Meta-Awareness Enhances Reasoning Models Self-Alignment Reinforcement Learning
Y. Kim, D. Jang and E. Yang, "Meta-Awareness Enhances Reasoning Models: Self-Alignment Reinforcement Learning", arXiv preprint arXiv:2510.03259, 2025.
대형 언어 모델의 추론 능력을 향상시키기 위해 강화학습을 적용하는 연구가 활발히 진행되고 있습니다. 하지만 현재의 추론 모델들은 "어떻게 생각해야 하는지"를 스스로 인지하는 메타 인지(meta-awareness) 능력이 부족합니다. 이 논문은 모델이 예측한 메타 정보와 실제 추론 과정 사이의 정렬(alignment)을 통해 메타 인지 능력을 향상시키는 MASA(Meta-Awareness via Self-Alignment) 프레임워크를 제안합니다.
요약
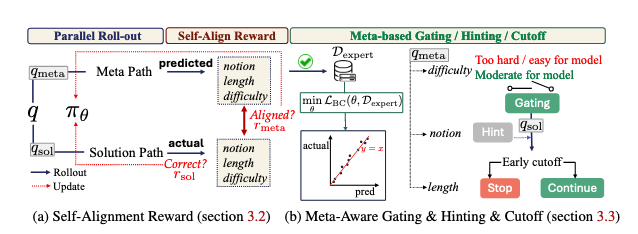
아키텍처: MASA는 병렬 롤아웃 구조를 사용하여 메타 예측 경로와 실제 풀이 경로를 분리합니다. 메타 예측 경로에서는 문제의 난이도, 풀이 길이, 필요한 수학 개념을 예측하고, 풀이 경로에서는 실제 문제를 해결합니다.
사용 모델: Qwen3-8B와 Qwen3-14B 기본 모델을 사용했으며, GRPO와 DAPO 알고리즘과 결합하여 학습을 진행했습니다.
데이터셋: DeepScalerR 데이터셋을 사용하여 학습했으며, AIME24, AIME25, AMC23, MATH500, Minerva, OlympiadBench 등의 수학 벤치마크에서 평가했습니다. 또한 논리적 추론, 과학적 추론, 코딩 영역의 13개 out-of-domain 벤치마크에서도 일반화 성능을 평가했습니다.
평가 메트릭: Pass@1과 Pass@32 점수를 사용하여 모델의 정확도를 측정했습니다.
훈련 방법:
- Self-Alignment 보상: 길이, 난이도, 수학 개념 예측에 대한 세 가지 보상 함수를 통해 메타 예측과 실제 롤아웃을 정렬
- Expert Trajectory Supervision: DAgger 스타일의 모방 학습을 통해 고품질 메타 예측을 학습
- Predictive Gating: 메타 예측을 기반으로 너무 쉽거나 어려운 문제를 사전에 필터링
- Early Cutoff: 예측된 길이를 초과하는 잘못된 롤아웃을 조기에 종료
주요 성과:
- Qwen3-8B 모델에서 수학 벤치마크 평균 6.2% 정확도 향상
- AIME25에서 19.3% 정확도 증가
- GRPO 대비 1.28배 빠른 학습 속도로 동일한 성능 달성
- Out-of-domain 벤치마크에서 평균 2.08% 정확도 향상
논문 상세
1. Introduction
최근 GRPO와 같은 강화학습 기반 사후 학습 방법이 대형 추론 모델(LRMs)의 성능을 크게 향상시켰습니다. 하지만 현재 모델들은 자신의 지식과 무지를 인식하는 메타 인지 능력이 부족합니다. 본 연구는 모델의 메타 예측과 실제 추론 과정 사이의 심각한 불일치를 입증하고, 이를 정렬함으로써 성능 향상을 달성할 수 있음을 보였습니다.
기존 메타 인지 접근법들은 외부 모델, 큐레이션된 데이터셋, 인간이 설계한 추론 파이프라인에 의존합니다. 반면 MASA는 자체 생성 신호를 활용하여 외부 소스 없이 메타 인지를 학습합니다.
2. Related Works
메타 인지 학습: 기존 연구들은 고정된 액션 루프를 사용하거나, 큐레이션된 데이터셋과 외부 검증기에 의존하여 확장성이 제한적입니다. MASA는 인간이 설계한 추론 파이프라인 없이 자체 생성 신호를 활용합니다.
효율적 추론을 위한 자기 제어: 난이도 평가를 통한 예산 할당, 출력 길이 제약 등의 방법이 연구되었습니다. 하지만 이들은 주로 추론 시간 효율성에 초점을 맞추며 때로는 성능 저하가 발생합니다. MASA는 학습 시간 효율성을 목표로 하며 성능과 효율성을 동시에 개선합니다.
3. MASA: Meta-Awareness via Self-Alignment
3.1 Preliminaries
GRPO는 작업 \(q\)에 대해 \(G\)개의 응답 롤아웃을 생성하고, 각 응답에 정답과의 일치 여부에 따라 보상 \(r_i\)를 할당합니다. 정책 최적화는 다음 목적 함수를 최소화합니다:

여기서 \(\Gamma_{i,t}(\theta) = \frac{\pi_\theta(o_{i,t}|q, o_{i,<t})}{\pi_{\theta_{old}}(o_{i,t}|q, o_{i,<t})}\)는 중요도 샘플링 비율입니다.
