Kosmos An AI Scientist for Autonomous Discovery
과학 연구는 직선적이지 않습니다. 일단 문헌을 뒤져 선행 연구를 찾아야죠. 틈새를 발견하고, 가설을 세우고, 데이터를 분석합니다. 그리고 다시 문헌으로 돌아갑니다. 훌륭하고 멋진 작업이죠. 정말, 정말 오래 걸린다는 점만 빼면요. 지난 몇 년간 LLM 기반의 AI 에이전트는 이러한 단계를 자동화해 왔습니다. 물론 아직도 많이 부족하죠. 제일 큰 문제는 기억력입니다.
제목: Kosmos: An AI Scientist for Autonomous Discovery
저자: Ludovico Mitchener, Angela Yiu, Benjamin Chang 외 다수
발표: 2025년 11월 (arXiv)
L. Mitchener, A. Yiu, B. Chang et al., "Kosmos: An AI Scientist for Autonomous Discovery," arXiv, vol. 2511.02824, Nov. 2025.
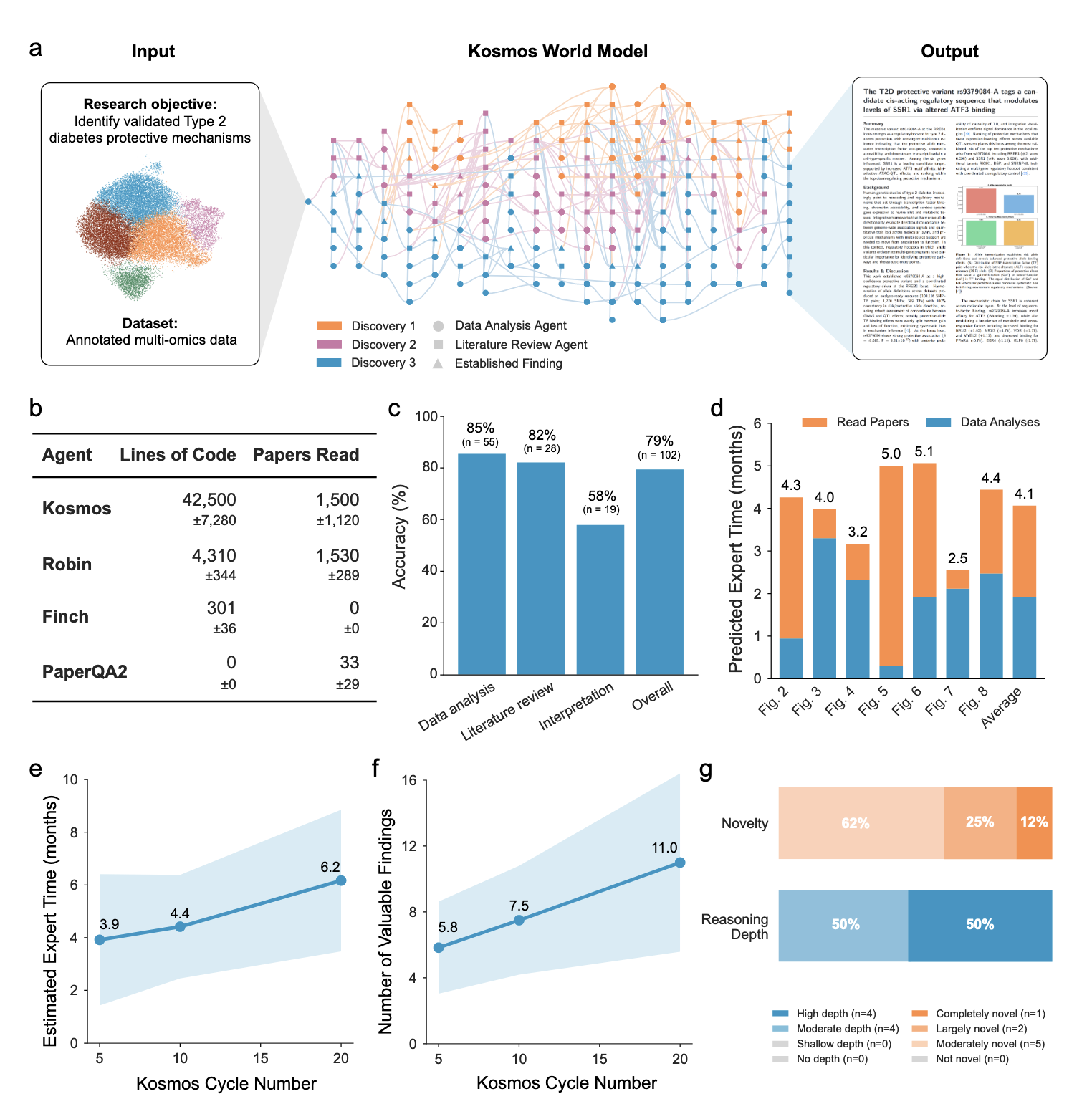
Kosmos는 이 문제를 풉니다. 구조화된 세계 모델(world model) 이라는 일종의 중앙 허브를 둡니다. 데이터 분석 에이전트와 문헌 검색 에이전트가 모두 여기에 정보를 저장하고 꺼냅니다. 그래서 시스템이 최대 12시간 동안 200번 이상 반복하면서도 일관성을 유지할 수 있습니다. 실제로 독립적인 과학자 평가에서 Kosmos 보고서 통계의 79.4%가 정확하다고 판단되었고, 실제 협력 연구팀은 이것이 자신들의 6개월 작업과 맞먹는다고 평가했습니다. 더 흥미로운 것은 단순히 기존 발견을 재현하는 데 그치지 않는다는 점입니다. 신경노화의 메커니즘 같은 인간 연구자가 놓쳤던 새로운 발견까지 만들어냈습니다.
요약
시스템 구조: 세계 모델을 통해 데이터 분석 에이전트와 문헌 검색 에이전트 간 정보 공유
