT&T Labs 팀이 손글씨 인식부터 미국 은행 수표 판독까지 한 편의 논문으로 묶은 정본. LeNet-5라는 합성곱 신경망 이름이 처음 등장한 글이고, MNIST가 처음 정의된 글이며, 학습 가능한 모듈을 그래프로 잇는 Graph Transformer Network 개념도 여기서 정식화됩니다.
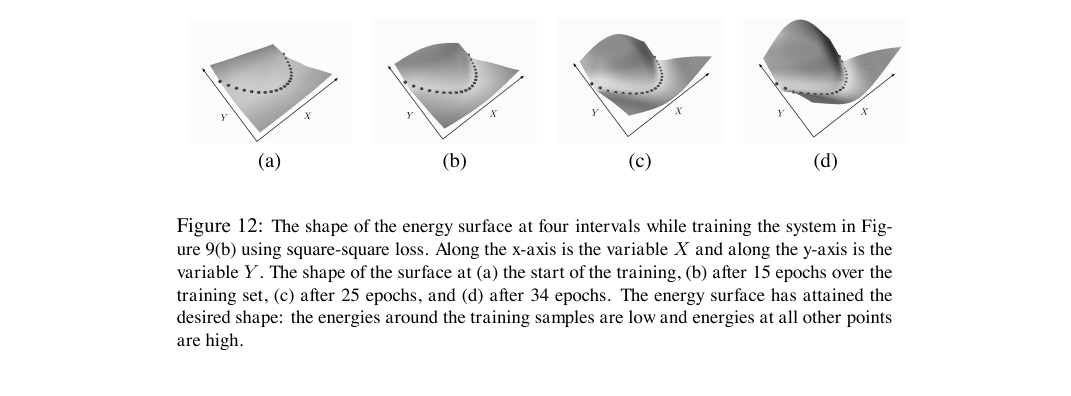
정규화된 확률을 거치지 않고 에너지 표면을 직접 깎는 학습 프레임워크의 정식 정의. 손실 함수의 좋고 나쁨을 마진 조건 하나로 가르고, GTN과 CRF·SVMM을 같은 그릇에 담는다.
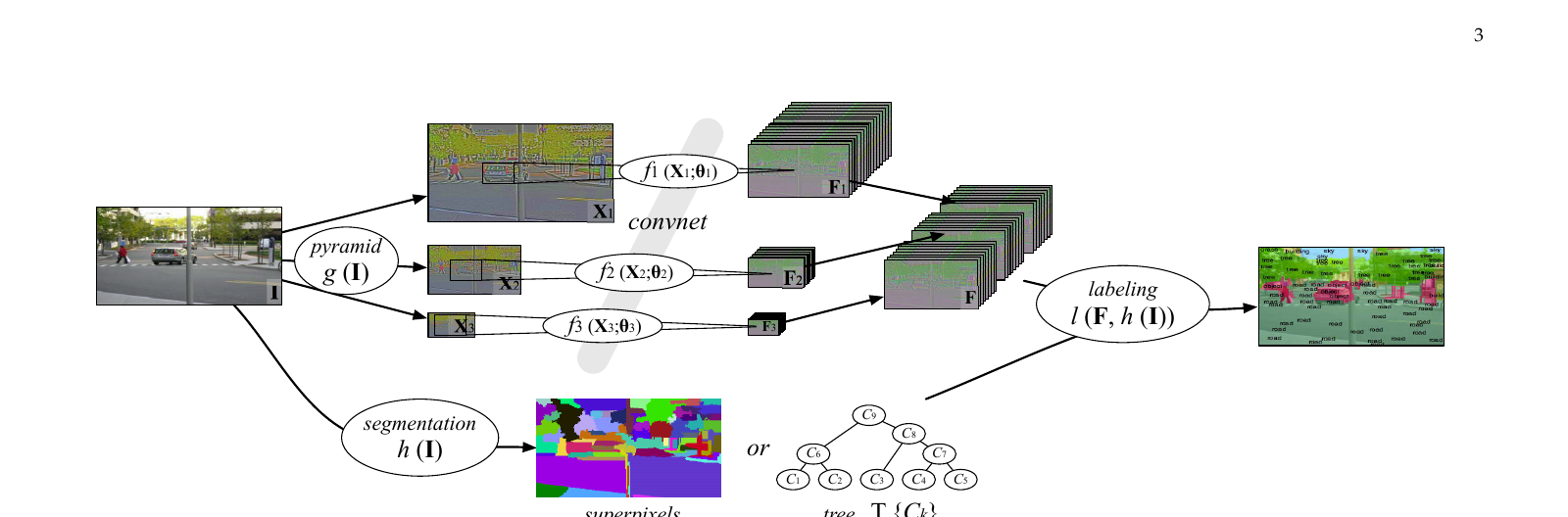
2012~2013년 NYU 르쿤 연구실과 ESIEE 나즈만 팀이 공동으로 정리한 장면 분할 정본. 