ImageNet Classification with Deep Convolutional Neural Networks
2012년, 딥러닝 대부 제프리 힌턴과 두 명의 대학원생은 컴퓨터 비전 분야에 혁명을 일으킬 논문을 발표합니다. 이 논문은 ImageNet 대회에서 기존 방법들을 압도적으로 뛰어넘는 성능을 보여주며 대 딥러닝 시대를 열었습니다. 논문에서 제안한 모델은 AlexNet이라고 불립니다. 단순히 우수한 성능을 보인 것이 아니라 현대 딥러닝의 핵심 기법들을 체계적으로 도입하여 실용적인 딥러닝의 가능성을 입증했습니다.
A. Krizhevsky, I. Sutskever, and G. E. Hinton, "ImageNet Classification with Deep Convolutional Neural Networks," Advances in Neural Information Processing Systems, vol. 25, pp. 1097-1105, 2012.
요약
AlexNet은 ImageNet LSVRC-2010 데이터셋의 130만 장의 고해상도 이미지를 1000개 클래스로 분류하는 과제에서 top-1 오류율 37.5%, top-5 오류율 17.0%를 달성했습니다. 이는 기존 최고 성능 대비 top-1에서 약 10%, top-5에서 약 11% 향상된 결과입니다.
핵심 아키텍처: 5개의 컨볼루션 레이어와 3개의 완전연결 레이어로 구성된 8층 네트워크로, 총 6000만 개의 매개변수와 65만 개의 뉴런을 가집니다.
사용 데이터셋: ImageNet LSVRC-2010/2012 (약 120만 훈련 이미지, 1000개 클래스)
평가 매트릭: Top-1 및 Top-5 분류 오류율
훈련 방법:
- GPU 2개를 활용한 병렬 훈련
- SGD with momentum (모멘텀 0.9, 배치 크기 128)
- 가중치 감쇠 0.0005
- 학습률 0.01에서 시작하여 검증 성능이 향상되지 않을 때 10으로 나누어 조정
논문 상세
2012년 이전까지 객체 인식 연구에 사용된 이미지 데이터셋은 수 만장 수준입니다. 이 정도로도 MNIST처럼 단순한 문제는 인간 수준의 성능에 근접합니다. 그러나 실제 환경의 복잡한 객체들을 인식하기 위해서는 훨씬 큰 데이터셋이 필요합니다. 이때 ImageNet이라는 대규모 데이터셋이 등장합니다. 이 대규모 데이터셋을 잘 활용한 모델이 이 논문이 소개하는 AlexNet입니다.
저자들은 CNN이 가진 몇 가지 장점에 주목했습니다:
- 깊이와 너비 조절: 모델의 용량을 유연하게 조정 가능
- 이미지의 특성 반영: 통계적 정상성과 픽셀 간 지역적 의존성 가정
- 효율성: 표준 피드포워드 네트워크 대비 적은 연결과 매개변수
데이터셋과 전처리
ImageNet은 1500만 장 이상의 고해상도 이미지로 구성된 대규모 데이터셋입니다. ILSVRC는 이 중 약 1000개 클래스에서 각각 1000장의 이미지를 선별하여 구성됩니다.
전처리 과정:
- 크기 정규화: 가변 해상도 이미지를 256×256으로 조정
- 중앙 크롭: 더 짧은 변을 256으로 조정한 후 중앙에서 256×256 패치 추출
- 픽셀 정규화: 훈련 세트의 평균 활성도를 각 픽셀에서 차감
- 원시 RGB 값 사용: 추가적인 전처리 없이 (중앙화된) 원시 RGB 값으로 훈련
아키텍처의 혁신적 요소
1. ReLU 활성화 함수
가장 중요한 혁신 중 하나는 기존의 tanh나 sigmoid 대신 ReLU를 사용한 것입니다. \[ReLU = \max(0, x)\]
ReLU는 오늘날에도 가장 많이 사용하는 활성화 함수입니다. 0보다 작은 수는 0으로 만들고 그 외의 수는 변화를 주지 않는 아주 단순한 함수입니다. 이 함수가 엄청난 발전을 불러옵니다.
- 빠른 학습: 포화되지 않는 비선형성으로 기울기 소실 문제 완화
- 계산 효율성: 단순한 임계값 연산
- 실험적 검증: CIFAR-10에서 25% 훈련 오류에 도달하는 데 tanh 대비 6배 빠름
2. 다중 GPU 훈련
GTX 580 GPU의 3GB 메모리 제한을 해결하기 위해 두 개의 GPU에 네트워크를 분산시켰습니다.