생산성: 1회 실행당 약 42,000줄의 코드 작성, 1,500편의 논문 정독, 선행 시스템 대비 9.8배 증가
정확도: 79.4% (데이터 분석: 85%, 문헌: 82%, 해석: 58%)
인간 등가 시간: 1회 실행 = 약 6개월의 인간 연구 시간
검증: 7개의 발견 사례 중 3개는 미출판/출판 후 논문 재현, 4개는 새로운 기여
응용 분야: 대사체학, 재료 과학, 신경과학, 통계유전학
본론
1. 기존 AI 에이전트의 한계
Kosmos 이전의 AI 과학자 시스템들은 중단된 맥락 때문에 깊은 탐색을 하지 못했습니다. 각 단계마다 정보를 잃어가며 진행되었기에 복잡한 다단계 추론을 완수할 수 없었던 것입니다.
여러 시스템들이 있었습니다. Robin은 문헌 검색과 데이터 분석을 자동화했지만, 에이전트 간 정보 공유가 제한적이고 주로 신약 개발에만 쓰였습니다. Sakana의 AI Scientist는 가설을 세우고 반복적으로 실험을 수행하며 논문까지 썼지만, 기계학습 연구에만 적용되었습니다. Google의 AI 공동 과학자는 가설 생성에 뛰어나지만 실제 실험을 수행하거나 분석하지 못했습니다. Virtual Lab은 SARS-CoV-2 중화 항체 설계에 성공했으나 탐색적 데이터 분석이 부족했습니다.
이들의 공통된 약점은 "맥락 손실"이었습니다. 에이전트 하나가 1,000개 행의 코드를 작성하고 나면, 그 결과를 다음 에이전트에 전달할 때 무엇이 중요했고 무엇을 시도했으며 왜 그 방향을 택했는지 설명하기 어렵습니다. 마치 한 학생이 써 놓은 과제 노트를 다음 학생이 이어받아야 하는데, 필기가 너무 빨라서 이해가 안 되는 것처럼요.
2. 세계 모델: 투명한 정보 공유 메커니즘
Kosmos의 핵심 혁신은 구조화된 세계 모델입니다. 모든 발견, 시도, 결과를 단계적으로 기록하면서 여러 에이전트가 동시에 접근 가능하게 만들었습니다.