다중 스케일 합성곱 망이 픽셀별로 큰 맥락을 보고, 영상 경사 위 분할 트리에서 클래스 순도를 최소화하는 *optimal cover*가 후처리를 대신합니다. Stanford Background, SIFT Flow, Barcelona 세 벤치마크에서 최신 기록을 세웠고 한 장 처리에 1초가 걸립니다.
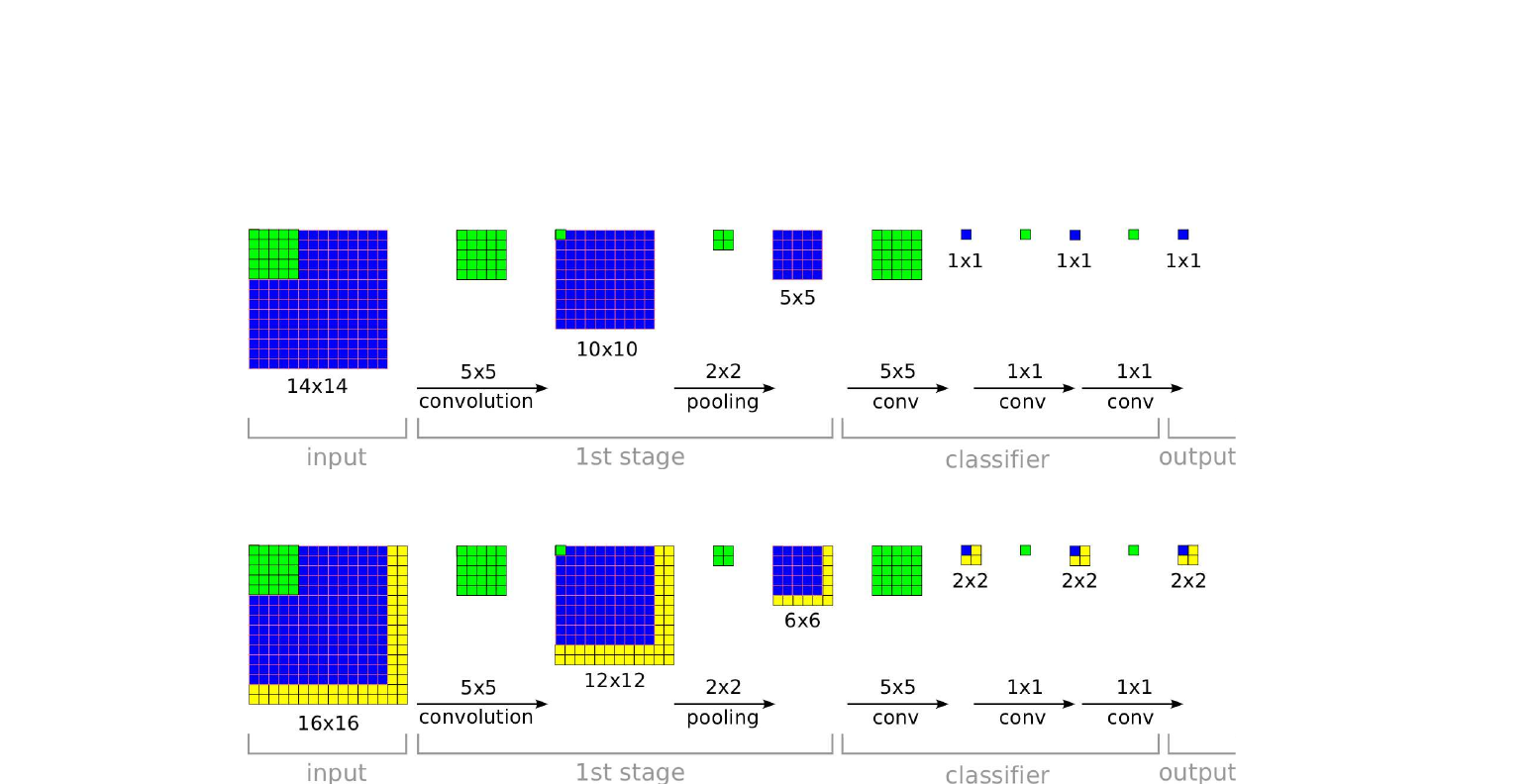
2013년 NYU CILVR 팀이 한 망으로 분류·위치 추정·검출 세 가지를 동시에 푼 연구. 합성곱 망 자체가 슬라이딩 윈도우라는 통찰을 정식화하고 미세 스트라이드 풀링으로 다중 스케일 평가를 효율화하여 ILSVRC 2013 위치 추정 부문에서 우승하였습니다.
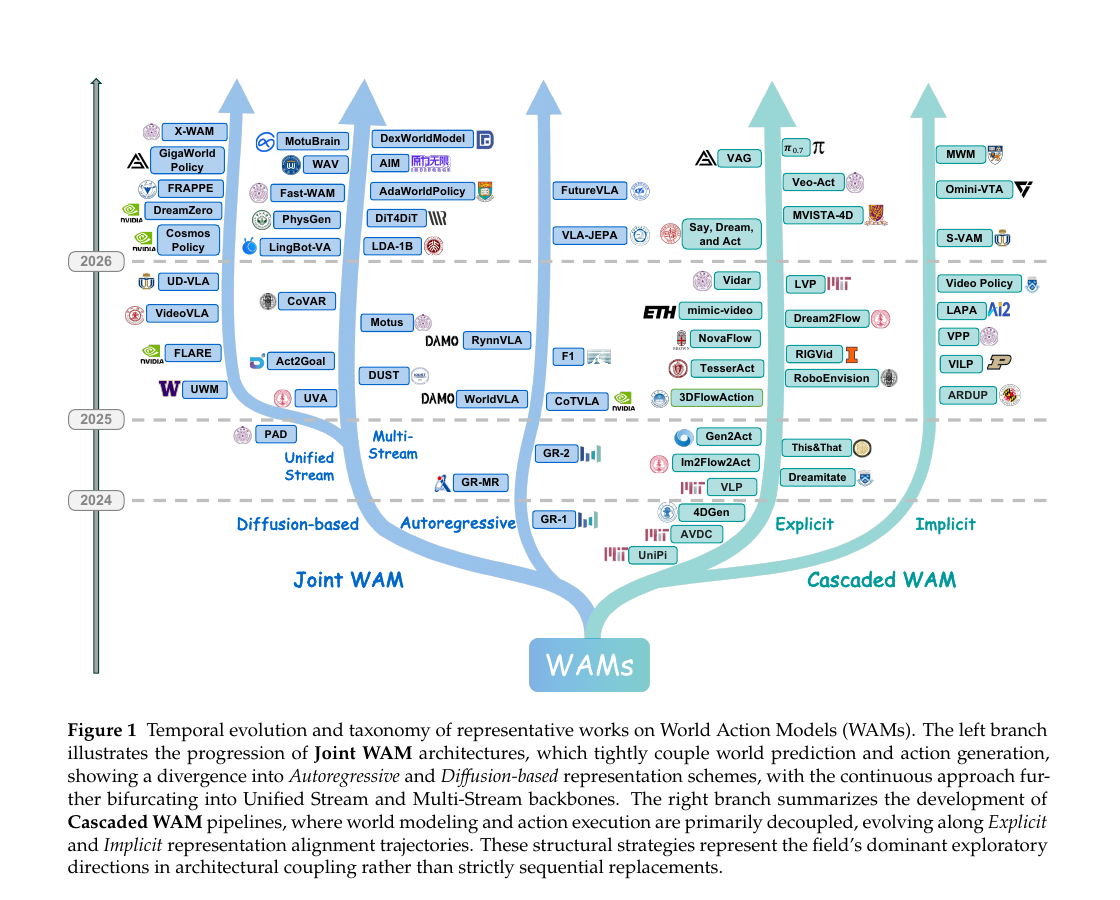
Vision-Language-Action 모델이 학습하는 reactive observation-to-action 매핑과 World Model 계열의 예측적 dynamics 모델링이 