병렬화 전략:
- 각 GPU에 커널의 절반씩 배치
- 특정 레이어에서만 GPU 간 통신
- 3번째 레이어: 2번째 레이어의 모든 커널 맵에서 입력
- 4번째, 5번째 레이어: 같은 GPU의 3번째 레이어 커널 맵에서만 입력
성능 향상: 단일 GPU 대비 top-1 오류율 1.7%, top-5 오류율 1.2% 감소
3. Local Response Normalization (LRN)
ReLU는 입력 정규화 없이도 학습이 가능하지만, 저자들은 일반화 성능 향상을 위해 LRN을 도입했습니다.
\[b^i_{x,y} = a^i_{x,y} / \left( k + \alpha \sum_{j=\max(0,i-n/2)}^{\min(N-1,i+n/2)} (a^j_{x,y})^2 \right)^\beta\]
여기서:
- \(a^i_{x,y}\): 커널 \(i\)를 위치 \((x,y)\)에 적용한 후 ReLU를 거친 활성도
- \(n=5\), \(k=2\), \(\alpha=10^{-4}\), \(\beta=0.75\)
효과: 실제 뉴런의 측면 억제 메커니즘을 모방하여 큰 활성도 간 경쟁 유도
4. 겹치는 풀링 (Overlapping Pooling)
전통적인 풀링은 인접한 풀링 단위가 겹치지 않지만(\(s = z\)), AlexNet은 겹치는 풀링을 사용했습니다.
설정: \(s = 2\), \(z = 3\) (스트라이드 2, 풀링 윈도우 3×3) 효과:
- 오버피팅 경향 감소
- Top-1 오류율 0.4%, top-5 오류율 0.3% 개선
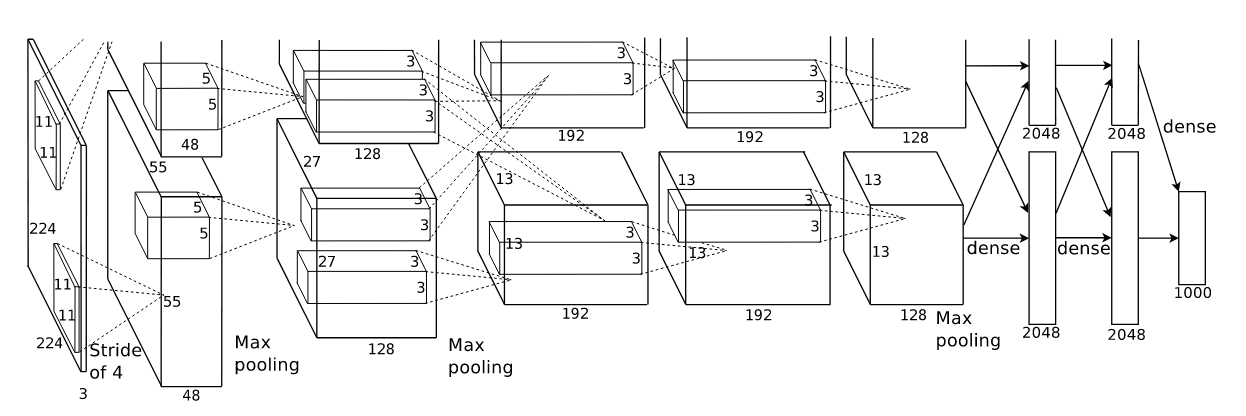
5. 전체 아키텍처
8개의 학습 가능한 레이어로 구성:
컨볼루션 레이어들:
- 1층: 224×224×3 입력 → 96개 11×11×3 커널, 스트라이드 4
- 2층: 256개 5×5×48 커널 (GPU당 48개씩)
- 3층: 384개 3×3×256 커널
- 4층: 384개 3×3×192 커널
- 5층: 256개 3×3×192 커널
완전연결 레이어들: 6. 6층: 4096개 뉴런 7. 7층: 4096개 뉴런
8. 8층: 1000개 뉴런 (1000-way softmax)
오버피팅 방지 기법
6000만 개의 매개변수를 가진 모델이 120만 개의 훈련 샘플로 학습할 때 오버피팅은 심각한 문제였습니다.
1. 데이터 증강 (Data Augmentation)
첫 번째 방법: 이미지 변환과 수평 반전
- 256×256 이미지에서 랜덤하게 224×224 패치 추출
- 수평 반전 적용
- 훈련 세트 크기 2048배 증가
- 테스트 시: 5개 패치(4 모서리 + 중앙) + 수평 반전 = 10개 예측의 평균
두 번째 방법: RGB 채널 강도 변경
- ImageNet 훈련 세트에서 RGB 픽셀 값의 주성분 분석
- 각 훈련 이미지에 주성분의 배수를 추가:
\[[p_1, p_2, p_3][\alpha_1\lambda_1, \alpha_2\lambda_2, \alpha_3\lambda_3]^T\]
여기서 \(p_i\)와 \(\lambda_i\)는 \(i\)번째 고유벡터와 고유값, \(\alpha_i \sim \mathcal{N}(0, 0.1)\)
효과: Top-1 오류율 1% 이상 감소
2. 드롭아웃 (Dropout)
완전연결 레이어에서 각 은닉 뉴런의 출력을 50% 확률로 0으로 설정합니다.