Kosmos의 중심에는 "세계 모델"이라는 개념이 있습니다. 이것은 단순한 로그 파일이 아닙니다. 연구자가 최초에 제시한 목표와 데이터를 받으면, Kosmos는 그 목표를 달성하기 위해 어떤 분석과 문헌 검색을 할지 계획을 세웁니다. 그리고 각 사이클에서 최대 10개의 병렬 작업을 시작합니다.
데이터 분석 에이전트가 "변수 X와 Y 사이에 강한 음의 상관관계를 발견했고, 이는 경로 A의 활성화를 시사한다"고 발견하면, 이를 세계 모델에 저장합니다. 그러면 문헌 검색 에이전트가 이것을 보고 "경로 A 활성화"를 검색 쿼리로 만들어서 관련 논문들을 읽습니다. 이렇게 읽은 논문들을 다시 세계 모델에 저장하면, 데이터 분석 에이전트가 "오, 그 경로는 저산소 상황에서 보존되는 메커니즘이군"이라고 알게 되고, 새로운 가설을 세워서 다음 분석을 계획합니다.
이 구조 덕분에 Kosmos는 평균 200번의 에이전트 롤아웃을 실행할 수 있습니다. Robin은 이 정도 규모에서 맥락을 잃었지만, 세계 모델이 있으면 200번을 돌려도 일관성이 유지됩니다. 결과적으로 1회 실행당 평균 42,000줄의 코드가 작성되고, 1,500편의 논문이 정독됩니다. 선행 시스템들은 평균 300-4,300줄, 33-1,500편 수준이었으므로, 이는 획기적인 증가입니다.
3. 정확성 검증: 어디까지 믿을 수 있나?
독립적인 과학자 평가 결과 Kosmos의 정확도는 79.4%입니다. 특히 데이터 기반 주장(85%)과 문헌 기반 주장(82%)은 상당히 신뢰할 수 있지만, 해석 단계(58%)에서는 주의가 필요합니다.
연구팀은 세 개의 대표적인 보고서에서 102개의 주장을 추출했습니다. 그 다음 각 분야의 전문가들에게 이 주장들을 평가하도록 했습니다. 평가 기준은 간단합니다: 그 주장을 재현할 수 있거나 문헌에서 지지를 찾을 수 있으면 "지지", 다른 결과를 얻으면 "반박"입니다.
결과는 흥미롭게도 정확도가 주장의 유형에 따라 달랐습니다. 데이터 분석에 직접 기반한 주장이 85% 정확했습니다. 예를 들어 "이 두 변수의 상관계수는 0.91"이라는 주장이 맞는지 틀린지는 쉽게 확인할 수 있으니까요. 문헌 기반 주장도 82% 정확했습니다. 이것도 논문들을 읽어서 확인할 수 있으니까요.
하지만 해석 단계는 정확도가 58%에 불과했습니다. "이 현상은 에너지 절약 메커니즘을 의미한다"는 주장처럼, 데이터를 어떻게 이해할지에 대한 해석은 더 미묘한 과정입니다. Kosmos는 통계적으로 유의미한 결과를 과학적으로 의미 있는 결과와 혼동하는 경향이 있다는 평가가 있었습니다.
중요한 점은 이것이 약점이 아니라 Kosmos의 가치 명제를 정의한다는 것입니다. 단순히 "정확하다"가 아니라 "광범위하고 편향되지 않은 탐색을 신뢰할 수 있게 수행한다"는 의미입니다. 인간 연구자는 자신의 선입견 때문에 특정 방향만 깊이 있게 탐색하는 경향이 있지만, Kosmos는 그 편향이 적습니다.
4. 실제 발견: 재현부터 혁신까지
Kosmos는 7가지 발견을 만들었습니다. 3개는 미공개/이전 논문 재현, 3개는 기존 발견에 새로운 근거 추가, 1개는 인간 연구자가 놓친 새로운 발견입니다.
4.1 대사체학: 저체온증 뇌보호 메커니즘
첫 번째 발견은 신경 저체온증입니다. 마우스 뇌의 뇌온도 조절 중추(내측 시상전뇌 POA)에 있는 특정 신경을 활성화하면 동물이 저체온 상태로 들어가고, 이것이 뇌 손상으로부터 보호한다는 미출판 발견이 있었습니다. 연구팀은 Kosmos에 대사체 데이터를 주고 "왜 이 저체온 상태가 보호적인가?"를 묻습니다.
