청화대와 HKUST가 공동으로 제안한 스트리밍 비디오 편집 프레임워크. 3단계 확산 모델 증류와 AR-oriented Mask Cache를 조합해 InsV2V 대비 97.38배 지연을 단축하고, 12.66 FPS 실시간 편집을 달성합니다.
태그: 영상처리
37개의 게시물
-
-
xAI가 이미지-to-비디오 Arena 1위 모델 Grok Imagine Video 1.5를 공개했습니다. 720p, 네이티브 동기화 오디오, 단일 패스 생성을 $4.20/min에 — Sora 2 대비 86% 저렴합니다.
-

장기 영상 생성에서 반복 등장 인물의 정체성을 유지하기 위해 메모리 기반 피사체 재구성을 보조 학습 목표로 삼는 Memento 프레임워크. 이중 경로 메모리(story query + shot query)로 장기 아이덴티티 단서와 단기 문맥을 분리해, 샷 단위 자기회귀 생성에서 일관된 인물 외형을 유지합니다.
-
알리바바 AMAP-ML DreamX Team이 공개한 5B 파라미터 인터랙티브 월드 모델. E-PRoPE 카메라 제어, 기하학 기반 메모리 검색, 이벤트 합성 제어를 갖추고 8B·14B 경쟁 모델을 전체 스코어에서 앞섰습니다.
-

쾌수 Kling 팀이 제안한 멀티샷 카메라 클로닝 프레임워크입니다. 레퍼런스 비디오의 카메라 파라미터를 3D 빈 공간 그리드 영상으로 변환해 크로스 페어드 데이터 없이도 복잡한 카메라 모션을 클로닝합니다.
-

1989년 AT&T Bell Labs 팀이 미국 우체국 우편번호 이미지에 역전파 합성곱 신경망을 적용해 1% 오류율을 달성한 연구. 합성곱 신경망의 첫 실세계 응용이자 LeNet 계보의 출발점입니다.
-
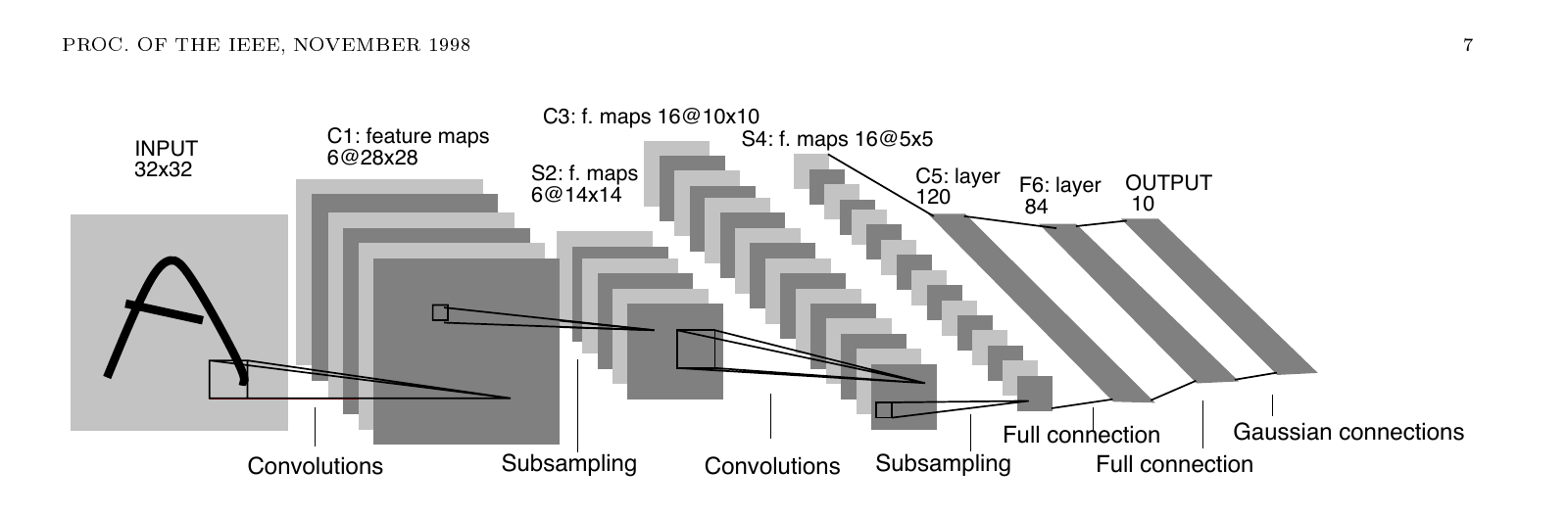
1998년 AT&T Labs 팀이 손글씨 인식부터 미국 은행 수표 판독까지 한 편의 논문으로 묶은 정본. LeNet-5라는 합성곱 신경망 이름이 처음 등장한 글이고, MNIST가 처음 정의된 글이며, 학습 가능한 모듈을 그래프로 잇는 Graph Transformer Network 개념도 여기서 정식화됩니다.