별도의 흐름으로 흘러오다가 한 모델 안에서 합쳐지기 시작했습니다. Fudan 신뢰성 임바디드 AI 연구소가 이 합류 지점을 World Action Models로 명명하고 정의·아키텍처·데이터·평가의 네 축으로 정리한 첫 서베이를 살펴봅니다.
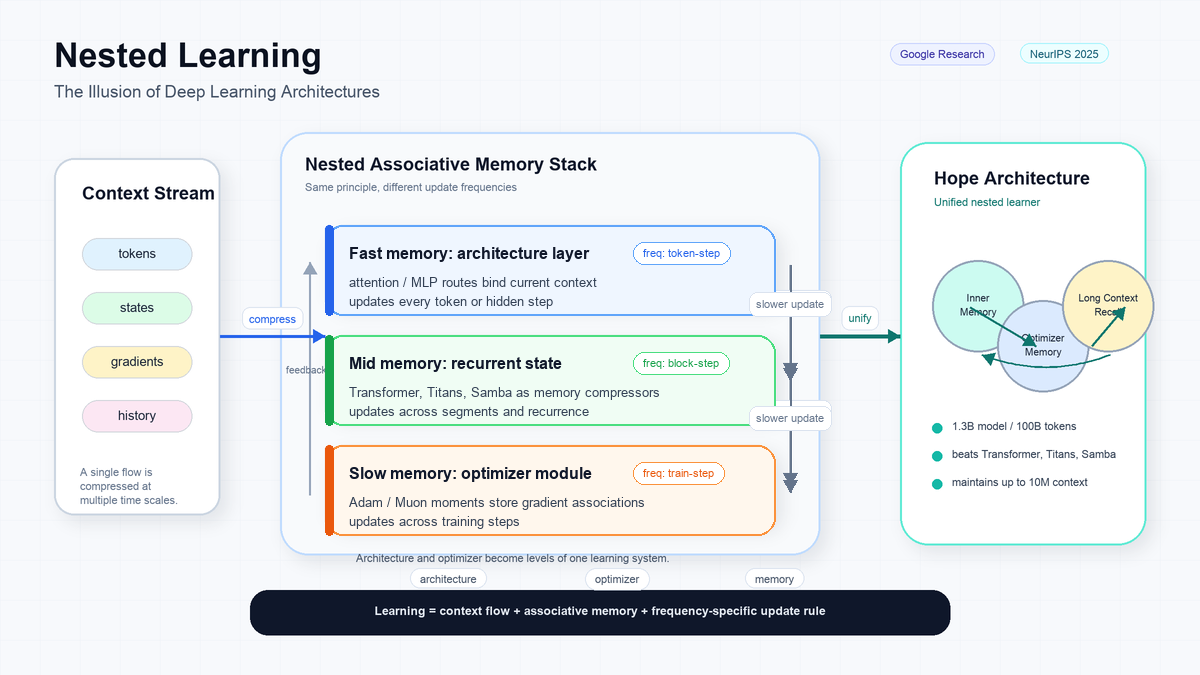
트랜스포머와 모던 옵티마이저(Adam, Muon)는 사실 같은 것의 다른 레벨이라는 주장입니다. Google Research가 NeurIPS 2025에서 발표한 Nested Learning은 모델 아키텍처와 옵티마이저를 "본인의 컨텍스트 흐름을 압축하는 연상 기억"의 중첩 시스템으로 통합합니다. 이를 토대로 만든 Hope 아키텍처는 1.3B/100B 토큰 규모에서 트랜스포머·Titans·Samba를 넘기며, 10M 컨텍스트까지 성능을 유지합니다.
이 블로그 하나로 AI 공부를 완결하는 순서

