VFF-Net Evolving forward–forward algorithms into convolutional neural networks for enhanced computational insights
G. Lee, J. Shin, and H. Kim, "VFF-Net: Evolving forward–forward algorithms into convolutional neural networks for enhanced computational insights", Neural Networks, vol. 190, pp. 107697, October 2025, DOI: 10.1016/j.neunet.2025.107697.
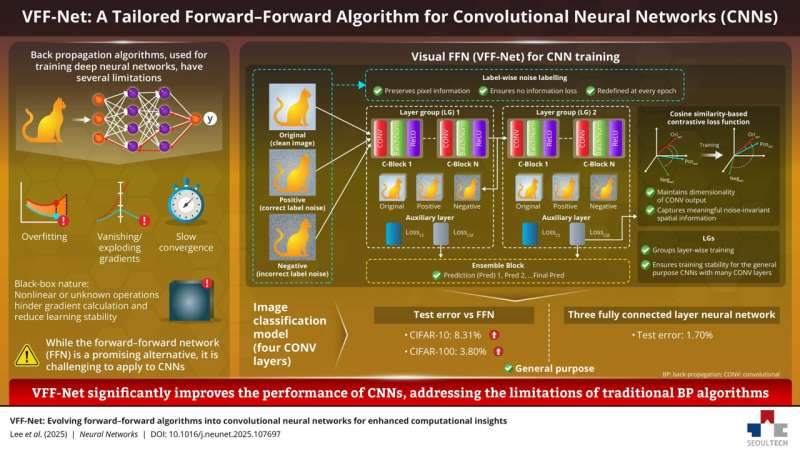
딥러닝의 표준 학습 알고리즘인 역전파(Backpropagation, BP)는 과적합, 기울기 소실/폭발, 느린 수렴, 블랙박스 특성 등의 한계를 가지고 있습니다. 이를 극복하기 위한 대안으로 forward-forward network(FFN)가 제안되었지만, FFN을 컨볼루션 신경망(CNN)에 적용하는 것은 여전히 도전적인 과제였습니다. 이번에 소개할 VFF-Net(Visual Forward-Forward Network)은 FFN을 깊은 CNN에 효과적으로 적용하기 위해 제안된 새로운 방법입니다. 이 논문은 세 가지 핵심 기술을 통해 CNN 학습 성능을 크게 향상시켰습니다. 이 논문을 이해하기 위해 FFN을 간단히 알아보겠습니다.
FFN
- 제안자: Geoffrey Hinton (역전파 알고리즘을 대중화시킨 바로 그 사람!)
- 발표 시기: 2022년 12월 (NeurIPS 2022 키노트 스피치)
- 논문: "The Forward-Forward Algorithm: Some Preliminary Investigations"
FFN의 핵심 아이디어:
역전파의 forward pass + backward pass를 두 개의 forward pass로 대체:
- Positive pass: 실제 데이터로 각 레이어의 goodness를 높임
- Negative pass: 잘못된/생성된 데이터로 goodness를 낮춤
이 논문은 무엇이 다른가?
VFF-Net은 Hinton의 원본 FFN을 CNN에 적용하기 위해 개선한 버전입니다:
- 원본 FFN은 주로 완전 연결(FC) 레이어에 초점
- VFF-Net은 CNN의 컨볼루션 레이어에서도 잘 작동하도록 개선
- LWNL, CSCL, LG 등의 새로운 기법 추가
요약
아키텍처: 4개의 컨볼루션 레이어로 구성된 CNN 모델
핵심 방법론:
- Label-wise noise labeling method: 입력 이미지의 정보 손실 문제 해결
- Cosine-similarity-based contrastive loss: CNN의 goodness function 문제 해결
- Layer grouping: 동일한 출력 채널을 가진 레이어를 그룹화하여 최적화할 극소값 수를 감소시키고 앙상블 효과 구현
데이터셋: MNIST, CIFAR-10, CIFAR-100
평가 메트릭: Test Error (%)
주요 성과:
- CIFAR-10: 기존 CNN 대상 FFN 모델 대비 8.31% 개선
- CIFAR-100: 3.80% 개선
- MNIST: 1.70% test error로 기존 BP보다 우수한 성능
논문 상세
1. 연구 배경 및 문제점
역전파 알고리즘은 딥러닝의 핵심 학습 방법이지만 다음과 같은 한계가 있습니다:
- 과적합 경향
- 기울기 소실/폭발 문제
- 느린 수렴 속도
- 블랙박스 특성
이를 극복하기 위해 forward-forward network(FFN)가 등장했습니다. FFN은 두 가지 데이터 흐름을 활용한 goodness 기반 greedy 알고리즘으로 BP를 우회합니다. 하지만 FFN을 CNN에 적용할 때 다음의 문제가 발생합니다:
첫 번째 문제: 기존 FFN의 goodness function은 주로 완전 연결(FC) 레이어를 위해 설계되었고, 입력 이미지의 공간적 특성을 고려하지 않았습니다. 이를 수정 없이 컨볼루션(CONV) 레이어에 직접 적용하면 이미지의 공간 차원에서 추상적인 정보를 놓치게 되어 정확도가 크게 저하됩니다.