-
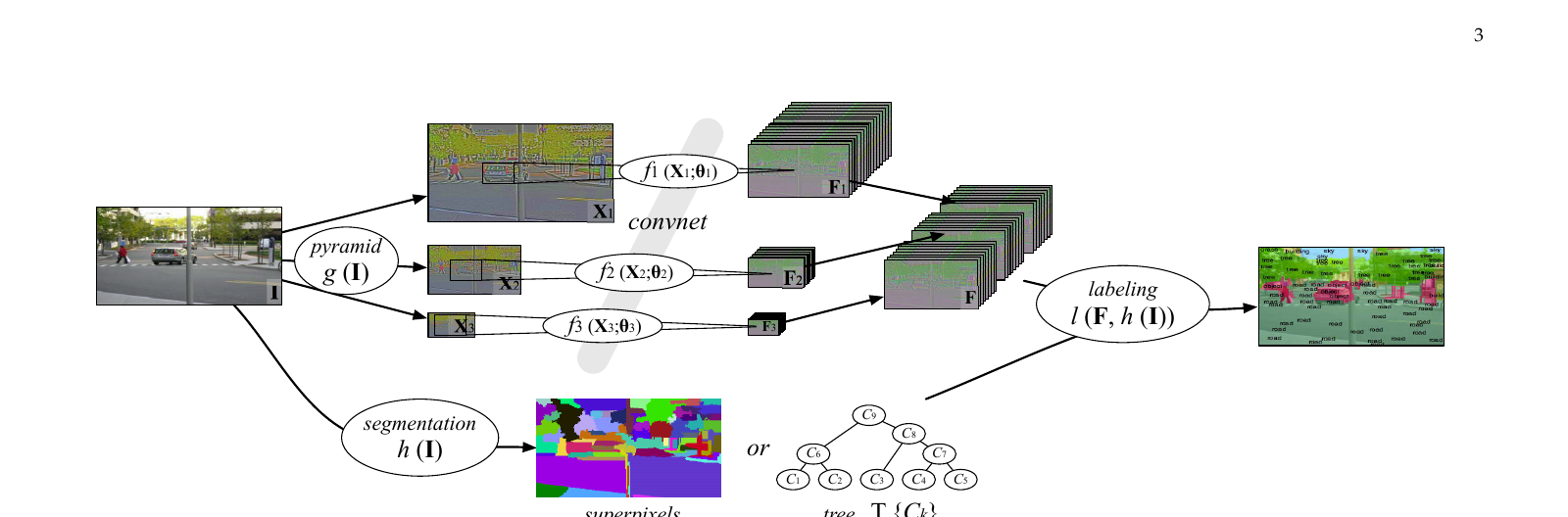
2012~2013년 NYU 르쿤 연구실과 ESIEE 나즈만 팀이 공동으로 정리한 장면 분할 정본. 다중 스케일 합성곱 망이 픽셀별로 큰 맥락을 보고, 영상 경사 위 분할 트리에서 클래스 순도를 최소화하는 *optimal cover*가 후처리를 대신합니다. Stanford Background, SIFT Flow, Barcelona 세 벤치마크에서 최신 기록을 세웠고 한 장 처리에 1초가 걸립니다.