텍스트-투-비디오 모델들은 눈을 뗄 수 없을 만큼 아름다운 영상을 만들어냅니다. 그런데 카메라가 크게 움직이는 순간, 뭔가 이상해집니다. 건물 벽이 녹아내리고, 물체가 갑자기 사라지고, 물리적으로 말이 안 되는 장면을 생성합니다. World-R1은 이 문제를 아키텍처 수정 없이, 강화학습(RL)만으로 해결한다고 주장합니다.
Stanford CS230 딥러닝 강의 (2025 가을) 전체 목차. 유튜브 강의 트랜스크립트를 한국어 도서 형식으로 정리한 시리즈.
스탠퍼드 CS230 첫 번째 강의. 딥러닝이 왜 지금 가장 강력한 머신러닝 기법인지, 스케일링이 성능에 미치는 영향, 그리고 CS230 강좌의 구조와 실무 역량까지 폭넓게 다룬다.
Stanford CS230 딥러닝 강의 Lecture 2. 지도 학습 프로젝트(주야간 분류, 트리거 워드 탐지, 얼굴 인증)를 통해 실전 의사결정을 익히고, 자기지도 학습과 약지도 학습의 원리를 다룬다.
딥러닝 프로젝트의 전체 생애주기를 얼굴 인식 시스템 구축 사례를 통해 다룬다. 데이터 수집 전략, 반복적 개발 루프, 배포 아키텍처, 모니터링과 유지보수까지 실무 전 과정을 포괄한다.
신경망 학습 중 이전 층의 매개변수 변화로 인해 각 층의 입력 분포가 지속적으로 변하는 현상
전체 데이터를 작은 배치로 나눠 배치마다 그래디언트를 계산하고 가중치를 업데이트하는 최적화 방법