작동 원리:
- 뉴런 간 복잡한 공적응 방지
- 다른 뉴런들과 함께 유용한 더 강건한 특징 학습 강제
- 테스트 시: 모든 뉴런 사용하되 출력에 0.5 곱셈
효과: 드롭아웃 없이는 심각한 오버피팅 발생, 수렴에 필요한 반복 횟수는 약 2배 증가
학습 세부사항
최적화 설정:
- 확률적 경사하강법 사용
- 배치 크기: 128
- 모멘텀: 0.9
- 가중치 감쇠: 0.0005
업데이트 규칙: \[v_{i+1} := 0.9 \cdot v_i - 0.0005 \cdot \epsilon \cdot w_i - \epsilon \cdot \left\langle \frac{\partial L}{\partial w} \bigg|_{w_i} \right\rangle_{D_i}\] \[w_{i+1} := w_i + v_{i+1}\]
가중치 초기화:
- 각 레이어의 가중치: 평균 0, 표준편차 0.01인 가우시안 분포
- 특정 레이어 편향: 1로 초기화 (ReLU에 양수 입력 제공)
- 나머지 레이어 편향: 0으로 초기화
학습률 스케줄링: 0.01에서 시작하여 검증 오류율이 개선되지 않을 때 10으로 나누어 조정
훈련 시간: NVIDIA GTX 580 3GB GPU 2개로 5-6일
실험 결과
ILSVRC-2010 결과
모델 |
Top-1 |
Top-5 |
|---|---|---|
Sparse coding |
47.1% |
28.2% |
SIFT + FVs |
45.7% |
25.7% |
AlexNet |
37.5% |
17.0% |
기존 최고 성능 대비 약 10% 포인트의 극적인 개선을 보였습니다.
ILSVRC-2012 결과
- 단일 CNN: Top-5 오류율 18.2%
- 5개 CNN 앙상블: 16.4%
- 사전 훈련된 CNN 포함 7개 앙상블: 15.3%
- 2등 성능: 26.2%
AlexNet의 성능은 2등과 10% 포인트 이상의 차이로 압도적이었습니다.
정성적 분석
학습된 필터 분석
1번째 컨볼루션 레이어에서 학습된 96개 11×11×3 커널들은 다음과 같은 특성을 보였습니다:
- 주파수 및 방향 선택적 커널: 다양한 방향과 주파수에 반응
- 색상 blob: 다양한 색상 패턴 감지
-
GPU 별 특화:
- GPU 1: 주로 색상에 무관한 커널
- GPU 2: 주로 색상에 특화된 커널
특징 표현 분석
마지막 은닉 레이어(4096차원)의 특징 벡터를 분석한 결과:
- 의미적으로 유사한 이미지들이 유클리드 거리상 가까운 위치에 매핑
- 픽셀 수준에서는 다르지만 의미적으로 유사한 이미지들 검색 가능
- 예: 다양한 포즈의 개, 코끼리 등이 올바르게 클러스터링
의의와 한계
혁신적 기여
- ReLU 활성화 함수: 깊은 네트워크의 실용적 훈련 가능하게 함
- GPU 활용: 대규모 CNN의 효율적 훈련 방법 제시
- 정규화 기법들: LRN, 드롭아웃, 데이터 증강의 체계적 적용
- 아키텍처 설계: 깊이의 중요성 입증 (임의 레이어 제거 시 성능 저하)
한계 및 개선 방향
- 비지도 사전 훈련 미사용: 계산 자원 확보 시 성능 향상 기대
- 네트워크 크기: 인간 시각 시스템 대비 여전히 작은 규모
- 정적 이미지 한계: 비디오의 시간적 구조 활용 필요성
후속 영향
AlexNet은 딥러닝 혁명의 시작점이 되었습니다:
- 아키텍처 발전: VGGNet, GoogLeNet, ResNet 등의 기반
- 기법 확산: ReLU, 드롭아웃, 배치 정규화 등의 표준화
- GPU 컴퓨팅: 딥러닝 훈련의 표준 플랫폼으로 자리잡음
- 산업 응용: 컴퓨터 비전 분야의 상용 솔루션 급속 발전
이 논문은 현재 우리가 사용하는 많은 딥러닝 기법들의 원형입니다. AI의 패러다임 전환을 이끈 기념비적 연구로 평가받고 있습니다.