Kosmos가 한 일은 다음과 같습니다. 먼저 저체온 쥐와 정상 체온 쥐의 뇌 대사체를 비교했습니다. 무겁게 꼬리가 달린 분포를 정규화한 후 통계 검사를 실행했습니다. 가장 큰 변화를 보인 경로들을 찾았습니다. 결과는 누클레오타이드 대사(nucleotide metabolism)였습니다.
다음, Kosmos는 가설을 세웠습니다: 저체온에서는 에너지를 절약하기 위해 새로운 핵산 합성(de novo synthesis)보다 기존 핵산을 재활용(salvage)하는 경로를 사용한다는 것입니다. 이 가설을 테스트하기 위해 Kosmos는 핵산 전구체와 생산물들 사이의 상관관계를 계산했습니다. 만약 salvage 경로가 활성화되었다면, 전구체는 줄어들고 생산물은 늘어날 것입니다. 정확히 그런 패턴이 나왔습니다.
동시에 문헌 검색 에이전트는 "저산소증에서 핵산 salvage"를 검색했고, 이것이 실제로 보존된 에너지 절약 전략이라는 여러 논문을 찾았습니다. 이를 통해 Kosmos는 최종 결론을 세웠습니다: "저체온 신경보호는 뇌 전역적으로 핵산 salvage로 전환되면서 에너지 항상성을 유지하고 핵산 풀을 보존한다."
흥미로운 점은 이것이 정말 원래 연구팀이 발견한 것과 거의 똑같다는 것입니다. 상위 15개 대사체 중 9개가 겹쳤고, 로그 fold-change 값의 상관계수가 0.998입니다.
4.2 재료과학: 페로브스카이트 태양전지의 "치명적 필터"
두 번째 발견은 완전히 다른 분야입니다. 페로브스카이트 태양전지는 효율이 높지만, 제조 과정의 미세한 환경 변화(온도, 습도, 용매 증기압)에 매우 민감합니다. 정확히 어떤 요소가 가장 중요한지 알려진 것이 없었습니다.
Kosmos에 제조 환경 데이터(센서 측정값)가 주어졌습니다. 상관계수와 부분 의존도 플롯을 계산했습니다. SHAP(SHapley Additive exPlanations) 값으로 각 변수의 영향도를 정량화했습니다. 결과는 명확했습니다: 열처리 단계의 습도가 "치명적 필터(fatal filter)"처럼 작동합니다. 습도가 60 g/m³를 넘으면 장치가 실패합니다.
더 흥미로운 것은 Kosmos가 발견한 추가 관계입니다. DMF 용매 증기압이 증가할수록 단락 전류 밀도(short-circuit current density)가 선형적으로 감소합니다. 이것은 이전에 보고되지 않은 관계였습니다. 나중에 원래 연구팀이 독립적으로 검증했을 때 같은 패턴이 나왔습니다.
4.3 신경과학: 보편적 뇌 네트워크 구조
세 번째 발견은 신경 연결성입니다. 5개 종(C. elegans, 초파리 유충, 초파리 성충, 제브라피시, 마우스)의 8개 뇌 전체 연결 데이터(connectome)가 주어졌습니다. 연구 목표는 간단합니다: "이 신경들의 성질들 사이에 보편적 원리가 있나요?"
Kosmos는 신경 길이와 시냅스 수, 연결도(degree)를 정규화하고 겹쳐 봤습니다. 놀랍게도 모든 종의 데이터가 하나의 곡선으로 겹쳤습니다. 다음, Kosmos는 로그-로그 플롯에서 이 변수들 사이의 거듭제곱 법칙(power-law scaling)을 찾았습니다. 마지막으로, 분포 형태를 테스트했습니다. 기존 이론은 신경 연결도가 거듭제곱 분포(power law)를 따른다고 했습니다. 하지만 Kosmos가 지수 분포, 거듭제곱 분포, 로그정규 분포를 모두 피팅했을 때 로그정규 분포가 가장 잘 맞았습니다.