역전파 중 그래디언트가 초기 층으로 전달될수록 지수적으로 작아져 학습이 안 되는 문제
원시 입력에서 최종 출력까지 중간 처리 단계 없이 단일 모델로 학습하는 방식
노이즈 추가(순방향)와 노이즈 제거(역방향) 과정을 학습하여 데이터를 생성하는 생성 모델
게이트 메커니즘으로 장거리 의존성 문제를 해결한 RNN의 개선 모델
음수 입력을 0으로 만들고 양수 입력은 그대로 통과시키는 신경망 활성화 함수
이전 시간 단계의 은닉 상태를 현재 입력과 함께 처리하여 순서가 있는 데이터를 모델링하는 신경망
신경망에서 연쇄 법칙을 이용해 각 매개변수의 그래디언트를 효율적으로 계산하는 알고리즘
신경망에 대한 적대적 공격의 원리와 방어 기법을 다루고, 생성 모델의 두 축인 GAN과 확산 모델의 수학적 직관과 훈련 방법을 상세히 설명한다.
Stanford CS230 딥러닝 강의 Lecture 5. 강화 학습의 기본 개념부터 Deep Q-Network, 경험 재생, 탐색-활용 균형, 그리고 RLHF까지 다룬다.
Stanford CS230 딥러닝 강의 Lecture 6. 음성 인식 시스템과 AI 딥 리서처 파이프라인을 예시로, ML 프로젝트의 반복 사이클, 오류 분석, 데이터 전략을 실전적으로 다룬다.
Stanford CS230 딥러닝 강의 Lecture 9. AI 시대의 커리어 전략, 기술 부채 관리, 하이프 필터링, 그리고 성공의 3가지 기둥을 다루는 실전 조언 강의.