-
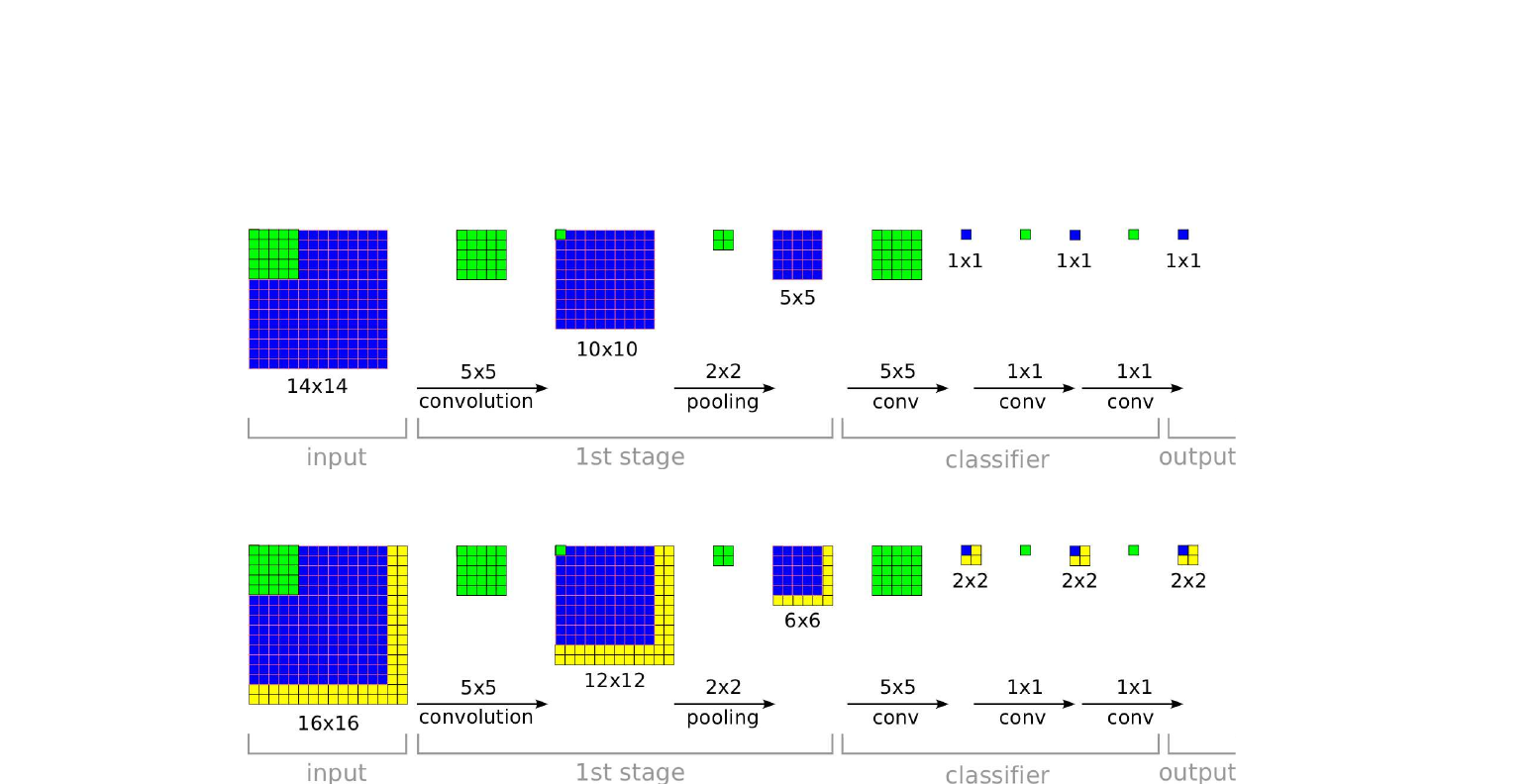 OverFeat - Integrated Recognition, Localization and Detection using Convolutional Networks 2026-05-24
OverFeat - Integrated Recognition, Localization and Detection using Convolutional Networks 2026-05-242013년 NYU CILVR 팀이 한 망으로 분류·위치 추정·검출 세 가지를 동시에 푼 연구. 합성곱 망 자체가 슬라이딩 윈도우라는 통찰을 정식화하고 미세 스트라이드 풀링으로 다중 스케일 평가를 효율화하여 ILSVRC 2013 위치 추정 부문에서 우승하였습니다.