두 번째 문제: FFN의 데이터 흐름은 원-핫 인코딩된 레이블을 입력 이미지의 픽셀 데이터에 직접 오버레이하는 방식으로 구성됩니다. 따라서 데이터셋의 클래스 수가 증가하면 입력 이미지의 정보 손실이 직접적으로 발생하여 모델 성능을 저해합니다.
세 번째 문제: CNN은 일반적으로 많은 CONV 레이어를 깊게 쌓고 BP를 사용하여 전체 네트워크의 계산 그래프를 최적화함으로써 성능을 향상시킵니다. 하지만 모든 레이어를 개별적으로 학습하는 FFN에서는 레이어 수가 증가할수록 전체 네트워크의 계산 그래프를 최적화하기가 어려워집니다.
2. 제안 방법: VFF-Net의 세 가지 핵심 기술
VFF-Net은 FFN의 개념을 컴퓨터 비전 작업에 널리 사용되는 CNN에 실질적으로 적용하기 위해 제안되었습니다. 이 방법은 세 가지 핵심 기술로 구성됩니다.
2.1 Label-wise Noise Labeling (LWNL)
입력 이미지의 정보 손실 문제를 해결하기 위한 방법입니다. 레이블을 이미지의 픽셀 정보에 직접 오버레이하지 않고, 정보 손실 없이 데이터 흐름을 가능하게 합니다. 이를 통해 입력 이미지의 모든 정보를 사용하여 학습과 추론이 가능하며, 다양한 도메인에서 높은 강건성을 보입니다.
2.2 Cosine Similarity-based Contrastive Loss (CSCL)
CONV 레이어의 특성에 맞춘 손실 함수입니다. 4차원 CONV 표현들 사이의 특정 마진을 공간 차원에서 의도적으로 제어함으로써 FFN을 CONV 레이어로 확장할 수 있게 합니다. 이는 중간 특징(intermediate features)을 직접 사용하여 CNN에 적용할 때 발생하는 goodness function의 성능 저하 문제를 해결합니다.
2.3 Layer Grouping (LG)
동일한 출력 채널 크기를 가진 레이어들을 그룹화하고 앙상블하는 방법입니다. 이는 최적화해야 할 극소값의 수를 줄이고, 앙상블 학습의 효과를 보여줌으로써 잘 알려진 기존 CNN 기반 모델로의 전이를 용이하게 합니다. 일반적인 CNN 기반 모델의 사전 학습된 가중치를 미세 조정할 수 있는 유연성도 제공합니다.
3. 실험 결과
VFF-Net은 여러 벤치마크 데이터셋에서 우수한 성능을 보였습니다:
CIFAR-10 및 CIFAR-100: 4개의 컨볼루션 레이어로 구성된 이미지 분류 모델에서 VFF-Net은 기존 CNN을 대상으로 하는 FFN 모델과 비교했을 때 test error를 CIFAR-10에서 최대 8.31%, CIFAR-100에서 3.80% 개선했습니다.
MNIST: 3개의 완전 연결 레이어로 구성된 신경망에서 VFF-Net은 1.70%의 test error를 달성했습니다. 이는 기존 BP뿐만 아니라 기존의 FC 레이어 기반 FFN 방법들보다도 우수한 성능입니다.
확장성: VFF-Net은 ResNet18/34/50을 미세 조정함으로써 범용 모델로 쉽게 확장될 수 있으며, 이는 다양한 도메인으로의 일반화 가능성을 시사합니다.
4. 결론
VFF-Net은 FFN을 개선하여 BP와의 성능 격차를 크게 줄이고, 기존 CNN 기반 모델로 이식 가능한 유연성을 보여줍니다. 세 가지 핵심 기술(LWNL, CSCL, LG)을 통해 입력 정보 손실 문제와 goodness function의 성능 저하 문제를 모두 해결했으며, 중간 특징을 직접 활용하여 정확도와 일반화 성능을 향상시켰습니다.
이 연구는 역전파의 대안으로서 FFN의 실용적 적용 가능성을 보여주며, 특히 CNN 구조에서 BP 없이도 경쟁력 있는 성능을 달성할 수 있음을 입증했습니다.