Stanford CS230 딥러닝 강의 Lecture 10. CNN 내부 해석 기법(Saliency Map, Integrated Gradients, Occlusion Sensitivity, CAM, Deconvolution)부터 프론티어 모델의 스케일링 법칙, 벤치마크 오염, 데이터 진단까지 다루는 모델 해석 강의.
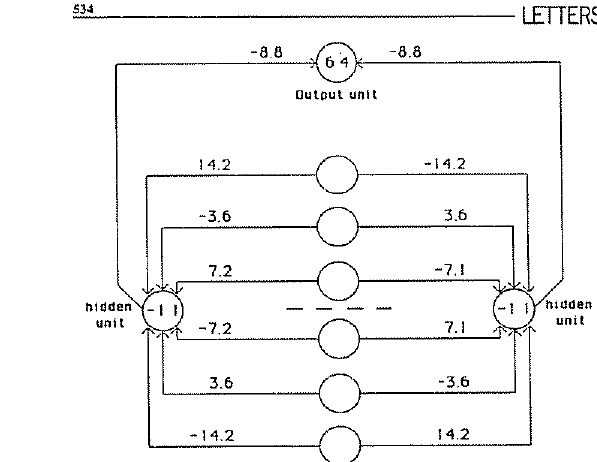
다층 신경망을 훈련하는 역전파 알고리즘을 Nature 한 편으로 정리하고, 은닉층이 과제에 맞는 내부 표현을 자동으로 만들 수 있음을 보인 1986년 논문입니다.
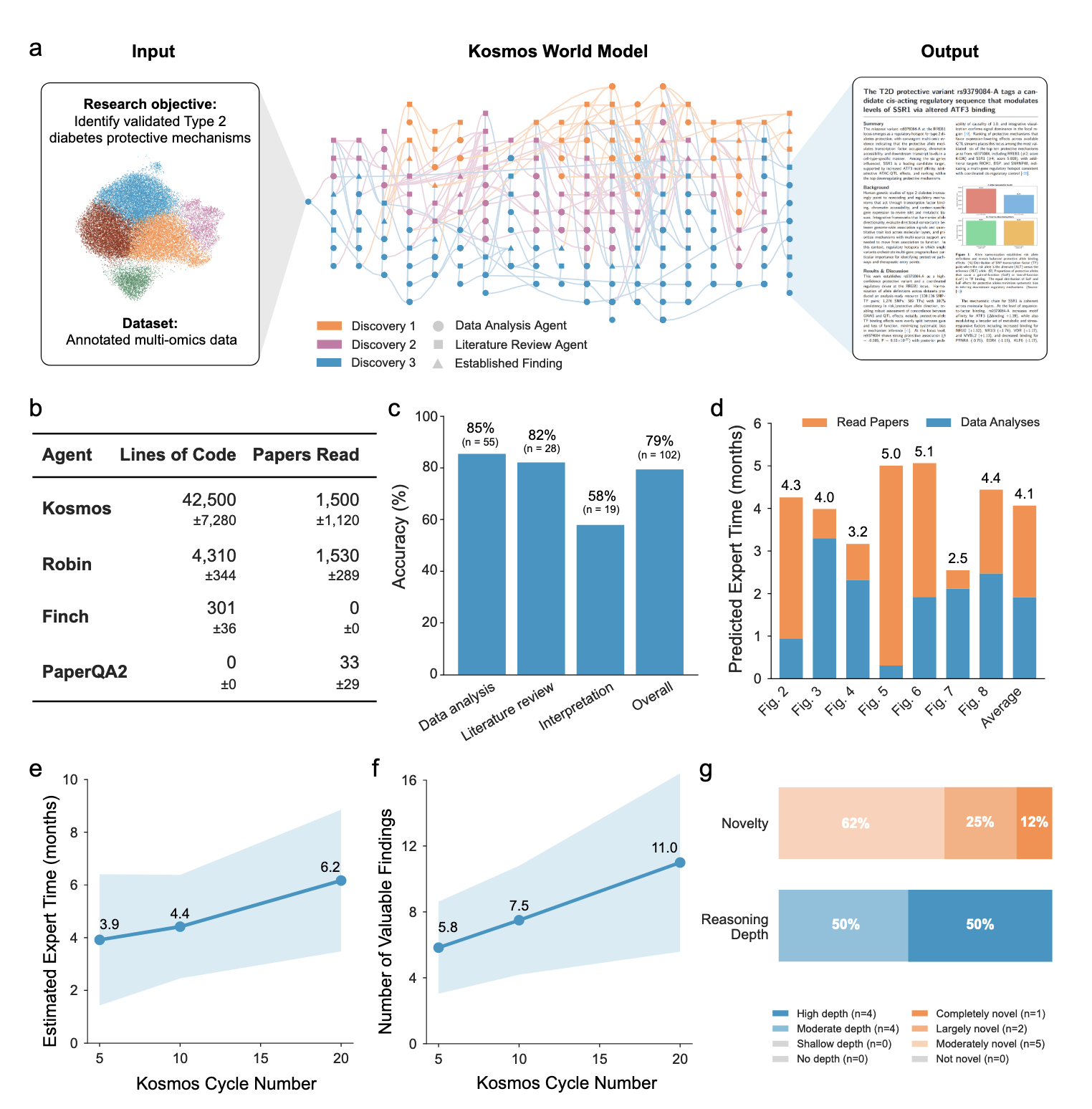
AI 과학자 Kosmos를 소개합니다. 데이터와 연구 목표를 주면 자동으로 논문을 읽고, 데이터를 분석하고, 가설을 생성해 과학 보고서를 작성합니다. 6개월간 인간 연구자가 수행할 작업을 하루에 끝내고 모든 단계가 투명하게 공개됩니다. 신경생물학, 재료과학, 통계유전학등 다양한 분야에서 실제 발견을 만들어냈습니다.
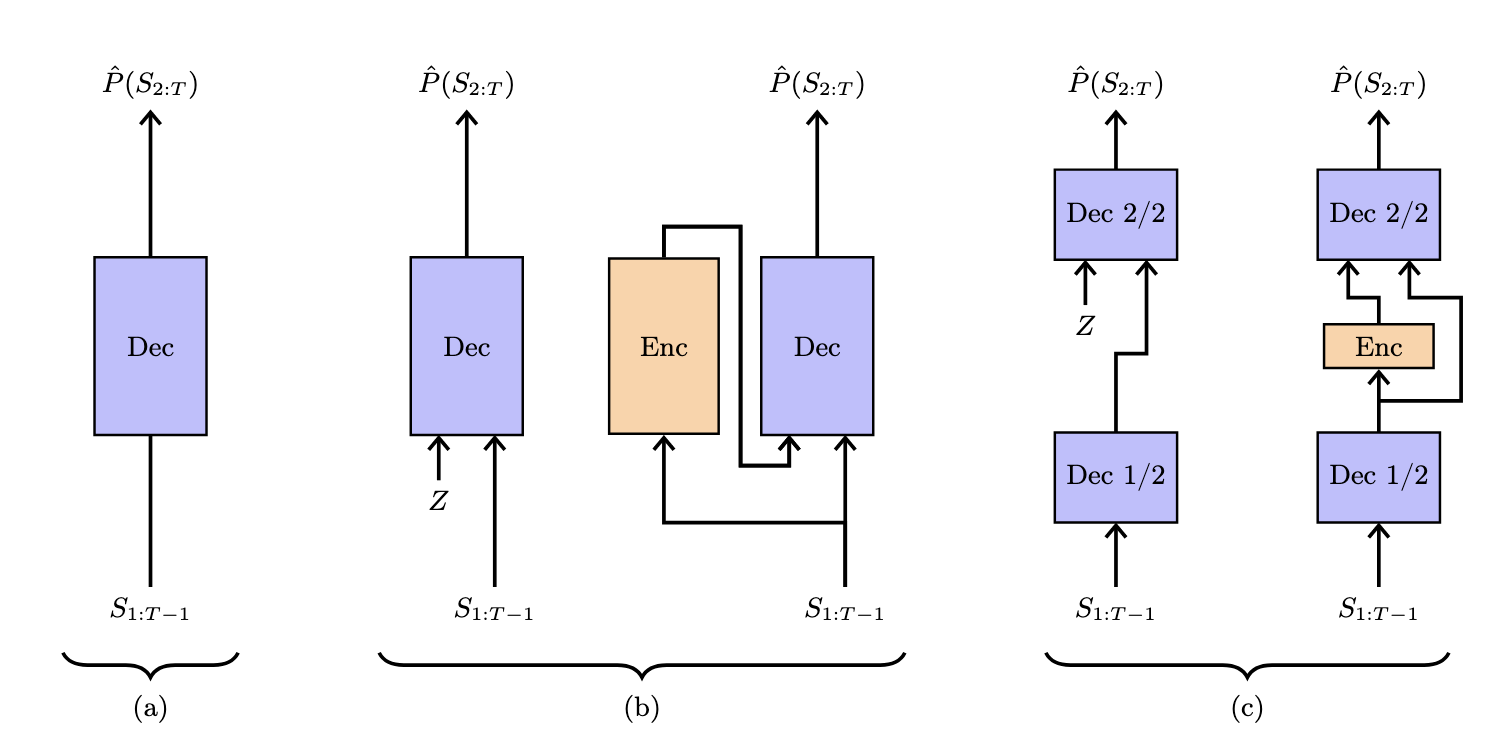
디코더 트랜스포머에 잠재 변수를 사용할 자유를 부여하는 접근을 탐구합니다. 하이퍼파라미터 조정 없이 여러 벤치마크에서 성능 향상을 달성합니다.