-

학습 없이 기성 비디오 디퓨전 모델로 1,000프레임짜리 긴 영상을 생성하는 MIGA. FIFO-Diffusion 계열의 train-inference gap을 zigzag·unified 두 단계로 좁히고, self-reflection + long-range frame guidance로 장기 일관성을 끌어올려 VBench·NarrLV에서 SOTA를 찍습니다.
-
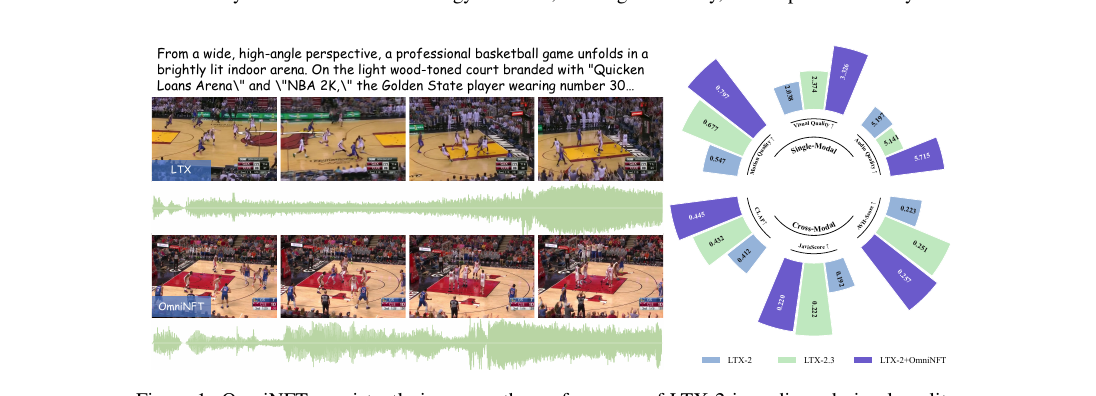
19B 규모 joint audio-video diffusion 모델 LTX-2 위에 RL fine-tuning을 얹어 영상 품질·음향 품질·립싱크를 동시에 끌어올린 OmniNFT를 정리합니다. modality-wise advantage routing, layer-wise gradient surgery, region-wise loss reweighting 세 디자인이 multi-modal RL의 reward hacking 양상을 어떻게 바꾸는지, 그리고 한국 비디오 생성 스타트업·후반 작업 도구 관점에서 어떤 의미를 갖는지 봅니다.
-

텍스트-투-비디오 모델들은 눈을 뗄 수 없을 만큼 아름다운 영상을 만들어냅니다. 그런데 카메라가 크게 움직이는 순간, 뭔가 이상해집니다. 건물 벽이 녹아내리고, 물체가 갑자기 사라지고, 물리적으로 말이 안 되는 장면을 생성합니다. World-R1은 이 문제를 아키텍처 수정 없이, 강화학습(RL)만으로 해결한다고 주장합니다.
-

벌써 4.5가 나온다구요? 두 달 정도밖에 안 지났습니다. 아직 4.5는 테크니컬 리포트가 없습니다. 대신 4.0 테크니컬 리포트를 가져왔습니다. 2K 해상도 이미지를 1.4~1.8초 만에 생성하며, T2I 생성과 이미지 편집 작업을 단일 모델에서 공동 학습합니다. 특히 복잡한 텍스트 렌더링, 다중 이미지 참조, 인컨텍스트 추론 생성 등 기존 모델들이 취약했던 영역에서 강점을 보입니다.