이것은 흥미로운 함의가 있습니다. 거듭제곱 분포는 "극단적인 이벤트"를 예측하지만, 로그정규 분포는 "곱셈적 과정"을 시사합니다. 즉, 신경은 선형적으로 성장하는 게 아니라 기존 구조에 비례해서 계속 성장하는 방식입니다. 이는 신경 발달 이론에 새로운 관점을 제시합니다.
원래 preprint 저자들과 비교했을 때, Kosmos의 로그정규 평균값이 대부분 출판값의 1 표준편차 내에 있었습니다(상관계수 0.77, 0.46).
4.4 통계유전학: SOD2와 심근 섬유화의 인과 관계
네 번째 발견은 더 기술적입니다. 심근 섬유화(심장 경직)는 심부전의 주요 원인인데, 어떤 단백질이 원인인지 알려진 것이 적습니다. Kosmos에는 전체 게놈 연관 연구(GWAS) 통계와 단백질 정량성 형질 유전자좌(pQTL) 데이터가 주어졌습니다.
Mendelian Randomization이라는 방법을 사용했습니다. 이것은 인과 관계를 추론하는 통계 기법입니다. 유전 변이는 무작위로 할당되기 때문에, 특정 유전 변이가 단백질 수치와 질병 사이를 "매개"한다면, 그 단백질이 원인일 가능성이 높다는 논리입니다.
Kosmos의 결과와 인간 분석의 결과를 비교했을 때, 놀랍도록 일치했습니다. 둘 다 SOD2(superoxide dismutase 2)를 가장 유의미한 인자로 찾았습니다. 효과 크기(effect size)까지 거의 동일했습니다. (Kosmos: β = −0.231, 인간: β = −0.258) 31개 겹치는 단백질의 효과 크기 상관계수는 0.999였습니다.
더 흥미로운 것은 기전입니다. Kosmos는 SOD2의 3' 비번역 영역(3'UTR)에 있는 유전 변이가 miRNA 결합 부위를 방해할 수 있다고 제안했습니다. 이것은 아직 검증 중인 가설이지만, 기존에는 SOD2가 세포 내 항산화 역할만 알려져 있었고, 혈중 SOD2가 심장 리모델링에 영향을 미친다는 아이디어는 새로웠습니다.
4.5 제2형 당뇨병: ATF3을 통한 보호 메커니즘
다섯 번째 발견은 자동 메커니즘 점수 개발입니다. 제2형 당뇨병 관련 1,000개 이상의 유전 변이가 있지만, 어떤 것이 정말 중요한지 알기 어렵습니다. Kosmos는 자동으로 "메커니즘 순위 점수(Mechanism Rank Score)"를 만들었습니다:
\[MRS = PIP \times (1 + \text{Concordance Score} + \text{Experimental Evidence Score})\]
여기서 PIP는 세밀한 매핑의 후대확률, Concordance Score는 여러 QTL 데이터 타입 간 방향 일치, Experimental Evidence Score는 ChIP-seq 검증입니다.
상위 SNP-유전자 쌍은 rs9379084였고, MRS = 6이었습니다. Kosmos는 이 위치의 5개 유전자들이 전사인자 ATF3의 표적이라는 것을 발견했습니다. 특히 SSR1이 주요 표적입니다. TWAS(Transcriptome-Wide Association Study) 데이터를 보면 SSR1의 유전적으로 예측된 수치만 유의미하게 당뇨병과 연관되었습니다.
5. 혁신: 인간이 놓친 것을 찾다
100자 내외: Kosmos의 진정한 가치는 수동적 재현이 아니라 능동적 발견에 있습니다. 인간 연구자가 생성했지만 분석하지 않은 데이터에서 새로운 메커니즘을 찾았습니다.
5.1 알츠하이머 질환: 수렴점(breakpoint) 방법론 개발
여섯 번째 발견은 분석 기법 자체의 혁신입니다. 알츠하이머 질환에서 세포는 시간이 지나면서 tau 단백질을 축적합니다. 원래 질문은 "tau 축적과 함께 어떤 단백질이 변하나?"였습니다.
Kosmos는 차등 발현 분석을 했고, 세포외 기질(ECM) 단백질들이 감소하는 것을 발견했습니다. 하지만 여기서 멈추지 않았습니다. Kosmos는 이렇게 생각했습니다: "tau가 축적되는 시간 과정을 따라가면서, 정확히 언제 ECM이 붕괴하는지 알 수 있지 않을까?"