LLM이 텍스트를 이해하는 첫 단계인 토큰화(Tokenization)의 다양한 방법을 정리합니다. 단어, 문자, 서브워드(BPE, WordPiece), SentencePiece 등 주요 토큰화 기법의 원리와 장단점을 비교하고, 모델 성능에 미치는 영향을 설명합니다.
NYU 박사, 문자 단위 텍스트 분류 합성곱 망과 AG News 벤치마크의 저자, 현재 구글 연구 과학자
AT&T Bell Labs Adaptive Systems Research 부서장, NIPS 학회 공동 창립자, DARPA 자율 주행 프로그램 매니저

GRU와 어텐션 메커니즘을 공동 개발해 트랜스포머의 직접 계보를 연 연구자. 현재 NYU 교수 겸 Genentech 프런티어 연구 총괄

바이브 코딩이라는 용어를 만든 AI 교육자로, 22개월의 창업 챕터를 접고 2026년 5월 Anthropic에 합류해 Claude 사전학습팀을 이끈다
트랜스포머 논문 공동저자, 전 Google Brain 연구원. Essential AI 공동창업자
희소 부호화·대규모 비지도 학습·다언어 기계 번역을 잇는 이탈리아 출신 연구자, Google DeepMind 시니어 연구자

UC 버클리 교수. 박사 시절 강화학습으로 헬리콥터에게 틱톡, 카오스 등 최상위 인간 조종사급 곡예비행을 가르쳤다
Siamese 네트워크용 contrastive loss를 도입한 인도 출신 머신러닝 연구자, 현재 NYU Courant + Grossman School of Medicine 정교수

27억 달러 딜로 Google에 복귀해 Gemini를 공동 리드하다가 2년도 안 돼 OpenAI로 떠난 트랜스포머 공동 발명자. 샘 올트먼은 영입에 10년 걸렸다고 말했다

OpenAI 전 수석 과학자. 지금 이끄는 SSI는 제품도 매출도 없이 기업가치 320억 달러를 인정받았다
화중과기대(HUST) 전자정보통신학부 교수. 컴퓨터비전·딥러닝 분야 연구 그룹 HUST Vision Lab 주재. CVPR·NeurIPS 등 100편 이상 논문 발표.

Google DeepMind CEO, 노벨 화학상 수상자. 인류가 \
UCLA 컴퓨터과학과 부교수, UCLA AGI Lab 대표, 통계적 머신러닝과 딥러닝 이론 전문가

Coursera 공동 창립자. Google Brain 시절 1만 6천 개 CPU 코어로 신경망을 학습시켜 고양이 얼굴을 스스로 인식하게 만들었다
단백질 3D 구조를 아미노산 서열만으로 예측하는 Google DeepMind의 AI, 2024년 노벨 화학상의 근거
상하이교통대 인공지능학원 조교수, EPIC Lab을 이끄는 효율적 AI 연구자. 지식 증류와 모델 압축이 전문
NTU S-Lab·MMLab@NTU를 이끄는 generative AI·멀티모달 연구자. SenseNova-U1 Senior Project Lead.
그래프 기반 영상 분할과 수리형태학을 잇는 프랑스 출신 연구자, Meta FAIR Paris 리서치 사이언티스트

딥러닝 3대 거장 중 한 명. 초지능 에이전트가 자기보존 목표를 가지면 10년 내 인류 멸종 위협이 현실화될 수 있다고 경고한다
Neocognitron의 발명자, 현대 합성곱 신경망의 구조적 원형을 만든 일본 신경망 연구자
베이징대학교 교수, MSALab(Multimedia Semantic Analytics Lab) 책임, 미디어 지능 컴퓨팅·멀티모달·확산 모델 연구. PerceptionDLM 교신저자
메타의 AI 연구 조직 FAIR, 얀 르쿤이 이끌어 온 오픈 연구의 거점
미국 수학자·전산학자. 노스이스턴대 교수. 역전파 1986 Nature 논문 3저자이자 REINFORCE 정책 그래디언트의 창시자.
트랜스포머 논문 공동저자, 전 Google Brain 연구원. 일본 도쿄 Sakana AI 공동창업자 겸 CTO