-

또이트댄스입니다. Depth Anything 3는 한 장의 이미지든 여러 장의 영상이든, 카메라 포즈 정보가 있든 없든 상관없이 3D 기하 정보를 예측하는 모델입니다. 평범한 트랜스포머 하나와 단순한 깊이-광선(depth-ray) 표현으로 이전 최고 성능을 44% 능가하는 성능을 달성했으며, 모든 데이터를 공개 학술 데이터셋으로만 학습했습니다.
-
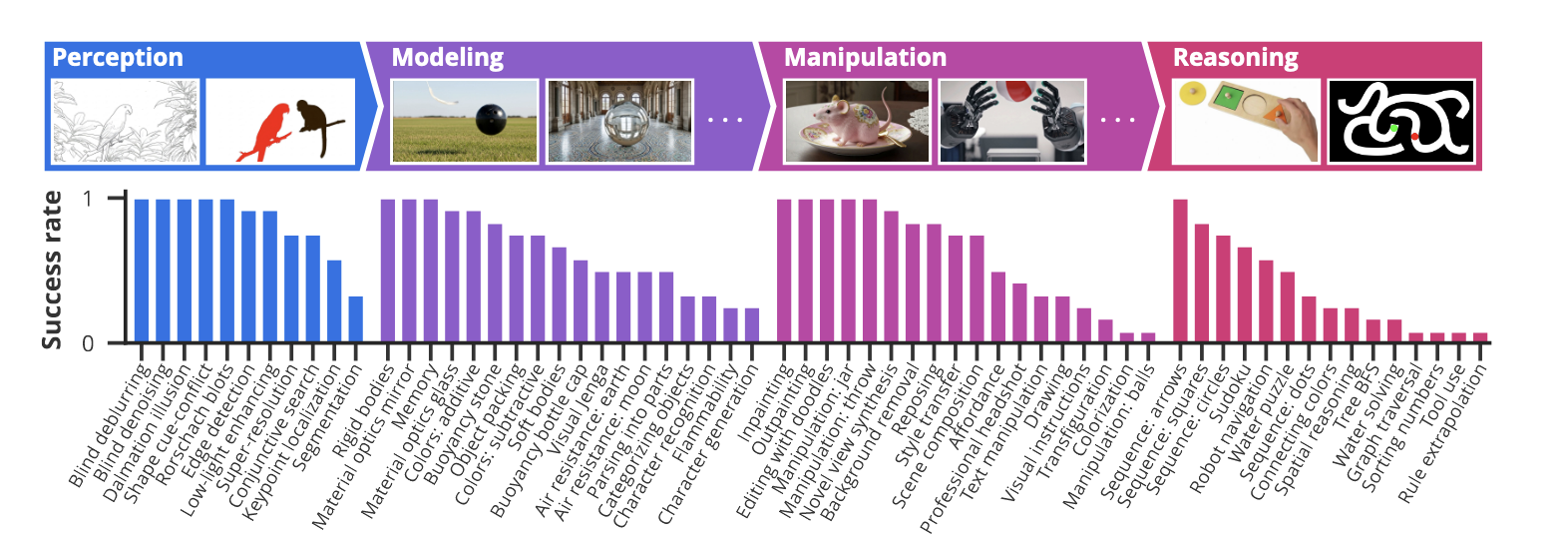
자연어 처리가 변화한 이유가 대규모 언어 모델이라면 컴퓨터 비전이 변화한 이유는 비디오 모델입니다. 믿고 보는 Google DeepMind의 최신 비디오 모델 연구 논문입니다. Veo 3가 명시적으로 학습하지 않은 다양한 시각적 작업을 제로샷 방식으로 해결할 수 있다고 제안합니다.