이를 위해 Kosmos는 "분할 회귀(segmented regression)"라는 기법을 적용했습니다. 이것은 데이터 과학에서는 알려진 기법이지만, 생물학에서 세포 타임라인에 적용된 것은 드문 방법입니다. 10개 ECM 단백질의 평균을 계산하고, pseudotime에 대해 선형 모델과 분할 모델을 비교했습니다. 분할 모델이 훨씬 더 좋은 적합(Davies test, p = 0.017)을 보였고, pseudotime 0.58에서 수렴점을 찾았습니다.
이 수렴점이 실제 의미가 있는지 확인하기 위해 Kosmos는 여러 검증을 수행했습니다. 슬라이딩 윈도우 상관 분석, 부트스트래핑, 그리고 독립적인 데이터셋 검증. 모두 같은 결론을 지지했습니다.
5.2 신경노화: 플립페이즈 붕괴와 미세아교세포 활성화의 이중 메커니즘
일곱 번째 발견은 정말로 새로운 것입니다. 마우스 노화 연구에서 내후각 피질(entorhinal cortex, ENT)의 신경들이 시간이 지남에 따라 취약해진다는 것이 알려져 있었습니다. 하지만 왜인지는 모르고 있었습니다.
Kosmos는 내후각 신경과 시각 피질 신경을 비교했습니다. 노화된 마우스에서 내후각 신경에서만 ATP10A가 강하게 상향조절되어 있었습니다. 문헌 검색으로 Kosmos는 ATP10A가 플립페이즈(flippase)라는 것을 알았습니다. 플립페이즈는 세포막의 지질 대칭성을 유지하는 효소입니다.
더 깊이 파고들었을 때, Kosmos는 놀라운 패턴을 발견했습니다. 노화에 따라 내후각 신경에서 플립페이즈 10개가 모두 하향조절되었습니다. 동시에, 미세아교세포(microglia)에서는 포식 관련 유전자들이 상향조절되었습니다.
이는 매우 구체적인 메커니즘을 시사합니다. 플립페이즈가 줄어들면 세포막 바깥쪽에 포스파티딜세린(phosphatidylserine, PS)이 노출됩니다. PS는 "먹어줘 신호(eat-me signal)"입니다. 동시에 미세아교세포들이 PS를 인식하는 수용체를 더 많이 표현합니다. 결과: 노화된 내후각 신경이 미세아교세포에 의해 포식됩니다.
이 발견은 원래 연구팀이 생성한 데이터에 숨어 있었지만, 인간 연구자들은 이 패턴을 찾지 못했습니다. Kosmos는 체계적이고 편향되지 않은 탐색을 통해 이를 발견했습니다. 독립적 데이터셋 검증, 임상 샘플에서의 재현성 등으로 이 발견의 신뢰성이 입증되었습니다.
6. 현실적 고찰: 한계와 가능성
100자 내외: Kosmos는 강력하지만 한계가 있습니다. 해석 정확도 문제, 데이터셋 크기 제한, 그리고 인간 과학자의 역할이 여전히 중요합니다. 하지만 이러한 한계들은 개선할 수 있는 영역입니다.
6.1 해석의 한계
앞서 본 것처럼, Kosmos의 가장 약한 부분은 해석입니다(정확도 58%). 통계적 유의성을 과학적 중요성과 헷갈립니다. 예를 들어 매우 큰 데이터셋에서 작지만 통계적으로 유의미한 효과를 찾으면, Kosmos는 그것의 과학적 의미를 과대평가할 수 있습니다.
논문 저자들은 이것이 근본적인 한계가 아니라 학습 문제라고 봅니다. Kosmos를 전문가들의 과학적 취향(scientific taste)과 더 일치하도록 훈련하면 개선될 수 있다는 의견입니다.
6.2 데이터 크기 제한
현재 Kosmos는 약 5GB까지의 데이터셋만 관리할 수 있습니다. 또한 원본 이미지나 원본 시퀀싱 데이터 같은 비구조화 데이터를 분석하는 데 서툽습니다. 이는 단기 제약이지만, 유전체학이나 생명과학의 원본 데이터는 종종 이보다 큽니다.