3.2 MASA: Meta-Awareness via Self-Alignment
정책 모델 \(\pi_\theta\)는 메타 예측 템플릿과 풀이 템플릿으로 프롬프트되어 \(q_{meta}\)와 \(q_{sol}\)을 생성합니다. 모델은 메타 예측 롤아웃 \({o_i^{meta}}_{i=1}^M\)과 풀이 롤아웃 \({o_i^{sol}}_{i=1}^G\)를 병렬로 생성합니다.
메타 예측 롤아웃에 대한 보상은 세 가지 기준의 평균으로 계산됩니다:
길이 보상: \[r_{length} = \mathbb{1}[\min(l_{correct}) \leq l_{pred} \leq \max(l_{correct})]\]
난이도 보상: \[r_{difficulty} = b^{|d_{pred} - d_{sol}|}\]
여기서 \(b < 1\)은 감쇠 계수입니다.
개념 보상: \[r_{notion} = \frac{1}{|n_{pred}|} \sum_{n \in n_{pred}} \mathbb{1}[f_{count}(n, 1) - f_{count}(n, 0) > 0]\]
여기서 \(f_{count}(n, t)\)는 정답/오답 롤아웃에서 개념 \(n\)의 등장 빈도를 계산합니다.
3.3 MASA-efficient: Meta-based Active Control
MASA-efficient는 DAgger 스타일의 모방 학습을 통해 expert 메타 예측 궤적을 학습합니다:
\[\min_\theta L_{BC}(\theta, \mathcal{D}_{expert}) - \alpha \nabla_\theta L_{RL}(\theta)\]
여기서 \(L_{BC}(\theta, \mathcal{D}_{expert}) = \mathbb{E}_{o \sim \mathcal{D}_{expert}} [-\sum_{t=1}^{|o|} \log \pi_\theta(o_t | o_{<t})]\)입니다.
Predictive Gating: 메타 예측을 기반으로 모델의 현재 능력을 벗어난 문제를 사전에 필터링합니다. 예측된 통과율의 표준편차가 0.1 미만일 때만 활성화됩니다.
Early Cutoff: 예측 길이의 2배를 초과하는 롤아웃을 조기에 종료하여 효율성을 높입니다.
4. Experiments
4.1 In-Domain 수학 벤치마크 성능
Qwen3-8B 모델에서 MASA는 6개 수학 벤치마크에서 평균 6.2%의 정확도 향상을 달성했습니다. 특히 AIME25에서 22.18%에서 26.46%로 19.3%의 상대적 향상을 보였습니다.
Qwen3-14B 모델에서도 평균 2.45%의 향상을 기록했으며, Pass@32에서는 더 작은 개선폭을 보였습니다.
4.2 Out-of-Domain 일반화
MASA는 명시적으로 일반화를 위해 학습되지 않았음에도 논리적, 과학적, 코딩 영역의 13개 벤치마크에서 일반화 성능을 개선했습니다:
- 논리적 추론: 평균 1.09% 향상
- 과학적 추론: 평균 1.08% 향상
- 코딩: 평균 0.57% 향상
4.3 Component 분석
메타 인지 보상의 영향: 학습이 진행됨에 따라 긍정적 개념들은 정답 롤아웃에서 더 자주 등장하고, 부정적 개념들은 정답 롤아웃에서 억제되는 패턴을 보였습니다.
Expert Trajectory의 효과: Expert SFT를 추가하면 predictive gating과 early cutoff의 정밀도가 안정화됩니다. Expert SFT 없이는 F1 점수가 각각 0.411, 0.732였으나, 추가 후 0.485, 0.836으로 향상되었습니다.
효율성 향상: MASA-efficient는 학습 시간을 34.5% 단축하면서도 MASA와 유사한 성능을 유지했습니다. 평균적으로 37%의 프롬프트가 gating에 의해 필터링되어 계산 자원을 크게 절약했습니다.
4.4 Ablation Studies
RL 알고리즘: DAPO와 결합했을 때도 MASA는 6개 수학 벤치마크 모두에서 성능 향상을 보였으며, AIME'24에서 18.61%의 상대적 향상을 달성했습니다.
메타 구성 요소의 기여도: Shapley \(R^2\) 분석 결과, 개념 인지(notion-awareness)가 분산의 67.1%를 설명하며 가장 지배적인 요인이었습니다. 난이도 인지와 길이 인지는 각각 23.1%, 8.4%를 차지했으며, 학습 단계의 영향은 1.4%로 미미했습니다.
5. Conclusion
MASA는 자체 정렬을 통해 메타 인지 능력을 강화하는 강화학습 프레임워크입니다. Expert 메타 예측 궤적을 학습에 통합하고 predictive gating과 early cutoff를 통해 안정적이고 효율적인 최적화를 가능하게 합니다.
실험 결과 MASA는 학습 속도를 1.28배 향상시키면서도 in-domain과 out-of-domain 성능을 모두 개선했습니다. 이는 메타 예측이 추론 모델을 향상시키는 원칙적인 방법임을 보여줍니다.
Limitation
본 연구는 길이, 난이도, 개념이라는 세 가지 메타 예측에 초점을 맞췄지만, 원칙적으로는 더 광범위한 메타 사고 전략으로 확장 가능합니다. Gating과 cutoff 하이퍼파라미터는 분석을 기반으로 오프라인에서 설정되었으나, 학습 중 온라인으로 탐색하는 것이 더 유익할 수 있습니다.