-
 DINOv3 2025-09-15
DINOv3 2025-09-15Meta AI의 70억 파라미터 자기지도학습 모델 DINOv3 논문을 요약합니다. 라벨 없이 이미지 특징을 학습하는 이 모델의 거대한 아키텍처, 데이터 큐레이션 전략, 그리고 패치 일관성을 유지하는 혁신 기술 'Gram Anchoring'을 중심으로 설명합니다.
-

알리바바 AMAP-ML 연구원으로 minWM 프레임워크·Omni-WorldBench·AngelSlim 등 인터랙티브 월드 모델과 효율 추론 전반에 기여
-
청화대학교(THU). 스트리밍 비디오 편집 연구. LiveEdit 공동 저자 및 코드 메인테이너.
-
청화대학교(THU). 스트리밍 비디오 편집 연구. LiveEdit 제1 저자.
-
중국과학원 자동화연구소(CASIA) 박사과정 연구자로 비전·언어 객체 추적과 train-free 비디오 생성 작업을 병행하는 1저자급 연구자
-
쾌수(Kuaishou) 소속 Kling 비디오 생성 모델 팀. 영상 생성 연구 및 상용 모델 개발.
-
Neocognitron의 발명자, 현대 합성곱 신경망의 구조적 원형을 만든 일본 신경망 연구자
-

USTC 자동화학과 정교수이자 컴퓨터 비전·대규모 멀티모달 모델 연구 그룹 지도교수. OmniNFT의 교신 저자로 [[장궈후이]]·[[위후]] 등 1저자 학생들의 시각 생성 + RL 라인을 총괄.
-
USTC 박사과정. [[자오펑]] 연구실에서 image restoration·diffusion·flow-based generative model을 연구. OmniNFT 공저자.
-
Baidu ERNIE Team 연구자로 Memento 장기 영상 생성 프로젝트를 이끈 Project Lead
-
HKUST 조교수(Division of Arts and Machine Creativity). 비디오 생성, 3D 월드 모델, 신경 렌더링 연구.
-
난징대학 컴퓨터학과 교수로 비디오 이해·행동 인식 분야 권위자이며 HYDRA-X 통합 멀티모달 모델의 교신저자
-
JD.COM 산하 AI 연구 조직. Vision and Multimodal Lab을 [[두안난]] 디렉터가 이끌고 있으며, 비전·멀티모달 파운데이션 모델과 비디오 생성 라인을 외부 대학(USTC 등)과 공동 연구.
-
USTC 박사과정. masked image generation·autoregressive image generation에 GRPO 계열 정책 최적화를 적용해온 1저자로, OmniNFT에서는 joint audio-video diffusion으로 RL 프레임워크를 확장.
-
중국과학원 자동화연구소(CASIA) 정교수이자 패턴인식국가중점실험실(NLPR) 시각 감시·추적 분야 시니어 PI
-
HKUST CSE PhD, Qifeng Chen 연구실. 비디오 생성·편집 "Follow Your" 시리즈 주저자. LiveEdit 교신 저자.
-
샤먼대학 교수로 Memento 장기 영상 생성 연구의 교신저자이며 영상 생성·인식 분야를 연구
-
알리바바 AMAP의 비디오 생성 라인 project lead로 MACE-Dance·S²-Guidance·VMBench·Omni-Effects 등 train-free·평가 작업을 묶어 이끄는 연구자
-
알리바바 AMAP-ML 연구원으로 "There is No VAE" 픽셀공간 생성 모델과 DreamX-World 1.0 인터랙티브 월드 모델의 핵심 기여자
-
JD Explore Academy 연구원. CVPR 2024 YOLO-World(Real-Time Open-Vocabulary Object Detection)의 공동·교신 저자로 알려진 비전 연구자. OmniNFT의 프로젝트 리더.
-
Lightricks가 공개한 19B 파라미터 규모의 joint audio-video foundation model. asymmetric dual-stream(비디오·오디오) 구조에 bidirectional cross-attention으로 modality imbalance를 처리. OmniNFT의 backbone으로 사용됨.
-
샤먼대학 박사과정생으로 Baidu ERNIE Team 인턴 중 Memento 장기 영상 생성 프레임워크를 공동 개발한 제1저자