6.3 의존하는 데이터 품질
중요한 통찰: Kosmos는 GIGO 원칙을 따릅니다(Garbage In, Garbage Out). 입력 데이터의 전처리 방식이 결과에 크게 영향을 미칩니다. 원래 연구팀은 발견 2, 5, 6에서 이 문제를 겪었습니다. 데이터를 다르게 전처리했을 때 Kosmos가 다른 결론에 도달했기 때문입니다.
이것은 Kosmos의 약점이 아니라 과학 연구의 보편적 특성입니다. 하지만 과학자가 직접 데이터 큐레이션에 관여해야 한다는 의미입니다.
6.4 과학자-루프의 중요성
Kosmos의 가장 현실적인 위치는 "과학자를 대체하는 것"이 아니라 "과학자를 가속화하는 것"입니다. 프로세스는: 과학자가 데이터와 목표를 선택 → Kosmos가 광범위한 탐색 수행 → 과학자가 결과 평가 및 해석.
이 루프에서 과학자의 역할은 여전히 중요합니다. Kosmos가 비정통적인 분석 방법을 제안할 때 그것이 타당한지 판단하고, 수많은 발견 중 어느 것이 정말 중요한지 선별하고, 그것이 충분히 검증되었는지 결정하는 것은 여전히 인간이 해야 할 일입니다.
7. 결론: 과학 연구의 미래는?
여기 가장 중요한 질문이 있습니다: Kosmos가 구현한 것은 정말 AI 에이전트 기술의 발전일까, 아니면 기존 기술의 영리한 조합일까?
둘 다입니다. Kosmos의 기술 자체는 완전히 새로운 것이 아닙니다. LLM 에이전트, 검색 도구, 코드 생성, 세밀한 매핑 기법 등은 모두 기존에 있던 것들입니다. 진정한 혁신은 "세계 모델"이라는 정보 공유 메커니즘과 이를 통한 맥락 유지입니다.
더 깊은 의미에서, Kosmos는 과학 연구의 구조 자체를 드러냅니다. 과학은 단순한 데이터 분석이 아니라 다중 모드 정보(문헌, 데이터, 가설, 실패한 시도)를 통합하고 일관된 내러티브로 구성하는 과정입니다. Kosmos가 이를 일부 자동화할 수 있다는 것은, 역설적이게도 과학이 얼마나 체계적인지를 보여줍니다.
그러나 과도한 낙관은 금물입니다. 79.4% 정확도는 좋지만 완벽하지 않습니다. 새로운 분야로의 적용 가능성도 아직 검증되지 않았습니다. 인간 과학자의 직관, 편집증적 검증, 그리고 "이게 정말 중요한가?"라는 질문은 여전히 인간의 특권입니다.
Kosmos의 진정한 기여는 "과학 자동화"라기보다 "과학 가속화"에 있습니다. 6개월이 하루가 되면, 과학자는 그 시간에 더 큰 질문을 던질 수 있습니다. 더 깊은 검증을 할 수 있습니다. 더 담대한 가설을 테스트할 수 있습니다. 이것이 Kosmos가 약속하는 미래입니다.
결론
강점:
- 세계 모델이라는 우아한 아키텍처로 장시간 일관성 유지
- 다양한 분야에 적용 가능한 일반성
- 모든 발견이 추적 가능하고 검증 가능한 투명성
- 인간이 놓친 발견까지 이루어낼 수 있는 가능성
약점:
- 해석 정확도 여전히 낮음 (58%)
- 데이터 크기 및 형식의 제한
- 학습 시간과 계산 비용 (12시간 × 많은 리소스)
- 발견의 신뢰성 평가가 여전히 인간에게 달려 있음
Kosmos는 AI 과학자의 현재 한계를 명확히 보여주면서도, 미래의 가능성을 제시합니다. 단순한 도구를 넘어 인간 과학자의 협력 파트너로 작동할 수 있다는 점에서 의의가 있습니다. 특히 광범위한 탐색과 편향 제거라는 측면에서 인간의 보완 역할을 할 수 있습니다. 다만, 과학적 판단력과 창의성의 본질적 부분은 여전히 인간의 영역으로 남아있습니다.