AlphaFold2 연구 책임자. 39세에 노벨 화학상을 받아 70년 만에 가장 젊은 화학상 수상자가 되었다
메타(Reality Labs)의 LLM 양자화 전문 연구자. SpinQuant, LLM-QAT, MobileLLM 등 온디바이스 효율화·압축 연구를 이끌었습니다.
메타 FAIR 리서치 사이언티스트. 딥러닝의 일반화를 압축·손실곡면 관점으로 파고드는 연구자. ICML 2022 Outstanding Paper 수상.
구글의 딥러닝 연구 조직, 2023년 DeepMind와 통합

비틀즈 노래를 패러디한 제목의 트랜스포머 논문 1저자로 인용 21만 건을 넘겼고, Adept 이후 Essential AI를 다시 창업했다
호주 University of Queensland EECS 강사. 비전-언어 모델과 멀티모달 추론을 연구하며 전 Meta Research Scientist
AT&T Bell Labs 신경망 연구의 이론적 기둥, 일반화 이론과 Optimal Brain Damage 공저자
Anthropic 공동 창립자이자 수석 과학자, 스케일링 법칙 핵심 저자
상하이교통대학교 부교수, KAUST 연구과학자. 머신러닝·지속학습·평생학습·포스트트레이닝 연구. GateMem 교신저자

NVIDIA를 새너제이 Denny's 식당 부스에서 창업했다. 20년 넘게 검은 가죽 재킷을 트레이드마크로 삼은 CEO

딥러닝의 아버지이자 노벨 물리학상 수상자. \
2012년 ImageNet을 압도하며 딥러닝 시대를 연 합성곱 신경망
2012년 AlexNet이 top-5 오류율을 전년도 26.2%에서 15.3%로 낮추며 딥러닝 시대를 연 이미지 인식 챌린지
OverFeat 1저자, NYU 박사 후 Google Brain 로보틱스로 옮겨 자기지도 로봇 학습을 이끄는 프랑스계 연구자
Anthropic 공동 창립자, 신경망 해석가능성 분야 선구적 연구자
프린스턴 대학교 컴퓨터과학 박사과정, Princeton AI Lab Fellow, LLM 아키텍처 및 추론 연구
미시간대 교수이자 LG AI연구원 CSO·EVP. 딥러닝 비지도 표현학습의 선구자 중 한 명.
TDNN과 다단계 시퀀스 인식의 전문가, LeNet-5 수표 판독 시스템의 산업 배포를 이끌었고 현재 AWS Principal Applied Scientist
Brown University 컴퓨터과학과 조교수. 딥러닝의 이론적 기초, 세계 모델, 자기 지도 학습 전문. Yann LeCun과 LeJEPA를 공동 저술
MBZUAI 머신러닝학과 조교수, VILA Lab 공동 운영. 효율적 딥러닝, 지식 증류, 에이전트 시스템 설계 연구
NYU 박사, 단일 이미지 깊이 추정의 표준이 된 다중 스케일 신경망 제안, 현재 Clarifai 연구 과학자
인지과학자, UCSD PDP 그룹의 중심 인물. 역전파 1986 Nature 논문 1저자이자 connectionism의 설계자.
스탠퍼드 CS229 딥러닝 파트 강사

논리학 박사 출신 트랜스포머 공동저자로, OpenAI 이적 후 최초의 추론 모델 o1 개발을 이끈 리서치 리드가 됐다
NYU 박사, 영상 예측과 FFT 기반 빠른 합성곱 신경망의 저자, 현재 Google DeepMind 연구 과학자
NORB 데이터셋을 만든 NYU 박사 출신 컴퓨터 비전 연구자, ImageNet 이전 시대의 객체 인식 벤치마크 기여자
스탠퍼드 CME295 트랜스포머와 LLM 강의 공동 강사

CNN의 아버지. Meta 퇴사 후 세운 AMI Labs가 시드 라운드 10억 3천만 달러로 유럽 역사상 최대 기록을 세웠다
Cornell 박사과정 + Google Research NYC 인턴, Titans·Atlas·Miras·Hope 연쇄 논문의 1저자
Torch7 공동 개발자, NeuFlow 하드웨어 가속기 설계자, NVIDIA를 거쳐 현재 Google DeepMind 시니어 연구자
ZFNet과 deconv 시각화로 알려진 컴퓨터 비전 연구자, NYU 교수이자 2025년 Meta FAIR 책임자로 부임

DrLIM·연속 학습·로봇 RL의 권위자, Google DeepMind VP of Research, 인문학 학부에서 ML 박사로 전환한 이력

RNA를 생물학적 소프트웨어로 보고 창업한 Inceptive가 2026년 Alnylam과 최대 20억 달러 계약을 맺은, 생명과학으로 전향한 유일한 트랜스포머 저자